Compression of standard headers has appeared in HTTP / 2, but the body of the URI, Cookie, User-Agent values can still be tens of kilobytes and require tokenization, search and comparison of substrings. The task becomes critical if an HTTP parser needs to handle heavy malicious traffic. Standard libraries provide extensive string processing tools, but HTTP strings have their own specifics. It is for this specificity that the Tempesta FW HTTP parser was developed. Its performance is several times higher compared to modern Open Source solutions and surpasses the fastest of them.Alexander Krizhanovsky (krizhanovsky) founder and system architect Tempesta Technologies, an expert in high performance computing in Linux / x86-64. Alexander will talk about the peculiarities of the structure of HTTP strings, explain why standard libraries are poorly suited for processing them, and present the Tempesta FW solution.Under the cat: how does HTTP Flood turn your HTTP parser into a bottleneck, x86-64 problems with branch mispredictions, caching and out-of-memory memory on typical HTTP parser tasks, comparing FSM with direct jumps, GCC optimization, auto-vectorization, strspn () - and strcasecmp () - like algorithms for HTTP strings, SSE, AVX2 and filtering injection attacks using AVX2.At Tempesta Technologies we develop custom software: we specialize in complex areas related to high performance. We are especially proud of the development of the core of Positive Technologies' first version WAF. Web Application Firewall (WAF) is an HTTP proxy: it deals with a very deep analysis of HTTP traffic for attacks (Web and DDoS). We wrote the first core for it.In addition to consulting, we are developing Tempesta FW - this is Application Delivery Controller (ADC). We’ll talk about him.Application Delivery Controller
Application Delivery Controller is an HTTP proxy with enhanced functionality. But I’ll talk about a feature that is related to security - about filtering DDoS and Web attacks. I’ll also mention the limitations, and I’ll show the work and functions with code examples.
Performance
Tempesta FW is built into the Linux TCP / IP Stack kernel. Thanks to this and a number of other optimizations, it is very fast - it can process 1.8 million requests per second on cheap hardware. This is 3 times faster than Nginx at the top load and is also fast when compared with kernel bypass approach.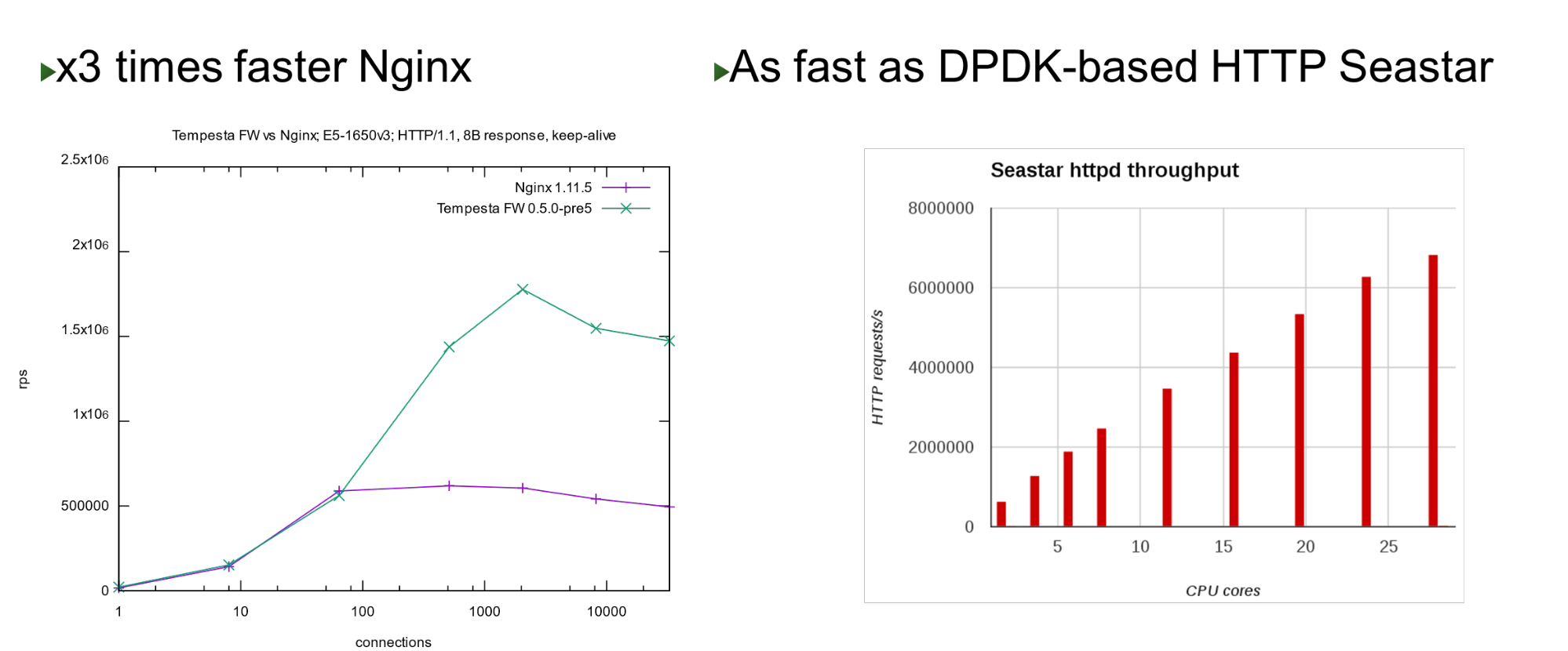 On a small number of cores, it shows similar performance with the Seastar project, which is used in ScyllaDB (written in DPDK).
On a small number of cores, it shows similar performance with the Seastar project, which is used in ScyllaDB (written in DPDK).Problem
The project was born when we started working on PT AF - in 2013. This WAF was based on one popular Open Source HTTP accelerator. Nginx, HAProxy, Varnish or Apache Traffic are good HTTP accelerators: they deliver content fine, cache, modify, but none of them are designed for massive traffic processing and filtering .Therefore, we thought that if there is a network-level firewall, why not continue this idea and integrate into the TCP / IP stack as an application-level firewall? Actually, it turned out Tempesta FW - a hybrid of HTTP accelerator and firewall .Note: Nginx will be used as an example in the report because it is a simple and popular web server. Instead, there could be any other Open Source HTTP server.HTTP
Let's look at our HTTP request (HTTP / (1, ~ 2))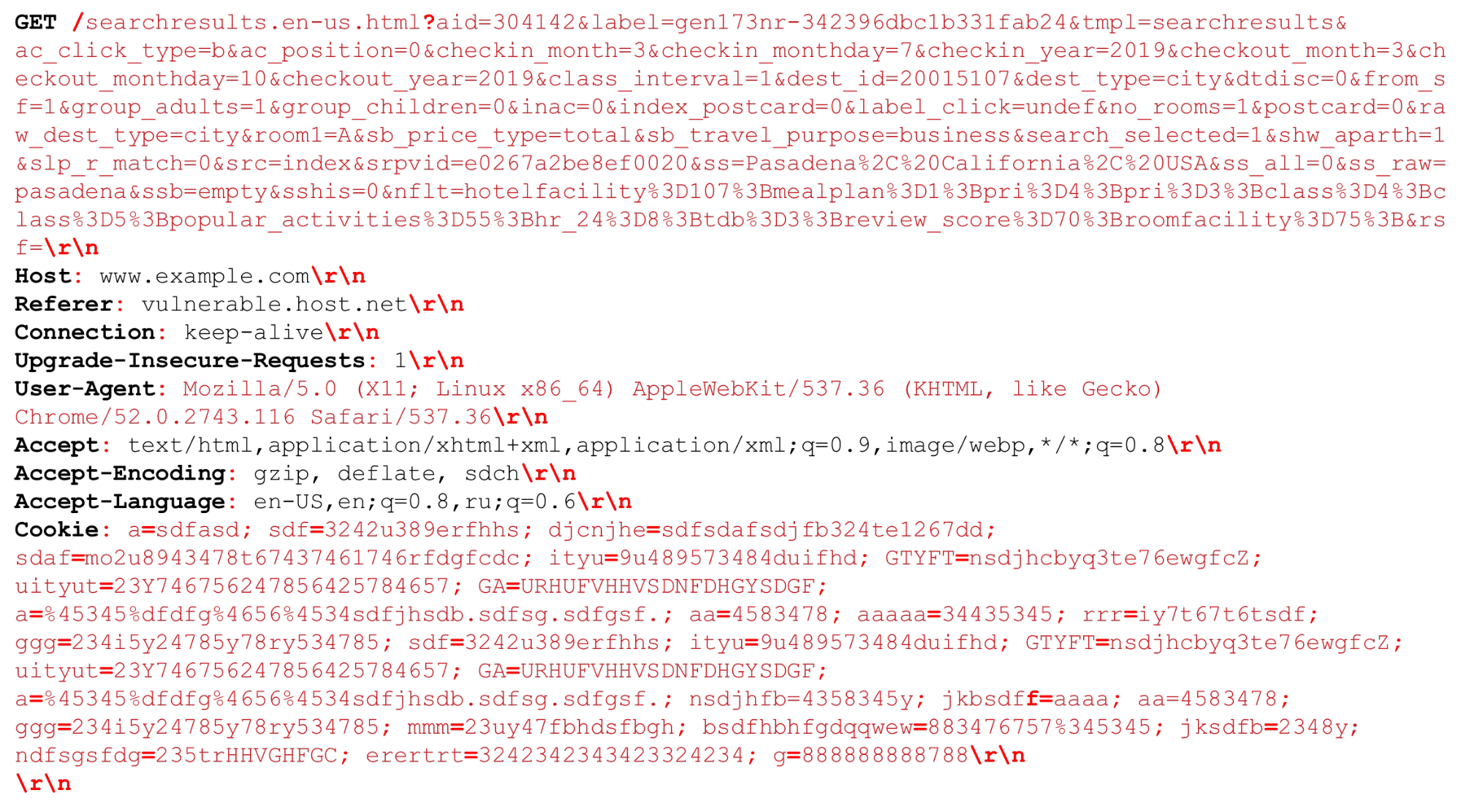 We can have a very large URI. Separators that are important at the time of HTTP parsing are highlighted in red bold . I will highlight the features: large strings of several kilobytes, as well as different delimiters, for example, additional "semicolons" that we need to parse, or the sequence "\ r \ n".A little bit about HTTP / 2 also needs to be said.
We can have a very large URI. Separators that are important at the time of HTTP parsing are highlighted in red bold . I will highlight the features: large strings of several kilobytes, as well as different delimiters, for example, additional "semicolons" that we need to parse, or the sequence "\ r \ n".A little bit about HTTP / 2 also needs to be said.HTTP / 2 Features
HTTP / 2 is a mixture of strings and binary data . This mix is more about optimizing the bandwidth of a connection than saving server resources.HTTP / 2 in HPACK uses a dynamic table . The first request from the client is not optimized, it is not in the table. You must parse it so that it is added to the table. If HTTP / 2 DDoS comes to you, this will be just the case. In the normal case, HTTP / 2 is a binary protocol, but you still need to parse text: text header names, data.Huffman encoding. This is a simple encoding, but Huffman is monstrously hard to program quickly for compression: Huffman encoding crosses the byte boundary, you cannot use vector extensions and you need to go by bytes. You will not be able to quickly process data in 32 or 16 bytes.Cookies, User-Agent, Referer, URIs can be very large . First, remove Huffman, then send it to a regular HTTP parser, the same as in HTTP / 1. Although it is allowed by the RFC, cookies are not recommended to be compressed, because this is confidential data - you should not give the attacker information about their size.Slow HTTP processing . All HTTP servers first decode HTTP / 2 and then send these lines to the HTTP / 1 parser that HTTP / 1 already uses.What is the problem with HTTP / 1 parsing?- You need to quickly program the state machine.
- You need to quickly process consecutive lines.
Malicious traffic targets the slowest (weakest) part of the process. Therefore, if we want to make a filter, we must pay attention to the slow parts so that they also work quickly.Nginx profile
Let's look at the nginx profile under the HTTP flood. Disable access log so that the file system does not slow down. When even a regular index page is requested, the parser goes up at the top.Left - "Flat profile". Interestingly, the hottest spot in it is not much heavier than the next, and after it the profile descends smoothly. This means, for example, that optimizing the first function twice will not help to significantly improve performance. That is why we did not optimize the same Nginx, but made a new project that will improve the performance of the entire tail of the profile.How regular HTTP parsers are encoded
Usually we have a loop ( while) that runs along the line, and two variables: state ( state) and current data ( str_ptr).We enter the cycle (1) and look at the current state (check state). We pass to the received data (symbol 'b') and implement some logic. We pass to the second state (2). Go to the end
Go to the end switch(3) - this is the second transition relative to the beginning of our code and, possibly, the second miss in the instruction cache. Then we go to the beginning while(4), eat the next character ... ... and again look for the state in the instructions inside
... and again look for the state in the instructions inside case 2:.When a variable has already been assigned a statevalue2, we could just go to the next instruction. But instead, they went up again and went down again. We “cut circles” by code instead of just going down. Normal parsers do not, for example, Ragel generates a parser with direct transitions.
Nginx HTTP Parser
A few words about the nginx parser and its environment.Nginx works with the normal socket API - the data that goes to the adapter is copied to user space. As a result, we have a large data chunk in which we are looking for what we need.Nginx uses an algorithm that works in two passes: first it searches for length, then it checks. In the first step, he scans the string for tokens, searches for the first token (“trial”). On the second, it tokens, checks the end of the request ( Get) and starts switch, according to the size of the token.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
“Get” is always in the same data chunk . Tempesta FW works with zero-copy. This means that data can come with a completely arbitrary size: 1 byte or 1000 bytes each. This "mechanism" does not suit us.Let's see how it works switchin GCC.Gcc
Lookup table . On the left is a typical example of enum: start with 0, then consecutive labels, 26 constants, and then some code that processes it all. On the right is the code that the compiler generates. First, compare the variable
First, compare the variable statein the EAX register with a constant. Next, we present all the labels in the form of a sequential array of pointers of 8 bytes (lookup table). On this instruction we pass on offset in this array - it is double dereferencing of pointers. Bottom right is the code that we switched to from this table.It turns out double dereferencing of memory: if we received secret data, then by bytes we find the address in the array and go to this pointer. It is important to know that in life it is still worse than in the example - for lookup table the compiler generatesthe code is more complicated in the case of a script for a Specter attack.Binary search . The next case is switchnot with sequential constants, but with arbitrary ones. The code is the same, but now GCC cannot compile such a large array and use constants as the index of the array. He switches to binary search. On the right we see a sequential comparison, the transition to the address and the continuation of the comparison - the binary search is by code.Nginx HTTP parser. Let's see what state machine nginx is. It has 9 kilobytes of code - this is three times less than the first level cache on the machine on which the benchmarks were launched (as on most x86-64 processors).
On the right we see a sequential comparison, the transition to the address and the continuation of the comparison - the binary search is by code.Nginx HTTP parser. Let's see what state machine nginx is. It has 9 kilobytes of code - this is three times less than the first level cache on the machine on which the benchmarks were launched (as on most x86-64 processors).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
The nginx header parser ngx_http_parse_header_line ()is a simple tokenizer. It does nothing with the values of the headers and their names, but simply puts the tokens of the HTTP headers into a hash. If you need any header value, scan the header table and repeat the analysis.We must strictly check the names and values of the headers for security reasons .Tempesta FW: string validation of HTTP strings
Our state machine is an order of magnitude more powerful: we do RFC header validation and immediately, in the parser, process almost everything. If nginx has 80 states, then we have 520, and there are more of them. If we drove on switch, then it would be 10 times larger.We have zero-copy I / O - chunks of different sizes can cut data in different places. different chunks can cut our data. In zero-copy I / O, for example, “GET” can (rarely) occur as “GET”, “GE” and “T” or “G”, “E” and “T”, so you need to store the state between pieces of data . We practically remove the costs of I / O, but in the profile it flies up - everything is bad. The large HTTP parser is one of the most critical places in the project.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
What to do to improve this situation?FSM Direct Referrals
The first thing we do is use not a loop, but direct transitions by labels ( go to) . Normal parser generators like Ragel do this. We encode each of our states with a label in
We encode each of our states with a label in switchand a label in C with the same name . Every time we want to go, we find a label in switchor access the same state directly from the code. The first time we go through switch, and then inside it we go directly to the desired label.Disadvantage : when we want to switch to the next state, we must immediately evaluate whether we still have data available (because zero-copy I / O). Condition bodyforIt is copied to each state: instead of one condition in a regular switch-driven FSM, we have 500 of them according to the number of states. Generating code for each state is not great.In the case of large state machines, for forwith a large switchinside, GTC also repeats the condition forseveral times inside the code.Replace with switchdirect transitions. The next optimization is that we don’t use it switchand switch to direct jumps to the saved meta addresses. We want to immediately go to the desired point as soon as we enter the function. GCC allows you to do this. GCC has a standard extension that may help. We take the label name (here it is
GCC has a standard extension that may help. We take the label name (here it is from) and assign its address to some C-variable via double ampersand (&&). Now we can make a direct jump instructionjmpto the address of this label with goto.Let's see what comes of it.Direct Conversion Performance
On a small number of states, the direct transition code generator is even a little slower than normal switch. But for large state machines, productivity doubles. If the state machine is small, it is better to use the usual one switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
Note: Tempesta code is more complicated than the examples. GitHub has all the benchmarks so you can see everything in detail. The original parser code is available at the link (main HTTP parser). In addition to it, in Tempesta FW there are smaller parsers that use FSM easier.Why direct transitions may be slower
In the state machine, we go through a lot of code, so (expected) there will be a lot of branch mispredictions. Let's perform “profiling” according to branch-misses prediction:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
On a large state machine with 406 states, we spend 38% of the time processing transitions in switch. On a state machine with direct transitions, hotspots are line parsing. Parsing a string in each state includes checking the condition of the end of the string: the condition forin the state machine on switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
Next, let's look at the profiling of both types of state machine by events L1 instruction cache miss - almost 30 kilobytes for switchand 50 kilobytes for direct jumps (more than the cache of the first level instructions).It seems that if we do not fit in the cache, there should be a lot of cache misses for such a state machine. But no, they are 2 times less. That's because the cache works better: we work with the code sequentially and manage to pull up data from the older caches.The compiler changes the order of the code
When we program the state machine code on go to, we first have the states that will be called first when the data is received: the HTTP method, URI, and then the HTTP headers. It seems logical that the code will be loaded into the processor cache sequentially, from top to bottom, just as we go through the data. But this is completely wrong. If you look at the assembler code, you will see amazing things. On the left is what we programmed: first we parse the methods
On the left is what we programmed: first we parse the methods GETand POSTthen somewhere far below the unlikely method UNLOCK. Therefore, we expect to see parsing GETand at the beginning of the assembler POST, and then UNLOCK. But everything is quite the opposite: GETin the middle, POSTat the end, and UNLOCKabove.This is because the compiler does not understand how data comes to us. He distributes the code according to his picture of beautiful code. In order for him to arrange the code in the correct order, we must use the compiler barrier .The compiler barrier is an assembly dummy through which the compiler will not reorder. By simply placing such barriers, we improved productivity by 4% .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
Compose the code in your own way
Since the compiler does not arrange the data as we want, we will do profiler guided optimization (optimization under the control of the profiler). Profiler guided optimization (PGO) is the total number of samples, not a sequence of calls. For example, a URI receives more samples than a method analysis, so it will position the URI processing code before processing the method.How it works? We’ll write the code, run benchmarks on it, give the result of the profiling to the compiler, and it will generate the optimal code for our loads. But the problem is that it simply compiles the hottest sections of code, but does not track the time dependency. If the biggest URI in the load, then this will be the hottest place. The URI will rise to the top of the function, and PGO will not show that the method name is always before the URI. Accordingly, PGO does not work.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
What does work?likely/ unlikely macros (for Linux kernel code, GCC intrinsics are available in user space __builtin_expect()). They say which code to place closer. For example, likely reports that the request body should be immediately behind if. Then prefetching the code (prefetching the processor) will select that code and everything will be fast. The picture shows the beginning of the parsing method, the end and the barrier. We did not expect to see the code behind the barrier. It seems that this should not be - we have put up a barrier.But what happens in reality? The compiler sees the
The picture shows the beginning of the parsing method, the end and the barrier. We did not expect to see the code behind the barrier. It seems that this should not be - we have put up a barrier.But what happens in reality? The compiler sees the likelycondition - it is most likely that we will enter the body of the condition and there we will switch to an unconditional jump to the labelReq_Uri. It turns out that the code that is after our condition is not processed in the "hot path". The compiler moves the code under the label behind if, despite the barrier, because the hot code condition is met.To this was not, GCC has an extension: the attributes hotand coldfor the labels. They say which label is hot (most likely) and which is cold (less likely). Here we agree on what is
Here we agree on what is GETmore likely POSTand leave it to him likely. Under the condition, URI processing rises, and POSTgoes below. All other code for the least likely state machine stays below because the label is cold.Ambiguous -O3
Let's look at compiler optimization. The first thing that comes to mind is to use not O2, but O3 - it should be faster. But this is not so - O3 sometimes generates worse code. O3 is a collection of some optimizations . If we add them to O2 separately, we get different options: some optimizations help, some interfere. For our specific code, we select only those optimizations that generate the code better. We leave the best result - here are 1,820 seconds relative to 1,838 and 1,858.Some options are highlighted in green - this is auto-vectorization.
O3 is a collection of some optimizations . If we add them to O2 separately, we get different options: some optimizations help, some interfere. For our specific code, we select only those optimizations that generate the code better. We leave the best result - here are 1,820 seconds relative to 1,838 and 1,858.Some options are highlighted in green - this is auto-vectorization.Autovectorization
An example of a cycle from the GCC guide .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
If we have some variable array that repeats, we can optimize the cycle - decompose into vectors. By default, auto- vectorization is enabled at the third level of optimization -O3 : GCC generates vector code where it can. But not all code can be automatically vectorized (even if it is vectorized in principle).We can enable the GCC option -fopt-info-vec-all, which shows what has been vectorized and what is not. We get that for our benchmark nothing is vectorized, but the code is still generated worse. Therefore, vectorization does not always work: sometimes it slows down the code. But we can always see what has been vectorized and what is not, and turn off vectorization, if necessary.Alignment: how to compare string with GET?
We make a small hack, as in nginx: we do not parse lines by bytes, but calculate intand compare lines with them.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
We know that if it is intnot aligned, then it slows down 2-3 times. We wrote a small benchmark that proves this.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
Then try to align int. We will look, if the address is intaligned, then compare by int, if not, bytes. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
But it turns out that this approach works worse:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
In short: there is a difference between the isolated, non-optimizable, benchmark code and the inlined parser code, which loses its optimization due to the large amount of code. There was no penalty in profiling.Note: a detailed discussion of why this is happening in our task can be read on GitHub .Why are HTTP strings important to us?
For example, this is a normal URI: If you are picky enough about the hotel, go to Booking and set some filters, get a URI more than a kilobyte.Nginx has a fairly massive parsing machine on
If you are picky enough about the hotel, go to Booking and set some filters, get a URI more than a kilobyte.Nginx has a fairly massive parsing machine on switch/ case. It does not work very fast. In addition, in the case of Tempesta FW, we need to not only parse the URI, but also check it for injections.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
Another URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d%0a% 0d% 0aHTTP / 1.1% 20200% 20OK% 0d% 0aContent-Type:% 20text /html% 0d% 0aContent -Length:% 2019% 0d% 0a% 0d% 0aShazam </html>.It looks like the first, but it has an injection. You’ll have to dig deep enough to understand this.Let's run a test : take the first URI, feed wrk, set it to nginx and see that parsing nginx gets very hot. If on the previous regular index query it was clear that the parser is already in the top, here it gets even hotter.
If on the previous regular index query it was clear that the parser is already in the top, here it gets even hotter.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
What is special about HTTP strings? There are different separators ' : 'and ' , ', and even the end of the lines, which can be either double-byte \r\nor single-byte \n, which was discussed at the beginning. There is no 0-termination of C-lines - for security reasons we want to more accurately check what comes to us. We have two standard functions that help in the parser.strspn: checks the alphabet, available characters in a string, dynamically compiles a valid alphabet, although it is known at the stage of compilation of the program.strcasecmp(). There is no need to convert case to compare xwith Foo:. In most cases strcasecmp(), only compliance / non-compliance is required for , and you do not need to know the position in the line.
They work slowly. Let's see the benchmarks and understand what is wrong with them.Quick parsers
There are several parsers.Nginx is the simplest parser, parser. It strictly checks RFC compliance. There are also PicoHTTPParser (H2O) and Cloudflare parsers. They process data faster, but may skip characters that are not allowed by the RFC.PCMESTRI. Parsers use several different approaches. The first is the PCMESTRI instruction, which is used in the Pico parser.We set ranges in the instructions. Unfortunately, we can load either 16 characters or 8 ranges. If the range consists of only one character - just repeat. Because of this limitation, the Pico parser cannot fully verify RFC compliance, because the RFC has more than 8 ranges in this location. We load the alphabet into the register, load the string, execute the instruction. At the exit, we quickly see whether there is a coincidence or not.AVX2 - CloudFlare Approach. The CloudFlare parser, using AVX2, processes 32 bytes of a string at a time, instead of 16 bytes with a Pico parser. Parsing is better at CloudFlare because it was transferred to AVX2.
We load the alphabet into the register, load the string, execute the instruction. At the exit, we quickly see whether there is a coincidence or not.AVX2 - CloudFlare Approach. The CloudFlare parser, using AVX2, processes 32 bytes of a string at a time, instead of 16 bytes with a Pico parser. Parsing is better at CloudFlare because it was transferred to AVX2. We check all the characters to a space in the ASCII table, all characters are greater than 128 and take the range between them. Simple code is fast.Compare PCMESTRI and AVX2. For us, the current limit is 1500. This is the maximum package size that comes to us. We see that the AVX2 code on big data is much faster than the Pico parser. But it works slower on small data, because instructions are heavier in AVX2.
We check all the characters to a space in the ASCII table, all characters are greater than 128 and take the range between them. Simple code is fast.Compare PCMESTRI and AVX2. For us, the current limit is 1500. This is the maximum package size that comes to us. We see that the AVX2 code on big data is much faster than the Pico parser. But it works slower on small data, because instructions are heavier in AVX2. Comparable to
Comparable tostrspn. If we decide to use strspn, things get worse, especially on big data. In the "combat" parser can not be used strspn.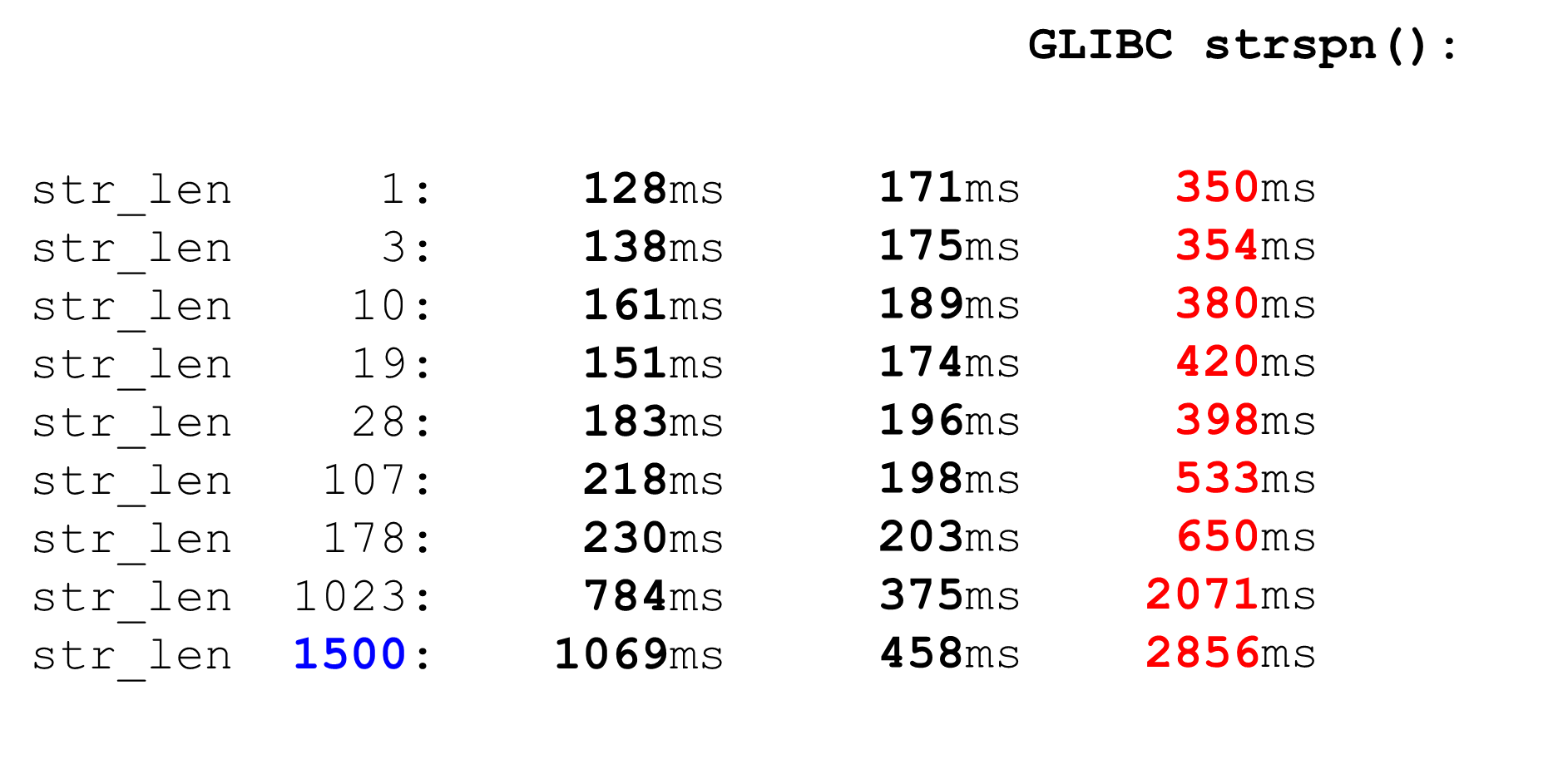
Tempesta matcher is faster and more accurate
Our speed parser is like these two. On small data, it is as fast as a Pico parser, on large - like CloudFlare. However, it does not skip invalid characters. How is the parser arranged? We, as nginx, define an array of bytes and check the input data by it - this is the prologue of the function. Here we work only with short terms, we use
How is the parser arranged? We, as nginx, define an array of bytes and check the input data by it - this is the prologue of the function. Here we work only with short terms, we use likelyit because branch misprediction is more painful for short lines than for long ones. We take this code up. We have a limit of 4 because of the last line - we must write a fairly powerful condition. If we process more than 4 bytes, the condition will be harder and the code slower.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
Main loop and large tail. In the main processing cycle, we divide the data: if it is long enough, we process 128, 64, 32, or 16 bytes each. It makes sense to process 128 each: in parallel, we use several processor channels (several pipeline) and a superscalar processor.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
Tail. The end of the function is similar to the beginning. If we have less than 16 bytes, then we process 4 bytes in a loop, and then no more than 3 bytes at the end.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
We load bit masks and data - this is the main algorithm of the main body of the function. We present an ASCII table (as in the picture) with 16 rows and 8 columns. First, we encode our table rows in the first register of BM URI: the first and second row.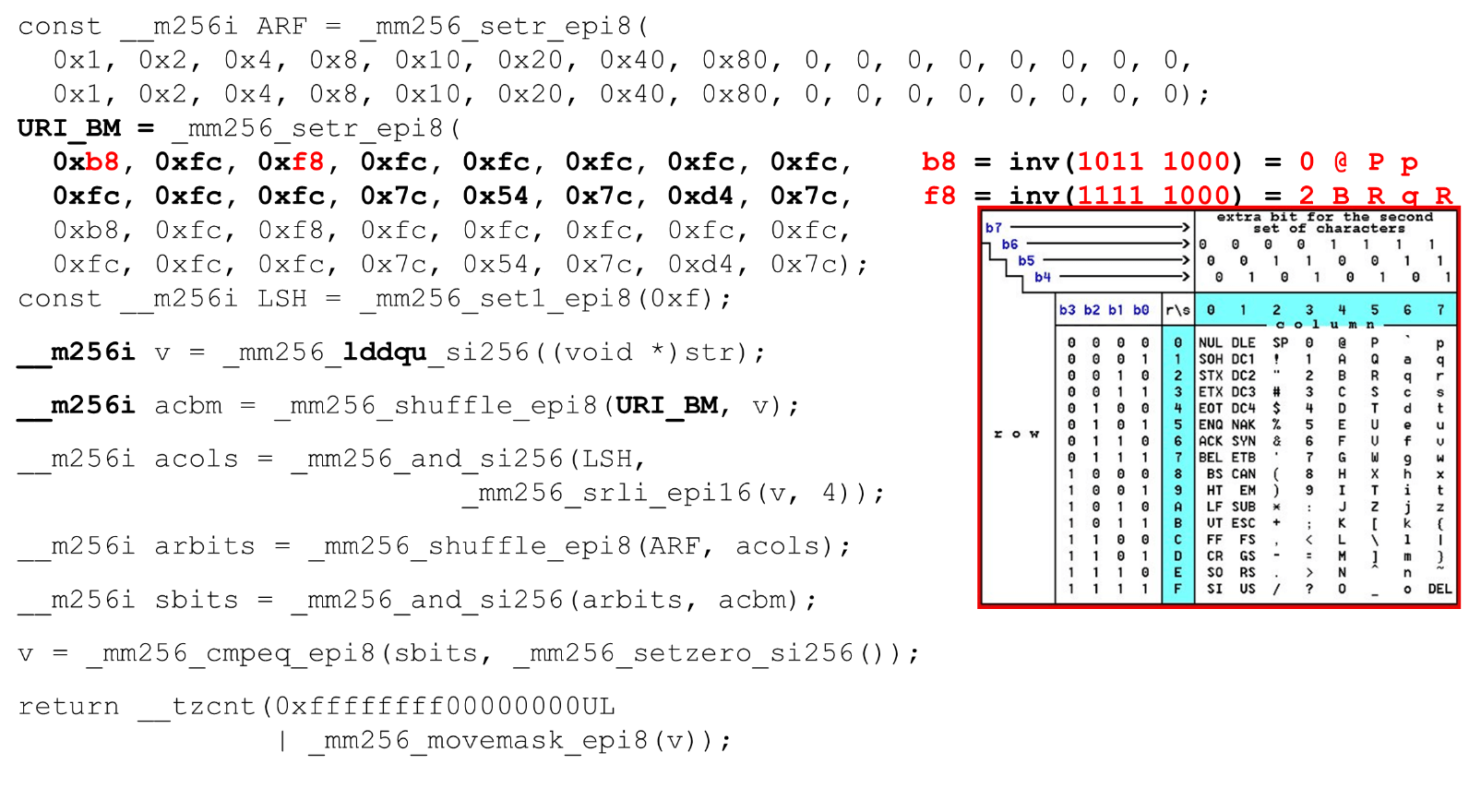 The actual symbols that we allow are
The actual symbols that we allow are 0 @ P pand 2 B R q R. They are encoded as follows: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.We encode in the reverse order: we start at 0, the first service character is not allowed, and then units are what is allowed.Set the ASCII bit masks. For example, a line comes in "pr": the first character from the first line is ASCII, the second from the second line. We run the shuffle statement, which shuffles our encoded table rows in accordance with the order of these characters in the input. Column ID for input. Next, we place the columns of the ASCII table in a different register. Then we “cross” the registers of columns and rows, and we get a correspondence: our character or not.Since the columns are the most significant 4 bits from the byte, we shift to the left. AVX has an offset of only 2 bytes, so first shift the byte, then n with our mask to get only significant bits.
Column ID for input. Next, we place the columns of the ASCII table in a different register. Then we “cross” the registers of columns and rows, and we get a correspondence: our character or not.Since the columns are the most significant 4 bits from the byte, we shift to the left. AVX has an offset of only 2 bytes, so first shift the byte, then n with our mask to get only significant bits. Arranging ASCII Columns Run the second shuffle, move the column to the desired positions. In both cases, the input byte from the last column, so in the first and second position we get the same column.
Arranging ASCII Columns Run the second shuffle, move the column to the desired positions. In both cases, the input byte from the last column, so in the first and second position we get the same column.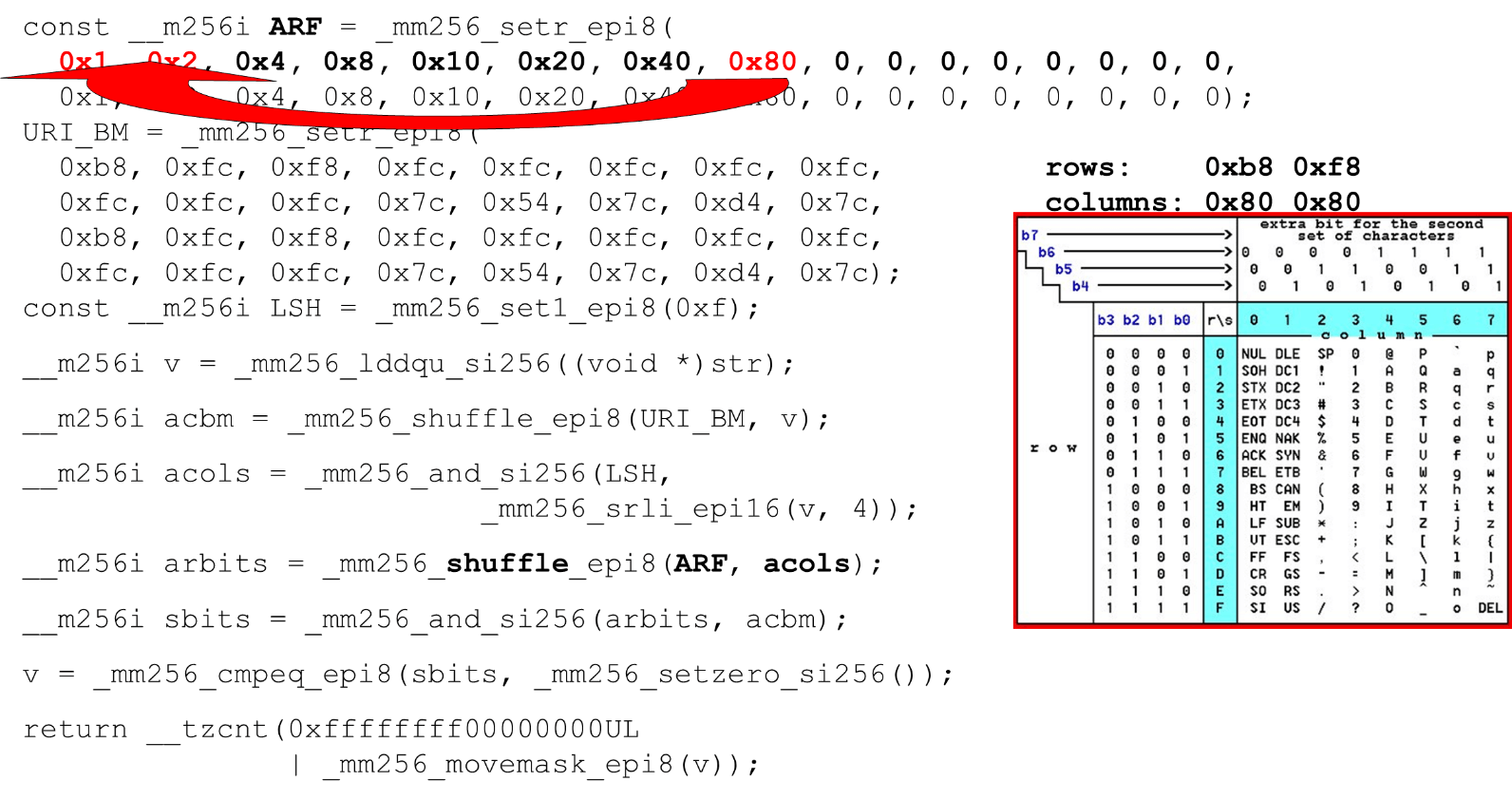 Intersection of columns and rows of masks . We do
Intersection of columns and rows of masks . We do and(“cross” the columns with columns) and we get that the input data is valid - the resultandfrom the intersection of columns and rows is not zero. Count the number of zeros at the end. We collect it all from the vector in
Count the number of zeros at the end. We collect it all from the vector in intand return it to the output - quite simply.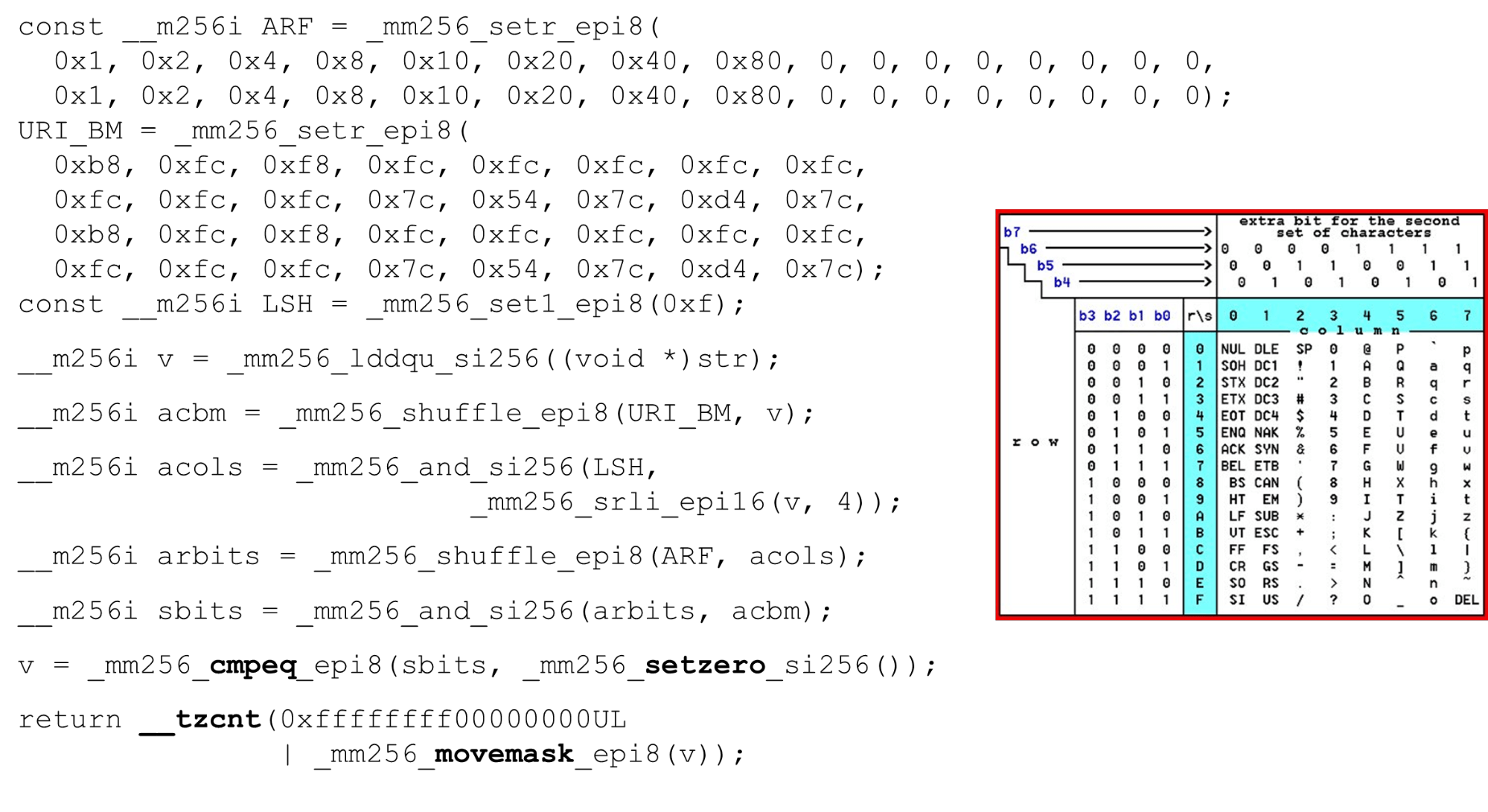 Customize the alphabets. Working with the ASCII table, we get a cheap feature: we use static tables, but nothing prevents asking the user which alphabet is available for URIs, names and values of different headers. The HTTP URI request and the header use 8 alphabets (plus or minus) to parse one HTTP request. These tables can be loaded into the same code and compared in a single alphabet specified by the user, a valid URI. If not, it’s different.
Customize the alphabets. Working with the ASCII table, we get a cheap feature: we use static tables, but nothing prevents asking the user which alphabet is available for URIs, names and values of different headers. The HTTP URI request and the header use 8 alphabets (plus or minus) to parse one HTTP request. These tables can be loaded into the same code and compared in a single alphabet specified by the user, a valid URI. If not, it’s different.Attacks
A few cases when this may be useful.SSRF attack with BlackHat'17 (“A New Era of SSRF”): http://foo@evil.com:80@google.com/- an unlikely ampersand symbol. In some applications it is used, in some not. But if you are not using it, you can exclude it from the valid alphabet and the attack will be blocked.RCE-attack: «effective is the perform command injection attacks like», BSides'16: User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... The User-Agent is a static header, but there are cases of an RCE attack when some come shellwith atypical characters for the User-Agent. We protect ourselves except for the dollar sign.Relative Path Overwrite . The last case is what Google had in 2016. Curly braces, colons, came to the URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. These are unlikely characters that can be excluded from the alphabet.strcasecmp ()
This is a fairly trivial code. We also compare strings of 32 bytes, two arrays each.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
We give the register only one line, because in the second we programmed the constants in our parser in lower case. Since we have significant comparisons, we subtract 128 from each byte (a trick from Hacker's Delight).We also compare the range of a valid character: whether we can register for this string or not, is it a letter or not. At the time of checking this, instead of two comparisons from a to z, we can use only one comparison (a trick from Hacker's Delight) and move to a constant.Performance strcasecmp ()
Tempesta is much faster than GLIBC, even the new version (18 or 19). The code strcasecmp()also uses AVX, but not the second version. AVX2 is faster, so Tempesta has faster code.
Linux kernel FPU
We use vector processor extensions - they are available in the kernel. Vector instructions are processed by the FPU processor module. This is not the main processor module, not the main registers, but quite voluminous.Therefore, there is optimization in Linux. If we go from the kernel to user space and back, we don’t save the context of the FPU registers (XMM, YMM, ZMM): we change the context of only the registers of the main processor module. It is assumed that the OS kernel does not work with the vector extension of the processor. But if you need it, for example, cryptography can do it, but need to use fpu_beginand fpu_endto save and restore the context of the FPU register:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
These are native macros that save and restore the state of the processor module , which is responsible for vector registers. These are fairly slow resources.AVX and SSE
Before the benchmarks of saving and restoring the FPU context, a couple of words about vector operations. Why sometimes it makes sense to work with assembler? Sometimes GCC generates suboptimal code. The problem is that on older processor models, there is a significant penalty from the transition from SSE to AVX. GCC has a new key vzeroupper- use it so that it does not generate this instruction vzeroupper, which clears the registers and removes this penalty.You need to use this instruction only if you are working with old code that was compiled for SSE by some third party. This is not our case and we can safely throw out these instructions.FPU
We have auto-vectorization in the processor. This means that in any user space code there will be vector operations. Any two processes in the system use vector processor extensions. When your process goes to the kernel and back, you do not waste time saving and restoring the vector state of the processor. But if you switch from one user space to another (context switch), then in addition to the fact that first level caches are disabled there, the context switch module on FPU begin / end also works poorly. The operation is quite expensive - a microbenchmark.In microbenchmarks, everything is always dramatic, but the operation is very expensive. Therefore, in user space, switch the context for a long time. In the kernel, we don’t have context switching, so everything is fast. We save and restore the vector processor only once for a sufficiently large set of packages.
Any two processes in the system use vector processor extensions. When your process goes to the kernel and back, you do not waste time saving and restoring the vector state of the processor. But if you switch from one user space to another (context switch), then in addition to the fact that first level caches are disabled there, the context switch module on FPU begin / end also works poorly. The operation is quite expensive - a microbenchmark.In microbenchmarks, everything is always dramatic, but the operation is very expensive. Therefore, in user space, switch the context for a long time. In the kernel, we don’t have context switching, so everything is fast. We save and restore the vector processor only once for a sufficiently large set of packages.Intelpocalypse
In the beginning, I showed a lookup table option for optimizing the switch code: a long process, enum, compile the switch table into an array and follow the double dereferencing of the pointer that jumps over this array. This is a scenario for a Specter attack that exploits speculative execution.Google has a good article on how double dereferencing of pointers in modern compilers is arranged right now (since the beginning of 2018). It does not work very well. If earlier in the register some address was stored and we went to this address, now we have a different code.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
How does it work? We “call” the function on l1, the process goes to this label and we make a hack: as if returning from the function (which is not), but rewrite the return address. When we do the instruction call, we place the return address, the current address on the stack, rewrite it with the necessary contents of the register and go to l1. But the processor, when its prefetcher is running, sees that there is a function, and then a barrier. Accordingly, everything will be slow - it throws out prefetching and we get rid of the Specter vulnerability. The code is slow, performance drops by 15%.The next relatively new attack is Meltdown.. It is specific to user space processes only. Very painful is reading kernel memory from user space. The attack is prevented by the Kernel Pate Table Isolation (KPTI), which compiles in new kernels by default. But KPTI is very expensive, up to 30-40% performance degradation ( as measured by MariaDB ).This is due to the fact that you no longer have lazy TLB optimization: the address space of the kernel and the processor is completely separated in different page tables (before, lazy TLB kept mapping the kernel space to the page table of each process). This is painful for user space, but not for Tempesta FW, which works completely in the kernel.Some useful links:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .