I regularly come across a situation where many developers sincerely believe that the index in PostgreSQL is such a Swiss knife that universally helps with any query performance problem. It is enough to add some new index to the table or to include the field somewhere in the existing one, and then (magic-magic!) All queries will use this index effectively. First, of course, either they will not, or not efficiently, or not all. Secondly, extra indexes will only add performance issues when writing.Most often, such situations occur during “long-playing” development, when not a custom product is made according to the “wrote once, gave, forgot” model, but, as in our case, is createdservice with a long life cycle .Improvements occur iteratively by the forces of many distributed teams , which are distributed not only in space but also in time. And then, not knowing the whole history of the development of the project or the features of the applied distribution of data in its database, you can easily "mess up" with the indices. But considerations and test requests under the cut allow you to predict and detect part of the problems in advance:
First, of course, either they will not, or not efficiently, or not all. Secondly, extra indexes will only add performance issues when writing.Most often, such situations occur during “long-playing” development, when not a custom product is made according to the “wrote once, gave, forgot” model, but, as in our case, is createdservice with a long life cycle .Improvements occur iteratively by the forces of many distributed teams , which are distributed not only in space but also in time. And then, not knowing the whole history of the development of the project or the features of the applied distribution of data in its database, you can easily "mess up" with the indices. But considerations and test requests under the cut allow you to predict and detect part of the problems in advance:- unused indexes
- prefix "clones"
- timestamp “in the middle”
- indexable boolean
- arrays in the index
- Null trash
The simplest thing is to find indices for which there were no passes at all . You just need to make sure that the statistics ( pg_stat_reset()) reset occurred a long time ago, and you don’t want to delete the used “rarely, but aptly” one. We use the system view pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
But even if the index is used and did not fall into this selection, this does not mean at all that it is well suited for your queries.What indices are [not] suitable
To understand why some queries “go bad on the index”, let's think about the structure of a regular btree index - the most frequent instance in nature. Indices from a single field usually do not create any problems, therefore, we consider the problems that arise on a composite of a pair of fields.An extremely simplified way, as it can be imagined, is a “layered cake”, where in each layer there are ordered trees according to the values of the corresponding field in order.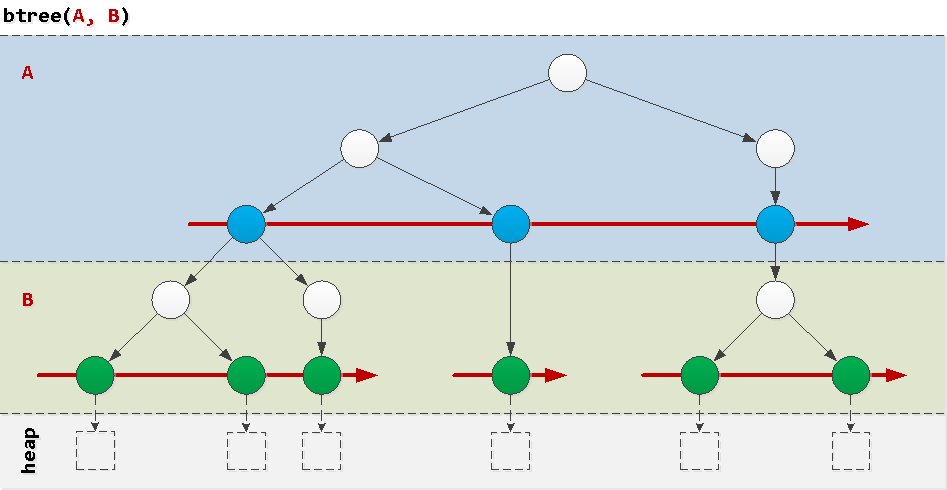 Now it is clear that the field A globally ordered, and B - only within a specific value A . Let's look at examples of conditions that occur in real queries, and how they will "walk" around the index.
Now it is clear that the field A globally ordered, and B - only within a specific value A . Let's look at examples of conditions that occur in real queries, and how they will "walk" around the index.Good: prefix condition
Note that the index btree(A, B)includes a “subindex” btree(A). This means that all the rules described below will work for any prefix index.That is, if you create a more complex index than in our example, something of the type btree(A, B, C)- you can assume that your database automatically "appears":btree(A, B, C)btree(A, B)btree(A)
And this means that the “physical” presence of the prefix index in the database is redundant in most cases. After all, the more indexes a table has to write - the worse it is for PostgreSQL, since it calls Write Amplification - Uber complained about it (and here you can find an analysis of their claims ).And if something prevents the base from living well, it is worth finding and eliminating it. Let's look at an example:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
Prefix Index Search QueryWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
Ideally, you should get an empty selection, but look - these are our suspicious index groups:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Then you decide for each group yourself whether it was worth removing the shorter index or the longer one was not needed at all.Good: all constants except the last field
If the values of all fields of the index, except the last, are set by constants (in our example, this is field A), the index can be used normally. In this case, the value of the last field can be set arbitrarily: constant, inequality, interval, dialing through IN (...)or = ANY(...). And also it can be sorted by it.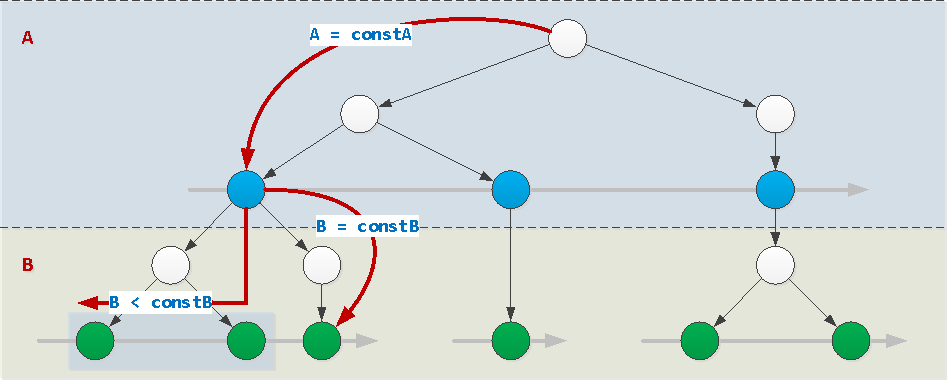
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Based on the prefix indexes described above, this will work well:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Bad: full enumeration of the "layer"
With part of the queries, the only enumeration of the movement in the index becomes a complete enumeration of all values in one of the “layers”. It is lucky if there are unity of such values - and if there are thousands? ..Usually such a problem occurs if inequality is used in the query , the condition does not determine the fields that are previous in the index order or this order is violated during sorting.WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Bad: interval or set is not in the last field
As a consequence of the previous one - if you need to find several values or their range on some intermediate “layer”, and then filter or sort by the fields lying “deeper” in the index, there will be problems if the number of unique values “in the middle” of the index is great.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Bad: expression instead of field
Sometimes a developer unconsciously turns a column in a query into something else - into some expression for which there is no index. This can be fixed by creating an index from the desired expression, or by performing the inverse transformation:WHERE A - const1 [op] const2
fix: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
fix: WHERE A = const::typeOfA
We take into account the cardinality of the fields
Suppose you need an index (A, B), and you want to choose only by equality : (A, B) = (constA, constB). The use of a hash index would be ideal , but ... In addition to the non-journaling (wal logging) of such indexes up to version 10, they also cannot exist on several fields:CREATE INDEX ON tbl USING hash(A, B);
In general, you have chosen btree. So what is the best way to arrange columns in it - (A, B)or (B, A)? To answer this question, it is necessary to take into account such a parameter as the cardinality of the data in the corresponding column - that is, how many unique values it contains.Let's imagine that A = {1,2}, B = {1,2,3,4}, and draw an outline of the index tree for both options: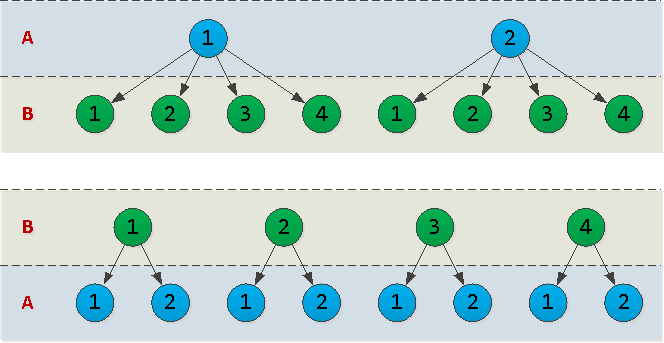 In fact, each node in the tree that we draw is a page in the index. And the more there are, the more disk space the index will occupy, the longer it will take to read from it.In our example, the option
In fact, each node in the tree that we draw is a page in the index. And the more there are, the more disk space the index will occupy, the longer it will take to read from it.In our example, the option (A, B)has 10 nodes, and (B, A)- 12. That is, it is more profitable to put the "fields" with as few unique values as possible "first" .Bad: a lot and out of place (timestamp "in the middle")
Exactly for this reason it always looks suspicious if a field with obviously large variability like timestamp [tz] is not the last in your index . As a rule, the values of the timestamp field increase monotonically, and the following index fields have only one value at each time point.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

Search query for non-final timestamp [tz] indexesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Here we analyze immediately both the types of the incoming fields themselves and the classes of operators applied to them - since some timestamptz-function like date_trunc may turn out to be an index field.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Bad: too little (boolean)
The flip side of the same coin, it becomes a situation where the index is boolean-field , which can take only 3 values NULL, FALSE, TRUE. Of course, its presence makes sense if you want to use it for applied sorting — for example, by designating them as the type of node in the tree hierarchy — whether it is a folder or a leaf (“folders first”).CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
But, in most cases, this is not the case, and requests come with some specific value of the boolean field. And then it becomes possible to replace the index with this field with its conditional version:CREATE INDEX ON tbl(id) WHERE public;
Boolean search query in indexesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Arrays in btree
A separate point is the attempt to "index the array" using the btree index. This is entirely possible since the corresponding operators apply to them :(<, >, = . .) , B-, , . ( ). , , .
But the trouble is that to use something he wants to operators of inclusion and intersection : <@, @>, &&. Of course, this does not work - because they need other types of indexes . How such a btree does not work for the function of accessing a specific element arr[i].We learn to find such:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
Array search query in btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
NULL index entries
The last quite common problem is “littering” the index with completely NULL entries. That is, records where the indexed expression in each of the columns is NULL . Such records do not have any practical benefit, but they add harm with each insert.Usually they appear when you create an FK field or value relationship with optional padding in the table. Then roll the index so that FK works out quickly ... and here they are. The less often the connection will be filled, the more “garbage” will fall into the index. We will simulate:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
In most cases, such an index can be converted to a conditional one, which also takes less:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
To find such indexes, we need to know the actual distribution of the data - that is, after all, read all the contents of the tables and superimpose it according to the WHERE-conditions of the occurrence (we will do this using dblink ), which can take a very long time .Search query for NULL entries in indexesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
I hope some of the queries in this article will help you.