Thousands of managers from sales offices across the country record tens of thousands of contacts in our CRM system every day - facts of communication with potential or already working with us customers. And for this client you must first find, and preferably very quickly. And this happens most often by name.Therefore, it is not surprising that, once again analyzing “heavy” requests at one of the most loaded databases — our own corporate VLSI account , I found “in the top” a request for a “quick” search by name for company cards.Moreover, a further investigation revealed an interesting example of optimization and then degradation of performance request in its subsequent refinement by several teams, each of which acted solely from well-meaning.0: what did the user want
[KDPV from here ]What does the user usually mean when he says “quick” search by name? Almost never it turns out to be an “honest” search on a substring of the type ... LIKE '%%'- because then not only and , but even even get the result . The user implies at the household level that you will provide him with a search at the beginning of a word in the title and show more relevant what begins with the entered one. And do it almost instantly - with interlinear input.''' '''' '1: limit the task
And even more so, a person will not specifically enter ' 'so that you have to search for every word prefix. No, it’s much easier for the user to respond to a quick hint for the last word than to deliberately “miss” the previous ones - see how any search engine works.In general, correctly formulating requirements for a task is more than half the solution. Sometimes careful analysis of the use case can significantly affect the result .What does the abstract developer do?1.0: external search engine
Oh, searching is difficult, I don’t want to do anything at all - let's give it to devops! Let them deploy to us an external search engine relative to the database: Sphinx, ElasticSearch, ... Aworking, albeit time-consuming, option in terms of synchronization and speed of change. But not in our case, since the search is carried out for each client only within the framework of his account data. And the data has a rather high variability - and if the manager has now inserted the card ' ', then after 5-10 seconds he can already remember that he forgot to indicate the email there and want to find and correct it.Therefore - let's search "directly in the database . " Fortunately, PostgreSQL allows us to do this, and not just one option - we’ll consider them.1.1: “honest” substring
We cling to the word "substring." But exactly for index search by substring (and even by regular expressions!) There is an excellent module pg_trgm ! Only then it will be necessary to sort correctly.Let's try to take a plate for simplicity of the model:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
We fill in there 7.8 million records of real organizations and index:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
Let’s look for the first 10 entries for interline search:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
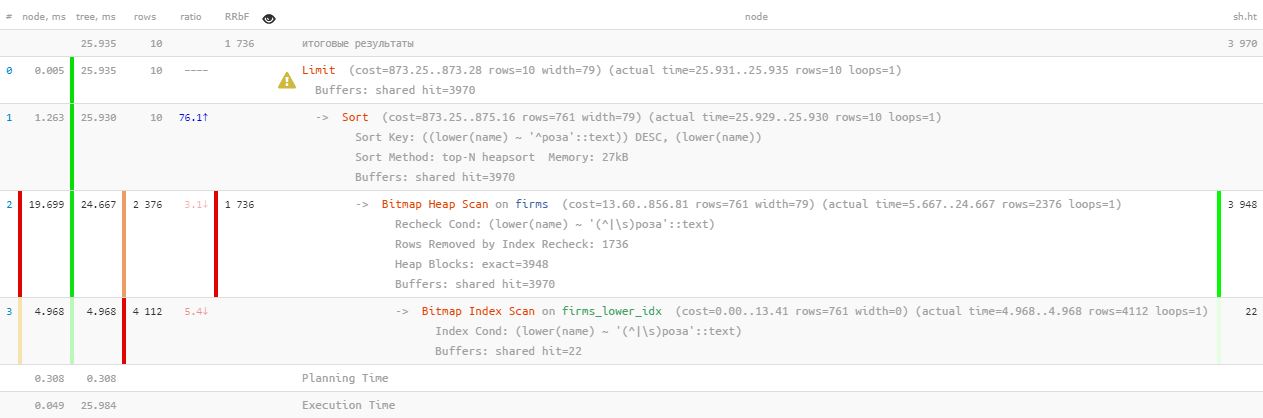 [take a look at explain.tensor.ru]Well, that’s ... 26ms, 31MB of read data and more than 1.7K filtered records - for 10 people. The overhead is too high, is it possible to be somehow more efficient?
[take a look at explain.tensor.ru]Well, that’s ... 26ms, 31MB of read data and more than 1.7K filtered records - for 10 people. The overhead is too high, is it possible to be somehow more efficient?1.2: text search? it's FTS!
Indeed, PostgreSQL provides a very powerful mechanism for full text search (Full Text Search), including the possibility of prefix search. A great option, even extensions do not need to be installed! Let's try:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [look at explain.tensor.ru]Here parallelization of query execution helped us a bit, reducing the time by half to 11ms . Yes, and we had to read 1.5 times less - only 20MB . And here, the smaller the better, because the larger the amount we subtract, the higher the chances of getting cache miss, and every extra data page read from disk is a potential “brake” for the request.
[look at explain.tensor.ru]Here parallelization of query execution helped us a bit, reducing the time by half to 11ms . Yes, and we had to read 1.5 times less - only 20MB . And here, the smaller the better, because the larger the amount we subtract, the higher the chances of getting cache miss, and every extra data page read from disk is a potential “brake” for the request.1.3: Still LIKE?
The previous request is good for everyone, but only if you pull it a hundred thousand times a day, then 2TB of read data will run up . At best - from memory, but if you are not lucky, then from the disk. So let's try to make it smaller.Recall that the user wants to see first "that begin with ..." . So this is in its pure form a prefix search with text_pattern_ops! And only if we are "not enough" up to 10 required records, then we will have to read them using the FTS search:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
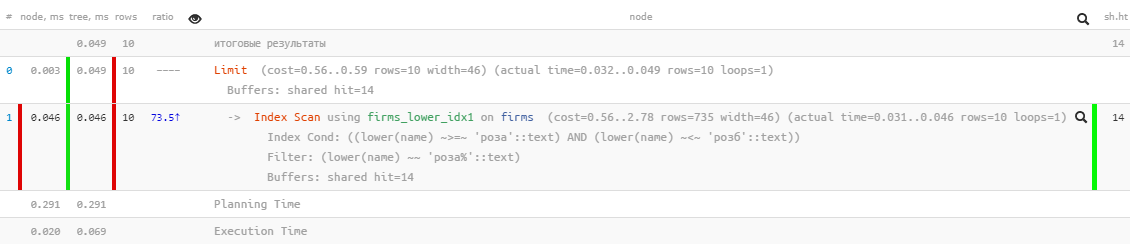 [look at explain.tensor.ru]Excellent performance - just 0.05ms and a little over 100KB read! Only we forgot to sort by name so that the user does not get lost in the results:
[look at explain.tensor.ru]Excellent performance - just 0.05ms and a little over 100KB read! Only we forgot to sort by name so that the user does not get lost in the results:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
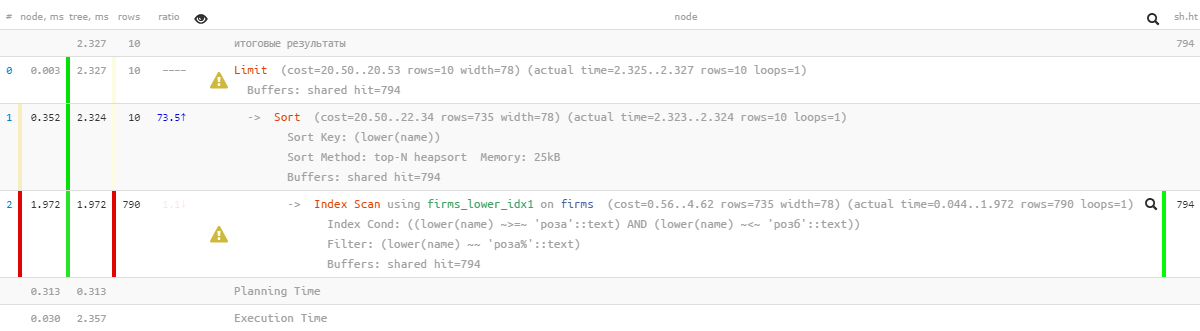 [look at explain.tensor.ru]Oh, something is not so pretty anymore - it seems that there is an index, but sorting flies past it ... It, of course, is many times more effective than the previous version, but ...
[look at explain.tensor.ru]Oh, something is not so pretty anymore - it seems that there is an index, but sorting flies past it ... It, of course, is many times more effective than the previous version, but ...1.4: “modify with a file”
But there is an index that allows you to search by range, and it’s normal to use sorting - normal btree !CREATE INDEX ON firms(lower(name));
Only a request for it will have to be “manually assembled”:SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [look at explain.tensor.ru]Great - both sorting works and resource consumption remains “microscopic”, thousands of times more efficient than “pure” FTS ! It remains to collect in a single request:
[look at explain.tensor.ru]Great - both sorting works and resource consumption remains “microscopic”, thousands of times more efficient than “pure” FTS ! It remains to collect in a single request:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
I note that the second subquery is only executed if the first returned less than theLIMIT number of rows expected by the last . I already wrote about this method of query optimization .So yes, we now have btree and gin on the table at the same time, but statistically it turned out that less than 10% of the requests reach the second block . That is, with such well-known typical limitations for the task, we were able to reduce the total server resource consumption by almost a thousand times!1.5 *: dispense with the file
Above LIKEwe were prevented from using the wrong sort. But it can be "set on the true path" by specifying the USING statement:The default is implied ASC. In addition, you can specify the name of a specific sort operator in a sentence USING. The sort operator must be a member of less than or greater than a certain family of B-tree operators. ASCusually equivalent USING <and DESCusually equivalent USING >.
In our case, “less” is ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [look at explain.tensor.ru]
[look at explain.tensor.ru]2: how to "sour" requests
Now we leave our request to “insist” for half a year or a year, and with surprise we again find it “in the top” with indicators of the total daily “pumping” of memory ( buffers shared hit ) in 5.5TB - that is, even more than it was originally.No, of course, our business has grown, and the load has increased, but not so much! So something is dirty here - let's figure it out.2.1: the birth of paging
At some point, another development team wanted to make it possible to “jump” into the registry from a quick subscript search with the same, but expanded results. And what registry without page navigation? Let's screw it!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
Now it was possible without straining for the developer to show the registry of search results with "type-page" loading.Of course, in fact, for each next page of data, more and more is being read (all of the previous time, which we discard, plus the desired “tail”) - that is, this is an unambiguous antipattern. And it would be more correct to start the search at the next iteration from the key stored in the interface, but about it - another time.2.2: want exotic
At some point, the developer wanted to diversify the resulting selection with data from another table, for which purpose the entire previous request was sent to the CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
And even so - not bad, because a subquery is calculated only for 10 returned records, if not ...2.3: DISTINCT meaningless and merciless
Somewhere in the process of such an evolution, a condition was lostNOT LIKE from the 2nd subquery . It is clear that after that I UNION ALLbegan to return some records twice - first found at the beginning of the line, and then again - at the beginning of the first word of this line. In the limit, all records of the 2nd subquery could coincide with the records of the first.What does a developer do instead of searching for a reason? .. No question!- double the size of the original samples
- put DISTINCT so that we get only single instances of each row
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
That is, it is clear that the result, in the end, is exactly the same, but the chance to “fly” to the 2nd CTE subquery has become much higher, and without this, it is clearly read more .But this is not the saddest thing. Since the developer asked me to select DISTINCTnot by specific, but immediately by all fields of the record, then the sub_query field - the result of the subquery - got there automatically. Now, for execution DISTINCT, the database had to execute not 10 subqueries, but all <2 * N> + 10 !2.4: cooperation above all!
So, the developers lived - they didn’t bother, because in the registry they were "patched up" to significant N values with a chronic slowdown in receiving each next "page".Until developers from another department came to them, and did not want to use such a convenient method for iterative search - that is, we take a piece from some sample, filter by additional conditions, draw the result, then the next piece (which in our case is achieved by increase N), and so on until we fill the screen.In general, in the caught specimen N reached values of almost 17K , and in just 24 hours at least 4K such requests were executed “in the chain”. The last of them boldly scanned already1GB of memory at each iteration ...