 The picture that you see is taken from the DeepMind site and shows 57 games in which their latest development Agent57 ( review of the article on Habré ) has achieved success. The number 57 itself was not taken from the ceiling - exactly so many games were chosen back in 2012 to become a kind of benchmark among the developers of AI for Atari games, after which various researchers measure their achievements on this particular dataset.In this post, I will try to look at these achievements from different angles in order to assess their value for applied tasks, and justify why I do not believe that this is the future. Well and yes, there will be many pictures under the cut, I warned.In the link above, developers write the right things, saying that
The picture that you see is taken from the DeepMind site and shows 57 games in which their latest development Agent57 ( review of the article on Habré ) has achieved success. The number 57 itself was not taken from the ceiling - exactly so many games were chosen back in 2012 to become a kind of benchmark among the developers of AI for Atari games, after which various researchers measure their achievements on this particular dataset.In this post, I will try to look at these achievements from different angles in order to assess their value for applied tasks, and justify why I do not believe that this is the future. Well and yes, there will be many pictures under the cut, I warned.In the link above, developers write the right things, saying thatSo although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
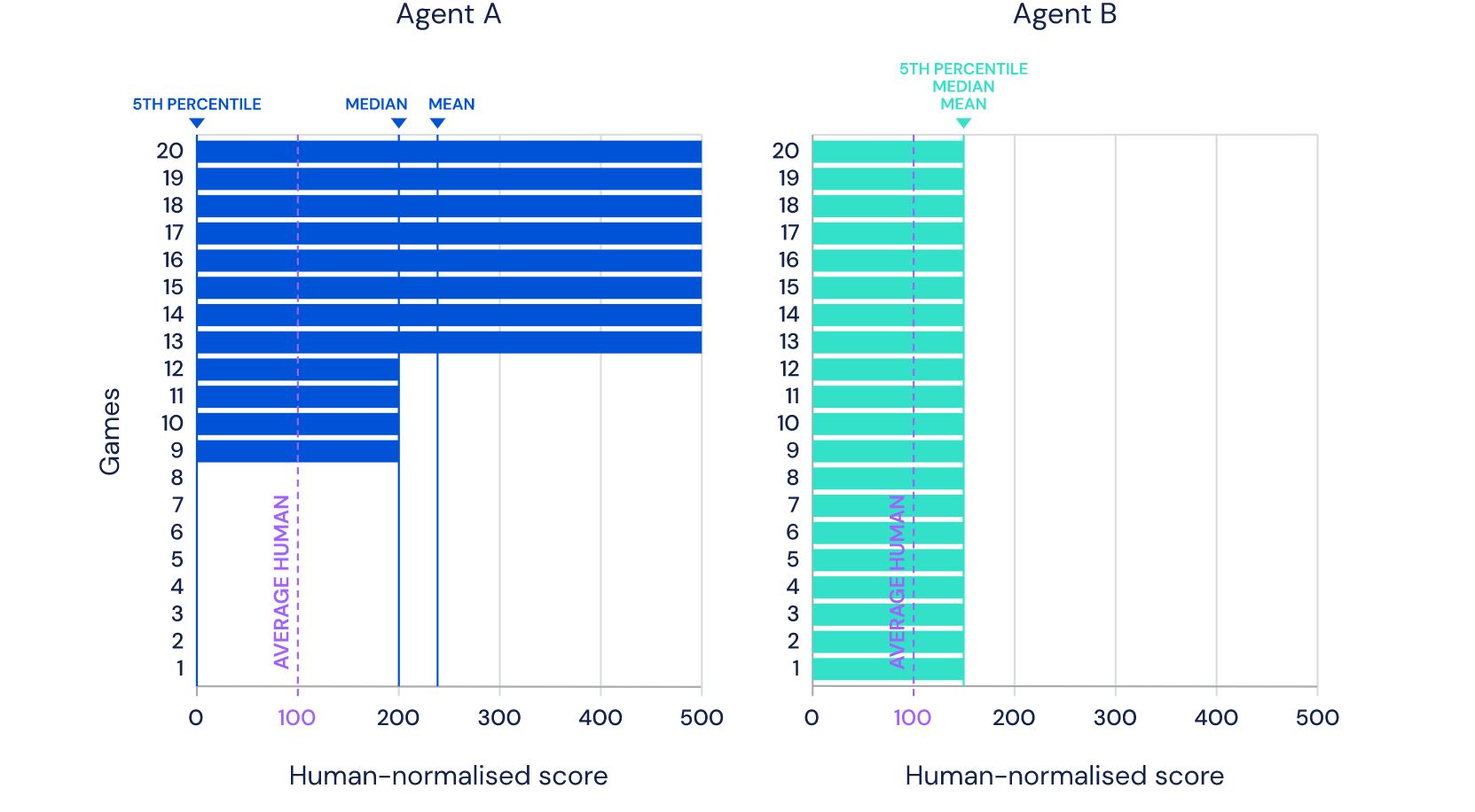 Which on the fingers means that before everyone was measured in the “average” standings, waving away the cases that are difficult for a computer, but now they’ve taken up just them. And thus, they achieved real superiority over man, and not super-results on computer-friendly cases.But let's look at the problem more globally to understand whether this is so. What is the interaction of the DeepMind AI with a video gameAn asterisk will hereinafter denote entities obtained by an algorithm created not with the help of AI, but with the help of expert opinion.Before disassembling the circuit, let's look at an alternative approach:
Which on the fingers means that before everyone was measured in the “average” standings, waving away the cases that are difficult for a computer, but now they’ve taken up just them. And thus, they achieved real superiority over man, and not super-results on computer-friendly cases.But let's look at the problem more globally to understand whether this is so. What is the interaction of the DeepMind AI with a video gameAn asterisk will hereinafter denote entities obtained by an algorithm created not with the help of AI, but with the help of expert opinion.Before disassembling the circuit, let's look at an alternative approach:Video Summary- + ,

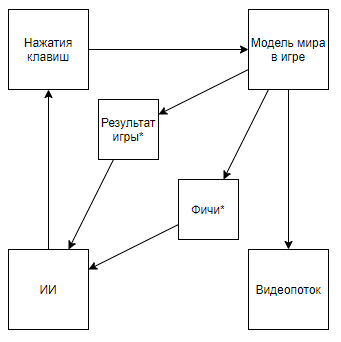 The scheme becomes like this. And if you climb on the author’s channel, you can find its application to retro games. Changing the scheme to this one, we come to the conclusion that the speed and effectiveness of training is growing by orders of magnitude, but at the same time, the scientific and engineering value of the achievements of such a trip becomes close to 0 (and yes, I do not take into account the popularization value).We can assume that the whole point is that the video is ejected from the pipeline, but consider the following scheme (I'm sure someone implemented something similar, but there’s no link at hand):Which is implemented when an expert who knows the necessary features writes a video stream parser that calculates features using key pixels.Or even such a scheme:Where first, AI1 is trained to extract features selected by an expert from the video.And then AI2 is taught to play by features extracted from the video stream using AI1. So we got a scheme that:
The scheme becomes like this. And if you climb on the author’s channel, you can find its application to retro games. Changing the scheme to this one, we come to the conclusion that the speed and effectiveness of training is growing by orders of magnitude, but at the same time, the scientific and engineering value of the achievements of such a trip becomes close to 0 (and yes, I do not take into account the popularization value).We can assume that the whole point is that the video is ejected from the pipeline, but consider the following scheme (I'm sure someone implemented something similar, but there’s no link at hand):Which is implemented when an expert who knows the necessary features writes a video stream parser that calculates features using key pixels.Or even such a scheme:Where first, AI1 is trained to extract features selected by an expert from the video.And then AI2 is taught to play by features extracted from the video stream using AI1. So we got a scheme that:- Uses a video stream, and does not have direct access to the model of the world.
- Doesn't rely on video stream parsers written by an expert
- It will be trained at times easier and more efficiently than the development of DeepMind
But ... we come to the same thing. Such an implementation, again, will have neither scientific nor engineering value in the context of application to retro games, since AI1 is a long-solved and very primitive task for modern image processing algorithms, and AI2 is also created very quickly and simply, which confirms the author of the above video .So, what's the value of DeepMind algorithms for Atari games? I'll try to summarize: the value is thatDeepMind algorithms are able to find the optimal behavior strategy for games with a primitive model of the MM world in conditions when the state of the world model S (MM, t) is represented with significant distortions by a certain distorting function F (S (MM, t)), only the quality of the decisions made can be evaluated a function that receives a sequence of F (S (MM, t)) values and algorithm reactions, and this sequence is of unknown length (the game can end in a different number of steps), but you can repeat the experiment an infinite number of times .Anticipating issues, . S(MM, t) , , . F(S(MM, t)) , .
Now let’s try to evaluate the applicability of such a value for solving real-world problems that somehow correlate with the tools, namely, they represent a real state with significant distortions, imply that the environment responds to the agent’s actions, gives an assessment only after a long sequence of decisions, and however, they allow the experiment to be performed many times.At first glance, an interesting application seems to be a game on the exchange. Even Google’s hints, giving it away as the only hint with real-world use, hint that the topic is hot.I’ll immediately point out an important point - almost all approaches to market analysis (not counting approaches that analyze real-world objects, such as parking lots in front of supermarkets, news, mentions of shares on Twitter) can be divided into two types. The first type is approaches representing the market as a time series. Second, as a stream of applications.Somehow the proponents of approaches of the first type see the market But the fundamental difference is not in the data used, but in the fact that, as a rule, those analyzing the market, as a time series, neglect their influence on the market, believing that, conditionally, on the daily interval, their transactions will not affect the further dynamics of the market. While the supporters of the second approach can both neglect, believing that their volume is insignificant in relation to market liquidity, and consider the market as a feedback system, believing that their actions affect the behavior of other players (for example, research and approaches related to the optimal execution of large orders, market-making, High-frequency trading).After looking through the search results, it is clear that all articles and posts devoted to trading using reinforcement training (the closest topic to the successes of DeepMind) are devoted to the first approach. But a reasonable question arises about the proportionality of the approach to the problem.First, let's draw a diagram similar to Atari games.Objective reality, . , , , , — . , , . , , , , , . , .
It seems that everything falls beautifully. And, I suspect that this similarity also warms up hype. But, what if we clarify the scheme a little: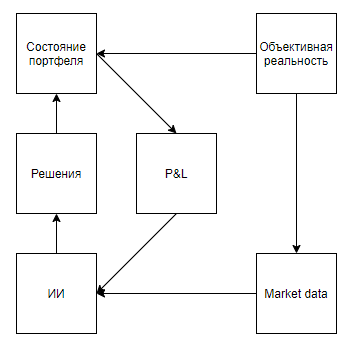
Anticipating the question of self-generating samples, , , . , , . , , . , , , , , .
The second approach (with a stream of applications) looks more promising. The so-called glassoften filled with applications of robots that hunt for fractions of a percent of the price, competing in a place in the queue, and often creating applications only to make the demand or supply appear, and provoke other bots to disadvantageous actions. It would seem, if you dream up, that if you create an exchange emulator and place HFT bots in it, which, taking billions of decisions, will self-learn, playing with the clones of themselves, and thereby develop an ideal strategy that will take into account all the optimal counter-strategies ... It’s a pity that if something like this happens, then about 5 people around the world will find out about it - the business principles of high-frequency traders imply absolute secrecy, and refusing to publish even unsuccessful results in order to leave enemies a chance to step on the same rake.I think it’s especially not worthwhile to focus on the impossibility of applying such approaches in marketing, HR, sales, management and other areas where the object is a person, because for the correct application it is necessary to enable AI to make millions, or even billions of experiments. And, even if many companies have a million interactions with an object where the AI can make a decision (choosing a banner to show to a potential client based on his profile, the decision to dismiss an employee), then no one will get a million experiments with the same object, which is exactly what is required for high-quality application. But what is worth focusing on is antifraud and cybersecurity.I don’t know, fortunately or unfortunately, but in the modern world very many economic relations are based on providing small value without obligations in exchange for expecting great value in the future, which gives rise to numerous freebie sources and potential for fraud.Examples:- The first free ride in taxi aggregators
- Payments of $ 70 for CPA in gambling, for a player who brought in $ 5
- Test $ 300 from cloud providers and trial periods
Moreover, the fraud potential of the modern economic system is supported by a low degree of protection for credit card transactions, because merchants often purposefully refuse the same 3D secure to simplify the user experience. Thus, for buyers of stolen cards for a small% of their balance, this list can be supplemented almost indefinitely.The main problem in the fight against such cases lies in the inability to collect a dataset of a sufficient volume -% fraud operations are 1-6 orders of magnitude lower than the percentage of good operations depending on the business. There is also a problem in the flexibility of fraudsters, which easily bypass static algorithms, adapting to antifraud systems that have been trained in past experience.And, it would seem, here it is. Algorithms like Agent57 launched in the sandbox will allow you to create the ideal fraudster, constantly update his skills, and at the same time solve the inverse problem - keep the algorithm for identifying it up to date. But there is one caveat. To win against the model of the world embedded in Atari games is not at all the same as to win from an antifraud system already trained on the basis of the behavior of millions of players, and a lot of actions with fraud are disproportionate to the many actions of a player in a retro game. For example, even such a simple action as entering a login on the registration form already carries billions of options for doing this. Starting from which user agent to transfer to the server, and ending with how many milliseconds to wait between entering the second and third login characters ...In general, I see it all somehow. Pretty bleak. And I really hope that I’m wrong, and somewhere I didn’t take something into account in the model. I would be grateful if I see counterexamples in the comments.