HighLoad ++, Mikhail Tyulenev (MongoDB): Causal consistency: from theory to practice
The next HighLoad ++ conference will be held on April 6 and 7, 2020 in St. Petersburg.Details and tickets here . HighLoad ++ Siberia 2019. Hall "Krasnoyarsk". June 25, 12:00. Abstracts and presentation . It happens that practical requirements conflict with a theory where aspects important for a commercial product are not taken into account. This report presents the process of selecting and combining various approaches to creating Causal consistency components based on academic research based on the requirements of a commercial product. Students will learn about the existing theoretical approaches to logical clocks, dependency tracking, system security, clock synchronization, and why MongoDB stopped on these or those solutions.Mikhail Tyulenev (hereinafter - MT): - I will talk about Causal consistency - this is a feature that we worked on in MongoDB. I work in a group of distributed systems, we did it about two years ago.
It happens that practical requirements conflict with a theory where aspects important for a commercial product are not taken into account. This report presents the process of selecting and combining various approaches to creating Causal consistency components based on academic research based on the requirements of a commercial product. Students will learn about the existing theoretical approaches to logical clocks, dependency tracking, system security, clock synchronization, and why MongoDB stopped on these or those solutions.Mikhail Tyulenev (hereinafter - MT): - I will talk about Causal consistency - this is a feature that we worked on in MongoDB. I work in a group of distributed systems, we did it about two years ago. In the process, I had to get acquainted with a lot of academic Research, because this feature is well studied. It turned out that not a single article fits into what is required in production, the database in view of the very specific requirements that are, probably, in any production applications.I will talk about how we, as a consumer of academic Research, prepare something from it that we can then present to our users as a ready-made dish that is convenient, safe to use.
In the process, I had to get acquainted with a lot of academic Research, because this feature is well studied. It turned out that not a single article fits into what is required in production, the database in view of the very specific requirements that are, probably, in any production applications.I will talk about how we, as a consumer of academic Research, prepare something from it that we can then present to our users as a ready-made dish that is convenient, safe to use.Causal consistency. Let's define concepts
To begin with, I want to outline in general terms what Causal consistency is. There are two characters - Leonard and Penny (the series "The Big Bang Theory"):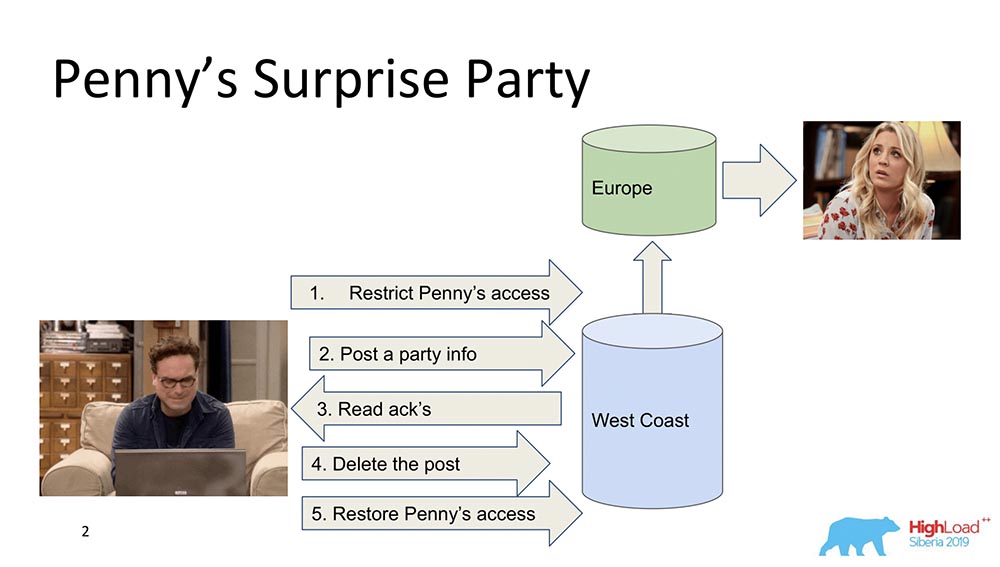 Suppose Penny is in Europe, and Leonard wants to make some kind of surprise for her, a party. And he doesn’t come up with anything better than throwing her out of the friend list, sending updates to feed all friends: “Let's make Penny happy!” (she in Europe, while sleeping, does not see this all and cannot see, because she is not there). At the end, it deletes this post, erases it from the "Feed" and restores access so that it does not notice anything and there is no scandal.This is all fine, but let's assume that the system is distributed, and the events went a bit wrong. Maybe, for example, it happens that the Penny access restriction occurred after this post appeared, if the events are not connected by a causal relationship. Actually, this is an example of when Causal consistency is required in order to fulfill a business function (in this case).In fact, these are quite non-trivial properties of the database - very few people support them. Let's move on to the models.
Suppose Penny is in Europe, and Leonard wants to make some kind of surprise for her, a party. And he doesn’t come up with anything better than throwing her out of the friend list, sending updates to feed all friends: “Let's make Penny happy!” (she in Europe, while sleeping, does not see this all and cannot see, because she is not there). At the end, it deletes this post, erases it from the "Feed" and restores access so that it does not notice anything and there is no scandal.This is all fine, but let's assume that the system is distributed, and the events went a bit wrong. Maybe, for example, it happens that the Penny access restriction occurred after this post appeared, if the events are not connected by a causal relationship. Actually, this is an example of when Causal consistency is required in order to fulfill a business function (in this case).In fact, these are quite non-trivial properties of the database - very few people support them. Let's move on to the models.Consistency Models
What is a consistency model in databases in general? These are some of the guarantees that a distributed system gives regarding what data and in what sequence the client can receive.In principle, all consistency models come down to how distributed the system is like a system that works, for example, on the same nod on a laptop. And this is how much the system, which works on thousands of geo-distributed “Nodes”, is similar to a laptop, in which all these properties are executed automatically in principle.Therefore, consistency models only apply to distributed systems. All systems that previously existed and worked on the same vertical scaling did not experience such problems. There was one Buffer Cache, and everything was always read from it.Strong Model
Actually, the very first model is Strong (or the line of rise ability, as it is often called). This is a consistency model that ensures that every change, as soon as confirmation is received that it has occurred, is visible to all users of the system.This creates a global order of all events in the database. This is a very strong consistency property, and it is generally very expensive. However, it is very well maintained. It is simply very expensive and slow - they are simply rarely used. This is called rise ability.There is another, more powerful property that is supported in the "Spanner" - called External Consistency. We will talk about him a little later.Causal
The following is Causal, just what I was talking about. There are several sublevels between Strong and Causal that I won’t talk about, but they all come down to Causal. This is an important model because it is the strongest of all models, the strongest consistency in the presence of a network or partitions.Causals is actually a situation in which events are connected by a causal relationship. Very often they are perceived as Read your on rights from the point of view of the client. If the client observed some values, he cannot see the values that were in the past. He is already starting to see prefix readings. It all comes down to the same thing.Causals as a model of consistency is a partial ordering of events on the server, in which events from all clients are observed in the same sequence. In this case, Leonard and Penny.Eventual
The third model is Eventual Consistency. This is what supports absolutely all distributed systems, a minimal model that generally makes sense. It means the following: when we have some changes in the data, they become consistent at some point.At such a moment, she does not say anything, otherwise she would turn into External Consistency - there would be a completely different story. Nevertheless, this is a very popular model, the most common. By default, all users of distributed systems use Eventual Consistency.I want to give some comparative examples: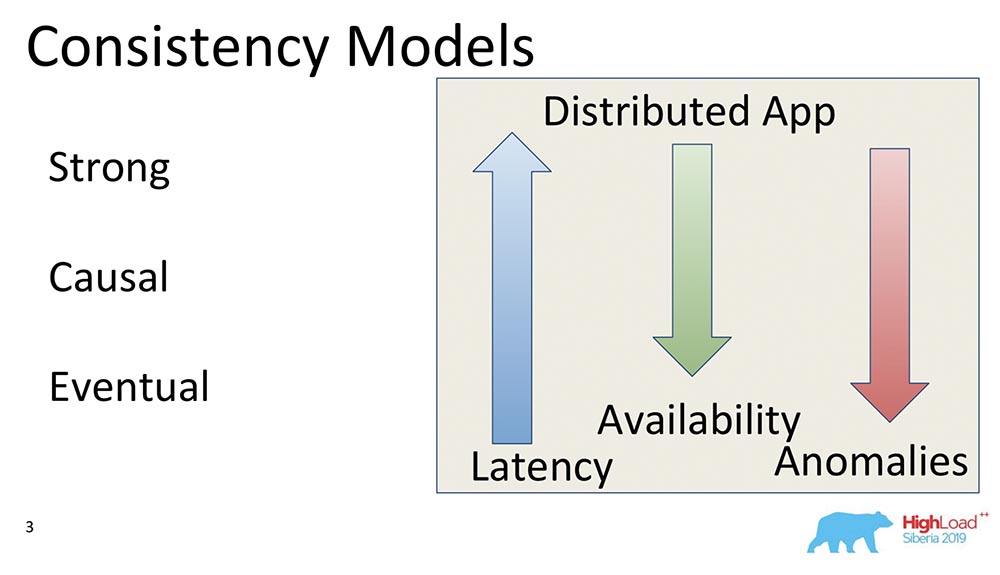 What do these arrows mean?
What do these arrows mean?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
When you see the words consistency, availability - what comes to mind? Right - CAP theorem! Now I want to dispel the myth ... It's not me - there is Martin Kleppman, who wrote a wonderful article, a wonderful book. The CAP theorem is a principle formulated in the 2000s that Consistency, Availability, Partitions: take any two, and you cannot choose three. It was a certain principle. It was proved as a theorem a few years later, by Gilbert and Lynch. Then it became used as a mantra - systems began to be divided into CA, CP, AP and so on.This theorem was actually proved for the following reasons ... First, Availability was considered not as a continuous value from zero to hundreds (0 - the system is "dead", 100 - answers quickly; we are so used to considering it), but as a property of the algorithm , which ensures that with all its executions it returns data.There is not a word about the response time! There is an algorithm that returns data after 100 years - a perfectly fine available algorithm, which is part of the CAP theorem.Second: a theorem was proved for changes in the values of the same key, despite the fact that these changes are a resizable line. This means that in fact they are practically not used, because the models are different Eventual Consistency, Strong Consistency (maybe).Why is this all? Moreover, the CAP theorem in the form in which it is proved is practically not applicable is rarely used. In a theoretical form, it somehow limits everything. It turns out a certain principle that is intuitively true, but in no way, in general, is proved.
The CAP theorem is a principle formulated in the 2000s that Consistency, Availability, Partitions: take any two, and you cannot choose three. It was a certain principle. It was proved as a theorem a few years later, by Gilbert and Lynch. Then it became used as a mantra - systems began to be divided into CA, CP, AP and so on.This theorem was actually proved for the following reasons ... First, Availability was considered not as a continuous value from zero to hundreds (0 - the system is "dead", 100 - answers quickly; we are so used to considering it), but as a property of the algorithm , which ensures that with all its executions it returns data.There is not a word about the response time! There is an algorithm that returns data after 100 years - a perfectly fine available algorithm, which is part of the CAP theorem.Second: a theorem was proved for changes in the values of the same key, despite the fact that these changes are a resizable line. This means that in fact they are practically not used, because the models are different Eventual Consistency, Strong Consistency (maybe).Why is this all? Moreover, the CAP theorem in the form in which it is proved is practically not applicable is rarely used. In a theoretical form, it somehow limits everything. It turns out a certain principle that is intuitively true, but in no way, in general, is proved.Causal consistency - the strongest model
What is happening now - you can get all three things: Consistency, Availability can be obtained using Partitions. In particular, Causal consistency is the strongest consistency model, which, in the presence of Partitions (network breaks), still works. Therefore, it is of such great interest, and therefore we are engaged in it. First, it simplifies the work of application developers. In particular, there is a lot of support from the server: when all the records that occur inside one client are guaranteed to arrive in this order on the other client. Secondly, it withstands partitions.
First, it simplifies the work of application developers. In particular, there is a lot of support from the server: when all the records that occur inside one client are guaranteed to arrive in this order on the other client. Secondly, it withstands partitions.Interior Kitchen MongoDB
Remembering that lunch, we move to the kitchen. I will talk about the system model, namely, what is MongoDB for those who first hear about such a database.
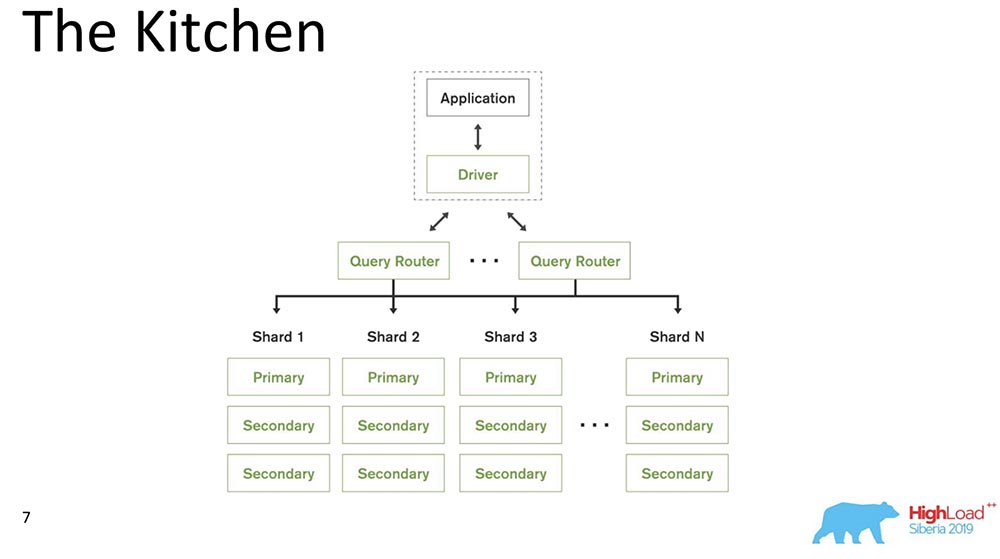 MongoDB (hereinafter referred to as “MongoBD”) is a distributed system that supports horizontal scaling, that is, sharding; and within each shard, it also supports data redundancy, i.e. replication.Sharding in “MongoBD” (non-relational database) performs automatic balancing, that is, each collection of documents (or “table” in terms of relational data) into pieces, and already the server automatically moves them between shards.The Query Router that distributes queries for the client is some client through which it works. He already knows where and what data is located, sends all requests to the correct shard.Another important point: MongoDB is a single master. There is one Primary - it can take records that support the keys that it contains. You cannot do multi-master write.We made release 4.2 - new interesting things appeared there. In particular, they inserted Lucene - the search - it was executable java directly in "Mongo", and there it became possible to search through Lucene, the same as in "Elastic".And they made a new product - Charts, it is also available on Atlas (Mongo's own Cloud). They have Free Tier - you can play around with this. I really liked the charts - the data visualization is very intuitive.
MongoDB (hereinafter referred to as “MongoBD”) is a distributed system that supports horizontal scaling, that is, sharding; and within each shard, it also supports data redundancy, i.e. replication.Sharding in “MongoBD” (non-relational database) performs automatic balancing, that is, each collection of documents (or “table” in terms of relational data) into pieces, and already the server automatically moves them between shards.The Query Router that distributes queries for the client is some client through which it works. He already knows where and what data is located, sends all requests to the correct shard.Another important point: MongoDB is a single master. There is one Primary - it can take records that support the keys that it contains. You cannot do multi-master write.We made release 4.2 - new interesting things appeared there. In particular, they inserted Lucene - the search - it was executable java directly in "Mongo", and there it became possible to search through Lucene, the same as in "Elastic".And they made a new product - Charts, it is also available on Atlas (Mongo's own Cloud). They have Free Tier - you can play around with this. I really liked the charts - the data visualization is very intuitive.Causal consistency ingredients
I counted about 230 articles that were published on this topic - from Leslie Lampert. Now from my memory I will bring to you some parts of these materials. It all started with an article by Leslie Lampert, which was written in the 1970s. As you can see, some research on this topic is still ongoing. Now Causal consistency is experiencing interest in connection with the development of distributed systems.
It all started with an article by Leslie Lampert, which was written in the 1970s. As you can see, some research on this topic is still ongoing. Now Causal consistency is experiencing interest in connection with the development of distributed systems.Limitations
What are the limitations? This is actually one of the main points, because the restrictions that production systems impose are very different from the restrictions that exist in academic articles. Often they are quite artificial.
- Firstly, “MongoDB” is a single master, as I have already said (this greatly simplifies).
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- Another point is generally anti-academic: compatibility of previous and future versions. Old drivers must support new updates, and the database must support old drivers.
In general, all this imposes limitations.Causal consistency components
I will now talk about some of the components. If we consider the general Causal consistency, we can distinguish blocks. We chose from the works that belong to a block: Dependency Tracking, the choice of hours, how these watches can be synchronized with each other, and how we ensure safety - this is an approximate plan of what I’ll talk about:
Full Dependency Tracking
Why is it needed? In order that when the data is replicated - each record, each data change contains information about what changes it depends on. The very first and naive change is when each message that contains a record contains information about previous messages: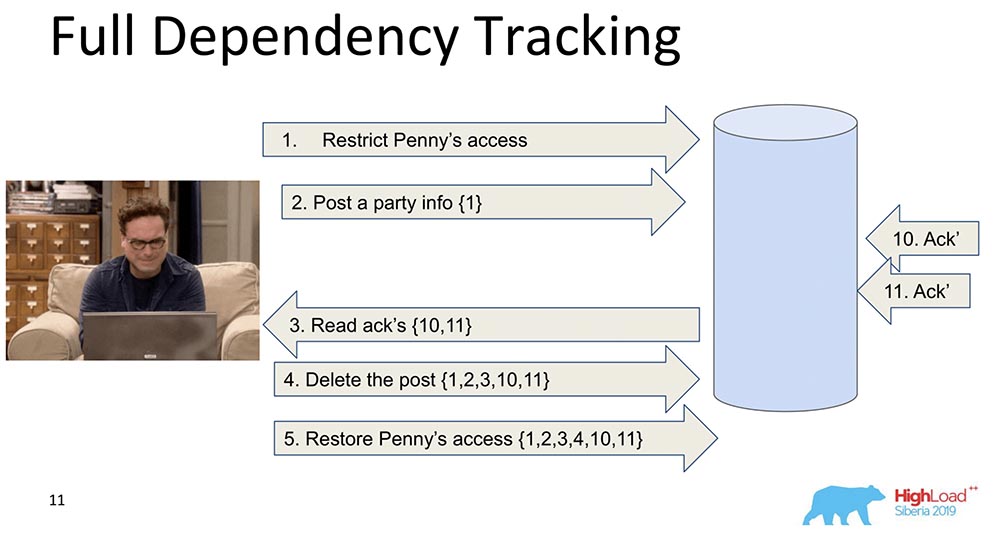 In this example, the number in braces is the number of records. Sometimes these records with values are even transferred in their entirety, sometimes some versions are transferred. The bottom line is that each change contains information about the previous one (obviously it carries everything in itself).Why did we decide not to use this approach (full tracking)? Obviously, because this approach is impractical: any change in the social network depends on all previous changes in this social network, transmitting, say, Facebook or Vkontakte in each update. Nevertheless, there is a lot of research namely Full Dependency Tracking - these are social networks, for some situations it really works.
In this example, the number in braces is the number of records. Sometimes these records with values are even transferred in their entirety, sometimes some versions are transferred. The bottom line is that each change contains information about the previous one (obviously it carries everything in itself).Why did we decide not to use this approach (full tracking)? Obviously, because this approach is impractical: any change in the social network depends on all previous changes in this social network, transmitting, say, Facebook or Vkontakte in each update. Nevertheless, there is a lot of research namely Full Dependency Tracking - these are social networks, for some situations it really works.Explicit Dependency Tracking
The next one is more limited. Here, too, transmission of information is considered, but only that which clearly depends. What depends on what, as a rule, is determined already by Application. When data is replicated, only responses are returned when a request is made, when previous dependencies were satisfied, that is, shown. This is the essence of how Causal consistency works.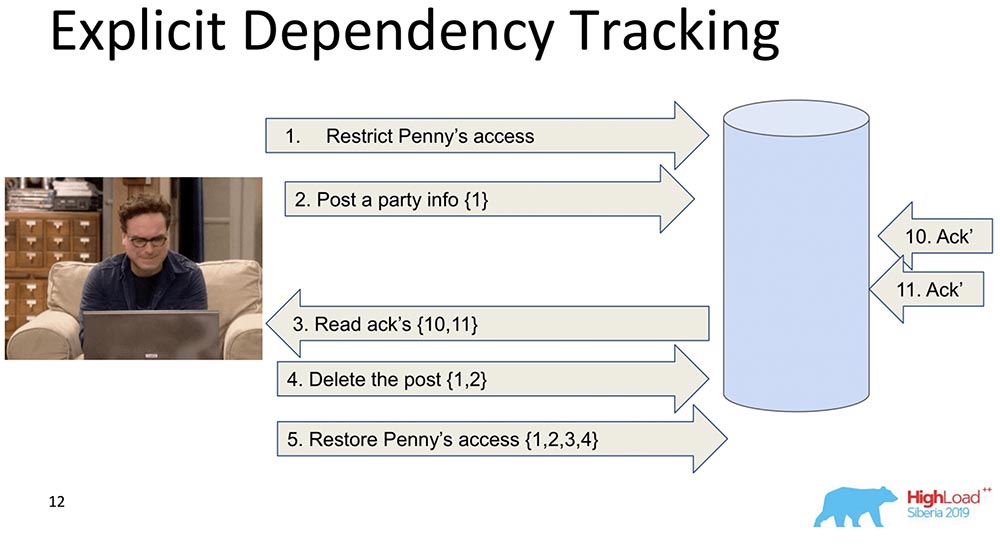 She sees that record 5 depends on records 1, 2, 3, 4 - respectively, she waits before the client gets access to the changes made by Penny's access decree when all previous changes have already passed to the database.This also does not suit us, because anyway there is too much information, and this will slow down. There is a different approach ...
She sees that record 5 depends on records 1, 2, 3, 4 - respectively, she waits before the client gets access to the changes made by Penny's access decree when all previous changes have already passed to the database.This also does not suit us, because anyway there is too much information, and this will slow down. There is a different approach ...Lamport Clock
They are very old. Lamport Clock implies that these dependency are collapsed into a scalar function called Lamport Clock.A scalar function is some abstract number. Often called logical time. At each event, this counter increases. Counter, which is currently known to the process, sends each message. It is clear that processes can be out of sync, they can have completely different times. Nevertheless, the system somehow balances the clock with such messaging. What happens in this case?I split that big shard in two so that it is clear: Friends can live in one node that contains a piece of the collection, and Feed can live in another node that contains a piece of this collection. It’s clear how they can get out of turn? First, Feed says, “Replicated,” and then Friends. If the system does not provide any guarantees that Feed will not be shown until the Friends dependencies in the Friends collection are also delivered, then we will just have a situation that I mentioned.You see how logically counter time increases on Feed: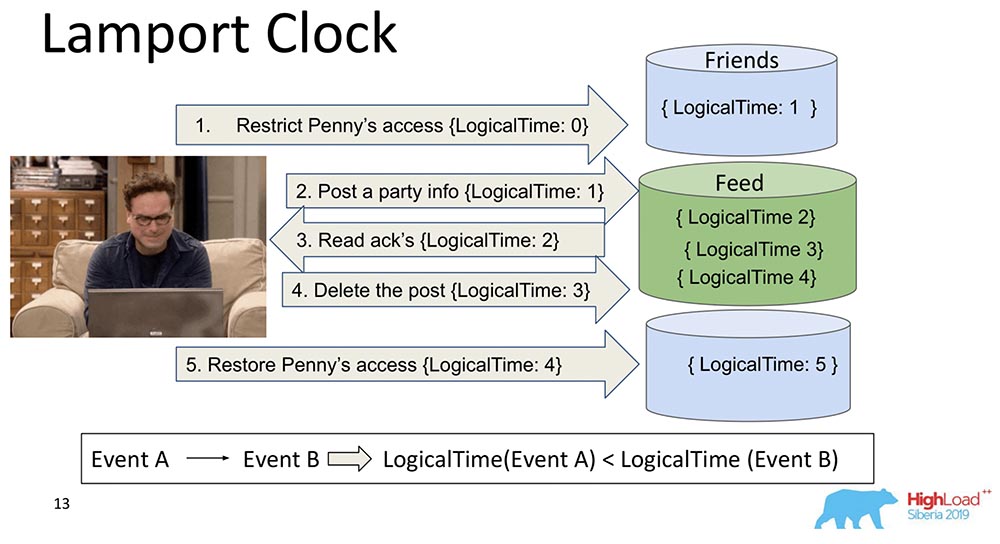 Thus, the main property of this Lamport Clock and Causal consistency (explained through Lamport Clock) is as follows: if we have events A and B, and event B depends on event A *, then it follows that the LogicalTime from Event A is less than the LogicalTime from Event B.* Sometimes they even say that A happened before B, that is, A happened before B - this is a kind of relationship that partially orders the whole set of events that generally happened.The reverse is wrong. This is actually one of the main disadvantages of Lamport Clock - partial ordering. There is a concept of simultaneous events, that is, events in which neither (A happened before B) nor (A happened before B). An example is the parallel addition by Leonard to friends of someone else (not even Leonard, but Sheldon, for example).This is the property that is often used when working with Lamport watches: they look at the function exactly and draw a conclusion from this - maybe these events are dependent. Because in one direction this is true: if LogicalTime A is less than LogicalTime B, then B cannot happen before A; and if more, then maybe.
Thus, the main property of this Lamport Clock and Causal consistency (explained through Lamport Clock) is as follows: if we have events A and B, and event B depends on event A *, then it follows that the LogicalTime from Event A is less than the LogicalTime from Event B.* Sometimes they even say that A happened before B, that is, A happened before B - this is a kind of relationship that partially orders the whole set of events that generally happened.The reverse is wrong. This is actually one of the main disadvantages of Lamport Clock - partial ordering. There is a concept of simultaneous events, that is, events in which neither (A happened before B) nor (A happened before B). An example is the parallel addition by Leonard to friends of someone else (not even Leonard, but Sheldon, for example).This is the property that is often used when working with Lamport watches: they look at the function exactly and draw a conclusion from this - maybe these events are dependent. Because in one direction this is true: if LogicalTime A is less than LogicalTime B, then B cannot happen before A; and if more, then maybe.Vector Clock
The logical development of Lamport watches is the Vector Clock. They differ in that each node that is here contains its own separate clock, and they are transmitted as a vector.In this case, you see that the zero index of the vector is responsible for Feed, and the first index of the vector is for Friends (each of these nodes). And now they will increase: the zero index of the "Feed" increases when recording - 1, 2, 3: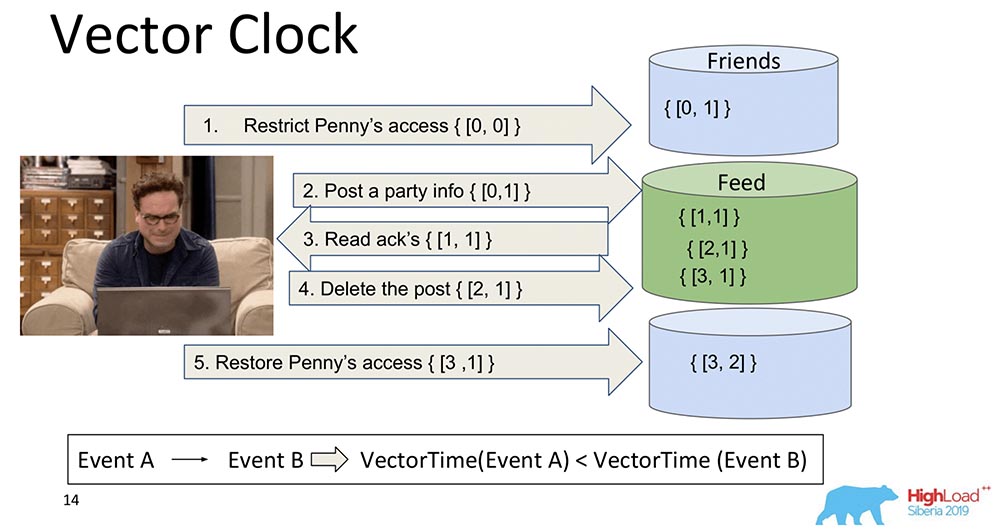 How is the Vector Clock better? The fact that they can figure out which events are simultaneous and when they occur on different nodes. This is very important for a sharding system like the MongoBD. However, we didn’t choose this, although it’s a wonderful thing, and it works great, and probably would suit us ...If we have 10 thousand shards, we cannot transfer 10 thousand components, even if we compress, we think up something else - all the same, the payload will be several times less than the volume of this whole vector. Therefore, grinding our hearts and teeth, we abandoned this approach and moved on to another.
How is the Vector Clock better? The fact that they can figure out which events are simultaneous and when they occur on different nodes. This is very important for a sharding system like the MongoBD. However, we didn’t choose this, although it’s a wonderful thing, and it works great, and probably would suit us ...If we have 10 thousand shards, we cannot transfer 10 thousand components, even if we compress, we think up something else - all the same, the payload will be several times less than the volume of this whole vector. Therefore, grinding our hearts and teeth, we abandoned this approach and moved on to another.Spanner TrueTime. Atomic clock
I said that there will be a story about Spanner. This is a cool thing, right the 21st century: atomic clocks, GPS synchronization.What idea? Spanner is a Google system that has recently even become available to people (they have attached SQL to it). Each transaction there has some time stamp. Since the time is synchronized *, each event can be assigned a specific time - the atomic clock has a wait time, after which it is guaranteed that another time will occur. Thus, just writing to the database and waiting for a certain period of time, the event serialization is automatically guaranteed. They have the strongest Consistency model, which in principle can be imagined - it is External Consistency.* This is the main problem of Lampart watches - they are never synchronous on distributed systems. They can diverge, even with NTP, they still do not work very well. "Spanner" has an atomic clock and synchronization seems to be then microseconds.Why didn’t we choose? We do not assume that our users have a built-in atomic clock. When they appear, being built into every laptop, there will be some kind of super cool GPS synchronization - then yes ... In the meantime, the best that is possible is Amazon, Base Stations for fanatics ... Therefore, we used other watches.
Thus, just writing to the database and waiting for a certain period of time, the event serialization is automatically guaranteed. They have the strongest Consistency model, which in principle can be imagined - it is External Consistency.* This is the main problem of Lampart watches - they are never synchronous on distributed systems. They can diverge, even with NTP, they still do not work very well. "Spanner" has an atomic clock and synchronization seems to be then microseconds.Why didn’t we choose? We do not assume that our users have a built-in atomic clock. When they appear, being built into every laptop, there will be some kind of super cool GPS synchronization - then yes ... In the meantime, the best that is possible is Amazon, Base Stations for fanatics ... Therefore, we used other watches.Hybrid Clock
This is actually what ticks the “MongoBD” while ensuring Causal consistency. What are they hybrid? A hybrid is a scalar value, but it consists of two components:
- The first is the unix era (how many seconds have passed since the "beginning of the computer world").
- The second is some increment, also a 32-bit unsigned int.
That's all, actually. There is such an approach: the part that is responsible for the time is synchronized with the clock all the time; every time an update occurs, this part is synchronized with the clock and it turns out that the time is always more or less correct, and increment allows you to distinguish between events that occurred at the same time.Why is this important for MongoBD? Because it allows you to make some kind of backup restorants at a certain point in time, that is, the event is indexed by time. This is important when some events are needed; for a database, events are changes to the database that occur at certain times in time.I will only tell you the most important reason (please, just don’t tell anyone)! We did this because ordered, indexed data in MongoDB OpLog looks like this. OpLog is a data structure that contains absolutely all changes in the database: they first go to OpLog, and then they are already applied to Storage itself in the case when it is a replicated date or shard.That was the main reason. Still, there are also practical requirements for developing the database, which means that it should be simple - there is little code, as few broken things as possible that need to be rewritten and tested. The fact that our oplogs were indexed by a hybrid watch greatly helped, and allowed us to make the right choice. It really paid off and somehow magically worked, on the very first prototype. It was very cool!Clock synchronization
There are several synchronization methods described in the scientific literature. I'm talking about synchronization when we have two different shards. If there is one replica set, there is no need for synchronization there: it is a “single master”; we have an OpLog in which all changes get into - in this case everything is already sequentially ordered in the "Oplog" itself. But if we have two different shards, time synchronization is important here. Here vector clocks helped more! But we do not have them. The second one is Heartbeats. You can exchange some signals that occur every unit of time. But Hartbits are too slow, we cannot provide latency to our client.True time is, of course, a wonderful thing. But, again, this is probably the future ... Although the Atlas can already be done, there are already fast "Amazonian" time synchronizers. But it will not be available to everyone.Gossiping is when all messages include time. This is roughly what we use. Each message between nodes, a driver, a router of data nodes, absolutely everything for MongoDB are some elements, database components that contain hours that flow. Everywhere they have the meaning of hybrid time, it is transmitted. 64 bits? It allows, it is possible.
The second one is Heartbeats. You can exchange some signals that occur every unit of time. But Hartbits are too slow, we cannot provide latency to our client.True time is, of course, a wonderful thing. But, again, this is probably the future ... Although the Atlas can already be done, there are already fast "Amazonian" time synchronizers. But it will not be available to everyone.Gossiping is when all messages include time. This is roughly what we use. Each message between nodes, a driver, a router of data nodes, absolutely everything for MongoDB are some elements, database components that contain hours that flow. Everywhere they have the meaning of hybrid time, it is transmitted. 64 bits? It allows, it is possible.How does it all work together?
Here I look at one replica set to make it a little easier. There are Primary and Secondary. Secondary does replication and is not always fully synchronized with Primary.There is an insert (insert) in the "Primaries" with a certain value of time. This insert increases the internal counter by 11, if it is maximum. Or it will check the clock values and synchronize by the clock if the clock is larger. This allows you to sort by time.After he makes a record, an important moment occurs. The hours are in “MongoDB” and are incremented only if recorded in the “Oplog”. This is an event that changes the state of the system. Absolutely in all classic articles, an event is considered to be a message entering a node: a message has arrived - that means the system has changed its state.This is due to the fact that during the study it is not entirely possible to understand how this message will be interpreted. We know for sure that if it is not reflected in the “Oplog”, then it will not be interpreted in any way, and only the entry in the “Oplog” is a change in the state of the system. This simplifies everything for us: the model simplifies and allows us to organize in the framework of one replica set, and many other useful things.It returns the value that has already been recorded in the “Oplog” - we know that in the “Oplog” this value already lies, and its time is 12. Now, say, the reading starts from another node (Secondary), and it transfers already afterClusterTime itself message. He says: “I need everything that happened after at least 12 or during twelve” (see fig. Above).This is what is called Causal a consistent (CAT). There is such a concept in theory that it is some slice of time, which is consistent in itself. In this case, we can say that this is the state of the system that was observed at time 12.Now there is nothing here, because it seems to simulate a situation where Secondary needs to replicate data from Primary. He is waiting ... And now the data has come - returns these values back.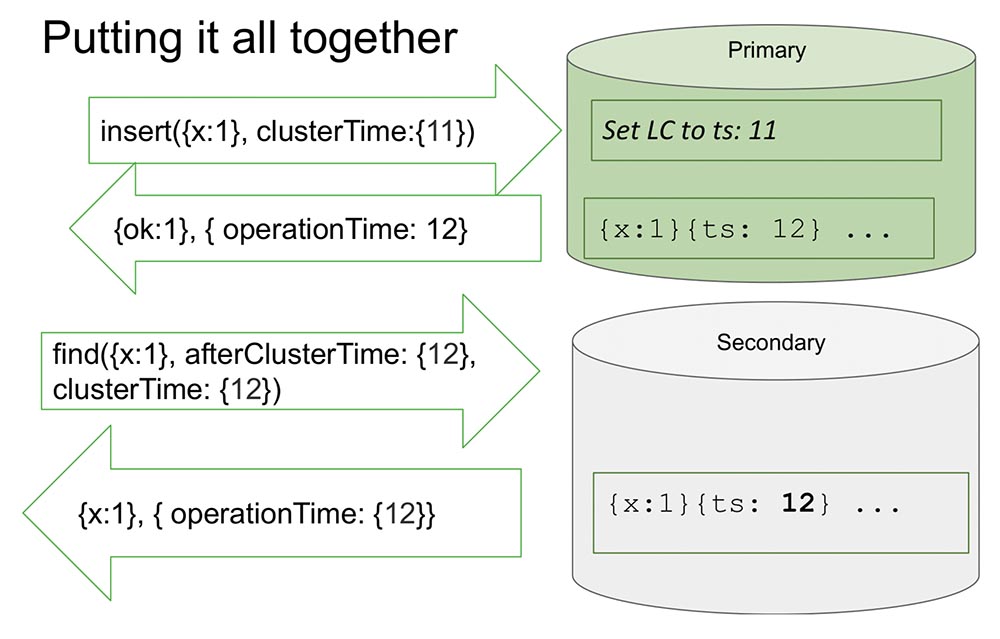 That's how it all works. Almost.What does "almost" mean? Let's assume that there is some person who has read and understood how this all works. I realized that every time ClusterTime occurs, it updates the internal logical clock, and then the next record increases by one. This function takes up 20 lines. Suppose this person transmits the largest possible 64-bit number, minus one.Why is minus one? Because the internal clock is substituted into this value (obviously, this is the largest possible and more than the current time), then there will be an entry in the “Olog”, and the clock will increment by one more - and there will already be a maximum value (there are simply all units, there’s nowhere to go , unsigned ints).It is clear that after this the system becomes completely inaccessible for nothing. It can only be unloaded, cleaned - a lot of manual work. Full availability:
That's how it all works. Almost.What does "almost" mean? Let's assume that there is some person who has read and understood how this all works. I realized that every time ClusterTime occurs, it updates the internal logical clock, and then the next record increases by one. This function takes up 20 lines. Suppose this person transmits the largest possible 64-bit number, minus one.Why is minus one? Because the internal clock is substituted into this value (obviously, this is the largest possible and more than the current time), then there will be an entry in the “Olog”, and the clock will increment by one more - and there will already be a maximum value (there are simply all units, there’s nowhere to go , unsigned ints).It is clear that after this the system becomes completely inaccessible for nothing. It can only be unloaded, cleaned - a lot of manual work. Full availability: Moreover, if this is replicated somewhere else, then the entire cluster simply lies down. An absolutely unacceptable situation that anyone can organize very quickly and simply! Therefore, we considered this moment as one of the most important. How to prevent it?
Moreover, if this is replicated somewhere else, then the entire cluster simply lies down. An absolutely unacceptable situation that anyone can organize very quickly and simply! Therefore, we considered this moment as one of the most important. How to prevent it?Our way is to sign clusterTime
So it is transmitted in the message (before the blue text). But we also began to generate a signature (blue text): The signature is generated by a key that is stored inside the database, inside the protected perimeter; it is generated, updated (users do not see anything). Hash is generated, and each message is signed during creation, and validated upon receipt.Probably, the question arises in people: "How much does it slow down?" I said that it should work quickly, especially in the absence of this feature.What does it mean to use Causal consistency in this case? This will show the afterClusterTime parameter. And without it, it will simply pass values anyway. Gossiping, since version 3.6, always works.If we leave the constant generation of signatures, this will slow down the system even in the absence of features, which does not meet our approaches and requirements. And what have we done?
signature is generated by a key that is stored inside the database, inside the protected perimeter; it is generated, updated (users do not see anything). Hash is generated, and each message is signed during creation, and validated upon receipt.Probably, the question arises in people: "How much does it slow down?" I said that it should work quickly, especially in the absence of this feature.What does it mean to use Causal consistency in this case? This will show the afterClusterTime parameter. And without it, it will simply pass values anyway. Gossiping, since version 3.6, always works.If we leave the constant generation of signatures, this will slow down the system even in the absence of features, which does not meet our approaches and requirements. And what have we done?Do it fast!
A simple enough thing, but the trick is interesting - I’ll share it, maybe someone will be interested.We have a hash that stores signed data. All data goes through the cache. The cache does not specifically sign the time, but Range. When a certain value comes, we generate a Range, mask the last 16 bits, and we sign this value: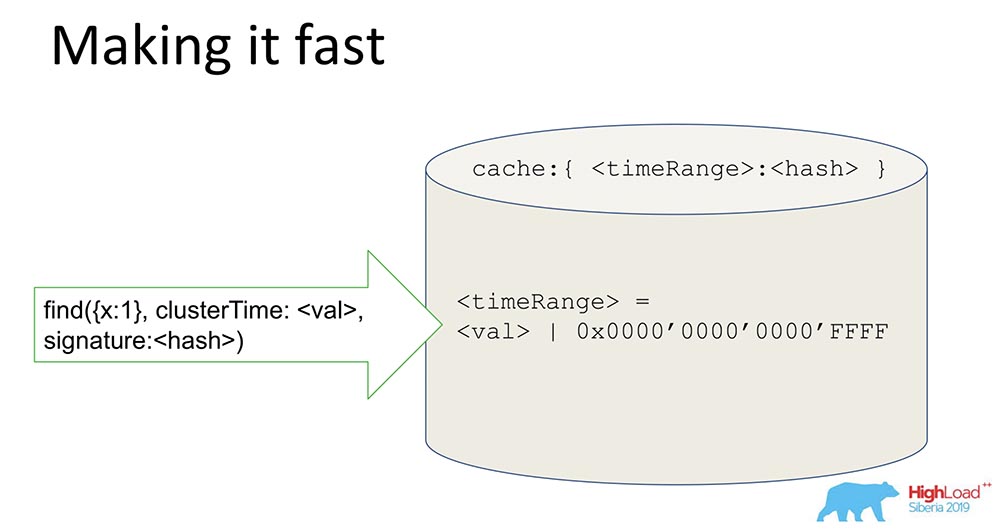 By receiving such a signature, we speed up the system (conditionally) by 65 thousand times. It works great: when they did the experiments, the time when we had a consistent update was really reduced there by 10 thousand times. It is clear that when they are at odds, this does not work. But in most practical cases this works. The combination of the Range signature with the signature resolved the security issue.
By receiving such a signature, we speed up the system (conditionally) by 65 thousand times. It works great: when they did the experiments, the time when we had a consistent update was really reduced there by 10 thousand times. It is clear that when they are at odds, this does not work. But in most practical cases this works. The combination of the Range signature with the signature resolved the security issue.What have we learned?
Lessons we learned from this:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- The last is that we had to consider different ideas and combine several generally different articles into one approach, together. The idea of signing, for example, came from an article that examined the Paxos protocol, which for non-Byzantine Faylor inside the authorization protocol, for the Byzantine ones outside the authorization protocol ... In general, this is exactly what we did in the end.
There is absolutely nothing new here! But as soon as we mixed it all together ... It's like saying that the Olivier salad recipe is nonsense, because eggs, mayonnaise and cucumbers have already come up with ... It's about the same story.
 On this I will end. Thank!
On this I will end. Thank!Questions
Question from the audience (hereinafter - B): - Thank you, Michael for the report! The theme of time is interesting. You are using gossiping. They said that everyone has their own time, everyone knows their local time. As I understand it, we have a driver - there can be many clients with drivers, query-planners too, a lot of shards ... But what is the system going to if we suddenly have a discrepancy: someone decides that he is for a minute ahead, someone - a minute behind? Where will we find ourselves?MT: - Great question really! I just wanted to say about shards. If I understand the question correctly, we have this situation: there is shard 1 and shard 2, reading occurs from these two shards - they have a discrepancy, they do not interact with each other, because the time they know is different, especially the time that They exist in oplogs.Suppose shard 1 made a million records, shard 2 did nothing at all, and the request came in two shards. And the first one has afterClusterTime over a million. In such a situation, as I explained, shard 2 will never respond at all.Q: - I wanted to know how they synchronize and choose one logical time?MT: - Very easy to sync. Shard, when afterClusterTime comes to him, and he does not find the time in the “Catch” - initiates no approved. That is, he raises his hands to this value with his hands. This means that it has no events matching this query. He creates this event artificially and thus becomes the Causal Consistent.Q: - And if after that some other events that were lost somewhere on the network still come to him?MT:- The shard is so arranged that they will not come anymore, since it is a single master. If he has already recorded, then they will not come, but will be after. It can’t happen that somewhere something is stuck, then he will do no write, and then these events arrived - and Causal consistency was violated. When he does no write, they all have to come next (he will wait for them). AT:- I have a few questions regarding the lines. Causal consistency assumes that there is a certain queue of actions that need to be performed. What happens if we lose one package? So the 10th went, the 11th ... the 12th disappeared, and everyone else is waiting for it to be fulfilled. And suddenly our car died, we can’t do anything. Is there a maximum queue length that accumulates before it is executed? What fatal failure occurs when any one state is lost? Moreover, if we write down that there is some kind of state previous, then we should somehow start from it? And they didn’t push from him!MT:- Also a wonderful question! What are we doing? MongoDB has the concept of quorum records, quorum reads. When can a message disappear? When the record is not quorum or when the reading is not quorum (some garbage can also stick).Concerning the Causal consistency, we performed a large experimental test, which resulted in the fact that when the recording and reading are not quorum, Causal consistency violations occur. Exactly what you say!Our tip: Use at least quorum reading when using Causal consistency. In this case, nothing will be lost, even if the quorum record is lost ... This is an orthogonal situation: if the user does not want the data to be lost, you need to use the quorum record. Causal consistency does not guarantee durability. The durability guarantee is provided by replication and machinery associated with replication.Q: - When we create an instance that sharding does for us (not master, but slave, respectively), it relies on the unix time of its own machine or on the time of the “master”; synchronized for the first time or periodically?MT:- Now I’ll make it clear. Shard (i.e., horizontal partition) - there is always Primary. And in a shard there may be a “master” and there may be replicas. But the shard always supports writing, because it must support a certain domain (Primary is in the shard).Q: - That is, everything depends purely on the "master"? Always use the "master" -time?MT: - Yes. It can be figuratively said: the clock is ticking when there is a recording in the "master", in the "Oplog".Q: - We have a client who connects, and he does not need to know anything about time?MT:- In general, you do not need to know anything! If we talk about how it works on the client: at the client, when he wants to use Causal consistency, he needs to open a session. Now everything is there: both transactions in the session and retrieve a rights ... A session is an ordering of logical events occurring with a client.If he opens this session and says there that he wants Causal consistency (if by default the session supports Causal consistency), everything automatically works. The driver remembers this time and increases it when it receives a new message. It remembers which answer returned the previous one from the server that returned the data. The following request will contain afterCluster ("time is greater than this").The client does not need to know absolutely nothing! This is absolutely opaque to him. If people use these features, what can I do? First, you can safely read secondaries: you can write in Primary, and read from geographically replicated secondaries and be sure that it works. At the same time, the sessions that were recorded on Primary can be transferred even to Secondary, that is, you can use not one session, but several.Q: - The topic of Eventual consistency is strongly related to the new Compute science layer - CRDT (Conflict-free Replicated Data Types) data types. Have you considered the integration of these types of data into the database and what can you say about it?MT: - Good question! CRDT makes sense for write conflicts: in MongoDB - single master.AT:- I have a question from the devops. In the real world, there are such Jesuit situations when the Byzantine Failure occurs, and the evil people inside the protected perimeter begin to stick into the protocol, send craft packages in a special way?
AT:- I have a few questions regarding the lines. Causal consistency assumes that there is a certain queue of actions that need to be performed. What happens if we lose one package? So the 10th went, the 11th ... the 12th disappeared, and everyone else is waiting for it to be fulfilled. And suddenly our car died, we can’t do anything. Is there a maximum queue length that accumulates before it is executed? What fatal failure occurs when any one state is lost? Moreover, if we write down that there is some kind of state previous, then we should somehow start from it? And they didn’t push from him!MT:- Also a wonderful question! What are we doing? MongoDB has the concept of quorum records, quorum reads. When can a message disappear? When the record is not quorum or when the reading is not quorum (some garbage can also stick).Concerning the Causal consistency, we performed a large experimental test, which resulted in the fact that when the recording and reading are not quorum, Causal consistency violations occur. Exactly what you say!Our tip: Use at least quorum reading when using Causal consistency. In this case, nothing will be lost, even if the quorum record is lost ... This is an orthogonal situation: if the user does not want the data to be lost, you need to use the quorum record. Causal consistency does not guarantee durability. The durability guarantee is provided by replication and machinery associated with replication.Q: - When we create an instance that sharding does for us (not master, but slave, respectively), it relies on the unix time of its own machine or on the time of the “master”; synchronized for the first time or periodically?MT:- Now I’ll make it clear. Shard (i.e., horizontal partition) - there is always Primary. And in a shard there may be a “master” and there may be replicas. But the shard always supports writing, because it must support a certain domain (Primary is in the shard).Q: - That is, everything depends purely on the "master"? Always use the "master" -time?MT: - Yes. It can be figuratively said: the clock is ticking when there is a recording in the "master", in the "Oplog".Q: - We have a client who connects, and he does not need to know anything about time?MT:- In general, you do not need to know anything! If we talk about how it works on the client: at the client, when he wants to use Causal consistency, he needs to open a session. Now everything is there: both transactions in the session and retrieve a rights ... A session is an ordering of logical events occurring with a client.If he opens this session and says there that he wants Causal consistency (if by default the session supports Causal consistency), everything automatically works. The driver remembers this time and increases it when it receives a new message. It remembers which answer returned the previous one from the server that returned the data. The following request will contain afterCluster ("time is greater than this").The client does not need to know absolutely nothing! This is absolutely opaque to him. If people use these features, what can I do? First, you can safely read secondaries: you can write in Primary, and read from geographically replicated secondaries and be sure that it works. At the same time, the sessions that were recorded on Primary can be transferred even to Secondary, that is, you can use not one session, but several.Q: - The topic of Eventual consistency is strongly related to the new Compute science layer - CRDT (Conflict-free Replicated Data Types) data types. Have you considered the integration of these types of data into the database and what can you say about it?MT: - Good question! CRDT makes sense for write conflicts: in MongoDB - single master.AT:- I have a question from the devops. In the real world, there are such Jesuit situations when the Byzantine Failure occurs, and the evil people inside the protected perimeter begin to stick into the protocol, send craft packages in a special way? MT: - Evil people inside the perimeter are like a Trojan horse! Evil people inside the perimeter can do many bad things.Q: - It is clear that leaving a hole in the server, roughly speaking, through which you can stick the elephant zoo and collapse the entire cluster forever ... It will take time for manual recovery ... This, to put it mildly, is wrong. On the other hand, this is curious: in real life, in practice, there are situations when naturally similar internal attacks occur?MT:- Since I rarely encounter security breachs in real life, I can’t say - maybe they happen. But if we talk about development philosophy, then we think so: we have a perimeter that provides the guys who make security - it's a castle, a wall; and inside the perimeter you can do anything you want. It is clear that there are users with the ability to only look, and there are users with the ability to erase the directory.Depending on the rights, the damage that users can do may be a mouse, or it may be an elephant. It is clear that a user with full rights can do anything at all. A user with not broad rights of harm can cause significantly less. In particular, he cannot break the system.AT:- In the secure perimeter, someone climbed to form unexpected protocols for the server in order to set up the server with cancer, and if you are lucky, then the entire cluster ... Does it ever happen so “well"?MT: - I have never heard of such things. The fact that this way you can fill up the server is not a secret. To fill up inside, being from the protocol, being an authorized user who can write something like that in a message ... Actually, it’s impossible, because anyway it will be verified. It is possible to disable this authentication for users who do not want to - this is then their problem; roughly speaking, they themselves destroyed the walls and you can cram an elephant there, which will trample ... In general, you can dress as a repairman, come and get it!AT:- Thanks for the report. Sergey (Yandex). In “Mong” there is a constant that limits the number of voting members in the Replica Set, and this constant is 7 (seven). Why is this a constant? Why is this not some kind of parameter?MT: - Replica Set we also have 40 nodes. There is always a majority. I don’t know which version ...Q: - In the Replica Set, you can run non-voting members, but voting - a maximum of 7. How, in this case, experience shutdown if we have the Replica Set pulled to 3 data centers? One data center can easily turn off, and another machine fall out.MT: - This is already a bit outside the scope of the report. This is a common question. Maybe then I can tell him.
MT: - Evil people inside the perimeter are like a Trojan horse! Evil people inside the perimeter can do many bad things.Q: - It is clear that leaving a hole in the server, roughly speaking, through which you can stick the elephant zoo and collapse the entire cluster forever ... It will take time for manual recovery ... This, to put it mildly, is wrong. On the other hand, this is curious: in real life, in practice, there are situations when naturally similar internal attacks occur?MT:- Since I rarely encounter security breachs in real life, I can’t say - maybe they happen. But if we talk about development philosophy, then we think so: we have a perimeter that provides the guys who make security - it's a castle, a wall; and inside the perimeter you can do anything you want. It is clear that there are users with the ability to only look, and there are users with the ability to erase the directory.Depending on the rights, the damage that users can do may be a mouse, or it may be an elephant. It is clear that a user with full rights can do anything at all. A user with not broad rights of harm can cause significantly less. In particular, he cannot break the system.AT:- In the secure perimeter, someone climbed to form unexpected protocols for the server in order to set up the server with cancer, and if you are lucky, then the entire cluster ... Does it ever happen so “well"?MT: - I have never heard of such things. The fact that this way you can fill up the server is not a secret. To fill up inside, being from the protocol, being an authorized user who can write something like that in a message ... Actually, it’s impossible, because anyway it will be verified. It is possible to disable this authentication for users who do not want to - this is then their problem; roughly speaking, they themselves destroyed the walls and you can cram an elephant there, which will trample ... In general, you can dress as a repairman, come and get it!AT:- Thanks for the report. Sergey (Yandex). In “Mong” there is a constant that limits the number of voting members in the Replica Set, and this constant is 7 (seven). Why is this a constant? Why is this not some kind of parameter?MT: - Replica Set we also have 40 nodes. There is always a majority. I don’t know which version ...Q: - In the Replica Set, you can run non-voting members, but voting - a maximum of 7. How, in this case, experience shutdown if we have the Replica Set pulled to 3 data centers? One data center can easily turn off, and another machine fall out.MT: - This is already a bit outside the scope of the report. This is a common question. Maybe then I can tell him.
A bit of advertising :)
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, cloud VPS for developers from $ 4.99 , a unique analog of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only we have 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - from $ 99! Read about How to Build Infrastructure Bldg. class c using Dell R730xd E5-2650 v4 servers costing 9,000 euros per penny? Source: https://habr.com/ru/post/undefined/
All Articles