In this article, I will tell you how to set up a machine learning environment in 30 minutes, create a neural network for image recognition, and then run the same network on a graphics processing unit (GPU).First, let's define what a neural network is.In our case, this is a mathematical model, as well as its software or hardware implementation, built on the principle of organization and functioning of biological neural networks - networks of nerve cells of a living organism. This concept arose in the study of processes occurring in the brain, and in an attempt to simulate these processes.Neural networks are not programmed in the usual sense of the word, they are trained. Learning ability is one of the main advantages of neural networks over traditional algorithms. Technically, training consists in finding the coefficients of connections between neurons. In the learning process, the neural network is able to identify complex relationships between input and output, as well as perform generalization.From the point of view of machine learning, a neural network is a special case of pattern recognition methods, discriminant analysis, clustering methods and other methods.Equipment
First, let's deal with the equipment. We need a server with the Linux operating system installed on it. Equipment for the operation of machine learning systems requires a sufficiently powerful and, as a consequence, expensive. For those who do not have a good car at hand, I recommend paying attention to the offer of cloud providers. The necessary server can be rented quickly and pay only for the time of use.In projects where it is necessary to create neural networks, I use the servers of one of the Russian cloud providers. The company offers rental cloud servers specifically for machine learning with powerful Tesla V100 graphics processing units (GPUs) from NVIDIA. In short: using a server with a GPU can be dozens of times more efficient (fast) compared to a server similar in cost where a CPU is used for calculations (a well-known central processor). This is achieved due to the specifics of the GPU architecture, which handles calculations faster.To perform the examples described below, we purchased the following server for several days:- 150 GB SSD
- RAM 32 GB
- Tesla V100 16 Gb processor with 4 cores
Ubuntu 18.04 was installed on the machine.Set the environment
Now install on the server everything you need to work. Since our article is primarily for beginners, I will talk in it about some points that will be useful to them.A lot of work when setting up the environment is done through the command line. Most of the users use Windows as a working OS. The standard console in this OS leaves much to be desired. Therefore, we will use the convenient Cmder / tool . Download the mini version and run Cmder.exe. Next, you need to connect to the server via SSH:ssh root@server-ip-or-hostname
Instead of server-ip-or-hostname, specify the IP address or DNS name of your server. Next, enter the password and upon successful connection, we should get something like this.Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
The main language for developing ML models is Python. And the most popular platform for using it on Linux is Anaconda .Install it on our server.We start by updating the local package manager:sudo apt-get update
Install curl (command line utility):sudo apt-get install curl
Download the latest version of Anaconda Distribution:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
We start the installation:bash Anaconda3-2019.10-Linux-x86_64.sh
During the installation process, you will need to confirm the license agreement. On successful installation, you should see this:Thank you for installing Anaconda3!
To develop ML models, many frameworks are now created, we work with the most popular: PyTorch and Tensorflow .Using the framework allows you to increase the speed of development and use ready-made tools for standard tasks.In this example, we will work with PyTorch. Install it:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
Now we need to launch the Jupyter Notebook - a popular development tool among ML specialists. It allows you to write code and immediately see the results of its execution. Jupyter Notebook is part of Anaconda and is already installed on our server. You need to connect to it from our desktop system.To do this, we first run Jupyter on the server by specifying port 8080:jupyter notebook --no-browser --port=8080 --allow-root
Next, opening another tab in our Cmder console (the top menu is the New console dialog), connect on port 8080 to the server via SSH:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
When you enter the first command, we will be offered links to open Jupyter in our browser:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Use the link for localhost: 8080. Copy the full path and paste into the address bar of the local browser of your PC. The Jupyter Notebook opens.Let's create a new laptop: New - Notebook - Python 3.Check the correct operation of all the components that we installed. We introduce a PyTorch code example into Jupyter and start the execution (Run button):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
The result should be something like this: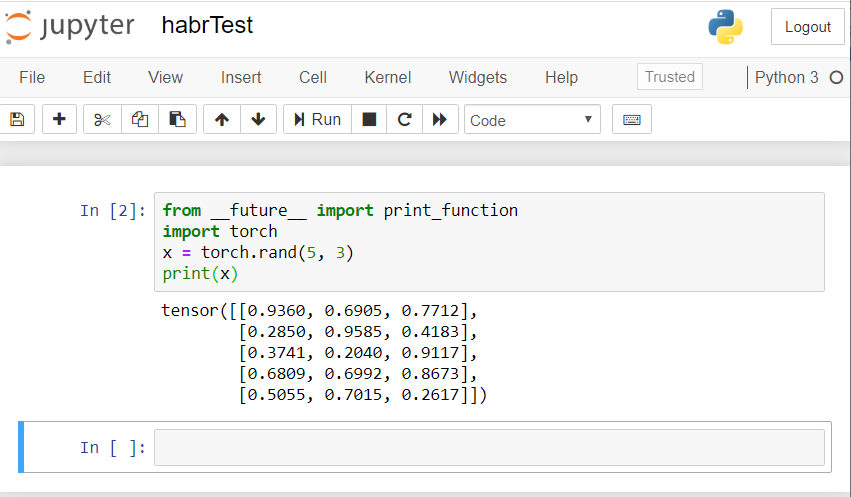 If you have a similar result, then we all set up correctly and can begin to develop a neural network!
If you have a similar result, then we all set up correctly and can begin to develop a neural network!Create a neural network
We will create a neural network for image recognition. We take this guide as a basis .To train the network, we will use the publicly available CIFAR10 dataset. He has classes: “airplane”, “car”, “bird”, “cat”, “deer”, “dog”, “frog”, “horse”, “ship”, “truck”. Images in CIFAR10 have a size of 3x32x32, i.e. 3-channel color images of 32x32 pixels.For work, we will use the created PyTorch package for working with images - torchvision.We will take the following steps in order:- Download and normalize training and test data sets
- Neural network definition
- Network training on training data
- Testing the network with test data
- Repeat GPU training and testing
All the code below we will execute in the Jupyter Notebook.Download and normalize CIFAR10
Copy and execute the following code in Jupyter:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
The answer should be like this:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
We will derive several training images for checking:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Neural network definition
Let us first examine how a neural network for image recognition works. This is a simple direct connection network. It takes input, passes it through several layers one by one, and then finally gives the output.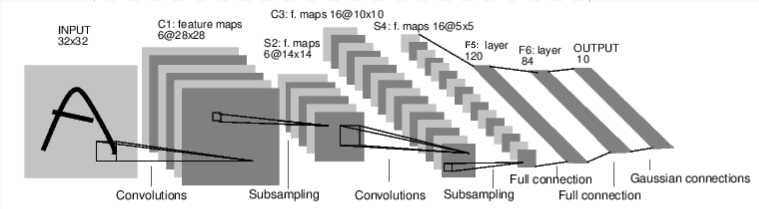 Let's create a similar network in our environment:
Let's create a similar network in our environment:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
We also define the loss function and the optimizer
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Network training on training data
We begin training our neural network. I draw your attention to the fact that after this, as you run this code, you will need to wait a while until the work is completed. It took me 5 minutes. Networking takes time. for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
We get the following result: We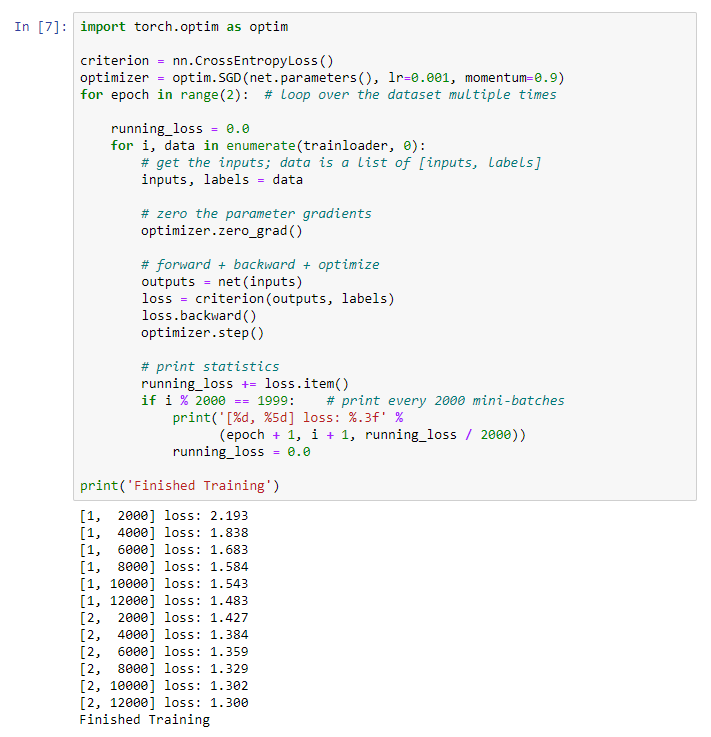 save our trained model:
save our trained model:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
Testing the network with test data
We trained the network using a set of training data. But we need to check if the network has learned anything at all.We will verify this by predicting the class label that the neural network outputs, and checking for truth. If the forecast is correct, we add the sample to the list of correct forecasts.Let's show the image from the test suite:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 Now ask the neural network to tell us what is in these pictures:
Now ask the neural network to tell us what is in these pictures:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
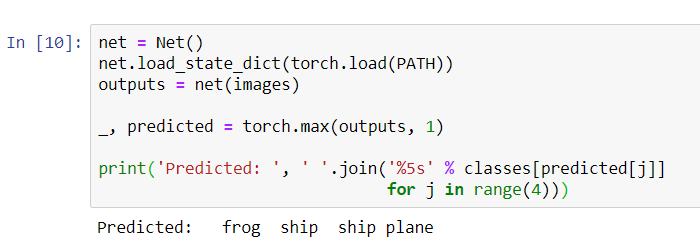 The results seem pretty good: the network correctly identified three of the four pictures.Let's see how the network works in the entire data set.
The results seem pretty good: the network correctly identified three of the four pictures.Let's see how the network works in the entire data set.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
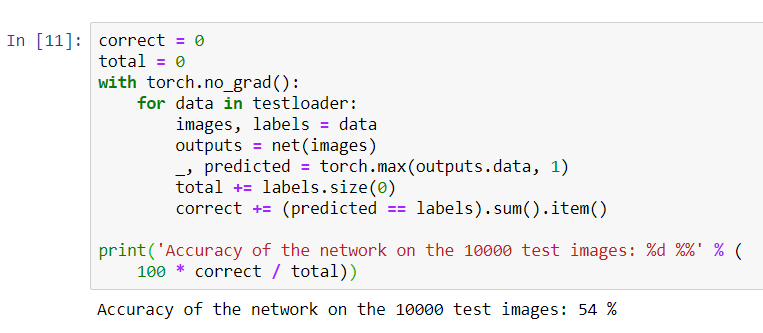 It looks like the network knows and works. If he defined classes at random, then the accuracy would be 10%.Now let's see what classes the network defines better:
It looks like the network knows and works. If he defined classes at random, then the accuracy would be 10%.Now let's see what classes the network defines better:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
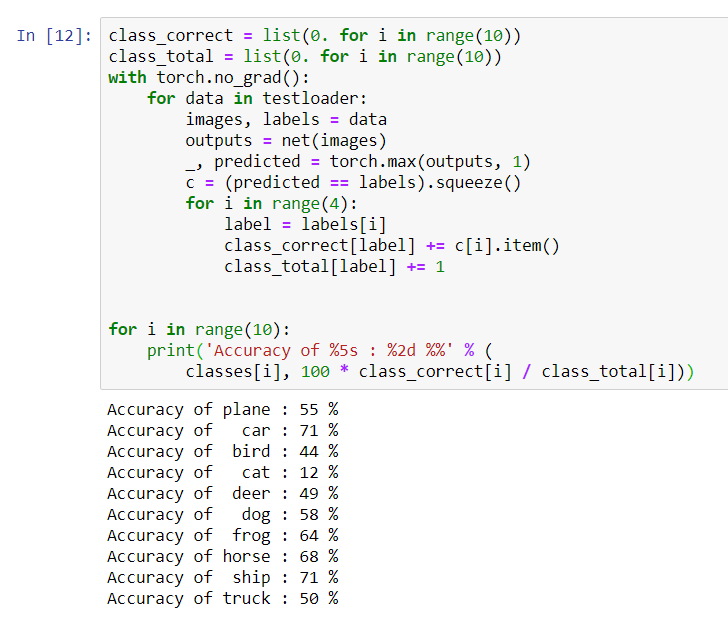 It seems that the network determines cars and ships best: 71% accuracy.So the network is working. Now let's try to transfer its work to the graphic processor (GPU) and see what changes.
It seems that the network determines cars and ships best: 71% accuracy.So the network is working. Now let's try to transfer its work to the graphic processor (GPU) and see what changes.GPU neural network training
First, I’ll briefly explain what CUDA is. CUDA (Compute Unified Device Architecture) is a parallel computing platform developed by NVIDIA for general computing on GPUs. With CUDA, developers can significantly accelerate computing applications using the capabilities of GPUs. On our server that we purchased, this platform is already installed.Let's first define our GPU as the first visible cuda device.device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 Send the network to the GPU:
Send the network to the GPU:net.to(device)
We will also have to send inputs and goals at every step and to the GPU:inputs, labels = data[0].to(device), data[1].to(device)
Run the network retraining already on the GPU:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
This time, network training lasted about 3 minutes. Recall that the same stage on a regular processor lasted 5 minutes. The difference is not significant, this is because our network is not so big. When using large arrays for training, the difference between the speed of the GPU and the traditional processor will increase.That seems to be all. What we managed to do:- We examined what the GPU is and chose the server on which it is installed;
- We set up a software environment for creating a neural network;
- We created a neural network for image recognition and trained it;
- We repeated the training of the network using the GPU and received an increase in speed.
I will be glad to answer questions in the comments.