Once it became interesting what topics the LDA (latent placement of Dirichlet) would highlight on the materials of LiveJournal. As they say, there is interest - no problem.To begin with, a little about LDA on the fingers, we won’t go into mathematical details (anyone who is interested - reads). So, LDA is one of the most common algorithms for modeling topics. Each document (be it an article, a book, or any other source of textual data) is a mixture of topics, and each topic is a mixture of words.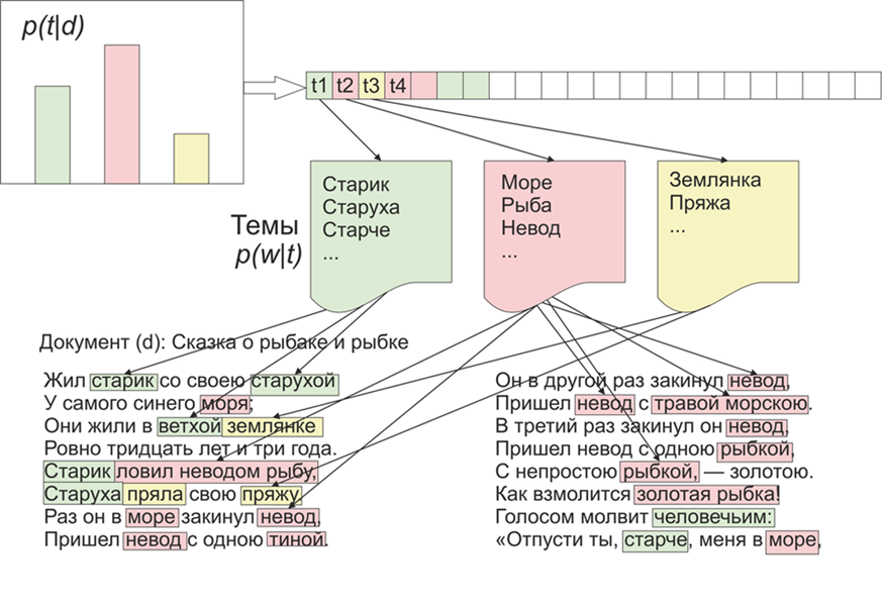 Image taken from WikipediaThus, the task of the LDA is to find groups of words that form topics from a collection of documents. Then, based on topics, you can cluster texts or simply highlight keywords.About 1800 articles were received from the LifeJournal website, all of them were converted to jsonl format. I will leave the uncleaned articles on Yandex disk . We’ll do some cleaning and normalization of the data: throw out the comments, delete the stop words (the list along with the source code is available on github), we will reduce all words to lowercase spelling, remove punctuation and words containing 3 letters or less. But one of the main pre-processing operations: deleting frequently occurring words, in principle, can be limited to deleting only stop words, but then frequently used words will be included in almost all topics with a high probability. In this case, it will be possible to post-process and delete such words. The choice is yours.
Image taken from WikipediaThus, the task of the LDA is to find groups of words that form topics from a collection of documents. Then, based on topics, you can cluster texts or simply highlight keywords.About 1800 articles were received from the LifeJournal website, all of them were converted to jsonl format. I will leave the uncleaned articles on Yandex disk . We’ll do some cleaning and normalization of the data: throw out the comments, delete the stop words (the list along with the source code is available on github), we will reduce all words to lowercase spelling, remove punctuation and words containing 3 letters or less. But one of the main pre-processing operations: deleting frequently occurring words, in principle, can be limited to deleting only stop words, but then frequently used words will be included in almost all topics with a high probability. In this case, it will be possible to post-process and delete such words. The choice is yours.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
Next, we bring all the words to normal form: for this we use the pymorphy2 library, which can be installed via pip.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
Yes, we will lose information about the form of words, but in this context, we are more interested in the compatibility of words with each other. This is where our preprocessing is finished, it is not complete, but it is sufficient to see how the LDA algorithm works.Further, the point mentioned above, in principle, can be omitted, but in my opinion, the results are more adequate, again, what threshold will be, you decide, for example, you can build a function that depends on the average length of documents and their number :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
Let's proceed directly to the training of the model, for this we need to install the gensim library, which contains a bunch of cool buns. First you need to encode all the words, the Dictionary function will do it for us, then we will replace the words with their numerical equivalents. The commented-out version of the LDA call is longer, since it is updated after each document, you can play with the settings and select the appropriate option.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
After the work of the program, the topics can be viewed using the commandlda.show_topic(i,topn=30)
, where i is the topic number, and topn is the number of words in the topic to be displayed.Now a small bonus for visualizing themes, for this you need to install the wordcloud library (like, similar utilities are also in matplotlib). This code visualizes themes and saves them in the current folder.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
And finally, a few examples of the topics that I got:
 Experiment and you can get even more meaningful results.
Experiment and you can get even more meaningful results.