Some time ago, I started an amazing journey into the world of the JIT compiler in order to find places where you can stick your hands in and speed something up, as In the course of the main work, a small amount of knowledge in LLVM and its optimizations has accumulated. In this article, I would like to share a list of my improvements in JIT (in .NET it is called RyuJIT in honor of some dragon or anime - I did not figure it out), most of which have already reached master and will be available in .NET (Core) 5 My optimizations affect different phases of JIT, which can be shown very schematically as follows: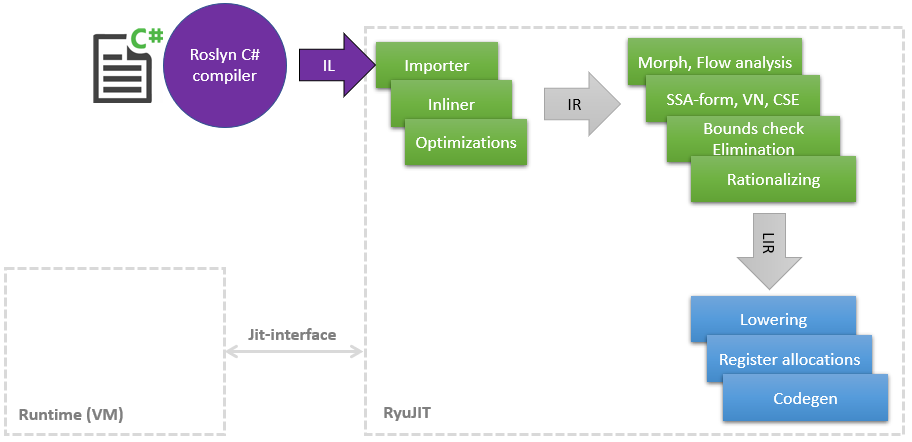 As can be seen from the diagram, JIT is a separate module related to the narrow Jit-Interface , by which JIT consults on some things, for example, is it possiblecast one class to another. The later the JIT compiles the method into Tier1, the more information the runtime can provide, for example, that the
As can be seen from the diagram, JIT is a separate module related to the narrow Jit-Interface , by which JIT consults on some things, for example, is it possiblecast one class to another. The later the JIT compiles the method into Tier1, the more information the runtime can provide, for example, that the static readonlyfields can be replaced with a constant, because the class is already statically initialized.So, let's start with the list.PR # 1817 : Boxing / unboxing optimizations in pattern matching
Phase: ImporterMany of the new C # features often sin by inserting box / unbox CIL opcodes . This is a very expensive operation, which is essentially the allocation of a new object on the heap, copying the value from the stack to it, and then also loads the GC in the end. There are already a number of optimizations in JIT for this case, but I found missing pattern matching in C # 8, for example:public static int Case1<T>(T o)
{
if (o is int x)
return x;
return 0;
}
public static int Case2<T>(T o) => o is int n ? n : 42;
public static int Case3<T>(T o)
{
return o switch
{
int n => n,
string str => str.Length,
_ => 0
};
}
And let's see the asm-codegen before my optimization (for example, for int specialization) for all three methods: And now after my improvement:
And now after my improvement: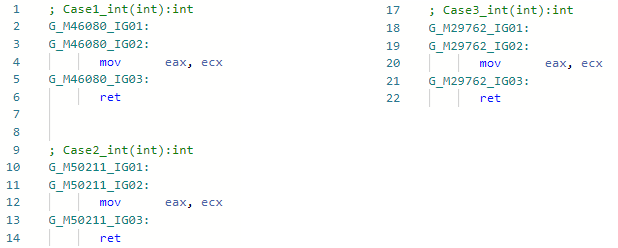 The fact is that optimization found patterns of IL code
The fact is that optimization found patterns of IL codebox !!T
isinst Type1
unbox.any Type2
when importing and having information about types, I was able to simply ignore these opcodes and not insert boxing-anboxing. By the way, I implemented the same optimization in Mono as well. Hereinafter, a link to Pull-Request is contained in the header of the optimization description.PR # 1157 typeof (T) .IsValueType ⇨ true / false
Phase: ImporterHere I trained JIT to immediately replace Type.IsValueType with a constant if possible. This is a minus the challenge and the ability to cut out whole conditions and branches in the future, an example:void Foo<T>()
{
if (!typeof(T).IsValueType)
Console.WriteLine("not a valuetype");
}
And let's see the codegen for Foo <int> specialization before the improvement: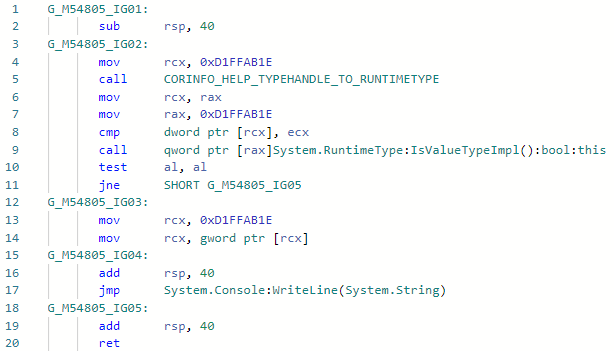 And after the improvement: The
And after the improvement: The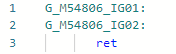 same can be done with other Type properties if necessary.
same can be done with other Type properties if necessary.PR # 1157 typeof(T1).IsAssignableFrom(typeof(T2)) ⇨ true/false
Phase: ImporterAlmost the same thing - now you can check for hierarchy in generic methods without fear that this is not optimized, for example:void Foo<T1, T2>()
{
if (!typeof(T1).IsAssignableFrom(typeof(T2)))
Console.WriteLine("T1 is not assignable from T2");
}
In the same way, it will be replaced by a constant true/falseand the condition can be deleted entirely. In such optimizations, of course, there are some corner cases that you should always keep in mind: System .__ Canon shared generics, arrays, co (ntr) variability, nullables, COM objects, etc.PR # 1378 "Hello".Length ⇨ 5
Phase: ImporterDespite the fact that the optimization is as obvious and simple as possible, I had to sweat a lot to implement it in JIT-e. The thing is that JIT did not know about the contents of the string, he saw string literals ( GT_CNS_STR ), but did not know anything about the specific contents of the strings. I had to help him by contacting VM (to expand the aforementioned JIT-Interface), and the optimization itself is essentially a few lines of code . There are a lot of user cases, besides the obvious ones, such as: str.IndexOf("foo") + "foo".Lengthto the non-obvious ones in which inlining is involved (I remind you: Roslyn does not deal with inlining, so this optimization would be ineffective in it, in addition, like all others), for example:bool Validate(string str) => str.Length > 0 && str.Length <= 100;
bool Test() => Validate("Hello");
Let's look at the codegen for Test ( Validate is inline):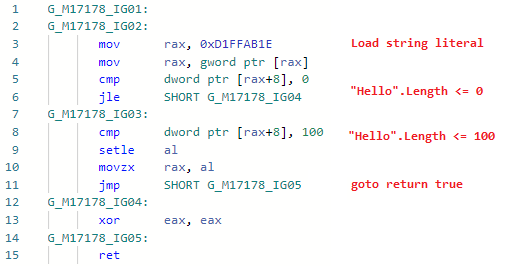 and now the codegen after adding the optimization:
and now the codegen after adding the optimization: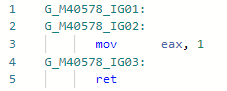 i.e. inline the method, replace the variables with string literals, replace .Length from literals with real string lengths, fold the constants, delete the dead code. By the way, since JIT can now check the contents of a string, doors have opened for other optimizations related to string literals. The optimization itself was mentioned in the announcement of the first preview of .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 in the section Code quality improvements in RyuJIT .
i.e. inline the method, replace the variables with string literals, replace .Length from literals with real string lengths, fold the constants, delete the dead code. By the way, since JIT can now check the contents of a string, doors have opened for other optimizations related to string literals. The optimization itself was mentioned in the announcement of the first preview of .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 in the section Code quality improvements in RyuJIT .PR # 1644: Optimizing Bound Checks.
Phase: Bounds Check EliminationFor many, it will not be a secret that every time you access an array by index, the JIT inserts a check for you that the array does not go beyond and throws an exception if this happens - in the case of erroneous logic, you could not to read random memory, get some value and continue on.int Foo(int[] array, int index)
{
return array[index];
}
Such a check is useful, but it can greatly affect performance: firstly, it adds a comparison operation and makes your code unbranched, and secondly, it adds an exception calling code to your method with all the consequences. However, in many cases, the JIT can remove these checks if it can prove to itself that the index will never go beyond that, or that there is already some other check and you don’t need to add one more - Bounds (Range) Check Elimination. I found several cases in which he could not cope and corrected them (and in the future I plan some more improvements of this phase).var item = array[index & mask];
Here in this code, I tell JIT that & maskessentially limits the index from above to a value mask, i.e. if the value maskand length of the array are known to JIT , you can not insert a bound check. The same goes for%, (& x >> y) operations. An example of using this optimization in aspnetcore .Also, if we know that in our array, for example, there are 256 elements or more, then if our unknown indexer is of the byte type, no matter how hard it tries, it will never be able to exit out of bounds. PR: github.com/dotnet/coreclr/pull/25912PR # 24584: x / 2 ⇨ x * 0.5
Phase: MorphC of this PR and started my amazing dive into the world of JIT optimizations. The operation "division" is slower than the operation "multiplication" (and if for integers and in general - an order of magnitude). Works for constants only equal to the power of two, example:static float DivideBy2(float x) => x / 2;
Codegen before optimization: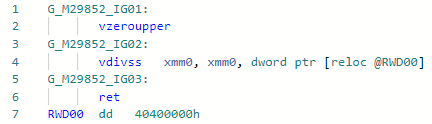 and after:
and after: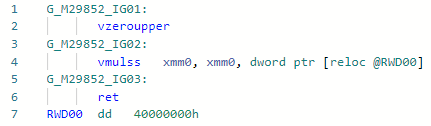 If we compare these two instructions for Haswell, then everything will become clear:
If we compare these two instructions for Haswell, then everything will become clear:vdivss (Latency: 10-20, R.Throughput: 7-14)
vmulss (Latency: 5, R.Throughput: 0.5)
This will be followed by optimizations that are still in the code-review stage and not the fact that they will be accepted.PR # 31978: Math.Pow(x, 2) ⇨ x * x
Phase: ImporterEverything is simple here: instead of calling pow (f) for a rather popular case, when the degree is constant 2 (well, it's free for 1, -1, 0), you can expand it into a simple x * x. You can expand any other degrees, but for this you need to wait for the implementation of the “fast math” mode in .NET, in which the IEEE-754 specification can be neglected for the sake of performance. Example:static float Pow2(float x) => MathF.Pow(x, 2);
Codegen before optimization: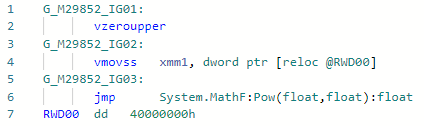 and after:
and after: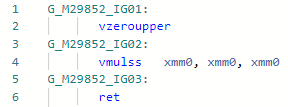
PR # 33024: x * 2 ⇨ x + x
Phase: LoweringAlso quite simple micro (nano) piphol optimization, allows you to multiply by 2 without loading the constant into the register.static float MultiplyBy2(float x) => x * 2;
Codegen before optimization: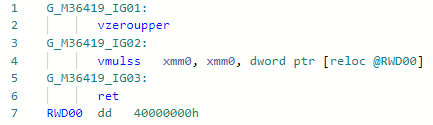 After:
After: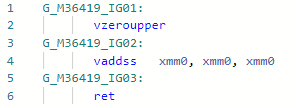 In general, the instruction is the
In general, the instruction is the mul(ss/sd/ps/pd)same in latency and throughput as add(ss/sd/ps/pd), but the need to load the constant “2” can slightly slow down the work. Here, in the example of the codegen above, I vaddssdid everything within the framework of one register.PR # 32368: Optimization of Array.Length / c (or% s)
Phase: MorphIt just so happened that the Length field of Array is a signed type, and division and remainder by a constant are much more efficient to do from an unsigned type (and not just a power of two), just compare this codegen: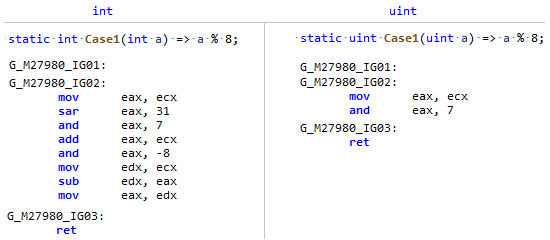 My PR just reminds JIT that
My PR just reminds JIT that Array.Lengththough significant, but in fact, the length of the array NEVER ( unless you are an anarchist ) can be less than zero, which means you can look at it as an unsigned number and apply some optimizations like for uint.PR # 32716: Optimization of simple comparisons in branchless code
Phase: Flow analysisThis is another class of optimizations that operates with basic blocks instead of expressions within one. Here JIT is a bit conservative and has room for improvements, for example cmove inserts where possible. I started with a simple optimization for this case:x = condition ? A : B;
if A and B are constants and the difference between them is unity, for example, condition ? 1 : 2then we, knowing that the comparison operation in itself returns 0 or 1, can replace jump with add. In terms of RyuJIT, it looks something like this: I recommend to see the description of the PR itself, I hope everything is clearly described there.
recommend to see the description of the PR itself, I hope everything is clearly described there.Not all optimizations are equally useful.
Optimizations require a rather high fee:* Increase = complexity of the existing code for support and reading* Potential bugs: testing compiler optimizations is insanely difficult and easy to miss something and get some kind of segfault from users.* Slow compilation* Increasing the size of the JIT binarAs you already understood, not all ideas and prototypes of optimizations are accepted and it is necessary to prove that they have the right to life. One of the accepted ways to prove this in .NET is to run the jit-utils utility, which will AOT compile a set of libraries (all BCL and corelib) and compare the assembler code for all methods before and after optimizations, this is how this report looks for optimization"str".Length. In addition to the report, there is still a certain circle of people (such as jkotas ) who, at a glance, can evaluate the usefulness and hack everything from the height of their experience and understanding which places in .NET can be a bottleneck and which ones can not. And one more thing: do not judge optimization by the argument “no one writes”, “it would be better to just show warning in Roslyn” - you never know how your code will look after JIT inlines everything that is possible and fills in constants.