Hello dear Khabrovites, in this small example I want to show how you can parse a page, the data on which is loaded using javascript widgets. Moreover, even if the page in this example is easy to save, you still can’t parse all the necessary photos from it because of these widgets. In this case, I use cian.ru as an example , which has its own api , which I will not use, instead I will use Selenium. I do not work at cian.ru, I just use this site as an example. The code in the parser is simple and designed for beginners.
A short introduction - when at my leisure I looked at examples of repairs in cian.ru, I thought it would be nice to save the photos I liked, but manually saving them would be a long time, besides this is not our method, so I decided to write this parser.
The parser is written in python3 from the distribution of Anaconda , Selenium and chromedriver binary, I installed separately from these links. (And of course, the Google Chrome browser must be installed on the system )
Below is the full parser code, then I will analyze the main points separately.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
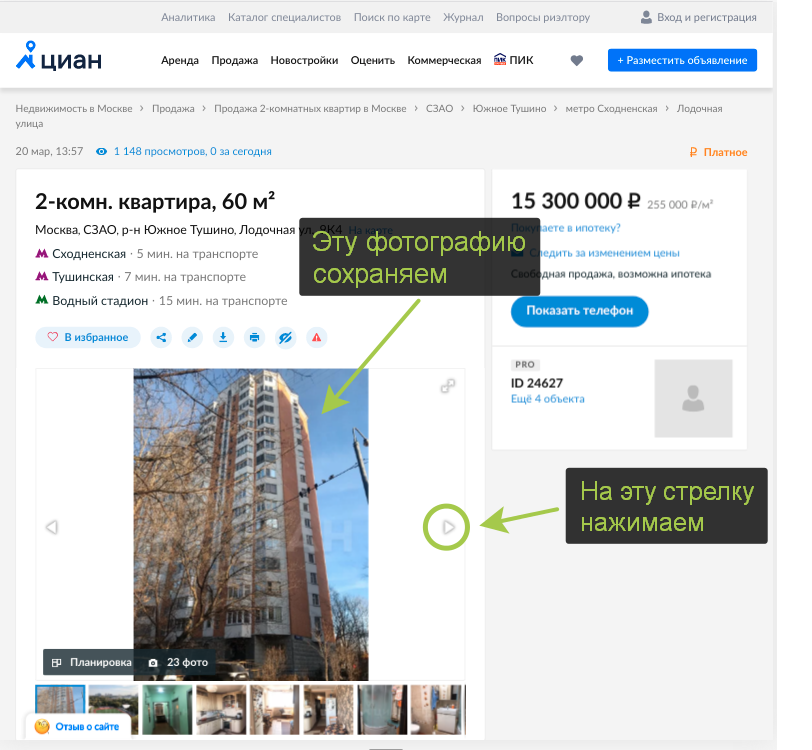
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.