He was not sure that he heard correctly. So much depended on it! But do not ask again? (c) Boris Akunin. The whole world is a theater.
While working on the voice assistant that was mentioned in the previous article , I realized that I just can’t help but share the beautiful FuzzyWuzzy library with you .In short, thanks to her, it is possible to make a fuzzy string comparison without any suffering.First steps
To get started, you need to do two steps:/ IMPORTANT! Python version 2.7 and higher /Step 1. Installation.Open the command line and enter:pip install fuzzywuzzy
Press Enter.Next, install python-Levenshtein in the same way to speed up string matching by 3-10 times.pip install python-Levenshtein
After installation is complete, the library is ready to import.Step 2. Importing into the project.from fuzzywuzzy import fuzz
from fuzzywuzzy import process
Functional
1. The most common comparison:a = fuzz.ratio(' ', ' ')
print(a)
If we change a couple of characters, then the output will get a different number.a = fuzz.ratio(' ', ' ')
print(a)
2. Partial comparison.This type of comparison in the entire second line looks for a match with the initial one, for example:a = fuzz.partial_ratio(' ', ' !')
print(a)
Ora = fuzz.partial_ratio(' ', ' , ')
print(a)
But you should remember about the register, sincea = fuzz.partial_ratio(' ', ' , ')
print(a)
3.Token comparison 1) Token Sort RatioWords are compared with each other, regardless of case or ordera = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio('1 2 ', '1 2 ')
print(a)
2) Token Set RatioThis comparison, unlike the past, equates strings, if their difference is the repetition of words.a = fuzz.token_set_ratio(' ', ' ')
print(a)
4. Advanced regular comparisonIn many cases, it is more advisable to use exactly WRatio , since it is case-sensitive and punctuation (not dividing the string)a = fuzz.WRatio(' ', '! !')
print(a)
a = fuzz.WRatio(' ', '!, !')
print(a)
5. Working with the listTo compare the lines with the lines from the list, the process module is usedcity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extract("", city, limit=2)
print(a)
If only the first one in the list is needed, then it is better to use extractOnecity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
Application
How and where to apply all of the above is up to you, but here is an example from my term paper :
try:
files = os.listdir('C:\\Users\\hartp\\Desktop\\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\\Users\\hartp\\Desktop\\' + filestart[0])
else:
speak(' ')
except FileNotFoundError:
speak(' ')
Let's go over the code and understand what's what. With the os.listdircommand , we get a list of all the files that are present at the end of the specified path (in our case, to the desktop).files = os.listdir('C:\\Users\\hartp\\Desktop\\')
print(files)
Next is a comparison of the lines of the file list with the name of the file that the user named (variable namerec ). I hope you noticed that the result of the extractOne function is a tuple of string and number (similarity index)Example from last chaptercity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
.
Based on this, we check the similarity index filestart [1]> = 80 ([1], since the tuple is numbered from 0, as in an array) and, if the condition is true, then run the os.startfile function with a file called filestart [0 ]. Otherwise, if the similarity index is less than 80 or an error occurs that the file was not found, we inform the user through the speak function .All roads lead to Matan
Hidden from people who are afraid of math, , ().
, .
( , ) — , .
S1 i S2 j
S1=vrhk
S2=rhgr
3 :
- : r → v
- : -r
- : rVhgr
:

0 1? ( — «0»), r , r ( , — «1»). v .
rh h, r ( ), , :
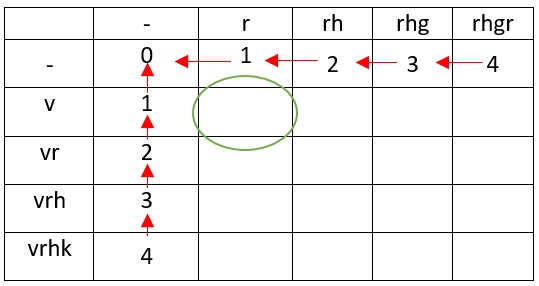
v r ( ).
, — v.
1. ? r , v. r , v, rv. , v v.
v rh
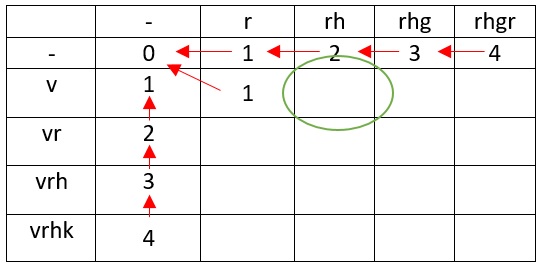
— v h r .
.
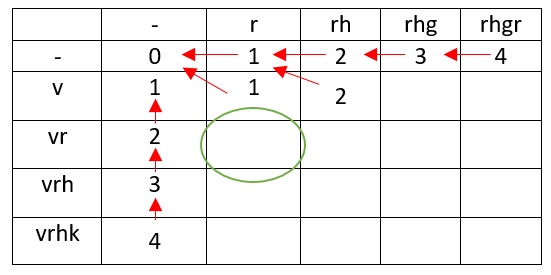
vr r , , , , .
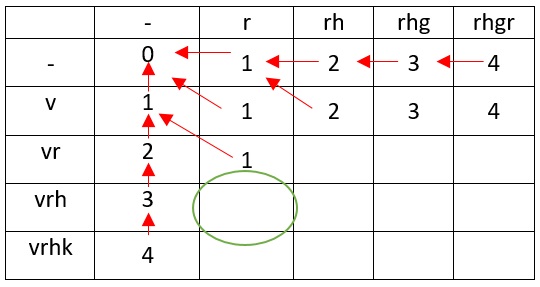
vrh r h ( vr r), 2

vr r vrh rh, , .
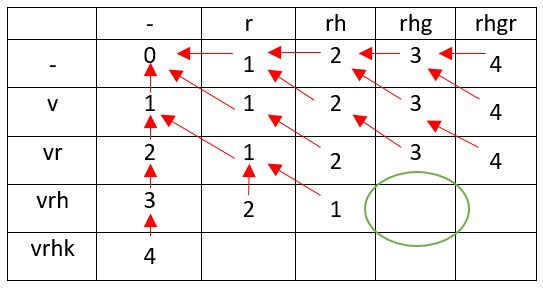
, vrh rhg , , , - ( ).
, , ( ) — vrhk rhgr.
Thank you all for your attention! I hope this article is useful to someone.