The translation of the article was prepared especially for students of the course “Databases” .
What you may not have known about sysbench random number generationSysbench is a popular performance testing tool. It was originally written by Peter Zaitsev in the early 2000s and became the de facto standard for testing and benchmarking. It is currently supported by Alexei Kopytov and is posted on Github at .However, I noticed that, despite its wide distribution, there are moments unfamiliar to many in sysbench. For example, the ability to easily modify MySQL tests using Lua or to configure the parameters of the built-in random number generator.What is this article about?
I wrote this article to show how easy it is to customize sysbench to your requirements. There are many ways to extend the functionality of sysbench and one of them is to configure the generation of random identifiers (IDs).By default, sysbench comes with five different options for generating random numbers. But very often (in fact, almost never), none of them is explicitly indicated, and even less often you can see the generation parameters (for options where they are available).If you have a question: “And why should I be interested in this? After all, the default values are quite suitable, ”then this post is designed to help you understand why this is not always the case.let's start
What are the ways to generate random numbers in sysbench? The following are currently implemented (you can easily see them through the --help option):- Special (special distribution)
- Gaussian (Gaussian distribution)
- Pareto (Pareto distribution)
- Zipfian (Zipf distribution)
- Uniform (uniform distribution)
By default, Special is used with the following parameters:rand-spec-iter = 12 - number of iterations for a special distributionrand-spec-pct = 1 - percentage of the entire range into which “special” values fall with a special distributionrand-spec-res = 75 - percentage of “special” values for use in a special distribution
Since I like simple and easy-to-reproduce tests and scripts, all subsequent data will be collected using the following sysbench commands:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100 prepare
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
Feel free to experiment yourself. The script description and data can be found here .Why does sysbench use a random number generator? One of the purposes is to generate IDs that will be used in queries. So, in our example, numbers between 1 and 100 will be generated, taking into account the creation of 10 tables with 100 rows in each.What if you run sysbench as described above and change only -rand-type?I ran this script and used general log to collect and analyze the frequency of the generated ID values. Here is the result:Special Uniform
Uniform Zipfian
Zipfian Pareto
Pareto Gaussian
Gaussian It can be seen that this parameter matters, right? After all, sysbench does exactly what we expected from it.Let's take a closer look at each of the distributions.
It can be seen that this parameter matters, right? After all, sysbench does exactly what we expected from it.Let's take a closer look at each of the distributions.Special
Special is used by default, so if you do NOT specify rand-type, then sysbench will use special. Special uses a very limited number of ID values. In our example, we can see that the values 50-51 are mainly used, the remaining values between 44-56 are extremely rare, while others are practically not used. Please note that the selected values are in the middle of the available range of 1-100.In this case, the peak is about two IDs representing 2% of the sample. If I increase the number of records to one million, the peak will remain, but it will be at 7493, which is 0.74% of the sample. Since this will be more restrictive, the number of pages is likely to be more than one.Uniform (uniform distribution)
As the name says, if we use Uniform, then all values will be used for the ID, and the distribution will be ... uniform.Zipfian (Zipf distribution)
The Zipf distribution, sometimes called the zeta distribution, is a discrete distribution commonly used in linguistics, insurance, and rare event modeling. In this case, sysbench will use numbers starting with the smallest (1) and very quickly reduce the frequency of use, moving to larger numbers.Pareto (Pareto)
Pareto applies the “80-20” rule . In this case, the generated IDs will be smeared even less and will be more concentrated in a small segment. In our example, 52% of all IDs had a value of 1, and 73% of the values were in the first 10 numbers.Gaussian (Gaussian distribution)
The Gaussian distribution (normal distribution) is well known and familiar . It is used mainly in statistics and forecasting around a central factor. In this case, the IDs used are distributed along the bell-shaped curve, starting with the average value, and slowly decreasing to the edges.What's the point of this?
Each of the above options has its own use and can be grouped by purpose. Pareto and Special focus on hot spots. In this case, the application uses the same page / data again and again. This may be what we need, but we must understand what we are doing and not make mistakes here.For example, if we test the performance of InnoDB page compression while reading, we should avoid using the default value of Special or Pareto. If we have a 1 TB data set and a 30 GB buffer pool, and we request the same page many times, then this page will already be read from disk and will be available uncompressed in memory.In short, such a test is a waste of time and effort.The same thing if we need to check the performance of the recording. Writing the same page over and over is not the best option.How about performance testing?Again, we want to test performance, but for what case? It is important to understand that the method of generating random numbers greatly affects the test results. And your “good enough defaults” can lead to erroneous conclusions.The following graphs show different latencies depending on the rand-type (test type, time, additional parameters and the number of threads are the same everywhere).From type to type, the delays are significantly different: Here I was reading and writing, and the data was taken from Performance Schema (
Here I was reading and writing, and the data was taken from Performance Schema (sys.schema_table_statistics) As expected, Pareto and Special take much longer than others, causing the system (MySQL-InnoDB) to artificially suffer from competition in one “hot spot”.Changing the rand-type affects not only the delay, but also the number of rows processed, as indicated by the performance schema.
 Given all of the above, it is important to understand what we are trying to evaluate and test.If my goal is to test system performance at all levels, I might prefer to use Uniform, which will equally load the data set / database server / system and more likely to distribute read / load / write evenly.If my job is to work with hot spots, then Pareto and Special are probably the right choice.But do not use the default values blindly. They may suit you, but often they are intended for extreme cases. In my experience, you can often adjust the settings to get the result you need.For example, you want to use the values in the middle by widening the interval so that there is no sharp peak (Special by default) or bell (Gaussian).You can configure Special to get something like this:
Given all of the above, it is important to understand what we are trying to evaluate and test.If my goal is to test system performance at all levels, I might prefer to use Uniform, which will equally load the data set / database server / system and more likely to distribute read / load / write evenly.If my job is to work with hot spots, then Pareto and Special are probably the right choice.But do not use the default values blindly. They may suit you, but often they are intended for extreme cases. In my experience, you can often adjust the settings to get the result you need.For example, you want to use the values in the middle by widening the interval so that there is no sharp peak (Special by default) or bell (Gaussian).You can configure Special to get something like this: In this case, the IDs are still nearby, and there is competition. But the influence of one “hot spot” is less, therefore possible conflicts will now be with several IDs, which, depending on the number of records on a page, can be on several pages.Another example is partitioning. For example, how to check how your system works with partitions, focusing on the latest data, archiving the old ones?Easy! Remember the Pareto distribution chart? You can change it according to your needs.
In this case, the IDs are still nearby, and there is competition. But the influence of one “hot spot” is less, therefore possible conflicts will now be with several IDs, which, depending on the number of records on a page, can be on several pages.Another example is partitioning. For example, how to check how your system works with partitions, focusing on the latest data, archiving the old ones?Easy! Remember the Pareto distribution chart? You can change it according to your needs. By specifying the -rand-pareto value, you can get exactly what you wanted by forcing sysbench to focus on large ID values.Zipfian can also be set up and, although you cannot get an inversion, as is the case with Pareto, you can easily switch from a peak on one value to a more even distribution. A good example is the following:
By specifying the -rand-pareto value, you can get exactly what you wanted by forcing sysbench to focus on large ID values.Zipfian can also be set up and, although you cannot get an inversion, as is the case with Pareto, you can easily switch from a peak on one value to a more even distribution. A good example is the following: The last thing to keep in mind, and it seems to me that these are obvious things, but it’s better to say than not to say that when changing the random number generation parameters, performance will change.Compare latency:
The last thing to keep in mind, and it seems to me that these are obvious things, but it’s better to say than not to say that when changing the random number generation parameters, performance will change.Compare latency: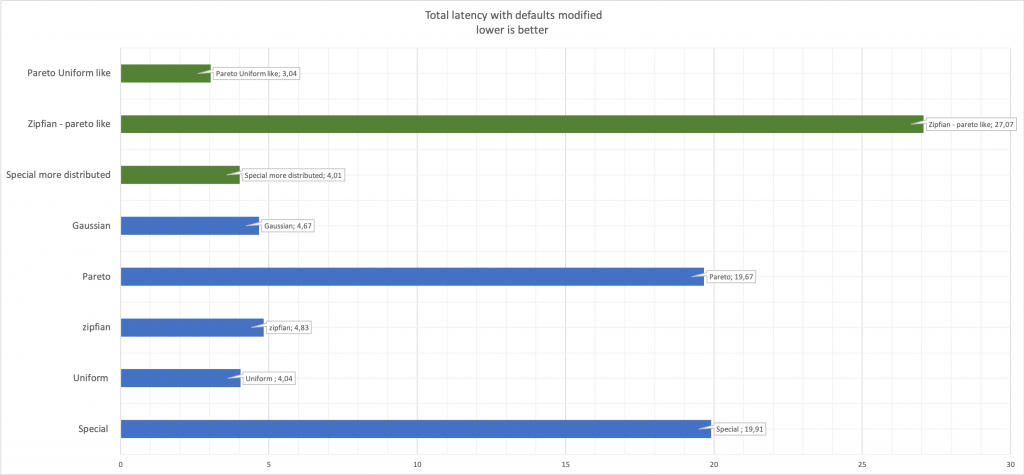 Here, green shows the changed values compared to the original blue.
Here, green shows the changed values compared to the original blue.
findings
At this point, you should already understand how easy it is to set up random number generation in sysbench, and how useful this can be for you. Keep in mind that the above applies to any calls, for example, when using sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Given this, do not mindlessly copy the code from other people's articles, but think and delve into what you need and how to achieve this.Before running the tests, check the random number generation options to make sure they are appropriate and appropriate for your needs. To simplify my life, I use this simple test . This test displays pretty clear ID distribution information.My advice is that you should understand your needs and conduct testing / benchmarking correctly.References
First of all, this is sysbench itself .Articles on Zipfian:Pareto:Percona's article on how to write your scripts in sysbenchAll the materials used for this article are on GitHub .
→ Learn more about the course