 Illustration by melmagazine.com (Source: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Currently, public networks with channels that are not protected from the intruder are widely used for information exchange. Messaging in such a connected and computer network users are forced to protect themselves. Since the user cannot protect the message channels themselves, he protects the message.What is protected in the message? Firstly, syntax (integrity) for this purpose usescoding(coding and analysis of codes), and secondly, semantics (confidentiality) for whichcryptology isused(cryptography and cryptographic analysis), thirdly, indirectly, the violator can limit the availability of the message by hiding the fact of its transmission, which uses steganology (steganography and steganalysis).The listed possibilities are theoretically and practically provided in varying degrees, and although each direction has been developing for a rather long time, they are still far from complete. In the present work, we will touch upon only one particular issue - the analysis of message codes.
Illustration by melmagazine.com (Source: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Currently, public networks with channels that are not protected from the intruder are widely used for information exchange. Messaging in such a connected and computer network users are forced to protect themselves. Since the user cannot protect the message channels themselves, he protects the message.What is protected in the message? Firstly, syntax (integrity) for this purpose usescoding(coding and analysis of codes), and secondly, semantics (confidentiality) for whichcryptology isused(cryptography and cryptographic analysis), thirdly, indirectly, the violator can limit the availability of the message by hiding the fact of its transmission, which uses steganology (steganography and steganalysis).The listed possibilities are theoretically and practically provided in varying degrees, and although each direction has been developing for a rather long time, they are still far from complete. In the present work, we will touch upon only one particular issue - the analysis of message codes.Introduction
The genetic code (HA) was chosen as the object of analysis. You can get acquainted with a curious example of the use of the Civil Code in the field of information security (apparently unprofessional and therefore not successful) here.In coding theory, two important directions can be distinguished: coding of the information source and channel coding. The first of them is implemented, as a rule, by the transmitting party and has the goal of eliminating message redundancy (for example, Morse code), the purpose of the second is to detect and eliminate errors in messages. Before the appearance of the correcting codes, the problem of eliminating errors was solved by retransmission of the distorted fragment of the message at the request of the receiving side.Here we note the fact that it is impossible for the receiving side to decrypt the ciphergram correctly if errors occur in its text. Ciphers do not allow to detect errors, nor even to fix them. For this reason, on the transmitting side of the communication system, the message-ciphergram is encoded with a correction code, and on the receiving side, the decoder in the received message detects (if any) and corrects the errors.After that, the cryptosystem comes into play and the legitimate recipient is given a decrypted message. These are, in general terms, the functioning of networks exchanging secure messages.In this work, we will analyze in detail the very important Genetic code, which was created not by the human mind, but by nature itself (a rare case).The Story of a Discovery and the Nobel Prize
We ask ourselves how, at the level of genetics and metabolism of organisms (cells), are nature implemented such provisions of information exchange in the life of species and their individual representatives?Before the Second World War, the scientific world knew that in living organisms the transmission of hereditary traits from generation to generation is carried out through relatively simple chemical units (genes), which include a huge amount of information necessary for the continuation and reproduction of life.All genes (not proteins) bind into chains (chromosomes) and materialize in deoxyribonucleic acid (DNA). The experts did not have clarity about how everything happens and how the DNA itself is structured.Young researchers, the British physicist F. Crick and the American biologist J. Watson, in 1953 (25.4) published an article in the journal Nature on the structure of deoxyribonucleic acid. At the beginning of their work in 1949, James Watson was 23 years old, Francis Crick and Maurice Wilkins, 33 each.In the article, the authors described a model of the spatial structure of DNA in the form of a double helix, two strands of which were twisted to the right. The strands themselves turned out to be connected by transverse "steps" formed from nucleotides.Definition . Nucleotides are compounds consisting of sugar, nitrogen-containing bases (purine or pyrimidine) and phosphoric acid. Nucleotides are the “building blocks” for DNA and RNA.
This DNA helix is the carrier of the genetic code - the code of heredity of traits of organisms of animals and plants. This was a completely unusual new work on the structure and properties of a molecule of deoxyribonucleic acid.The DNA model of young authors was confirmed by comparing it with an X-ray diffraction pattern of the crystal structure of DNA of the English biophysicist Maurice Wilkins. Later, a genetic code was discovered containing and transmitting information on the synthesis of the structure and composition of proteins - the main components of each cell of living organisms that implements the cell cycle.Definition . The cell cycle is the correct alternation of periods of relative rest with periods of cell division.
In the same year, the authors later published another article that described a possible mechanism for copying DNA by matrix synthesis in the division of living cells. The double helix of DNA was likened to a “lightning lock”.Each thread of the spiral, after “undoing the lock” and diluting the threads, became a synthesizing matrix and was completed with a second thread of material from the cytoplasm of the cell according to the principle of complementarity to complete DNA. It also said that a certain sequence of bases (codons, triplets) is a code that contains genetic information.The idea of mathematizing the code was first expressed by G. Gamov in an article in 1954 as the problem of translating words from a four-letter alphabet (system) into words of a twenty-letter alphabet. He presented the problem of coding life phenomena not as a biochemical, but as a combinatorial mathematical problem. The preliminary long-lasting efforts of the authors of this work are well described in D. Watson's book, The Thread of Life.In 1962, Watson, Crick, and Wilkins received the Nobel Prize in Physiology or Medicine "for discoveries in the molecular structure of nucleic acids and for determining their role in the transfer of information in living matter."They had information about the following facts:- In 1866, Gregor Mendel formulated the provisions that the "elements", later called genes, determine the inheritance of the physical properties of individuals of the species.
- , , () , , .
- 1869 . , . . () (). . 4- ( ): (), (), (G), (); (), (U) , (G), (), ( ) .
- , , – , .
- 1950 . , 4- .
- , , .
- , 20- , (), .
- 1944 « ? ». : « - , , ?».
- 1954 , () 4- 20- , , .
Researchers had to take the next step, and it was taken.There was no shortage of hypotheses and assumptions, but someone had to verify their truth.Overlapping codes (one nucleotide letter is part of more than one codon): triangular, major-minor and sequential, proposed by Gamov and colleagues;non-overlapping codes: combination of Gamow and Ichas, the "comma-free code" of Scream, Griffith and Orgel. In the combination code, amino acids (20) are encoded by triplets of 4 nucleotides, but their order is not important, but only their composition: triplets TTA, TAT, ATT encode the same amino acid in proteins.The comma-free code explained how the “reading frame” is selected. Such a “sliding window” along the DNA strand, where the letters follow, one after another without separators (commas) into words suggests that the words are somehow different. According to the model of F. Crick, an assumption was made: all triplets are divided into meaningful ones, i.e., corresponding to specific amino acids, and not having meaning.If only meaningful triplets form DNA, then in another “reading frame” such triplets will turn out to be meaningless. The authors of this code showed that it is possible to choose triplets that satisfy such requirements and that there are exactly 20. Of course, the authors did not have full confidence in their correctness.Indeed, after 1960, it was shown that the codons, considered by Crick to be senseless, carried out protein synthesis in vitro, and by 1965 the meaning of all 64 triplet codons was established. It also turned out that a number of amino acids are encoded by two, three, four and even six different triplets, i.e. there is a certain redundancy, the purpose of which remains to be determined.Genetic code of life. Inherited Information
. – , ( , G, C, T), , . ( ) – . . .
To encode each of the 20 types of canonical amino acids, from which almost all proteins are further constructed and the terminal stop signal, a set of three nucleotides (letters) called a triplet (codon) is sufficient. The codon sequence forms a gene in the chromosome strand and determines the amino acid sequence in the polypeptide chain of the protein encoded by this gene. There was a concept of "one gene - one enzyme."The classical presentation of information (linearity of its recording) is texts in a broad sense (speech, letters, books, images, films, music, etc.) of this word in some natural language (EY). The language includes an extensive vocabulary (vocabulary), and if it has written language apart from spoken language, then the alphabet with a grammar.To preserve information for a long time and transfer copies of it, a strong, well-protected memory and writing system is required. The hereditary information of living organisms is recorded by nature's EY in long texts with words in a certain “molecular” alphabet, which are stored in the form of chromosomes in the nuclei of all cells of living organisms.The processes and ways of transferring information recorded on its natural carrier molecules are formulated by F. Crick (1958) in the form of the central dogma of molecular biology . Three main processes provide control of all other processes of cell functioning and the life of organisms as a whole.These processes are: replication , transcription and translation. Further, they will be discussed in more detail. Information in organisms is transmitted only in one direction from nucleic acids (DNA → RNA → protein) to a protein; reverse transmission does not exist. Special cases of DNA → protein, RNA → RNA, RNA → DNA are possible.Reading information along molecular chains is permissible in only one forward direction. The term “reading frame” is used.Definition . A reading frame (open) is a sequence of non-overlapping codons capable of synthesizing a protein, starting with a start codon and ending with a stop codon. The frame is determined by the very first triplet from which the broadcast begins.
To start broadcasting, a start codon is not enough, you also need an initiation codon (there are three of them: AUG, GUG, UUG). After reading it, translation takes place by sequentially reading the codons of the ribosomal rRNA and attaching the amino acids to each other by the ribosome until the stop codon is reached.During translation, codons are always “read” from some starting initiating symbol (AUG) and do not overlap. Reading after the start of triplet after triplet goes to the stop codon of the completion of the synthesis of the protein polypeptide chain.These facts are summarized in a table of methods for transmitting genetic information.Table 1 - the Central dogma of molecular biology The history of the study of texts of the heredity of organisms, their comprehension, is long, rich in discoveries, achievements, delusions and disappointments. The list of events in the history of comprehension (cognition) of the texts of nature is of undoubted interest, both for science and for each individual person.The words of the texts are very long, but the alphabet of writing “EYA nature” contains only four letters - these are molecular bases: in RNA it is A (adenine), C (cytosine), G (guanine), U (uracil) (in DNA, uracil is replaced on T (thymine)). The language of wildlife is the language of molecules.Biologists have established that each word of the text of heredity is formed by a polymer DNA molecule (deoxyribonucleic acid, discovered in 1868 by the physician I.F. Misher), built of 4 bases (nucleotides - from nuclear - nuclear).The bases are bonded (connected) to each other in pairs, A ← → T, T ← → A, G ← → C, C ← → G with special hydrogen bonds that implement the principle of complementarity (complementarity). These facts were established at different times, by different scientists and methods of many sciences (physics, chemistry, biology, cytology, genetics, etc.). Difficulties on the way of knowing this NJ met constantly.DNA molecules did not crystallize, but when this was done, the task of establishing the DNA structure was reduced to solving the inverse problem of X-ray diffraction analysis (Fourier transform of the diffraction pattern of the crystal created on the screen by X-rays).The model calculated and hand-assembled by J. Watson and Francis Crick in 1953 is similar to the LEGO children's game, where the elements were molecular bases and the interatomic distances and pivot angles were very accurately maintained, the chromosome structure was reproduced on a large scale.This model practically confirmed the diverse hypotheses of theorists and convincingly proved the absence of discrepancies with practical experiments and the results of X-ray diffraction analysis of crystalline DNA.The main detailed data on the chemical structure of DNA and the numerical characteristics of the model were obtained by Rosalinda Franklin and M. Wilkins earlier in 1953 in the laboratory of X-ray analysis. The conflict of scientists is described in the novel "Loneliness on the Net" by Janusz Leon Wisniewski.The presence of the visual structure of DNA and its quantitative characteristics gave impetus to the development of genetics and all biosciences, from which the idea of the Human Genome project arose in 2000. Watson became the first leader of this project, the chromosome set of the human Homo sapiens was completely deciphered within the project. The complete genetic map of the 1st chromosome was completed in 2006. The map contains 3141 genes and 991 pseudogenes.From the point of view of mathematics, four elements of the alphabet can be attributed to four elements of a finite extended Galois field GF (2 2 ) = ( 0, 1, α, β ), the operations with which are performed modulo the irreducible polynomial p (x) = x 2 + x + 1 . Then α + β = 1, α ∙ β = 1and the mapping of the field elements to letters takes the form
The history of the study of texts of the heredity of organisms, their comprehension, is long, rich in discoveries, achievements, delusions and disappointments. The list of events in the history of comprehension (cognition) of the texts of nature is of undoubted interest, both for science and for each individual person.The words of the texts are very long, but the alphabet of writing “EYA nature” contains only four letters - these are molecular bases: in RNA it is A (adenine), C (cytosine), G (guanine), U (uracil) (in DNA, uracil is replaced on T (thymine)). The language of wildlife is the language of molecules.Biologists have established that each word of the text of heredity is formed by a polymer DNA molecule (deoxyribonucleic acid, discovered in 1868 by the physician I.F. Misher), built of 4 bases (nucleotides - from nuclear - nuclear).The bases are bonded (connected) to each other in pairs, A ← → T, T ← → A, G ← → C, C ← → G with special hydrogen bonds that implement the principle of complementarity (complementarity). These facts were established at different times, by different scientists and methods of many sciences (physics, chemistry, biology, cytology, genetics, etc.). Difficulties on the way of knowing this NJ met constantly.DNA molecules did not crystallize, but when this was done, the task of establishing the DNA structure was reduced to solving the inverse problem of X-ray diffraction analysis (Fourier transform of the diffraction pattern of the crystal created on the screen by X-rays).The model calculated and hand-assembled by J. Watson and Francis Crick in 1953 is similar to the LEGO children's game, where the elements were molecular bases and the interatomic distances and pivot angles were very accurately maintained, the chromosome structure was reproduced on a large scale.This model practically confirmed the diverse hypotheses of theorists and convincingly proved the absence of discrepancies with practical experiments and the results of X-ray diffraction analysis of crystalline DNA.The main detailed data on the chemical structure of DNA and the numerical characteristics of the model were obtained by Rosalinda Franklin and M. Wilkins earlier in 1953 in the laboratory of X-ray analysis. The conflict of scientists is described in the novel "Loneliness on the Net" by Janusz Leon Wisniewski.The presence of the visual structure of DNA and its quantitative characteristics gave impetus to the development of genetics and all biosciences, from which the idea of the Human Genome project arose in 2000. Watson became the first leader of this project, the chromosome set of the human Homo sapiens was completely deciphered within the project. The complete genetic map of the 1st chromosome was completed in 2006. The map contains 3141 genes and 991 pseudogenes.From the point of view of mathematics, four elements of the alphabet can be attributed to four elements of a finite extended Galois field GF (2 2 ) = ( 0, 1, α, β ), the operations with which are performed modulo the irreducible polynomial p (x) = x 2 + x + 1 . Then α + β = 1, α ∙ β = 1and the mapping of the field elements to letters takes the form , and the additional (complementary) nucleotide is calculated according to the rule ¬ → x + 1 , whence T → A + 1, C → G + 1.Structurally, the DNA model represents two equidistant polymer chains of pairwise connected nucleotides (by the principle of a rope ladder) and twisted into a right double spiral. Below in the text, vertically written pairs of letters correspond to the steps of the "ladder":T A GGTTCG T ...
, and the additional (complementary) nucleotide is calculated according to the rule ¬ → x + 1 , whence T → A + 1, C → G + 1.Structurally, the DNA model represents two equidistant polymer chains of pairwise connected nucleotides (by the principle of a rope ladder) and twisted into a right double spiral. Below in the text, vertically written pairs of letters correspond to the steps of the "ladder":T A GGTTCG T ...
ATCCAAGCA ...Two chains repeat the sequence of letters, but the beginning of one is located opposite the end of the other. Information in DNA molecules is recorded with a high degree of redundancy, which, of course, provides a high level of reliability when reading information and copying it (replication: DNA → DNA). One more word is attributed to the original word, but in additional code.All chromosomes contain genes in their composition and are contained in each cell in a very small volume (in the cell nucleus) and are short and very long. The distance between DNA strands is 2 nm, between the “steps” - 0.31 nm, one complete revolution of the “helix” every 10 pairs. The total length of all DNA stretched into one strand reaches 2 m. Human hereditary information is recorded on 23 chromosomes. The length of the chromosome is about 10 9nucleotides, and the diameter of the nucleus is less than a micrometer. Thus, the DNA in the cell is compacted.Definition . Gene (Greek.γενοζ - genus). The structural and functional unit of the heredity of living organisms. Genes (more precisely alleles) determine the hereditary traits of organisms transmitted from parents to offspring during reproduction.
In the words of DNA, it is possible to isolate and consider individual sub-subparts (genes) that carry integral information about the structure of one protein molecule or one RNA molecule. In addition, genes are characterized by regulatory sequences (promoters).Promoters can be located both in close proximity to an open reading frame encoding a protein or the beginning of an RNA sequence, and at a distance of many millions of base pairs (nucleotides), for example, in cases with enhancers, insulators and suppressors.Each gene is designed and responsible for creating a specific protein necessary for the life of the body. The concept of genotype denotes the hereditary constitution of gametes (germ cells) and zygotes (somatic cells), in contrast to the phenotype describing acquired characters that are not inherited.Block codes
Code is a multi-valued concept. First of all, a code can be called a code set of code words that form the code itself. It is these words that the decoder recognizes on the receiving side when transmitting messages, and on the transmitting side, the encoder forms them.When generating code words, a unique mapping of a finite ordered set of characters belonging to a certain finite alphabet to another, not necessarily ordered, usually more extensive set of characters for encoding transmission, storage or transformation of information is used. Welist the properties of the genetic code under consideration:- . . in Vitro ( ). () () .
- . , .
- . . ( ) – , , .
. . 4- , , 20 , , ( ) .
, (), 4; 2- (), 42 =16 ; () 43 = 64 > 20 . .
- . . , -, , - . .
. 64 1965 . , . , (). .
2 —

20 61 , . , . AUG – .
. . AGC, GCU, CUA,… , . , . .
- . - .
, . ( ) ( ) .
- . - , . : AUG ( ) , – .
- . . . 1961 . .
- – ;
- – ( ) .
Consider two discrete sets X and n containing respectively | X | and | n | elements and mapping φ : n → X . When representing arbitrary mappings of sets with words in the alphabet X, we get a set of X n words, each of n characters in length from the available q = | X |, which form the alphabet of text messages. It is convenient to arrange all the words X n in lexicographical order in a general list.Our goal in this part of the work is to generate a code that provides encoding (conversion) of the transmitted data into a form convenient for transmission in space and time and broadcasting (translation) from one language to another understandable to the message recipient.Generating a code involves choosing the alphabet, determining regularity, and when choosing a regular code, determining the length of the code word, determining the number of code words, determining the letter-by-word composition of each word.Table 3 - The genetic code consists of 64 code words of 3 letters each. Table 4 - Inverse values of the code sequence of RNA triplets
Table 4 - Inverse values of the code sequence of RNA triplets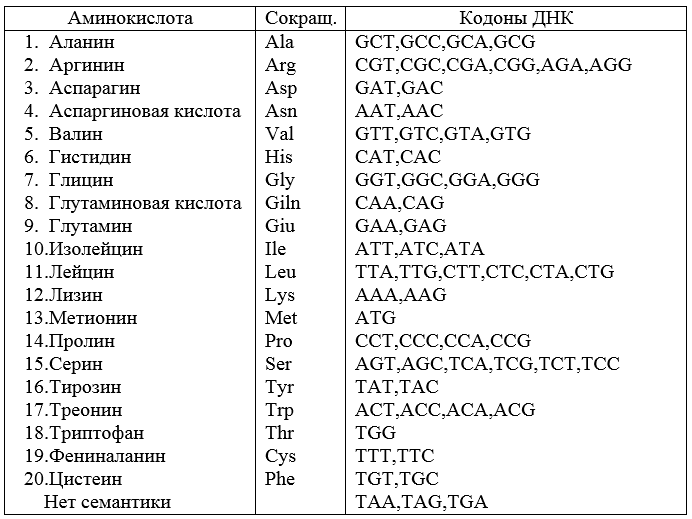 Additional properties of the code, for example, the code should not have a comma, are determined by more stringent requirements for the named code parameters. A comma-free code must have words with a maximum period. Such requirements are focused on the convenience of subsequent synthesis of the codec. Closely related to these provisions of code synthesis are issues of coding information and its decoding.
Additional properties of the code, for example, the code should not have a comma, are determined by more stringent requirements for the named code parameters. A comma-free code must have words with a maximum period. Such requirements are focused on the convenience of subsequent synthesis of the codec. Closely related to these provisions of code synthesis are issues of coding information and its decoding.Code analysis
The task of code analysis sounds completely different when the code already exists and is used, but little is known about it itself. Coded messages are available for viewing and study, but they are so diverse and numerous that the principle of their creation is not visible even with a very extensive analysis.Actually, the coding system itself is also available for observation and study, but the level of complexity of its construction and functioning does not allow to obtain a complete qualitative and reliable description.Information (data) is a message, i.e. a chain of characters of the alphabet, which from some starting position can be divided into segments (blocks) of length n characters, and each such segment is a code word. The code in this case is block.On the receiving side of the message channel, the recipient should be able to correctly divide the continuous string of message characters into separate words. The use of word delimiters (commas) is undesirable since it requires resources.Synchronization . Without synchronization, the correct translation of the message is impossible. This implies one of the requirements for the generated code - the code must be designed so that synchronization is uniquely provided by the means (properties) of the code itself and the information receiving device.Definition . The process of establishing a position containing the start (initial) character of a code word is called synchronization.
The synchronization task is simply solved if the alphabet uses a special word separator character, for example, a comma. The reading frame of the next codeword is set immediately after the separator.
Such a separator is convenient, but undesirable for several reasons.- Firstly, the code must be such that at the point of arrival of the message it has exactly the same form as at the point of departure (ensuring integrity);
- Secondly, the encoding, decoding time and transmission duration should be as short as possible, since this reduces the possibility of distorting environmental influences on the message text;
- Thirdly, it is desirable to have a small amount of message carrier, since it requires less storage, protection, and other resources.
For better distinguishability of code words, they should be removed from one another by a certain distance in the complete list of possible words, i.e. differ in the composition of the meanings of the symbols, as the vectors of the vector space are components.Therefore, code words can be not all and not any words of the set X n , but only a subset of them D є X n . The choice of the symbolic composition of the code words represents the main task of its formation, since it is the composition of the code words that must ensure the satisfaction of the formulated requirements for the code. Thus, we will further consider the code without a comma.. , . = (1, 2, …, n) = (1, 2, …, n). || = (1, 2, …, n, 1, 2, …, n). n – 1 n n . .
. (2, …, n, 1), (3, …, n, 1, 2)…( n, 1,…, n-2, n-1), .
If all overlaps in concatenation for any pair of code words are not code words, then the mechanism of the receiving side (decoder) of the information transmission channel has the ability to set a unique starting position. This is possible if the decoder of the list D has all the code words and the possibility of matching them with read n characters from the received message.We show how this is done. Let a symbol be selected and fixed in the received sequence of characters. Having counted n characters from the fixed one, the decoder compares the word that turned out with the words in the code list. If there is a match with one of the words in the code list, then synchronization is established. The fixed symbol and its position are starting.If there is no match with any of the words in the code list, i.e., hit the overlapping word, this means that the starting position is located to the left of the fixed position.We move to the left one position from the fixed one and repeat the actions of the previous step until we get at one step a match with one of the code words. This process necessarily has a successful completion in the correct starting position, i.e., synchronization is established on average for the number of n / 2 steps.. () D є n n , , єD .
We have already established that such a code ensures correct synchronization in long chains of code words without separators between them. What words from the set X n are included in the subset D є X n ? If the cardinality of the set X n is divided by integers, then the cardinality D can be one of these divisors (the Lagrange group theorem) and the code is called a group block code without a decimal point ., , D. , D n ( n D), . , D.
Let's move on to the issue of the number of words in the generated code.The power of the code is without a comma. We will find the largest possible number of words in the code D , which we denote by | D | = W n ( q) . It is not possible to get the exact meaning, but an upper estimate for the number of words can be obtained using the concept of the word period . Denote by T k x the cyclic shift of a word of length n by k steps, k < n .. d ( ) k, k = d ≤ n, d | n. d = n (). .
, = (1, 2, 3, 1, 2, 3 ) d < n. || . || = (1, 2, 3 ; 1, 2, 3 , 1, 2, 3 ; 1, 2, 3). , (;) , . , n.
n(q) q . D Wn(q) ≤ n(q)/n .


 Thus, for the source data of example 1, from a set of arbitrary 64 words with a length of 3 characters, you can create a code containing 20 words and providing synchronization. This code is not without flaws. If an error is introduced into one of the words in a single character, the code will not be synchronized. In other words, the code is unstable against errors.The given numerical example can be used to illustrate and explain the genetic code of living organisms, which was created by nature on a long path of evolution and completely deciphered by modern science in 1966. It is established that the genetic code is not overlapping, and the meaning (interpretation) of each codon is revealed.The final table is as follows (Fig. 2).It follows from the table that the code is degenerate. This means the existence of synonyms in the code, for example, GUU = GUC = Val, CGG = AGA = Arg , etc. Three codons UAA, UAG, UGA do not carry non-sense. These are termination codons; the appearance of any of them in a sequence of characters signifies the end of translation (transmission). An organism dies if, as a result of an error, the letter of the semantic codon is changed to a termination codon.Such changes are possible and are called mutations.
Thus, for the source data of example 1, from a set of arbitrary 64 words with a length of 3 characters, you can create a code containing 20 words and providing synchronization. This code is not without flaws. If an error is introduced into one of the words in a single character, the code will not be synchronized. In other words, the code is unstable against errors.The given numerical example can be used to illustrate and explain the genetic code of living organisms, which was created by nature on a long path of evolution and completely deciphered by modern science in 1966. It is established that the genetic code is not overlapping, and the meaning (interpretation) of each codon is revealed.The final table is as follows (Fig. 2).It follows from the table that the code is degenerate. This means the existence of synonyms in the code, for example, GUU = GUC = Val, CGG = AGA = Arg , etc. Three codons UAA, UAG, UGA do not carry non-sense. These are termination codons; the appearance of any of them in a sequence of characters signifies the end of translation (transmission). An organism dies if, as a result of an error, the letter of the semantic codon is changed to a termination codon.Such changes are possible and are called mutations.Definition . Mutations are relatively stable changes in the hereditary substance.
Each chromosome contains the genes x1, x2, ..., xn , which form a complex trait X of the body. A pair of chromosomes in a cell obtained by the fusion of paternal and maternal germ cells is formed during reproduction: one chromosome is obtained from the father, the other from the mother (diploid pair of chromosomes).In homologous chromosomes, all genes coincide in their function, but may differ by several nucleotides. Such differences are often the result of mutations, which can be caused by chemical, radiation, radioactive exposure, temperature, ionizing radiation.Hereditary diseases are caused by similar mutations, fixed in the chromosome set of germ cells of one of the parents. A known example of a human gene encoding hemoglobin. When replacing the letter T with the letter A , an alternative form of hemoglobin appears in one position of the gene. This manifests itself in a disease called sickle anemia.When the value of the trait coincides in both homologous chromosomes, the individual is called homozygous for this gene. In other cases, heterozygosity occurs. Homozygosity is characterized by diploid pairs of type a), and heterozygosity by pairs of type b) (Fig. 3) Figure 3 - diploid pairs of homozygotes and heterozygotesInstead of one diploid pair, four homologous chromosomes A, A, a, a, are formedand they are distributed equally between the four formed gametes. Each gamete also receives one of the chromosomes B, B, b, b, corresponding to a complex trait. This distribution occurs for chromosomes independently between four gametes and between different characters. These facts were established by Mendel and in 1865 he published.The most impressive feature of the genetic code is its versatility. The given scheme (Fig. 1) can be successfully used for decoding RNA of animals and plants. In 1979, results appeared on the mitochondrial genetic code, which differs from the values of some codons in the table and with other codon recognition rules.The translation is carried out by the ribosome - a special organ of the cell. Synchronization (setting the reading frame) is carried out using the prefix, AGGAGGU , which is called the Shine-Dolgarno sequence. This purine sequence is present in the word in the singular, and the probability of its distortion is small. But if distortion does happen, then the body will be in disaster.Figure 1 - Correspondence of code words to amino acids Figure 2– DNA, mRNA and protein helix
Figure 3 - diploid pairs of homozygotes and heterozygotesInstead of one diploid pair, four homologous chromosomes A, A, a, a, are formedand they are distributed equally between the four formed gametes. Each gamete also receives one of the chromosomes B, B, b, b, corresponding to a complex trait. This distribution occurs for chromosomes independently between four gametes and between different characters. These facts were established by Mendel and in 1865 he published.The most impressive feature of the genetic code is its versatility. The given scheme (Fig. 1) can be successfully used for decoding RNA of animals and plants. In 1979, results appeared on the mitochondrial genetic code, which differs from the values of some codons in the table and with other codon recognition rules.The translation is carried out by the ribosome - a special organ of the cell. Synchronization (setting the reading frame) is carried out using the prefix, AGGAGGU , which is called the Shine-Dolgarno sequence. This purine sequence is present in the word in the singular, and the probability of its distortion is small. But if distortion does happen, then the body will be in disaster.Figure 1 - Correspondence of code words to amino acids Figure 2– DNA, mRNA and protein helix Figure 2 shows how the amino acid sequence in a protein molecule is encoded by a codon sequence in a DNA molecule. Here, matrix mRNA is an intermediary molecule. Its chains diverge according to the principle of “zipper”, in which the role of the lock is played by an enzyme that breaks the molecule through hydrogen bonds.In cells, the genetic code is carried out by three matrix processes: replication (occurs in the nucleus), transcription and translation .Transcription (letter-wise recording of DNA → mRNA) is a biological process in eukaryotic cells that takes place in the cell nucleus (separated by a nuclear membrane from the cytoplasm) and is a synthesis of i-RNA molecules in the corresponding sections of DNA. The DNA nucleotide sequence is "rewritten" into the same RNA sequence.Translation (reading and translation of RNA → protein) the biological process in prokaryotic cells is combined with the transcription process, occurs in the cell cytoplasm, on the ribosomes; the sequence of mRNA nucleotides is transported from the nucleus, translated into the amino acid sequence (synthesis of the polypeptide chain on the mRNA matrix): this stage proceeds with the participation of transport RNA (tRNA) and the corresponding enzymes.Thus, translation is a protein synthesis by the ribosome based on information recorded in matrix mRNA. To obtain 20 amino acids, as well as a stop signal, signifying the end of a protein sequence, three consecutive nucleotides, called a triplet, are sufficient.Living organisms are distributed among plants and animals by species.
Figure 2 shows how the amino acid sequence in a protein molecule is encoded by a codon sequence in a DNA molecule. Here, matrix mRNA is an intermediary molecule. Its chains diverge according to the principle of “zipper”, in which the role of the lock is played by an enzyme that breaks the molecule through hydrogen bonds.In cells, the genetic code is carried out by three matrix processes: replication (occurs in the nucleus), transcription and translation .Transcription (letter-wise recording of DNA → mRNA) is a biological process in eukaryotic cells that takes place in the cell nucleus (separated by a nuclear membrane from the cytoplasm) and is a synthesis of i-RNA molecules in the corresponding sections of DNA. The DNA nucleotide sequence is "rewritten" into the same RNA sequence.Translation (reading and translation of RNA → protein) the biological process in prokaryotic cells is combined with the transcription process, occurs in the cell cytoplasm, on the ribosomes; the sequence of mRNA nucleotides is transported from the nucleus, translated into the amino acid sequence (synthesis of the polypeptide chain on the mRNA matrix): this stage proceeds with the participation of transport RNA (tRNA) and the corresponding enzymes.Thus, translation is a protein synthesis by the ribosome based on information recorded in matrix mRNA. To obtain 20 amino acids, as well as a stop signal, signifying the end of a protein sequence, three consecutive nucleotides, called a triplet, are sufficient.Living organisms are distributed among plants and animals by species.. – , . , , .
Cell division is of two types: one for the formation of somatic cells (body cells), the other for the formation of germ cells (gametes). The type of organism is determined by the presence, number and composition of chromosomes in the cells of organisms that are unchanged (constant). The normal growth and development of the body is ensured by the formation and growth of somatic cells as a result of mitosis. In mitosis, all chromosomes located in the cell nucleus double before the start of cell division (DNA replication) and are distributed equally between two daughter cells. The set of 2n2c chromosomes in each somatic cell is exactly the same. Mitosis maintains a constant diploid number of chromosomes in cells.Another process of meiosis is the formation of gametes, which are necessary for the continuation of the genus of organisms. In meiosis, each cell divides twice, and the number of chromosomes doubles once. Meiosis leads to the formation of diploid cells with haploid gametes with a set of n2c . With subsequent fertilization, gametes form a new generation organism with a diploid karyotype (nc + nc = 2n2c) .This mechanism is realized in all species that reproduce sexually. Meiosis ensures the constancy of chromosome sets (karyotypes) - heredity, and the creation of new combinations of paternal and maternal genes genotypic variability.The proposed work opens up the possibility of using the genetic code to solve the tasks of information protection. A correct understanding of the phenomenon of nature and its use is possible only with the expenditure of effort on the part of the researcher, who is not stopped by difficulties in the way of deep knowledge of nature surrounding us and its manifestations.
The normal growth and development of the body is ensured by the formation and growth of somatic cells as a result of mitosis. In mitosis, all chromosomes located in the cell nucleus double before the start of cell division (DNA replication) and are distributed equally between two daughter cells. The set of 2n2c chromosomes in each somatic cell is exactly the same. Mitosis maintains a constant diploid number of chromosomes in cells.Another process of meiosis is the formation of gametes, which are necessary for the continuation of the genus of organisms. In meiosis, each cell divides twice, and the number of chromosomes doubles once. Meiosis leads to the formation of diploid cells with haploid gametes with a set of n2c . With subsequent fertilization, gametes form a new generation organism with a diploid karyotype (nc + nc = 2n2c) .This mechanism is realized in all species that reproduce sexually. Meiosis ensures the constancy of chromosome sets (karyotypes) - heredity, and the creation of new combinations of paternal and maternal genes genotypic variability.The proposed work opens up the possibility of using the genetic code to solve the tasks of information protection. A correct understanding of the phenomenon of nature and its use is possible only with the expenditure of effort on the part of the researcher, who is not stopped by difficulties in the way of deep knowledge of nature surrounding us and its manifestations.