In anticipation of the start of the Data Engineer course , we prepared a translation of a small but interesting material.
In this article, I will talk about how Parquet compresses large datasets into a small footprint file, and how we can achieve a bandwidth far exceeding the bandwidth of the I / O stream using concurrency (multithreading).Apache Parquet: Best at Low Entropy Data
As you can understand from the specification of the Apache Parquet format , it contains several levels of coding that can achieve a significant reduction in file size, among which are:- Encoding (compression) using a dictionary (similar to the pandas.Categorical way of presenting data, but the concepts themselves are different);
- Compression of data pages (Snappy, Gzip, LZO or Brotli);
- Encoding of the execution length (for null - pointers and indexes of the dictionary) and integer bit packing;
To show you how this works, let's look at a dataset:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Almost all Parquet implementations use the default dictionary for compression. Thus, the encoded data is as follows:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Indexes in the dictionary are additionally compressed by the repetition coding algorithm:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
Following the return path, you can easily restore the original array of strings.In my previous article, I created a dataset that compresses very well in this way. When working with pyarrow, we can enable and disable encoding using the dictionary (which is enabled by default) to see how this will affect the file size:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
A data set that takes up 1 GB (1024 MB) in pandas.DataFrame, with Snappy compression and compression using a dictionary, takes only 1.436 MB, that is, it can even be written to a diskette. Without compression using the dictionary, it will occupy 44.4 MB.Concurrent reading in parquet-cpp using PyArrow
In the implementation of Apache Parquet in C ++ - parquet-cpp , which we made available for Python in PyArrow, the ability to read columns in parallel was added.To try this feature, install PyArrow from conda-forge :conda install pyarrow -c conda-forge
Now when reading the Parquet file, you can use the argument nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
For data with low entropy, decompression and decoding are strongly tied to the processor. Since C ++ does all the work for us, there are no problems with GIL concurrency and we can achieve a significant increase in speed. See what I was able to achieve by reading a 1 GB dataset in a pandas DataFrame on a quad-core laptop (Xeon E3-1505M, NVMe SSD):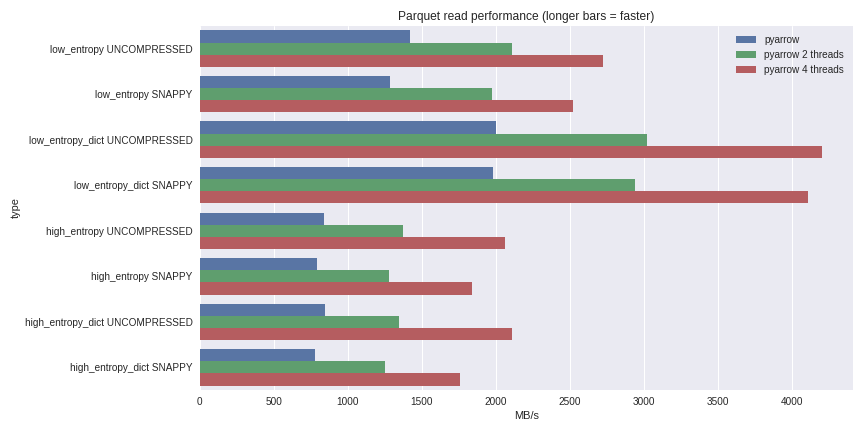 You can see the full benchmarking scenario here .I have included performance here for both compression cases using a dictionary and cases without using a dictionary. For data with low entropy, despite the fact that all files are small (~ 1.5 MB using dictionaries and ~ 45 MB without), compression using a dictionary significantly affects performance. With 4 threads, pandas read performance increases to 4 GB / s. This is much faster than the Feather format or any other I know.
You can see the full benchmarking scenario here .I have included performance here for both compression cases using a dictionary and cases without using a dictionary. For data with low entropy, despite the fact that all files are small (~ 1.5 MB using dictionaries and ~ 45 MB without), compression using a dictionary significantly affects performance. With 4 threads, pandas read performance increases to 4 GB / s. This is much faster than the Feather format or any other I know.Conclusion
With the release of version 1.0 parquet-cpp (Apache Parquet in C ++), you can see for yourself the increased I / O performance that is now available to Python users.Since all the basic mechanisms are implemented in C ++, in other languages (for example, R), you can create interfaces for Apache Arrow (columnar data structures) and parquet-cpp . Python binding is a lightweight shell of the core libarrow and libparquet C ++ libraries.That's all. If you want to learn more about our course, sign up for an open day , which will be held today!