Over the 10 years of ivi's existence, we have compiled a database of 90,000 videos of various lengths, sizes and quality. Hundreds of new ones appear every week. We have gigabytes of metadata, which are useful for recommendations, simplify the navigation of the service and setting up advertising. But we began to extract information directly from the video only two years ago.In this article I will tell you how we parse films into structural elements and why we need it. At the end, there is a link to the Github repository with algorithm code and examples.
What does a video consist of?
The video clip has a hierarchical structure. It's about digital video, so at the lowest level are pixels , colored dots that make up a still picture.Still pictures are called frames - they replace each other and create the effect of movement. At the installation, the frames are cut into groups, which, as directed by the director, are interchanged and glued back. The sequence of frames from one assembly gluing to another in English is called the term shot. Unfortunately, the Russian terminology is unsuccessful, because in it such groups are also called frames. In order not to get confused, let's use the English term. Just enter the Russian-language version: "shot" .Shots are grouped by meaning, they are called scenes.The scene is characterized by the unity of place, time and characters.We can easily get individual frames and even pixels of these frames, because the digital video encoding algorithms are so arranged. This information is required for reproduction.Borders of shots and scenes are much more difficult to obtain. Sources from installation programs may help, but they are not available to us.Fortunately, algorithms can do this, albeit not perfectly accurately. I’ll tell you about the algorithm for dividing into scenes.
At the installation, the frames are cut into groups, which, as directed by the director, are interchanged and glued back. The sequence of frames from one assembly gluing to another in English is called the term shot. Unfortunately, the Russian terminology is unsuccessful, because in it such groups are also called frames. In order not to get confused, let's use the English term. Just enter the Russian-language version: "shot" .Shots are grouped by meaning, they are called scenes.The scene is characterized by the unity of place, time and characters.We can easily get individual frames and even pixels of these frames, because the digital video encoding algorithms are so arranged. This information is required for reproduction.Borders of shots and scenes are much more difficult to obtain. Sources from installation programs may help, but they are not available to us.Fortunately, algorithms can do this, albeit not perfectly accurately. I’ll tell you about the algorithm for dividing into scenes.Why do we need this?
We solve the search problem inside the video and want to automatically test every scene of every movie on ivi. Dividing into scenes is an important part of this pipeline.To know where the scenes begin and end, you need to create synthetic trailers. We already have an algorithm that generates them, but so far, scene detection is not used there.The recommender system is also useful for dividing into scenes. From them, signs are obtained that describe which films users like in structure.What are the approaches to solving the problem?
The problem is solved from two sides:- They take the whole video and look for the boundaries of the scenes.
- First, they divide the video into shots, and then combine them into scenes.
We went the second way, because it is easier to formalize, and there are scientific articles on this topic. We already know how to split video into shots. It remains to collect these shots into scenes.The first thing you want to try is clustering. Take the shots, turn them into vectors, and then divide the vectors into classical groups using classical clustering algorithms. The main drawback of this approach: it does not take into account that shots and scenes follow each other. A shot from another scene cannot stand between two shots of one scene, and with clustering this is possible.In 2016, Daniel Rothman and his IBM colleagues proposed an algorithm that takes into account the time structure and formulated combining shots into scenes as an Optimal Sequential Grouping task:
The main drawback of this approach: it does not take into account that shots and scenes follow each other. A shot from another scene cannot stand between two shots of one scene, and with clustering this is possible.In 2016, Daniel Rothman and his IBM colleagues proposed an algorithm that takes into account the time structure and formulated combining shots into scenes as an Optimal Sequential Grouping task:- given a sequence of shots
- need to divide it into segments so that this separation is optimal.
What is optimal separation?
For now, we assume that is given, that is, the number of scenes is known. Only their borders are unknown.Obviously, some kind of metric is needed. Three metrics were invented, they are based on the idea of pairwise distances between shots.Preparatory steps are as follows:- We turn shots into vectors (a histogram or outputs of the penultimate layer of a neural network)
- Find the pairwise distances between the vectors (Euclidean, cosine, or some other)
- We get a square matrix , where each element is the distance between shots and .
 This matrix is symmetrical, and on the main diagonal it will always have zeros, because the distance of the vector to itself is zero.Dark squares are traced along the diagonal - areas where neighboring shots are similar to each other, correspondingly less distance.If we choose good embeddings that reflect the semantics of shots and choose a good distance function, then these squares are the scenes. Find the borders of the squares - we will find the borders of the scenes.Looking at the matrix, Israeli colleagues formulated three criteria for optimal partitioning:
This matrix is symmetrical, and on the main diagonal it will always have zeros, because the distance of the vector to itself is zero.Dark squares are traced along the diagonal - areas where neighboring shots are similar to each other, correspondingly less distance.If we choose good embeddings that reflect the semantics of shots and choose a good distance function, then these squares are the scenes. Find the borders of the squares - we will find the borders of the scenes.Looking at the matrix, Israeli colleagues formulated three criteria for optimal partitioning:
is the scene border vector.Which of the criteria for optimal partitioning to choose?
A good loss function for an Optimal Sequential Grouping task has two properties:- If the film consists of one scene, then wherever we try to divide it into two parts, the value of the function will always be the same.
- If properly divided into scenes, the value will be less than if not correctly.
It turns out and do not cope with these requirements, and coping. To illustrate this, we will conduct two experiments.In the first experiment, we will make a synthetic matrix of pairwise distances, filling it with uniform noise. If we try to divide into two scenes, we get the following picture: says that in the middle of the video there is a change of scenes, which is actually not true. At abnormal jumps if you put the partition at the beginning or at the end of the video. Only behaves as required.In the second experiment, we will make the same matrix with uniform noise, but subtract two squares from it, as if we had two scenes that are slightly different from each other.
says that in the middle of the video there is a change of scenes, which is actually not true. At abnormal jumps if you put the partition at the beginning or at the end of the video. Only behaves as required.In the second experiment, we will make the same matrix with uniform noise, but subtract two squares from it, as if we had two scenes that are slightly different from each other.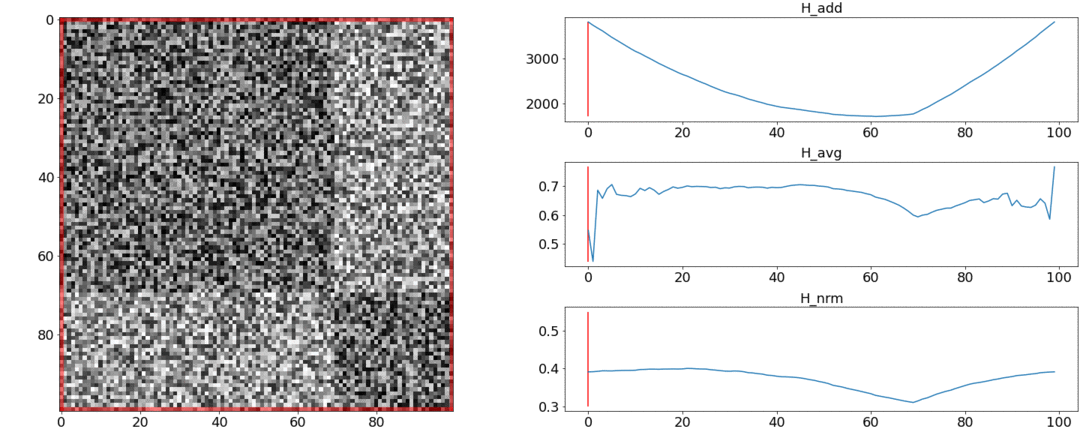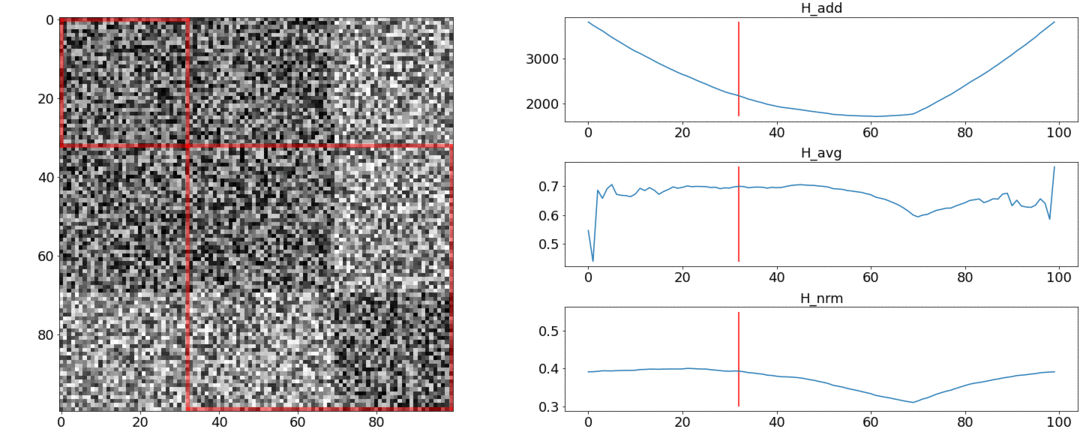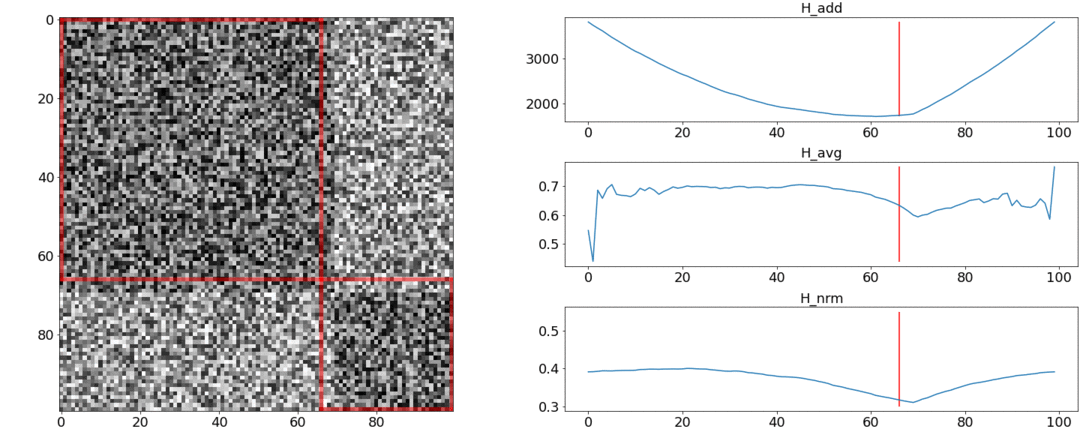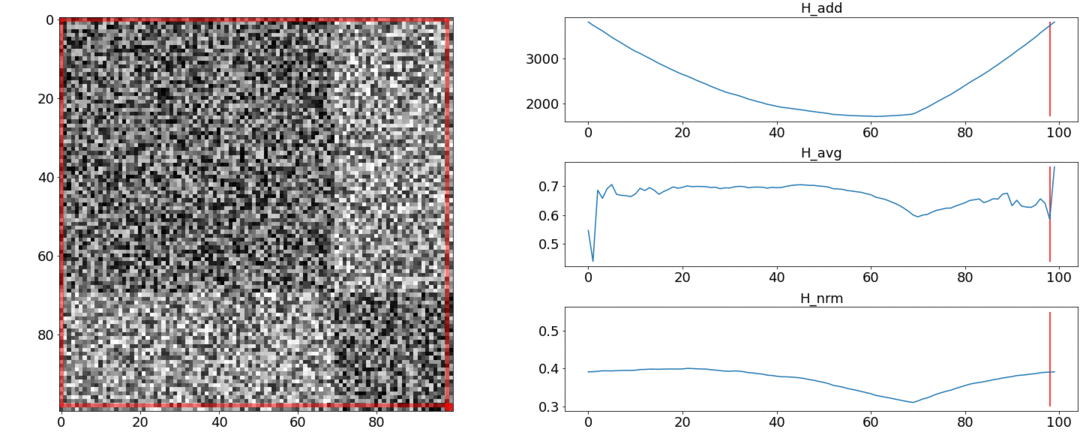 To detect this gluing, the function must take a minimum value when . But a minimum is still closer to the middle of the segment, while- to the beginning. At a clear minimum is visible at .Tests also show that the most accurate split is achieved using. It seems that you need to take it, and everything will be fine. But let's first look at the complexity of the optimization algorithm.Daniel Rothman and his group suggested looking for optimal partitioning using dynamic programming . The task is divided into subtasks in a recursive manner and solved in turn. This method gives a global optimum, but to find it, you need to iterate over eachall combinations of partitions from the 0th to the Nth shots and choose the best. Here - the number of scenes, and - the number of shots.No tweaks and accelerations optimization will work in time . ATThere is one more parameter for enumeration - the area of the partition, and at each step it is necessary to check all its values. Accordingly, the time increases to.We managed to make some improvement and speed up the optimization using the Memorization technique - caching the recursion results in memory so as not to read the same thing many times over. But, as the tests below show, a strong increase in speed was not achieved.
To detect this gluing, the function must take a minimum value when . But a minimum is still closer to the middle of the segment, while- to the beginning. At a clear minimum is visible at .Tests also show that the most accurate split is achieved using. It seems that you need to take it, and everything will be fine. But let's first look at the complexity of the optimization algorithm.Daniel Rothman and his group suggested looking for optimal partitioning using dynamic programming . The task is divided into subtasks in a recursive manner and solved in turn. This method gives a global optimum, but to find it, you need to iterate over eachall combinations of partitions from the 0th to the Nth shots and choose the best. Here - the number of scenes, and - the number of shots.No tweaks and accelerations optimization will work in time . ATThere is one more parameter for enumeration - the area of the partition, and at each step it is necessary to check all its values. Accordingly, the time increases to.We managed to make some improvement and speed up the optimization using the Memorization technique - caching the recursion results in memory so as not to read the same thing many times over. But, as the tests below show, a strong increase in speed was not achieved.How to estimate the number of scenes?
A group from IBM suggested that since many rows of the matrix are linearly dependent, the number of square clusters along the diagonal will be approximately equal to the rank of the matrix.To obtain it and at the same time filter out noise, you need a singular decomposition of the matrix.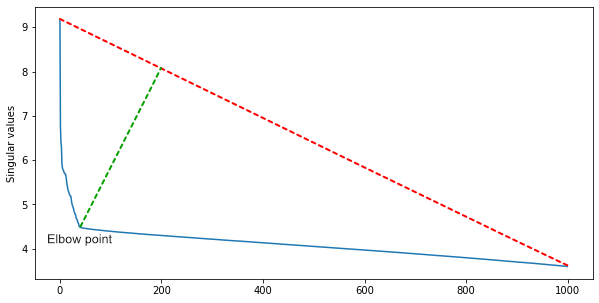 Among the singular values, sorted in descending order, we find the elbow point - the one from which the decrease in values decelerates sharply. The elbow point index is the approximate number of scenes in a movie.For a first approximation, this is enough, but you can supplement the algorithm with heuristics for different genres of cinema. In action films, there are more scenes, and in an arthouse - less.
Among the singular values, sorted in descending order, we find the elbow point - the one from which the decrease in values decelerates sharply. The elbow point index is the approximate number of scenes in a movie.For a first approximation, this is enough, but you can supplement the algorithm with heuristics for different genres of cinema. In action films, there are more scenes, and in an arthouse - less.Tests
We wanted to understand two things:- Is the speed difference so dramatic?
- How much accuracy does it suffer when using a faster algorithm?
Tests were divided into two groups: synthetic and real data. On synthetic tests, the quality and speed of both algorithms were compared, and on real ones, they measured the quality of the fastest algorithm. Speed tests were performed on the MacBook Pro 2017, 2.3 GHz Intel Core i5, 16 GB 2133 MHz LPDDR3.Synthetic quality tests
We generated 999 matrices of pairwise distances ranging in size from 12 to 122 shots, randomly divided them into 2-10 scenes and added normal noise from above.For each matrix, the optimal partitions were found in terms of and , and then counted Precision, Recall, F1, and IoU metrics.We consider Precision and Recall for the interval using the following formulas:
We consider F1 as usual, substituting interval Precision and Recall:
To compare the predicted and true segments within the film, for each predicted, we find the true segment with the largest intersection and consider the metric for this pair.Here are the results: Function optimization won in all metrics, as in the tests of the authors of the algorithm.
Function optimization won in all metrics, as in the tests of the authors of the algorithm.Synthetic speed tests
To test the speed, we conducted other synthetic tests. The first one is how the running time of the algorithm depends on the number of shotswith a fixed number of scenes: The test confirmed a theoretical assessment: optimization time grows polynomially with growth compared to linear time at .If you fix the number of shots and gradually increase the number of scenes , we get a more interesting picture. At first, time is expected to grow, but then it starts to plummet. The fact is that the number of possible denominator values (formula) that we need to check in proportion to the number of ways that we can break segments on . It is calculated using the combination of by :
The test confirmed a theoretical assessment: optimization time grows polynomially with growth compared to linear time at .If you fix the number of shots and gradually increase the number of scenes , we get a more interesting picture. At first, time is expected to grow, but then it starts to plummet. The fact is that the number of possible denominator values (formula) that we need to check in proportion to the number of ways that we can break segments on . It is calculated using the combination of by :
With growth the number of combinations first grows, and then falls as you approach . This seems to be cool, but the number of scenes will rarely be equal to the number of shots, and will always take on such a value that there are many combinations. In the already mentioned "Avengers" 2700 shots and 105 scenes. Number of Combinations:
This seems to be cool, but the number of scenes will rarely be equal to the number of shots, and will always take on such a value that there are many combinations. In the already mentioned "Avengers" 2700 shots and 105 scenes. Number of Combinations:
To be sure that everything was understood correctly and not entangled in the notation of the original articles, we wrote a letter to Daniel Rothman. He confirmed that really slow to optimize and not suitable for videos longer than 10 minutes, and in practice gives acceptable results.Real data tests
So, we have chosen a metric , which, although a little less accurate, works much faster. Now we need metrics, from which we will build on the search for a better algorithm.For the test we marked out 20 films of different genres and years. The markup was done in five stages:- Prepared materials for cutting:
- rendered frame numbers on the video
- printed storyboards with frame numbers so that you can immediately capture dozens of frames and see the borders of mounting glues.
- Using the prepared materials, the marker wrote down the frame numbers in the text file that correspond to the borders of the shots.
- Then he divided the shots into scenes. The criteria for combining shots into scenes are described above in the section “What does the video consist of?”
- The finished markup file was checked by the developers of the CV team. The main task during verification is to verify the boundaries of the scenes, because the criteria can be interpreted subjectively.
- The markup verified by the person was driven out through a script that found typos and errors like “frame of the end of the shot is less than the beginning of the shot”.
This is how the scribbler and the inspector’s screen looks: And this is how the first 300 shots of the film “Avengers: Infinity War” are divided into scenes. On the left are the true scenes, and on the right are the ones predicted by the algorithm:
And this is how the first 300 shots of the film “Avengers: Infinity War” are divided into scenes. On the left are the true scenes, and on the right are the ones predicted by the algorithm: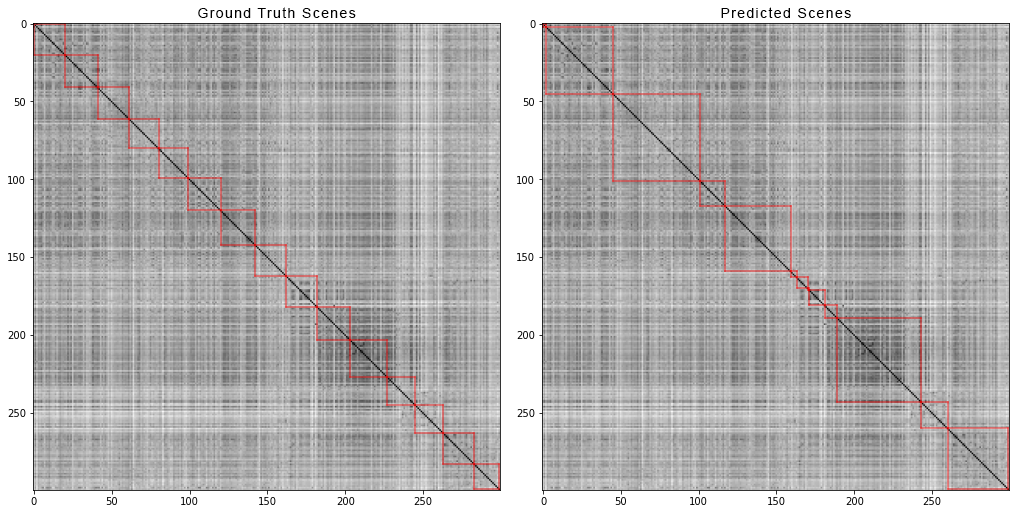 In order to obtain a matrix of pairwise distances, we did the following:For each video from the dataset, we generated matrices of pairwise distances and, just as for the synthetic data, we calculated four metrics. Here are the numbers that came out:
In order to obtain a matrix of pairwise distances, we did the following:For each video from the dataset, we generated matrices of pairwise distances and, just as for the synthetic data, we calculated four metrics. Here are the numbers that came out:- Precision : 0.4861919030708739
- Recall : 0.8225937459424839
- F1 : 0.513676858711775
- IoU : 0.37560909807842874
So what?
We got a base line that does not work perfectly, but now you can build on it while we are looking for more accurate methods.Some of the further plans:- Try other CNN architectures for feature extraction.
- Try other distance metrics between shots.
- Try other optimization methods , for example, genetic algorithms.
- Try to reduce the breakdown of the whole film into separate parts on which fulfills in a reasonable time, and compare what will be the loss in quality.
The code of both methods and experiments on synthetic data were published on Github . You can touch and try to speed up yourself. Likes and pull requests are welcome.Bye everyone, see you in the next articles!