This article describes some methods to speed up loading front-end applications to implement a responsive, fast user interface.We will discuss the general architecture of the frontend, how to preload the necessary resources and increase the likelihood that they are in the cache. We will discuss a little how to give resources from the backend and when it is possible to limit ourselves to static pages instead of an interactive client application.The download process is divided into three stages. For each stage, we formulate general strategies for increasing productivity:- Initial rendering : how long does it take for the user to see at least something
- Reduce rendering blocking requests
- Avoid sequential chains
- Reuse server connections
- Service Workers for Instant Rendering
- : ,
- :
Until the initial rendering, the user does not see anything on the screen. What do we need for this rendering? At a minimum, upload an HTML document, and in most cases additional resources, such as CSS and JavaScript files. Once they are available, the browser can begin some kind of rendering. WebPageTestcharts are provided throughout this article . The query sequence for your site will probably look something like this. The HTML document loads a bunch of additional files, and the page is rendered after they are downloaded. Please note that CSS files are loaded in parallel to each other, so each additional request does not add significant delay. (Note: in the screenshot, gov.uk is an example where HTTP / 2 is now enabled so that the resource domain can reuse an existing connection. See below for server connections.)
so that the resource domain can reuse an existing connection. See below for server connections.)Reduce rendering blocking requests
Style sheets and (by default) scripts block the rendering of any content below them.There are several options to fix this:- Move script tags to the bottom of the body
- Download scripts in asynchronous mode using
async
- If JS or CSS should be loaded sequentially, it is better to embed them with small snippets
Avoid conversations with sequential requests that block rendering
The delay in rendering the site is not necessarily associated with a large number of requests that block rendering. More important is the size of each resource, as well as the start time of its download. That is, the moment when the browser suddenly realizes that this resource needs to be downloaded.If the browser detects the need to download the file only after completing another request, then there is a chain of requests. It can form for various reasons:@importCSS Rules
- Web fonts referenced by the CSS file
- Downloadable JavaScript or script tags
Take a look at this example: One of the CSS files on this site loads the Google font through the rule
One of the CSS files on this site loads the Google font through the rule @import. This means that the browser has to take turns executing the following requests:- HTML document
- CSS applications
- CSS for Google Fonts
- Google Font Woff File (not shown in diagram)
To fix this, first move the Google Fonts CSS request from the tag @importto the link in the HTML document. So we shorten the chain by one link.To speed things up even further, embed Google Fonts CSS directly into your HTML or CSS file.(Keep in mind that the CSS response from the Google Fonts server depends on the user agent line. If you make a request using IE8, the CSS will refer to the EOT file, IE11 will receive the woff file, and modern browsers will receive the woff2 file. If you agree that old browsers will be limited to system fonts, you can simply copy and paste the contents of the CSS file to yourself).Even after the start of rendering, the user is unlikely to be able to interact with the page, because the font needs to be loaded to display the text. This is an additional network delay that I would like to avoid. The swap parameter is useful here , it allows you to use it font-displaywith Google Fonts, and store fonts locally.Sometimes the query chain cannot be resolved. In such cases, you might want to consider the preload or preconnect tag . For example, the website in the example above may connect to fonts.googleapis.combefore the actual CSS request arrives.Reusing server connections to speed up requests
To establish a new connection to the server, usually requires three packet exchanges between the browser and the server:- DNS lookup
- Establish a TCP Connection
- Establish an SSL Connection
After the connection is established, at least one more packet exchange is required to send a request and receive a response.The chart below shows that we initiate a connection with four different servers: hostgator.com, optimizely.com, googletagmanager.com, and googelapis.com.However, subsequent server requests may reuse an existing connection . The download base.csseither index1.csshappens faster because they are located on the same server hostgator.comwith which a connection has already been established.
Reduce file size and use CDN
You control two factors that affect the query execution time: the size of the resource files and the location of the servers.Send as little data to the user as possible and make sure they are compressed (for example, using brotli or gzip).Content Delivery Networks (CDNs) have servers all over the world. Instead of connecting to a central server, a user can connect to a CDN server that is closer. Thus, packet exchange will be much faster. This is especially suitable for static resources such as CSS, JavaScript, and images, as they are easy to distribute via CDN.Eliminate network latency with service workers
Service Workers allow you to intercept requests before sending them to the network. This means that the answer comes almost instantly !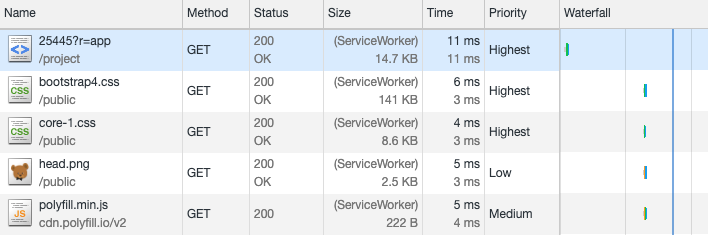 Of course, this only works if you really do not need to receive data from the network. The answer should already be cached, so the benefit will appear only from the second application download.The service worker below caches the HTML and CSS needed to render the page. When the application loads again, it tries to issue cached resources itself - and accesses the network only if they are unavailable.
Of course, this only works if you really do not need to receive data from the network. The answer should already be cached, so the benefit will appear only from the second application download.The service worker below caches the HTML and CSS needed to render the page. When the application loads again, it tries to issue cached resources itself - and accesses the network only if they are unavailable.self.addEventListener("install", async e => {
caches.open("v1").then(function (cache) {
return cache.addAll(["/app", "/app.css"]);
});
});
self.addEventListener("fetch", event => {
event.respondWith(
caches.match(event.request).then(cachedResponse => {
return cachedResponse || fetch(event.request);
})
);
});
In this guide, explained in detail on the use of service workers` to preload and cache resources.Download application
So, the user sees something on the screen. What further steps are necessary for him to use the application?- Download application code (JS and CSS)
- Download the required data for the page
- Download additional data and images
 Please note that not only downloading data from the network may delay rendering. Once your code is loaded, the browser should analyze, compile and execute it.
Please note that not only downloading data from the network may delay rendering. Once your code is loaded, the browser should analyze, compile and execute it.Download only the necessary code and maximize the number of hits in the cache
“Break a package” means downloading only the code needed for the current page, not the entire application. It also means that parts of the package can be cached, even if other parts have changed and need to be reloaded.As a rule, the code is divided into the following parts:- Code for a specific page (page-specific)
- Common application code
- Third-party modules that rarely change (great for caching!)
Webpack can automatically do this optimization, break the code, and reduce the overall load weight. The code is broken into pieces using the optimization.splitChunks object . Separate the runtime (runtime) into a separate file: this way you can benefit from long-term caching. Ivan Akulov wrote a detailed guide on breaking a package into separate files and caching in Webpack .It is not possible to automatically allocate code for a specific page. You must manually identify those parts that can be downloaded separately. Often this is a specific path or set of pages. Use dynamic imports to lazily load this code.Dividing the overall package into parts will increase the number of requests to download your application. But this is not a big problem if requests are executed in parallel, especially if the site is loaded using the HTTP / 2 protocol. You can see this for the first three queries in the following diagram: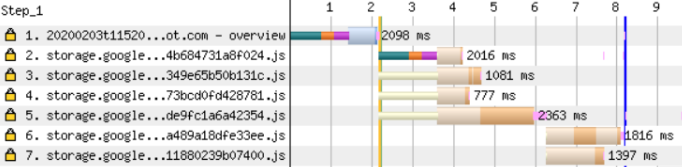 However, two consecutive queries are also visible in the diagram. These fragments are needed only for this particular page and they are loaded dynamically through
However, two consecutive queries are also visible in the diagram. These fragments are needed only for this particular page and they are loaded dynamically through import().You can try to fix the problem by inserting a tag preload preload .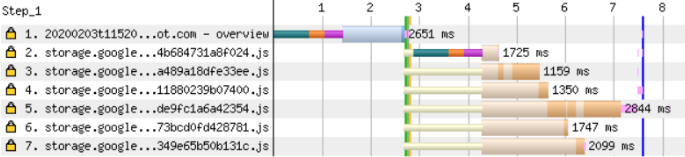 But we see that the total page load time has increased.Resource preloading is sometimes counterproductive as it delays the loading of more important files. ReadAndy Davis's article on preloading fonts and how this procedure blocks the start of page rendering.
But we see that the total page load time has increased.Resource preloading is sometimes counterproductive as it delays the loading of more important files. ReadAndy Davis's article on preloading fonts and how this procedure blocks the start of page rendering.Loading data for a page
Your application should probably show some data. Here are some tips you can use to download this data early without unnecessary rendering delays.Do not wait for the full download of the package before you start downloading the data
Here is a special case of a chain of sequential requests: you download the entire application package, and then this code requests the necessary data for the page.There are two ways to avoid this:- Embed data in an HTML document
- Run a data request using the built-in script inside the document
Embedding the data in HTML ensures that the application does not wait for it to load. It also reduces the complexity of the system, since you do not need to handle the boot status.However, this is not a good idea if such a technique delays the initial rendering.In this case, as well as if you are submitting a cached HTML document through a service worker, you can use the built-in script to download this data as an alternative. You can make it available as a global object, here's a promise:window.userDataPromise = fetch("/me")
If the data is ready, and in such a situation, the application can immediately start rendering or wait until it is ready.When using both methods, you need to know in advance what data the page will load before the application starts rendering. This is usually obvious for user-related data (username, notifications, etc.), but more difficult with content that is specific to a particular page. Perhaps it makes sense to highlight the most important pages and write your own logic for them.Do not block rendering while waiting for irrelevant data
Sometimes, to generate data, you need to run slow complex logic on the backend. In such cases, you can try to download a simpler version of the data first, if this is enough to make the application functional and interactive.For example, an analytics tool may first download a list of all charts before loading data. This allows the user to immediately search for the diagram of interest to him, and also helps to distribute backend requests to different servers.
Avoid Consecutive Data Queries
This may contradict the previous paragraph that it is better to put out non-essential data in a separate request. Therefore, it should be clarified: avoid chains with sequential data requests, if each completed request does not lead to the fact that the user is shown more information .Instead of first querying which user is logged in and then requesting a list of his groups, immediately return the list of groups along with the user information in the first query. You can use GraphQL for this , but the endpoint user?includeTeams=truealso works fine.Server side rendering
Server-side rendering means pre-rendering the application, so a full-page HTML is returned on client request. The client sees the page completely rendered, without waiting for additional code or data to load!Since the server sends the client just static HTML, the application is not interactive at this point. You need to download the application itself, start the rendering logic, then connect the necessary event listeners to the DOM.Use server-side rendering if viewing non-interactive content is valuable in and of itself. It’s also nice to cache rendered HTML on the server and immediately return it to all users without delay. For example, server-side rendering is great when using React to display blog posts.ATThis article by Mikhail Yanashek describes how to combine service workers and server-side rendering.Next page
At some point, the user is about to press a button and go to the next page. From the moment you open the start page, you control what happens in the browser, so you can prepare for the next interaction.Resource preloading
If you preload the code needed for the next page, the delay disappears when the user starts navigation. Use prefetch tags or webpackPrefetchfor dynamic import:import(
"./TodoList"
)
Consider what kind of load you place on the user in terms of traffic and bandwidth, especially if he is connected via a mobile connection. If a person downloaded the mobile version of the site and the data storage mode is active, then it is reasonable to preload less aggressively.Strategically consider which parts of the application the user will need before.Reuse of already downloaded data
Cache data locally in your application and use it to avoid future requests. If the user goes from the list of his groups to the “Edit group” page, you can make the transition instantly, reusing previously downloaded data about the group.Please note that this will not work if the object is often edited by other users and the downloaded data may become outdated. In these cases, there is an option to first show existing read-only data while simultaneously executing a request for updated data.Conclusion
This article lists a number of factors that can slow down your page at different stages of the loading process. Tools like Chrome DevTools , WebPageTest and Lighthouse will help you figure out which of these factors affect your application.In practice, rarely is optimization immediately going in all directions. We need to find out what has the greatest impact on users, and focus on it.While I was writing the article, I realized one important thing: I had an entrenched belief that many individual server requests were bad for performance. This was the case in the past, when each request required a separate connection, and browsers allowed only a few connections per domain. But with HTTP / 2 and modern browsers this is no longer the case.There are good arguments in favor of splitting the application into parts (with multiplying queries). This allows you to download only the necessary resources and it is better to use the cache, since only the changed files will have to be reloaded.