A typical condition for implementing CI / CD in Kubernetes: the application must be able to stop accepting new client requests before stopping, and most importantly, successfully complete existing ones. Compliance with this condition allows you to achieve zero downtime during the deployment. However, even when using very popular bundles (such as NGINX and PHP-FPM), you can encounter difficulties that will lead to a surge of errors with every deployment ...
Compliance with this condition allows you to achieve zero downtime during the deployment. However, even when using very popular bundles (such as NGINX and PHP-FPM), you can encounter difficulties that will lead to a surge of errors with every deployment ...Theory. How pod lives
We have already published this article in detail about the pod life cycle . In the context of this topic, we are interested in the following: at the moment when the pod enters the Terminating state , new requests cease to be sent to it (pod is removed from the list of endpoints for the service). Thus, to avoid downtime during the deployment, for our part, it is enough to solve the problem of the application stopping correctly.It should also be remembered that the grace period is 30 seconds by default : after this, the pod will be terminated and the application should manage to process all requests before this period. Note: although any request that runs for more than 5-10 seconds is already problematic, and graceful shutdown will not help him anymore ...To better understand what happens when pod finishes its work, it is enough to study the following scheme: A1, B1 - Getting changes about state of
A1, B1 - Getting changes about state of
A2: Sending SIGTERM
B2 - Removing pod from endpoints
B3 - Getting changes (endpoints list has changed)
B4 - Updating iptables rulesNote: removing endpoint pod and sending SIGTERM is not done sequentially, but in parallel. And due to the fact that Ingress does not receive an updated list of Endpoints right away, new requests from clients will be sent to pod, which will cause 500 errors during pod termination(we translated more detailed material on this issue ) . You need to solve this problem in the following ways:- Send in the headers of the Connection: close response (if it concerns an HTTP application).
- If there is no way to make changes to the code, then the article describes a solution that will allow you to process requests until the end of the graceful period.
Theory. How NGINX and PHP-FPM End Their Processes
Nginx
Let's start with NGINX, as everything is more or less obvious with it. Immersed in the theory, we learn that NGINX has one master process and several "workers" - these are child processes that process client requests. A convenient feature is provided: using the command to nginx -s <SIGNAL>terminate processes either in fast shutdown mode or in graceful shutdown. Obviously, we are interested in precisely the latter option.Then everything is simple: you need to add a command to the preStop hook that will send a graceful shutdown signal. This can be done in Deployment, in the container block: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Now, at the moment the pod completes its work in the NGINX container logs, we will see the following:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
And that will mean what we need: NGINX waits for the completion of queries, and then kills the process. However, a common problem will be discussed below, because of which, even if there is a command, the nginx -s quitprocess does not complete correctly.And at this stage we’ve finished with NGINX: at least you can understand from the logs that everything works as it should.What about PHP-FPM? How does it handle graceful shutdown? Let's get it right.PHP-FPM
In the case of PHP-FPM, a little less information. If you focus on the official manual on PHP-FPM, then it will tell you that the following POSIX signals are received:SIGINT, SIGTERM- fast shutdown;SIGQUIT - graceful shutdown (what we need).
The rest of the signals in this problem are not required, therefore, their analysis is omitted. To complete the process correctly, you will need to write the following preStop hook: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
At first glance, this is all that is required to perform a graceful shutdown in both containers. However, the task is more complicated than it seems. Next, we examined two cases in which the graceful shutdown did not work and caused a short-term inaccessibility of the project during the deployment.Practice. Possible problems with graceful shutdown
Nginx
First of all, it is useful to remember: in addition to executing the command, nginx -s quitthere is another step that you should pay attention to. We ran into a problem when NGINX instead of a SIGQUIT signal sent SIGTERM anyway, due to which the requests did not complete correctly. Similar cases can be found, for example, here . Unfortunately, we could not establish a specific reason for this behavior: there was a suspicion of the NGINX version, but it was not confirmed. The symptomatology was that in the logs of the NGINX container the messages “open socket # 10 left in connection 5” were observed , after which the pod stopped.We can observe such a problem, for example, by the answers to the Ingress we need: Status code indicators at the time of the deploymentIn this case, we get just the 503 error code from Ingress itself: it cannot access the NGINX container, since it is no longer available. If you look at the logs of the container with NGINX, they contain the following:
Status code indicators at the time of the deploymentIn this case, we get just the 503 error code from Ingress itself: it cannot access the NGINX container, since it is no longer available. If you look at the logs of the container with NGINX, they contain the following:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
After changing the stop signal, the container starts to stop correctly: this is confirmed by the fact that a 503 error is no longer observed.If you encounter a similar problem, it makes sense to figure out which stop signal is used in the container and how the preStop hook looks exactly. It is possible that the reason lies precisely in this.PHP-FPM ... and more
The problem with PHP-FPM is described trivially: it does not wait for the completion of child processes, terminates them, because of which there are 502 errors during the deployment and other operations. Since 2005 there have been several error messages on bugs.php.net (for example, here and here ) that describe this problem. But you probably will not see anything in the logs: PHP-FPM will announce the completion of its process without any errors or third-party notifications.It is worth clarifying that the problem itself may, to a lesser or greater extent, depend on the application itself and may not appear, for example, in monitoring. If you still encounter it, then a simple workaround comes to mind: add a preStop hook withsleep(30). It will allow you to complete all requests that were before (we don’t accept new ones, since the pod is already in the Terminating state ), and after 30 seconds the pod itself will end with a signal SIGTERM.It turns out that lifecyclefor the container it will look like this: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
However, due to the 30-second indication, sleepwe will significantly increase the deployment time, since each pod will be terminated for at least 30 seconds, which is bad. What can be done with this?Let us turn to the party responsible for the direct execution of the application. In our case, this is PHP-FPM , which by default does not monitor the execution of its child processes : the master process is terminated immediately. This behavior can be changed using a directive process_control_timeoutthat specifies time limits for waiting for signals from the master by child processes. If you set the value to 20 seconds, this will cover most of the requests running in the container, and after their completion the master process will be stopped.With this knowledge, we will return to our last problem. As already mentioned, Kubernetes is not a monolithic platform: it takes some time for the interaction between its various components. This is especially true when we consider the work of Ingresss and other related components, because due to such a delay at the time of deployment it is easy to get a surge of 500 errors. For example, an error may occur at the stage of sending a request to upstream, but the “time lag” of interaction between components is rather short - less than a second.Therefore, in conjunction with the already mentioned directive process_control_timeout, the following construction can be used for lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
In this case, we compensate for the delay by the team sleepand do not significantly increase the deployment time: is there a noticeable difference between 30 seconds and one? .. Essentially process_control_timeout, it takes on the “main job” , but is lifecycleused only as a “safety net” in case of lag.Generally speaking, the described behavior and the corresponding workaround concern not only PHP-FPM . A similar situation may arise in one way or another when using other languages / frameworks. If you cannot fix the graceful shutdown in other ways — for example, rewrite the code so that the application correctly processes termination signals — you can use the described method. It may not be the most beautiful, but it works.Practice. Load testing to verify pod performance
Load testing is one way of checking how the container works, since this procedure brings you closer to real combat conditions when users visit the site. You can use Yandex.Tank to test the above recommendations : it perfectly covers all our needs. The following are tips and tricks for testing with a clear - thanks to the graphs of Grafana and Yandex.Tank itself - an example from our experience.The most important thing here is to check for changes in stages.. After adding a new fix, run the test and see if the results have changed compared to the previous launch. Otherwise, it will be difficult to identify ineffective solutions, and in the future you can only do harm (for example, increase the deployment time).Another caveat - look at the logs of the container during its termination. Is graceful shutdown information recorded there? Are there any errors in the logs when accessing other resources (for example, a neighboring PHP-FPM container)? Errors of the application itself (as in the case of NGINX described above)? I hope that the introductory information from this article will help to better understand what happens to the container during its termination.So, the first test run took place without lifecycleand without additional directives for the application server (process_control_timeoutin PHP-FPM). The purpose of this test was to identify the approximate number of errors (and whether they exist at all). Also, from additional information, it should be known that the average deployment time of each hearth was about 5-10 seconds to the state of full readiness. The results are as follows: A splash of 502 errors is visible on the Yandex.Tank information panel, which occurred at the time of the deployment and lasted up to 5 seconds on average. Presumably this terminated the existing requests to the old pod when it was terminated. After that, 503 errors appeared, which was the result of a stopped NGINX container, which also disconnected due to the backend (because of which Ingress could not connect to it).Let's see how
A splash of 502 errors is visible on the Yandex.Tank information panel, which occurred at the time of the deployment and lasted up to 5 seconds on average. Presumably this terminated the existing requests to the old pod when it was terminated. After that, 503 errors appeared, which was the result of a stopped NGINX container, which also disconnected due to the backend (because of which Ingress could not connect to it).Let's see howprocess_control_timeoutin PHP-FPM will help us wait for the completion of child processes, i.e. fix such errors. Repeated deployment using this directive: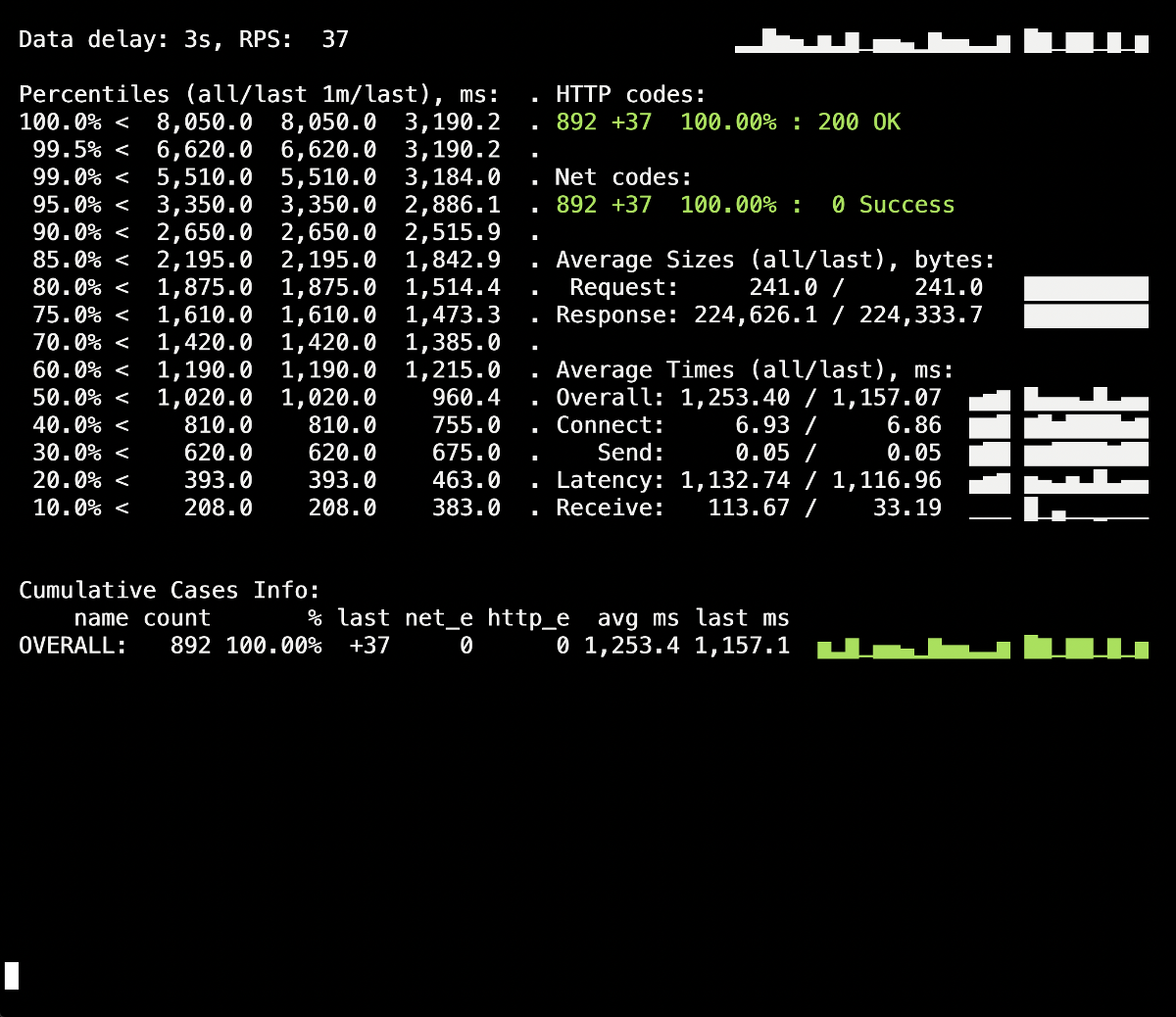 There are no more errors during the deployment of the 500s! The deployment is successful, the graceful shutdown works.However, it is worth remembering the moment with Ingress containers, a small percentage of errors in which we can get due to a time lag. To avoid them, it remains to add the construction with
There are no more errors during the deployment of the 500s! The deployment is successful, the graceful shutdown works.However, it is worth remembering the moment with Ingress containers, a small percentage of errors in which we can get due to a time lag. To avoid them, it remains to add the construction with sleepand repeat the deployment. However, in our particular case, no changes were visible (no errors again).Conclusion
For the correct completion of the process, we expect the following behavior from the application:- Wait a few seconds, then stop accepting new connections.
- Wait for all requests to complete and close all keepalive connections that do not execute requests.
- Complete your process.
However, not all applications can work this way. One solution to the problem in the realities of Kubernetes is:- Adding a pre-stop hook that will wait a few seconds
- studying the configuration file of our backend for the relevant parameters.
The NGINX example allows us to understand that even an application that initially must correctly process signals for completion may not do this, so it is critical to check for 500 errors during the deployment of the application. It also allows you to look at the problem more broadly and not concentrate on a separate pod or container, but look at the entire infrastructure as a whole.Yandex.Tank can be used as a testing tool in conjunction with any monitoring system (in our case, data from Grafana with a backend in the form of Prometheus were taken for the test). Problems with the graceful shutdown are clearly visible under heavy loads that the benchmark can generate, and monitoring helps to analyze the situation in more detail during or after the test.Responding to feedback on the article: it is worth mentioning that the problems and solutions are described here in relation to NGINX Ingress. For other cases, there are other solutions that, perhaps, we will consider in the following materials of the cycle.PS
Other from the K8s tips & tricks cycle: