What is a data structure?Simply put, a data structure is a container in which data is stored in a specific layout (format, or the way it is organized in memory). This “layout” allows the data structure to be effective in some operations and ineffective in others. Your goal is to understand the data structures so that you can choose the data structure that is most optimal for the problem in question.Why do we need data structures?Because data structures are used to store data in an organized manner, and since data is the most important element of computer science, the true value of data structures is obvious.No matter what problem you solve, you have to deal with the data in one way or another - whether it is an employee’s salary, stock prices, shopping list or even a simple telephone directory.Based on different scenarios, the data should be stored in a specific format. We have several data structures that cover the need to store data in different formats.Commonly Used Data StructuresLet's first list the most commonly used data structures, and then look at them one by one:- Arrays - Arrays
- Stacks - Stacks
- Queues - Queues
- Linked Lists - Related Lists
- Trees - Trees
- Graphs - graphs
- Tries (they are essentially trees, but it's still nice to name them separately). - priority
- Hash Tables - hash tables
Arrays - ArraysAn array is the simplest and most widely used data structure. Other data structures, such as stacks and queues, are derived from arrays.Here is an image of a simple array of size 4 containing elements (1, 2, 3, and 4).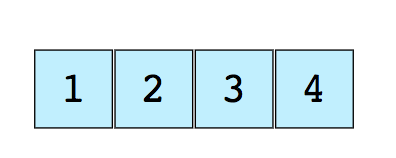 Each data item is assigned a positive numerical value called an index, which corresponds to the position of this item in the array. Most languages define the starting index of an array as 0.The following are two types of arrays:
Each data item is assigned a positive numerical value called an index, which corresponds to the position of this item in the array. Most languages define the starting index of an array as 0.The following are two types of arrays:- One-dimensional arrays (as shown above)
- Multidimensional arrays (arrays inside arrays) Multi-dimensional arrays
Basic operations on arrays.Insert - inserts anelement at a specified index.Delete (Delete) - removes an element at a specified index.Size - get the total number of elements in an array.For self-study:1 Find the second minimum element of the array.2. The first non-repeating integers in the array.3. Merge two sorted arrays.4. Reorder the positive and negative values in the array.StacksWe are all familiar with the famous option Undo (Cancel), which is present in almost every application. Ever wondered how this works? The essence of the mechanism is that you save the previous states of your work (which are limited by a certain number) in memory in such a way that the last action appears first. This cannot be done with just arrays. That's where the stack comes in handy!A real example of a stack is a stack of books arranged vertically. To get a book somewhere in the middle, you need to delete all the books placed on top of it. Here's how the LIFO (Last In First Out) method works .Here is an image of a stack containing three data elements (1, 2, and 3), where 3 is at the top and will be deleted first: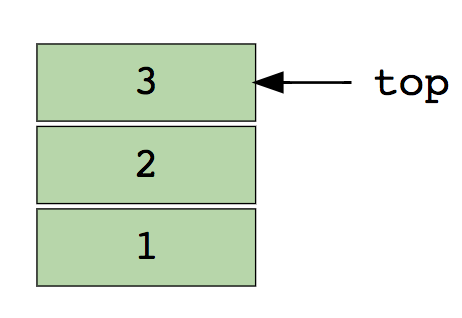 The basic operations with stacks:Push - inserts an element on top of others.Pull (Pop) - returns the top element after removal from the stack.Empty? (IsEmpty) - returns true (true) if the stack is empty.Top (Top) - returns the top element without deleting from the stack.For independent study:1. Evaluate the postfix expression using the stack.2. Sort values on the stack.3. Check the balanced brackets in the expression.QueuesLike a stack, a queue is another linear data structure in which items are stored sequentially. The only significant difference between the stack and the queue is that instead of using the LIFO method, Queue implements a methodFIFO, which is short for First in First Out .A great real-life example of a line: a number of people waiting at the ticket office. If a new person arrives, he joins the line from the end, not from the beginning - and the person standing in front will be the first to receive a ticket and, therefore, will leave the line.Here is an image of a queue containing four data elements (1, 2, 3, and 4), where 1 is at the top and will be deleted first:
The basic operations with stacks:Push - inserts an element on top of others.Pull (Pop) - returns the top element after removal from the stack.Empty? (IsEmpty) - returns true (true) if the stack is empty.Top (Top) - returns the top element without deleting from the stack.For independent study:1. Evaluate the postfix expression using the stack.2. Sort values on the stack.3. Check the balanced brackets in the expression.QueuesLike a stack, a queue is another linear data structure in which items are stored sequentially. The only significant difference between the stack and the queue is that instead of using the LIFO method, Queue implements a methodFIFO, which is short for First in First Out .A great real-life example of a line: a number of people waiting at the ticket office. If a new person arrives, he joins the line from the end, not from the beginning - and the person standing in front will be the first to receive a ticket and, therefore, will leave the line.Here is an image of a queue containing four data elements (1, 2, 3, and 4), where 1 is at the top and will be deleted first: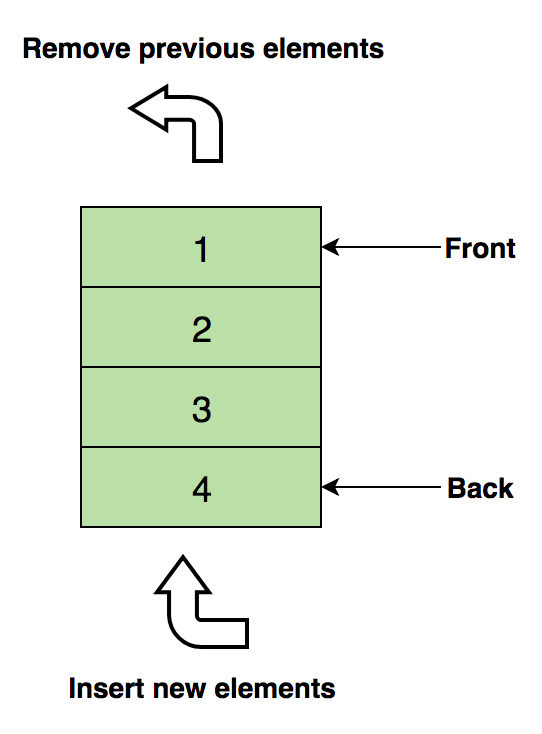 Basic operations with the queue:Enqueue - inserts an element at the end of the queue.Dequeue - Deletes an item from the beginning of the queue.Empty? (IsEmpty) - returns true (true) if the queue is empty.Top (Top) - returns the first element of the queue.For independent study:1. Implementation of the stack using the queue.2. The inverse first k elements of the queue.3. Generation of binary numbers from 1 to n using the queue.Linked ListA linked list is another important linear data structure that at first glance may look similar to arrays, but differs in memory allocation, internal structure, and how the basic insert and delete operations are performed.A linked list is like a chain of nodes, where each node contains information such as data, and a pointer to the next node in the chain. There is a header pointer that points to the first element of the linked list, and if the list is empty, then it simply points to zero or nothing.Linked lists are used to implement file systems, hash tables, and adjacency lists.Here is a visual representation of the internal structure of a linked list:
Basic operations with the queue:Enqueue - inserts an element at the end of the queue.Dequeue - Deletes an item from the beginning of the queue.Empty? (IsEmpty) - returns true (true) if the queue is empty.Top (Top) - returns the first element of the queue.For independent study:1. Implementation of the stack using the queue.2. The inverse first k elements of the queue.3. Generation of binary numbers from 1 to n using the queue.Linked ListA linked list is another important linear data structure that at first glance may look similar to arrays, but differs in memory allocation, internal structure, and how the basic insert and delete operations are performed.A linked list is like a chain of nodes, where each node contains information such as data, and a pointer to the next node in the chain. There is a header pointer that points to the first element of the linked list, and if the list is empty, then it simply points to zero or nothing.Linked lists are used to implement file systems, hash tables, and adjacency lists.Here is a visual representation of the internal structure of a linked list: The following are the types of linked lists:
The following are the types of linked lists:- Single Link List (Unidirectional)
- Doubly linked list (bidirectional)
Basic Operations on a Linked ListInsertAtEnd - Inserts an item at the end of a linked list.InsertB Start (InsertAtHead) - Inserts an item at the beginning of a linked list.Delete - removes this item from the linked list.DeleteBeginning (DeleteAtHead) - deletes the first element of the linked list.Search - returns the found item from the linked list.Empty? (IsEmpty) - returns true (true) if the linked list is empty.For independent study:1. Flip the linked list (Invert, reverse, display backwards).2. Define a loop in a linked list.3. Return the Nth node from the end in the linked list.4. Remove duplicates from the linked list.GraphsGraphs are a collection of nodes that are connected to each other in the form of a network. Nodes are also called vertices. The pair (x, y) is called an edge, which indicates that the vertex x is connected with the vertex y. An edge can contain weight / cost, showing how much cost it takes to move from top x to y.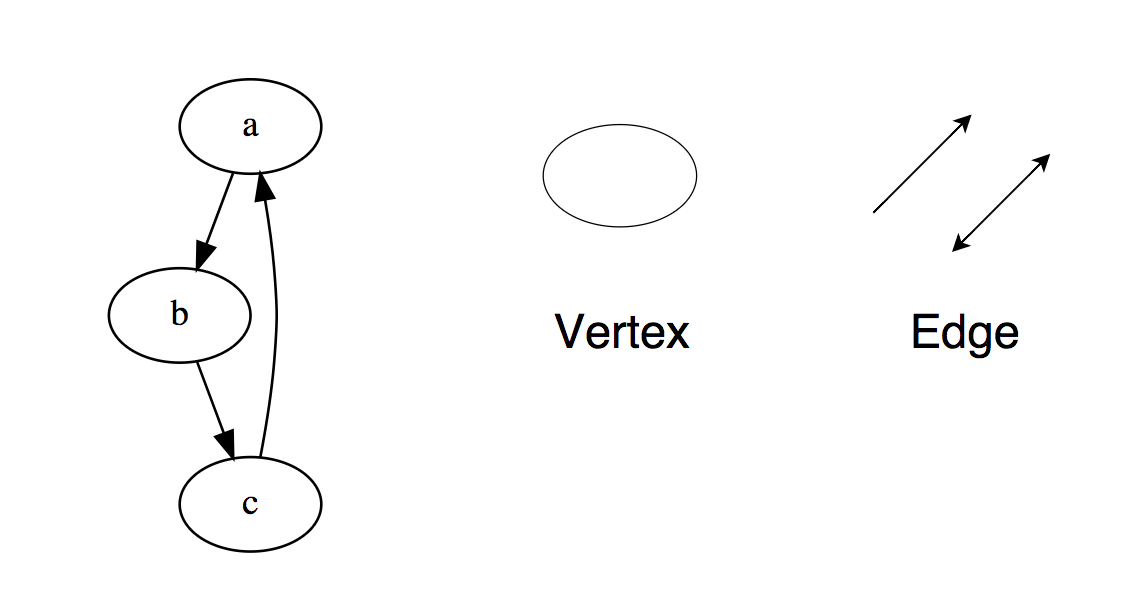 Types of graphs:
Types of graphs:- Undirected graph
- Directed graph
In programming languages, graphs are represented in two forms:The following is an example of a contiguous Adjacency List (undirected graph).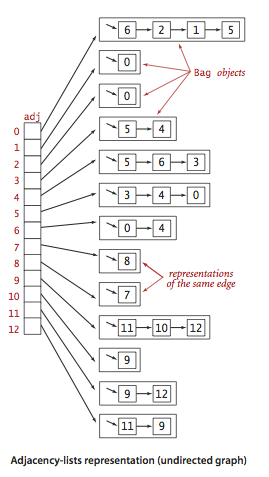 Known examples of moving algorithms along graphs:For independent study:1. Implementation of the Breadth and Depth First search2. Check if the graph is a tree or not.3. Counting the number of edges in the graph.4. Find the shortest path between the peaks.TreesA tree is a hierarchical data structure consisting of vertices (nodes) and edges that connect them. Trees look like graphs, but the key point that distinguishes a tree from a graph is that a loop cannot exist in a tree. A tree is a torn graph.Trees are widely used in artificial intelligence and complex algorithms to provide an efficient storage mechanism for problem solving algorithms.Here is an image of a simple tree and the basic terms used in the tree data structure:
Known examples of moving algorithms along graphs:For independent study:1. Implementation of the Breadth and Depth First search2. Check if the graph is a tree or not.3. Counting the number of edges in the graph.4. Find the shortest path between the peaks.TreesA tree is a hierarchical data structure consisting of vertices (nodes) and edges that connect them. Trees look like graphs, but the key point that distinguishes a tree from a graph is that a loop cannot exist in a tree. A tree is a torn graph.Trees are widely used in artificial intelligence and complex algorithms to provide an efficient storage mechanism for problem solving algorithms.Here is an image of a simple tree and the basic terms used in the tree data structure: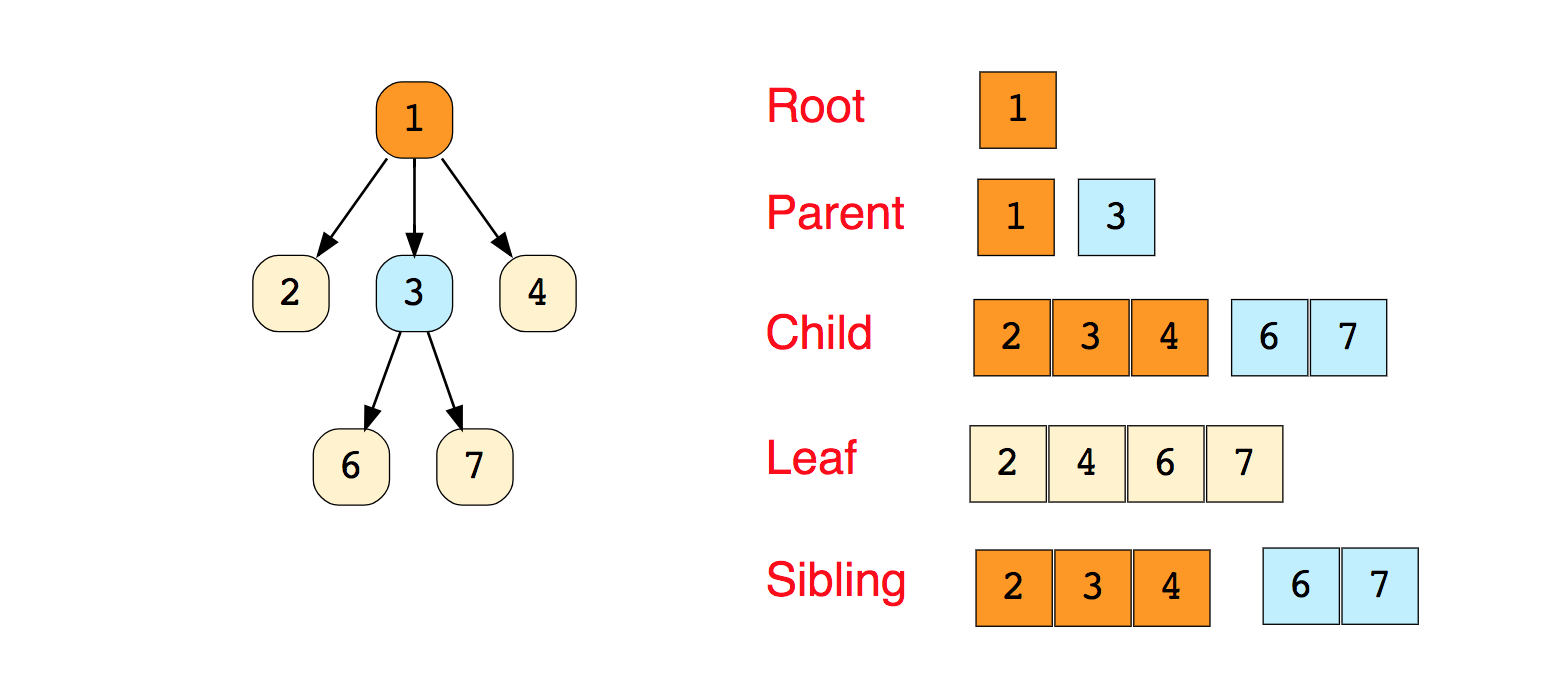 There are tree types:
There are tree types:- N-
- (Balanced Tree)
- (Binary Tree)
- (Binary Search Tree)
- AVL
- - (Red Black Tree)
- 2–3
From the above, the Binary Tree and the Binary Search Tree are the most commonly used trees.For independent study:1. Find the height of the binary tree.2. Find the kth maximum value in the binary search tree.3. Find the nodes at a distance of "k" from the root.4. Find the ancestors of the given node in the binary tree.Practical examples:1. Facebook: Each user is a vertex, and two people are friends when there is an edge between two vertices. Also recommendations to friends are calculated on the basis of graph theory.2. Google Maps: Different locations are represented by peaks and roads are represented by edges, graph theory is used to find the shortest path between two peaks.3. Transport networks: in them the peaks are the intersections of roads and ribs - these are the road segments between their intersections.4. Representation of molecular structures where the vertices are molecules and the edges are the bonds between the molecules.5. Discrete signaling processes in graphs. ( and there’s a good article here too, and this one at the same time )6. Empirical observations show that most genes are regulated by a small number of other genes, usually less than ten. Therefore, a genetic network can be considered as a sparse graph, that is, a graph in which a node is connected to several other nodes. If oriented (acyclic) graphs or undirected graphs are saturated with probabilities, the result is probabilistically oriented graphical models and probabilistic undirected graphical models, respectively.7. Theory of Mayer cluster expansion of the volatility functiongas (Z) in thermodynamics requires the calculation of two, three, four conditions and so on. There is a systematic way to do this combinatorially with charts, and it helps to find out the connectivity of such charts. Knowing graph theory can be useful when you want to summarize a subset of these diagrams.8. Map coloring: the famous four-color theorem states that you can always color map regions correctly so that no two adjacent regions are assigned the same color using no more than four different colors. In this model, regions with colors are nodes, and adjacencies are edges of the graph.9. The task with three cottages is a well-known mathematical puzzle. It can be formulated as follows: Three cottages on a plane (or sphere), each of which must be connected to gas, water and electricity companies. The problem is solved using a graph on the plane .10. Search for the center of the graph: For each vertex, find the length of the shortest path to the farthest vertex. The center of the graph is the vertex for which this value is minimal. This is important for architectural planning of settlements in which a hospital, fire department or police station should be located so that the farthest point is as close as possible.For C # lovers, like me, a link with examples of C # graphing code is here. For the most advanced library with the implementation of graphs in C ++ here . For fans of AI and Skynet, stomp here .Sequences (Trie)Sequences, also known as trees with prefixes (Prefix Trees), are a tree-like data structure that is effective enough to solve problems associated with strings. They provide a quick search and are mainly used for searching words in a dictionary, automatic sentences in a search engine, and even for IP routing.Here is an illustration of how the three words “top”, “thus”, and “their” are stored in Priority: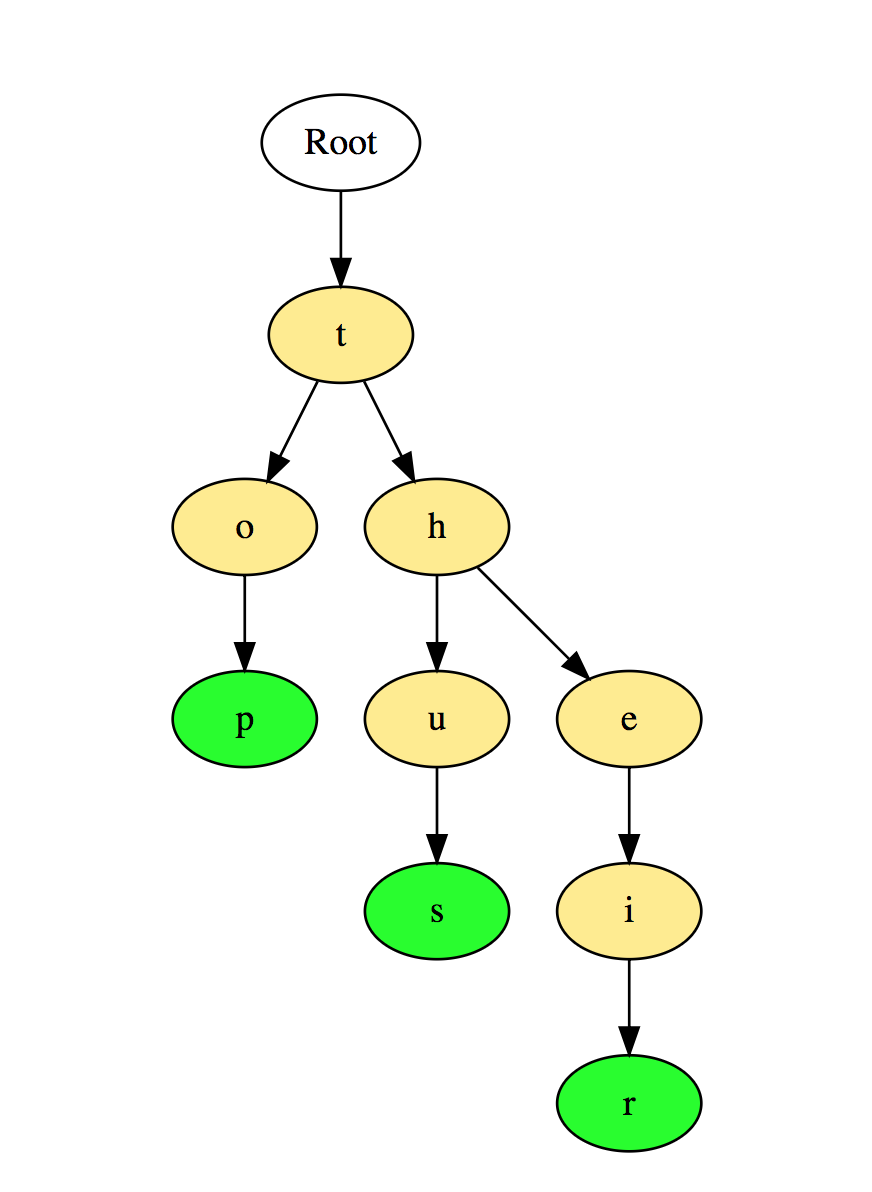 Words are stored from top to bottom, where the green nodes “p”, “s” and “r” point to the end of “top”, “ thus ”, and“ their ”, respectively.For independent study:1. Count the total number of words in the Priority.2. Print all words stored in the Priority.3. Sorting array elements using Priority.4. Generate words from the dictionary using Queues.5. Create the T9 dictionary.Practical examples of use:1. Selection from the dictionary or completion when typing a word.2. Search in contacts in the phone or phone dictionary.Hash TableHashing is a process used to uniquely identify objects and store each object by some pre-calculated unique index called its “key”. Thus, the object is stored in the form of a key-value pair, and a collection of such elements is called a dictionary. Each object can be found using this key.There are different hash-based data structures, but the hash table is the most commonly used data structure. A hash table is used when you need to access elements with a key, and you can determine the useful value of the key.Hash tables are typically implemented using arrays.The performance of hashing a data structure depends on these three factors:
Words are stored from top to bottom, where the green nodes “p”, “s” and “r” point to the end of “top”, “ thus ”, and“ their ”, respectively.For independent study:1. Count the total number of words in the Priority.2. Print all words stored in the Priority.3. Sorting array elements using Priority.4. Generate words from the dictionary using Queues.5. Create the T9 dictionary.Practical examples of use:1. Selection from the dictionary or completion when typing a word.2. Search in contacts in the phone or phone dictionary.Hash TableHashing is a process used to uniquely identify objects and store each object by some pre-calculated unique index called its “key”. Thus, the object is stored in the form of a key-value pair, and a collection of such elements is called a dictionary. Each object can be found using this key.There are different hash-based data structures, but the hash table is the most commonly used data structure. A hash table is used when you need to access elements with a key, and you can determine the useful value of the key.Hash tables are typically implemented using arrays.The performance of hashing a data structure depends on these three factors:- Hash function
- Hash Table Size
- Collision Processing Method
Here is an illustration of how a hash is displayed in an array. The index of this array is calculated using a hash function.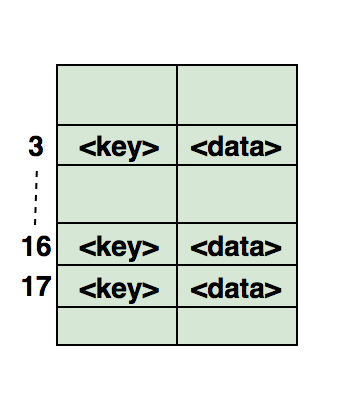 For independent study:1. Find symmetric pairs in the array.2. Follow the full travel path.3. Find if the array is a subset of another array.4. Check if the given arrays are disjoint.Below is a sample hash table usage code in .Net
For independent study:1. Find symmetric pairs in the array.2. Follow the full travel path.3. Find if the array is a subset of another array.4. Check if the given arrays are disjoint.Below is a sample hash table usage code in .Netstatic void Main(string[] args)
{
Hashtable ht = new Hashtable
{
{ "001", "Zara Ali" },
{ "002", "Abida Rehman" },
{ "003", "Joe Holzner" },
{ "004", "Mausam Benazir Nur" },
{ "005", "M. Amlan" },
{ "006", "M. Arif" },
{ "007", "Ritesh Saikia" }
};
if (ht.ContainsValue("Nuha Ali"))
{
Console.WriteLine(" !");
}
else
{
ht.Add("008", "Nuha Ali");
}
ICollection key = ht.Keys;
foreach (string k in key)
{
Console.WriteLine(k + ": " + ht[k]);
}
Console.ReadKey();
}
Practical examples:1. The game "Life". In it, a hash is a set of coordinates of every living cell.2. A primitive version of the Google search engine could map all existing words into a set of URLs where they occur. In this case, hash tables are used twice: the first time to map words to sets of URLs, and, the second time, to save each set of URLs.3. When implementing a multiway tree structure / algorithm, hash tables can be used for quick access to any child element of the internal node.4. When writing a program for playing chess, it is very important to keep track of the positions that were evaluated previously, so that you could come back when you need them again if necessary.5. Any programming language needs to map the variable name to its address in memory. In fact, in scripting languages like Javascript and Perl, fields can be added to the object dynamically, which means that the objects themselves are like hash maps.