Recently, in an interview I was asked if I worked with distributed transactions, in the sense that I had to do the insertion / update of such records, provided:- Single transaction.
- It can be several various databases such as Oracle, MS SQL Server and PostgreSQL.
- The response to a CRUD operation can be significant.
- The insertion sequence is not important.
What did colleagues achieve by asking this question? Check my experience or get a ready-made solution? Actually it’s not important for me, but what’s important - the problem in the theory of the question seemed interesting to me, and I decided to write an article on how this problem could be solved.Before I describe my solution, let's recall how a typical distributed transaction is implemented using the Microsoft platform as an example.Option number 1. C ++ application and ODBC driver (owned by Microsoft Distributed Transaction Coordinator (MSDTC) for SQL Server)Microsoft Distributed Transaction Coordinator (MSDTC) allows applications to expand or distribute transactions across two or more instances of SQL Server. A distributed transaction works even if two instances are located on different computers.MSDTC only works locally for Microsoft SQL Server and is not available for the Microsoft Azure SQL cloud database service.MSDTC is called by the SQL Server Native Client Driver for Open Database Connectivity (ODBC) when your C ++ program manages a distributed transaction. The native client ODBC driver has an XA Open Distributed Transaction Processing (DTP) compliant transaction manager. This compliance is required by MSDTC. Typically, all transaction management commands are sent through this ODBC driver for the native client. The sequence is as follows:An ODBC application for a native C ++ client starts a transaction by invoking SQLSetConnectAttr with auto-commit disabled.The application updates some data on SQL Server X on computer A.The application updates some data on SQL Server X on computer B.If the update fails on SQL Server Y, all uncommitted updates in both instances of SQL Server are rolled back.Finally, the application completes the transaction by calling SQLEndTran (1) with the SQL_COMMIT or SQL_ROLLBACK option.(1) MSDTC can be called without ODBC. In this case, MSDTC becomes a transaction manager, and the application no longer uses SQLEndTran.Only one distributed transaction.Suppose your ODBC application for a native C ++ client is enrolled in a distributed transaction. Then the application is credited to the second distributed transaction. In this case, the SQL Server Native Client ODBC driver leaves the original distributed transaction and is included in the new distributed transaction.Read more about MSDTC here..Option number 2. The C # application, as an alternative to the SQL database in the Azur cloud,MSDTC is not supported for either the Azure SQL Database or the Azure SQL Data Warehouse.However, you can create a distributed transaction for an SQL database if your C # program uses the .NET System.Transactions.TransactionScope class.The following example shows how to use the TransactionScope class to define a block of code to participate in a transaction.static public int CreateTransactionScope(
string connectString1, string connectString2,
string commandText1, string commandText2)
{
int returnValue = 0;
System.IO.StringWriter writer = new System.IO.StringWriter();
try
{
using (TransactionScope scope = new TransactionScope())
{
using (SqlConnection connection1 = new SqlConnection(connectString1))
{
connection1.Open();
SqlCommand command1 = new SqlCommand(commandText1, connection1);
returnValue = command1.ExecuteNonQuery();
writer.WriteLine(" command1: {0}", returnValue);
using (SqlConnection connection2 = new SqlConnection(connectString2))
{
connection2.Open();
returnValue = 0;
SqlCommand command2 = new SqlCommand(commandText2, connection2);
returnValue = command2.ExecuteNonQuery();
writer.WriteLine(" command2: {0}", returnValue);
}
}
scope.Complete();
}
}
catch (TransactionAbortedException ex)
{
writer.WriteLine(" : {0}", ex.Message);
}
Console.WriteLine(writer.ToString());
return returnValue;
}
Option number 3. C # and Entity Framework Core applications for distributed transactions.By default, if the database provider supports transactions, all changes in one call to SaveChanges () are applied to the transaction. If any of the changes is not performed, the transaction is rolled back, and none of the changes are applied to the database. This means that SaveChanges () is guaranteed to either complete successfully or leave the database unchanged in case of an error.For most applications, this default behavior is sufficient. You must manually control transactions only if the requirements of your application deem it necessary.You can use the DbContext.Database APIto start, commit, and roll back transactions. The following example shows two SaveChanges () operations and a LINQ query executed in a single transaction.Not all database providers support transactions. Some providers may or may not issue transactions when invoking a transaction API.using (var context = new BloggingContext())
{
using (var transaction = context.Database.BeginTransaction())
{
try
{
context.Blogs.Add(new Blog { Url = "http://blogs.msdn.com/dotnet" });
context.SaveChanges();
context.Blogs.Add(new Blog { Url = "http://blogs.msdn.com/visualstudio" });
context.SaveChanges();
var blogs = context.Blogs
.OrderBy(b => b.Url)
.ToList();
transaction.Commit();
}
catch (Exception)
{
}
}
}
If you use EF Core in the .NET Framework , the implementation of System.Transactions there supports distributed transactions.As you can see from the documentation within the framework of the platform and the Microsoft product line, distributed transactions are not a problem: MSDTC, the cloud itself is fault-tolerant, a bunch of ADO .NET + EF Core for exotic combinations (read here ).How can the transaction review on the Microsoft platform help us solve the problem? Very simple, there is a clear understanding that there is simply no standard toolkit for implementing a distributed transaction across heterogeneous databases in a .NET application.And if so, then we make our own home-made coordinated distributed transaction coordinator (CRT).One of the implementation options is distributed transactions based on microservices (see here ). This option is not bad, but it requires serious refinement of the Web API for all systems involved in the transaction.Therefore, we need a slightly different mechanism. The following is a general approach to developing MCT.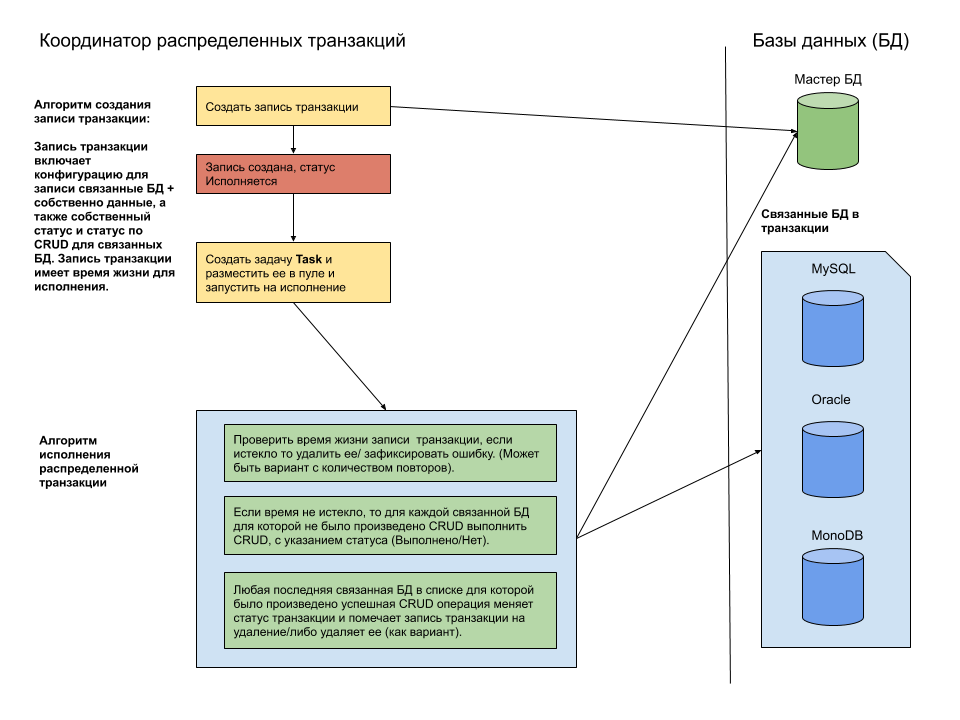 As you can see from the diagram, the main idea is to create and store with the updated status the transaction record stored in the master database (or table). This model of CRT allows you to implement distributed transactions that meet the requirements:
As you can see from the diagram, the main idea is to create and store with the updated status the transaction record stored in the master database (or table). This model of CRT allows you to implement distributed transactions that meet the requirements:- atomicity
- coherence
- isolation
- longevity
- may be part of the application in which the user has created a record, or may be a completely separate application in the form of a system service. may contain a special subprocess that generates transactions in a pool for execution when a power outage occurs (not shown in the diagram). Business rules for converting (mapping) the source data generated by the user for related databases can be dynamically added and configured via XML / JSON format and stored in the local application folder or in a transaction record (as an option). Accordingly, for this case, it is advisable to unify the conversion to related databases at the code level by implementing the modularity of the converters in the form of DLLs. (And yes, SRT implies direct access to the database without the participation of the Web API.)Thus, SRT in a simple form can be successfully implemented as part of the application, or as a separate, customizable and independent solution (which is better).Once again, I will clarify that a distributed transaction is, by definition, a one-time storage of information without changing it, but with the ability to map various databases into data schemes. So if you need to record data at other bases, for example, at the Ministry of Internal Affairs, the FSB and insurance companies, when recording incidents in the hospital’s emergency room (bullet wound), then this approach will certainly help you. The same mechanism can work perfectly in financial institutions.I hope this approach seemed interesting to you, write what you think about it, colleagues and friends!