What should I do if I want to write down a lot of “facts” in the database of a much larger volume than it can withstand? First, of course, we bring the data to a more economical normal form and get “dictionaries”, which we will write once . But how to do it most effectively?This is exactly the question we faced when developing monitoring and analysis of PostgreSQL server logs , when other methods of optimizing the record in the database were exhausted.We’ll make a reservation right away that our collectors are running Node.js , so we don’t interact with processor registers and caches in any way. And the option of using "hundred" or external caching services / databases gives too much delay for incoming streams of several hundred Mbps .Therefore, we try to cache everything in RAM , specifically in the memory of the JavaScript process. About how to organize this more efficiently, and we will go further.Availability Caching
Our main task is to make sure that the only instance of any object gets into the database. These are the repeatedly repeated original texts of SQL queries, templates of plans for their implementation , nodes of these plans — in short, some text blocks .Historically, as an identifier we used a UUID-value, which was obtained as a result of direct calculation of the MD5 hash from the text of the object. After that, we check the availability of such a hash in the local "dictionary" in the process memory , and if it is not there, only then we write to the database in the "dictionary" table.That is, we do not need to store the original text value itself (and sometimes it takes tens of kilobytes) - just the very fact of the presence of the corresponding hash in the dictionary is enough .Key Dictionary
Such a dictionary can be kept in Array, and used Array.includes()to check for availability, but this is quite redundant - the search degrades (at least in previous versions of V8) linearly from the size of the array, O (N). And in modern implementations, despite all the optimizations, it loses at a speed of 2-3%.Therefore, in the pre-ES6 era, storage was the traditional solution Object, with stored values as keys. But everyone assigned the values of the keys what he wanted - for example Boolean,:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
But it’s quite obvious that we are clearly storing the excess here - the very value of the key that no one needs. But what if it is not stored at all? So the Set object appeared .Tests show that searching with help is Set.has()approximately 20-25% faster than key verification c Object. But this is not his only advantage. Since we store less, then we should need less memory - and this directly affects performance when it comes to hundreds of thousands of such keys.So, Objectin which there are 100 UUID keys in a text representation, it occupies 6,216 bytes in memory :
Setwith the same contents - 2,632 bytes :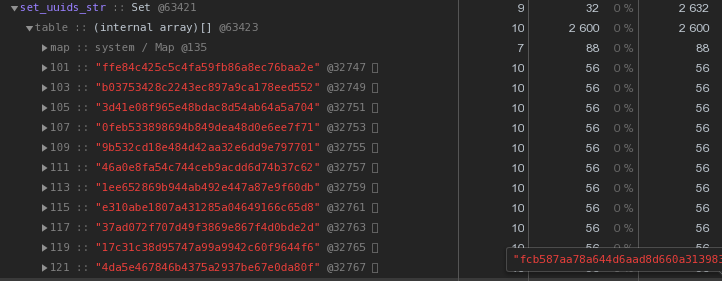 That is, it
That is, it Setworks faster and at the same time takes2.5 times less memory - the winner is obvious.We optimize the storage of UUID keys
In general, in the nature of distributed systems, UUID keys are quite common - in our VLSI they are, at a minimum, used to identify documents and regulations in electronic document management , people in messaging , ...Now let's take a closer look at the picture above - each UUID is the key stored in the hex representation “costs” us 56 bytes of memory . But we have hundreds of thousands of them, so it’s reasonable to ask: “Is it possible to have less?”First, recall that the UUID is a 16-byte identifier. Essentially a piece of binary data. And for transmission by email, for example, binary data is encoded in base64 - try to apply it:let str = Buffer.from(uuidstr, 'hex').toString('base64');
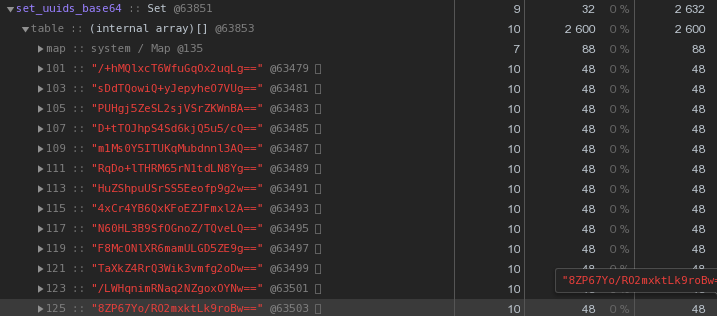 Already 48 bytes each is better, but imperfect. Let's try translating the hexadecimal representation directly into a string:
Already 48 bytes each is better, but imperfect. Let's try translating the hexadecimal representation directly into a string:let str = Buffer.from(uuidstr, 'hex').toString('binary');
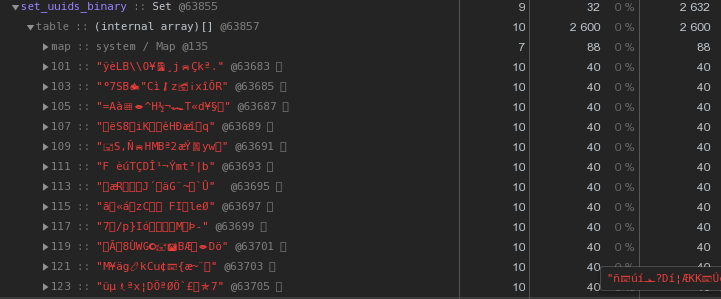 Instead of 56 bytes per key - 40 bytes, saving almost 30% !
Instead of 56 bytes per key - 40 bytes, saving almost 30% !Master, worker - where to store dictionaries?
Considering that the vocabulary data from the workers intersect quite strongly, we made the storage of the dictionaries and writing them to the database in the master process, and the transfer of data from the workers through the IPC message mechanism .However, a significant portion of the master’s time was spent on channel.onread- that is, processing the receipt of packets with "dictionary" information from child processes: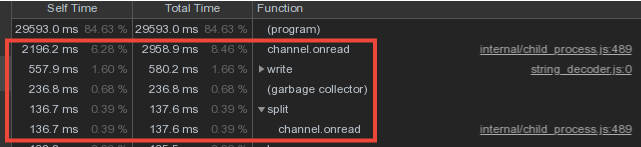
Dual Set Write Barrier
Now let's think for a second - the workers send and send the master the same vocabulary data (basically these are the plan templates and the repeating request bodies), he parses them with his sweat and ... does nothing, because they have already been sent to the database before !So if we Set“protected” the database from re-recording from the master with a dictionary, why not use the same approach to “protect” the master from being transferred from the worker? ..Actually, that was done, and reduced the direct costs of servicing the exchange channel three times :
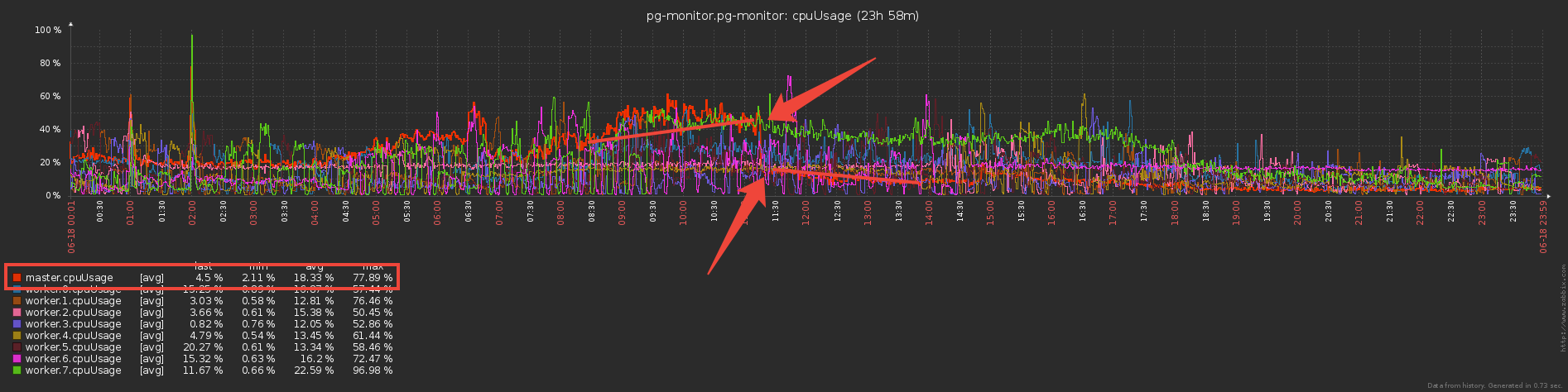 But now the workers do seem to do more work - store dictionaries and filter by them? Or not? .. In fact, they began to work significantly less, since the transfer of large volumes (even via IPC!) Is not cheap.
But now the workers do seem to do more work - store dictionaries and filter by them? Or not? .. In fact, they began to work significantly less, since the transfer of large volumes (even via IPC!) Is not cheap.Nice bonus
As the wizard now began to receive a much smaller amount of information, it began to allocate much less memory for these containers - which means that the time spent on the Garbage Collector’s work decreased significantly, which positively affected the latency of the system as a whole.Such a scheme provides protection against repeated entries at the collector level, but what if we have several collectors? Only the trigger with will help here INSERT ... ON CONFLICT DO NOTHING.Speed up hash calculation
In our architecture, the entire log stream from one PostgreSQL server is processed by one worker.That is, one server is one task for the worker. In this case, the loading of workers is balanced by the purpose of the server tasks so that the CPU consumption by the workers of all collectors is approximately the same. This is a separate service dispatcher.“On average,” each worker handles dozens of tasks that produce approximately the same total load. However, there are servers that significantly surpass the rest in the number of log entries. And even if the dispatcher leaves this task the only one on the worker, its download is much higher than the others:We removed the CPU profile of this worker: On the top lines, the calculation of MD5 hashes. And they are really calculated a huge amount - for the entire stream of incoming objects.
On the top lines, the calculation of MD5 hashes. And they are really calculated a huge amount - for the entire stream of incoming objects.xxHash
How to optimize this part, except for these hashes, we can not?We decided to try another hash function - xxHash , which implements Extremely fast non-cryptographic hash algorithm . And the module for Node.js is xxhash-addon , which uses the latest version of the xxHash 0.7.3 library with the new XXH3 algorithm.Check by running each option on a set of rows of different lengths:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Results:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
As expected , xxhash3 was much faster than MD5 !It remains to check for resistance to collisions. Sections of the dictionary tables are being created for us every day, so outside the boundaries of the day we can safely allow the intersection of hashes.But just in case, they checked with a margin in the interval of three days - not a single conflict that suits us more than suits.Hash Replacement
But we simply cannot take and exchange old UUID fields in the dictionary tables for a new hash, because both the database and the existing frontend wait for objects to continue to be identified by UUID.Therefore, we will add one more cache to the collector - for already calculated MD5. Now it will be a Map , in which the keys are xxhash3, the values are MD5. For identical lines, we do not recount the “expensive” MD5 again, but take it from the cache:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
We remove the profile - the fraction of the time for computing hashes has decreased markedly, cheers! So now we count xxhash3, then check the MD5 cache and get the desired MD5, and then check the dictionary cache - if this md5 is not there, then send it to the database for writing.Something too many checks ... Why check the dictionary cache if you have already checked the MD5 cache? It turns out that all dictionary caches are no longer needed and it’s enough to have only one cache - for MD5, with which all the basic operations will be performed:
So now we count xxhash3, then check the MD5 cache and get the desired MD5, and then check the dictionary cache - if this md5 is not there, then send it to the database for writing.Something too many checks ... Why check the dictionary cache if you have already checked the MD5 cache? It turns out that all dictionary caches are no longer needed and it’s enough to have only one cache - for MD5, with which all the basic operations will be performed: As a result, we replaced the check in several “object” dictionaries with one MD5 cache, and the resource-intensive operation of calculating MD5 is Hash is performed only for new entries, using the much more efficient xxhash for the incoming stream.thankKilor for help in preparing the article.
As a result, we replaced the check in several “object” dictionaries with one MD5 cache, and the resource-intensive operation of calculating MD5 is Hash is performed only for new entries, using the much more efficient xxhash for the incoming stream.thankKilor for help in preparing the article.