Prelude
This is the first of four articles in the series that will provide insight into the mechanics and design of pointers, stacks, heaps, escape analysis, and Go / pointer semantics. This post is about stacks and pointers.Table of Contents:- Language Mechanics On Stacks And Pointers
- Language Mechanics On Escape Analysis ( translation )
- Language Mechanics On Memory Profiling
- Design Philosophy On Data And Semantics
Introduction
I will not dissemble - pointers are difficult to understand. If used improperly, pointers can cause unpleasant errors and even performance problems. This is especially true when writing competitive or multithreaded programs. Not surprisingly, many languages try to hide pointers from programmers. However, if you write in Go, you cannot escape pointers. Without a clear understanding of pointers, it will be difficult for you to write clean, simple, and efficient code.Frame borders
Functions are performed within the boundaries of frames that provide a separate memory space for each corresponding function. Each frame allows the function to work in its own context, and also provides flow control. A function has direct access to memory inside its frame via a pointer, but access to memory outside the frame requires indirect access. For a function to access memory outside its frame, this memory must be used in conjunction with this function. The mechanics and limitations set by these boundaries must be understood and studied first.When a function is called, a transition between two frames occurs. The code goes from the frame of the calling function to the frame of the called function. If the data is needed to call the function, then this data must be transferred from one frame to another. The transfer of data between two frames in Go is done "by value."The advantage of “by value” data transmission is readability. The value that you see in the function call is what is copied and accepted on the other side. That's why I associate “pass by value” with WYSIWYG, because what you see is what you get. All this allows you to write code that does not hide the cost of switching between two functions. This helps maintain a good mental model of how each function call will affect the program during the transition.Look at this little program that calls a function by passing integer data "by value":Listing 1:01 package main
02
03 func main() {
04
05
06 count := 10
07
08
09 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
10
11
12 increment(count)
13
14 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
15 }
16
17
18 func increment(inc int) {
19
20
21 inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
23 }
When your Go program starts, the runtime creates the main goroutine to start executing all the code, including the code inside the main function. Gorutin is the execution path that fits into the thread of the operating system, which ultimately runs on some kernel. Starting with version 1.8, each goroutine is provided with an initial block of continuous memory of 2048 bytes in size, which forms the stack space. This initial stack size has changed over the years and may change in the future.The stack is important because it provides physical memory space for the frame boundaries that are given to each individual function. By the time the main goroutine performs the main function in Listing 1, the program stack (at a very high level) will look like this:Figure 1: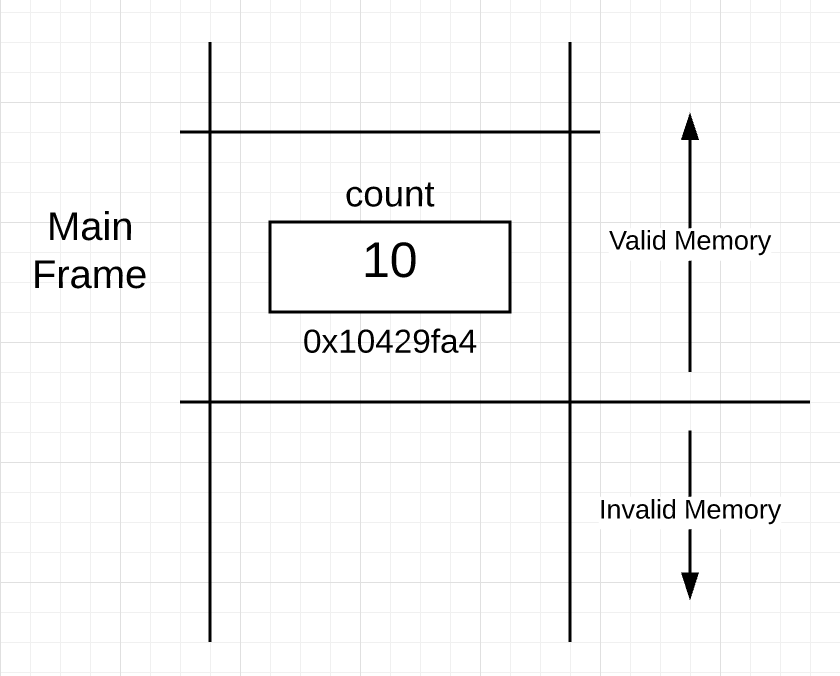 In Figure 1, you can see that part of the stack was “framed” for the main function. This section is called the " stack frame ", and it is this frame that denotes the boundary of the main function on the stack. The frame is set as part of the code that executes when the function is called. You can also see that the memory for the count variable was allocated at 0x10429fa4 inside the frame for main.There is another interesting point, illustrated in Figure 1. All the stack memory under the active frame is not valid, but the memory from the active frame and above is valid. You need to clearly understand the boundary between the valid and invalid part of the stack.
In Figure 1, you can see that part of the stack was “framed” for the main function. This section is called the " stack frame ", and it is this frame that denotes the boundary of the main function on the stack. The frame is set as part of the code that executes when the function is called. You can also see that the memory for the count variable was allocated at 0x10429fa4 inside the frame for main.There is another interesting point, illustrated in Figure 1. All the stack memory under the active frame is not valid, but the memory from the active frame and above is valid. You need to clearly understand the boundary between the valid and invalid part of the stack.Addresses
Variables are used to assign a name to a specific memory cell to improve the readability of the code and help you understand what data you are working with. If you have a variable, then you have a value in memory, and if you have a value in memory, then it must have an address. On line 09, the main function calls the built-in println function to display the "value" and "address" of the count variable.Listing 2:09 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
Using the ampersand “&” to get the address of a variable’s location is not new, other languages also use this operator. The output of line 09 should look like the output below if you are running code on a 32-bit architecture such as Go Playground:Listing 3:count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
Function Call
Next, on line 12, the main function calls the increment function.Listing 4:12 increment(count)
Making a function call means that the program must create a new section of memory on the stack. However, everything is a little more complicated. To successfully complete a function call, it is expected that data will be transferred across the frame boundary and placed in a new frame during the transition. In particular, an integer value is expected to be copied and transmitted during the call. You can see this requirement by looking at the declaration of the increment function on line 18.Listing 5:18 func increment(inc int) {
If you look again at the call to the increment function on line 12, you will see that the code passes the “value” of the variable count. This value will be copied, transferred, and placed in a new frame for the increment function. Remember that the increment function can only read and write to memory in its own frame, so it needs the inc variable to get, store and access its own copy of the transmitted counter value.Just before the code inside the increment function starts to execute, the program stack (at a very high level) will look like this:Figure 2: You can see that there are now two frames on the stack - one for main and one below for increment. Inside the frame for increment, you can see the inc variable containing the value 10, which was copied and passed during the function call. The inc variable address is 0x10429f98, and it is smaller in memory because the frames are pushed onto the stack, which are just implementation details that mean nothing. The important thing is that the program retrieved the count value from the frame for main and placed a copy of this value in the frame to increase using the inc variable.The rest of the code inside increment increments and displays the "value" and "address" of the inc variable.Listing 6:
You can see that there are now two frames on the stack - one for main and one below for increment. Inside the frame for increment, you can see the inc variable containing the value 10, which was copied and passed during the function call. The inc variable address is 0x10429f98, and it is smaller in memory because the frames are pushed onto the stack, which are just implementation details that mean nothing. The important thing is that the program retrieved the count value from the frame for main and placed a copy of this value in the frame to increase using the inc variable.The rest of the code inside increment increments and displays the "value" and "address" of the inc variable.Listing 6:21 inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
The output of line 22 in the playground should look something like this:Listing 7:inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
Here's what the stack looks like after executing the same lines of code:Figure 3: After executing lines 21 and 22, the increment function ends and returns control to the main function. Then the main function again displays the “value” and “address” of the local variable count on line 14.Listing 8:
After executing lines 21 and 22, the increment function ends and returns control to the main function. Then the main function again displays the “value” and “address” of the local variable count on line 14.Listing 8:14 println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
The full output of the program in the playground should look something like this:Listing 9:count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
The count value in the frame for main is the same before and after the call to increment.Return from functions
What actually happens to the memory on the stack when the function exits and control returns to the calling function? The short answer is nothing. Here's what the stack looks like after the increment function returns:Figure 4: The stack looks exactly the same as in Figure 3, except that the frame associated with the increment function is now considered invalid memory. This is because the frame for main is now active. The memory created for the increment function has remained untouched.Clearing the memory frame of the return function will be a waste of time, because it is not known whether this memory will ever be needed again. So the memory remained the way it was. During each function call, when a frame is taken, the stack memory for this frame is cleared. This is done by initializing any values that fit into the frame. Since all values are initialized as their "zero value", the stacks are correctly cleared with every function call.
The stack looks exactly the same as in Figure 3, except that the frame associated with the increment function is now considered invalid memory. This is because the frame for main is now active. The memory created for the increment function has remained untouched.Clearing the memory frame of the return function will be a waste of time, because it is not known whether this memory will ever be needed again. So the memory remained the way it was. During each function call, when a frame is taken, the stack memory for this frame is cleared. This is done by initializing any values that fit into the frame. Since all values are initialized as their "zero value", the stacks are correctly cleared with every function call.Value Sharing
What if it was important for the increment function to work directly with the count variable that exists inside the frame for main? This is where the time comes for pointers. Pointers serve one purpose - to share a value with a function so that the function can read and write this value, even if the value does not exist directly within its frame.If you don’t think you need to “share” the value, then you don’t need to use a pointer. When learning pointers, it’s important to think that using a clean dictionary, not operators or syntax. Remember that pointers are intended to be shared and when reading code replace the & operator with the phrase “sharing”.Types of Pointers
For each type that you declared, or that was declared directly by the language itself, you get a free pointer type that you can use for sharing. There is already a built-in type called int, so there is a pointer type named * int. If you declare a type named User, you get a pointer type named * User for free.All types of pointers have two identical characteristics. First, they start with the * character. Secondly, they all have the same size in memory and a representation occupying 4 or 8 bytes that represent the address. On 32-bit architectures (for example, in the playground) pointers require 4 bytes of memory, and on 64-bit architectures (for example, your computer) they require 8 bytes of memory.In the specification, pointer typesare considered type literals , which means they are nameless types made up of an existing type.Indirect memory access
Look at this little program that makes a function call, passing the address "by value". This will split the count variable from the stack frame of main with the increment function:Listing 10:01 package main
02
03 func main() {
04
05
06 count := 10
07
08
09 println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
10
11
12 increment(&count)
13
14 println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
15 }
16
17
18 func increment(inc *int) {
19
20
21 *inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
23 }
Three interesting changes were made to the original program. The first change is on line 12:Listing 11:12 increment(&count)
This time, on line 12, the code does not copy and passes the "value" to the count variable, but passes its "address" instead of the count variable. Now you can say: “I am sharing” the variable count with the function increment. This is what the & operator says - “share.”Understand that this is still “passing by value,” and the only difference is that the value you pass is the address, not the integer. Addresses are also values; this is what is copied and passed across the border of the frame to call the function.Since the address value is copied and passed, you need a variable inside the increment frame to get and save this integer address. An integer pointer variable declaration is on line 18.Listing 12:18 func increment(inc *int) {
If you passed the address of the value of type User, then the variable would have to be declared as * User. Despite the fact that all pointer variables store address values, they cannot be passed any address, only addresses associated with the type of pointer. The basic principle of sharing a value is that the receiving function must read or write to that value. You need information about the type of any value to read and write to it. The compiler will ensure that only values associated with the correct pointer type are used with this function.Here's what the stack looks like after calling the increment function:Figure 5: Figure 5 shows what the stack looks like when "pass by value" is performed using the address as the value. The pointer variable inside the frame for the increment function now points to the count variable, which is located inside the frame for main.Now, using the pointer variable, the function can perform an indirect read and change operation for the count variable located inside the frame for main.Listing 13:
Figure 5 shows what the stack looks like when "pass by value" is performed using the address as the value. The pointer variable inside the frame for the increment function now points to the count variable, which is located inside the frame for main.Now, using the pointer variable, the function can perform an indirect read and change operation for the count variable located inside the frame for main.Listing 13:21 *inc++
This time, the * character acts as an operator and is applied to the pointer variable. Using * as an operator means "the value that the pointer points to." A pointer variable provides indirect access to memory outside the frame of the function that uses it. Sometimes this indirect reading or writing is called pointer dereferencing. The increment function still needs to have a pointer variable in its frame, which it can directly read to perform indirect access.Figure 6 shows what the stack looks like after line 21.Figure 6: Here is the final output from this program:Listing 14:
Here is the final output from this program:Listing 14:count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ]
count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
You may notice that the “value” of the inc pointer variable matches the “address” of the count variable. This establishes a sharing relationship that allowed indirect access to memory outside the frame. As soon as the increment function writes through the pointer, the change is visible to the main function when control is returned to it.Pointer variables are not special
Pointer variables are not special because they are the same variables as any other variable. They have a memory allocation, and they contain meaning. It just so happened that all pointer variables, regardless of the type of value they can point to, always have the same size and presentation. What can be confusing is that the * character acts as an operator inside the code and is used to declare a pointer type. If you can distinguish a type declaration from a pointer operation, this can help eliminate some confusion.Conclusion
This post describes the purpose of pointers, the operation of the stack, and the mechanics of pointers in Go. This is the first step in understanding the mechanics, design principles, and usage techniques needed to write coherent and readable code.In the end, here is what you learned:- Functions are performed within the frame boundaries, which provide a separate memory space for each corresponding function.
- When a function is called, a transition between two frames occurs.
- The advantage of “by value” data transmission is readability.
- The stack is important because it provides physical memory space for the frame boundaries that are given to each individual function.
- All stack memory below the active frame is invalid, but memory from the active frame and above is valid.
- , .
- , , .
- — , , .
- , , , , .
- - , .
- - - , , . , .