Hello again! In anticipation of the start of the course “Software Architect”, we prepared a translation of another interesting material.
The past few years have seen an increase in the popularity of microservice architecture. There are many resources that teach you how to implement it correctly, but quite often people talk about it as a silver pool. There are many arguments against the use of microservices, but the most significant of them is that this type of architecture is fraught with uncertain complexity, the level of which depends on how you manage the relationship between your services and teams. You can find a lot of literature that will explain why (perhaps) in your case, microservices will not be the best choice.We at letgo migrated from a monolith to microservices to satisfy the need for scalability, and immediately became convinced of its beneficial effect on the work of teams. When used correctly, microservices have given us several advantages, namely:- : , . ( ..) . ( ) Users.
- : , . . , , , , . .
-
Not all microservice architectures are event-driven. Some people advocate synchronous communication between services in this architecture using HTTP (gRPC, REST, etc.). At letgo, we try not to follow this pattern and asynchronously associate our services with domain events . Here are the reasons we do this:- : . , DDoS . , DDoS . , . .
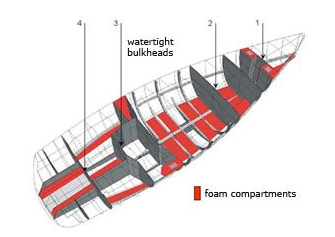
(bulkheads) – , , .- : . , , , , . , , API, , , , . Users , Chat.
Based on this, we at letgo try to adhere to asynchronous communication between services, and synchronous only works in such exceptional cases as feature MVP. We do this because we want each service to generate its own entities based on domain events published by other services in our Message Bus.In our opinion, success or failure in the implementation of microservice architecture depends on how you cope with its inherent complexity and how your services interact with each other. Dividing code without transferring the communication infrastructure to asynchronous will turn your application into a distributed monolith.
Event-driven architecture in letgo
Today I want to share an example of how we use domain events and asynchronous communication in letgo: our User entity exists in many services, but its creation and editing is initially processed by the Users service. In the database of the Users service, we store a lot of data, such as name, email address, avatar, country, etc. In our Chat service, we also have a user concept, but we do not need the data that the User entity from the Users service has. The user’s name, avatar and ID (link to the profile) are displayed in the list of dialogs. We say that in a chat there is only a projection of the User entity, which contains partial data. In fact, in Chat we are not talking about users, we call them “talkers”. This projection refers to the Chat service and is built on the events that Chat receives from the Users service.We do the same with listings. In the Products service, we store n pictures of each listing, but in the list view of dialogs we show one main picture, so our projection from Products to Chat requires only one picture instead of n.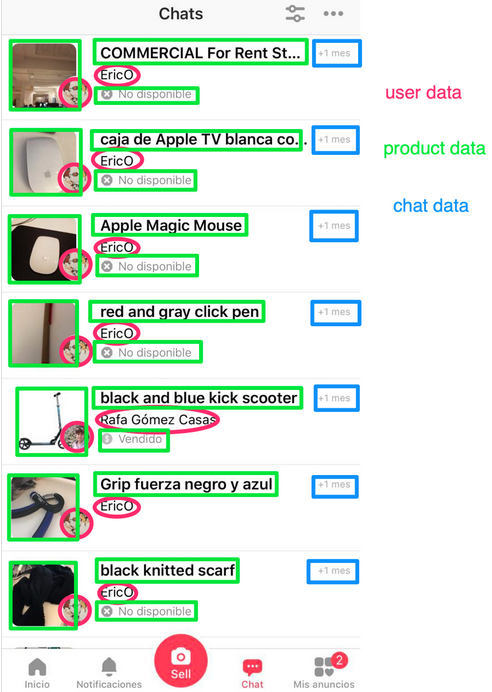 View a list of dialogs in our chat. It shows which specific service on the backend provides information.If you look at the list of dialogs again, you will see that almost all the data that we show is not created by the Chat service, but belongs to it, because the User and Chat projections are owned by Chat. There is a trade-off between accessibility and consistency of projections, which we will not discuss in this article, but I will only say that it is clearly easier to scale many small databases than one large one.
View a list of dialogs in our chat. It shows which specific service on the backend provides information.If you look at the list of dialogs again, you will see that almost all the data that we show is not created by the Chat service, but belongs to it, because the User and Chat projections are owned by Chat. There is a trade-off between accessibility and consistency of projections, which we will not discuss in this article, but I will only say that it is clearly easier to scale many small databases than one large one.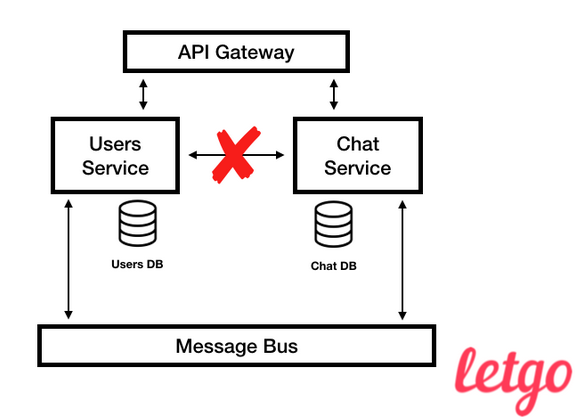 Simplified view of letgo architecture
Simplified view of letgo architectureAntipatterns
Some intuitive solutions often became mistakes. Here is a list of the most important antipatterns we encountered in our domain-related architecture.1. Thick eventsWe try to make our domain events as small as possible while not losing their domain value. We should have been careful when refactoring legacy codebases with large entities and switching to event architecture. Such entities can lead us to fat events, but since our domain events transformed into a public contract, we needed to make them as simple as possible. In this case, refactoring is best viewed from the side. To start, we design our events using the event storm techniqueand then refactor the service code to adapt it to our events.We should also be more careful with the “product and user” problem: many systems use product and user entities, and these entities, as a rule, pull all the logic behind them, and this means that all domain events are associated with them.2. Events as intentions Adomain event, by definition, is an event that has already occurred. If you publish something in a message bus to request what happened in some other service, you are most likely running an asynchronous command rather than creating a domain event. As a rule, we refer to past domain events: ser_registered , product_publishedetc. The less one service knows about the other, the better. Using events as commands links services and increases the likelihood that a change in one service will affect other services.3. Lack of independent serialization or compression. Thesystems of serialization and compression of events in our subject area should not depend on the programming language. You don’t even need to know in what language consumer services are written. That is why we can use Java or PHP serializers, for example. Let your team spend time discussing and choosing a serializer, because changing it in the future will be difficult and time-consuming. We at letgo use JSON, however there are many other serialization formats with good performance.4. Lack of standard structureWhen we started porting the letgo backend to an event-oriented architecture, we agreed on a common structure for domain events. It looks something like this:{
“data”: {
“id”: [uuid], // event id.
“type”: “user_registered”,
“attributes”: {
“id”: [uuid], // aggregate/entity id, in this case user_id
“user_name”: “John Doe”,
…
}
},
“meta” : {
“created_at”: timestamp, // when was the event created?
“host”: “users-service” // where was the event created?
…
}
}
Having a common structure for our domain events allows us to quickly integrate services and implement some libraries with abstractions.5. Lack of schema validationDuring serialization, we at letgo experienced problems with programming languages without strong typing.
{
“null_value_one”: null, // thank god
“null_value_two”: “null”,
“null_value_three”: “”,
}
A well-established testing culture that guarantees the serialization of our events, and an understanding of how the serialization library works, helps to cope with this. We at letgo are switching to Avro and the Confluent Schema Registry, which provides us with a single point of determining the structure of the events of our domain and avoids errors of this type, as well as obsolete documentation.6. Anemic domain eventsAs I said before, and as the name implies, domain events must have a value at the domain level. Just as we try to avoid the inconsistency of states in our entities, we must avoid this in domain events. Let's illustrate this with the following example: the product in our system has geolocation with latitude and longitude, which are stored in two different fields of the products table of the Products service. All products can be "moved", so we will have domain events to present this update. Previously, for this we had two events: product_latitude_updated and product_longitude_updated , which did not make much sense if you were not a rook on a chessboard. In this case, the product_location_updated events will make more sense.or product_moved . A rook is a chess piece. It used to be called a tour. A rook can only move vertically or horizontally through any number of unoccupied fields.7. Lack of debugging toolsWe at letgo produce thousands of domain events per minute. All these events become an extremely useful resource for understanding what is happening in our system, registering user activity, or even reconstructing the state of a system at a specific point in time using event search. We need to skillfully use this resource, and for this we need tools to check and debug our events. Requests like “show me all the events generated by John Doe in the last 3 hours” can also be useful in detecting fraud. For these purposes, we have developed some tools on ElasticSearch, Kibana and S3.8. Lack of event monitoringWe can use domain events to test the health of the system. When we deploy something (which happens several times a day depending on the service), we need tools to quickly verify the correct operation. For example, if we deploy a new version of the Products service on production and see a decrease in the number of product_published events20%, it is safe to say that we broke something. We are currently using InfluxDB, Grafana, and Prometheus to achieve this with derived functions. If you recall the course of mathematics, you will understand that the derivative of the function f (x) at the point x is equal to the tangent of the tangent angle drawn to the graph of the function at this point. If you have a function for publishing the speed of a specific event in a subject area and you take a derivative from it, you will see the peaks of this function and you can set notifications based on them. Using these notifications, you can avoid phrases such as “warn me if we publish less than 200 events per second for 5 minutes” and focus on a significant change in the speed of publication.
A rook is a chess piece. It used to be called a tour. A rook can only move vertically or horizontally through any number of unoccupied fields.7. Lack of debugging toolsWe at letgo produce thousands of domain events per minute. All these events become an extremely useful resource for understanding what is happening in our system, registering user activity, or even reconstructing the state of a system at a specific point in time using event search. We need to skillfully use this resource, and for this we need tools to check and debug our events. Requests like “show me all the events generated by John Doe in the last 3 hours” can also be useful in detecting fraud. For these purposes, we have developed some tools on ElasticSearch, Kibana and S3.8. Lack of event monitoringWe can use domain events to test the health of the system. When we deploy something (which happens several times a day depending on the service), we need tools to quickly verify the correct operation. For example, if we deploy a new version of the Products service on production and see a decrease in the number of product_published events20%, it is safe to say that we broke something. We are currently using InfluxDB, Grafana, and Prometheus to achieve this with derived functions. If you recall the course of mathematics, you will understand that the derivative of the function f (x) at the point x is equal to the tangent of the tangent angle drawn to the graph of the function at this point. If you have a function for publishing the speed of a specific event in a subject area and you take a derivative from it, you will see the peaks of this function and you can set notifications based on them. Using these notifications, you can avoid phrases such as “warn me if we publish less than 200 events per second for 5 minutes” and focus on a significant change in the speed of publication.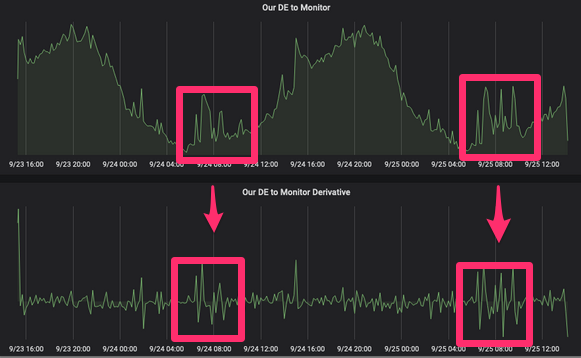 Something strange happened here ... Or maybe it's just a marketing campaign9. The hope that everything will be fineWe are trying to create sustainable systems and reduce the cost of their restoration. In addition to infrastructure issues and the human factor, one of the most common things that can affect event architecture is the loss of events. We need a plan with which we can restore the correct state of the system by re-processing all the events that were lost. Here, our strategy is based on two points:
Something strange happened here ... Or maybe it's just a marketing campaign9. The hope that everything will be fineWe are trying to create sustainable systems and reduce the cost of their restoration. In addition to infrastructure issues and the human factor, one of the most common things that can affect event architecture is the loss of events. We need a plan with which we can restore the correct state of the system by re-processing all the events that were lost. Here, our strategy is based on two points:- : , « , », - , . letgo Data, Backend.
- : - . , , , message bus . – , , . , user_registered Users, , MySQL, user_id . user_registered, , . , , - MySQL ( , 30 ). -, DynamoDB. , , , . , , , , .
10. Lack of documentation on domain eventsOur domain events have become our public interface for all systems on the backend. Just as we document our REST APIs, we need to document domain events as well. Any employee of the organization should be able to view updated documentation for each domain event published by each service. If we use schemes for checking domain events, they can also be used as documentation.11. Resistance to consumption of own eventsYou are allowed and even encouraged to use your own domain events to create projections in your system, which, for example, are optimized for reading. Some teams resisted this concept, because they were confined to the concept of consumption of other people's events.See you on the course!