When another fruitful year comes to an end, I want to look back, take stock and show what we were able to do during this time. The #DeepPavlov library, for a minute, is already two years old, and we are glad that our community is growing every day.Over the year of work on the library, we have achieved:- Library downloads increased by a third compared to last year. Now DeepPavlov has more than 100 thousand installations and more than 10 thousand container installations.
- The number of commercial solutions has increased due to state-of-art technologies implemented in DeepPavlov, in various industries from retail to industry.
- The first release of DeepPavlov Agent has been released .
- The number of active community members has increased 5 times.
- Our team of undergraduate and graduate students was selected to participate in the Alexa Prize Socialbot Grand Challenge 3 .
- The library has become a winner of the contest from the company Google «Powered by TensorFlow Challenge».
What helped to achieve such results and why is DeepPavlov the best open source for building conversational AI? We will tell in our article.
#DeepPavlov aims at the result
Recently, dialogue systems have become the standard for human-machine interaction. Chatbots are used in almost all industries, simplifying the interaction between people and computers. They integrate seamlessly into websites, messaging platforms, and devices. Many companies today prefer to delegate routine tasks to interactive systems that can handle multiple user requests at the same time, saving labor costs.However, often companies do not know where to start when developing a bot to meet the needs of their business. Historically, chatbots can be divided into two large groups: based on rules and based on data. The first type relies on predefined commands and templates. Each of these commands should be written by the chatbot developer using regular expressions and text data analysis. In contrast, data-driven chat bots rely on machine learning models that have been pre-trained on dialogue data.Open Source Library - DeepPavlovoffers a free and easy-to-use solution for building interactive systems. DeepPavlov comes with several pre-trained components to solve problems associated with natural language processing (NLP). DeepPavlov solves problems such as: classification of text, correction of typos, recognition of named entities, answers to questions on the knowledge base and many others. And you can install DeepPavlov in one line by running:pip install -q deeppavlov
* The framework allows you to train and test models, as well as customize their hyperparameters. The library supports Linux and Windows platforms. You can try this and other models in the demo version of the library .Currently, modern results in many tasks have been achieved through the use of models based on BERT. The DeepPavlov team integrated BERT into the following three tasks: text classification, recognition of named entities, and answers to questions. As a result, we have made significant improvements in all these tasks.1. BERT DeepPavlov Models
BERT for text classification A text classification
model based on BERT DeepPavlov serves, for example, to solve the problem of detecting insults. The model includes predicting whether a comment published in a public discussion is considered offensive to one of the participants. For this case, the classification is carried out only in two classes: insult and not insult.Any pre-trained model can be used for output both through the command line interface (CLI) and through Python. Before using the model, make sure that all necessary packages are installed using the command:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT for Named Entity Recognition
In addition to text classification models, DeepPavlov includes a BERT-based model for named entity recognition (NER). This is one of the most common tasks in NLP and the most used model of our library. At the same time, NER has many business applications. For example, a model can extract important information from a resume to facilitate the work of human resources specialists. In addition, NER can be used to identify relevant entities in customer requests, such as product specifications, company names, or company branch information.The DeepPavlov team trained the NER model in the OntoNotes English-language building, which has 19 types of markup, including PER (person), LOC (location), ORG (organization) and many others. To interact with, you must install it with the command:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT for answering questions A
contextual answer to a question is the task of finding an answer to a question in a given context (for example, a Wikipedia paragraph), where the answer to each question is a context segment. For example, the triple of context, question and answer below forms the correct triplet for the task of answering the question. Presentation of the work of the question-answer system in a demo.A system of answers to questions can automate many processes in a business. For example, this can help employers get answers based on internal company documentation. In addition, the model will help test students' ability to understand the text in the learning process. Recently, however, the task of answering questions based on context has attracted great attention of scientists. One of the key turning points in this area was the release of the Stanford Question Answer Set (SQuAD). The SQuAD dataset has led to countless approaches to solving the question-answer system problem. One of the most successful is the DeepPavlov BERT model. It surpasses all others and is currently producing results bordering on human characteristics.To use the BERT-based QA model with DeepPavlov, you must:
Presentation of the work of the question-answer system in a demo.A system of answers to questions can automate many processes in a business. For example, this can help employers get answers based on internal company documentation. In addition, the model will help test students' ability to understand the text in the learning process. Recently, however, the task of answering questions based on context has attracted great attention of scientists. One of the key turning points in this area was the release of the Stanford Question Answer Set (SQuAD). The SQuAD dataset has led to countless approaches to solving the question-answer system problem. One of the most successful is the DeepPavlov BERT model. It surpasses all others and is currently producing results bordering on human characteristics.To use the BERT-based QA model with DeepPavlov, you must:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
More models can be found in the documentation . And if you need tutorials on using library components, then look for them in our official blog .2. DeepPavlov Agent - a platform for creating multi-tasking chat bots
Today, there are several approaches to the development of interactive agents. When developing conversation agents, the modular architecture is mainly used for a focused dialogue in which the script unfolds. However, often the user needs to combine a focused dialogue, for example, with another functionality - answering questions or searching for information, as well as maintaining a conversation. Thus, the ideal dialogue agent is a personal assistant that combines different types of agents, switches between its functionalities and characters, depending on which task it is used in. At the same time, the agent must accumulate information about its essence, adjust its algorithms to a specific user. On the other hand, it should be able to integrate with external services. For instance,make queries to external databases, get information from there, process it, highlight the important and transmit it to the user. To solve this problem, in October 2019, the first release of DeepPavlov Agent 1.0, a platform for creating multi-tasking chat bots, was released. The agent helps developers of production chatbots organize several NLP models in one pipeline.Read more about the platform and features in the documentation .3. Implementation of DeepPavlov NLP SaaS
To simplify the work with pre-trained NLP models from DeepPavlov, in September 2019, a SaaS service was launched. DeepPavlov Cloud allows you to analyze text, as well as store documents in the cloud. To use the models, you need to register in our service and get a token in the Tokens section of your personal account. At the moment, the service supports several pre-trained NLP models in Russian and is in the process of testing the system.4. Participation in DSCT8 or targeted dialogue system
The use of virtual assistants such as Amazon Alexa and Google Assistant has opened up opportunities for developing applications that allow us to simplify the implementation of many everyday tasks, such as ordering a taxi, booking a table in a restaurant, and many others. To solve such problems, focused dialogue systems are used.Dialogue State Traking (DST) is a key component in such dialogue systems. DST is responsible for translating utterances in human language into a semantic representation of the language, in particular, for extracting intents and slot-value pairs corresponding to the user's goal.During team participation in DSTC8The GOLOMB model (GOaL-Oriented Multi-task BERT-based dialogue state tracker) was developed - a goal-oriented multi-task model based on BERT to track the state of the dialogue. To predict the state of dialogue, the model solves several classification problems and the task of finding a substring. Soon this model will appear in the DeepPavlov library. In the meantime, you can read the full article here . Presentation of the poster at the AAAI-20 conference in New York (USA).
Presentation of the poster at the AAAI-20 conference in New York (USA).
5. Participation in the Alexa Prize Socialbot Grand Challenge
The team of DeepPavlov, consisting of students and graduate students of the Moscow Institute of Physics and Technology, was selected to participate in the Alexa Prize Socialbot Grand Challenge 3 - an international competition dedicated to the development of conversational AI technology. The aim of the competition is to create a bot that can freely communicate with people on relevant topics. Of the 375 applications, the Alexa Prize committee selected 10 finalists, including our team - DREAM. At the moment, the team has moved to the quarter finals of the competition and is fighting to reach the semifinals. You can follow the news and cheer for ours on the official page , and do not forget to subscribe to Twitter . Team composition Dream Team.
Team composition Dream Team.
6. Participation in the Powered by TF Challenge
As stated earlier, DeepPavlov comes with several pre-trained components powered by TensorFlow and Keras. And this year, the DeepPavlov team won the Google Powered by TF Challenge contest for the best machine learning project that uses the TensorFlow library. Of the more than 600 contest participants, Google chose the five best projects, one of which was the DeepPavlov library. The project was presented on the official TensorFlow blog . It is worth noting that the flexibility of TensorFlow allows us to create any neural network architecture we can think of. And in particular, we use TensorFlow for seamless integration with BERT-based models.
7. Community development
The global goal of our project is to enable developers and researchers in the field of conversational artificial intelligence to use the most advanced tools for creating next-generation interactive systems, as well as to become an internationally significant platform in the field of AI for the exchange of experience and teaching state-of-art technologies.To achieve this, DeepPavlov employeesconduct free semester training courses for students and staff involved in Computer Science. One of them is the course: “Deep learning in natural language processing” ”, which includes seminars and workshops. Classes include topics such as: building dialogue systems, methods for evaluating a dialogue system with the ability to generate a response, various frameworks for dialog systems, methods for estimating the amount of remuneration due to optimization of dialogue policies, types of user requests, consideration of modeling call-center calls. In 2020, we launched a new recruitment and already 900 students and employees undergo training free of charge. You can follow the news and the set for this and other courses on our website . And if you missed the courses, but want to learn more - then on ouryoutube channel you can always find them in the record.Today, DeepPavlov library provides AI-ready components for working with text, which are used in 92 countries of the world. As of February 2020, the number of downloads of the library reached 100,000 thousand, and the dynamics of installations are gaining momentum. Also, more than 30 companies in Russia have already implemented and are successfully using solutions based on DeepPavlov. This shows that such solutions are very popular all over the world.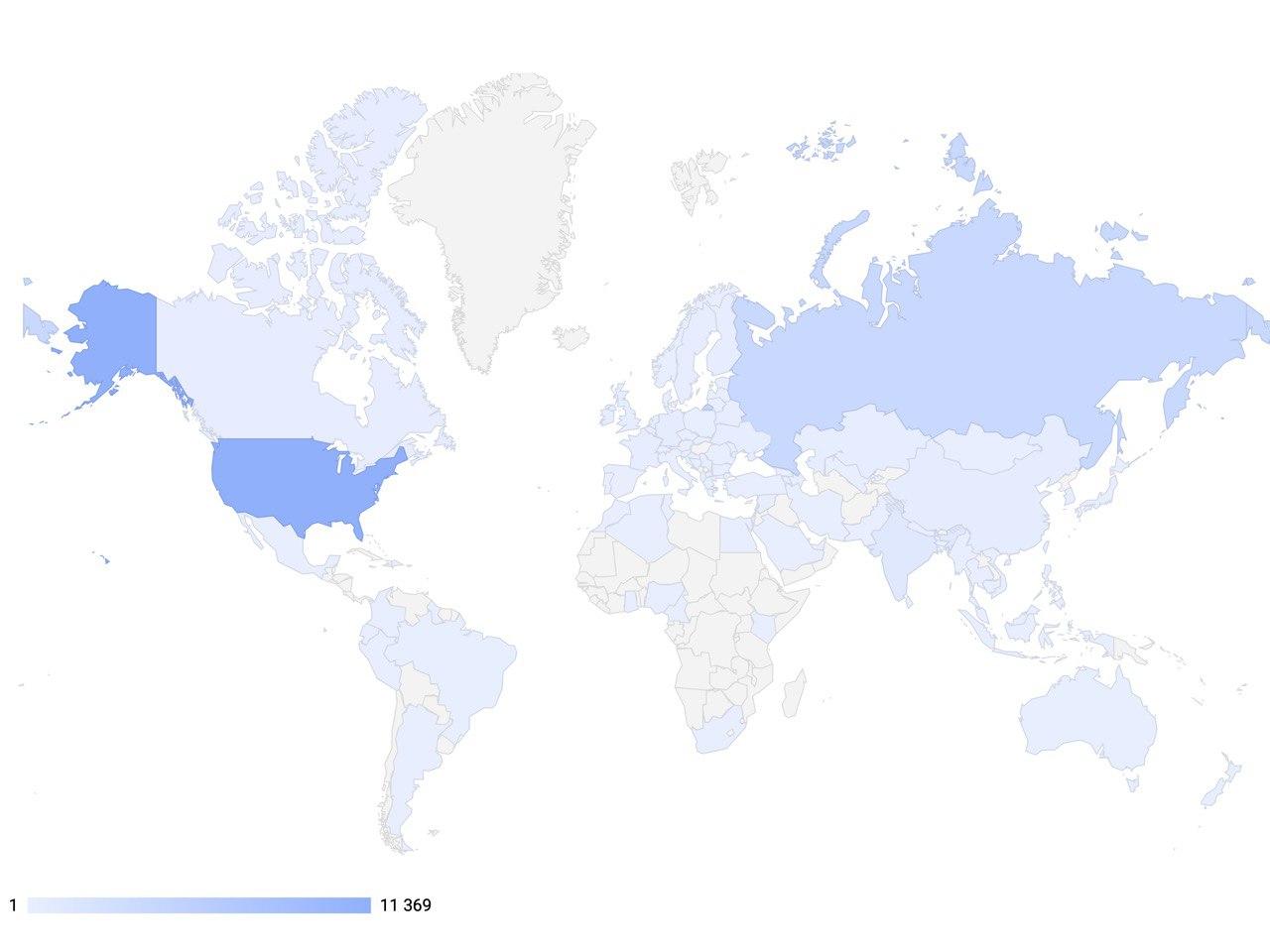
What's next?
We are pleased to share our successes with you, so we have prepared an event for our community. We want to share experience and knowledge from real production projects on how to create the best AI assistants. Join the meeting of users and developers of the DeepPavlov open library on February 28 to talk about artificial intelligence and its application, as well as meet other members of the community. The event will be held as part of the AI week from February 25 to 28. We are waiting for everyone who uses DeepPavlov or wants to get to know our technology.All information on speakers and the program can be found on the site, registration is required for attending the event.Join: DeepPavlov 2 years
The AI industry will continue to evolve, and we believe that DeepPavlov will become an advanced technology that every developer will use to understand natural language. Next year, we will work to double our community, increase open source tools, and improve machine learning research. And do not forget that DeepPavlov has a forum - ask your questions regarding the library and models. Thank you for the attention!