 In October last year, the first Yandex Yandex Scale cloud conference was held. It announced the launch of many new services, including Yandex IoT Core, which allows you to exchange data with millions of IoT devices.In this article, I’ll talk about why Yandex IoT Core is needed and how it works, as well as how it can interact with other Yandex. Cloud services. You will learn about the architecture, the intricacies of the interaction of components and the features of the implementation of functionality - all this will help you optimize the use of these services.First, let us recall the main advantages of public clouds and PaaS - reducing development time and costs, as well as support and infrastructure costs, which is also relevant for IoT projects. But there are a few less obvious useful features that you can get in the cloud. This effective scaling and fault tolerance are important aspects when working with devices, especially in projects for critical information infrastructure.Effective scaling is the ability to freely increase or decrease the number of devices without experiencing technical problems and seeing a predictable change in the cost of the system after the changes.Fault tolerance is the confidence that services are designed and deployed in such a way as to ensure the highest possible performance even in the event of a failure of some resources.Now let's get into the details.
In October last year, the first Yandex Yandex Scale cloud conference was held. It announced the launch of many new services, including Yandex IoT Core, which allows you to exchange data with millions of IoT devices.In this article, I’ll talk about why Yandex IoT Core is needed and how it works, as well as how it can interact with other Yandex. Cloud services. You will learn about the architecture, the intricacies of the interaction of components and the features of the implementation of functionality - all this will help you optimize the use of these services.First, let us recall the main advantages of public clouds and PaaS - reducing development time and costs, as well as support and infrastructure costs, which is also relevant for IoT projects. But there are a few less obvious useful features that you can get in the cloud. This effective scaling and fault tolerance are important aspects when working with devices, especially in projects for critical information infrastructure.Effective scaling is the ability to freely increase or decrease the number of devices without experiencing technical problems and seeing a predictable change in the cost of the system after the changes.Fault tolerance is the confidence that services are designed and deployed in such a way as to ensure the highest possible performance even in the event of a failure of some resources.Now let's get into the details.IoT Script Architecture
First, let's see what the overall architecture of the IoT script looks like. Two large parts can be distinguished in it:
Two large parts can be distinguished in it:- The first is the delivery of data to the storage and the delivery of commands to devices. When you build an IoT system, this task must be solved in any case, no matter what project you do.
- The second is working with received data. Everything is similar to any other project based on the analysis and visualization of data sets. You have a repository with an initial array of information, working with which will allow you to realize your task.
The first part is approximately the same in all IoT systems: it is built on general principles and fits into a common scenario suitable for most IoT systems.The second part is almost always unique in terms of the functions performed, although it is built on standard components. At the same time, without a high-quality, fault-tolerant and scalable system of interaction with hardware, the effectiveness of the analytical part of the architecture is reduced to almost zero, because there is simply nothing to analyze.That is why the Yandex.Cloud team decided first of all to concentrate on building a convenient ecosystem of services that would quickly, efficiently and reliably deliver data from devices to storages, and vice versa - send commands to devices. To solve these problems, we are working on the functionality and integration of Yandex IoT Core, Yandex Functions and data storage services in the Cloud:
To solve these problems, we are working on the functionality and integration of Yandex IoT Core, Yandex Functions and data storage services in the Cloud:- Yandex IoT Core service is a multi-tenant fail-safe scalable MQTT broker with a set of additional useful functions.
- Yandex Cloud Functions service is a representative of the promising serverless direction and allows you to run your code as a function in a safe, fault-tolerant and automatically scalable environment without creating and maintaining virtual machines.
- Yandex Object Storage is an effective storage of large data arrays and is very suitable for “historical” archive records.
- , , Yandex Managed Service for ClickHouse, «» . «» , , , .
If data storage and analysis services are “general-purpose” services that have already been written about a lot, then Yandex IoT Core and its interaction with Yandex Cloud Functions usually cause a lot of questions, especially for people who are just starting to understand Internet of things and cloud technologies. And since these services provide fault tolerance and scaling of work with devices, we will first see what they have under the hood.How Yandex IoT Core works
Yandex IoT Core is a specialized platform service for two-way data exchange between the cloud and devices running the MQTT protocol. In fact, this protocol has become the standard for transferring data to IoT. It uses the concept of named queues (topics), where, on the one hand, you can write data, and on the other hand, receive them asynchronously by subscribing to events of this queue.The Yandex IoT Core service is multi-tenant, which means one single entity that is accessible to all users. That is, all devices and all users interact with the same service instance.This allows, on the one hand, to ensure uniformity of work for all users, on the other hand, effective scaling and fault tolerance, in order to maintain a connection with an unlimited number of devices and process an unlimited amount of data both in volume and speed.It follows that the service must have both redundancy mechanisms and the ability to flexibly manage the resources used - in order to respond to load changes.In addition, multi-tenancy requires a special logic of sharing access rights to MQTT topics.Let's see how this is implemented.Like many other Yandex.Cloud services, Yandex IoT Core is logically divided into two parts - Control Plane and Data Plane: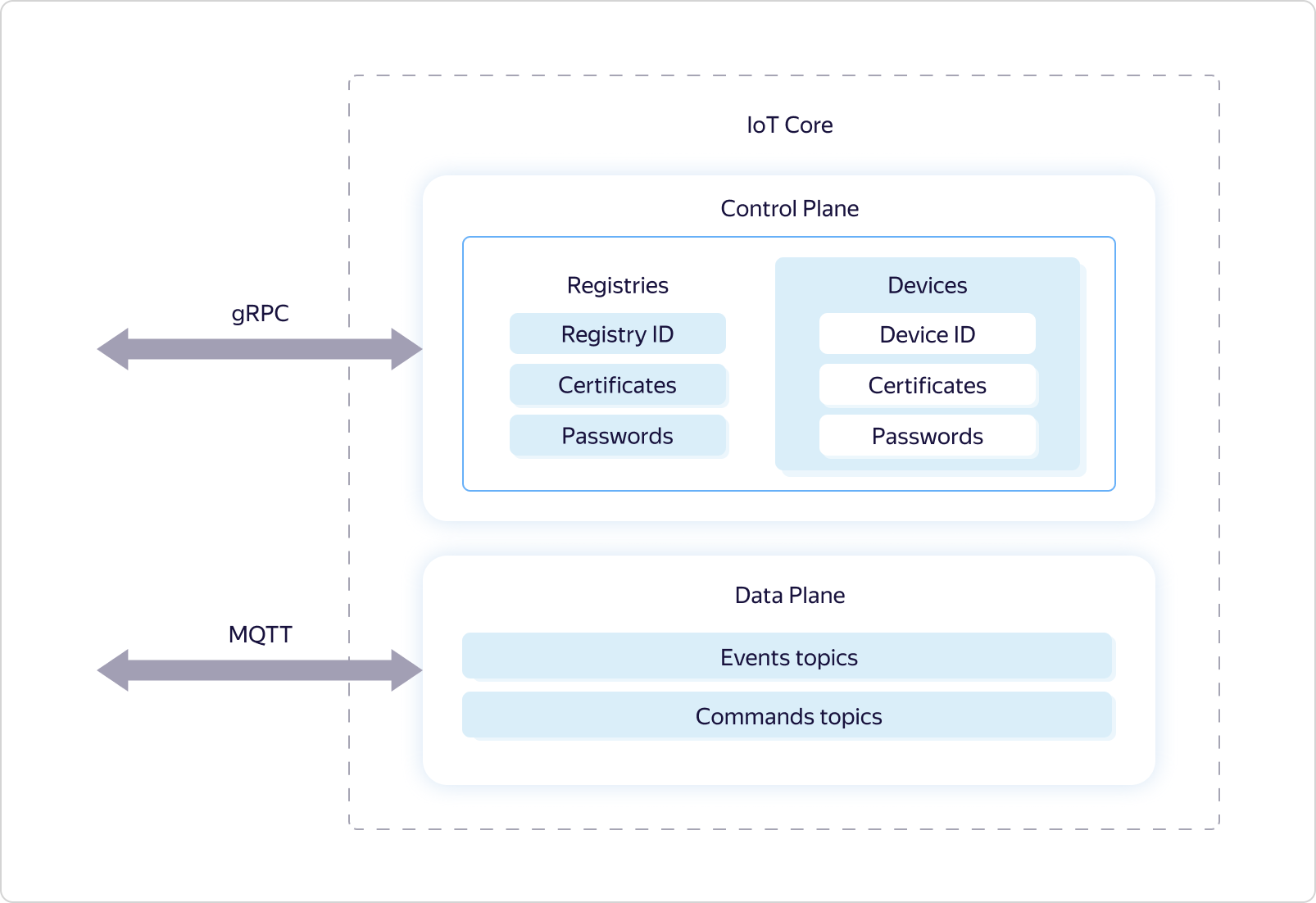 Data Plane is responsible for the logic of operation under the MQTT protocol, and Control Plane is responsible for delimiting access rights to certain topics and uses the logical entities Registry and Device for this.
Data Plane is responsible for the logic of operation under the MQTT protocol, and Control Plane is responsible for delimiting access rights to certain topics and uses the logical entities Registry and Device for this. Each Yandex.Cloud user can have several registries, each of which can contain its own subset of devices.Access to topics is provided as follows:
Each Yandex.Cloud user can have several registries, each of which can contain its own subset of devices.Access to topics is provided as follows: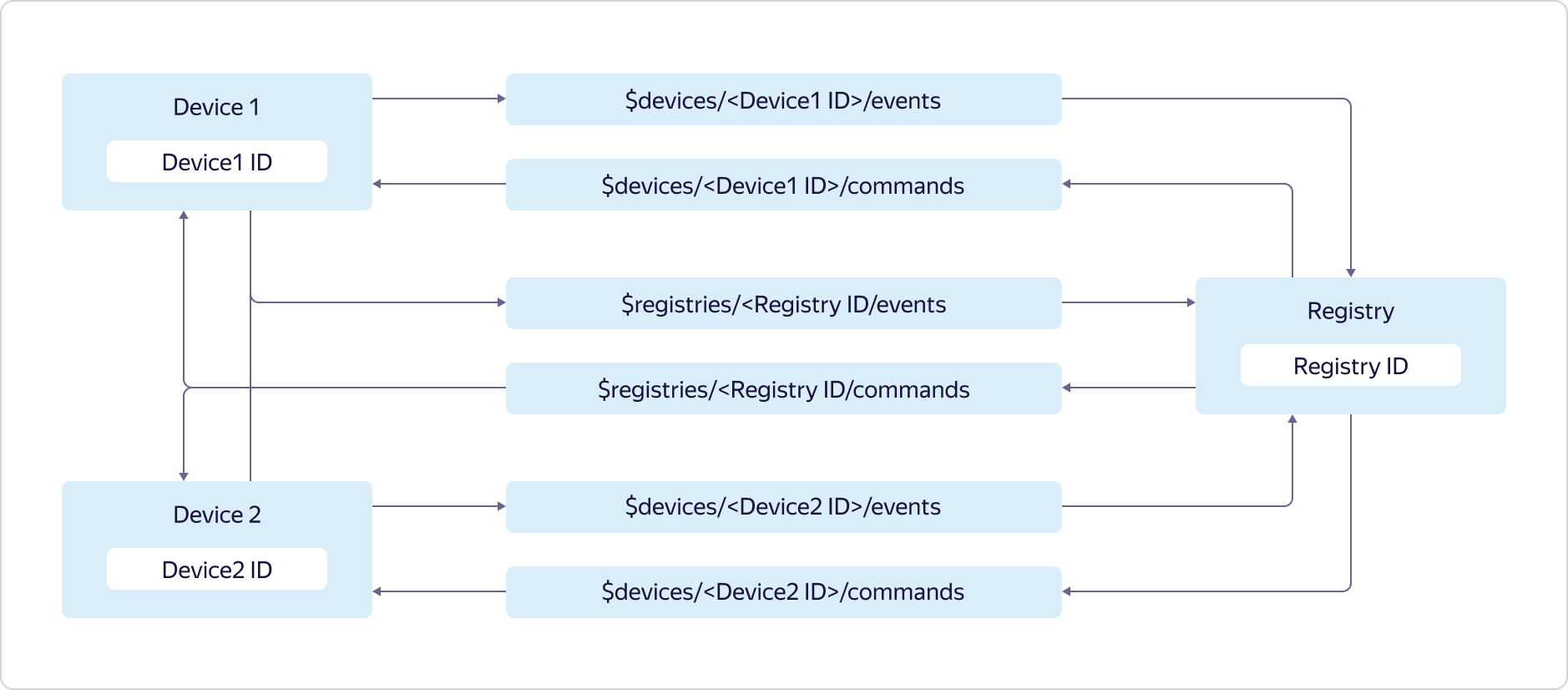 Devices can send data only to their events topic and registry events topic:
Devices can send data only to their events topic and registry events topic:$devices/<Device1 ID>/events
$registries/<Registry ID>/events
and subscribe to messages only from your topic of commands and topic of registry commands:$devices/<Device1 ID>/commands
$registries/<Registry ID>/commands
The registry can send data to all topics of device commands and to the topic of registry commands:$devices/<Device1 ID>/commands
$devices/<Device2 ID>/commands
$registries/<Registry ID>/commands
and subscribe to messages from all topics of device events and the topic of registry events:$devices/<Device1 ID>/events
$devices/<Device2 ID>/events
$registries/<Registry ID>/events
To work with all the entities described above, Data Plane has a gRPC-protocol and a REST-protocol, on the basis of which access is realized through the GUI-console of Yandex.Cloud and the CLI command-line interface.As for the Data Plane, it supports the MQTT protocol version 3.1.1. However, there are several features:- When connecting, be sure to use TLS.
- Only TCP connection is supported. WebSocket is not yet available.
- Authorization is available both by login and password (where login is the device or registry ID, and passwords are set by the user), and using certificates.
- The Retain flag is not supported, when using which the MQTT broker saves the message marked with the flag and sends it the next time you subscribe to the topic.
- Persistent Session is not supported, in which the MQTT broker saves information about the client (device or registry) to facilitate reconnection.
- With subscribe and publish, only the first two levels of service are supported:
- QoS0 - At most once. There is no delivery guarantee, but there is no re-delivery of the same message.
- QoS1 - At least once. Delivery is guaranteed, but there is a chance of re-receiving the same message.
To simplify the connection to Yandex IoT Core, we regularly add new examples for different platforms and languages to our repository on GitHub, and also describe scripts in the documentation.The service architecture looks like this: The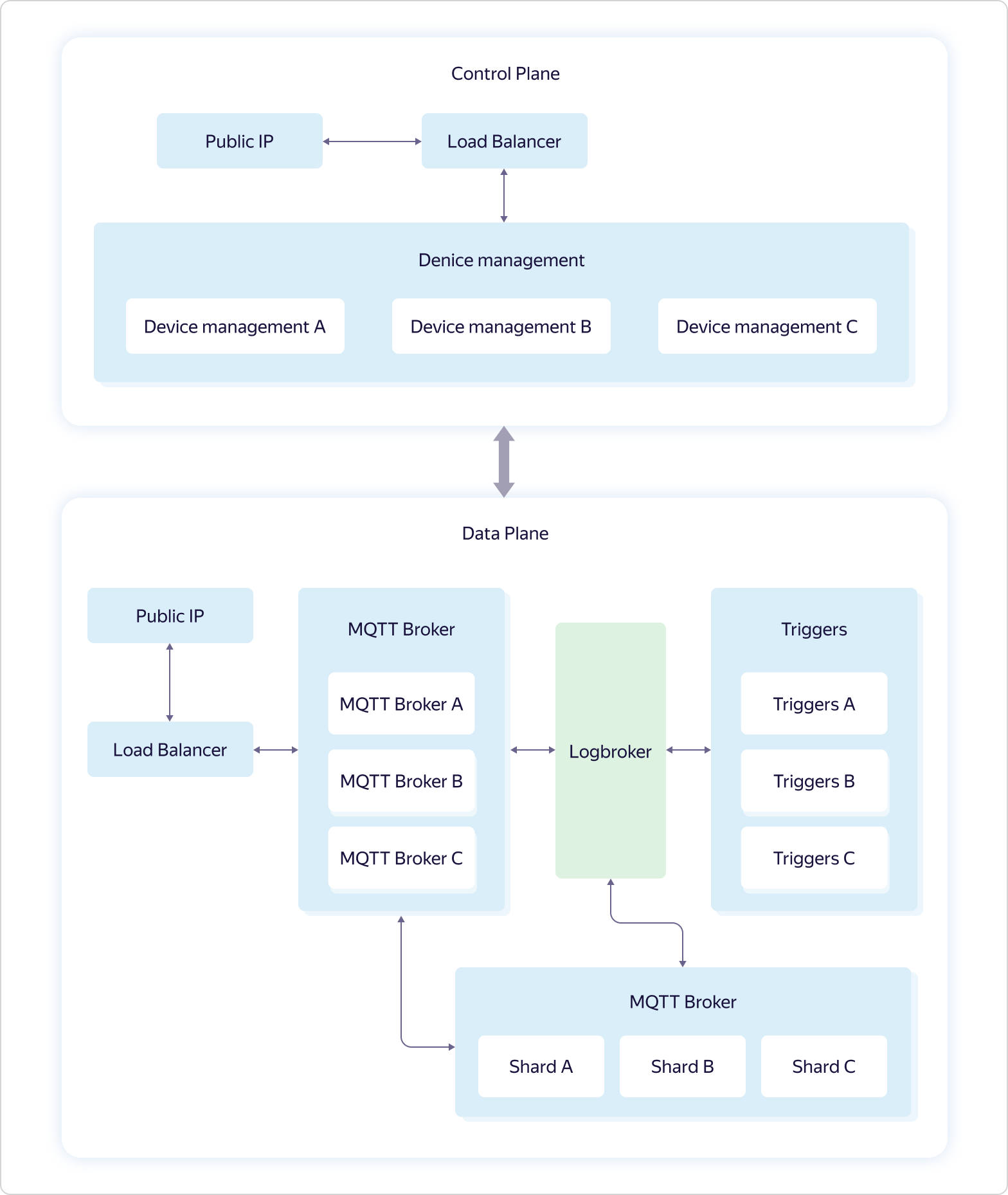 business logic of the service includes four parts:
business logic of the service includes four parts:- Device management — . Control Plane.
- MQTT Broker — MQTT-. Data Plane.
- Triggers — Yandex Cloud Functions. Data Plane.
- Shards — MQTT- . Data Plane.
All interaction with the "outside world" goes through load balancers. Moreover, in accordance with the dogfooding philosophy, Yandex Load Balancer is used, which is available to all Yandex.Cloud users.Each part of the business logic consists of several sets of three virtual machines — one in each availability zone (in Scheme A, B, and C). Virtual machines are exactly the same as all Yandex.Cloud users. When the load increases, scaling occurs with the help of the whole set - three machines are added at once within the framework of one part of the business logic. This means that if one set of three MQTT Broker machines cannot handle the load, then another set of three MQTT Broker machines will be added, while the configuration of other parts of the business logic will remain the same.And only Logbroker is not publicly available. It is a service for efficient fail-safe operation with data streams. It is based on Apache Kafka, but it has many other useful functions: it implements disaster recovery processes (including exactly once semantics when you have a message delivery guarantee without duplication) and service processes (such as cross-center replication, data distribution to clusters of calculation), and also has a mechanism for uniform non-duplicate distribution of data between flow subscribers - a kind of load balancer.The device management features in Control Plane are described above. But with Data Plane, everything is much more interesting.Each instance of MQTT Broker works independently and knows nothing about other instances. All received data (publish from customers) is sent by brokers to Logbroker, from where they are picked up by Shards and Triggers. And it is in shards that synchronization occurs between instances of brokers. Shards know about all MQTT clients and the distribution of their subscriptions (subscribe) across instances of MQTT brokers and determine where to send the received data.For example, the MQTT client A is subscribed to the topic from broker A, and the MQTT client B is subscribed to the same topic from broker B. If the MQTT client C makes publish to the same topic, but to broker C, then the shard transfers data from broker C to brokers A and B, as a result of which the data will be received by both MQTT client A and MQTT client B.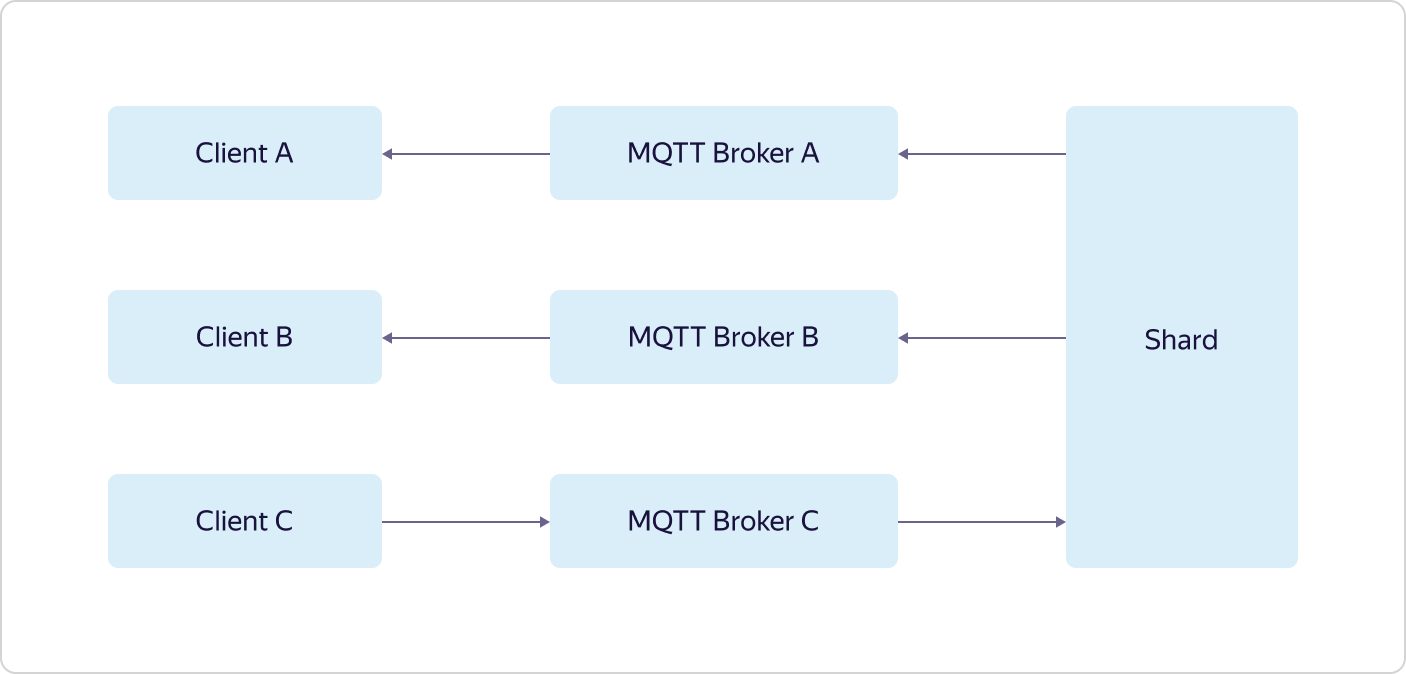 The last part of the business logic, triggers (Triggers), also receives all the data received from MQTT clients and, if this is configured by the user, passes them to the triggers of the Yandex Cloud Functions service.As you can see, Yandex IoT Core has a rather complicated architecture and logic of work, which is difficult to repeat on local installations. This allows him to withstand the loss of even two of the three availability zones, and work out an unlimited number of connections and unlimited data volumes.Moreover, all this logic is hidden from the user “under the hood”, but from the outside everything looks very simple - as if you are working with a single MQTT broker.
The last part of the business logic, triggers (Triggers), also receives all the data received from MQTT clients and, if this is configured by the user, passes them to the triggers of the Yandex Cloud Functions service.As you can see, Yandex IoT Core has a rather complicated architecture and logic of work, which is difficult to repeat on local installations. This allows him to withstand the loss of even two of the three availability zones, and work out an unlimited number of connections and unlimited data volumes.Moreover, all this logic is hidden from the user “under the hood”, but from the outside everything looks very simple - as if you are working with a single MQTT broker.Triggers and Yandex Cloud Functions
Yandex Cloud Functions is a representative of the so-called "serverless" (serverless) services in Yandex.Cloud. The main essence of such services is that the user does not spend his time setting up, deploying and scaling the environment to execute code, but only deals with the most valuable thing for him - writing the code itself that performs the necessary task. In the case of functions, this is the so-called atomic stateless code that can be triggered by some event. “Atomic” and “stateless” mean that this code should perform some relatively small but integral task, while the code should not use any variables in order to store values between calls.There are several ways to call functions: a direct HTTP call, a timer call (cron), or an event subscription. As the latter, the service already supports subscribing to message queues (Yandex Message Queue), events generated by the Object Storage service, and (most valuable for the IoT scenario) subscribing to messages in Yandex IoT Core.Despite the fact that you can work with Yandex IoT Core using any MQTT-compatible client, Yandex Cloud Functions is one of the most optimal and convenient ways to receive and process data. The reason for this is very simple. A function can be called on every incoming message from any device, and the functions will be executed in parallel to each other (due to atomicity and stateless approach), and the number of their calls will naturally change as the number of incoming messages from devices changes. Thus, the user can completely ignore the issues of setting up the infrastructure and, moreover, unlike the same virtual machines, payment will only occur for the work actually performed.This will allow you to significantly save at low load and get a clear and predictable cost with growth.The mechanism for calling functions on events (subscribing to events) is called a trigger (Trigger). Its essence is depicted in the diagram: A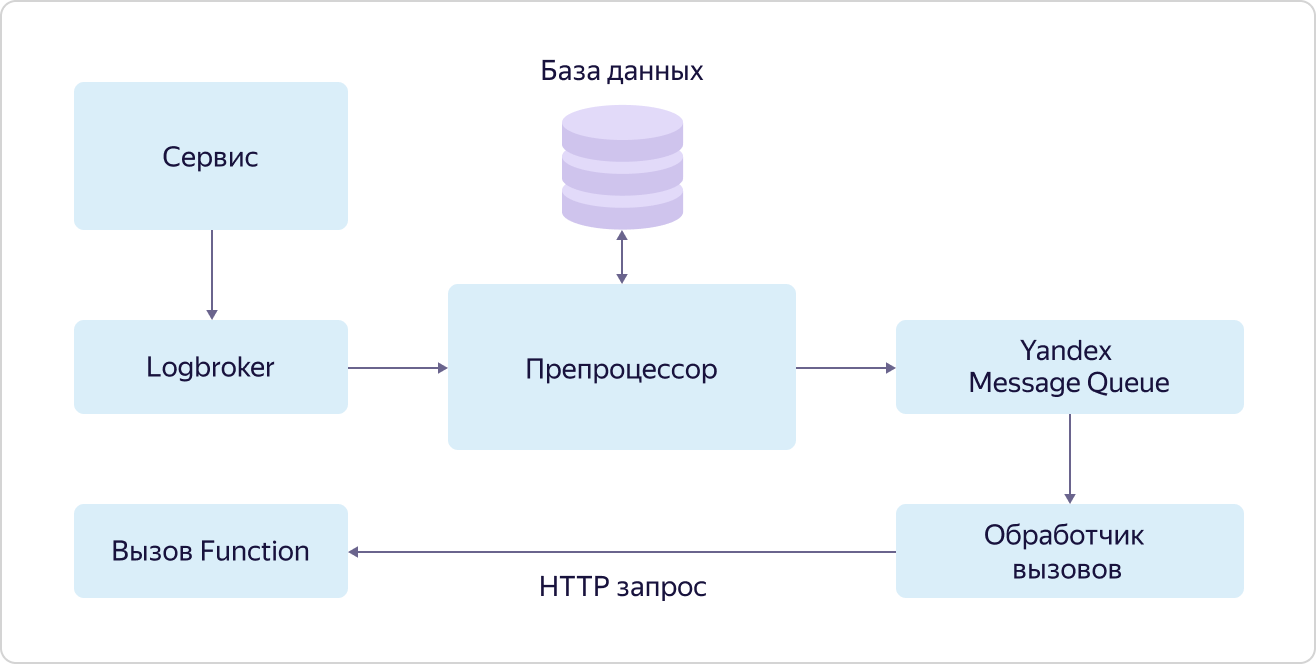 service that generates events for calling functions puts them in a queue in Logbroker. In the case of Yandex IoT Core, Triggers from Data Plane do this. Further, these events are taken by the preprocessor, which is looking for a record in the database for this event indicating the function to be called. If such an entry is found, the preprocessor puts the information about the function call (function ID and call parameters) in the queue in the Yandex Message Queue service, from where the call handler picks it up. The handler, in turn, sends an HTTP request to call the function to the Yandex Cloud Functions service.At the same time, again, in accordance with the dogfooding philosophy, the Yandex Message Queue service, accessible to all users, is used, and the functions are called in exactly the same way that any other users can call their functions.Let's say a few words about Yandex Message Queue. Despite the fact that this, like Logbroker, is a queue service, there is one significant difference between them. When processing messages from queues, the handler informs the queue that it has finished and the message can be deleted. This is an important reliability mechanism in such services, but it complicates the logic of working with messages.Yandex Message Queue allows you to "parallelize" the processing of each message within the queue. In other words, the message from the queue that is currently being processed does not block the possibility of another "thread" to pick up the next event from the queue for processing. This is called message-level concurrency.And LogBroker operates on message groups, and until the whole group is processed, the next group cannot be picked up for processing. This approach is called concurrency at the partition level.And it is precisely the use of Yandex Message Queue that allows you to quickly and efficiently process in parallel a lot of requests to call a function for events from a particular service.Despite the fact that triggers are a separate independent unit, they are part of the Yandex Cloud Functions service. We just have to figure out exactly how the functions are called.
service that generates events for calling functions puts them in a queue in Logbroker. In the case of Yandex IoT Core, Triggers from Data Plane do this. Further, these events are taken by the preprocessor, which is looking for a record in the database for this event indicating the function to be called. If such an entry is found, the preprocessor puts the information about the function call (function ID and call parameters) in the queue in the Yandex Message Queue service, from where the call handler picks it up. The handler, in turn, sends an HTTP request to call the function to the Yandex Cloud Functions service.At the same time, again, in accordance with the dogfooding philosophy, the Yandex Message Queue service, accessible to all users, is used, and the functions are called in exactly the same way that any other users can call their functions.Let's say a few words about Yandex Message Queue. Despite the fact that this, like Logbroker, is a queue service, there is one significant difference between them. When processing messages from queues, the handler informs the queue that it has finished and the message can be deleted. This is an important reliability mechanism in such services, but it complicates the logic of working with messages.Yandex Message Queue allows you to "parallelize" the processing of each message within the queue. In other words, the message from the queue that is currently being processed does not block the possibility of another "thread" to pick up the next event from the queue for processing. This is called message-level concurrency.And LogBroker operates on message groups, and until the whole group is processed, the next group cannot be picked up for processing. This approach is called concurrency at the partition level.And it is precisely the use of Yandex Message Queue that allows you to quickly and efficiently process in parallel a lot of requests to call a function for events from a particular service.Despite the fact that triggers are a separate independent unit, they are part of the Yandex Cloud Functions service. We just have to figure out exactly how the functions are called. All requests to call functions (both external and internal) fall into the load balancer, which distributes them to routers in different access zones (AZ), several pieces are deployed in each zone. Upon receiving a request, the router first of all goes to the Identity and Access manager (IAM) service to make sure that the request source has rights to call this function. He then turns to scheduler and asks which worker to run the function on. Worker is a virtual machine with a customized runtime of isolated functions. Further, the router, having received from the scheduler the address of the worker on which to execute the function, sends a command to this worker to start the function with certain parameters.Where does the worker come from? This is where all the serverless magic happens. Schedulers, analyzing the load (the number and duration of functions), manage (start and stop) virtual machines with a particular runtime. NodeJS and Python are now supported. And here one parameter is extremely important - the speed of launching functions. The service development team has done a great job, and now the virtual machine starts in a maximum of 250 ms, while using the most secure environment for isolating functions from each other - QEMU virtualization, which runs all Yandex. Cloud. At the same time, if there is already a working worker for the incoming request, the function starts almost instantly.And, in accordance with the same dogfooding approach, the Load Balancer uses a public service accessible to all users, and the worker, scheduler and router are ordinary virtual machines, the same as all users.Thus, the fault tolerance of the service is implemented at the level of the load balancer and redundancy of the key system components (router and scheduler), and scaling occurs due to the deployment or reduction of the number of workers. Moreover, each accessibility zone works independently, which allows surviving the loss of even two of the three zones.
All requests to call functions (both external and internal) fall into the load balancer, which distributes them to routers in different access zones (AZ), several pieces are deployed in each zone. Upon receiving a request, the router first of all goes to the Identity and Access manager (IAM) service to make sure that the request source has rights to call this function. He then turns to scheduler and asks which worker to run the function on. Worker is a virtual machine with a customized runtime of isolated functions. Further, the router, having received from the scheduler the address of the worker on which to execute the function, sends a command to this worker to start the function with certain parameters.Where does the worker come from? This is where all the serverless magic happens. Schedulers, analyzing the load (the number and duration of functions), manage (start and stop) virtual machines with a particular runtime. NodeJS and Python are now supported. And here one parameter is extremely important - the speed of launching functions. The service development team has done a great job, and now the virtual machine starts in a maximum of 250 ms, while using the most secure environment for isolating functions from each other - QEMU virtualization, which runs all Yandex. Cloud. At the same time, if there is already a working worker for the incoming request, the function starts almost instantly.And, in accordance with the same dogfooding approach, the Load Balancer uses a public service accessible to all users, and the worker, scheduler and router are ordinary virtual machines, the same as all users.Thus, the fault tolerance of the service is implemented at the level of the load balancer and redundancy of the key system components (router and scheduler), and scaling occurs due to the deployment or reduction of the number of workers. Moreover, each accessibility zone works independently, which allows surviving the loss of even two of the three zones.useful links
In conclusion, I want to give a few links that will allow you to study the services in more detail: