 (image taken from here )
(image taken from here )
Today we would like to tell you about the task of post-processing the results of recognition of text fields based on a priori knowledge of the field. Earlier, we already wrote about the method of field correction based on trigrams , which allows you to correct some recognition errors of words written in natural languages. However, a significant part of important documents, including identification documents, are fields of a different nature - dates, numbers, VIN-codes of cars, TIN and SNILS numbers, machine-readable zoneswith their checksums and more. Although they cannot be attributed to the fields of a natural language, nevertheless, such fields often have some, sometimes implicit, language model, which means that some correction algorithms can also be applied to them. In this post, we will discuss two mechanisms for post-processing recognition results that can be used for a large number of documents and field types.The language model of the field can be conditionally divided into three components:- Syntax : rules governing the structure of a text field representation. Example: the “document expiration date” field in a machine-readable zone is represented as seven digits “DDDDDDD”.
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
Having information about the semantic and syntactic structure of the document and the recognized field, you can build a specialized algorithm for post-processing the recognition result. However, taking into account the need to support and develop recognition systems and the complexity of their development, it is interesting to consider “universal” methods and tools that would allow, with minimal effort (from the developers), to build a fairly good post-processing algorithm that would work with an extensive class documents and fields. The methodology for setting up and supporting such an algorithm would be unified, and only the language model would be a variable component of the algorithm structure.It is worth noting that post-processing of text field recognition results is not always useful, and sometimes even harmful: if you have a fairly good line recognition module and you work in critical systems with identification documents, then some kind of post-processing it is better to minimize and produce results “as is”, or clearly monitor any changes and report them to the client. However, in many cases, when it is known that the document is valid, and that the language model of the field is reliable, the use of post-processing algorithms can significantly increase the final recognition quality.So, the article will discuss two post-processing methods that claim to be universal. The first is based on weighted finite converters, requires a description of the language model in the form of a finite state machine, is not very easy to use, but more universal. The second one is easier to use, more efficient, requires only writing a function for checking the validity of the field value, but also has a number of disadvantages.Weighted End Transmitter Method
A beautiful and fairly general model that allows you to build a universal algorithm for post-processing recognition results is described in this work . The model relies on the data structure of Weighted Finite-State Transducers (WFST).WFSTs are a generalization of weighted finite state machines - if a weighted finite state machine encodes some weighted language  (i.e., a weighted set of lines over a certain alphabet
(i.e., a weighted set of lines over a certain alphabet  ), then WFST encodes a weighted map of a language
), then WFST encodes a weighted map of a language  above the alphabet
above the alphabet  into a language
into a language  above the alphabet
above the alphabet  . A weighted finite state machine, taking a string
. A weighted finite state machine, taking a string  over the alphabet , assigns some weight to it
over the alphabet , assigns some weight to it  , whereas WFST, taking a string
, whereas WFST, taking a string over the alphabet , associates with it a set of (possibly infinite) pairs
over the alphabet , associates with it a set of (possibly infinite) pairs  , where
, where  is the line above the alphabet into which the line is converted , and
is the line above the alphabet into which the line is converted , and  is the weight of such a conversion. Each transition of the converter is characterized by two states (between which the transition is made), the input characters (from the alphabet ), the output characters (from the alphabet ) and the weight of the transition. An empty character (empty string) is considered to be an element of both alphabets. The weight of the string
is the weight of such a conversion. Each transition of the converter is characterized by two states (between which the transition is made), the input characters (from the alphabet ), the output characters (from the alphabet ) and the weight of the transition. An empty character (empty string) is considered to be an element of both alphabets. The weight of the string  to string conversion
to string conversion  is the sum of the products of the transition weights along all the paths on which the concatenation of the input characters forms the string , and the concatenation of the output characters forms the string, and which transfer the converter from the initial state to one of the terminal ones.The composition operation is determined over WFST, on which the post-processing method is based. Let two transformers be given
is the sum of the products of the transition weights along all the paths on which the concatenation of the input characters forms the string , and the concatenation of the output characters forms the string, and which transfer the converter from the initial state to one of the terminal ones.The composition operation is determined over WFST, on which the post-processing method is based. Let two transformers be given  and
and  , and convert the line above
, and convert the line above  to the line above
to the line above  with the weight
with the weight  , and convert over to the line
, and convert over to the line  above
above  with the weight
with the weight  . Then the converter
. Then the converter  , called the composition of the converters, converts the string into a string with a weight
, called the composition of the converters, converts the string into a string with a weight . The composition of the transducers is a computationally expensive operation, but it can be calculated lazily - the states and transitions of the resulting transducer can be constructed at the moment when they need to be accessed.The algorithm for post-processing the recognition result based on WFST is based on three main sources of information - the hypothesis
. The composition of the transducers is a computationally expensive operation, but it can be calculated lazily - the states and transitions of the resulting transducer can be constructed at the moment when they need to be accessed.The algorithm for post-processing the recognition result based on WFST is based on three main sources of information - the hypothesis  model, the error model,
model, the error model,  and the language model
and the language model  . All three models are presented in the form of weighted final transducers:
. All three models are presented in the form of weighted final transducers:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
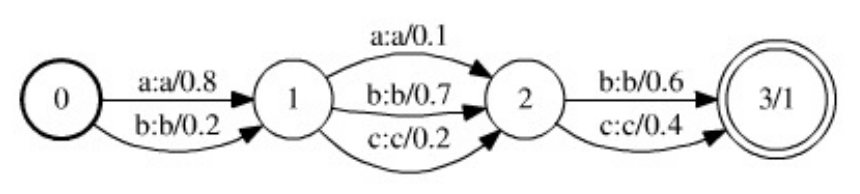
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
After defining a model of hypotheses, errors, and a language model, the task of post-processing recognition results can now be posed as follows: consider the composition of all three models  (in terms of WFST composition). The converter
(in terms of WFST composition). The converter  encodes all possible conversions of strings from the hypothesis model into strings from the language model , applying transforms encoded in the error model to strings . Moreover, the weight of such a transformation includes the weight of the original hypothesis, the weight of the transformation, and the weight of the resulting string (in the case of a weighted language model). Accordingly, in such a model, the optimal post-processing of the recognition result will correspond to the optimal (in terms of weight) path in the convertertranslating it from the initial to one of the terminal states. The input line along this path will correspond to the selected initial hypothesis, and the output line to the corrected recognition result. The optimal path can be sought using algorithms for finding the shortest paths in directed graphs.The advantages of this approach are its generality and flexibility. The error model, for example, can be easily expanded in such a way as to take into account deletions and additions of characters (for this, it is only worth adding transitions with an empty output or input symbol, respectively, to the error model). However, this model has significant disadvantages. First, the language model here should be presented as a finite weighted finite transformer. For complex languages, such an automaton can turn out to be rather cumbersome, and in case of a change or refinement of the language model, it will be necessary to rebuild it. It should also be noted that the composition of the three transducers as a result has, as a rule, an even more bulky transducer,and this composition is calculated every time you start post-processing one recognition result. Due to the bulkiness of the composition, the search for the optimal path in practice has to be performed with heuristic methods such as A * -search.Using the model of verifying grammars, it is possible to construct a simpler model of the task of post-processing recognition results, which will not be as general as the model based on WFST, but easily extensible and easy to implement.A checking grammar is a pair
encodes all possible conversions of strings from the hypothesis model into strings from the language model , applying transforms encoded in the error model to strings . Moreover, the weight of such a transformation includes the weight of the original hypothesis, the weight of the transformation, and the weight of the resulting string (in the case of a weighted language model). Accordingly, in such a model, the optimal post-processing of the recognition result will correspond to the optimal (in terms of weight) path in the convertertranslating it from the initial to one of the terminal states. The input line along this path will correspond to the selected initial hypothesis, and the output line to the corrected recognition result. The optimal path can be sought using algorithms for finding the shortest paths in directed graphs.The advantages of this approach are its generality and flexibility. The error model, for example, can be easily expanded in such a way as to take into account deletions and additions of characters (for this, it is only worth adding transitions with an empty output or input symbol, respectively, to the error model). However, this model has significant disadvantages. First, the language model here should be presented as a finite weighted finite transformer. For complex languages, such an automaton can turn out to be rather cumbersome, and in case of a change or refinement of the language model, it will be necessary to rebuild it. It should also be noted that the composition of the three transducers as a result has, as a rule, an even more bulky transducer,and this composition is calculated every time you start post-processing one recognition result. Due to the bulkiness of the composition, the search for the optimal path in practice has to be performed with heuristic methods such as A * -search.Using the model of verifying grammars, it is possible to construct a simpler model of the task of post-processing recognition results, which will not be as general as the model based on WFST, but easily extensible and easy to implement.A checking grammar is a pair  , where is the alphabet, and
, where is the alphabet, and  is the predicate of admissibility of a string over the alphabet , i.e.
is the predicate of admissibility of a string over the alphabet , i.e.  . A checking grammar encodes a certain language over the alphabet as follows: a line
. A checking grammar encodes a certain language over the alphabet as follows: a line  belongs to the language if the predicate takes a true value on this line. It is worth noting that checking grammar is a more general way of representing a language model than a state machine. Indeed, any language represented as a finite state machine, can be represented in the form of a checking grammar (with a predicate
belongs to the language if the predicate takes a true value on this line. It is worth noting that checking grammar is a more general way of representing a language model than a state machine. Indeed, any language represented as a finite state machine, can be represented in the form of a checking grammar (with a predicate  , where
, where  is the set of lines accepted by the automaton . However, not all languages that can be represented as a checking grammar are representable as a finite automaton in the general case (for example, a language of words of unlimited length over alphabet
is the set of lines accepted by the automaton . However, not all languages that can be represented as a checking grammar are representable as a finite automaton in the general case (for example, a language of words of unlimited length over alphabet  , in which the number of characters is
, in which the number of characters is  greater than the number of characters
greater than the number of characters  .)Let the recognition result (hypothesis model) be given as a sequence of cells(same as in the previous section). For convenience, we assume that each cell contains K alternatives and all alternative estimates take a positive value. Evaluation (weight) of the string will be considered the product of the ratings of each of the characters of this string. If the language model is specified in the form of a checking grammar , then the post-processing problem can be formulated as a discrete optimization (maximization) problem on a set of controls
.)Let the recognition result (hypothesis model) be given as a sequence of cells(same as in the previous section). For convenience, we assume that each cell contains K alternatives and all alternative estimates take a positive value. Evaluation (weight) of the string will be considered the product of the ratings of each of the characters of this string. If the language model is specified in the form of a checking grammar , then the post-processing problem can be formulated as a discrete optimization (maximization) problem on a set of controls  (the set of all lines of length over the alphabet ) with an admissibility predicate and functional
(the set of all lines of length over the alphabet ) with an admissibility predicate and functional  , where
, where  is the symbol estimate
is the symbol estimate  in the ith cell .Any discrete optimization problem (i.e., with a finite set of controls) can be solved using a complete enumeration of controls. The described algorithm efficiently iterates over the controls (rows) in decreasing order of the functional value until the validity predicate accepts the true value. We set as the
in the ith cell .Any discrete optimization problem (i.e., with a finite set of controls) can be solved using a complete enumeration of controls. The described algorithm efficiently iterates over the controls (rows) in decreasing order of the functional value until the validity predicate accepts the true value. We set as the  maximum number of iterations of the algorithm, i.e. the maximum number of rows with the maximum estimate on which the predicate will be calculated.First, we sort the alternatives in descending order of estimates, and we further assume that for any cell the inequality
maximum number of iterations of the algorithm, i.e. the maximum number of rows with the maximum estimate on which the predicate will be calculated.First, we sort the alternatives in descending order of estimates, and we further assume that for any cell the inequality  for is true
for is true  . The position will be the sequence of indices
. The position will be the sequence of indices  corresponding to the row
corresponding to the row . Position evaluation, i.e. functional value in that position, consider the product alternatives assessments corresponding to the indices included in position:
. Position evaluation, i.e. functional value in that position, consider the product alternatives assessments corresponding to the indices included in position:  . To store positions, you need the PositionBase data structure , which allows you to add new positions (with getting their addresses), get the position at the address and check whether the specified position is added to the database.In the process of listing positions, we will select an unviewed position with a maximum rating, and then add to the queue for consideration of PositionQueue all positions that can be obtained from the current one by adding one to one of the indices included in the position. The queue for consideration PositionQueue will contain triples
. To store positions, you need the PositionBase data structure , which allows you to add new positions (with getting their addresses), get the position at the address and check whether the specified position is added to the database.In the process of listing positions, we will select an unviewed position with a maximum rating, and then add to the queue for consideration of PositionQueue all positions that can be obtained from the current one by adding one to one of the indices included in the position. The queue for consideration PositionQueue will contain triples  , where
, where - evaluation of the position not
- evaluation of the position not  reviewed , - address of the position viewed in PositionBase from which this position was obtained,
reviewed , - address of the position viewed in PositionBase from which this position was obtained,  - index of the position element with the address that was increased by one to obtain this position. Positioning a PositionQueue queue will require a data structure that allows you to add another triple , as well as retrieve a triple with maximum rating .At the first iteration of the algorithm, it is necessary to consider the position
- index of the position element with the address that was increased by one to obtain this position. Positioning a PositionQueue queue will require a data structure that allows you to add another triple , as well as retrieve a triple with maximum rating .At the first iteration of the algorithm, it is necessary to consider the position  with the maximum estimate. If the predicate takes the true value on the line corresponding to this position, then the algorithm ends. Otherwise, the position is added to PositionBase , and inPositionQueue adds all triples of the view
with the maximum estimate. If the predicate takes the true value on the line corresponding to this position, then the algorithm ends. Otherwise, the position is added to PositionBase , and inPositionQueue adds all triples of the view  , for all
, for all  , where
, where  is the address of the starting position in PositionBase . At each subsequent iteration of the algorithm, the triple with the maximum value of the estimate is extracted from the PositionQueue , the position in question is restored to the address of the initial position and index . If the position has already been added to the database of the considered PositionBase positions , then it is skipped and the next three with the maximum value of the estimate is extracted from the PositionQueue . Otherwise, the predicate value is checked on the line corresponding to the position . If the predicatetakes the true value on this line, then the algorithm ends. If the predicate does not accept the true value on this line, then the line is added to the PositionBase (with the address assigned
is the address of the starting position in PositionBase . At each subsequent iteration of the algorithm, the triple with the maximum value of the estimate is extracted from the PositionQueue , the position in question is restored to the address of the initial position and index . If the position has already been added to the database of the considered PositionBase positions , then it is skipped and the next three with the maximum value of the estimate is extracted from the PositionQueue . Otherwise, the predicate value is checked on the line corresponding to the position . If the predicatetakes the true value on this line, then the algorithm ends. If the predicate does not accept the true value on this line, then the line is added to the PositionBase (with the address assigned  ), all derived positions are added to the PositionQueue queue , and the next iteration proceeds.
), all derived positions are added to the PositionQueue queue , and the next iteration proceeds.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
Note that during the iterations the predicate will be checked no more than once, there will be no more additions to the PositionBase , and addition to the PositionQueue , extraction from the PositionQueue , as well as a search in the PositionBase will occur no more than  once. If the implementation PositionQueue used "bunch" of data structure, and for the organization PositionBase using the data structure "Bor", the complexity of the algorithm is
once. If the implementation PositionQueue used "bunch" of data structure, and for the organization PositionBase using the data structure "Bor", the complexity of the algorithm is  , where
, where  - trudoemost test predicate on the length of the line .Perhaps the most important drawback of the algorithm based on checking grammars is that it cannot process hypotheses of different lengths (which may arise due to segmentation errors : loss or occurrence of extra characters, gluing and cutting characters, etc.), whereas changes in hypotheses such as “deleting a character”, “adding a character”, or even “replacing a character with a pair” can be encoded in the error model of the WFST-based algorithm.However, the speed and ease of use (when working with a new type of field you just need to give the algorithm access to the value validation function) make the method based on checking grammars a very powerful tool in the arsenal of the developer of document recognition systems. We use this approach for a large number of various fields, such as various dates, bank card number (predicate - checking the Moon code ), fields of machine-readable document areas with checksums, and many others.
- trudoemost test predicate on the length of the line .Perhaps the most important drawback of the algorithm based on checking grammars is that it cannot process hypotheses of different lengths (which may arise due to segmentation errors : loss or occurrence of extra characters, gluing and cutting characters, etc.), whereas changes in hypotheses such as “deleting a character”, “adding a character”, or even “replacing a character with a pair” can be encoded in the error model of the WFST-based algorithm.However, the speed and ease of use (when working with a new type of field you just need to give the algorithm access to the value validation function) make the method based on checking grammars a very powerful tool in the arsenal of the developer of document recognition systems. We use this approach for a large number of various fields, such as various dates, bank card number (predicate - checking the Moon code ), fields of machine-readable document areas with checksums, and many others.
The publication was prepared on the basis of the article : A universal algorithm for post-processing recognition results based on validating grammars. K.B. Bulatov, D.P. Nikolaev, V.V. Postnikov. Proceedings of ISA RAS, Vol. 65, No. 4, 2015, pp. 68-73.