
In 2019, we witnessed the brilliant use of machine learning. The OpenAI GPT-2 model has demonstrated an impressive ability to write coherent and emotional texts that are superior to our understanding of what modern language models can generate. GPT-2 is not some particularly new architecture - it is very reminiscent of the Transformer-Decoder (decoder-only Transformer). The difference between GPT-2 is that it is a truly huge language model based on Transformer, trained on an impressive data set. In this article, we will look at the architecture of the model that allows us to achieve such results: we will examine in detail the self-attention layer and the use of the decoding Transformer for tasks that go beyond language modeling.
Content
1: GPT-2
?
Word2vec , – , , . – , .
, GPT-2 , , , . GPT-2 40 (WebText), OpenAI . , , SwiftKey, 78 , GPT-2 500 , GPT-2 – 13 ( 6,5 ).

GPT-2 AllenAI GPT-2 Explorer. GPT-2 ( ), .
, – .. . – , - .
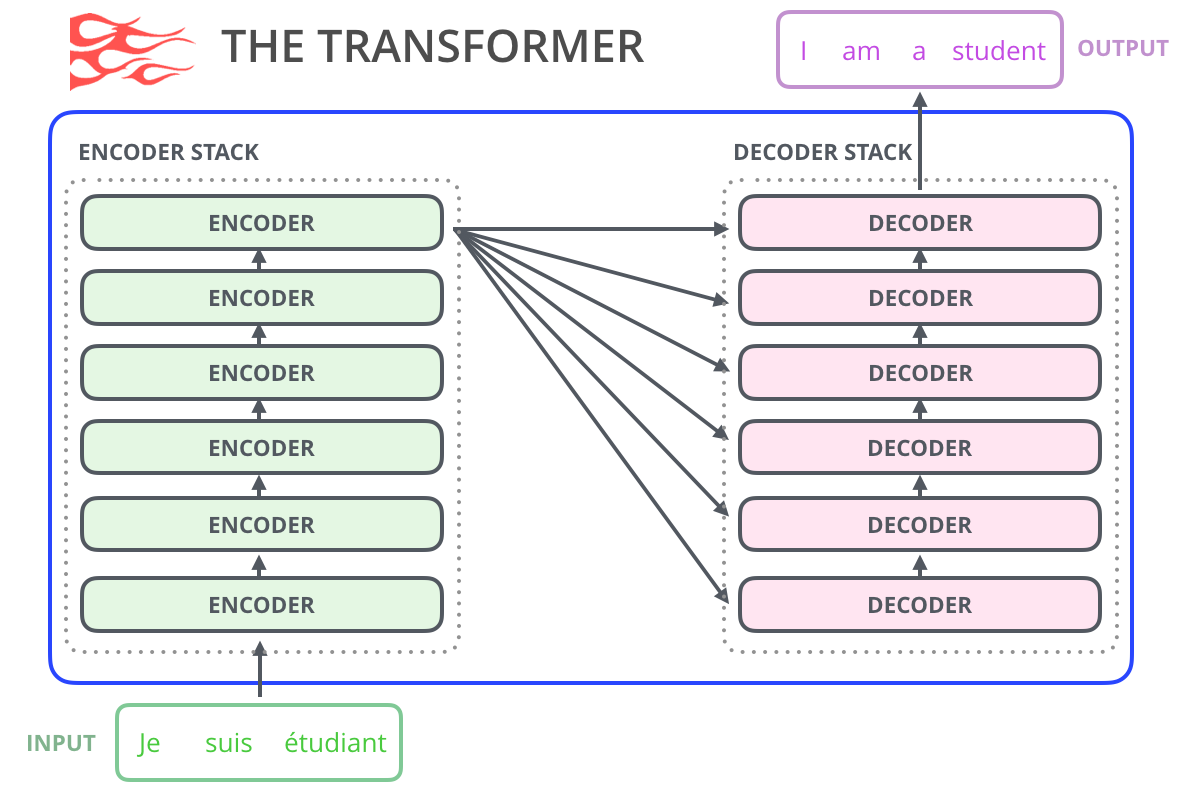
, , , , ( AlphaStar).
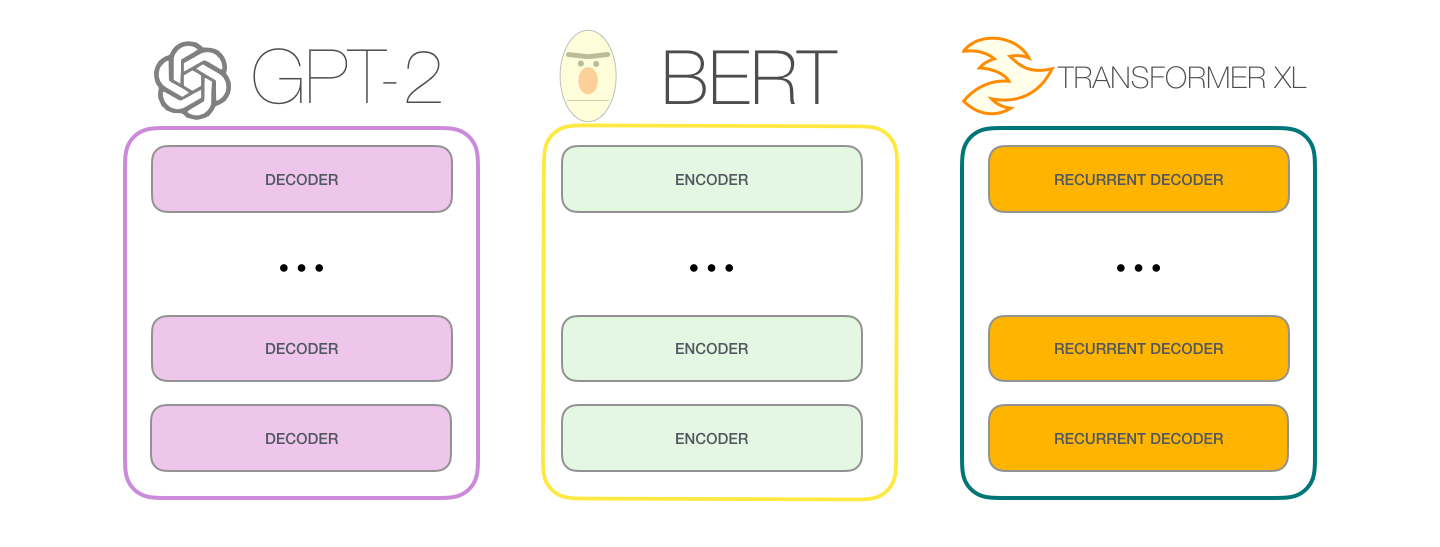
? , GPT-2 :
BERT'
:
, .
GPT-2 . BERT , , . . , GPT-2, , . , GPT-2 :
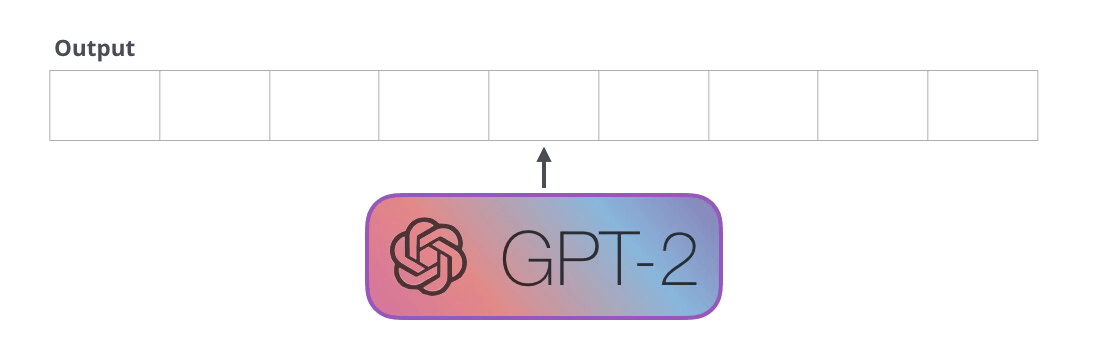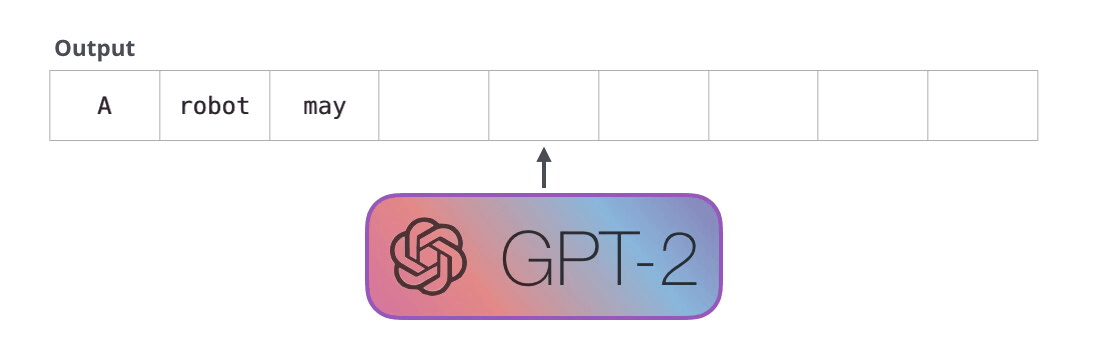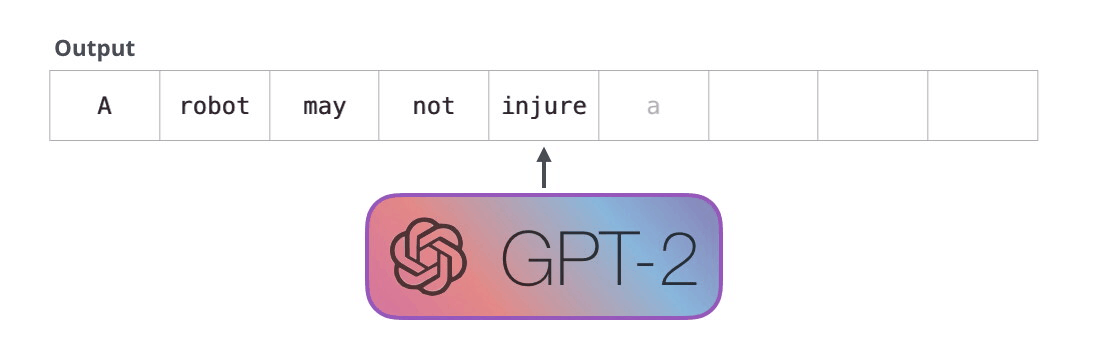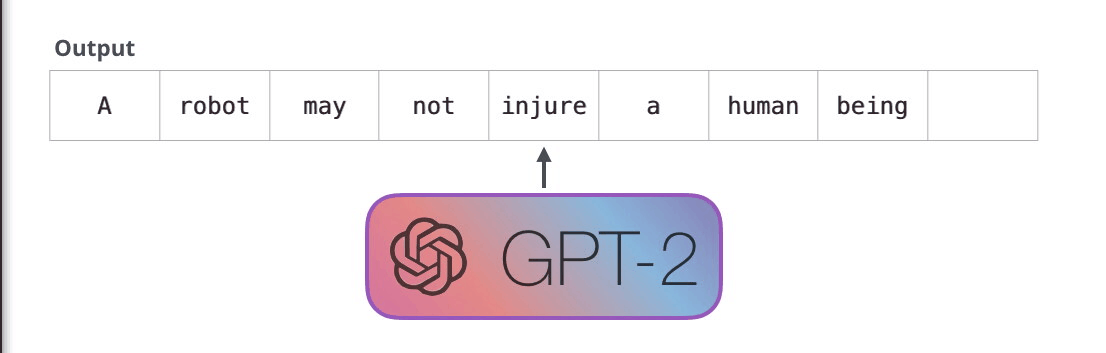
: , , . . «» (auto-regression) RNN .

GPT-2 TransformerXL XLNet . BERT . . , BERT . XLNet , .
.
– :

(, 512 ). , .
– , . :

, [mask] , BERT', , , .
, , #4, , :
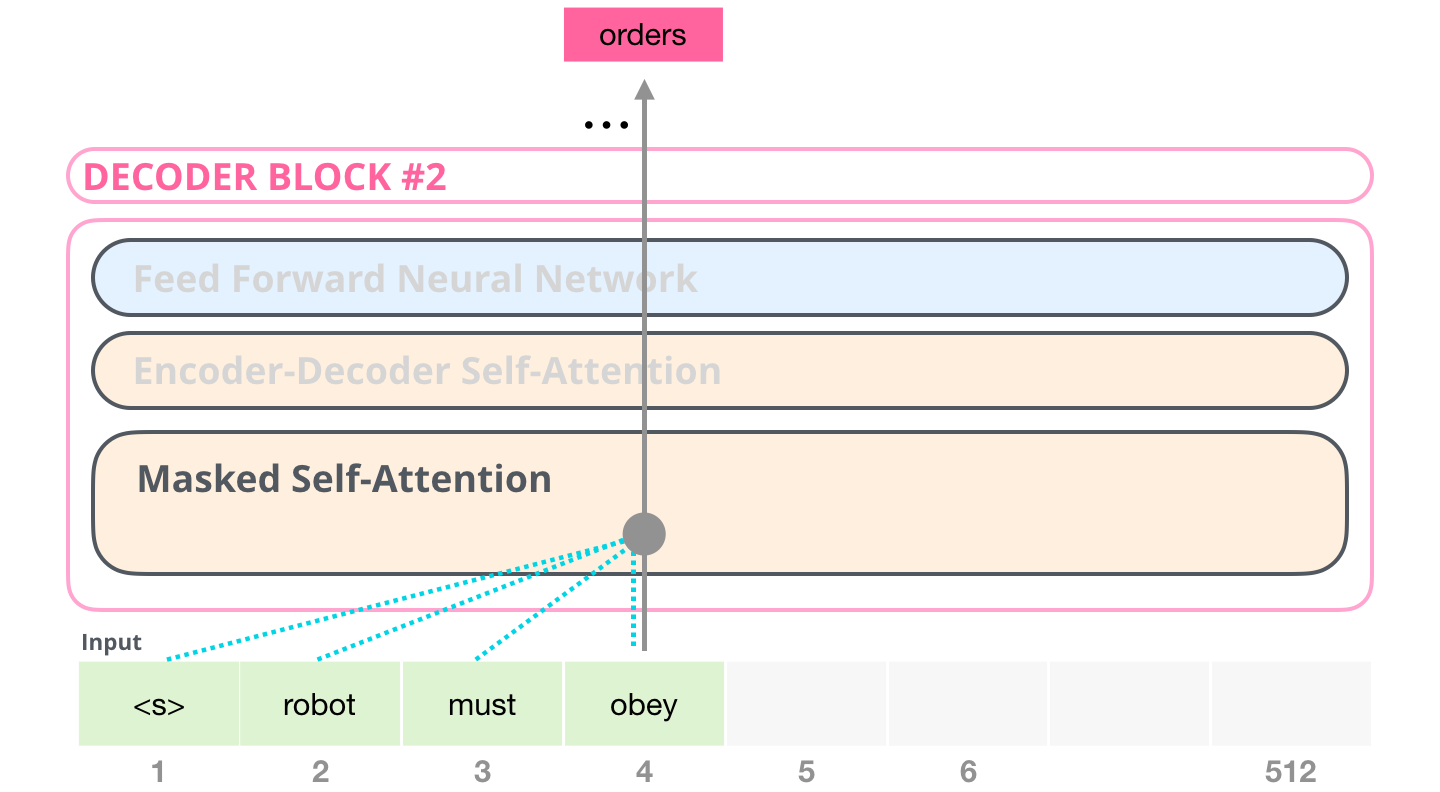
, BERT, GPT-2. . :
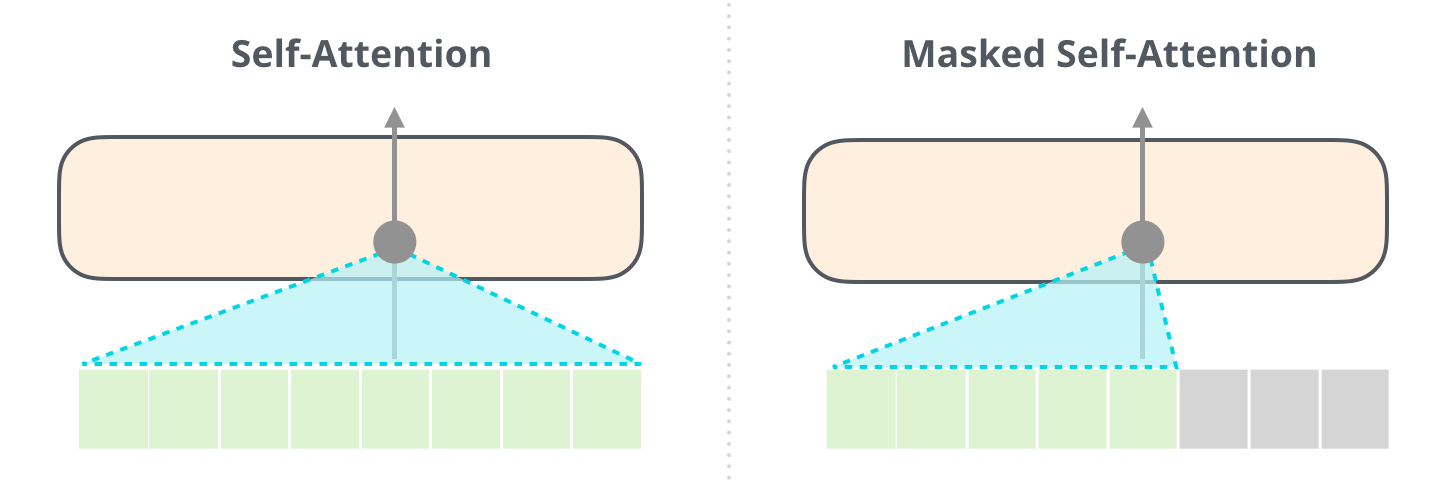
, «Generating Wikipedia by Summarizing Long Sequences» , : . «-». 6 :
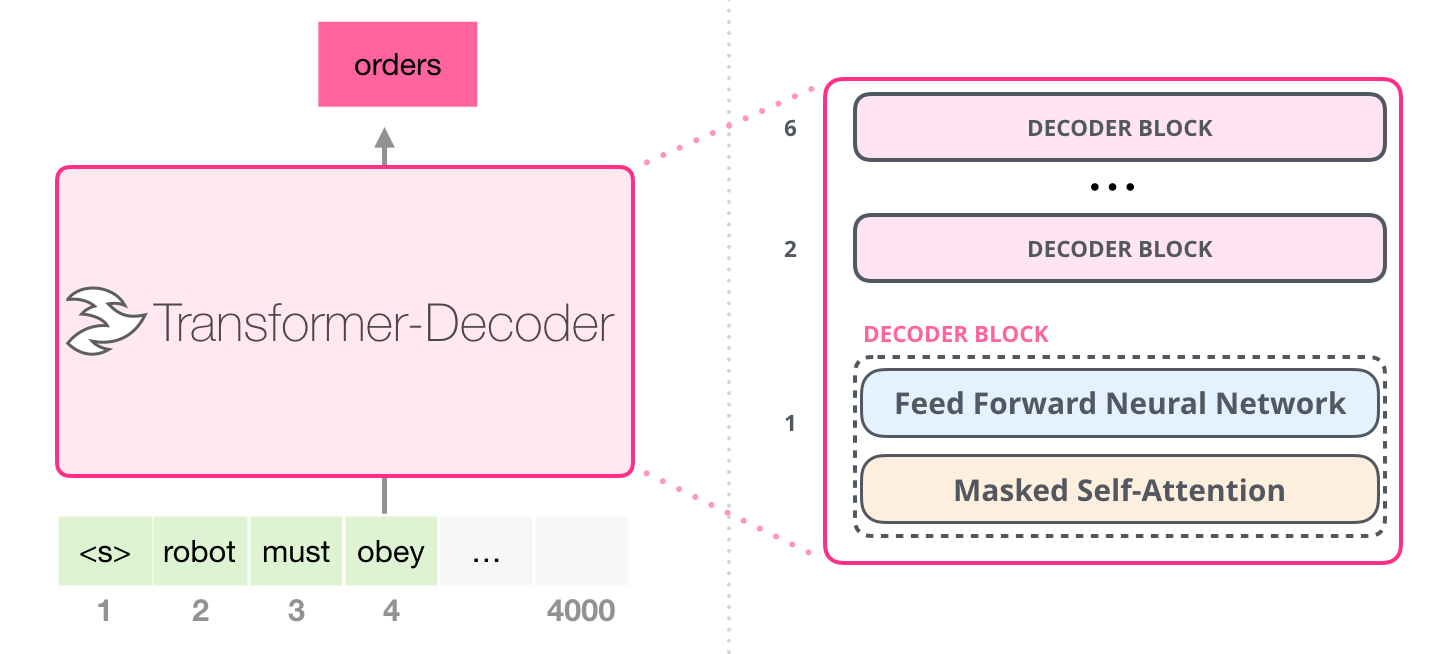
. , . , 4000 – 512 .
, , . « », / .
GPT-2 OpenAI .
- : GPT-2
, , . , , , , . (Budgie)
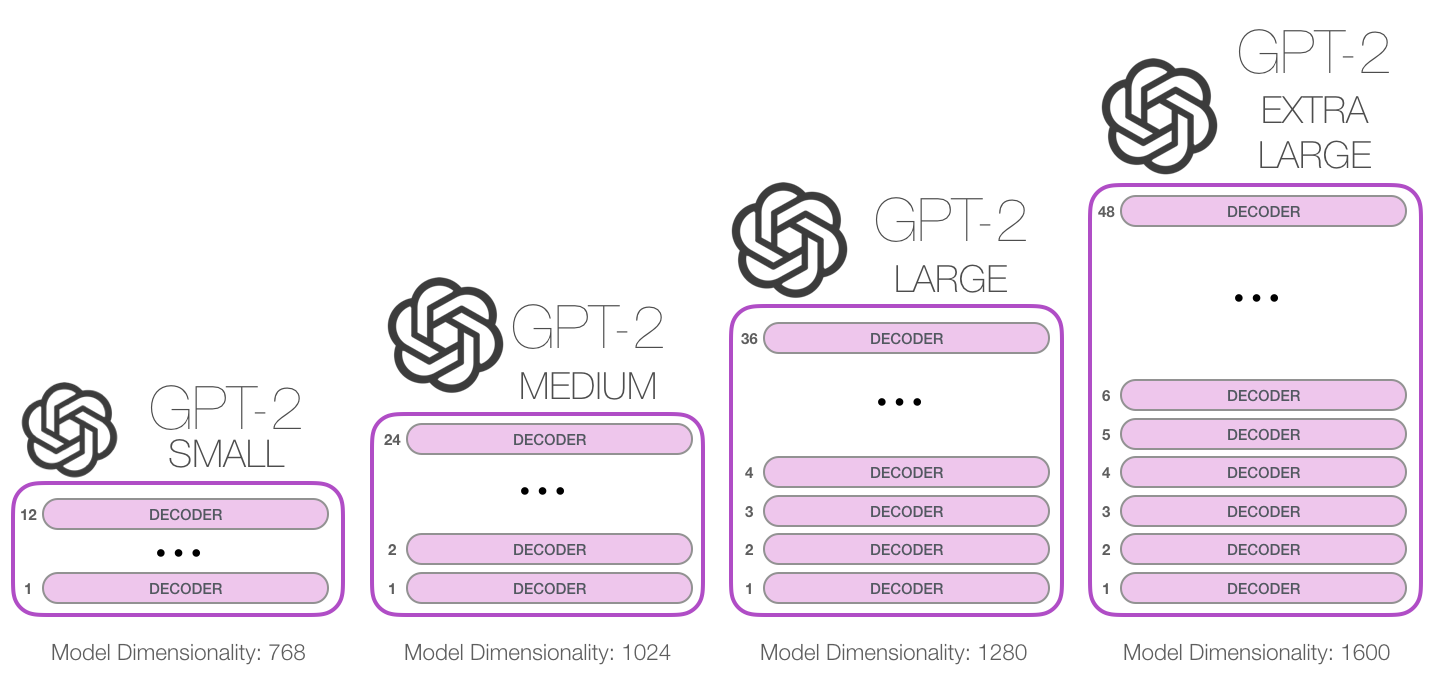
GPT-2 , .

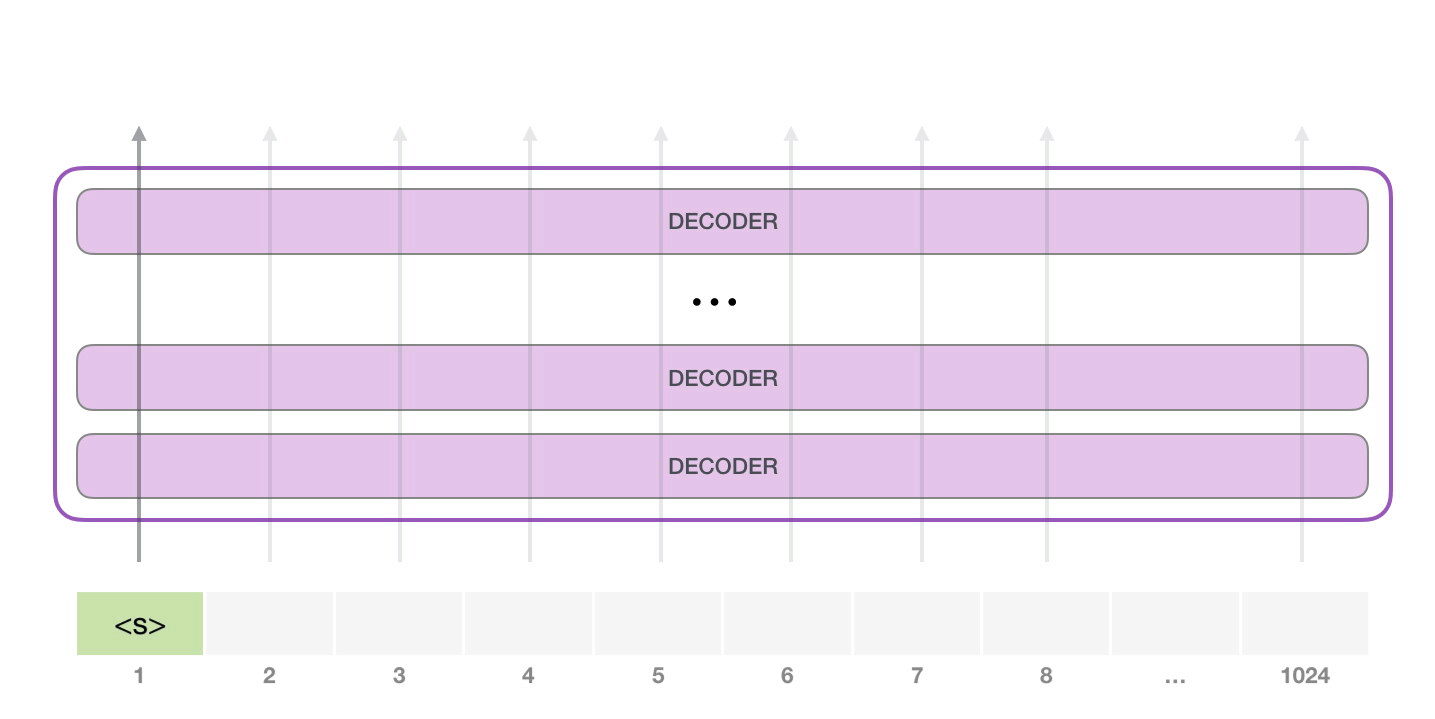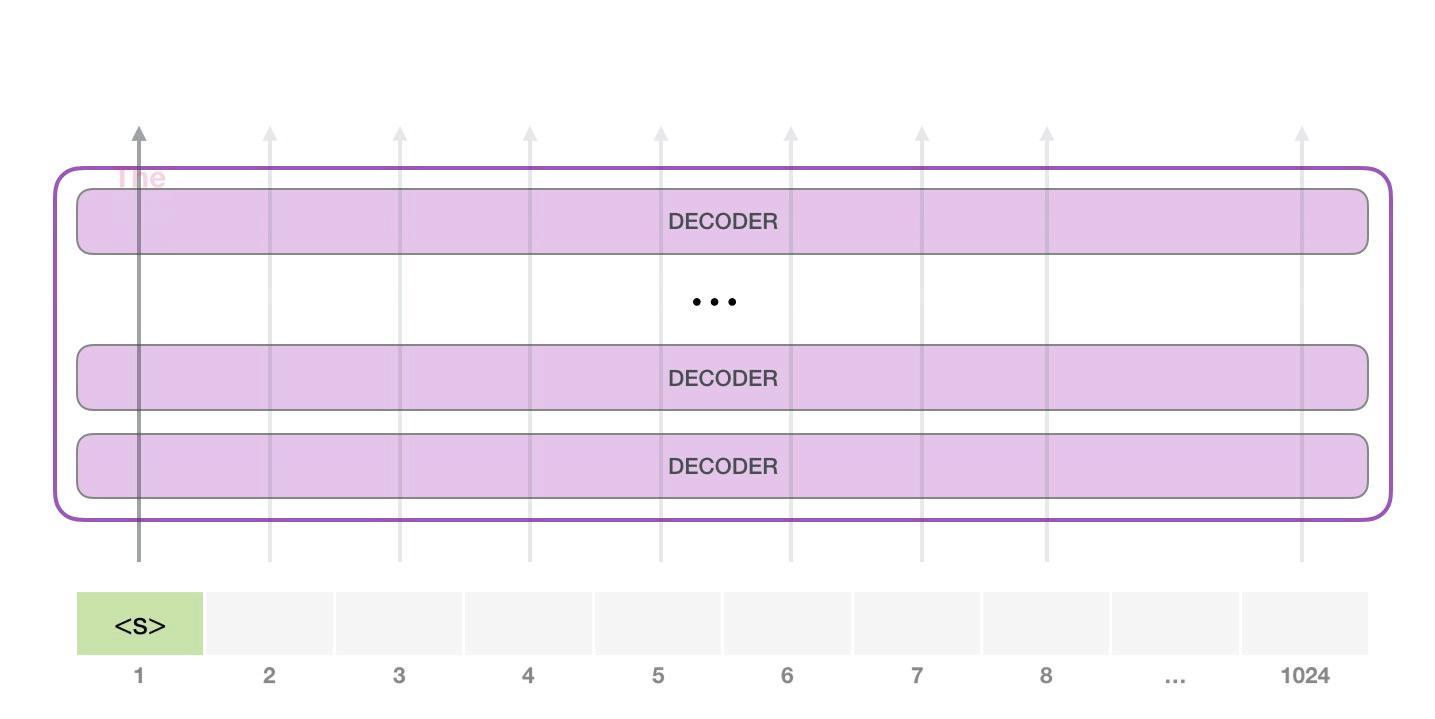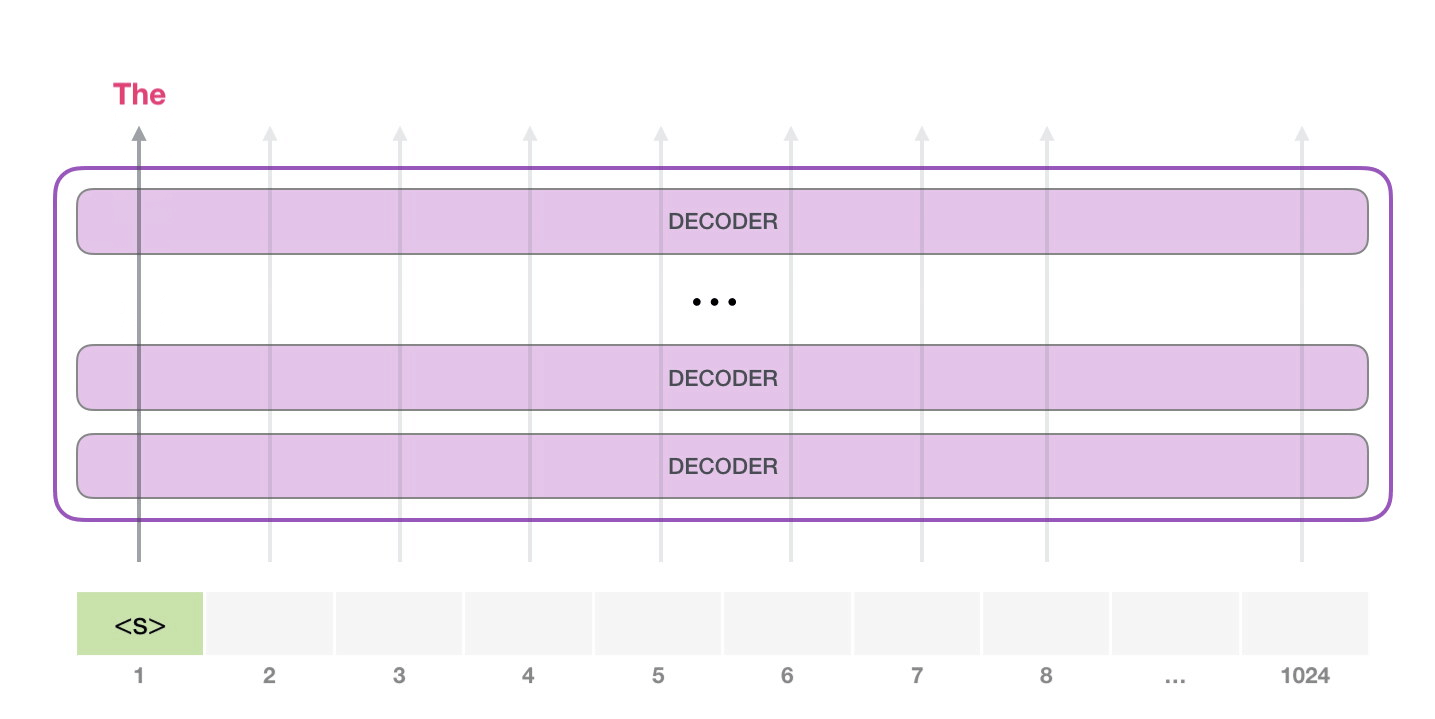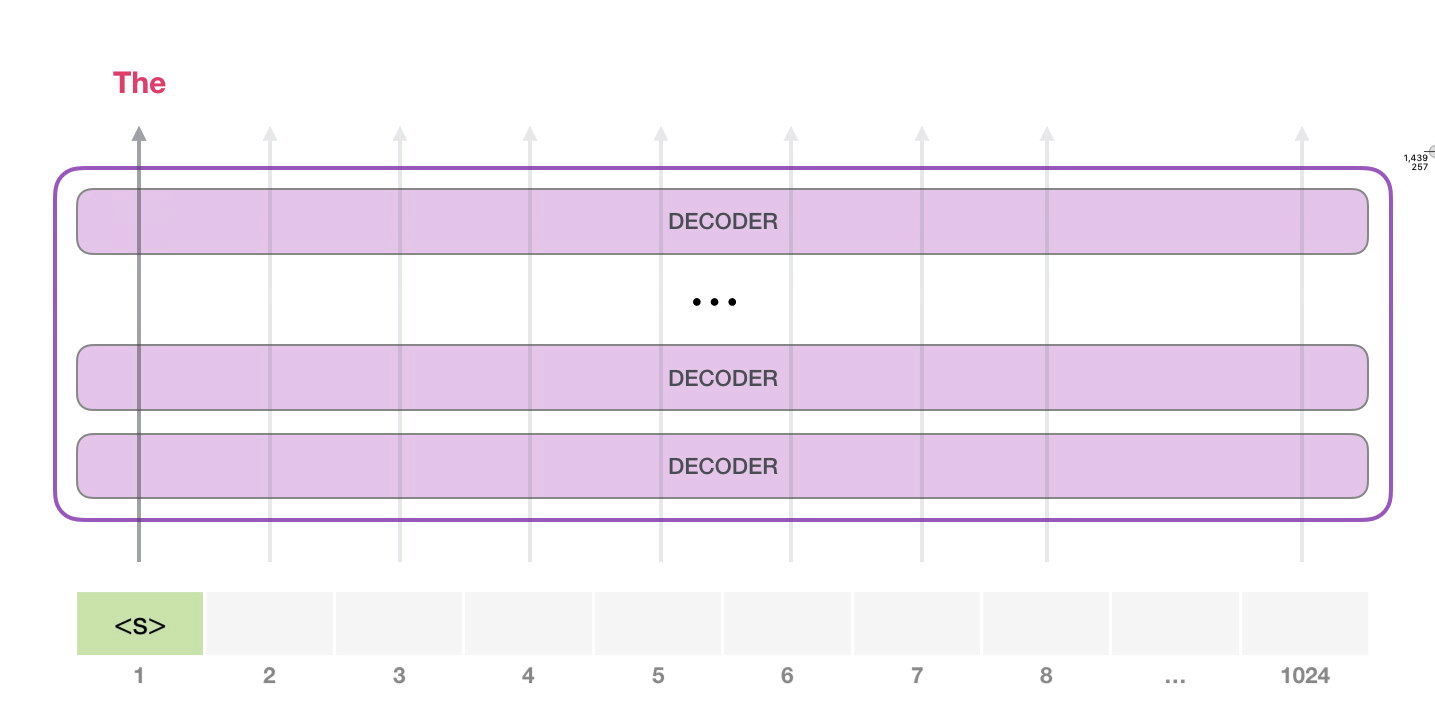
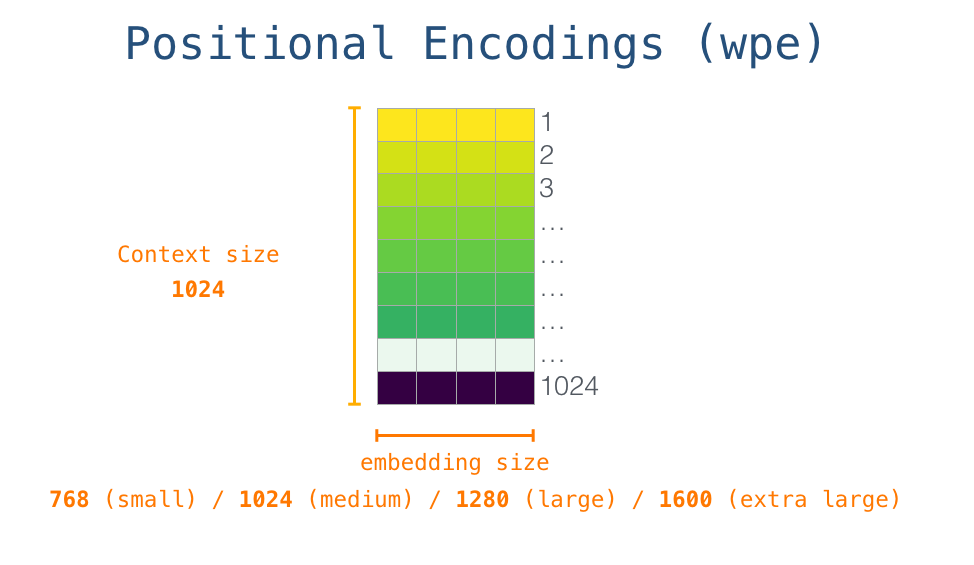
GPT-2 1024 . .
GPT-2 – ( ) (), (.. ). , ( <|endoftext|>; <|s|>).
, . , (score) – , (50 GPT-2). – «the». - – , , , , – . . GPT-2 top-k, , , (, , top-k = 1).
:
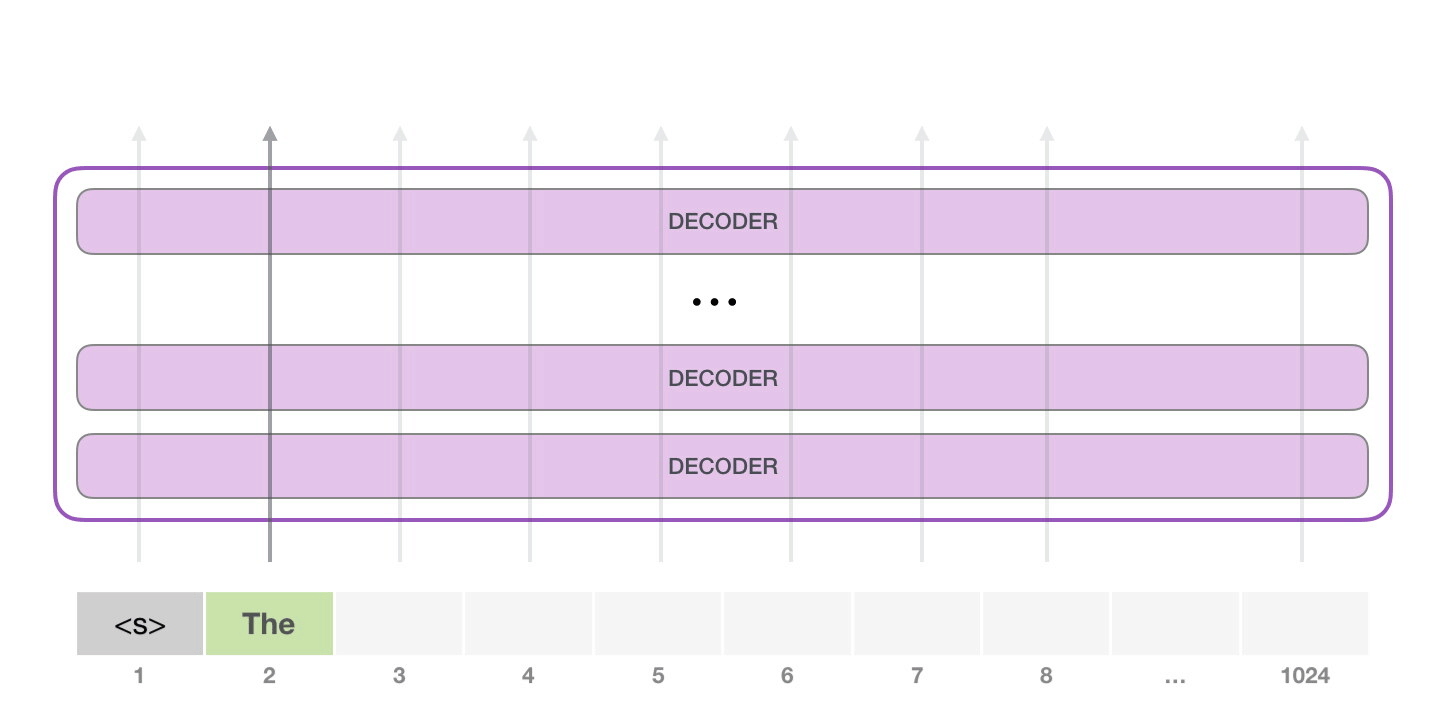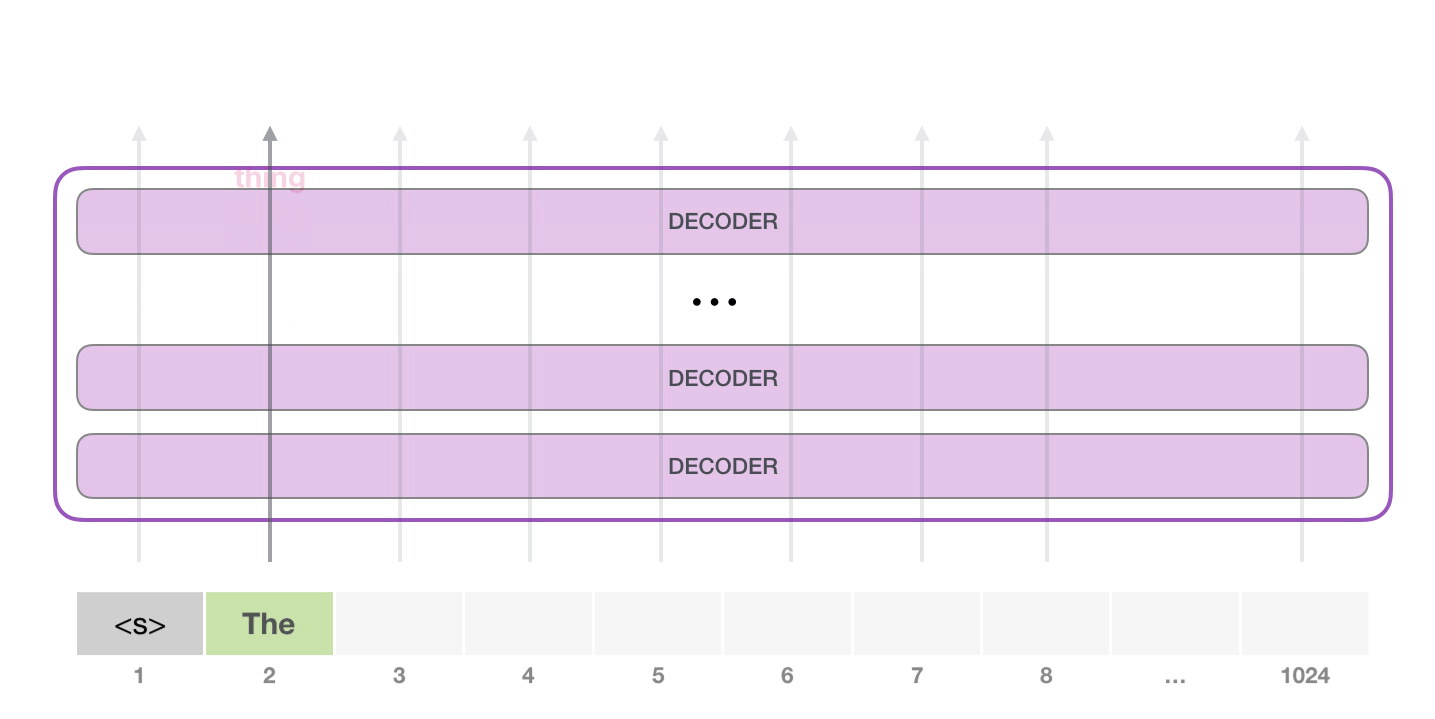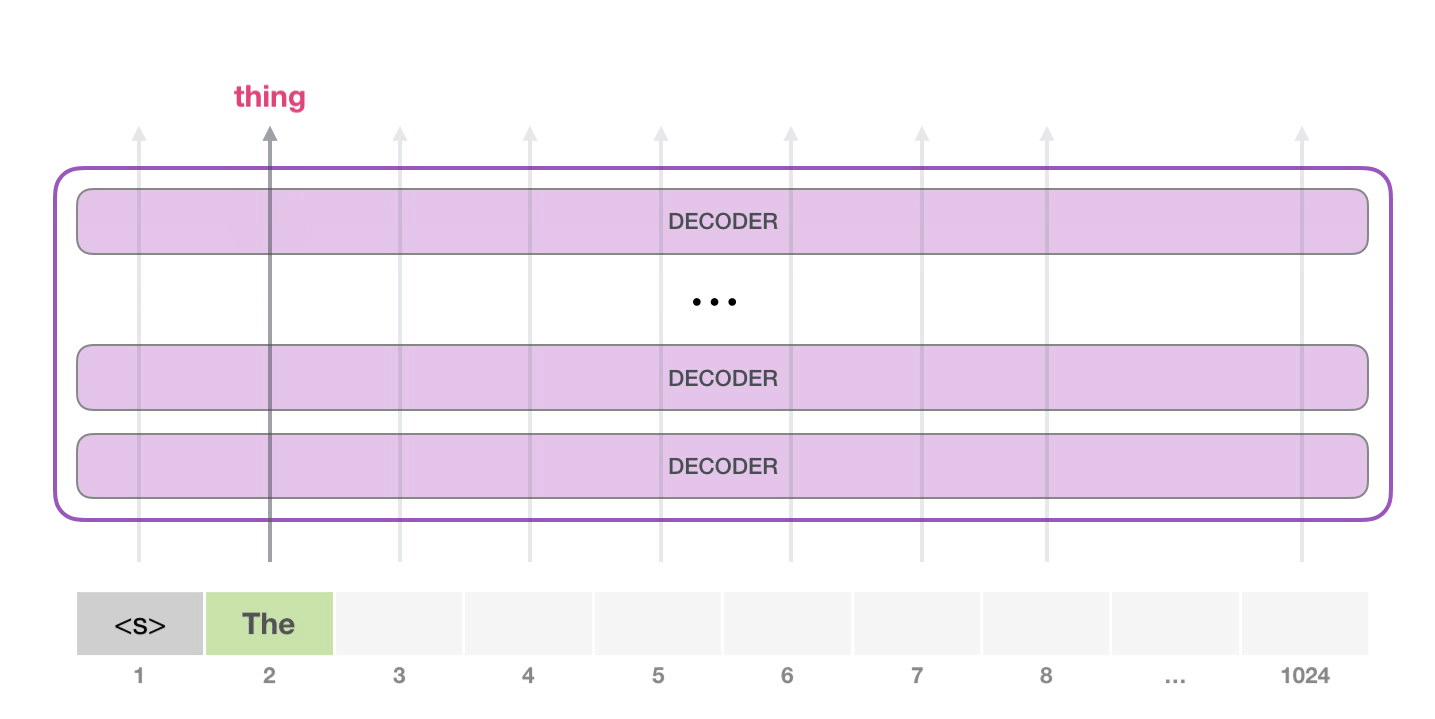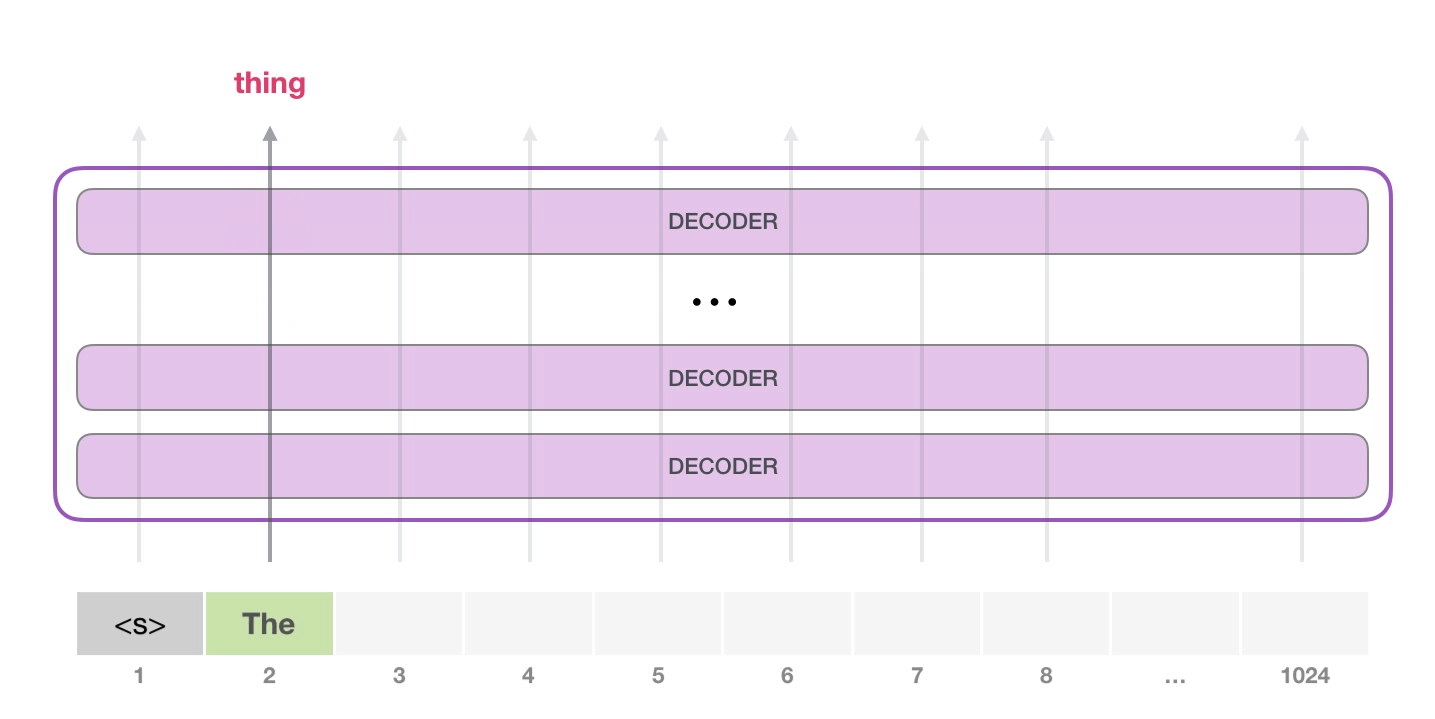
, . GPT-2 ( ). GPT-2 .
. . NLP-, , – , .
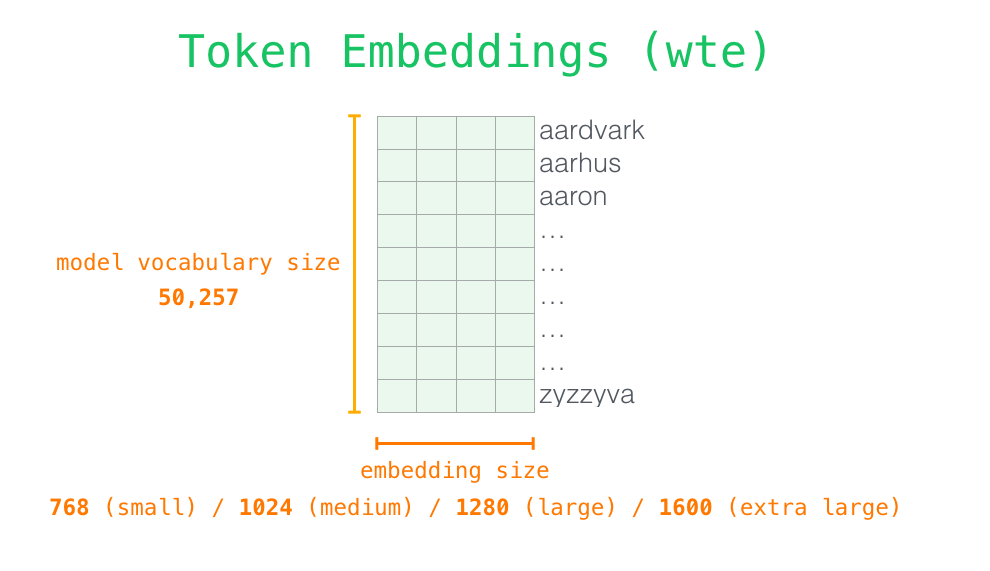
– , - . GPT-2. 768 /.
, <|s|> . , – , . , 1024 .
. , GPT-2.

#1.
, , . , . , , .

. , :
, , , .
, . , . , , :
: , , ( ). , , .
, «a robot» «it». , , , .

. :
- – , ( ). , ;
- – . ;
- – ; , , .

. – , . . , – . , .
(: ).
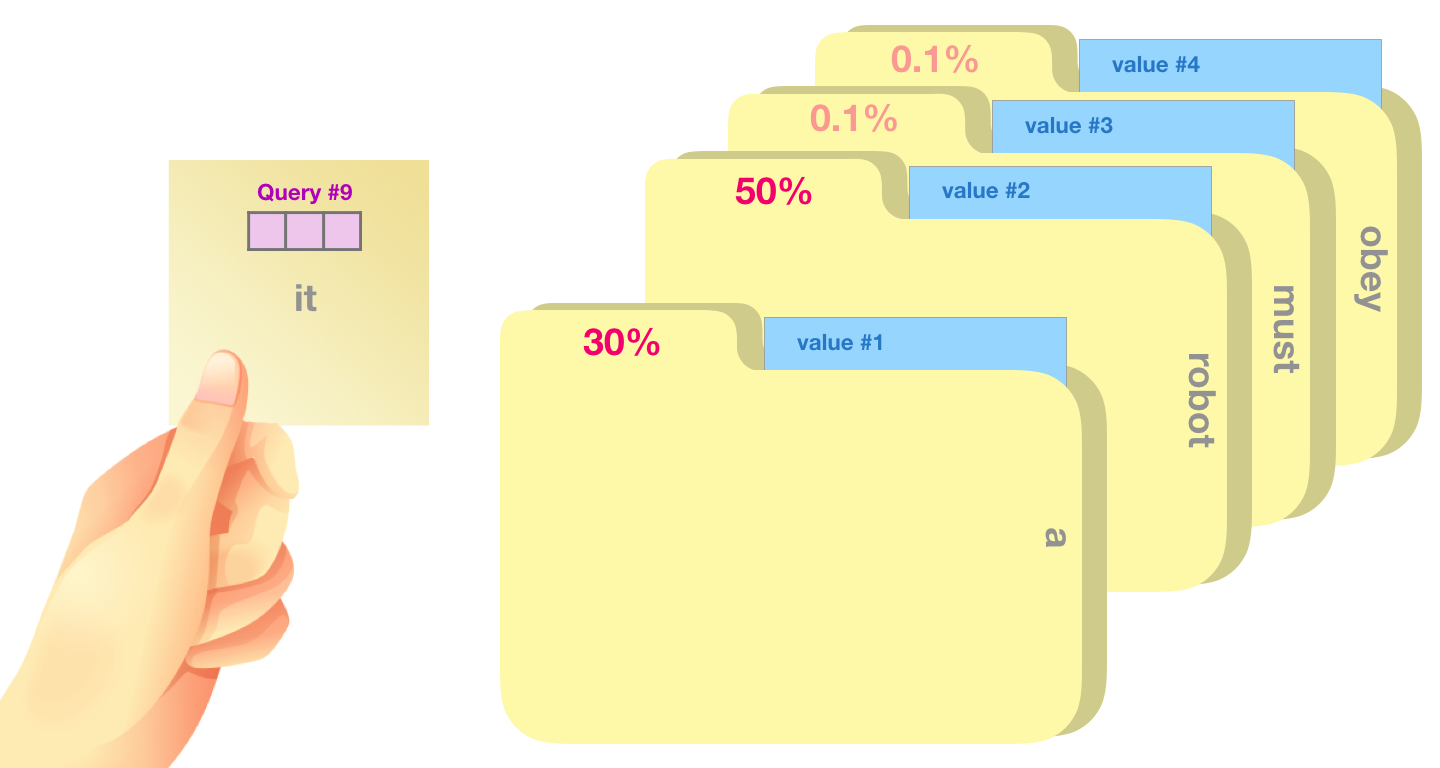
, .
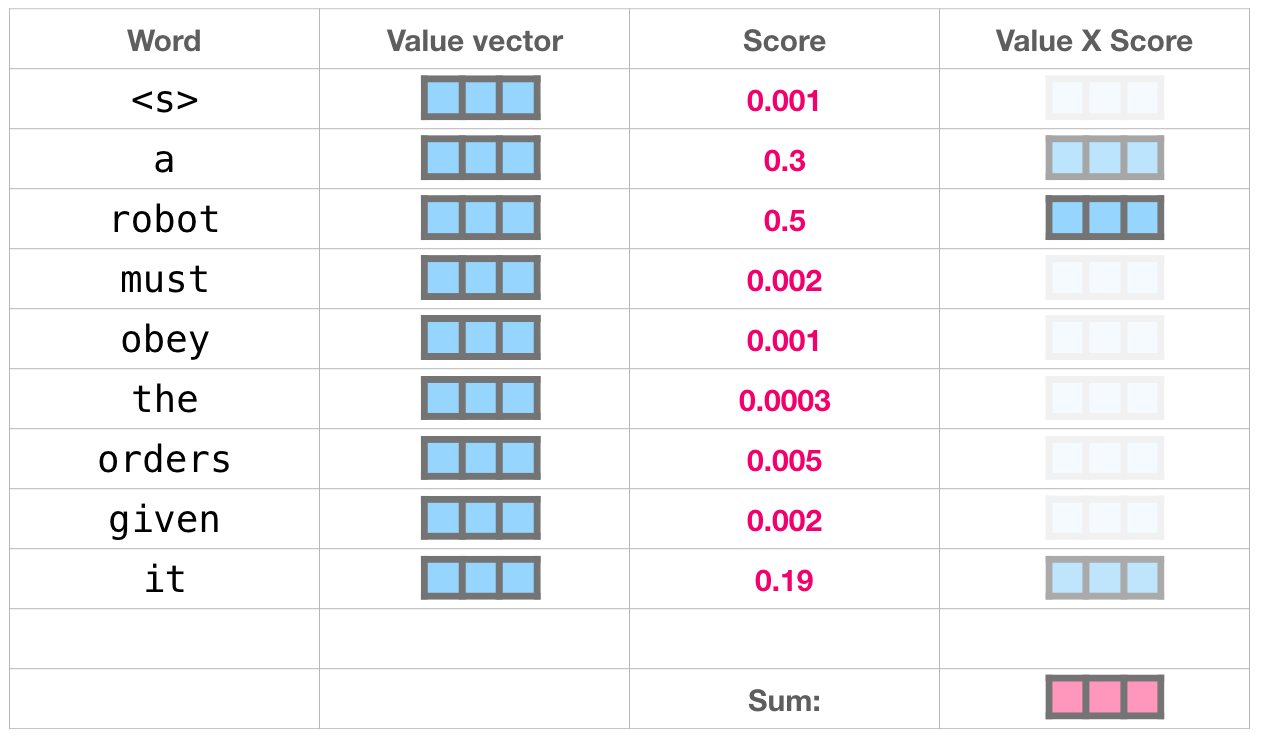
, 50% «robot», 30% «a» 19% – «it». . .
( ), .
, . .
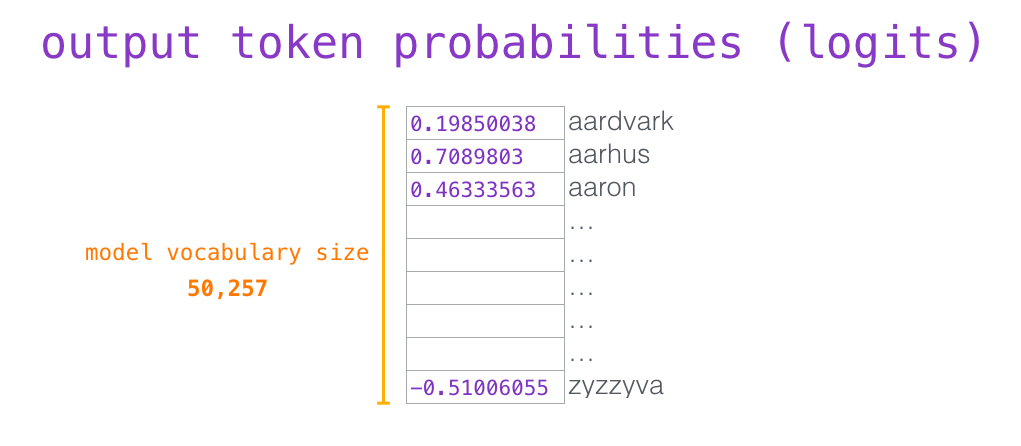
(top_k = 1). , . , , ( ). – top_k 40: 40 .
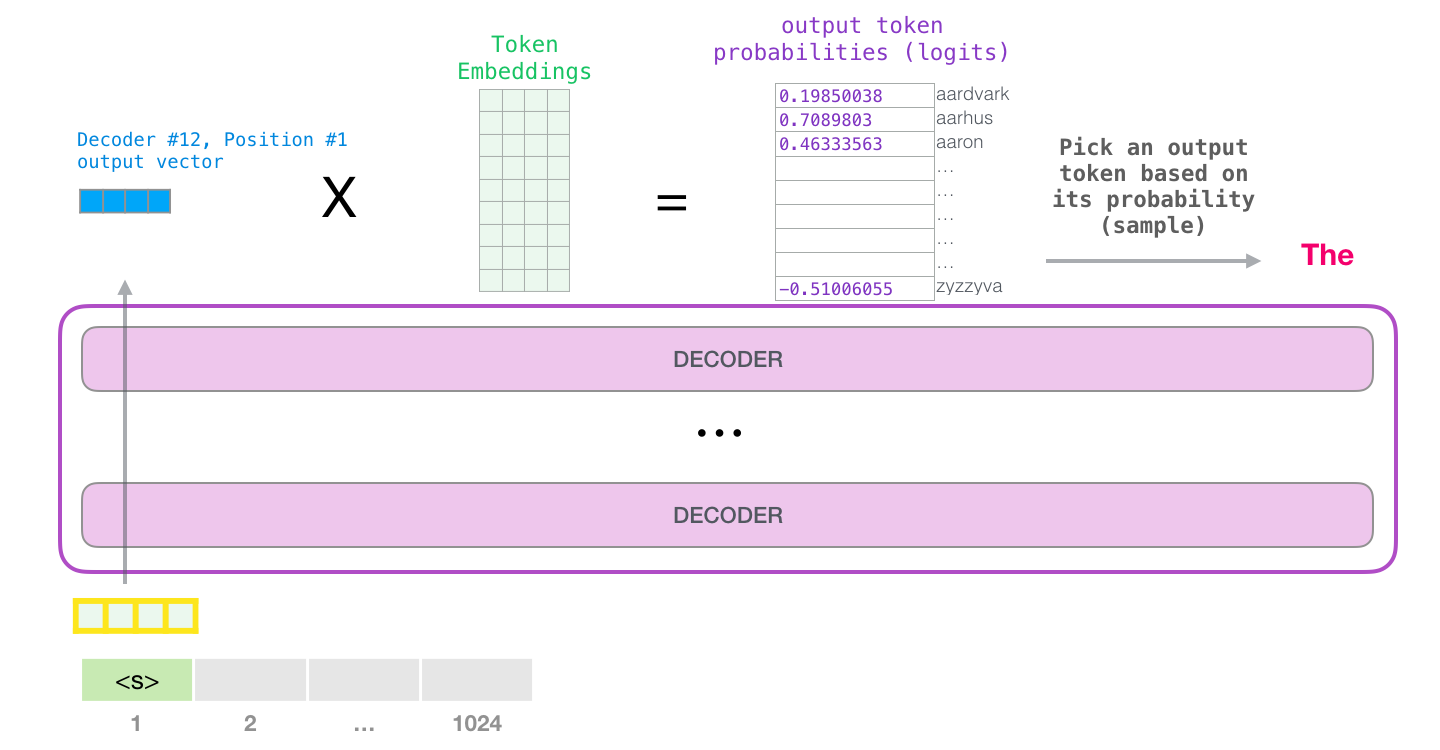
, . , (1024 ) .
: GPT-2,
, , GPT-2. , , . , ( TransformerXL XLNet).
, :
- «» «» ; GPT-2 (Byte Pair Encoding) . , .
- GPT-2 / (inference/evaluation mode). . . (512), 1, .
- / . .
- , . Transformer , .
- . «zoom in», :
2:
, «it»:

, . , , . , , .
( )
, . , 4 .
:
- , ;
- ;
- .
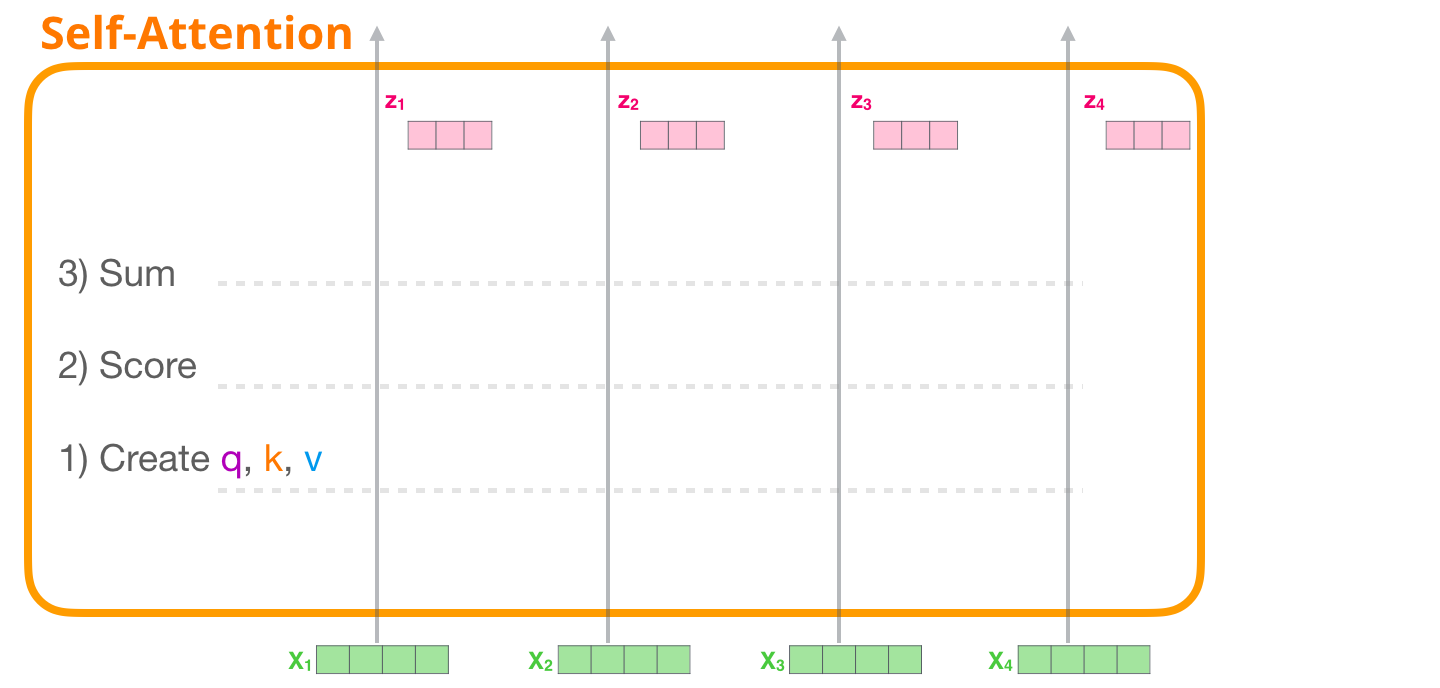
1 – ,
. . . ( «» ):

, WQ, WK, WV
2 –
, , №2: .
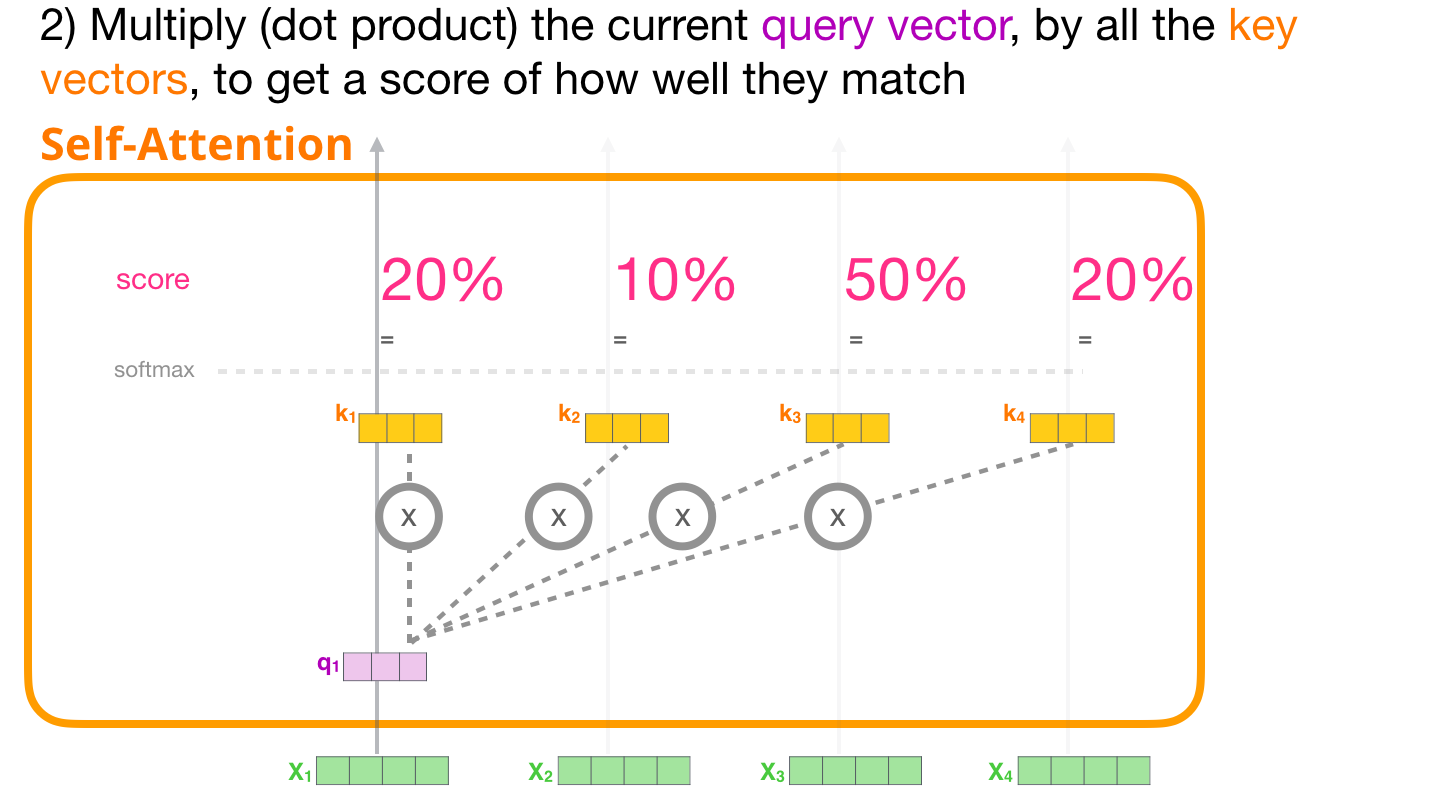
( ) ,
3 –
. , .
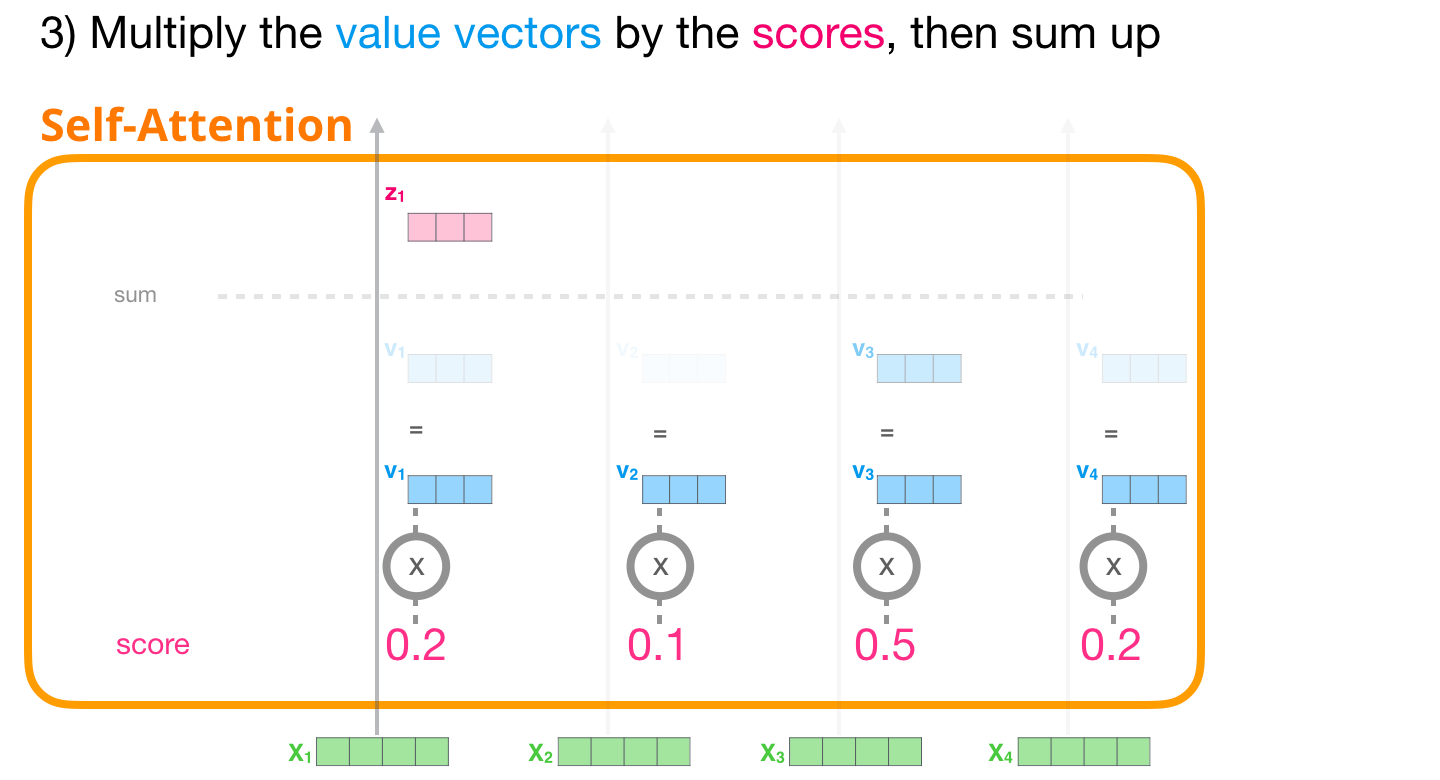
, – , .
, , . ( ).
, , , . №2. , . . , :
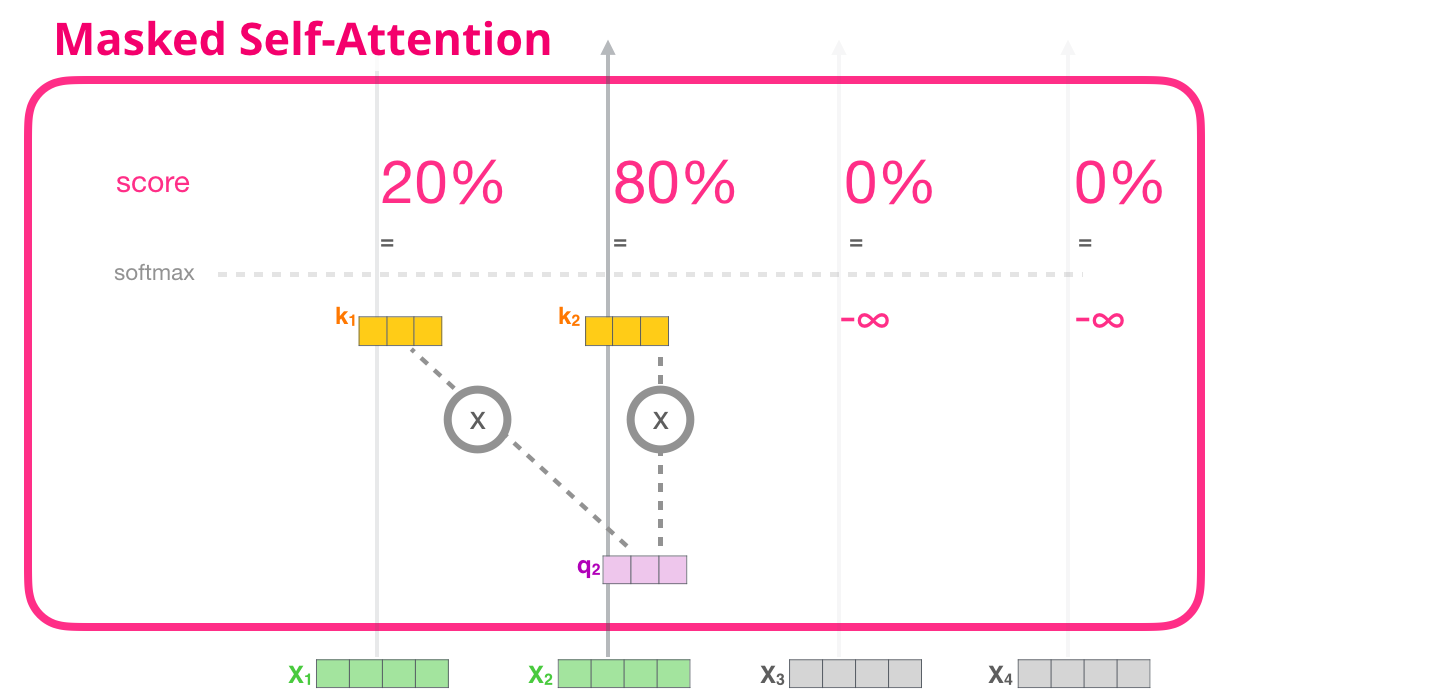
, (attention mask). , , («robot must obey orders»). 4 : ( , – ). .. , 4 , ( 4 ) .

, . , , ( ), :
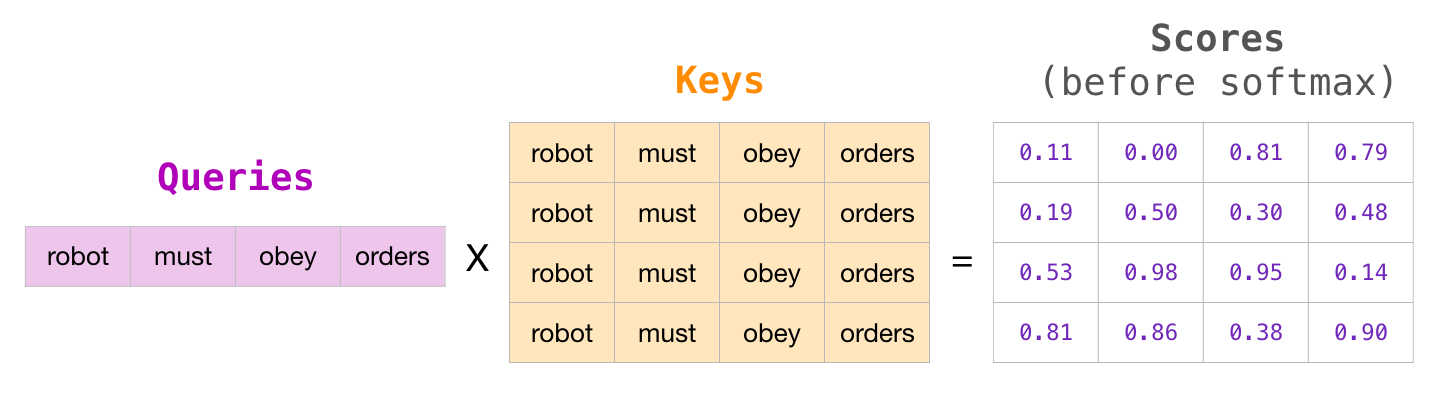
«» . , , – (-inf) (, -1 GPT-2):

, , , :

:
- ( №1), («robot»), 100% .
- ( №2), («robot must»), «must» 48% «robot» 52% «must».
- ..
GPT-2
GPT-2.
:
, GPT-2 , . , , , .
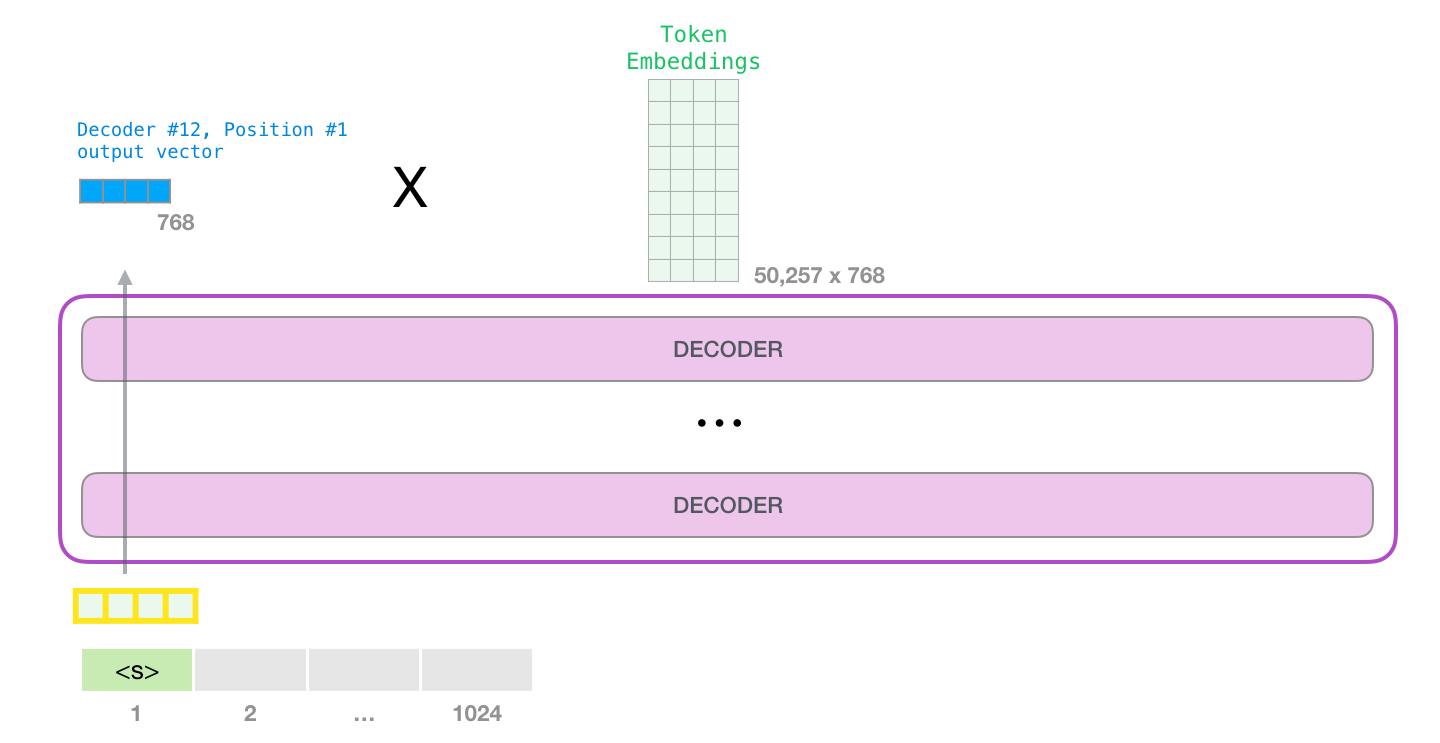
( <|s|>).
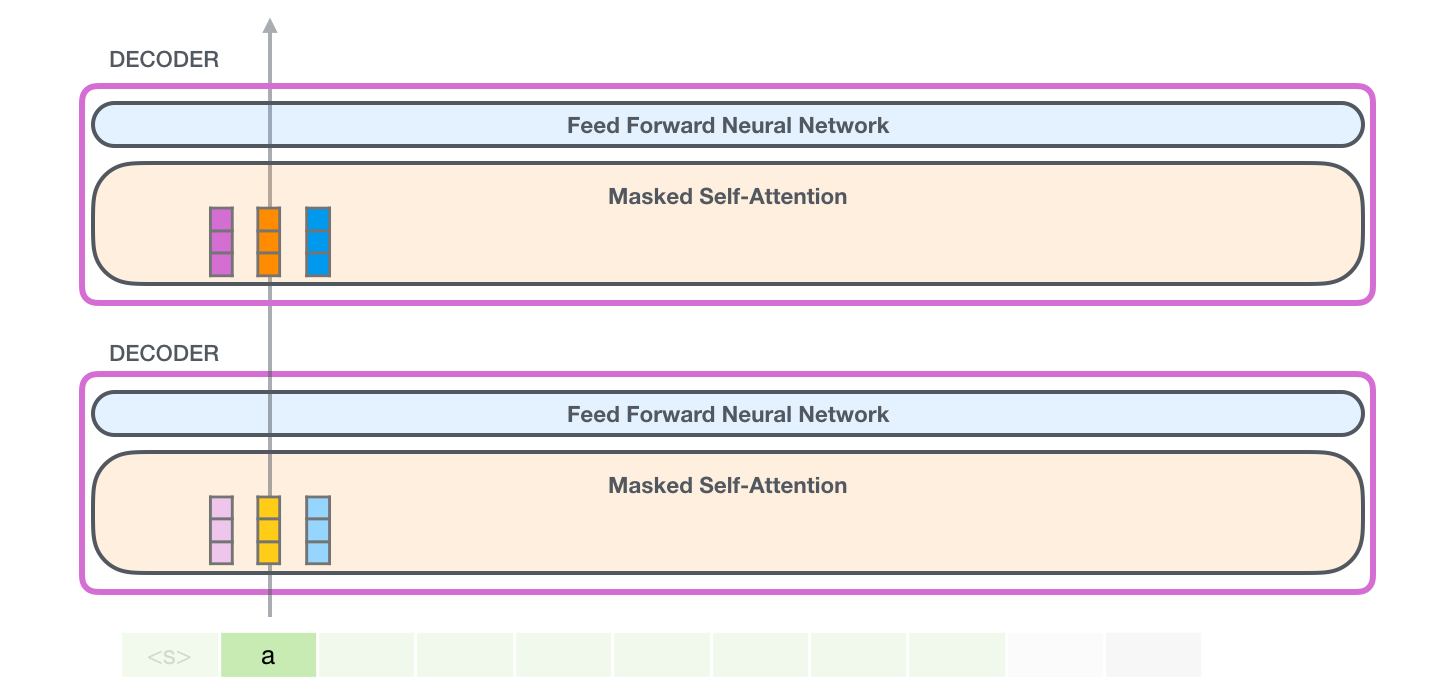
GPT-2 «a». :

, «robot», , «a» – , :

GPT-2: 1 – ,
, «it». , «it» + #9:
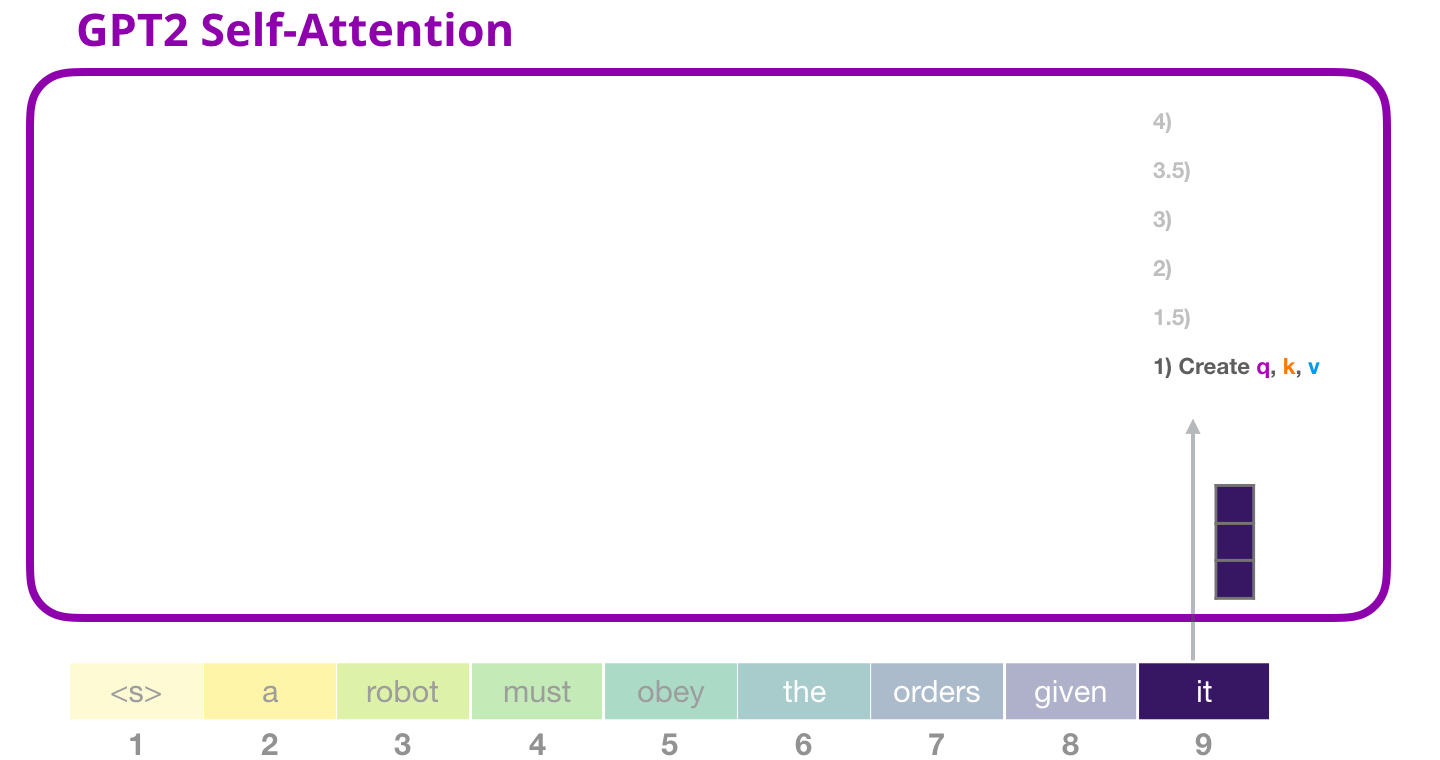
( ), , .

(bias vector),
, , «it».
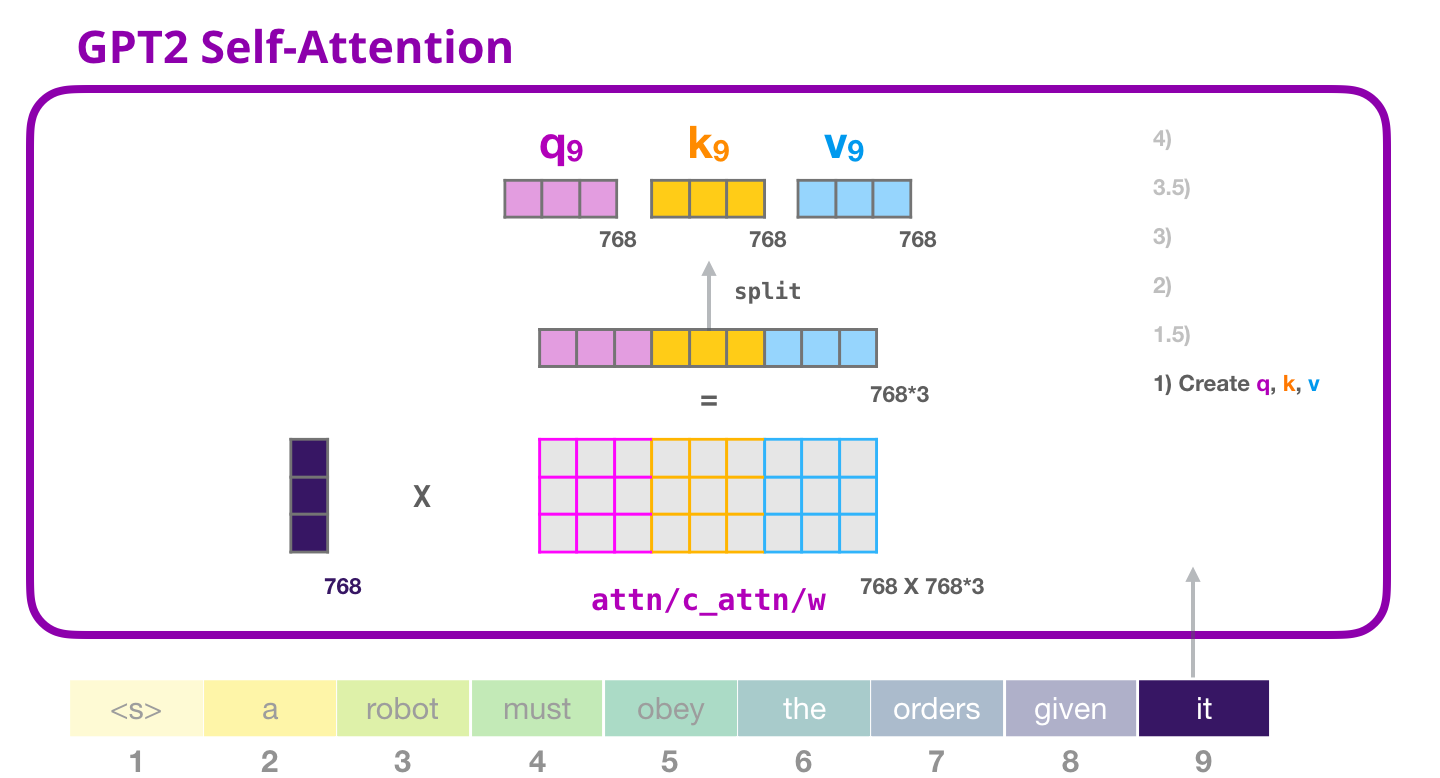
( ) ,
GPT-2: 1.5 – «»
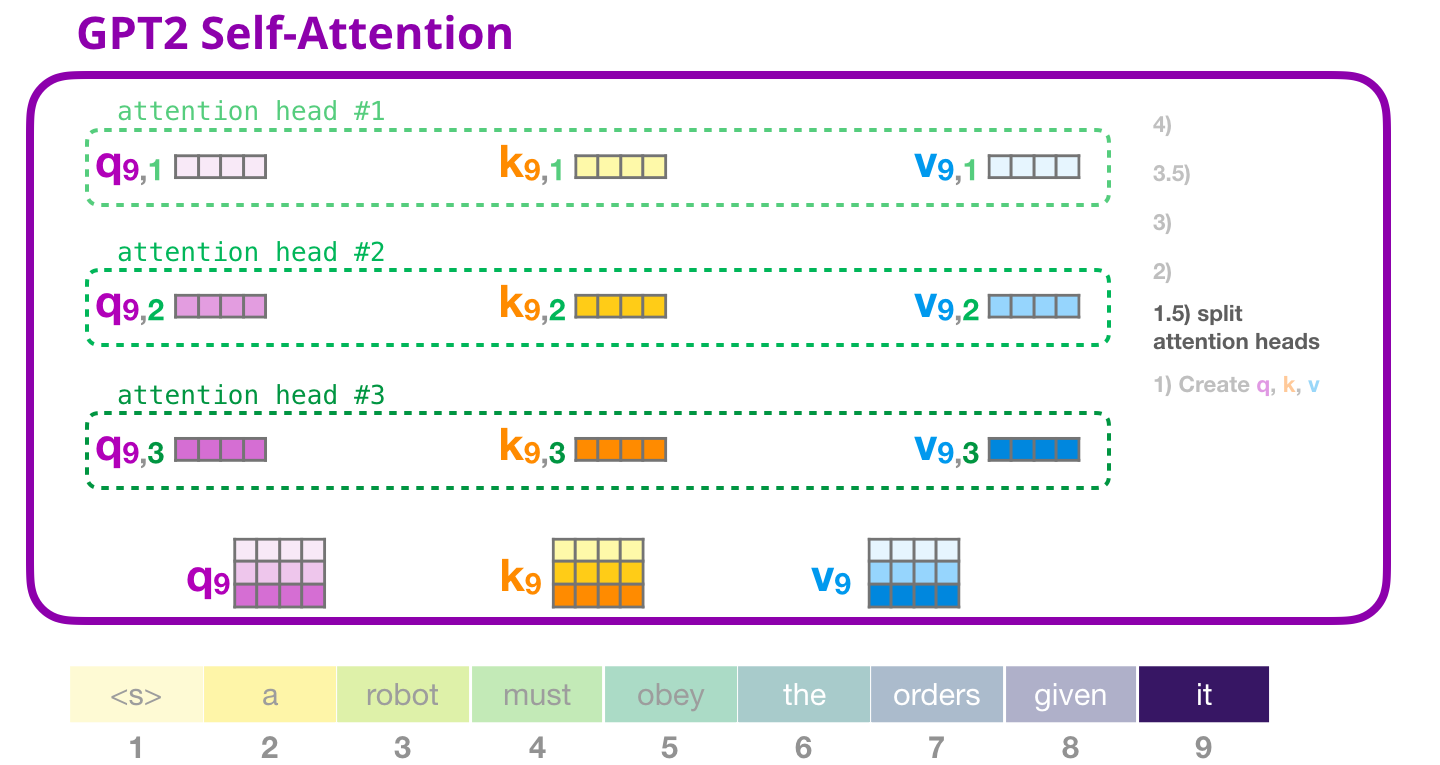
, «» . . (Q), (K) (V). «» – . GPT-2 12 «» , :
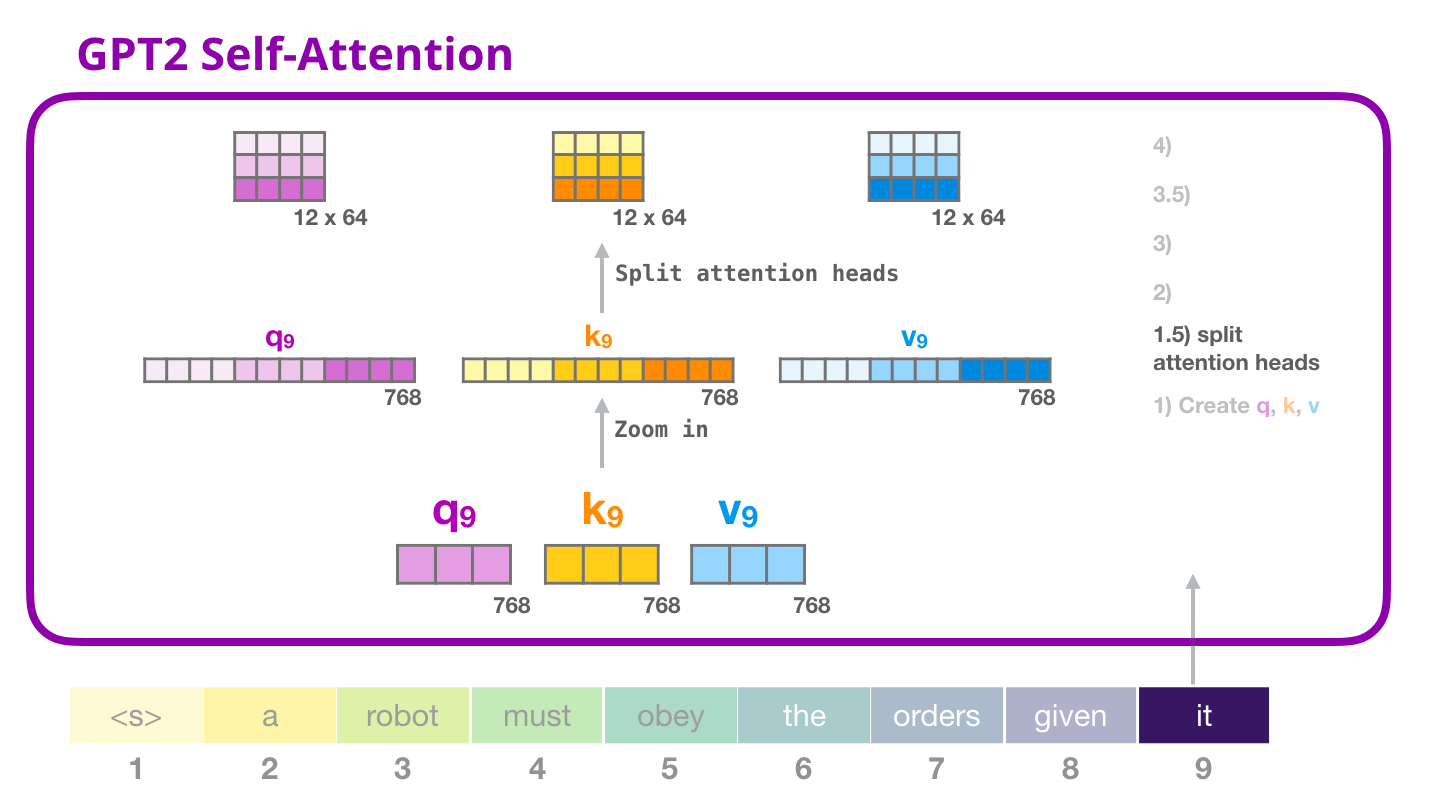
, «» . «» , ( 12 «» ):
GPT-2: 2 –
( , «» ):
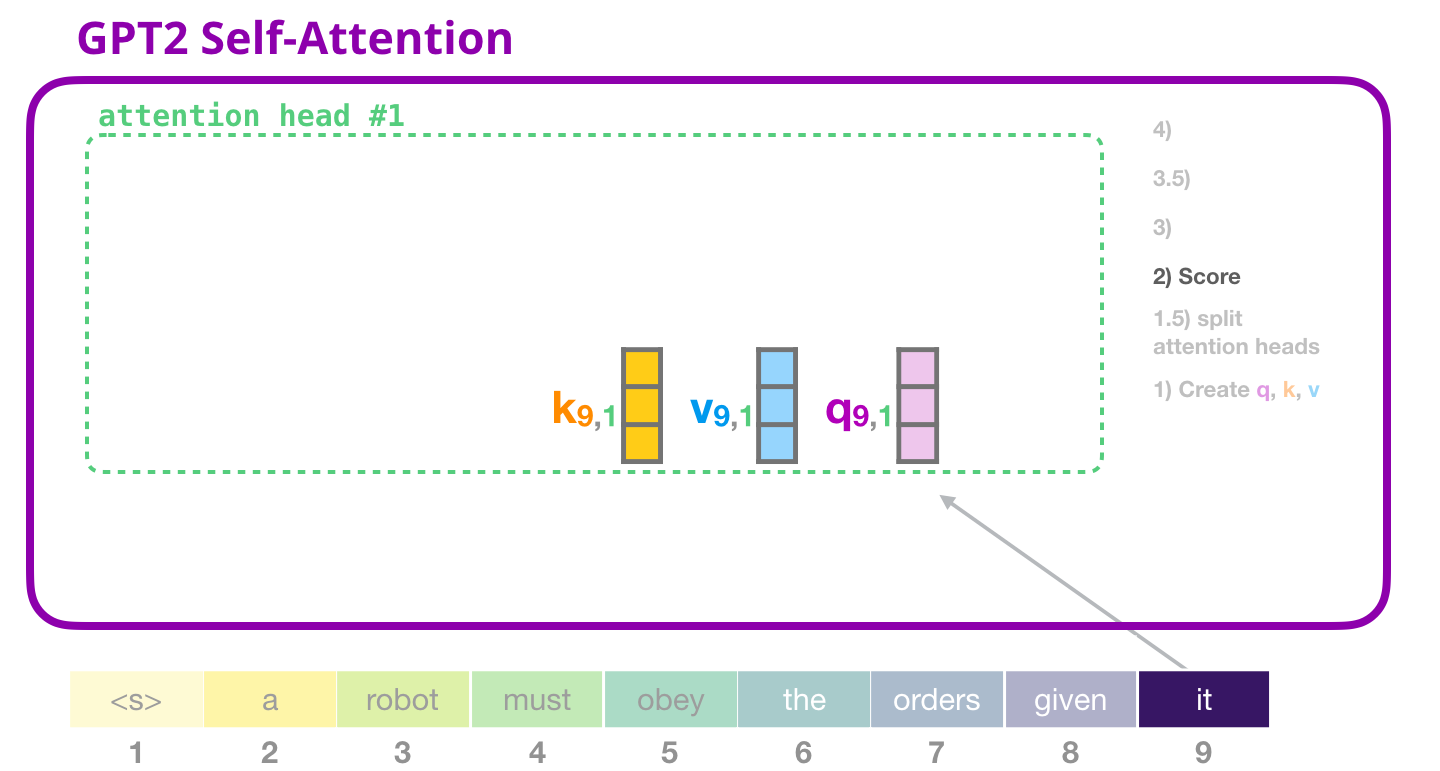
( «» #1 ):
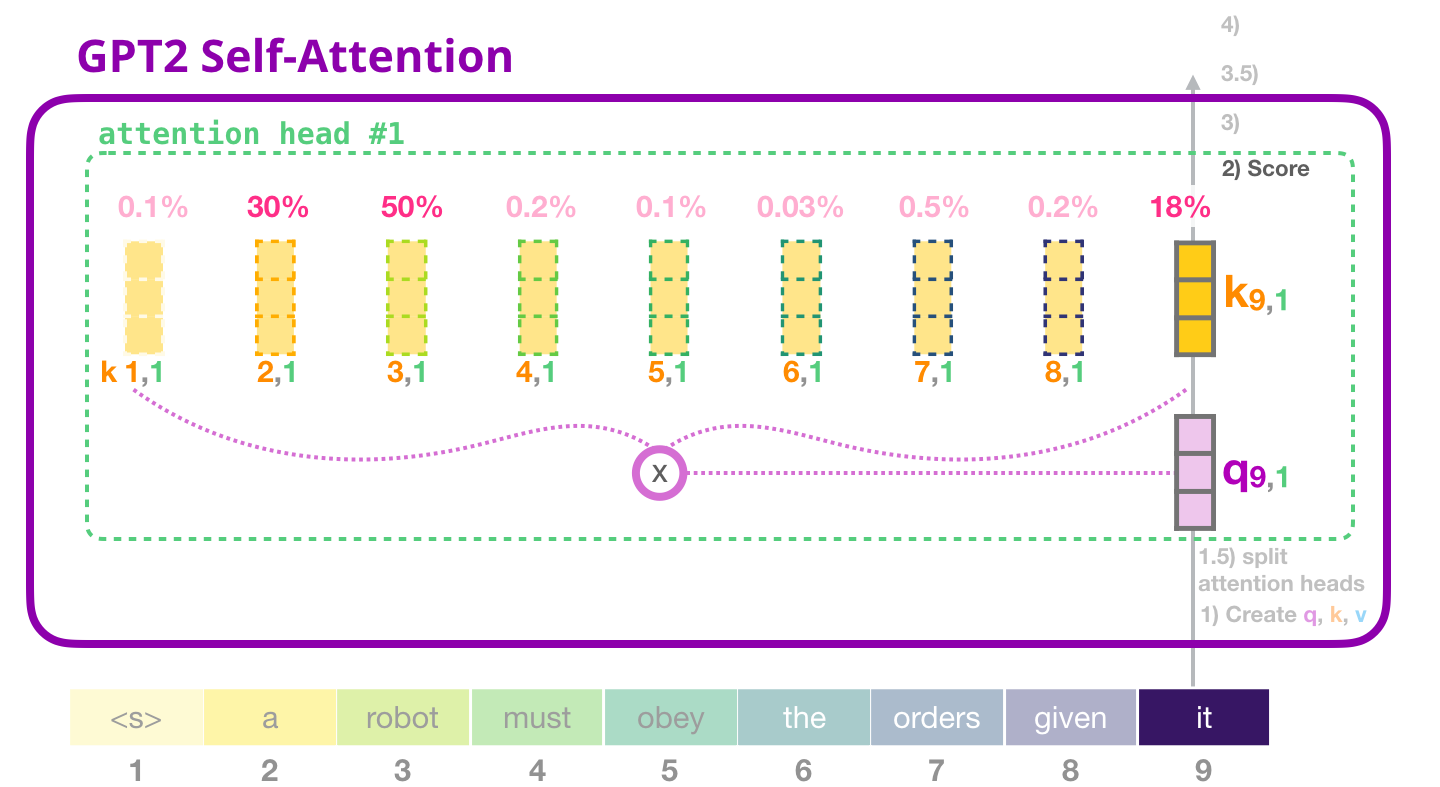
GPT-2: 3 –
, , , «» #1:

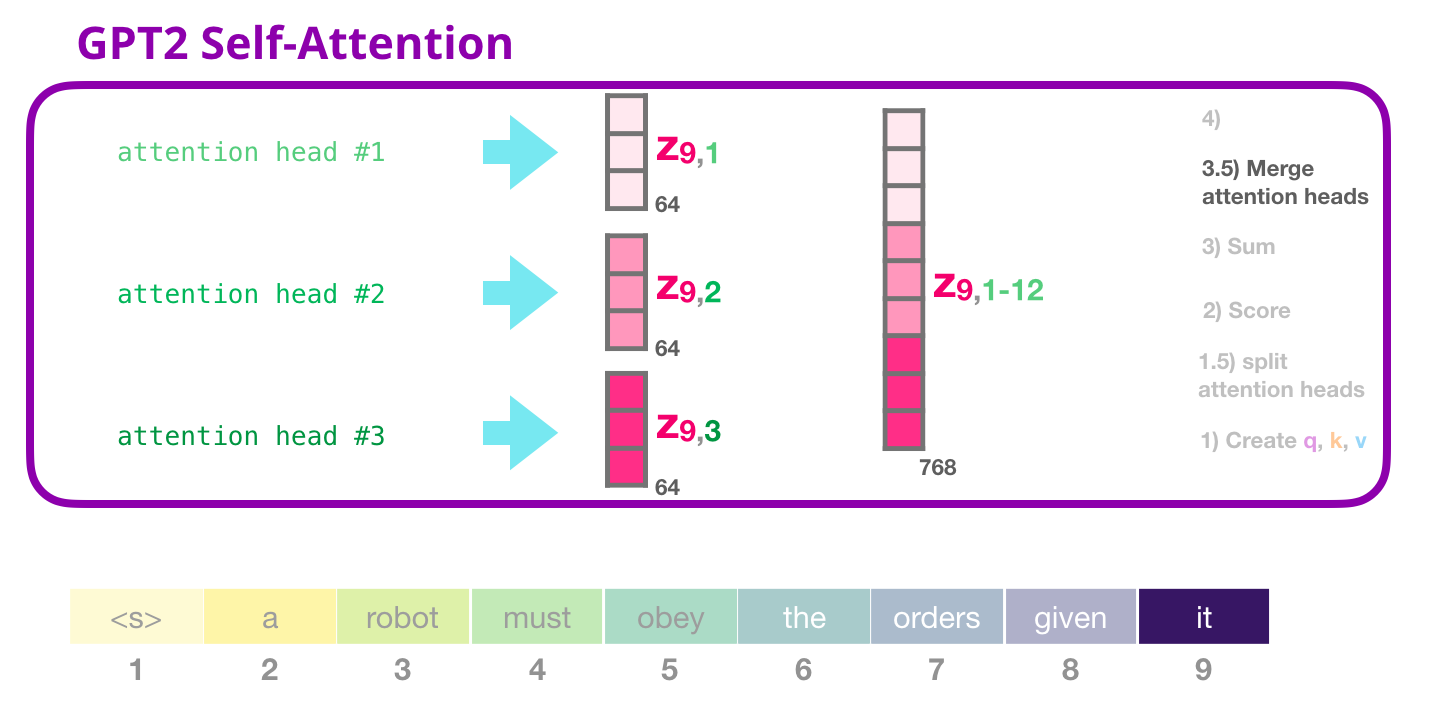
GPT-2: 3.5 – «»
«» , , :
. .
GPT-2: 4 –
, , . , «» :

, , :
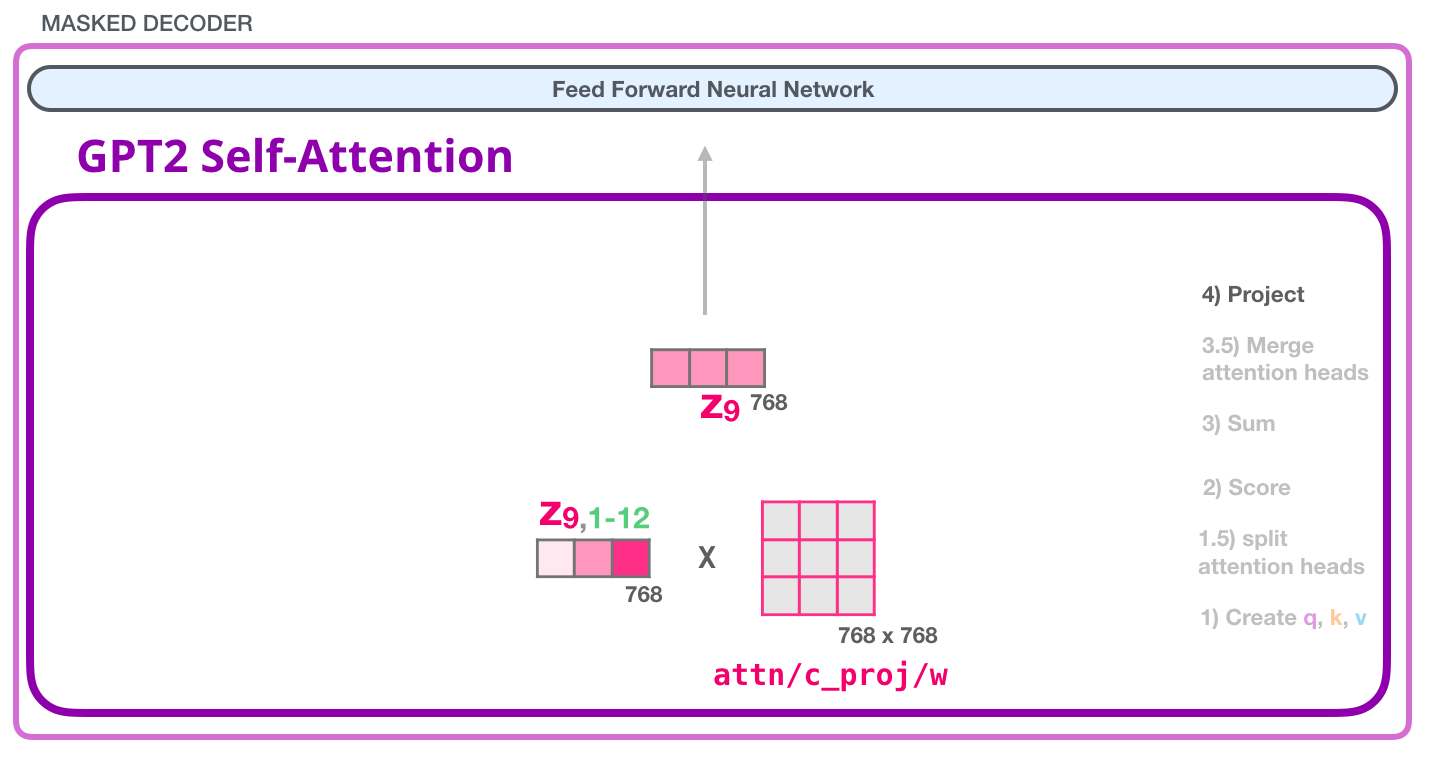
GPT-2: #1
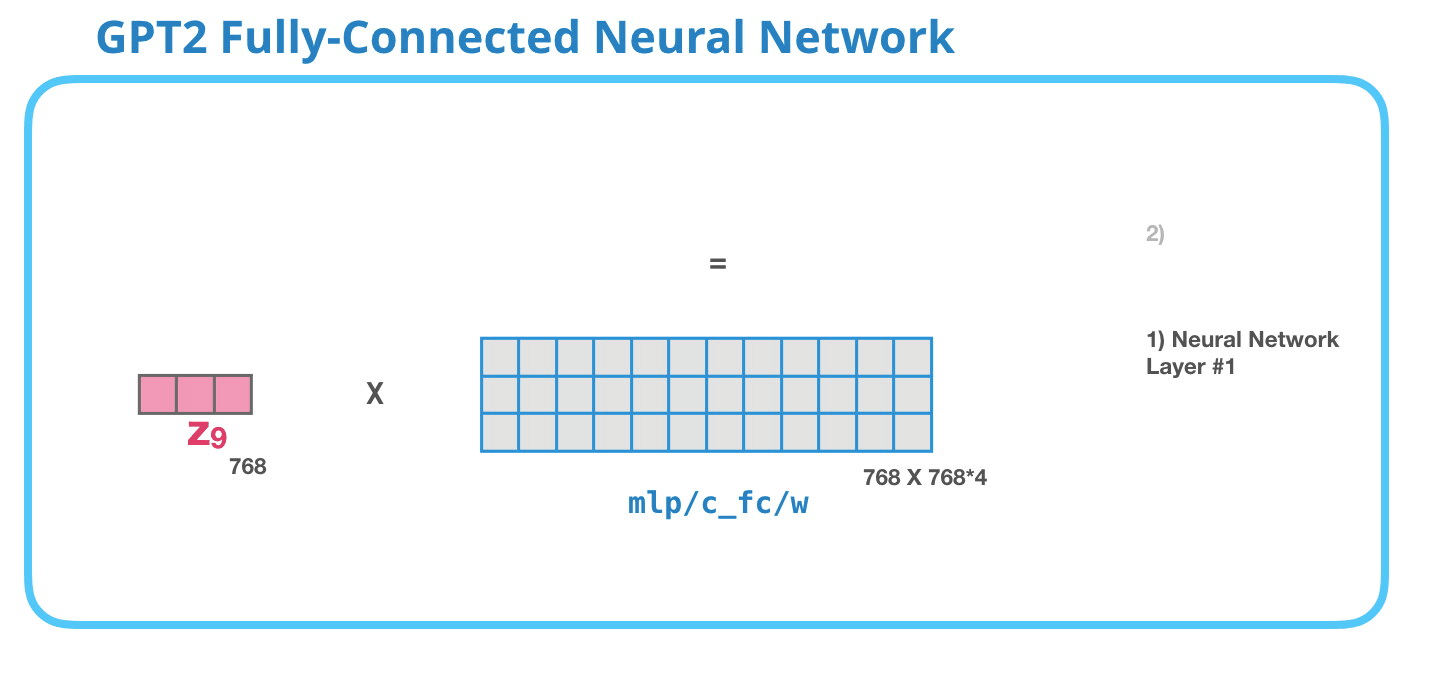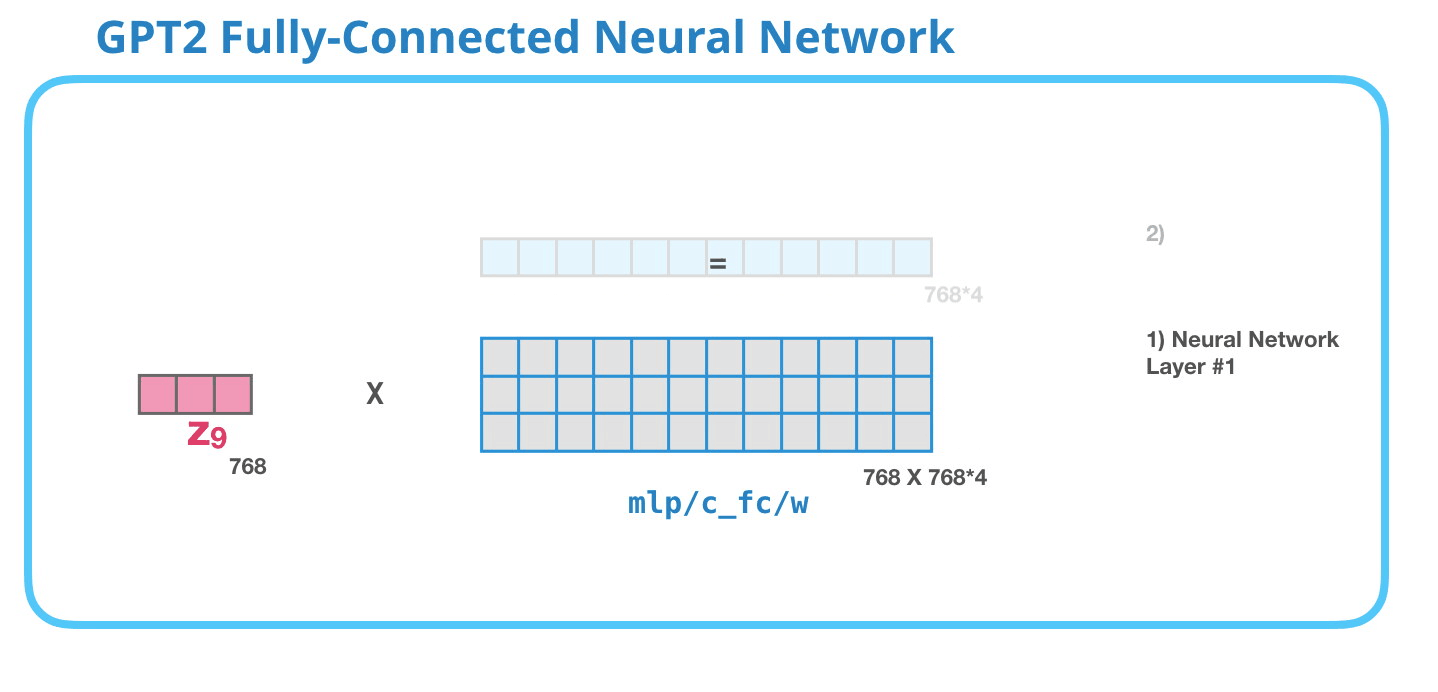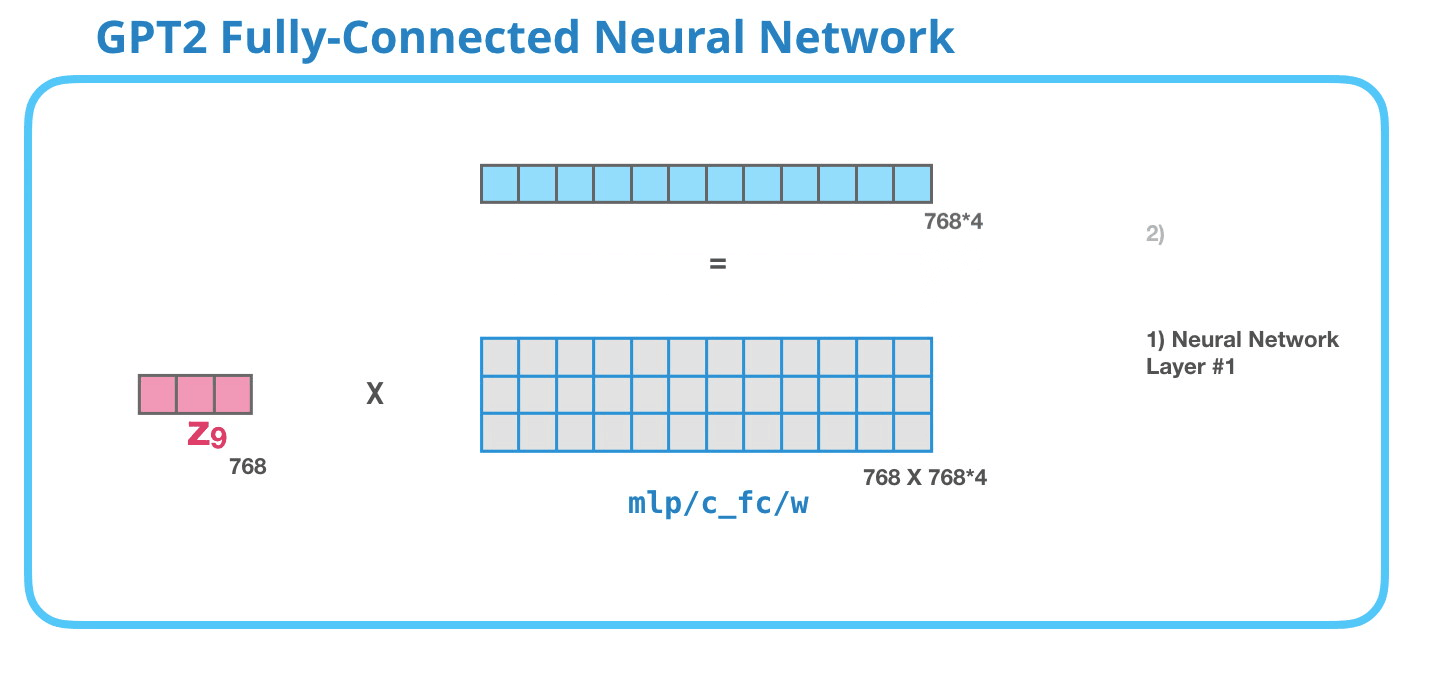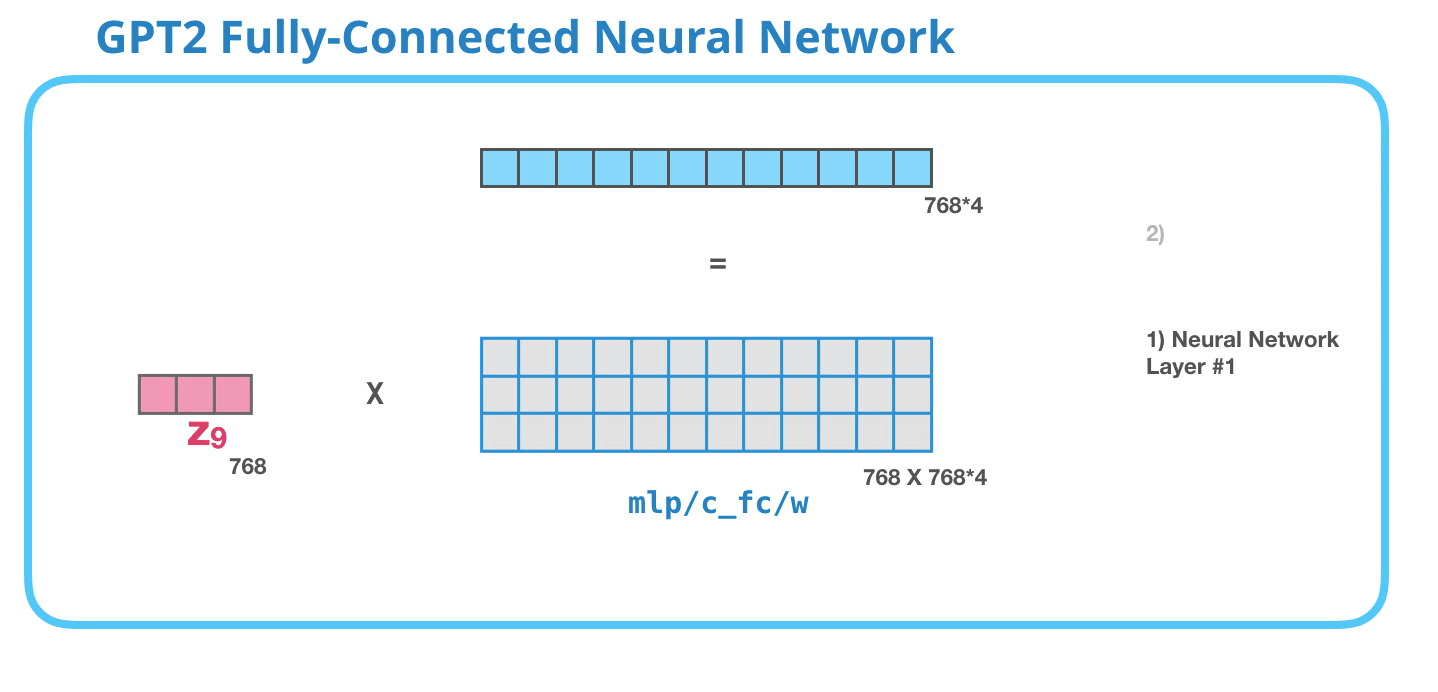
– , , . . 4 ( GPT-2 768, 768*4 = 3072 ). ? ( 512 #1 – 2048). , , .
( )
GPT-2:
(768 GPT-2). .

( )
!
, - . , . , , :
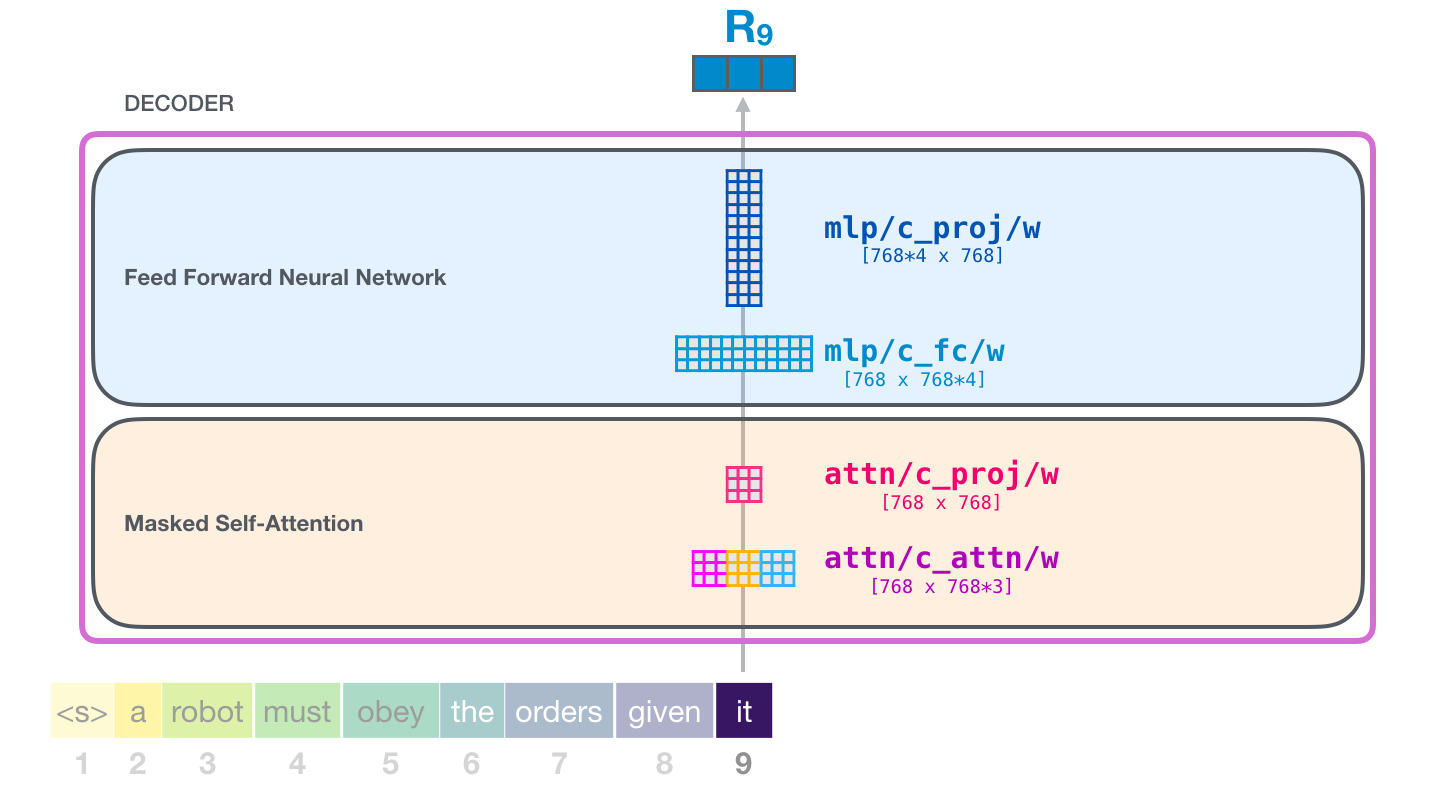
. , :
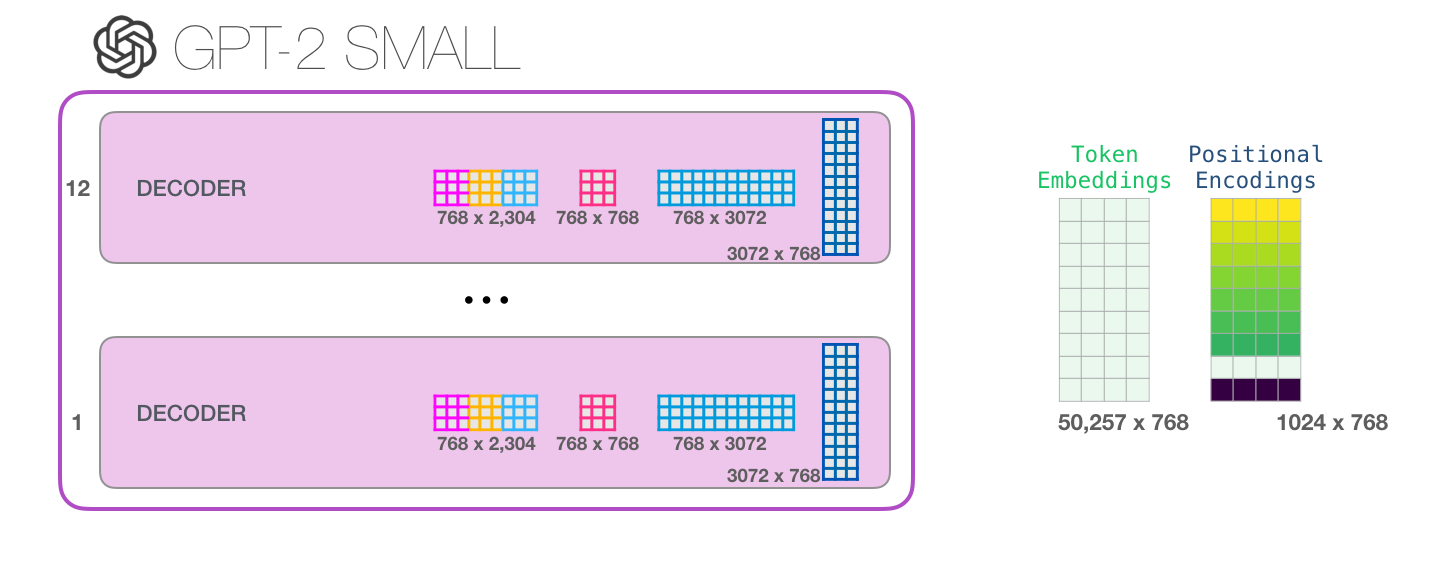
, :
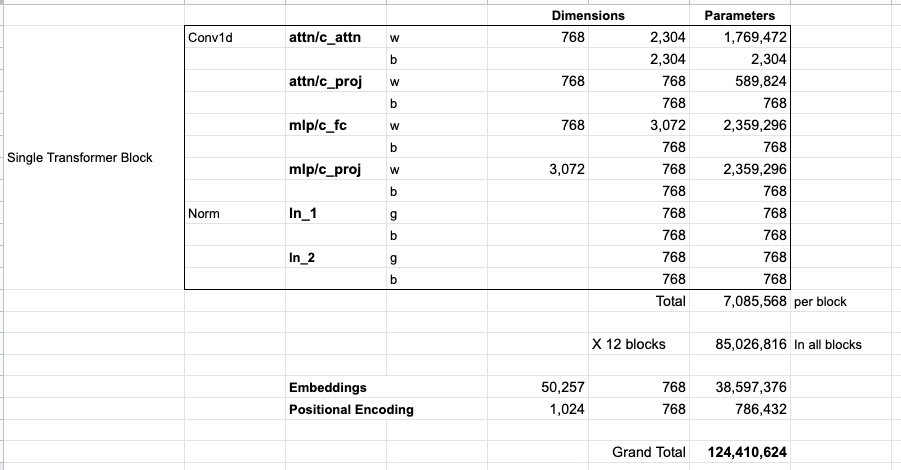
- 124 117. , , (, ).
3:
, . , . .
. :
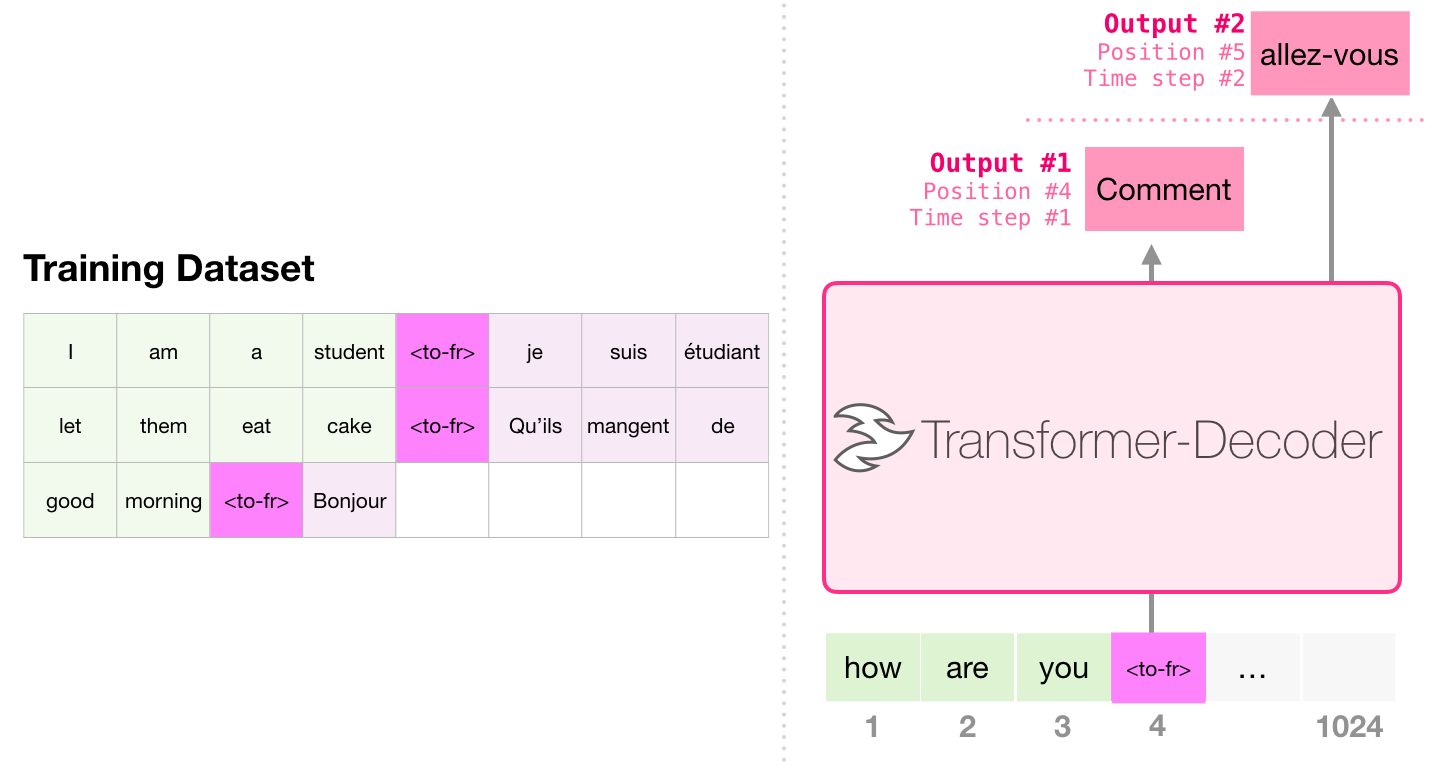
, . , ( , ) . :
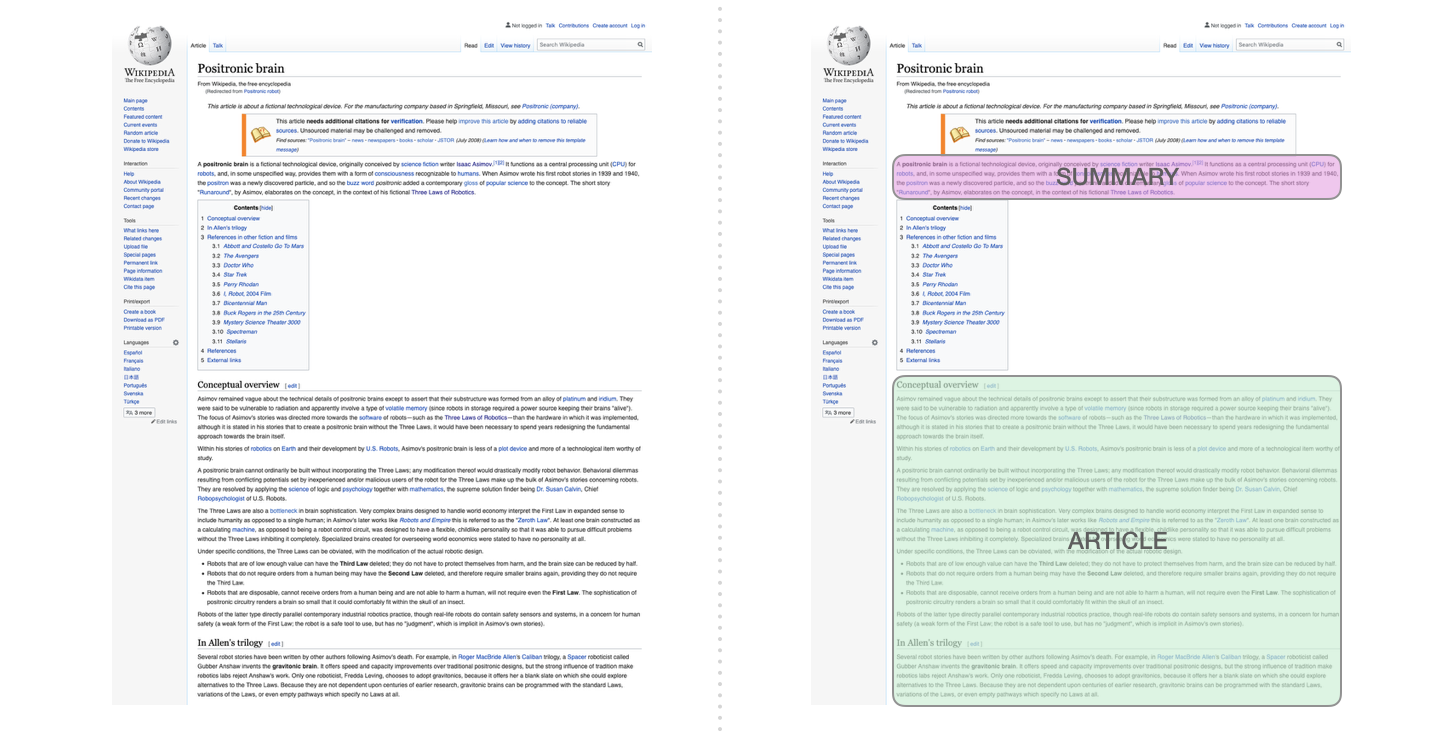
.
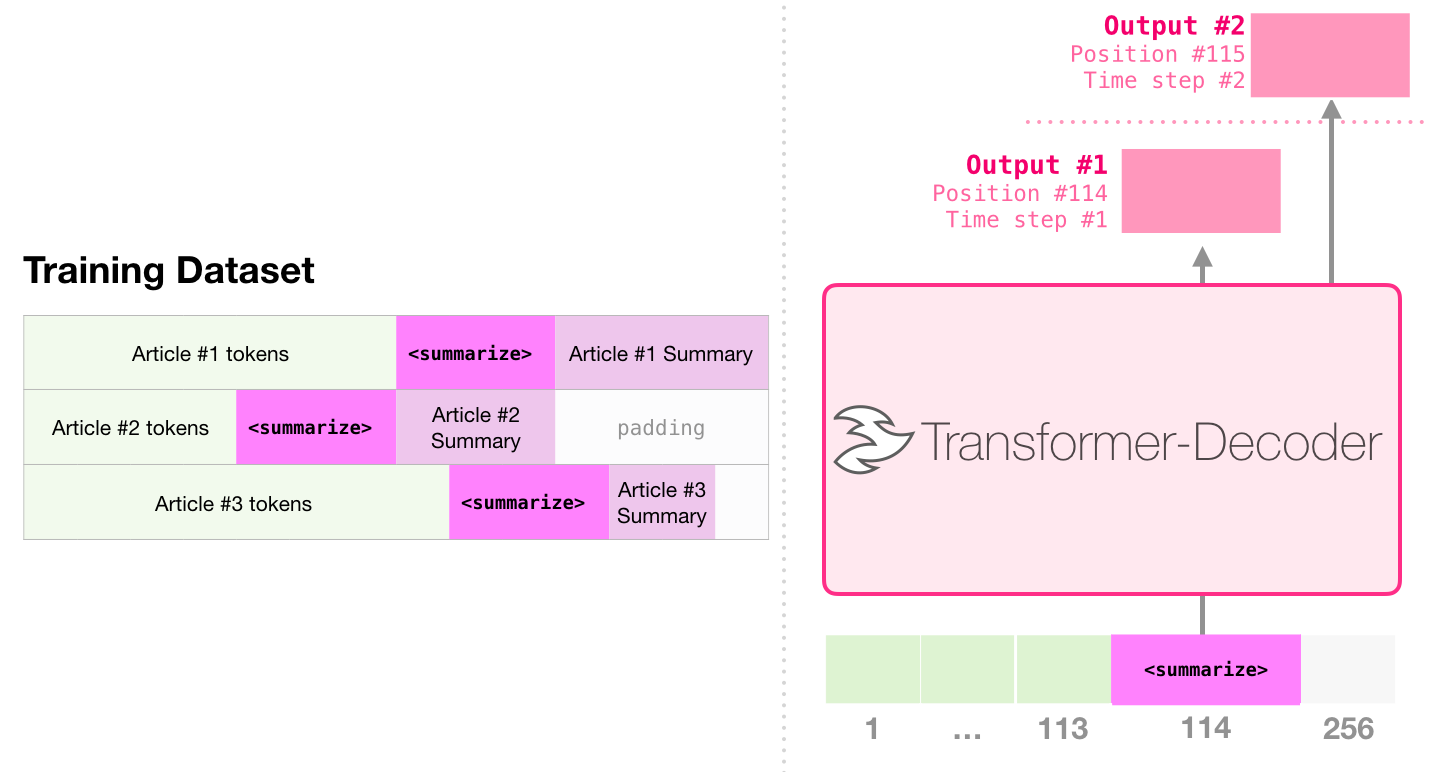
Sample Efficient Text Summarization Using a Single Pre-Trained Transformer , . , , - .
GPT-2 .
. « » – (, « »).
, . , (), ( ). (, , ) «» – , .
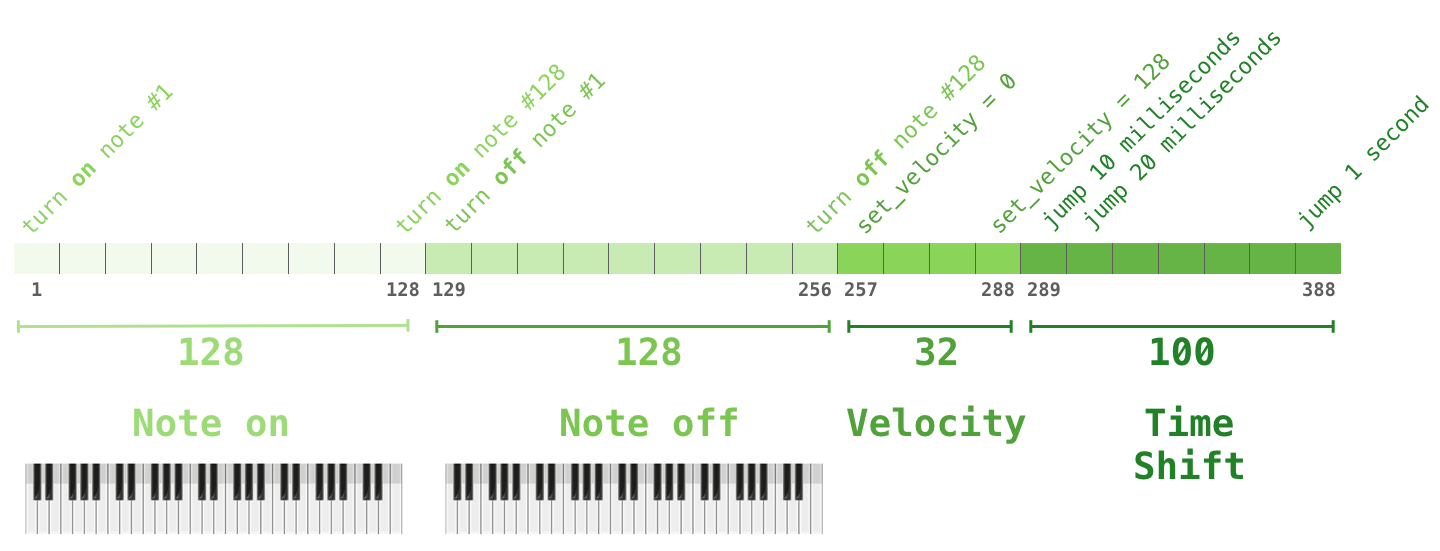
– one-hot . midi . :

one-hot :
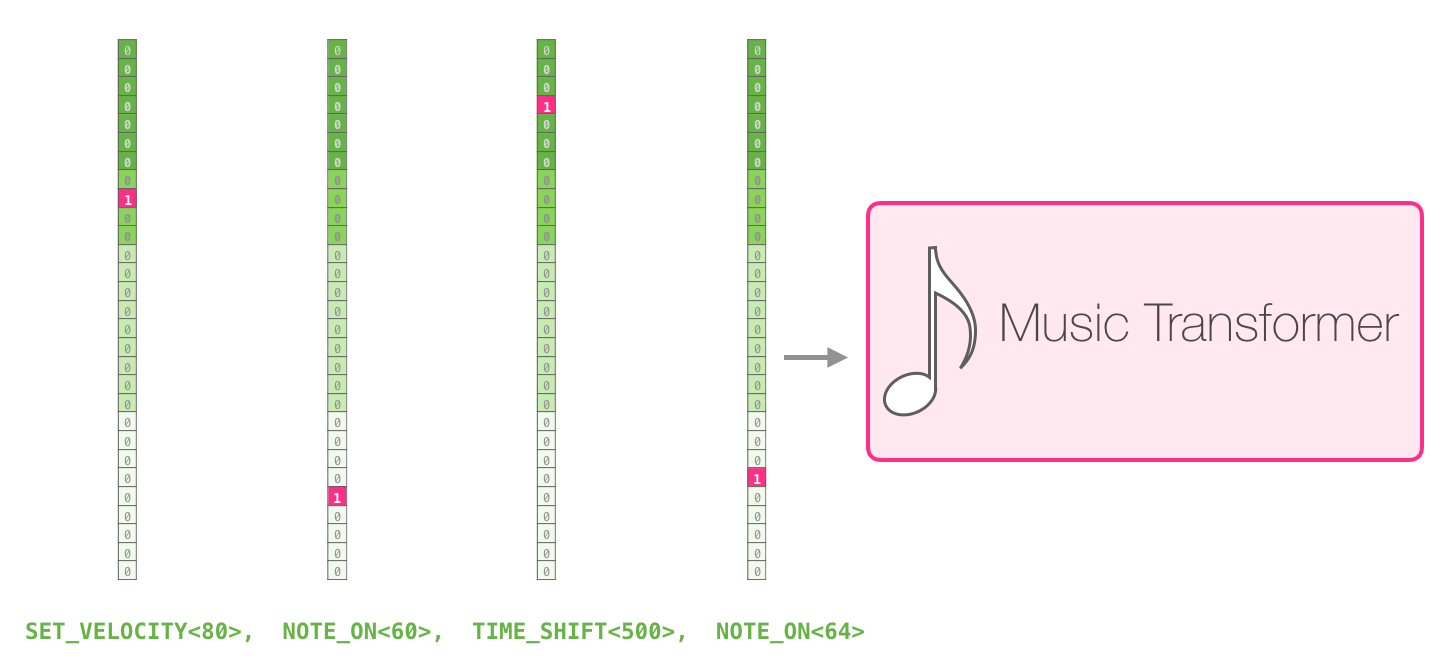
:
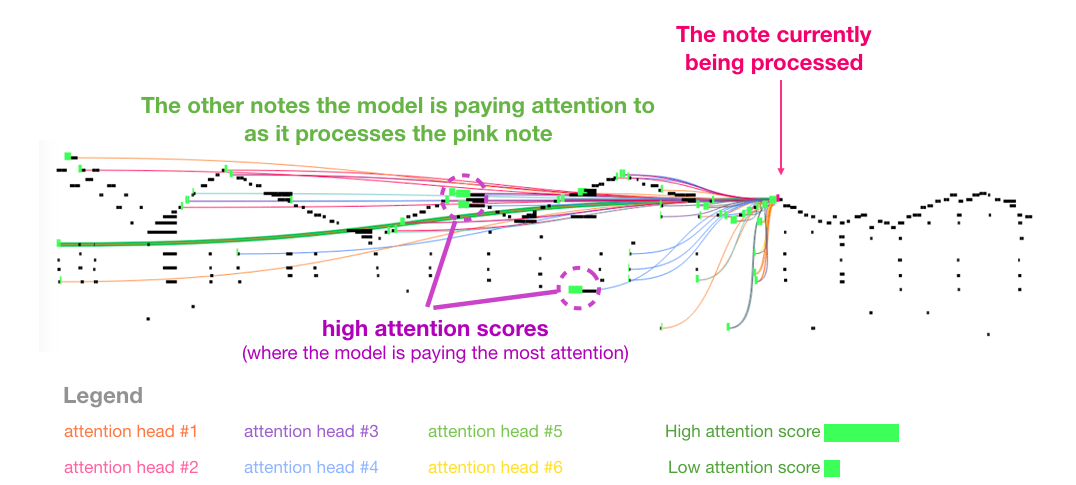
, . .
GPT-2 – . , , , , .
Authors