Recently, the task of character recognition in application programs is not particularly difficult - you can use many ready-made OCR-libraries, many of which are almost perfected. But nevertheless, sometimes a task may arise to develop your own recognition algorithm without using third-party “sophisticated” OCR libraries.
This is exactly the task that arose during my work, and there are several reasons why it is better not to use ready-made libraries: the closed project, with its further certification, a certain restriction on the number of lines of code and the size of connected libraries, all the more so because you have to recognize enough in the subject area specific character set.
The recognition algorithm is simple, and, of course, does not pretend to be the most accurate, fast and effective, but copes with its small task well.
Suppose we have input in the form of scanned images of documents in a structured form. These documents have a special one-character code located in the upper left corner. Our task is to recognize this symbol and then perform some actions, for example, classify the source document according to the given rules.

The algorithm diagram is as follows:
 Since we know in advance where our symbol is located, cutting a certain area is not difficult. In order to remove all the “irregularities” of the edges of the symbol, we translate the image into monochrome (black and white).
Since we know in advance where our symbol is located, cutting a certain area is not difficult. In order to remove all the “irregularities” of the edges of the symbol, we translate the image into monochrome (black and white).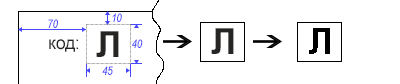
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
Next, you need to convert the resulting fragment “pixel by pixel” into a binary string, that is, a string where, for example, '*' corresponds to a black pixel, and a space to white.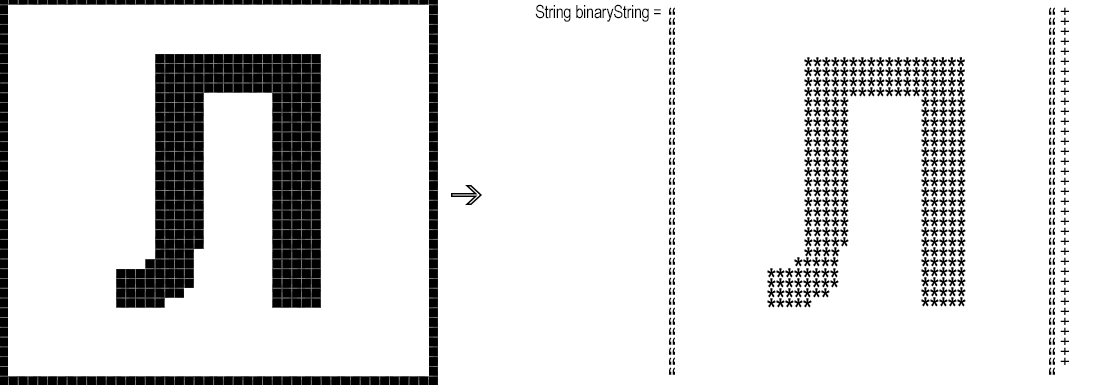
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
Next, you need to find the minimum Levenshtein distance between the received string and pre-prepared reference strings (in fact, you can take any string comparison method).int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
The function of finding the Levenshtein distance is implemented as a method according to the standard algorithm:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
The resulting findSymbol will be our recognized character.This algorithm can be optimized to improve performance and supplemented with various checks to improve recognition efficiency. Many indicators depend on the specific subject area of the problem being solved (number of characters, variety of fonts, image quality, etc.).In a practical way, it was found that the method qualitatively copes even with problematic issues such as “similarity” of characters, for example, “L” <-> "P", "5" <-> "S", "O" <-> "0". Since, for example, the distance between the binary strings “L” and “P” will always be greater than between the recognized “L” and the reference string “L”, even with some “irregularities”.In general, if you need to solve a similar problem (for example, recognition of playing cards), with a number of restrictions on the use of neurons and other ready-made solutions, you can safely take and modify this method.