I have long known about the Have I Been Pwned (HIBP) site . True, until recently, he had never been there. I always had two passwords. One of them was repeatedly used for garbage mail and a couple of accounts on strange sites. But I had to refuse it, because the mail was hacked. And to be honest, I’m grateful to the hacker because this event made me review my passwords - the way I use and store them.Of course, I changed passwords on all accounts where there was a compromised password. Then I wondered if the leaked password was in the HIBP database. I did not want to enter the password on the site, so I downloaded the database (pwned-passwords-sha1-ordered-by-count-v5) The base is very impressive. This is a 22.8 GB text file with a set of SHA-1 hashes, one in each line with a counter, how many times the password with this hash occurred in leaks. I figured out the SHA-1 of my cracked password and tried to find it.Contents
[G] rep
We have a text file with a hash in each line. Probably the best place to go is grep.grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtMy password was at the top of the list with a frequency of more than 1,500 times, so it really sucks. Accordingly, the search results returned almost instantly.But not everyone has weak passwords. I wanted to check how long it would take to find the worst case scenario - the last hash in the file:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtResult: 33,35s user 23,39s system 41% cpu 2:15,35 totalThis is sad. After all, since my mail was hacked, I wanted to check the presence of all my old and new passwords in the database. But a two-minute grep simply does not allow you to comfortably do this. Of course, I could write a script, run it and go for a walk, but this is not an option. I wanted to find a better solution and learn something.Trie structure
The first idea was to use a trie data structure. The structure seems ideal for storing SHA-1 hashes. The alphabet is small, so the nodes will also be small, as will the resulting file. Maybe it even fits in RAM? Key search should be very fast.So I implemented this structure. Then he took the first 1,000,000 hashes of the source database to build the resulting file and check if everything is in the created file.Yes, I could find everything in the file, so the structure worked well. The problem was different.The resulting file was released in size 2283686592B (2.2 GB). This is not good. Let's count and see what happens. A node is a simple structure of sixteen 32-bit values. The values are "pointers" to the following nodes with the specified SHA-1 hash symbol. So, one node takes 16 * 4 bytes = 64 bytes. It seems to be a little? But if you think about it, one node represents one character in a hash. Thus, in the worst case, the SHA-1 hash will take 40 * 64 bytes = 2560 bytes. This is much worse than, for example, a textual representation of a hash that takes up only 40 bytes.The trie structure has the advantage of reusing nodes. If you have two words aaaand abb, then the node for the first characters is reused, because the characters are the same - a.Let's get back to our problem. Let's calculate how many nodes are stored in the resulting file: file_size / node_size = 2283686592 / 64 = 35682603Now let's see how many nodes will be created in the worst case from a million hashes: 1000000 * 40 = 40000000Thus, the trie structure reuses only 40000000 - 35682603 = 4317397nodes, which is 10.8% of the worst-case scenario.With such indicators, the resulting file for the entire HIBP database would take 1421513361920 bytes (1.02 TB). I don’t even have enough hard drive to check the speed of key search.That day, I found out that the trie structure is not suitable for relatively random data.Let's look for another solution.Binary search
SHA-1 hashes have two nice features: they are comparable to each other and they are all the same size.Thanks to this, we can process the original HIBP database and create a file from the sorted SHA-1 values.But how to sort a 22 GB file?Question. Why sort the source file? HIBP returns a file with strings already sorted by hashes.
Answer. I just did not think about it. At that moment I did not know about the sorted file.Sorting
Sorting all the hashes in RAM is not an option; I don't have much RAM. The solution was this:- Split a large file into smaller ones that fit in RAM.
- Download data from small files, sort in RAM and write back to files.
- Combine all small, sorted files into one big one.
With a large sorted file, you can search our hash using a binary search. Hard drive access matters. Let's calculate how many hits are required in a binary search: log2(555278657) = 29.0486367039that is, 30 hits. Not so bad.At the first stage, optimization can be performed. Convert text hashes to binary data. This will reduce the size of the resulting data by half: from 22 to 11 GB. Fine.Why merge back?
At that moment, I realized that you can do smarter. What if you do not combine small files into one large one, but conduct a binary search in sorted small files in RAM? The problem is how to find the desired file in which to look for the key. The solution is very simple. New approach:- Create 256 files with the names "00" ... "FF".
- When reading hashes from a large file, write hashes that begin with “00 ..” to a file called “00”, hashes that begin with “01 ..” - to a file “01” and so on.
- Download data from small files, sort in RAM and write back to files.
Everything is very simple. In addition, another optimization option appears. If the hash is stored in the file “00”, then we know that it begins with “00”. If the hash is stored in the file "F2", then it begins with "F2". Thus, when writing hashes to small files, we can omit the first byte of each hash! This is 5% of all data. 555 MB is saved in total.Parallelism
Separation into smaller files provides another opportunity for optimization. Files are independent of each other, so we can sort them in parallel. We remember that all your processors like to sweat at the same time;)Don't be a selfish bastard
When I implemented the above solution, I realized that other people probably had a similar problem. Probably many others also download and search the HIBP database. So I decided to share my work.Before that, I once again revised my approach and found a couple of problems that I would like to fix before posting the code and tools on Github.Firstly, as an end user, I would not want to use a tool that creates many strange files with strange names, in which it is not clear what is stored, etc.Well, this can be solved by combining the files "00" .. "FF" in one big file.Unfortunately, having one large file for sorting poses a new problem. What if I want to insert a hash in this file? Just one hash. This is only 20 bytes. Oh, the hash starts with "000000000 ..". Okay. Let's free up space for it by moving 11 GB of other hashes ...You understand what the problem is. Inserting data in the middle of a file is not the fastest operation.Another drawback of this approach is that you need to store the first bytes again - it is 555 MB of data.And last but not least, a binary search on data stored on a hard drive is much slower than accessing RAM. I mean, this is 30 disk reads versus 0 disk reads.B3
Again. What we have and what we want to achieve.We have 11 GB of binary values. All values are comparable and have the same size. We want to find out if a particular key is present in the stored data, and also want to change the database. And so that everything works quickly.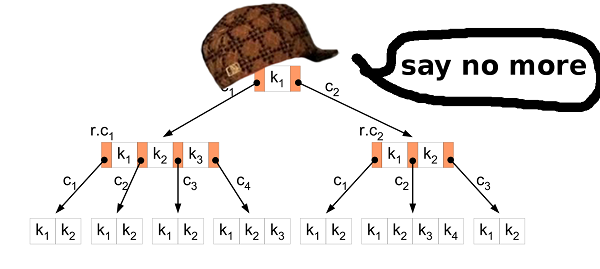 B-tree? RightThe B-tree allows you to minimize access to the disk when searching, modifying, etc. It has much more features, but we need these two.
B-tree? RightThe B-tree allows you to minimize access to the disk when searching, modifying, etc. It has much more features, but we need these two.Insertion Sort
The first step is to convert the data from the HIBP source file to the B-tree. This means that you need to extract all the hashes in turn and insert them into the structure. The usual insertion algorithm is suitable for this. But in our case, you can do better.Inserting a lot of raw data into a B-tree is a well-known scenario. Wise people have invented a better approach for this than the usual insert. First of all, you need to sort the data. This can be done as described above (split the file into smaller ones and sort them in RAM). Then insert the data into the tree.In the usual algorithm, if you find the leaf node where you want to insert the value and it is filled, then you create a new node (on the right) and evenly distribute the values between the two nodes, left and right (plus one value goes to the parent node but it’s not important here). In short, the values in the left node are always less than the values in the right. The fact is that when you insert the sorted data, you know that smaller values will no longer be inserted into the tree, so no more values will go to the left node. The left node remains half empty all the time. Moreover, if you insert enough values, you may find that the right node is full, so you need to move half the values to the new right node. The split node remains half empty, as in the previous case. Etc…As a result, after all the inserts, you get a tree in which almost all the nodes are half empty. This is not a very efficient use of space. We can do better.Separate or not?
In the case of inserting sorted data, you can make a small modification to the insertion algorithm. If the node into which you want to paste the value is full, do not break it. Just create a new, empty node and paste the value into the parent node. Then, when you insert the following values (which are larger than the previous ones), you insert them into a fresh, empty node.To preserve the properties of the B-tree, after all insertions, it is necessary to sort out the rightmost nodes in each layer of the tree (except the root) and evenly divide the values of this extreme node and its left neighbor. So you get the smallest possible tree.HIBP Tree Properties
When designing a B-tree, you need to choose its order. It shows how many values can be stored in one node, as well as how many children the node can have. By manipulating this parameter, we can manipulate the height of the tree, the binary size of the node, etc.In HIBP, we have 555278657hashes. Suppose we want a tree three in height (so we need no more than three read operations to check for the presence of a hash). We need to find a value of M such that logM(555278657) < 3. I chose 1024. This is not the smallest possible value, but it leaves it possible to insert more hashes and preserve the height of the tree.Output file
The HIBP source file has a size of 22.8 GB. The output file with the B-tree is 12.4 GB. It takes about 11 minutes to create it on my machine (Intel Core i7-6700, 3.4 GHz, 16 GB RAM), hard disk (not SSD).Benchmarks
The B-tree option shows a pretty good result:| | time [μs] | % |
| -----------------: | ------------: | ------------: |
| okon | 49 | 100 |
| grep '^ hash' | 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++ line by line | 135'720'201 | 276'980'002 |
okon - library and CLI
As I said, I wanted to share my work with the world. I implemented a library and command line interface for processing the HIBP database and quickly searching for hashes. The search is so fast that it can, for example, be integrated into a password manager and give feedback to the user each time a key is pressed. There are many possible uses.The library has a C interface, so it can be used almost everywhere. CLI is a CLI. You can simply build and run (:The code is in my repository .Disclaimer: okon does not yet provide an interface for inserting values into the created B-tree. It can only process the HIBP file, create a B-tree and search in it. These functions work quite well, so I decided to share the code and continue working on the insert and other possible functions.Links and discussion
Thanks for reading
(: