Very often, for my 15 years of experience as a software developer and team leader, I come across the same thing. Programming turns into a religion - rarely anyone tries to introduce technology based on a reasonable choice, reasonably, taking into account restrictions, portability, assessing the degree of attachment to the vendor, the real price, the prospects of technology and freedom of license. Developers go to conferences or read posts - start hype, and their IT directors and managers are fed not only with tales of a bright agile future at events, various visionaries, sales and consultants. And it turns out that the technologies were in the project, not taking into account the convenience of development and implementation, non-functional requirements of the project, but because it is hype and google uses itself,amazon recommends (although their vacancies say that they themselves do not often use it) or the highest decision has been made by the company's management to implement "this."
What affects the choice of database
From my point of view, when choosing a database, I have to solve at least the following trade-offs:- real-time transaction processing or online analytic processing
- vertically or horizontally scalable
- in the case of a distributed base - data consistency / availability / separation resistance (CAP theorem)
- a specific data scheme and restrictions in the database or storage that does not require a data scheme
- data model - key-value, hierarchical, graph, document or relational
- processing logic as close to data as possible or all processing in the application
- work mainly in RAM or with a disk subsystem
- universal solution or specialized
- we use the existing expertise on a database that is not particularly suitable for the requirements of the project or we develop a new one in suitable but not familiar training, “blood and sweat” (the same applies not only to development, but also to operation)
- built-in or in another process / network
- hipster or retrograde
Often we get a “gift” to the implemented solution:- “Alien” query language
- the only native API for working with the database, which will complicate the transition to other databases (time, team effort and project budget were spent)
- unavailability of drivers for other platforms / languages / operating systems
- lack of source codes, descriptions of the data format on the disk (or a ban on reverse engineering licenses, especially Oracle with the buggy Coherence)
- license cost growth year by year
- own ecosystem and difficulty finding specialists
- , ,
The horizontal scaling of systems is quite complex and requires team expertise. Experienced developers are quite expensive in the market, distributed applications are more difficult to develop, debug and test. Therefore, if it is possible to change the server to a more powerful one and the amount of data the system allows, they often do so. Now servers can have terabytes of RAM and hundreds of processor cores on board. So, as never before, it becomes important to use all server resources as efficiently as possible. The cost of database licenses is also important, and if they are sold by processor cores, the operating budget, even with vertical scaling, can cost as much as a superpower space program. Therefore, it is important to keep this in mind so as not to be unable to scale the database performance due to licenses.It is clear that with the help of marketing they will try to convince you that only the solution of a certain company will solve all your problems (but they are silent about how many new ones will appear). There is no one ideal database that will suit everyone and is suitable for everything.So in the foreseeable future, we will still support several different databases for processing the same data for different types of queries in different systems. No solutions for Data Fabric without data caching, Data Lake can not yet be compared with databases with mass-parallel architecture in terms of performance and query optimality. Transactional data will still be stored in PostgreSQL, Oracle, MS Sql Server, analytical queries in Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata, and raw data swamps in HDFS / S3 / ADLS (Azure) will be managed by Dremio , Redshift Spectrum, Apache Spark, Presto.But the solutions listed above are poorly suited for analyzing time series data with a low response time. According to its popularity in working with time series data, it is now in the favorites of InfluxDB. In the in-memory database niche, kdb + and memSQL keep their places.QuestDB
What can oppose all of these open source QuestDB solutions with an Apache license?- An attempt to get the most out of the hardware for performing analytical queries - vectorization of aggregation functions, working with data through memory mapped files
- SQL as the language of DML queries and DDL operations for managing the database structure
- support for join tables specific to time series DB
- support for window and aggregation functions in SQL
- the ability to embed a database in an application on the JVM
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
When this database can be useful to you - if you are developing financial systems on the JVM with a low latency and you need a solution for data analytics in RAM. As a replacement for kdb + due to the cost of licenses. If you collect metrics according to the Influx / Telegraf protocol, but the performance and usability of working with InfluxDB is not satisfactory. If your project is running on the JVM and you need a built-in database to store metrics or application data that are only added and not updated.The new release 4.2.0 with support for SIMD instructions caused a wave of comments on Reddit . For fans to participate in the competition of knowledge of modern hardware and its effective programming, I recommend talking to the author of the database (bluestreak01) in the comments!SIMD operations
The project team conducted a test on synthetic data and compared QuestDB 4.2.0 with kdb 4.0 to aggregate a billion values, harnessing the SIMD instructions of the processors.On the Intel 8850H platform: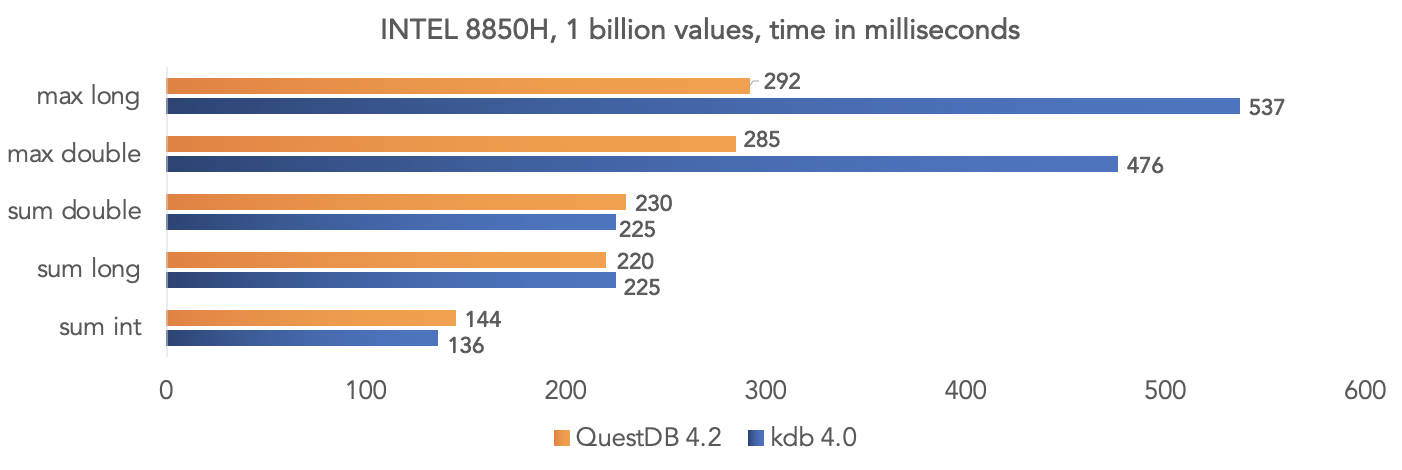 On the AMD Ryzen 3900X platform:
On the AMD Ryzen 3900X platform: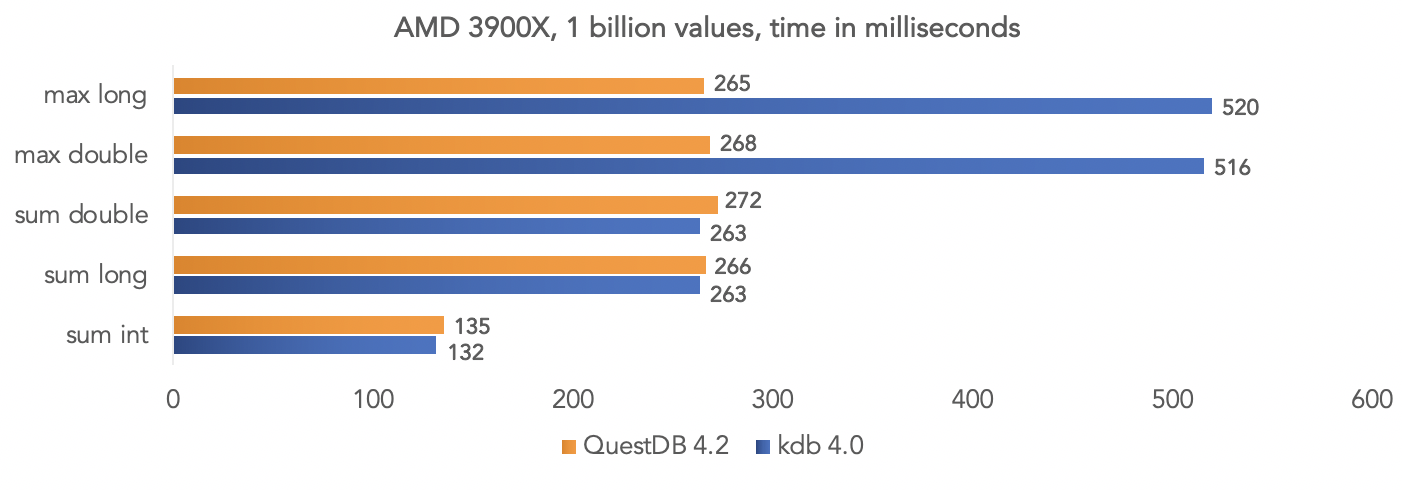 It’s clear that these are all tests in a “vacuum”, but you can compare on your data if your project uses kdb and share the results with the community.
It’s clear that these are all tests in a “vacuum”, but you can compare on your data if your project uses kdb and share the results with the community.Running docker database image
The database is published on dockerhub with every release. More details are described in the project documentation .Get the QuestDB image:docker pull questdb/questdb
We launch:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
After that, you can connect using the PostgreSQL protocol to port 8812, the web console is available on port 9000.Jdbc access
Depending on our project, we add the PostrgreSQL jdbc driver org.postgresql: postgresql: 42.2.12 , for this test I use my QuestDB module for testcontainers . The test is available on github along with the build script:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Running docker leads to additional overhead, and this can be avoided by simply implementing org.questdb: core: jar: 4.2.0 as a dependency on the project and running io.questdb.ServerMain:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Embedding in java application
But this is the fastest way to work with the database using the inprocess java API:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Web console
The project includes a web console for querying QuestDB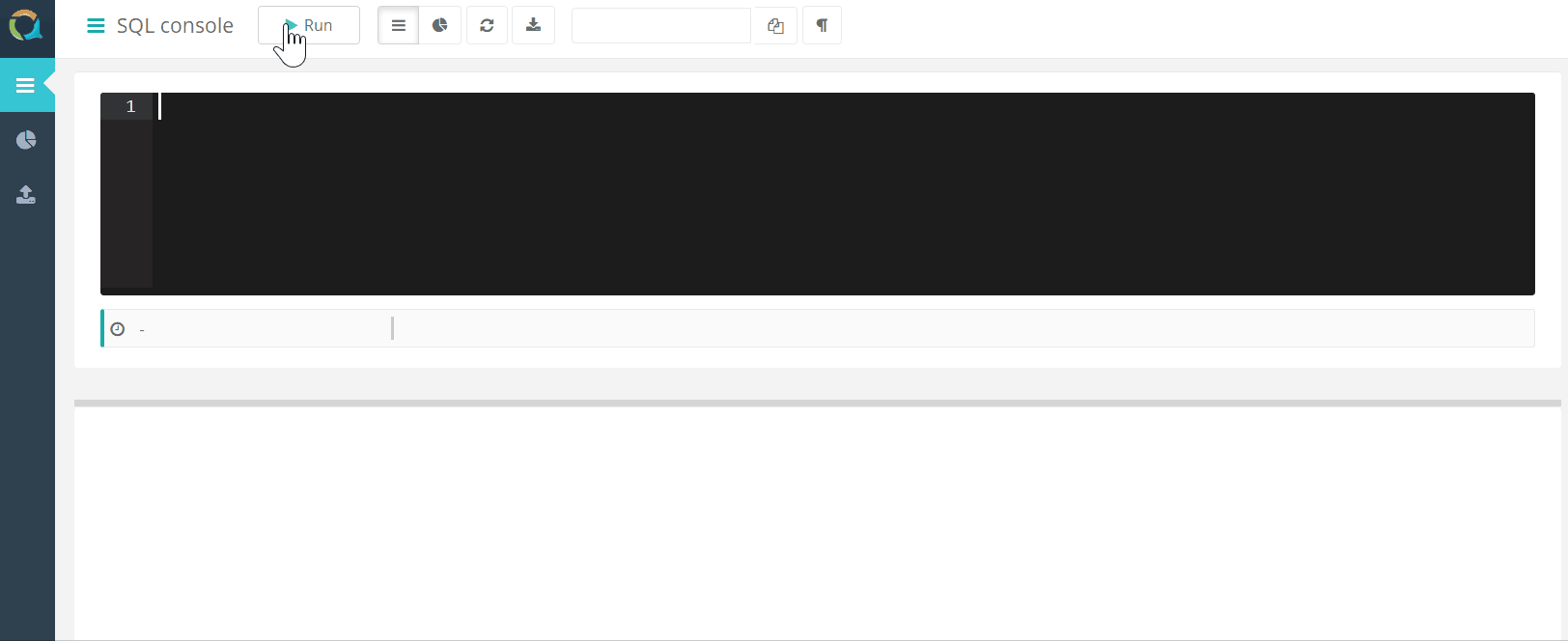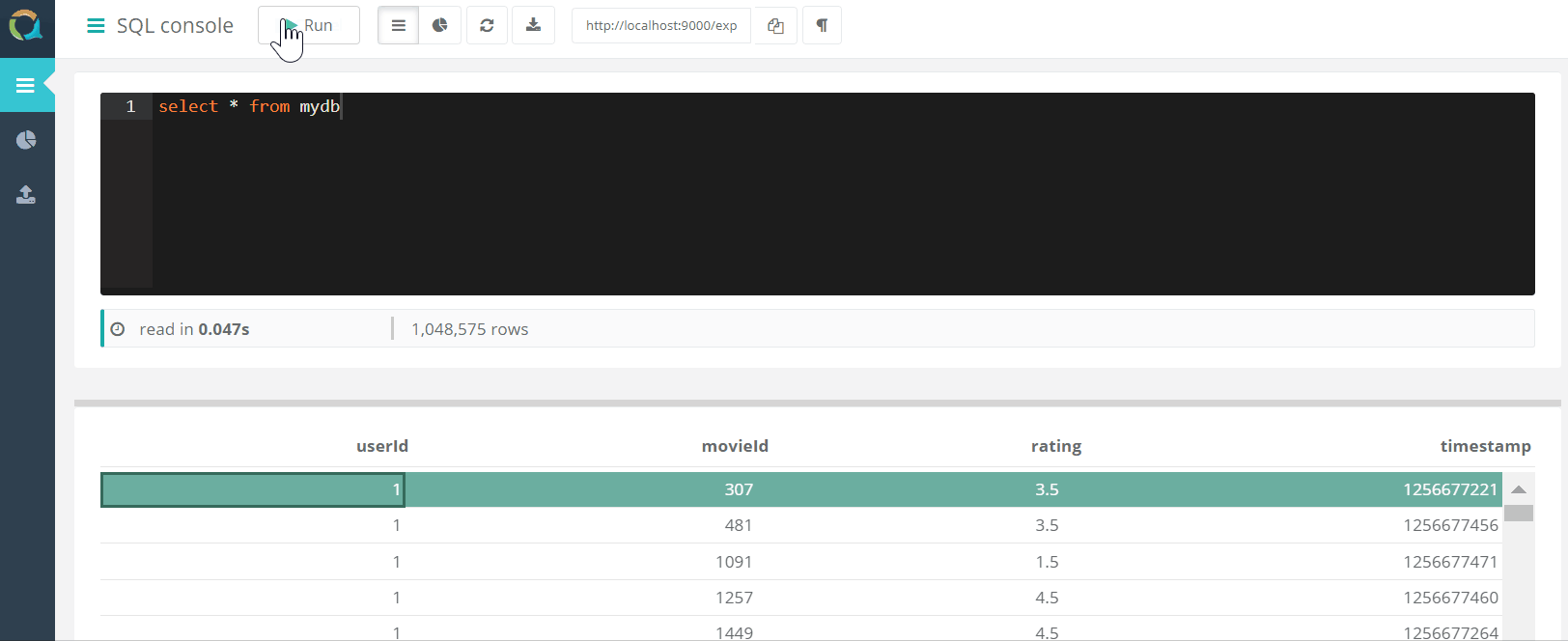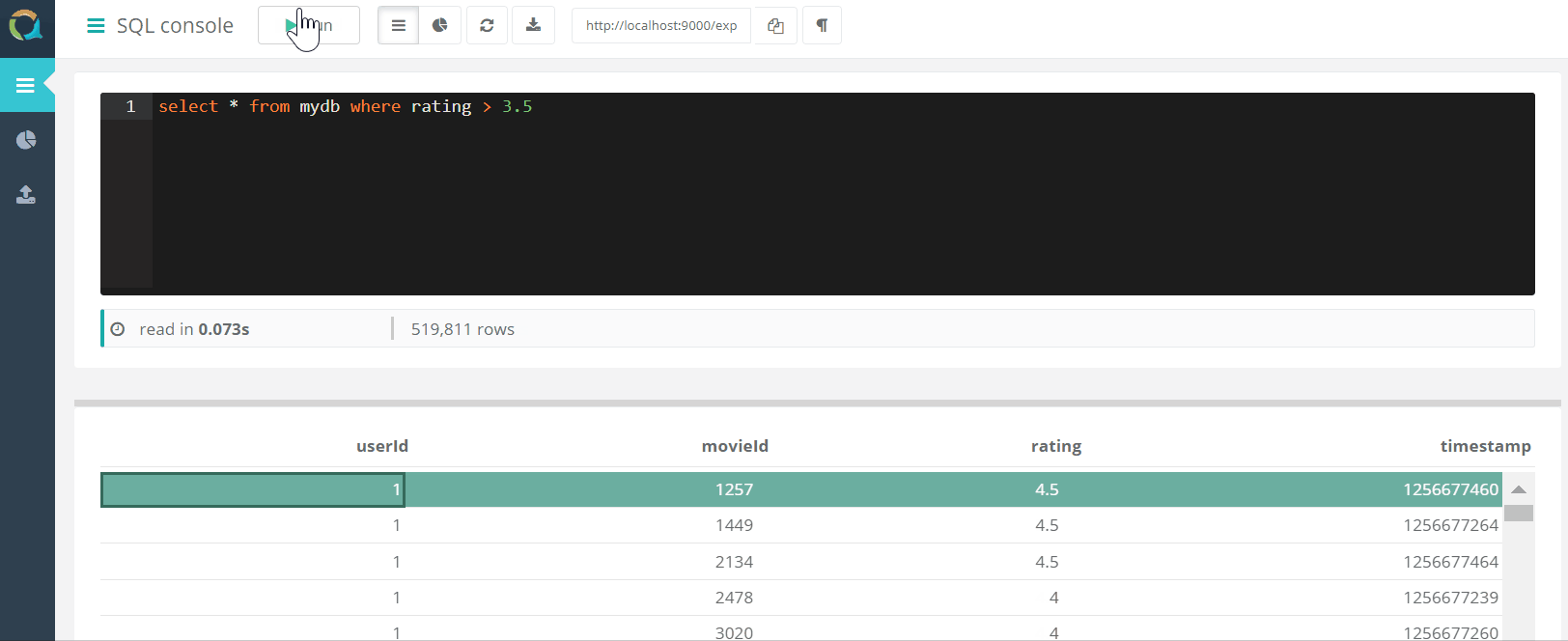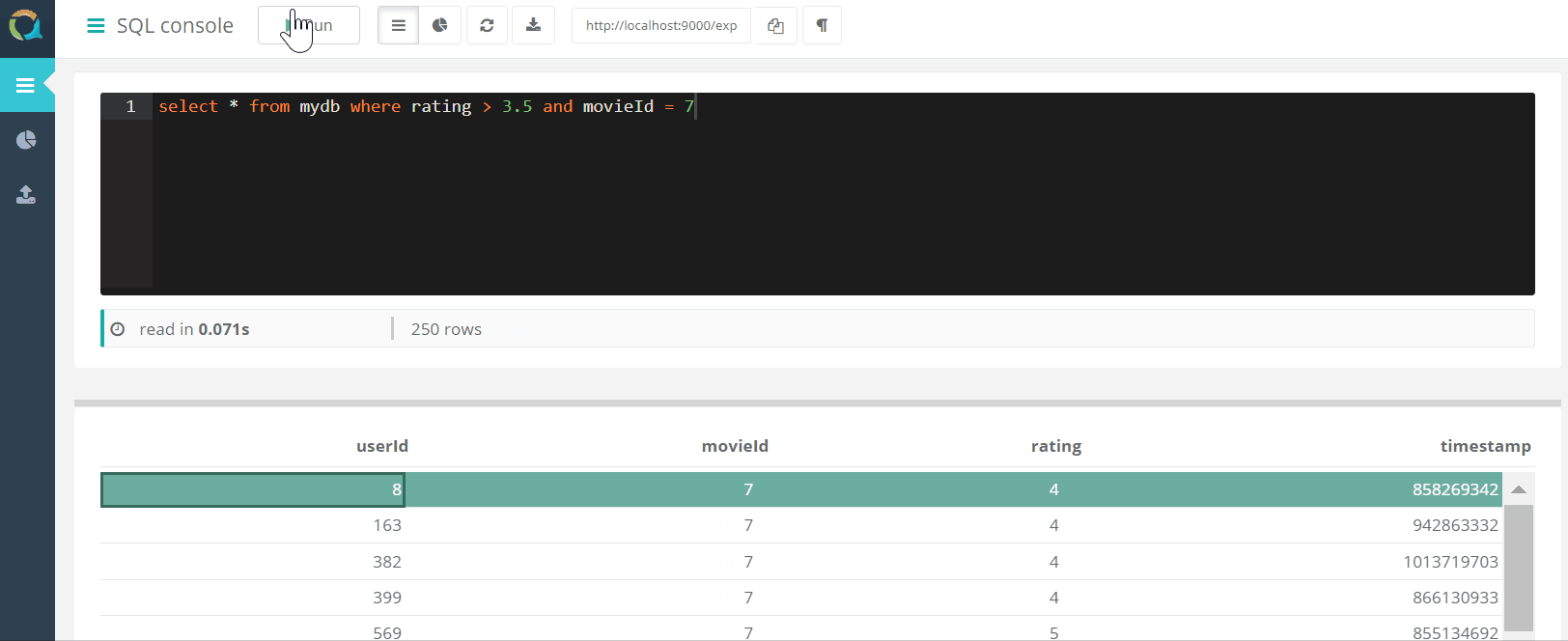 AND downloading data to a database in csv format through a browser.
AND downloading data to a database in csv format through a browser.
Do you need another database?
This project is young and still lacks some corporate features, but it is developing quite quickly and several contributors are actively working on the project. I ’ve been following QuestDB since last August and developed a couple of extensions for this project ( jdbc function and osquery ), and also integrated this project with testcontainers. Now I am trying to solve my current problems in Dremio with incremental data uploading, data partitioning and lengthy transactions to data sources in production using QuestDB, supplementing it with data export functions. I plan to share my experience in the following publications. It bribes me especially that I can debug my functions and database on the platform that I am familiar with, write unit tests that run at the speed of light.You decide as an experienced developer. Once again, QuestDB is not a replacement for OLTP databases - PostgreSQL, Oracle, MS Sql Server, DB2, or even an H2 replacement for testsin the JVM. This is a powerful specialized open-source database with support for PostgreSQL, Influx / Telegraf network protocols. If your usage scenario fits the features that are implemented in it and the main scenario of using a column database, then the choice is justified!