Hundreds, thousands, and in some services, millions of queues, through which a huge amount of data passes, are spinning under the hood of our product. All this must be processed in some magical way and not be shot. In this post I will tell you what architectural approaches we use at home, having a fairly modest technology stack and not having a small data center in our “pantry”.
What do we have?
So, on the one hand, we have a well-known technology stack: Nginx, PHP, PostgreSQL, Redis. On the other hand, tens of thousands of events occur in our system every minute, and in the peak it can reach hundreds of thousands of events. In order to make it clear what these events are, and how we should respond to them, I will make a small product digression, after which I will tell you how we developed the Event-based automation system.ManyChat is a platform for marketing automation. The owner of the Facebook page can connect it to our platform and configure the automation of interaction with his subscribers (in other words, create a chat bot). Automation usually consists of many chains of interactions that may not be interconnected. Within these automation chains, certain actions can occur with the subscriber, for example, assigning a specific tag in the system, or assigning / changing the value of a field in a subscriber’s card. This data further allows you to segment the audience and build a more relevant interaction with the subscribers of the page.Our customers really wanted Event-based automation - the ability to customize the execution of an action when a specific event is triggered within the subscriber (for example, tagging).Since a trigger event can work from different automation chains, it is important that there is a single point of configuration for all Event-based actions on the client side, and on our processing side there should be a single bus that processes the change of the subscriber context from different automation points.In our system, there is a common bus through which all events occurring with subscribers pass. This is more than 500 million events per day. Their processing is rather delicate - this is a record in the data warehouse, so that the page owner has the opportunity to historically see everything that happened to his subscribers.It would seem that in order to implement an Event-based system we already have everything, and it is enough for us to integrate our business logic into the processing of a common event bus. But we have certain requirements for our new system:- We do not want to get degraded performance in processing the main event bus
- It is important for us to maintain the order of processing messages in the new system, as this may be tied to the business logic of the client who sets up the automation
- Avoid the effect of noisy neighbors when active pages with a large number of subscribers clog the queue and block the processing of events of "small" pages
If we integrate the processing of our logic into the processing of a common event bus, then we will get a serious degradation in performance, since we will have to check each event for compliance with the configured automation. As part of the automation setup, certain filters can be applied (for example, start automation when an event is triggered only for female clients older than 30 years). That is, when processing events in the main bus, a huge amount of extra requests to the database will be processed, and also a rather heavy-weight logic will start comparing the current context of the subscriber with the automation settings. This option does not suit us, so we went to think further.
Organization of a cascade of queues
Since our business logic associated with the event-based system is very well separable from the logic for processing events from the main bus, we decide to put the types of events we need from the shared bus in a separate queue for further processing in a separate data stream. Thus, we remove the problem associated with degradation of performance in processing the main event bus.At the same stage, we decide what it would be cool to transfer events to the next cascade queue to put these events in separate queues for each bot. Thus, isolating the activity of each bot with the framework of its turn, which allows us to solve the problem associated with the effect of noisy neighbors.Our data flow diagram now looks like this: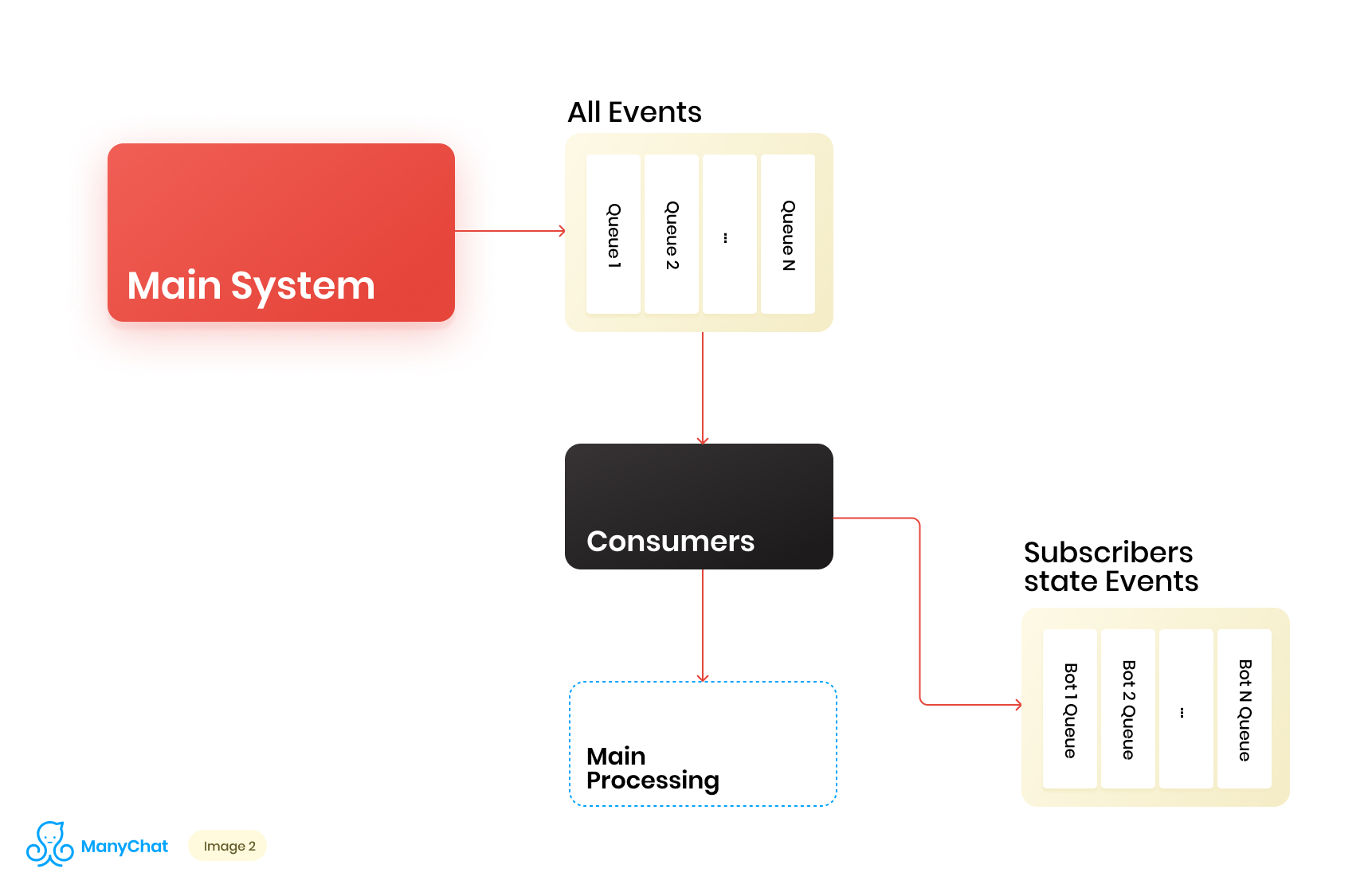 However, in order for this scheme to work, we need to solve the issue of processing new queues.There are more than 1 million connected pages (bots) on our platform, which means that potentially we can get ~ 1 million queues in our scheme, only at the level of the event-based layer. From a technical point of view, this is not scary for us. As the queue server, we use Redis with its standard data types, such as LIST, SORTED SET, and others. This means who each queue is the standard data structure for Redis in RAM, which can be created or deleted on the fly, which allows us to easily and flexibly operate a huge number of queues in our system. I’ll talk more deeply about using Redis as a queue server with technical details in a separate post, but for now let's get back to our architecture.It is clear that each bot has a different activity, and that the probability of getting 1 million queues in the “need to process now” state is extremely small. But at one point in time, it is quite possible that we will have a couple of tens of thousands of active queues that require processing. The number of these queues is constantly changing. These queues themselves also change, some of them are subtracted completely and deleted, some of them are dynamically created and filled with events for processing. Accordingly, we need to come up with an effective way to handle them.
However, in order for this scheme to work, we need to solve the issue of processing new queues.There are more than 1 million connected pages (bots) on our platform, which means that potentially we can get ~ 1 million queues in our scheme, only at the level of the event-based layer. From a technical point of view, this is not scary for us. As the queue server, we use Redis with its standard data types, such as LIST, SORTED SET, and others. This means who each queue is the standard data structure for Redis in RAM, which can be created or deleted on the fly, which allows us to easily and flexibly operate a huge number of queues in our system. I’ll talk more deeply about using Redis as a queue server with technical details in a separate post, but for now let's get back to our architecture.It is clear that each bot has a different activity, and that the probability of getting 1 million queues in the “need to process now” state is extremely small. But at one point in time, it is quite possible that we will have a couple of tens of thousands of active queues that require processing. The number of these queues is constantly changing. These queues themselves also change, some of them are subtracted completely and deleted, some of them are dynamically created and filled with events for processing. Accordingly, we need to come up with an effective way to handle them.Processing a huge pool of queues
So we have a bunch of queues. At each point in time, there may be a random amount. An important condition for processing each queue, which was mentioned at the beginning of his post, is that events within each page should be processed strictly sequentially. This means that at one point in time, each queue cannot be processed by more than one worker in order to avoid competitive problems.But to make the ratio of queues to handlers 1: 1 is a dubious task. The number of queues is constantly changing, both up and down. The number of running handlers is also not infinite, at least we have a limitation on the part of the operating system and hardware, and we would not want workers to stand idle on empty queues. To solve the problem of interaction between handlers and queues, we implemented a round robin system to process our queue pool.And here the control line came to our aid. When the event is forwarded from the shared bus to the event-based queue of a particular bot, we also put the identifier of this bot queue in the control queue. The control queue stores only the identifiers of the queues that are in the pool and need to be processed. Only unique values are stored in the control queue, that is, the same bot queue identifier will be stored in the control queue only once, regardless of how many times it is written there. On Redis, this is implemented using the SORTED SET data structure.Further, we can distinguish a certain number of workers, each of whom will receive from the control queue his identifier of the bot queue for processing. Thus, each worker will independently process the chunk from the queue assigned to him, after processing the chunk, return the identifier of the processed queue to the control, thereby returning it to our round robin. The main thing is not to forget to provide the whole thing with locks, so that two workers could not process the same bot queue in parallel. This situation is possible if the bot identifier enters the control queue when it is already being processed by the worker. For locks, we also use Redis as the key: value store with TTL.When we take a task with a bot queue identifier from the control queue, we put a TTL lock on the queue taken and begin processing it. If the other consumer takes the task with the queue that is already being processed from the control queue, he will not be able to lock, return the task to the control queue and receive the next task. After processing the bot queue by the consumer, he removes the lock and goes to the control queue for the next task.The final scheme is as follows:
When the event is forwarded from the shared bus to the event-based queue of a particular bot, we also put the identifier of this bot queue in the control queue. The control queue stores only the identifiers of the queues that are in the pool and need to be processed. Only unique values are stored in the control queue, that is, the same bot queue identifier will be stored in the control queue only once, regardless of how many times it is written there. On Redis, this is implemented using the SORTED SET data structure.Further, we can distinguish a certain number of workers, each of whom will receive from the control queue his identifier of the bot queue for processing. Thus, each worker will independently process the chunk from the queue assigned to him, after processing the chunk, return the identifier of the processed queue to the control, thereby returning it to our round robin. The main thing is not to forget to provide the whole thing with locks, so that two workers could not process the same bot queue in parallel. This situation is possible if the bot identifier enters the control queue when it is already being processed by the worker. For locks, we also use Redis as the key: value store with TTL.When we take a task with a bot queue identifier from the control queue, we put a TTL lock on the queue taken and begin processing it. If the other consumer takes the task with the queue that is already being processed from the control queue, he will not be able to lock, return the task to the control queue and receive the next task. After processing the bot queue by the consumer, he removes the lock and goes to the control queue for the next task.The final scheme is as follows: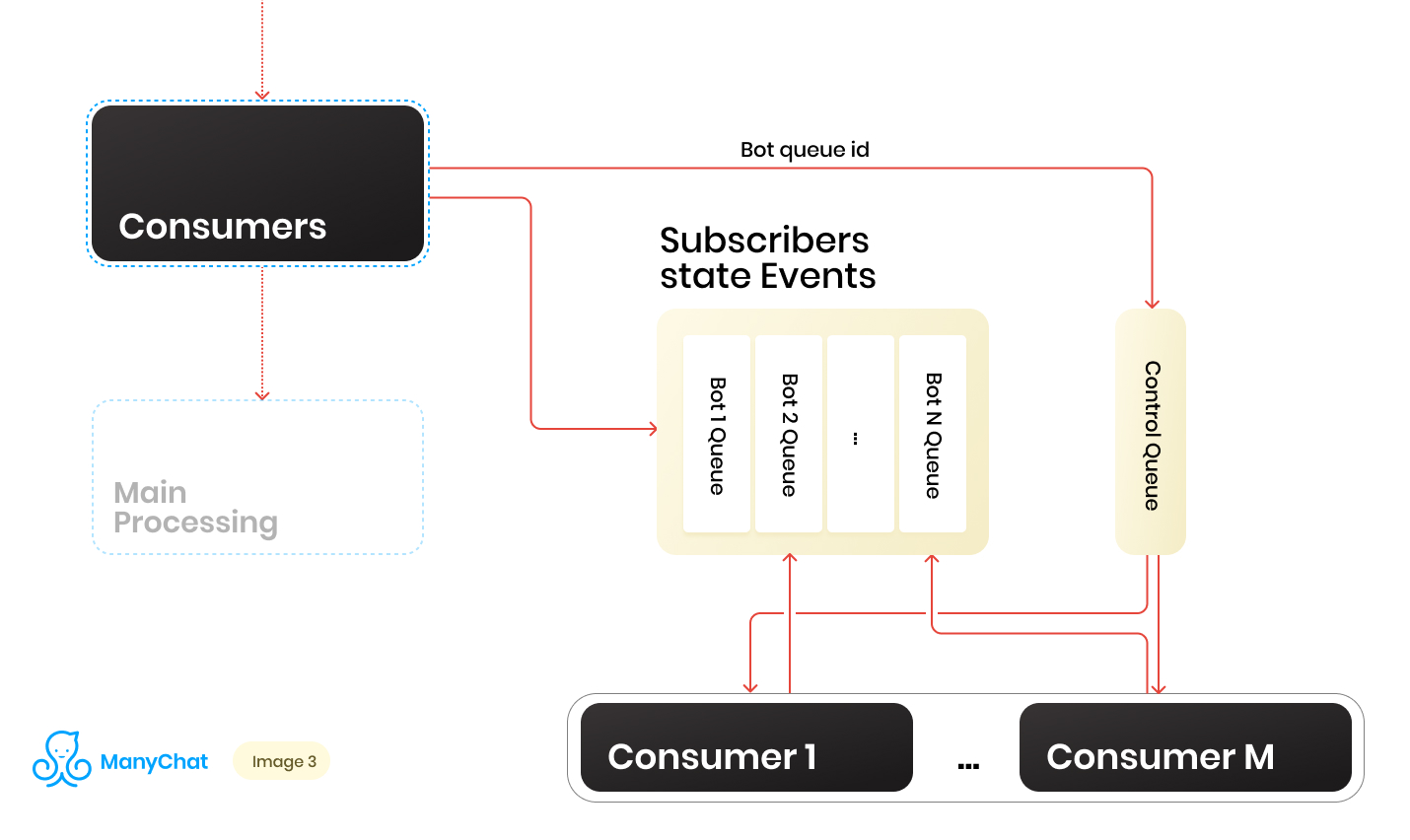 As a result, with the current scheme, we solved the main identified problems:
As a result, with the current scheme, we solved the main identified problems:- Performance degradation in the main event bus
- Event Handling Violation
- The effect of noisy neighbors
How to deal with dynamic load?
The scheme is working, but in it we have a fixed number of consumers for a dynamic number of queues. Obviously, with this approach, we will sag in the processing of queues every time their number increases sharply. It seems that it would be nice for our workers to dynamically start or extinguish when needed. It would also be nice if this doesn’t greatly complicate the process of rolling out new code. At such moments, the hands are very itchy to go and write your process manager. In the future, we did just that, but this story is different.Thinking, we decided, why not once again use all familiar and familiar tools. So we got our internal API, which worked on a standard bundle of NGINX + PHP-FPM. As a result, we can replace our fixed pool of workers with APIs, and let NGINX + PHP-FPM resolve and manage the workers ourselves, and it’s enough for us to have between the control queue and our internal API only one control consumer who will send queue identifiers to our API to processing, and the queue itself will be processed in the worker raised by PHP-FPM.The new scheme was as follows: It looks beautiful, but our control consumer works in one thread, and our API works synchronously. This means that the consumer will hang every time while PHP-FPM is grinding a queue. This does not suit us.
It looks beautiful, but our control consumer works in one thread, and our API works synchronously. This means that the consumer will hang every time while PHP-FPM is grinding a queue. This does not suit us.Making our API asynchronous
But what if we could send a task to our API, and let it thresh business logic there, and our control consumer will follow the next task in the control queue, after which it will be pulled back into the API, and so on. No sooner said than done.The implementation takes a couple of lines of code, and the Proof of Concept looks like this:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
In the dropFPMSession () method, we break the connection with the client, giving it a response of 200, after which we can perform any heavy logic in postprocessing. The client in our case is the control consumer. It is important for him to quickly scatter tasks from the control queue into processing on the API and to know that the task has reached the API.Using this approach, we took off a bunch of headaches associated with the dynamic control of consumers and their automatic scaling.Scalable further
As a result, the architecture of our subsystem began to consist of three layers: Data Layer, Processes and Internal API. At the same time, information passes through all data streams about which bot the processed event / task belongs to. Obviously, we can use our key / bot identifier for sharding, while continuing to scale our system horizontally.If we imagine our architecture as a solid unit, it will look like this: Having increased the number of such units, we can put a thin balancer in front of them, which will throw our events / tasks into the necessary units, depending on the sharding key.
Having increased the number of such units, we can put a thin balancer in front of them, which will throw our events / tasks into the necessary units, depending on the sharding key. Thus, we get a large margin for horizontal scaling of our system.When implementing business logic, you should not forget about the thread safety concept, otherwise you can get unexpected results.Such a scheme with cascades of queues and the removal of heavy business logic into asynchronous processing has been used in several parts of the system for more than two years. The load during this time for each of the subsystems has grown tens of times, and the proposed implementation allows us to easily and quickly scale. At the same time, we continue to work on our main stack, without expanding it with new tools / languages and without increasing, thereby overhead the introduction and support of new tools.
Thus, we get a large margin for horizontal scaling of our system.When implementing business logic, you should not forget about the thread safety concept, otherwise you can get unexpected results.Such a scheme with cascades of queues and the removal of heavy business logic into asynchronous processing has been used in several parts of the system for more than two years. The load during this time for each of the subsystems has grown tens of times, and the proposed implementation allows us to easily and quickly scale. At the same time, we continue to work on our main stack, without expanding it with new tools / languages and without increasing, thereby overhead the introduction and support of new tools.