In 2019, the CPDoS Cache Poisoned Denial of Service) vulnerability was discovered on the CDN network, which allows poisoning the HTTP cache of the CDN provider and causing a denial of service. The vulnerability has not yet gathered a lot of hype, as it has not been seen in real attacks. But I want to talk about one of the cache poisoning methods separately. HTTP Method Override.If other variants of exploiting the vulnerability in one way or another rely on bugs or features of request modification by an intermediary, then the Method Override variant is based on the tactic of the same name, which is not part of the HTTP standard, carries with it additional problems, and which arose and spread due to careless relationship to security. Here we will consider it.Short about CPDoS if you missed it, URI method .
, , , , - . — - - -, , - , . , .
, . , ,
-. - , , .
Limit the client, less can - less will break
The very need to override the method in the request arose due to the fact that some Web Application Firewalls and HTTP client implementations were very limited and did not allow the execution of methods other than GET and POST. The problem is not that it was an implementation restriction, but that it was an intentional restriction of HTTP clients by a security policy.It is clear that everything was carried out well-intentioned to cut off the cramped traffic, non-standard for ordinary HTTP clients. But in pursuit of security, all methods except GET and POST were cut off. Perhaps because these are the only methods that are not optional and required for general purpose servers.Why it was required to introduce such a strict restriction is not clear. Yes, attacks with the introduction of various characters in order to confuse the parser are just the hobby of text protocols. But you could allow a little more methods, for example, take at least those that are described in the standard itself or registered with IANA . It was not worth it to completely remove the method check, but you could dial a number of the most popular methods and exclude from them those that change the interaction protocol and break the work with connections on the proxy server (CONNECT). But no, it turned out a security policy that introduced unnecessary restrictions and prohibitions for customers.And the customers were limited to the wrong ones. They wanted to limit the variability of messages from HTTP clients, and limited the clients that these WAFs protected, the end application servers and their developers. Now, developers were left with only two methods that were not always enough to describe the logic of the HTTP client.Constraints are created to overcome them.
It was to be expected that this excessive restriction would sooner or later begin to interfere with web developers. The irony is that it’s so easy to not get rid of such WAFs. Especially when they are with customers or providers. To challenge other people's security policies is a disastrous matter.Due to the flexibility of HTTP, it is not difficult to circumvent this limitation; just add something to the request where you could override the method. Strict WAF will only check the method in the Request Line (the first line of the request) and will be happy to see an approved GET or POST there. And the backend will be able to parse the added element and extract the real method from it.You can google a bunch of articles, really a bunchabout how bad proxies broke REST applications, and how the authors had to pass the real method in a separate header. In all of them, they suggest that you enter approximately the same header (X-HTTP-Method, X-HTTP-Method-Override or X-Method-Override - the spelling varies somewhat) to indicate an overridden method. Very, very rarely can one find references that can be used for the same purpose query-component URI.What is missing from these articles is the Security Considerations section. And they just are.Is method overriding safe?
Sometimes web application developers forget that between the client and the server there may be intermediate participants who interact over the HTTP protocol: proxies, provider web caches, CDN and WAF. The proliferation of TLS greatly reduces the chance of an intermediate participant between the client and server. Most likely the only proxy between the client and the backend will be its own server with Nginx. And such a configuration is easy enough to test on typical scenarios before release.But we are moving into the age of CDN, and more and more applications will be hiding behind CDNs that read and manipulate user traffic. Backends directly almost never serve users, and hide behind reverse proxies to increase responsiveness and performance. Therefore, you will have to remember how overriding a method can affect the processing of a request on a mediation server.The attacks I want to talk about are primarily applicable to HTTP / 1.1. HTTP / 2 in some way inherits the behavior of the old standard, in some ways it goes its own way, so the applicability of each attack to the new standard will be considered separately.Cache attacks
Most often, intermediate servers do not take into account method overrides, do not check the headers of the X-HTTP-Method-Override family, and work with the request using its main method from the Request Line. And since the overridden method is not included in the key to search for a request in the cache (method + URI), such servers cannot distinguish POST from POST + X-HTTP-Method-Override: DELETE. This means that you cannot allow caching of any requests to a certain URI if the backend can monitor and execute overridden methods.The CPDoS document has a good example of what happens if you cache such a request. When an attacker disguises a POST request as a GET request, the proxy does not recognize the substitutions and treats the request as a legitimate GET request. The backend, however, recognizes the overridden method and executes the verb described in the X-HTTP-Method-Override - POST header. Since the POST method is not defined for the destination URI, the server generates an error. Further, the backend response is stored in the cache as a response to the original method - GET. Now any next GET request for the same URI will return a cached error.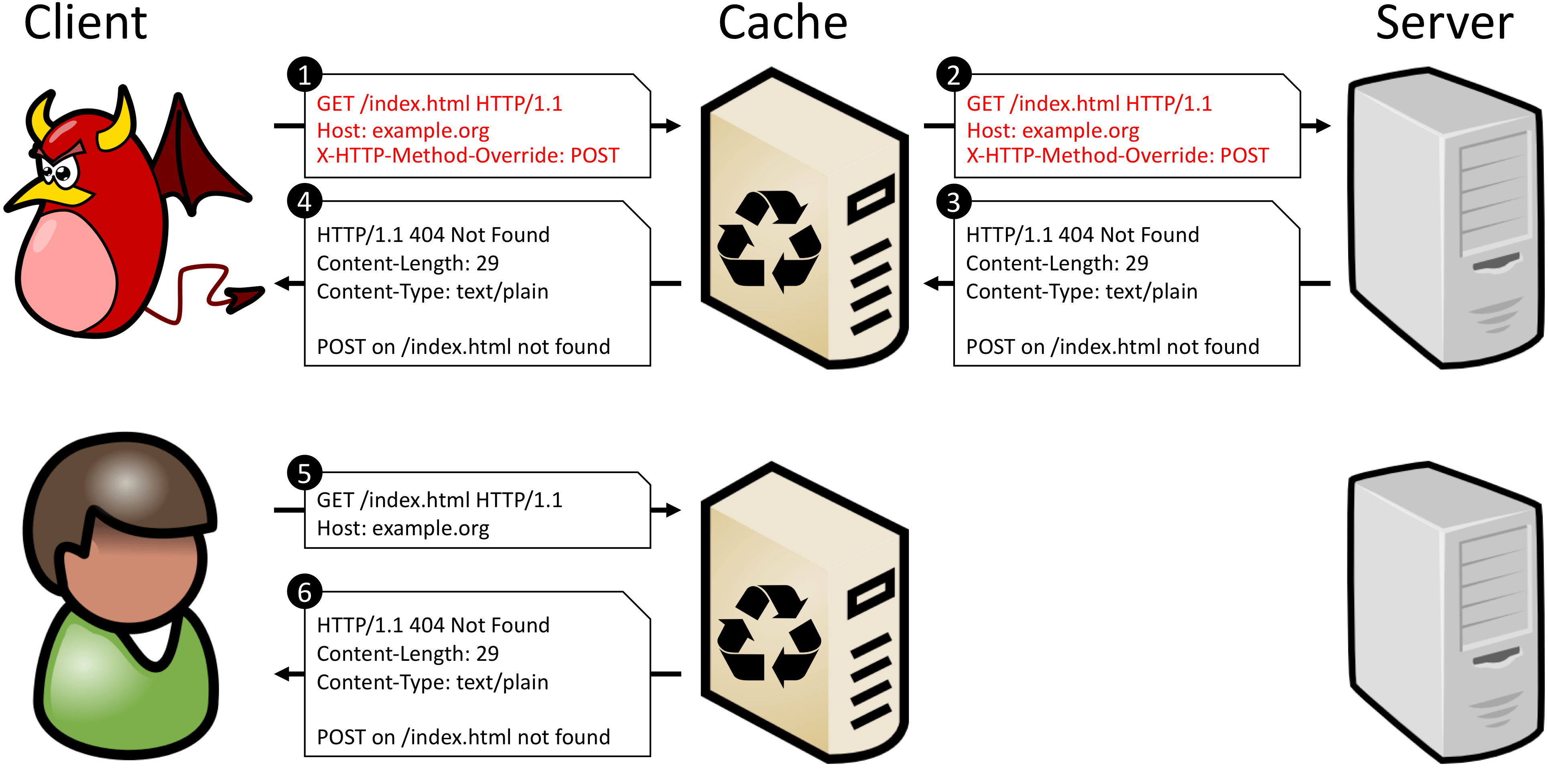
POST /some-uri HTTP/1.1
X-HTTP-Method-Override: DELETE
↓ ↓ ↓
POST /some-uri?method=DELETE HTTP/1.1
Now requests with different methods look different for the cache, as they get different keys. Some proxies prefer not to cache responses to requests containing the query component in the URI. But this will only affect caching efficiency. This method always solves problems with incorrect caching.Another way is to leave the method override in a separate header, but enter a secondary key to find the answer in the cache. This is possible with the Vary header. When servicing the request, the server will repeat the header with the method override and reflect the name of this header in the Vary header. Then, at the following requests, the cache server will use the value of the overridden method as a secondary key when searching for a request in the cache.This method works if the intermediate server can work with secondary keys. This is usually the case, but the proxy trust level, which cuts all methods except GET and POST, is usually lower and it is better to check this.Overriding a method through any entity inside the request body has exactly the same drawbacks as overriding through an additional header - it is out of the cache's visibility.Message Queuing Attacks
Even if cache attacks are closed, that's not all. An attacker by overriding a method may try to change the framing of the response and thereby violate the correspondence of the request-response pairs for other clients. Or force the server side of the application to process the same request several times.The most important thing that is required for this is an intermediate server operating in reverse-proxy mode. That is, any caching or CDN server. Such a proxy supports a relatively small number of connections to the backend, and multiplies requests from many clients in each of them. This is necessary both to take the load of supporting a large number of client connections from the backends to the proxy server, and to balance the load between the backends. Termination of TLS connections also occurs on the proxy, client connections are never connected directly to the backend.Since now requests from different clients will be in the same connection between the backend and the proxy, it is necessary to maintain a clear correspondence between the request-response pairs. Most proxies do not pipeline(pipelines) requests to the backend and works with it in the request-response mode. The request-response mode is simpler and subject to virtually one threat - connection blocking. If you make the connection hang on a single request-response pair, you can cause a delay or even a refusal to process the following requests (for example, if you succeed in overflowing the queues of requests for proxies).More productive proxies pipeline requests to the backend - this allows you to send a packet of requests to the server right away and wait for their execution. Performance is higher, but there are more threats. Firstly, the problem of head-of-line blocking does not disappear anywhere - even if the backend can rake the query pipeline and execute them in parallel, they cannot be sent if the first of them hangs. Secondly, if you break the response framing, you can confuse the proxy and break the correspondence of the request-response pairs, then some clients may receive other people's answers, or at least achieve an instant connection closure with the backend.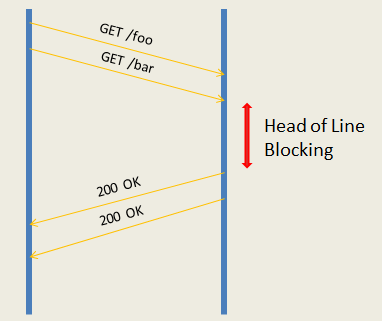

Automatic spam replay
I said above that requests of the form GET + X-HTTP-Method-Override: PATCH from respectable clients are bad. And this is bad because methods have two properties: security and idempotency . Security means that the method does not change the state of the server (read-only), and does not interest us in the context of this article. The idempotency of the method ensures that repeated request has the same effect as a single request. You can draw an analogy: (a = 5)- idempotent request, and (a += 2) - non-idempotent.This property is what interests us. If the connection between the client and server suddenly breaks, the client, knowing that the method is idempotent, can automatically resend the request. Proxies behave the same way. Non-idempotent requests are not automatically repeated because it is not known how they affect the server and what the client will receive in the end. I think everyone knows the pop-ups in the browser: "Are you sure you want to repeat the request?"If you mask a non-idempotent method as idempotent, then in case of errors it will not be discarded, but will be redirected to the server again. Even if the client will consider the real request method before resubmitting the request, this will not help much, because the proxy server is not aware of the method override and will repeat such requests.If an attacker is able to force disconnections between the backend and clients, he will be able to cause the server to repeatedly execute non-idempotent requests and reduce the reliability and predictability of the application. In the previous section, we just found a way how you can cause connection breaks with the same method override. Although it must be remembered that the Internet is an unreliable network, by definition, and the application itself is in danger.To protect against this attack, you should use only methods that do not add new properties to the request as a transport. POST is a good candidate, because by default it is neither safe nor idempotent.That ancient HTTP / 1.1, as with HTTP / 2?
HTTP / 2 has changed the way requests are transported between nodes, but it has not changed their lexical meaning. Therefore, in those attacks that relate to the request value, HTTP / 2 behaves the same. But “transport” attacks are not reproduced, as they are already taken into account in the standard.Attacks on the cache are reproduced in a similar manner to HTTP / 1, and the protection is similar.Message Queuing attacks are not applicable to HTTP / 2. The HTTP messages in it are divided into separate frames, with separate frame headers that explicitly determine the length and end of the message. As if the attacker would not change the method and modify the HTTP headers, this will not affect the message frame. Stealing the answer will fail.Attacks on the repetition of non-idempotent messages is applicable even taking into account the fact that in HTTP / 2 there arenotification mechanism of the last processed request . In HTTP / 2, multiple requests are multiplied in the same TCP and thus create flows . Each thread has its own number. If the HTTP / 2 server disconnects, it can indicate the number of the last processed request in GOAWAY. Requests with a higher number are always safe to redirect; requests with a lower number are only redirected if they are idempotent. If a request with an overridden method looks idempotent for a proxy server, then the proxy will forward it to the server.How to safely override a method
The short answer is no way. It is better not to use method overrides at all. And completely disable support in the backend, if any. Block HTTP clients overriding methods. Refuse proxy / WAF, which cuts the "extra" methods.If you have to somehow live with the redefinition of the method, then to prevent enough edits to the backend. First, it is advisable to override the method only through the query component of the URI.Secondly, there should be a white list of the transformation of methods: which are acceptable as a "transport" and which are the resulting ones. There should not be generalized transformation functions when any method can be overridden by any. The “transport” method should not have the properties of security and idempotency if the resulting one does not. Dangerous transformations should be prohibited, the same replacement GET -> HEAD.Do I need to patch a problem proxy / WAF?
If the proxy implements only the GET and POST methods, and blocks the others for one reason or another, definitely yes. You can optimize it primarily for GET and POST, but blocking other methods is a bad idea. Which still creates a gulf of distrust in the product: if basic things are blocked, what to expect from the implementation of more complex problems?If you are worried about the security of protected web applications, then it might be worthwhile to secure applications from unsafe method override policies. Of course, in the general case, without knowing the details of the web application implementation, it is impossible to completely protect the application from incorrect overrides, but you can partially cover users who simply do not know about the problem. It is necessary not only to protect against poisoning your own cache, but also to make it possible to enable or disable overriding for each protected application. To do this, keep track of commonly used headers.X-HTTP-Method, X-HTTP-Method-Override and X-Method-Override. Tracking the redefinition in the query component of the URI does not make much sense: the cache does not poison such a request, and query can be very long and have a completely arbitrary format.?
Security developers, do not limit application developers to security policies. They will still find how to get around them, and the more flexible the protocol, the easier it is to do it. It is very likely that they will not kick you and wait until you make the restrictions more reasonable, but simply bypass them.If you figured out how to implement something in the protocol, but it overrides or runs counter to one of the key concepts of the standard, then compatibility and security problems will surely arise. And they need to be covered at the same time as the decision. Everytime. If you met such advice and did not see security warnings, then do not duplicate the advice all over the Internet. Always be critical of the decision and figure out what might go wrong .Instead of an afterword
What proxy server problems did you encounter? What had to be circumvented and how?