The advent of async / await in C # has led to a redefinition of how to write simple and correct parallel code. Often, using asynchronous programming, programmers not only do not solve the problems that were with the threads, but also introduce new ones. Deadlocks and flights don't go anywhere - they just become harder to diagnose. Dmitry Ivanov - Software Analysis TeamLead at Huawei, a former JetBrains Rider techlide and developer of the ReSharper core: data structures, caches, multithreading, and a regular speaker at the DotNext conference .Under the cutscene - video recording and text transcript of Dmitry's report from the DotNext 2019 Piter conference.Further narration on behalf of the speaker.In multi-threaded or asynchronous code, something often breaks. The reason could be both deadlock and race. As a rule, a race crashes once out of a thousand, often not locally, but only on a build server, and it takes several days to catch it. I am sure for many this is a familiar situation.In addition, looking at asynchronous code even by experienced developers, I find myself thinking that some things can be written down three times shorter and more correctly.This suggests that the problem is not in people, but in the instrument. People just use the tool and want it to solve their problem. The tool itself has a very large number of capabilities (sometimes even superfluous), settings, an implicit context, which leads to the fact that it is very easy to use incorrectly. Let's try to figure out how to use async / await and work with a class
Dmitry Ivanov - Software Analysis TeamLead at Huawei, a former JetBrains Rider techlide and developer of the ReSharper core: data structures, caches, multithreading, and a regular speaker at the DotNext conference .Under the cutscene - video recording and text transcript of Dmitry's report from the DotNext 2019 Piter conference.Further narration on behalf of the speaker.In multi-threaded or asynchronous code, something often breaks. The reason could be both deadlock and race. As a rule, a race crashes once out of a thousand, often not locally, but only on a build server, and it takes several days to catch it. I am sure for many this is a familiar situation.In addition, looking at asynchronous code even by experienced developers, I find myself thinking that some things can be written down three times shorter and more correctly.This suggests that the problem is not in people, but in the instrument. People just use the tool and want it to solve their problem. The tool itself has a very large number of capabilities (sometimes even superfluous), settings, an implicit context, which leads to the fact that it is very easy to use incorrectly. Let's try to figure out how to use async / await and work with a class Taskin .NET.Plan
- Problems with approaches that are solved with async / await.
- Examples of controversial design.
- A task from real life that we will solve asynchronously.
Async / await and issues to be resolved
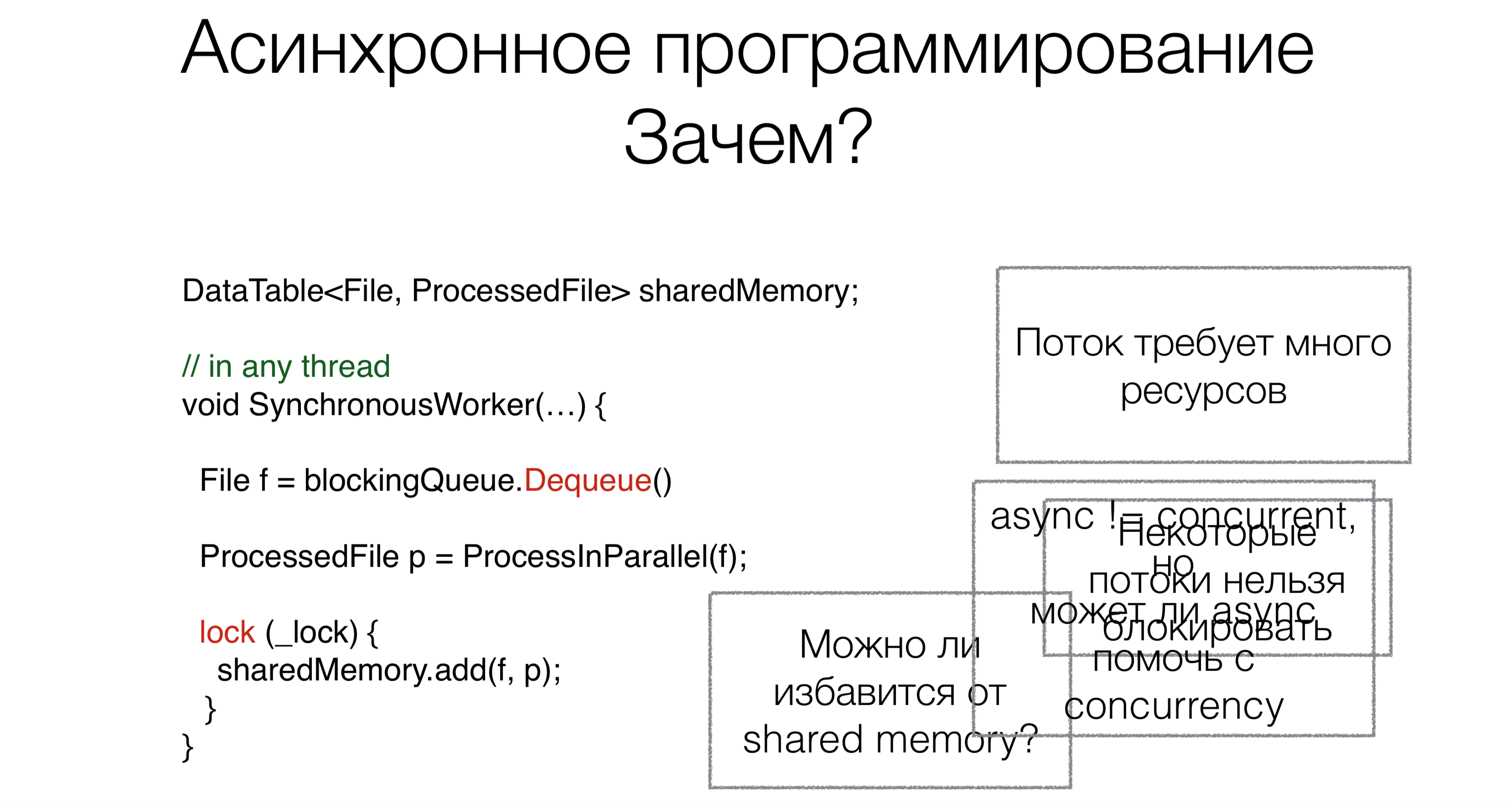 Why do we need async / await? Let's say we have code that works with shared shared memory.At the beginning of work, we read the request, in this case, the file from the blocking queue (for example, from the Internet or from the disk), using the Dequeue blocking request (blocking requests will be marked in red in the pictures with examples).This approach requires a lot of threads, and each thread requires resources, creates a load on scheduler. But this is not the main problem. Suppose people could rewrite operating systems so that these systems support both a hundred thousand and a million threads. But the main problem is that some threads simply cannot be taken. For example, you have a user interface thread. There are no normal adequate UI frameworks where access to data would be not only from one thread, yet. UI thread cannot be blocked. And in order not to block it, we need asynchronous code.Now let's talk about the second task. After we read the file, it needs to be processed somehow. We will do it in parallel.Many of you have heard that parallelism is not the same as asynchrony. In this case, the question arises: can asynchrony help write parallel code more compact, beautiful and faster?The last task is to work with shared memory. Do we need to drag this mechanism with locks, synchronization to asynchronous code, or can this be somehow avoided? Can async / await help with this?
Why do we need async / await? Let's say we have code that works with shared shared memory.At the beginning of work, we read the request, in this case, the file from the blocking queue (for example, from the Internet or from the disk), using the Dequeue blocking request (blocking requests will be marked in red in the pictures with examples).This approach requires a lot of threads, and each thread requires resources, creates a load on scheduler. But this is not the main problem. Suppose people could rewrite operating systems so that these systems support both a hundred thousand and a million threads. But the main problem is that some threads simply cannot be taken. For example, you have a user interface thread. There are no normal adequate UI frameworks where access to data would be not only from one thread, yet. UI thread cannot be blocked. And in order not to block it, we need asynchronous code.Now let's talk about the second task. After we read the file, it needs to be processed somehow. We will do it in parallel.Many of you have heard that parallelism is not the same as asynchrony. In this case, the question arises: can asynchrony help write parallel code more compact, beautiful and faster?The last task is to work with shared memory. Do we need to drag this mechanism with locks, synchronization to asynchronous code, or can this be somehow avoided? Can async / await help with this?Path to async / await
Let's look at the evolution of asynchronous programming in general in the world and in .NET.Callback
Void Foo(params, Action callback) {…}
Void OurMethod() {
…
Foo(params,() =>{
…
});
}
Asynchronous programming began with callbacks. That is, first you need to call some part of the code synchronously, and the second part - asynchronously. For example, you read from a file, and when the data is ready, it will be delivered to you somehow. This asynchronous part is passed as a callback .More callbacks
void Foo(params, Action callback) {...}
void Bar(Action callback) {...}
void Baz(Action callback) {...}
void OurMethod() {
...
Foo(params, () => {
...
Bar(() => {
Baz(() => {
});
});
});
}
Thus, from one callback you can register another callback , from which you can register a third callback, and in the end it all turns into a Callback Hell .
Callback: exceptions
void Foo(params, Action onSuccess, Action onFailure) {...}
void OurMethod() {
...
Foo(params, () => {
...
},
() => {
...
});
}
How to work with exceptions? For example, ReSharper, when separately responding to exceptions and to good execution, does not demonstrate the most beautiful pieces of code - there are separate callbacks for an exceptional situation and for a successful continuation. The result is just such a callback hell , but not linear, but tree-like, which can be completely confusing. In .NET, the first callback approach is called the Asynchronous Programming Model (APM). The method will be called
In .NET, the first callback approach is called the Asynchronous Programming Model (APM). The method will be called AsyncCallback, which is essentially the same as Action, but the approach has some features. First of all, methods should begin with the word “Begin” (reading from a file is BeginRead), which returns some AsyncResult. HimselfAsyncResult- This is a handler that knows that the operation has completed and that has a mechanism WaitHandle. You WaitHandlecan hang on, waiting for the operation to complete asynchronously. On the other hand, you can call EndOperation, that is, make EndReadand hang synchronously (which is very similar to a property Task.Result).This approach has a number of problems. Firstly, it does not protect us from callback hell . Secondly, it remains completely unclear what to do with exceptions. Thirdly, it is not clear on which thread this callback will be called - we have no control over the call. Fourth, the question arises, how to combine pieces of code with callbacks? The second model is called Event-Based Asynchronous Pattern. This is a reactive callback approach. The idea of the method is that we pass to the method
The second model is called Event-Based Asynchronous Pattern. This is a reactive callback approach. The idea of the method is that we pass to the method OperationNameAsyncsome object that has event Completed and subscribe to this event. As you noticed, BeginOperationNamechanges to OperationNameAsync. Confusion can occur when you go into the Socket class, where two patterns are mixed: ConnectAsyncand BeginConnect.Please note that you must call to cancel OperationNameAsyncCancel. Since in .NET this is not found anywhere else, usually everyone sends CancellationToken s . Thus, if you accidentally encounter a method in the library that ends with Async, you need to understand that it does not necessarily return Task, but can return a similar construction. Consider a model that is known in Java asFutures , in JavaScript, as Promises , and in .NET, as Task Asynchronous Patterns , in other words, “tasks.” This method assumes that you have some calculation object, and you can see the status of this object (running or finished). In .NET, there is a so-called
Consider a model that is known in Java asFutures , in JavaScript, as Promises , and in .NET, as Task Asynchronous Patterns , in other words, “tasks.” This method assumes that you have some calculation object, and you can see the status of this object (running or finished). In .NET, there is a so-called RnToCompletion, convenient separation of two statuses: the start of the task and the completion of the task. A common error occurs when a method is called on a task IsCompletedthat returns not successful continuation, but RnToCompletion, Canceledand Faulted. Thus, the result of clicking on “Cancel” in the UI application should differ from the return of exceptions (executions). In .NET, a distinction has been made: if execution is your mistake that you want to secure, then Cancel- forced operation.In .NET, a concept was also introduced TaskScheduler- it is a kind of abstraction on top of threads that tells where to run task. In this case, the cancellation support was designed at the design level. Almost all the operations in the library in .NET have CancellationTokenthat can be passed. This does not work for all languages: for example, in Kotlin you can undo task, but in .NET you cannot. The solution may be the division of responsibility between those who cancel the task, and the task itself. When you receive a task, you cannot cancel it otherwise than explicitly — you must pass it on CancellationToken.A special object TaskCompletionSoureallows you to easily adapt old APIs that are associated with the Event-Based Asynchronous Pattern or Asynchronous Programming Model. There is a document that you must read if you program in tasks. It describes all agreements regarding tasas. For example, any method, returning the task, should return it in a running state, which means that it cannot be Created, while all such operations must end in Async.Combining continuations
Task ourMethod() {
return Task.RunSynchronously(() =>{
...
})
.ContinueWith(_ =>{
Foo();
})
.ContinueWith(_ =>{
Bar();
})
.ContinueWith(_ =>{
Baz();
})
}
As for the combination, taking into account the callback hell , it can appear in a more linear form, despite the presence of pieces of repeating code with minimal changes. It seems that the code is improving this way, but there are pitfalls here too.Start & continue tasks
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
Task.ContinueWith(Action<Task>,
TaskContinuationOptions,
TaskScheduler,
CancellationToken
)
Let us turn to three parameters during the standard task launch: the first are the options for starting the task, the second is the schedulerone on which the task is launched, and the third - CancellationToken. TaskScheduler tells where the task starts and is an object that you can independently override. For example, you can override a method
TaskScheduler tells where the task starts and is an object that you can independently override. For example, you can override a method Queue. If you do TaskSchedulerfor thread pool, the method Queuetakes a thread from thread pooland sends your task there.If you take schedulerover the main thread, it puts everything in one queue, and tasks are executed sequentially on the main thread. However, the problem is that in .NET you can execute task without passing TaskScheduler. The question arises: how then does .NET calculate what task was passed to it? When the task starts through StartNewinsideAction, ThreadStatic. Currentexhibited in the one TaskSchedulerthat we gave her.This design seems rather controversial due to the implicit context. There were cases when it TaskSchedulercontained asynchronous code that inherited somewhere very deeply TaskScheduler.Currentand overlapped with another scheduler, which led to deadlocks. In this case, you can use the option TaskCreationOption.HideScheduler. This is an alarm bell that says that we have some option that overrides the ThreadStaticsetting.Everything is the same with continuations. The question arises: where does it come from TaskSchedulerfor continuations? First of all, it is taken in the method in which you started Continuation. It is also TaskSchedulertaken from ThreadStatic. It is important that for async / await, continuations work very differently. We turn to the parameters
We turn to the parameters TaskCreationOptionsand TaskContinuationOptions. Their main problem is that there are a lot of them. Some of these parameters cancel each other, some are mutually exclusive. All these parameters can be used in all possible combinations, so it’s difficult to keep in mind everything that can happen with longing. Some of these options work completely incomprehensibly. For example, the parameters
For example, the parameters ExecuteSynchronouslyand RunContinuationsAsynchronouslyrepresent two possible application options, but whether continuation will be launched synchronously or asynchronously depends on so many things that you will not know about. Another example: we launched task, launched continuation and simultaneously gave two parameters
Another example: we launched task, launched continuation and simultaneously gave two parametersTaskContinuations.ExecuteSynchronously, after which they started the continuation asynchronously. Will it be executed in the same stack where the previous task ends, or will it be transferred to thread pool? In this case, there will be a third option: it depends.
TaskCompletionSource
Consider TaskCompletionSource. When you create task, you set its result through SetResultto adapt the previous asynchronous patterns to the task world. You TaskCompletionSourcecan request tcs.Task, and this task will go into a state finishwhen you call tcs.SetResult. However, if you run this on the thread pool , you will get deadlock . The question is, why if we did not write anything even synchronously? We create
We create TaskCompletionSource, start a new task, and we have a second thread that starts something in this task. It goes over and falls into expectation for a hundred milliseconds. Then our main thread - green - goes to await and that’s it. He releases the stack, the stack hangs, waiting to be called in a continuation ontask.Waitwhen tcsexposed.In the blue thread we get to tcs, and then the most interesting. Based on internal considerations of .NET, he TaskCompletionSourcebelieves that the continuation of this tcscan be performed synchronously, that is, directly on the same stack, then this task.Waitis performed synchronously on the same stack. This is very strange, despite the fact that we have not even written anywhere ExecuteSynchronously. This is probably the problem with mixing synchronous and asynchronous code. Another problem with this
Another problem with this TaskCompletionSourceis that when we call SetResultunder the lock , you cannot call arbitrary code, since under the lock you can do only some small granular activity. Run underneath some action-s, it’s impossible to come from where they came from. How to solve this problem?var tcs = new TaskCompletionSource<int>(
TaskContinuationsOptions.RunContinuationsAsynchronously
) ;
lock(mylock)
{
tcs.SetResult(O);
});
It is TaskCompletionSourceworth using only for adaptation of not Task code in libraries. Almost everything else can be solved through await. In this case, it is always strongly recommended to prescribe the parameter "TaskCompletionSource.RunContinuationsAsynchronously" . You almost always need to run a continuation asynchronously. In this case, you tcs.SetResulthave something under which nothing will be launched. Why should continuation be performed synchronously? Because it
Why should continuation be performed synchronously? Because it RunContinuationsAsynchronouslyrefers to the following ContinueWith, and not to ours. In order for him to relate to ours, you need to write the following: This example shows how parameters are not intuitive, how they intersect with each other, how they introduce cognitive complexity - it is so difficult to write.
This example shows how parameters are not intuitive, how they intersect with each other, how they introduce cognitive complexity - it is so difficult to write.Parent-child hierarchy
Task.Factory.StartNew(() =>
{
Task.Factory.StartNew(() => {
})
})
.ContinueWith(...)
There are other options for using parameters. For example, a Parent-child hierarchy arises when you launch one task and run another under it. In this case, if you write ContinueWith, you ContinueWithwill not wait for the task launched inside.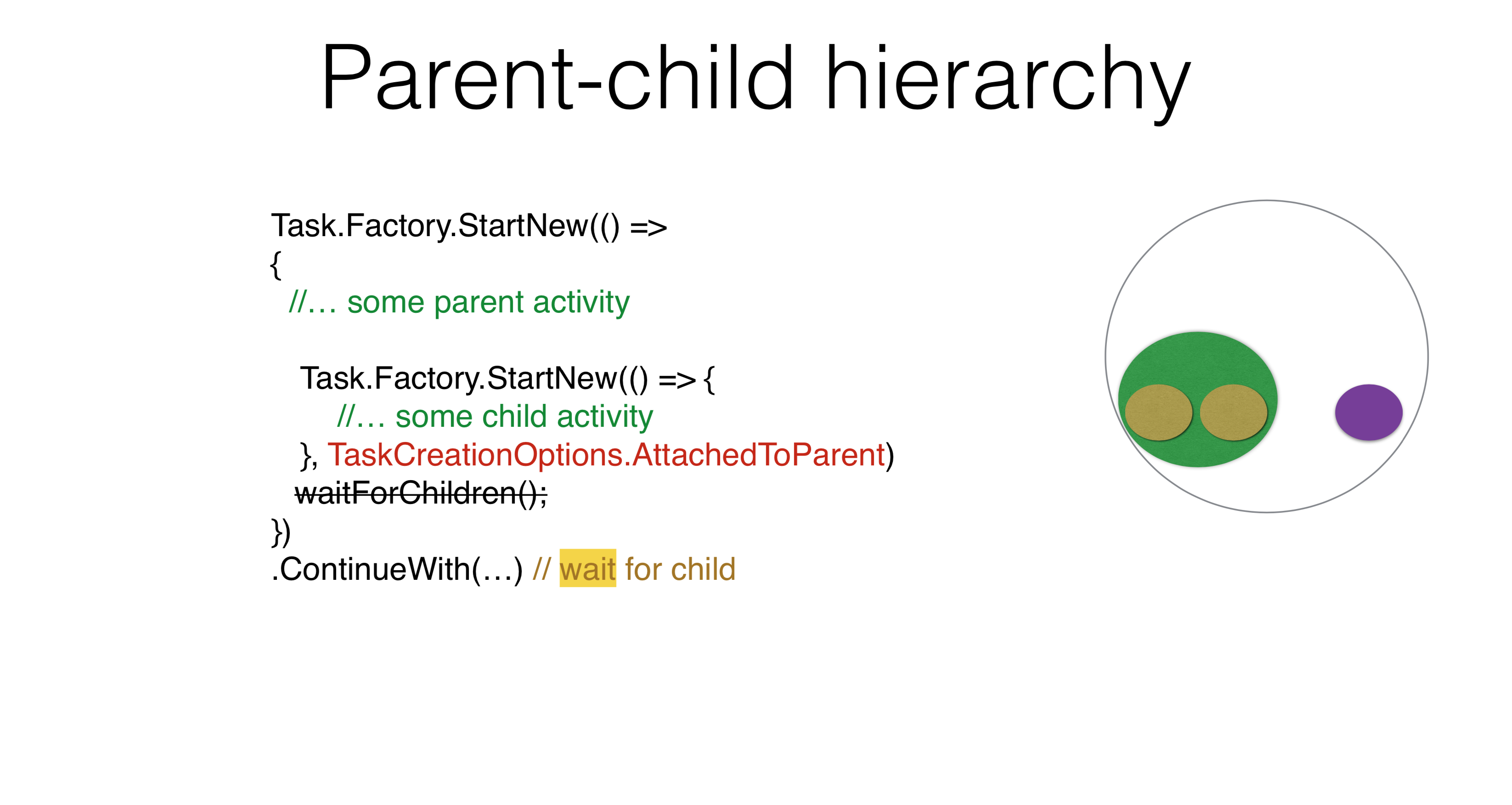 If you write
If you write TaskCreationOptions.AttachedToParent, it ContinueWithwill wait. You can use this property in your products. I think everyone can come up with an example in which there is a hierarchy of tasks, with the task waiting for the subtask, and the subtask for its subtasks. No need to write anywhere WaitForChildren, this wait happens asynchronously. That is, the body of the parent task ends, and after that the parent task is not considered complete, does not start its continuations until the child tasks work.Task.Factory.StartNew(() =>
{
Foo();
})
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
There may be a problem in which the task is transferred somewhere in ThreadStatic, then everything that you started with AttachedToParentwill be added to this parent task, which is an alarm bell.Task.Factory.StartNew(() =>
{
Foo();
}, TaskCreationOptions.DenyChildAttach)
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
On the other hand, there is an option that cancels the previous option DenyChildAttach. Such an application occurs quite often.Task.Run(() =>
{
Foo();
})
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
It is worth remembering that Task.Runthis is the standard way to start, which by default implies DenyChildAttach.The implicit context that you put in ThreadStaticadds complexity to you. You do not understand how the task works, because you need to know the context. Another issue that may arise is related to the idle state of async / await. That's because in async / await you do not have tasks, but actions. Continuation is not honest task, but action. When you write async / await code, you don’t need to use AttachedToParentit because you explicitly tie the tasks to wait through await, and this is the right approach. You have six options on how to start a continuation. You launched task, launched
You have six options on how to start a continuation. You launched task, launchedContinueWith. Question: What status will this continuation have? There are five possible answers:- general continuation will be completed successfully; RunToCompletion will occur;
- the task will be in error;
- cancellation will occur;
- the task will not reach completion at all, it will be in some kind of limbo;
- option - “depends”.
 In this case, the task will be in the “canceled” state, although nowhere is the word “canceled” anywhere. Here we throw the reception and do nothing. The problem is that when you read someone else's code with a lot of options - even if you knew about these options 10 minutes ago - you still forget what happens here. So do not write.
In this case, the task will be in the “canceled” state, although nowhere is the word “canceled” anywhere. Here we throw the reception and do nothing. The problem is that when you read someone else's code with a lot of options - even if you knew about these options 10 minutes ago - you still forget what happens here. So do not write.Cancellation
Task.Factory.StartNew(() =>
{
throw new OperationCanceledException();
});
Failed
The third parameter at the start of the task is kancellation. You write OperationCanceledException, that is, a special action that puts task in the “Canceled” state. In this case, the task will be in the “Failed” state, because not all OperationCanceledExceptionare equal.Task.Factory.StartNew(() =>
{
throw new OperationCanceledException(cancellationToken);
}, cancellationToken);
Canceled
For task to be able to Canceled, you need to throw it OperationCanceledExceptionalong with its CancellationToken. In reality, you never explicitly do this, but do it this way:Task.Factory.StartNew(() =>
{
cancellationToken.ThrowIfCancellationRequested();
}, cancellationToken);
Canceled
Is it necessary to distinguish cancellationToken? Somewhere inside the task, you check that someone deleted you: throw throw cancellation, then the task goes into state Canceled. Or someone clicked “Cancel” at run time and canceled the task. Our practice at JetBrains suggests that you do not need to distinguish between these tokens. If you get an OperationCanceledException - a special kind that occurs when some cancellation has occurred, you can distinguish it. In this case, you just need to complete the task normally, do not log in, and when you receive the execution - log in.Deep stack
Task.Factory.StartNew(() =>
{
Foo();
}, cancellationToken);
void Foo() {
Bar() {
...
Baz() {
}
}
}
Let's say you have a deep stack. This CancellationTokenis the only explicit parameter that we discussed. It must be transmitted everywhere through absolutely all hierarchies. What should I do if, in the presence of a deep hierarchy, you need to cancel your task somewhere, at the very lowest level, to throw out the reception? There is such a special trick that we use. He is called AsyncLocal.static AsyncLocal<Cancelation> asyncLocalCancellation;
Task.Factory.StartNew(() =>
{
asyncLocalCancellation.Set(cancellationToken)
Foo();
}, cancellationToken);
void Foo() {
async Bar() {
...
Baz() {
asyncLocalCancellation.Value.CheckForInterrupt();
}
}
}
This is the same as, ThreadStaticonly the special ThreadLocalone that survives async / await code trips. Since your code is asynchronous, and you have this kancellation, you put it in AsyncLocal, and somewhere at a deep level you can say " CheckForInterrupt Throw If Cancellation Requested". Again, this is the only parameter CancellationTokenthat needs to completely smear the entire code, but, in my opinion, for most tasks you just need to know what happened OperationCanceledException, and from this draw a conclusion which state: Canceled or Failed.Cognitive complexity
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
JetBrains.Lifetimes
lifetime.Start(TaskScheduler, Action)
lifetime.StartMainRead(Action)
lifetime.StartMainWrite(TaskScheduler, Action)
lifetime.StartBackgroundRead(TaskScheduler, Action)
The more difficult the code is to read when starting the task, the higher the risk of error. Looking at the code after a year, you will forget what it does, because there are a large number of parameters. But we have the JetBrains.Lifetimes library , which offers modern lifetimes, well-optimized CancellationToken, with which the Start method was rewritten and the problem with repeating pieces of code was solved, as with Task.Factory.StartNewand TaskCreationOptions.There are a small number of schedulers that allow you to schedule a task on the main thread with read lock. That is, read lock is not something that you choose explicitly, it is a special scheduler that schedules your code on the main thread with read lock, as well as the main thread with write lock, background thread - and now the methods become very simple to start the shuffle. At the same time, lifetimes automatically cancel through AsyncLocal, significantly simplifying the code. Let's see how async / await solve these problems, and what problems they introduce.In this example, part of the code is executed synchronously, then await and asynchronous code. Firstly, it’s good that there are much fewer repeating pieces of code ( boiler-plate ). Secondly, it’s good that asynchronous code is very similar to synchronous code, this is exactly what async / await is for . You can write asynchronously in the same way as you wrote synchronously, without taking up threads.What in this case will the compiler deploy? The synchronous code will execute synchronously, after which the task
Let's see how async / await solve these problems, and what problems they introduce.In this example, part of the code is executed synchronously, then await and asynchronous code. Firstly, it’s good that there are much fewer repeating pieces of code ( boiler-plate ). Secondly, it’s good that asynchronous code is very similar to synchronous code, this is exactly what async / await is for . You can write asynchronously in the same way as you wrote synchronously, without taking up threads.What in this case will the compiler deploy? The synchronous code will execute synchronously, after which the task InnerAsyncwill execute synchronously , where does the special GetAwaiter object come from. In this case, we are interested TaskAwaiter. You can write your awaiter for absolutely any object. As a result, we wait for the task to complete InnerAsyncand synchronously execute it continuationCode. If the task did not complete, then continuationCode is scheduled on the Context scheduler . It may be that, even though you wrote await , absolutely everything will be called synchronously.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync();
await Task.Yield();
continuationCode();
}
There is one trick Task.Yield- this is a special task that ensures that its awaiter will not always return to you IsCompleted. Accordingly, continuationit will not be called synchronously in this place. For a UI thread, this can be important because you do not take this thread for a large amount of time. How to choose a thread for continuation? The async / await philosophy is this: you write asynchronous code the same as synchronous. If you have a thread pool , it makes no difference to you - continuationCode will be executed on another thread. Regardless of whether it was
How to choose a thread for continuation? The async / await philosophy is this: you write asynchronous code the same as synchronous. If you have a thread pool , it makes no difference to you - continuationCode will be executed on another thread. Regardless of whether it was InnerAsynccompleted when you said await or not, you need everything to execute on the UI thread.The mechanism for task await is as follows: it is taken static, it is calledSynchronizationContextand from it is created TaskScheduler. SynchronizationContext is a thing with the Post method, which is very similar to the method Queue. In fact TaskScheduler, which was earlier, it simply takes SynchronizationContextand through Post performs its task on it.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(false);
continuationCode();
}
There is a way to change this behavior using a parameter ContinueOnCapturedContext. The most disgusting API that is in .NET is called ConfigureAwait. In this case, the API creates a special awaiter that is different from TaskAwaiterthat that shifts the continuation, it runs on the same thread, in the same context in which the method ended InnerAsync and where the task ended.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
There is an insane amount of advice on the Internet: if you have a deadlock , please smear all your ConfigureAwait code and everything will be fine. This is the wrong way. ConfigureAwaitcan be used in cases where you want to slightly improve performance, or at the end of the method, in some library methods.Deadlocks
async Task MyFuncAsync() {
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
myFuncAsync().Wait()
This is a classic deadlock . On the UI thread, they waited ten seconds and did Wait. Due to what you have done Wait, it continuationCodewill never be launched, Waittherefore , it will never return. All of it takes place at the very beginning.async Task OnBluttionClick() {
int v = Button.Text.ParseInt();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
Button.Text.Set((v+1).ToString());
}
myFuncAsync().Wait()
Imagine that this is some real activity. We clicked on the button, took it Button.ParseInt, made await , wrote ConfigureAwaitWe say: "Please do not close our UI stream, perform the continuation." The problem is that we want the second part after ConfigureAwaitalso to be executed on the UI thread, because this is the philosophy of await . That is, your asynchronous code looks the same as synchronous code, and runs in the same context. In this case, of course, there will be an error. And besides Button.Text.Setthere can be any number of method calls that also assume their context. What to do in this situation? You can do this:async Task MyFuncAsync() {
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
PumpUntil(() => task.IsCompleted);
With a UI thread, you must prohibit doing it Waiton threads that have a common message queue. Instead of doing Waitor writing ConfigureAwait, you can pump this queue of messages, and at the same time, the continuum will also be pumped. If you can not mix synchronous and asynchronous code, then you should not mix them. But sometimes this can not be avoided.For example, you have old code, and you have to mix them, then you pump the UI stream. Visual Studio pumps the UI thread on expectations, it even SynchronizationContextchanged a little. If you go into WaitHandle on any Wait, then when you hang, your UI stream is pumped. Thus, they choose between deadlocks and races in favor of race s.Pumpuntil- This is a non-ideal API, that is, when you perform random continuity in an arbitrary place, there may be nuances. There is no other way, unfortunately. Mix synchronous and asynchronous codes. If anything, the whole Rider is so arranged in the old places, so sometimes there are nuances too.Change context
async Task MyFuncAsync() {
synchronousCode();
await myTaskScheduler;
continuationCode();
}
There is another interesting way to use async / await . You can write Awaiteron schedulerand jump on threads. I read posts in Visual Studio, they wrote for a very long time that it’s not good to jump back and forth in the middle of the method, but now they do it themselves. Visual Studio has an API that jumps on threads through schedulers. For normal use, doing this is not good.Structured concurrency
async Task MyFuncAsync() {
synchronousCode();
await Task.Factory.StartNew(() => {...}, myTaskScheduler);
continuationCode();
}
For convenient immersion in the new context and return to the old, some structural competition, or structural parallelism, should be built. For example, in the sixties, the GoTo operator was considered harmful because it violated structurality. So it is here. Jumping on threads violates the structural. Surprisingly, using a async state machine seems like a good way out. That is, where your usual structure is violated, you jump on GoTo, you can violate thread structure: do await , mix it with tags. This is an extremely strange and rare situation when you need to do this. Still, it is better when await returns to the same context. Thus, the thread pool will not have the same thread, but the same context as it was originally.Sequential behavior
Why is await not the same as parallel execution? Await execution is sequential execution. In this case, we start the first task, wait for it, start the second task - we wait. We have no parallelism. For most uses, parallelism is not needed. Parallelism itself is more complex than sequence. Serial code is simpler than parallel, it is an axiom. But sometimes you need to run something in parallel code, and you do it like this:async Task MyAsync() {
var task1 = StartTask1Async();
await task1;
var task2 = StartTask2Async();
await task2;
}
Concurrent behavior
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}
Here the tasks start in parallel. It is clear that methods can return task immediately in a running state, then there will be no parallelism. Let's say that both tasky throw an execution. And you waited for the first task, then on the first await took off. That is, as soon as you wrote await task1, you took off and did not process exception task2. Interestingly, this is absolutely valid code. And it is this code that led .NET to the fact that in version 4.5 the behavior of working with executions has changed.Exception handling
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}
Previously, unhandled executions simply threw the process, and if you didn’t catch some execution in UnobservedExceptionHandler(this is also some staticthat you can attach to schedulers), then this process did not execute. Now this is absolutely valid code. Although .NET changed its behavior, it retained the setting to return the behavior in the opposite direction.async Task MyAsync(CancellationToken cancellationToken) {
await SomeTask1 Async(cancellationToken);
await Some Task2Async( cancellation Token);
}
try {
await MyAsync( cancellation Token);
} catch (OperationException e) {
} catch (Exception e) {
log.Error(e);
}
See how the processing of the execution goes. CancellationToken-s must be transmitted, it is necessary to "smear" CancellationToken-s all the code. The normal behavior of async is that you do not check anywhere Task.Status ancellationToken, you work with asynchronous code in the same way as with synchronous. That is, in the case of a cancellation, you get an execution, and in this case, you do nothing when you receive it OperationCanceledException.The difference between the status of Canceled and Faulted is that you did not receive OperationCanceledException, but the usual execution. And in this case, we can pledge it, you just need to get an execution and draw conclusions based on this. If you started the task explicitly, through Task, you would have flown AggregateException. And in async, in the case they AggregateExceptionalways throw the very first execution that was in it (in this case - OperationCanceled).In practice
Synchronous method
DataTable<File, ProcessedFile> sharedMemory;
void SynchronousWorker(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
For example, a demon works in ReSharper - an editor that tints the file for you. If the file is opened in the editor, then there is some activity that puts it in a blocking queue. Our process workerreads from there, after which it performs a bunch of different tasks with this file, tints it, parses, builds, after which these files are added to sharedMemory. With a sharedMemorylock, other mechanisms are already working with it.Asynchronous method
When rewriting code to asynchronous, we will first of all replace it voidwith async Task. Be sure to write the word “Async” at the end. All asynchronous methods must end in Async - this is a convention.DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
After that, you need to do something with ours blockingQueue. Obviously, if there is some synchronous primitive, then there must be some asynchronous primitive. This primitive is called channel: the channels that live in the package
This primitive is called channel: the channels that live in the package System.Threading.Channels. You can create channels and queues, limited and unlimited, which you can wait asynchronously. Moreover, you can create a channel with a value of "zero", that is, it will not have a buffer at all. Such channels are called rendezvous channels and are actively promoted in Go and Kotlin. And in principle, if it is possible to use channels in asynchronous code, this is a very good pattern. That is, we change the queue to the channel where there are methods ReadAsyncand WriteAsync.ProcessInParallel is a bunch of parallel code that does the processing of a file and turns it intoProcessedFile. Can async help us write not asynchronous, but parallel code more compactly?Simplify Parallel Code
The code can be rewritten in this way:DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
 What do they look like
What do they look like ProcessInParallel? For example, we have a file. First, we break it into lexemes, and we can have two tasks in parallel: building search caches and building a syntax tree. After that comes the task of “searching for semantic errors.” It is important here that all these tasks form a directed acyclic graph. That is, you can run some parts in parallel threads, some cannot, and there are obviously dependencies which task should wait for other tasks. You get a graph of such tasks, you want to somehow scatter them along the threads. Is it possible to write it beautifully, without errors? In our code, this problem was solved several times, each time in a different way. It rarely happens when this code is written without errors. We define this task graph as follows: let's say that each task has other tasks on which it depends, then using the ExecuteBefore dictionary we write the skeleton of our method.
We define this task graph as follows: let's say that each task has other tasks on which it depends, then using the ExecuteBefore dictionary we write the skeleton of our method.Skeleton solutions
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore; async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
return res;
}
If you solve this problem head-on, then you need to do a topological sorting of this graph. Then take a task that has no dependent tasks, execute it, analyze the structure under a lock, see which tasks have no dependent ones. Run, scatter them somehow through Task Runner. We write it a little more compactly: topological sorting of the graph + execution of such tasks on different threads.Async lazy
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore;
async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
var lazy = new Dictionary<Action<ProcessedFile>, Lazy<Task>>();
foreach ((action, beforeList) in ExecuteBefore)
lazy[action] = new Lazy<Task>(async () =>
{
await Task.WhenAll(beforeList.Select(b => lazy[b].Value))
await Task.Yield();
action(res);
}
await Task.WhenAll(lazy.Values.Select(l => l.Value))
return res;
}
There is a pattern called Async Lazy. We create ours ProcessedFileon which different actions should be executed. Let's create a dictionary: we will format each of our stage (Action ProcessedFile) into some Task, or rather, into Lazy from Task and run along the original graph. The variable actionwill have the action itself , and in beforeList - those actions that must be performed before ours. Then create Lazyfrom action. We write in Task await. Thus, we are waiting for all the tasks that must be completed before it. In beforeList, select the one Lazythat is in this dictionary.Please note that here nothing will be executed synchronously, so this code will not fall on ItemNotFoundException in Dictionary. We carry out all the tasks that were before ours, performing a search by actionLazy Task. Then we execute our action. In the end, you just need to ask each task to start, otherwise you never know if something did not start. In this case, nothing started. This is the solution. This method is written in 10 minutes, it is absolutely obvious.Thus, asynchronous code made our decision, initially it occupied a couple of screens with complex competitive code. Here he is absolutely consistent. I don’t even use it ConcurrentDictionary, I use the usual one Dictionary, because we do not write anything to it competitively. There is a consistent, consistent code. We solve the problem of writing parallel code using async-s beautifully, which means - without bugs.Get rid of locks
DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Is it worth pulling in async and these locks? Now there are all kinds of async locks, async semaphores, that is, an attempt to use the primitives that are in synchronous and asynchronous code. This concept seems to be wrong, because with the lock you protect something from parallel execution. Our task is to translate parallel execution into sequential, because it is easier. And if it’s easier, there are fewer errors.Channel<Pair<File, ProcessedFile>> output;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
await output.WriteAsync();
}
We can create some channel and put there a couple of File and ProcessedFile, and ReadAsyncsome other procedure will process this channel , and it will do it sequentially. Lock itself, in addition to protecting the structure, essentially linearizes access, a place where all threads from consecutive ones become parallel. And we are replacing this explicitly with the channel. The architecture is as follows: workers receive files from
The architecture is as follows: workers receive files from inputand send them somewhere to the processor, which also processes everything sequentially, there is no parallelism. The code looks much simpler. I understand that not everything can be done in this way. Such an architecture, when you can build data pipes, does not always work. It may be that you have a second channel that comes into your processor and not acyclic directed graph is formed from the channels, but a graph with cycles. This is an example that Roman Elizarov told KotlinConf in 2018. He wrote an example on Kotlin with these channels, and there were cycles there, and this example was shut down. The problem was that if you have such cycles in a graph, then everything becomes more complicated in the asynchronous world. Asynchronous deadlocks are bad in that they are much more difficult to solve than synchronous when you have a stack of threads, and it’s clear what hung on. Therefore, it is a tool that must be used correctly.
It may be that you have a second channel that comes into your processor and not acyclic directed graph is formed from the channels, but a graph with cycles. This is an example that Roman Elizarov told KotlinConf in 2018. He wrote an example on Kotlin with these channels, and there were cycles there, and this example was shut down. The problem was that if you have such cycles in a graph, then everything becomes more complicated in the asynchronous world. Asynchronous deadlocks are bad in that they are much more difficult to solve than synchronous when you have a stack of threads, and it’s clear what hung on. Therefore, it is a tool that must be used correctly.Summary
- Avoid synchronization in asynchronous code.
- Serial code is simpler than parallel.
- Asynchronous code can be simple and use a minimum of parameters and an implicit context that change its behavior.
If you have developed the habit of writing synchronous code, and even if the asynchronous code is very similar to the synchronous one, you don’t need to drag primitives there, which you are used to in synchronous code like async mutex. Use feeds, if possible, and other Message passing primitives .Serial code is simpler than parallel. If you can write your architecture so that it looks sequentially, without running parallel code and locking, then write the architecture sequentially.And the last thing that we saw from a large number of examples with tasks. When you design your system, try to rely less on implicit context. Implicit context leads to a misunderstanding of what is happening in the code, and you can forget about implicit problems in a year. And if another person works on this code and redo something in it, this can lead to difficulties that you once knew about, and the new programmer does not know because of the implicit context. As a result, poor design is characterized by a large number of parameters, their combination and implicit context.What to read
-10 . DotNext .