Kafka Streams is a Java library for analyzing and processing data stored in Apache Kafka. As with any other streaming processing platform, it is capable of performing data processing with and / or without state preservation in real time. In this post I will try to describe why achieving high availability (99.99%) is problematic in Kafka Streams and what we can do to achieve it.What do we need to know
Before describing the problem and possible solutions, let's look at the basic concepts of Kafka Streams. If you have worked with Kafka APIs for Consumers / Producers, then most of these paradigms are familiar to you. In the following sections, I will try to describe in a few words the storage of data in partitions, the rebalancing of consumer groups and how the basic concepts of Kafka clients fit into the Kafka Streams library.Kafka: Partitioning Data
In the Kafka world, producer applications send data as key-value pairs to a specific topic. The topic itself is divided into one or more partitions in Kafka brokers. Kafka uses a message key to indicate in which partition the data should be written. Consequently, messages with the same key always end up in the same partition.Consumer applications are organized into consumer groups, and each group can have one or more instances of consumers.Each instance of a consumer in the consumer group is responsible for processing data from a unique set of partitions of the input topic.
Consumer instances are essentially a means of scaling up processing in your group of consumers.Kafka: Rebalancing Consumer Group
As we said earlier, each instance of the consumer group receives a set of unique partitions from which it consumes data. Whenever a new consumer joins a group, rebalancing must take place so that he gets a partition. The same thing happens when the consumer dies, the rest of the consumer should take his partitions to ensure that all partitions are processed.Kafka Streams: Streams
At the beginning of this post we got acquainted with the fact that the Kafka Streams library is built on the basis of APIs of producers and consumers and the data processing is organized in the same way as the standard solution on Kafka. In the Kafka Streams configuration, the application.id field is equivalent to group.idin the consumer API. Kafka Streams pre-creates a certain number of threads and each of them performs data processing from one or more partitions of input topics. Speaking in the terminology of the Consumer API, streams essentially coincide with instances of Consumer from the same group. Threads are the main way to scale data processing in Kafka Streams, this can be done vertically by increasing the number of threads for each Kafka Streams application on one machine, or horizontally by adding an additional machine with the same application.id.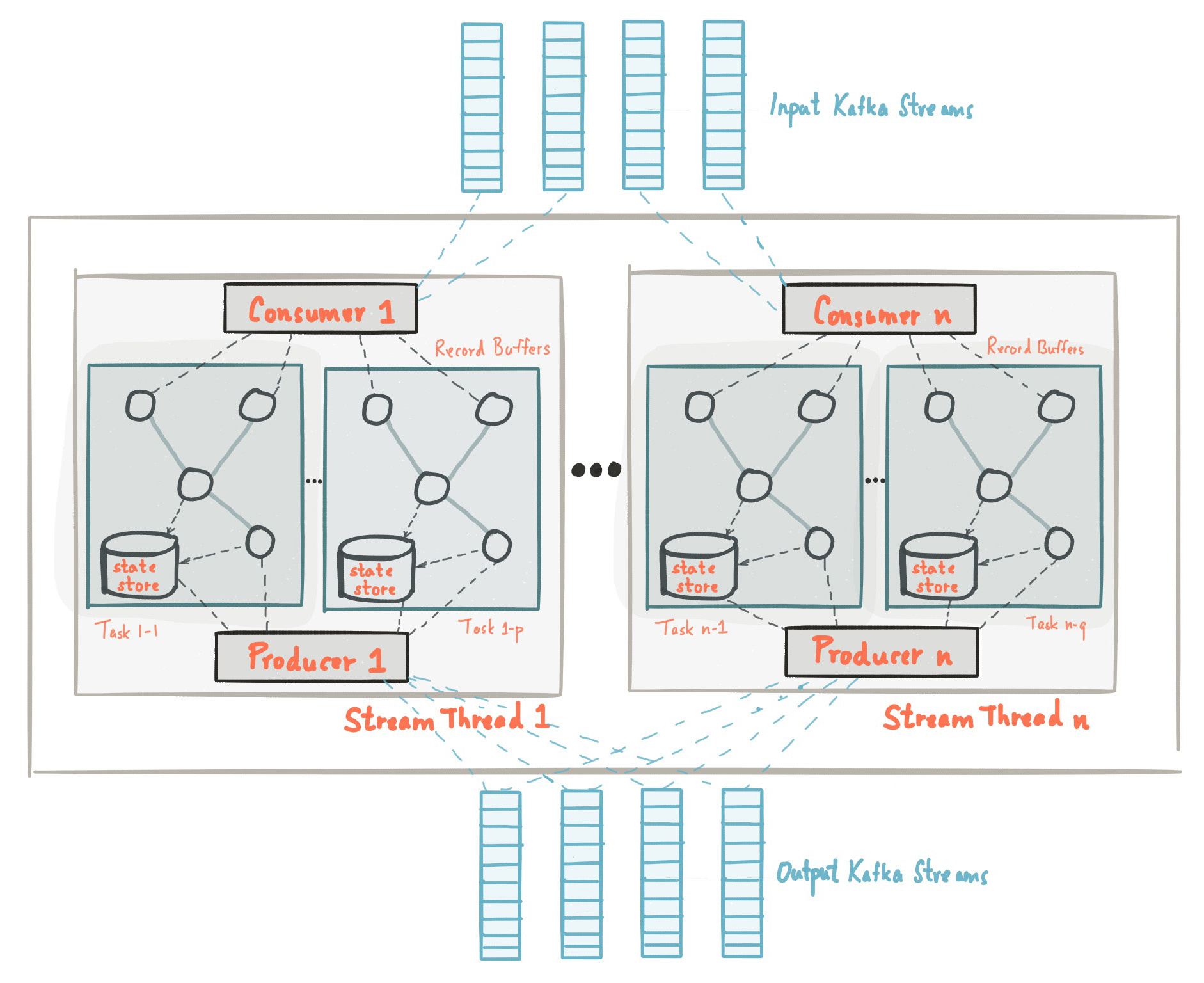 Source: kafka.apache.org/21/documentation/streams/architectureThere are many more elements in Kafka Streams, such as tasks, processing topology, threading model, etc., which we will not discuss in this post. More information can be found here.
Source: kafka.apache.org/21/documentation/streams/architectureThere are many more elements in Kafka Streams, such as tasks, processing topology, threading model, etc., which we will not discuss in this post. More information can be found here.Kafka Streams: State Storage
In stream processing, there are operations with and without state preservation. The state is what allows the application to remember the necessary information that goes beyond the scope of the record currently being processed.State operations, such as count, any type of aggregation, joins, etc., are much more complicated. This is due to the fact that having only one record, you cannot determine the last state (say, count) for a given key, so you need to store the state of your stream in your application. As we discussed earlier, each thread processes a set of unique partitions; therefore, a thread processes only a subset of the entire data set. This means that each Kafka Streams application thread with the same application.id maintains its own isolated state. We won’t go into details about how the state is formed in Kafka Streams, but it’s important to understand that the state is restored using the change-log topic and is saved not only on the local disk, but also in Kafka Broker.Saving the state changes log in Kafka Broker as a separate topic is made not only for fault tolerance, but also so that you can easily deploy new instances of Kafka Streams with the same application.id. Since the state is stored as a change-log topic on the broker's side, a new instance can load its own state from this topic.More information about state storage can be found here .Why is high availability problematic with Kafka Streams?
We reviewed the basic concepts and principles of data processing with Kafka Streams. Now let's try to combine all the parts together and analyze why achieving high availability can be problematic. From the previous sections, we must remember:- The data in the Kafka topic is divided into partitions, which are distributed between the Kafka Streams streams.
- Kafka Streams applications with the same application.id are, in fact, one group of consumers, and each of its threads is a separate isolated instance of the consumer.
- For state operations, the thread maintains its own state, which is “reserved” by the Kafka topic in the form of a change log.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
Before highlighting the essence of this post, let me first tell you what we created in TransferWise and why high availability is very important to us.In TransferWise, we have several nodes for streaming processing, and each node contains several instances of Kafka Streams for each product team. Kafka Streams instances that are designed for a specific development team have a special application.id and usually have more than 5 threads. In general, teams typically have 10-20 threads (equivalent to the number of instances of consumers) throughout the cluster. Applications that are deployed on nodes listen on input topics and perform several types of operations with and without state on input data and provide real-time data updates for subsequent downstream microservices.Product teams need to update aggregated data in real time. This is necessary in order to provide our customers with the ability to instantly transfer money. Our usual SLA:On any given day, 99.99% of aggregated data should be available in less than 10 seconds.
To give you an idea, during stress testing, Kafka Streams was able to process and aggregate 20,085 input messages per second. Thus, 10 seconds of SLA under normal load sounded quite achievable. Unfortunately, our SLA was not reached during the rolling update of the nodes on which the applications are deployed, and below I will describe why this happened.Sliding node update
At TransferWise, we strongly believe in the continuous delivery of our software and usually release new versions of our services a couple of times a day. Let's look at an example of a simple continuous service update and see what happens during the release process. Again, we must remember that:- The data in the Kafka topic is divided into partitions, which are distributed between the Kafka Streams streams.
- Kafka Streams applications with the same application.id are, in fact, one group of consumers, and each of its threads is a separate isolated instance of the consumer.
- For state operations, the thread maintains its own state, which is “reserved” by the Kafka topic in the form of a change log.
- , Kafka , .
A release process on a single node usually takes eight to nine seconds. During the release, instances of Kafka Streams on the node “gently reboot”. Thus, for a single node, the time required to correctly restart the service is approximately eight to nine seconds. Obviously, shutting down a Kafka Streams instance on a node causes a rebalancing of the consumer group. Since the data is partitioned, all partitions that belonged to the bootable instance must be distributed between active Kafka Streams applications with the same application.id. This also applies to aggregated data that has been saved to disk. Until this process completes, data will not be processed.Standby replicas
To reduce rebalancing time for Kafka Streams applications, there is a concept of backup replicas, which are defined in the config as num.standby.replicas. Backup replicas are copies of the local state store. This mechanism makes it possible to replicate the state store from one instance of Kafka Streams to another. When the Kafka Streams thread dies for any reason, the duration of the state recovery process can be minimized. Unfortunately, for the reasons that I will explain below, even backup replicas will not help with a rolling service update.Suppose we have two instances of Kafka Streams on two different machines: node-a and node-b. For each of the Kafka Streams instances, num.standby.replicas = 1 is indicated on these 2 nodes. With this configuration, each Kafka Streams instance maintains its own copy of the repository on another node. During a rolling update, we have the following situation:- The new version of the service has been deployed to node-a.
- The Kafka Streams instance on node-a is disabled.
- Rebalancing has begun.
- The repository from node-a has already been replicated to node-b, since we specified the configuration num.standby.replicas = 1.
- node-b already has a shadow copy of node-a, so the rebalancing process happens almost instantly.
- node-a starts up again.
- node-a joins a group of consumers.
- Kafka broker sees a new instance of Kafka Streams and starts rebalancing.
As we can see, num.standby.replicas helps only in scenarios of a complete shutdown of a node. This means that if node-a crashed, then node-b could continue to work correctly almost instantly. But in a rolling update situation, after disconnecting, node-a will join the group again, and this last step will cause a rebalance. When node-a joins the consumer group after a reboot, it will be considered as a new instance of the consumer. Again, we must remember that real-time data processing stops until a new instance restores its state from the change-log topic.Please note that rebalancing partitions when a new instance is joined to a group does not apply to the Kafka Streams API, since this is exactly how the protocol of the Apache Kafka consumer group works.Achievement: High Availability with Kafka Streams
Despite the fact that Kafka client libraries do not provide built-in functionality for the problem mentioned above, there are some tricks that can be used to achieve high cluster availability during a rolling update. The idea behind backup replicas remains valid, and having backup machines when the time is right is a good solution that we use to ensure high availability in the event of instance failure.The problem with our initial setup was that we had one group of consumers for all teams on all nodes. Now, instead of one group of consumers, we have two, and the second acts as a “hot” cluster. In prod, nodes have a special variable CLUSTER_ID, which is added to the application.id of Kafka Streams instances. Here is a sample Spring Boot application.yml configuration:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
At one point in time, only one of the clusters is in active mode, respectively, the backup cluster does not send messages in real time to downstream microservices. During the release of the release, the backup cluster becomes active, which allows for a rolling update on the first cluster. Since this is a completely different group of consumers, our customers do not even notice any violations in processing, and subsequent services continue to receive messages from the recently active cluster. One of the obvious disadvantages of using a backup group of consumers is the additional overhead and resource consumption, but, nevertheless, this architecture provides additional guarantees, control and fault tolerance of our streaming processing system.In addition to adding an additional cluster, there are also tricks that can mitigate the problem with frequent rebalancing.Increase group.initial.rebalance.delay.ms
Starting with Kafka 0.11.0.0, the configuration group.initial.rebalance.delay.ms has been added. According to the documentation, this setting is responsible for:The amount of time in milliseconds that GroupCoordinator will delay the initial rebalancing of the group’s consumer.
For example, if we set 60,000 milliseconds in this setting, then with a rolling update we may have a minute window for the release of the release. If the Kafka Streams instance successfully restarts in this time window, no rebalancing will be called. Please note that the data for which the restarted Kafka Streams instance was responsible will continue to be unavailable until the node returns to online mode. For example, if an instance reboot takes about eight seconds, you will have eight seconds of downtime for the data that this instance is responsible for.It should be noted that the main disadvantage of this concept is that in the event of a node failure, you will receive an additional delay of one minute during restoration, taking into account the current configuration.Shrinking segment size in change-log topics
The big delay in rebalancing Kafka Stream is due to the restoration of state stores from change-log topics. Change-log topics are compressed topics, which allows you to store the latest record for a particular key in the topic. I will briefly describe this concept below.Topics in Kafka Broker are organized in segments. When a segment reaches the configured threshold size, a new segment is created and the previous one is compressed. By default, this threshold is set to 1 GB. As you probably know, the main data structure underlying the Kafka topics and their partitions is the log structure with a forward write, that is, when messages are sent to the topic, they are always added to the last “active” segment, and compression is not going on.Therefore, most stored storage states in changelog are always in the “active segment” file and never compressed, resulting in millions of uncompressed changelog messages. For Kafka Streams, this means that during rebalancing, when the Kafka Streams instance restores its state from the changelog topic, it needs to read a lot of redundant entries from the changelog topic. Given that state stores only care about the last state, and not about history, this processing time is wasted. Reducing the size of the segment will cause more aggressive data compression, so new instances of Kafka Streams applications can recover much faster.Conclusion
Even though Kafka Streams does not provide a built-in ability to provide high availability during a rolling service update, this can still be done at the infrastructure level. We must remember that Kafka Streams is not a “cluster framework” unlike Apache Flink or Apache Spark. It is a lightweight Java library that allows developers to create scalable applications for streaming data. Despite this, it provides the necessary building blocks to achieve such ambitious streaming goals as “99.99%” availability.