My name is Pavel Parkhomenko, I am an ML developer. In this article, I would like to talk about the design of the Yandex.Zen service and share technical improvements, the introduction of which allowed to increase the quality of recommendations. From the post you will learn how to find the most relevant for the user among millions of documents in just a few milliseconds; how to do continuous decomposition of a large matrix (consisting of millions of columns and tens of millions of rows) so that new documents receive their vector in tens of minutes; how to reuse user-article matrix decomposition to get a good vector representation for video. Our recommendation database contains millions of documents of various formats: text articles created on our platform and taken from external sites, videos, narratives and short posts. The development of such a service is associated with a large number of technical challenges. Here are some of them:
Our recommendation database contains millions of documents of various formats: text articles created on our platform and taken from external sites, videos, narratives and short posts. The development of such a service is associated with a large number of technical challenges. Here are some of them:- Separate computational tasks: do all the heavy operations offline, and in real time only perform rapid application of models in order to be responsible for 100-200 ms.
- Quickly consider user actions. For this, it is necessary that all events are instantly delivered to the recommender and affect the outcome of the models.
- Make the tape so that new users quickly adapt to their behavior. People who have just entered the system should feel that their feedback influences recommendations.
- Quickly understand who to recommend a new article.
- Respond quickly to the constant emergence of new content. Tens of thousands of articles are published every day, and many of them have a limited lifespan (say, news). This is their difference from films, music and other long-lived and expensive content creation.
- Transfer knowledge from one domain domain to another. If the recommender system has trained models for text articles and we add video to it, you can reuse existing models so that the new type of content is better ranked.
I will tell you how we solved these problems.Candidate Selection
How in a few milliseconds to reduce the set of documents under consideration a thousand times, without practically worsening the quality of the ranking?Suppose we trained many ML models, generated attributes based on them, and trained another model that ranks documents for the user. Everything would be fine, but you can’t just take and count all the signs for all documents in real time, if there are millions of these documents, and recommendations need to be built in 100-200 ms. The task is to choose from millions a certain subset that will be ranked for the user. This step is commonly called candidate selection. It has several requirements. Firstly, the selection must take place very quickly, so that as much time as possible remains on the ranking itself. Secondly, by greatly reducing the number of documents for ranking, we must keep the documents relevant to the user as fully as possible.Our principle of candidate selection has evolved evolutionarily, and at the moment we have come to a multi-stage scheme: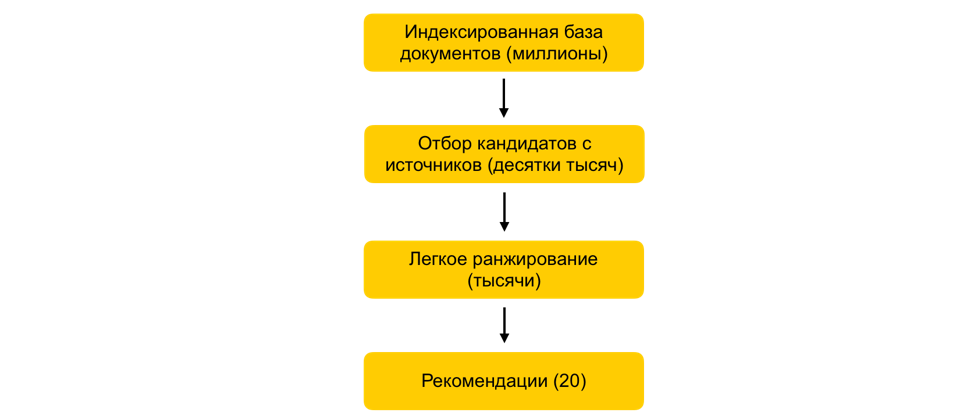 First, all documents are divided into groups, and the most popular documents are taken from each group. Groups can be sites, topics, clusters. For each user, based on his story, the groups closest to him are selected and the best documents are already taken from them. We also use the kNN index to select the documents closest to the user in real time. There are several methods for constructing the kNN index, we have the best earned HNSW(Hierarchical Navigable Small World graphs). This is a hierarchical model that allows you to find N nearest vectors for a user from a millionth database in a few milliseconds. Previously, we offline index our entire database of documents. Since the search in the index works quite quickly, if there are several strong embeddings, you can make several indexes (one index for each embedding) and access each of them in real time.We still have tens of thousands of documents for each user. This is still a lot to count all the attributes, so at this stage we apply easy ranking - a lightweight heavy ranking model with fewer attributes. The task is to predict what documents the heavy model will have in the top. The documents with the highest prediction will be used in the heavy model, that is, at the last stage of ranking. This approach allows for tens of milliseconds to reduce the database of documents considered for the user from millions to thousands.
First, all documents are divided into groups, and the most popular documents are taken from each group. Groups can be sites, topics, clusters. For each user, based on his story, the groups closest to him are selected and the best documents are already taken from them. We also use the kNN index to select the documents closest to the user in real time. There are several methods for constructing the kNN index, we have the best earned HNSW(Hierarchical Navigable Small World graphs). This is a hierarchical model that allows you to find N nearest vectors for a user from a millionth database in a few milliseconds. Previously, we offline index our entire database of documents. Since the search in the index works quite quickly, if there are several strong embeddings, you can make several indexes (one index for each embedding) and access each of them in real time.We still have tens of thousands of documents for each user. This is still a lot to count all the attributes, so at this stage we apply easy ranking - a lightweight heavy ranking model with fewer attributes. The task is to predict what documents the heavy model will have in the top. The documents with the highest prediction will be used in the heavy model, that is, at the last stage of ranking. This approach allows for tens of milliseconds to reduce the database of documents considered for the user from millions to thousands.ALS step in runtime
How to take into account the user's feedback immediately after a click?An important factor in the recommendations is the response time to the user's feedback. This is especially important for new users: when a person is just starting to use the recommendation system, he receives a non-personalized stream of documents of various topics. As soon as he makes the first click, you must immediately take this into account and adapt to his interests. If all factors are calculated offline, a quick system response will become impossible due to the delay. So you need to process user actions in real time. For these purposes, we use the ALS step in runtime to build a vector representation of the user.Suppose we have a vector representation for all documents. For example, we can offline build on the basis of the article text embeddings using ELMo, BERT or other machine learning models. How can one get a vector representation of users in the same space based on their interaction in the system?The general principle of the formation and decomposition of the user-document matrixm n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

One of the possible ways of matrix decomposition is ALS (Alternating Least Squares). We will optimize the following loss function:
Here r ui is the interaction of user u with document i, q i is the vector of document i, p u is the vector of user u.Then the user vector that is optimal from the point of view of the mean square error (for fixed document vectors) is found analytically by solving the corresponding linear regression.This is called an ALS step. And the ALS algorithm itself consists in the fact that we alternately fix one of the matrices (users and articles) and update the other, finding the optimal solution.Fortunately, finding a user's vector representation is a fairly quick operation that can be done in runtime using vector instructions. This trick allows you to immediately take into account the user's feedback in the ranking. The same embedding can be used in the kNN index to improve the selection of candidates.Distributed Collaborative Filtering
How to do incremental distributed matrix factorization and quickly find a vector representation of new articles?Content is not the only source of signals for recommendations. Collaborative information is another important source. Good signs in ranking can traditionally be obtained from the decomposition of the user-document matrix. But when trying to do this decomposition, we ran into problems:1. We have millions of documents and tens of millions of users. The matrix does not fit entirely on one machine, and the decomposition will be very long.2. Most of the content in the system has a short lifetime: documents remain relevant for only a few hours. Therefore, it is necessary to construct their vector representation as quickly as possible.3. If you build the decomposition immediately after the publication of the document, a sufficient number of users will not have time to evaluate it. Therefore, its vector representation is likely to be not very good.4. If the user likes or dislikes, we will not be able to immediately take this into account in the expansion.To solve these problems, we implemented a distributed decomposition of the user-document matrix with a frequent incremental update. How exactly does it work?Suppose we have a cluster of N machines (N in the hundreds) and we want to make a distributed decomposition of the matrix on them, which does not fit on one machine. The question is how to perform this decomposition so that, on the one hand, there is enough data on each machine and, on the other, so that the calculations are independent?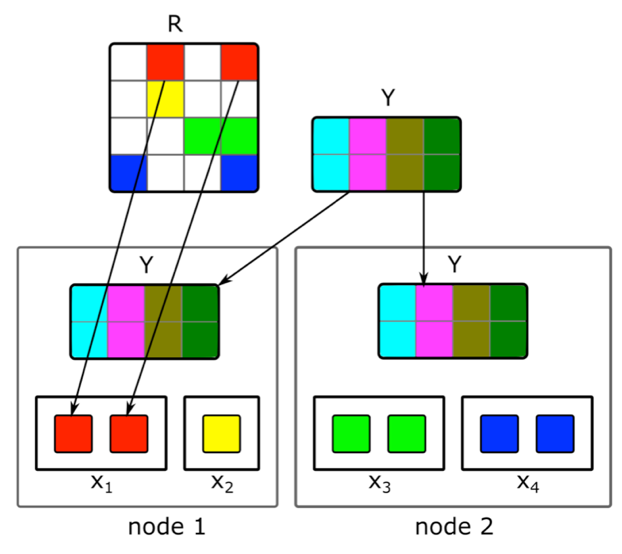 We will use the ALS decomposition algorithm described above. Consider how to perform one ALS step in a distributed manner - the rest of the steps will be similar. Suppose we have a fixed matrix of documents and we want to build a matrix of users. To do this, we divide it into N parts in rows, each part will contain approximately the same number of rows. We will send to each machine non-empty cells of the corresponding lines, as well as a matrix of document embeddings (in whole). Since it is not very large, and the user-document matrix is usually very sparse, this data will fit on a regular machine.Such a trick can be repeated for several eras until the model converges, alternately changing the fixed matrix. But even then, the decomposition of the matrix can last several hours. And this does not solve the problem of the need to quickly receive embeddings of new documents and update embeddings of those about which there was little information when building the model.The introduction of a quick incremental update of the model helped us. Suppose we have a current trained model. Since her training, new articles have appeared with which our users have interacted, as well as articles that have had little interaction with the training. To quickly embed such articles, we use user embeddings obtained during the first large model training and take one ALS step to calculate the matrix of documents with a fixed matrix of users. This allows you to receive embeddings quite quickly - within a few minutes after the publication of a document - and often update embeddings of fresh documents.In order to immediately take into account human actions for recommendations, in runtime we do not use user embeds received offline. Instead, we take the ALS step and get the current user vector.
We will use the ALS decomposition algorithm described above. Consider how to perform one ALS step in a distributed manner - the rest of the steps will be similar. Suppose we have a fixed matrix of documents and we want to build a matrix of users. To do this, we divide it into N parts in rows, each part will contain approximately the same number of rows. We will send to each machine non-empty cells of the corresponding lines, as well as a matrix of document embeddings (in whole). Since it is not very large, and the user-document matrix is usually very sparse, this data will fit on a regular machine.Such a trick can be repeated for several eras until the model converges, alternately changing the fixed matrix. But even then, the decomposition of the matrix can last several hours. And this does not solve the problem of the need to quickly receive embeddings of new documents and update embeddings of those about which there was little information when building the model.The introduction of a quick incremental update of the model helped us. Suppose we have a current trained model. Since her training, new articles have appeared with which our users have interacted, as well as articles that have had little interaction with the training. To quickly embed such articles, we use user embeddings obtained during the first large model training and take one ALS step to calculate the matrix of documents with a fixed matrix of users. This allows you to receive embeddings quite quickly - within a few minutes after the publication of a document - and often update embeddings of fresh documents.In order to immediately take into account human actions for recommendations, in runtime we do not use user embeds received offline. Instead, we take the ALS step and get the current user vector.Transfer to another domain area
How to use a user's feedback to text articles to build a vector representation of a video?Initially, we recommended only text articles, so many of our algorithms are focused on this type of content. But when adding content of a different type, we were faced with the need to adapt models. How did we solve this problem using the example video? One option is to retrain all models from scratch. But this is a long time, besides, some of the algorithms are demanding on the volume of the training sample, which is not yet in the right quantity for a new type of content in the first moments of its life on the service.We went the other way and reused text models for the video. In creating vector representations of the video, the same trick with ALS helped us. We took a vector representation of users based on text articles and took the ALS step using information about video views. So we easily got a vector representation of the video. And in runtime, we simply calculate the proximity between the user vector obtained from text articles and the video vector.Conclusion
The development of the core of a real-time recommender system is fraught with many tasks. It is necessary to quickly process data and apply ML methods to effectively use this data; Build complex distributed systems capable of processing user signals and new content units in a minimum amount of time; and many other tasks.In the current system, the device of which I described, the quality of recommendations for the user grows with its activity and the duration of the service. But of course, here lies the main difficulty: it is difficult for the system to immediately understand the interests of a person who interacted little with content. Improving recommendations for new users is our key concern. We will continue to optimize the algorithms so that the content relevant to the person gets into his feed faster and the irrelevant does not appear.