HighLoad ++, Anastasia Tsymbalyuk, Stanislav Tselovalnikov (Sberbank): how we became MDA
The next HighLoad ++ conference will be held on April 6 and 7, 2020 in St. Petersburg.Details and tickets here . HighLoad ++ Siberia 2019. Hall "Krasnoyarsk". June 25, 2 p.m. Abstracts and presentation .Developing an industrial data management and dissemination system from scratch is no easy task. Especially when there is a complete backlog, time for work is a quarter, and product requirements are perpetual turbulence. We will tell on the example of constructing a metadata management system, how to build an industrial scalable system in a short period of time, which includes the storage and dissemination of data.Our approach takes full advantage of metadata, dynamic SQL code, and code generation based on Swagger codegen and handlebars. This solution reduces the development and reconfiguration time of the system, and adding new management objects does not require a single line of new code.We will tell you how it works in our team: what rules we adhere to, what tools we use, what difficulties we encountered and how we heroically overcome them.Anastasia Tsymbalyuk (hereinafter - AC): - My name is Nastya, and this is Stas!Stas Tselovalnikov (hereinafter - SC): - Hello everyone!AC: - Today we will tell you about MDA, and how, using this approach, we reduced development time and introduced the world to an industrial scalable metadata management system. Hooray!SC: - Nastya, what is MDA?AC: - Stas, I think we will smoothly move on to this now. More precisely, I’ll talk about this a little bit at the end of the presentation. Let's talk about us first:
We will tell on the example of constructing a metadata management system, how to build an industrial scalable system in a short period of time, which includes the storage and dissemination of data.Our approach takes full advantage of metadata, dynamic SQL code, and code generation based on Swagger codegen and handlebars. This solution reduces the development and reconfiguration time of the system, and adding new management objects does not require a single line of new code.We will tell you how it works in our team: what rules we adhere to, what tools we use, what difficulties we encountered and how we heroically overcome them.Anastasia Tsymbalyuk (hereinafter - AC): - My name is Nastya, and this is Stas!Stas Tselovalnikov (hereinafter - SC): - Hello everyone!AC: - Today we will tell you about MDA, and how, using this approach, we reduced development time and introduced the world to an industrial scalable metadata management system. Hooray!SC: - Nastya, what is MDA?AC: - Stas, I think we will smoothly move on to this now. More precisely, I’ll talk about this a little bit at the end of the presentation. Let's talk about us first: I can describe myself as a seeker of synergy in industrial IT solutions.SC: - And me?
I can describe myself as a seeker of synergy in industrial IT solutions.SC: - And me?What does the SberData team do?
AC: - And you are just an industrial mastodon, because you brought more than one solution to the prom!SC: - In fact, we work together at Sberbank on the same team and manage SberData metadata: AC: - SberData, if in a simple way, is an analytical platform where all the digital tracks of each client flow. If you are a client of Sberbank, all the information about you flows exactly there. A lot of dataset are stored there, but we understand that the amount of data does not mean their quality. And data without context is sometimes completely useless, because we cannot apply, interpret, protect, enrich it.Just these tasks are solved by metadata. They show us the business context and the technical component of the data, that is, where they appeared, how they were transformed, at what point the minimal description, markup is now. This is already enough to start using the data and trust it. This is precisely the task metadata solves.SC: - In other words, the mission of our team is to increase the efficiency of the Sberbank information analytical platform due to the fact that the information you just talked about should be delivered to the right people at the right time in the right place. And remember, you also said that if data is modern oil, then metadata is a map of the deposits of this oil.AC:- Indeed, this is one of my brilliant statements, which I am very proud of. Technically, this task was reduced to the fact that we had to create a metadata management tool inside our platform and ensure its full life cycle.But in order to plunge into the problems of our subject area and understand what point we are at, I suggest rolling back 9 months ago.So, imagine: outside the window is the month of November, the birds all flew south, we are sad ... And by that time we had a successful pilot with the team, there were customers - we all stayed in the comfort zone until the very point of no return occurred.
AC: - SberData, if in a simple way, is an analytical platform where all the digital tracks of each client flow. If you are a client of Sberbank, all the information about you flows exactly there. A lot of dataset are stored there, but we understand that the amount of data does not mean their quality. And data without context is sometimes completely useless, because we cannot apply, interpret, protect, enrich it.Just these tasks are solved by metadata. They show us the business context and the technical component of the data, that is, where they appeared, how they were transformed, at what point the minimal description, markup is now. This is already enough to start using the data and trust it. This is precisely the task metadata solves.SC: - In other words, the mission of our team is to increase the efficiency of the Sberbank information analytical platform due to the fact that the information you just talked about should be delivered to the right people at the right time in the right place. And remember, you also said that if data is modern oil, then metadata is a map of the deposits of this oil.AC:- Indeed, this is one of my brilliant statements, which I am very proud of. Technically, this task was reduced to the fact that we had to create a metadata management tool inside our platform and ensure its full life cycle.But in order to plunge into the problems of our subject area and understand what point we are at, I suggest rolling back 9 months ago.So, imagine: outside the window is the month of November, the birds all flew south, we are sad ... And by that time we had a successful pilot with the team, there were customers - we all stayed in the comfort zone until the very point of no return occurred.Model Metadata Management System
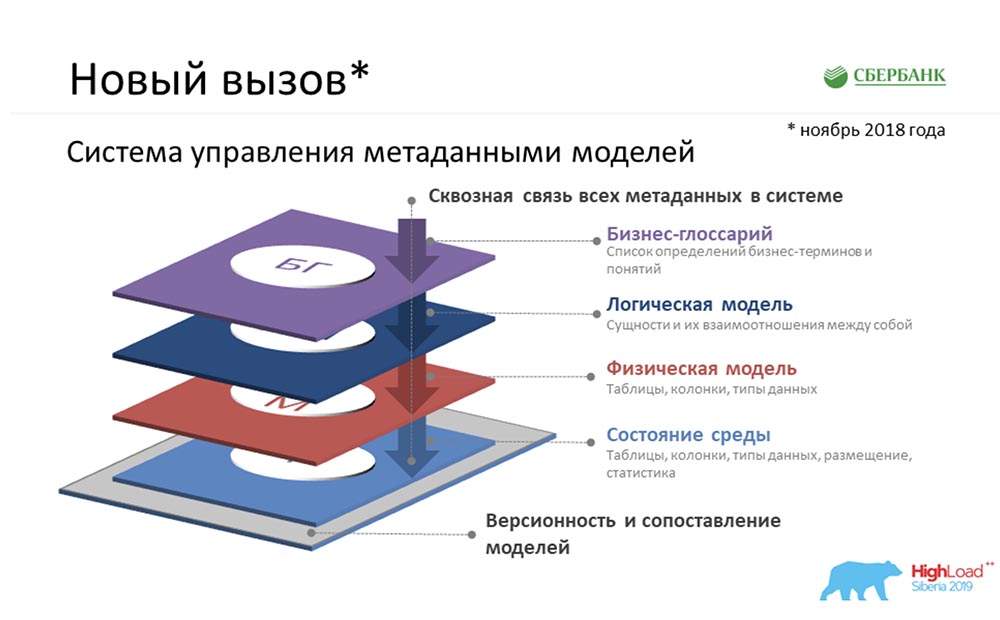 SC: - There was something else you had about being in a comfort zone ... In fact, we were set the task of creating Metadata Broker, which was supposed to give the opportunity to communicate with our customers, programs, systems. Our clients should have had the opportunity at the backend level to either send some kind of metadata package or receive it. And we, providing this function, at our level had to accumulate the most consistent, relevant information on metadata at four logical levels:
SC: - There was something else you had about being in a comfort zone ... In fact, we were set the task of creating Metadata Broker, which was supposed to give the opportunity to communicate with our customers, programs, systems. Our clients should have had the opportunity at the backend level to either send some kind of metadata package or receive it. And we, providing this function, at our level had to accumulate the most consistent, relevant information on metadata at four logical levels:- Business Glossary Level.
- The level of the logical model.
- The level of the physical model.
- The state of the environment that we received due to the reverse of industrial environments.
And all this must be consistent.AC: - Yes, really. But here I would also somehow explain in a simple way, because I do not exclude that the subject area is unclear and incomprehensible ... Abusiness glossary is about what smart people in suits come up with for hours ... how to name a term, how to come up with a formula calculation. They think for a long time, and in the end they have just a business glossary.The logical model is about how the analyst sees himself in the world, who is able to communicate with these smart people in suits and ties, but at the same time understands how it would be possible to land. Far from the details of physical realization.The physical model is about when it is the turn of harsh programmers, architects who really understand how to land these objects - in which table to put, which fields to create, which indexes to hang ... Thestate of the environment is a kind of cast. This is like a testimony from a car. A programmer sometimes wants to tell the machine one thing, but she misunderstands. Just the state of the environment shows us the real state of affairs, and we constantly compare everything; and we understand that there is a difference between what the programmer said and the actual state of the environment.Case for describing metadata
SC: - Let’s explain it with a concrete example. For example, we have four of these designated levels. Suppose we have these serious people in ties who work at the level of a business glossary - they don’t understand at all how and what is arranged inside. But they understand that they need to make a form of mandatory reporting, they need to get, say, the average balance on personal accounts: To this level, a person should already have his own business glossary (terms of mandatory reporting) or have it (average balance on a personal account). Next comes the analyst who understands him perfectly, can speak the same language with him, but he can speak the same language with programmers as well.He says: “Listen, here you have the whole story divided into separate accounts as entities, and they have an attribute - the average balance.”Next comes the architect and says: “We will do this showcase of loans to legal entities. Accordingly, we will make a physical table of personal accounts, we will make a physical table of daily balances on personal accounts (because they are received every day at the closing of the trading day). And once a month on the deadline we will calculate the average (table of monthly balances), as requested. ”No sooner said than done. And then our parser came, who went to the industrial circuit and said: “Yes, I see - there are necessary tables ...” What else enriched this table? Here (as an example) - partitions and indexes, although, strictly speaking, both partitions and indexes could be at the design level of the physical model, but there could be something else (for example, data volume).
To this level, a person should already have his own business glossary (terms of mandatory reporting) or have it (average balance on a personal account). Next comes the analyst who understands him perfectly, can speak the same language with him, but he can speak the same language with programmers as well.He says: “Listen, here you have the whole story divided into separate accounts as entities, and they have an attribute - the average balance.”Next comes the architect and says: “We will do this showcase of loans to legal entities. Accordingly, we will make a physical table of personal accounts, we will make a physical table of daily balances on personal accounts (because they are received every day at the closing of the trading day). And once a month on the deadline we will calculate the average (table of monthly balances), as requested. ”No sooner said than done. And then our parser came, who went to the industrial circuit and said: “Yes, I see - there are necessary tables ...” What else enriched this table? Here (as an example) - partitions and indexes, although, strictly speaking, both partitions and indexes could be at the design level of the physical model, but there could be something else (for example, data volume).Registration and storage at the metadata level
AC: - How is everything stored with us? This is a super-simplified form of the example that Stas painted earlier! How will all this lie with us?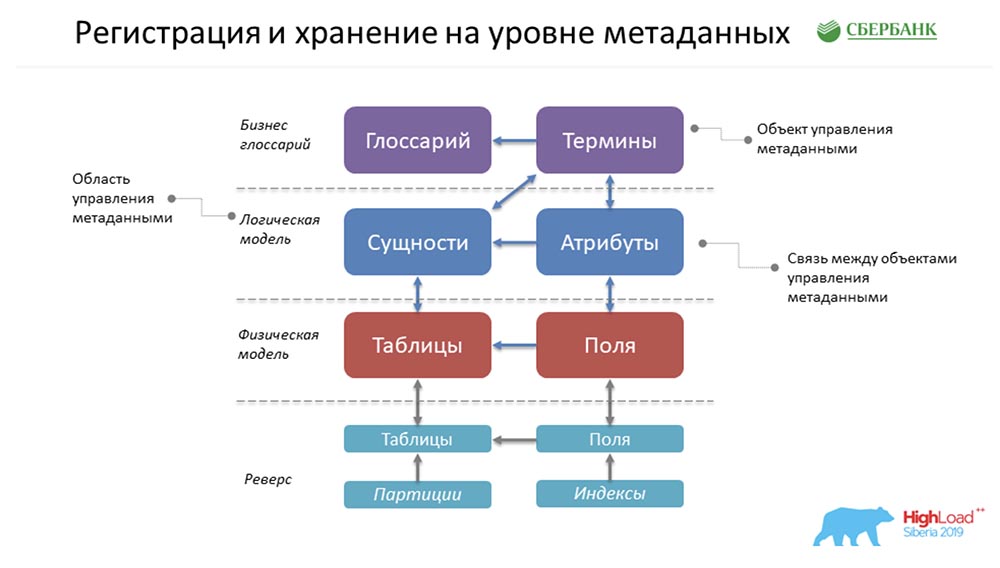 In fact, it will be one line in the Glossary object, one in the Terms object, one in the Entities, one in the Attributes, and so on. In the figure above, each rectangle is an object in our control system, which represents this or that information stored there.In order to slowly introduce you to terminology, I ask you to note the following ... What is a metadata management object? Physically, this is presented in the form of a table, but in fact, certain information is stored there on terms, glossaries, entities, attributes, etc. This term, “object,” we will continue to use in our presentation.SC: - Here it must be said that each cube is just a table in our system where we store metadata, and we call this the control object.
In fact, it will be one line in the Glossary object, one in the Terms object, one in the Entities, one in the Attributes, and so on. In the figure above, each rectangle is an object in our control system, which represents this or that information stored there.In order to slowly introduce you to terminology, I ask you to note the following ... What is a metadata management object? Physically, this is presented in the form of a table, but in fact, certain information is stored there on terms, glossaries, entities, attributes, etc. This term, “object,” we will continue to use in our presentation.SC: - Here it must be said that each cube is just a table in our system where we store metadata, and we call this the control object.Metadata requirements
What did we have at the entrance? At the entrance we received quite interesting requirements. There were a lot of them, but here we want to show three main ones: The first requirement is quite classical. We are told: "Guys, everything that has come to you once has to come forever." Historization is complete, and any change in your metadata system that has come to you (it doesn’t matter if a packet of 100 fields has arrived (100 changes) or one field has changed in one table) requires a new registration of the metadata. They also require a response to be returned:
The first requirement is quite classical. We are told: "Guys, everything that has come to you once has to come forever." Historization is complete, and any change in your metadata system that has come to you (it doesn’t matter if a packet of 100 fields has arrived (100 changes) or one field has changed in one table) requires a new registration of the metadata. They also require a response to be returned:- by default - current state;
- by date;
- by revision number.
The second requirement was more interesting: we were told that they can work with us on objects, but they have to program a lot in Java, but they don’t want to. They suggested that we mix 100 objects (or 10) at once, and we should handle this business (because we can). What does the mixing mean? For example, 10 columns came. They have a link to the table identifier, but we don’t have the table itself - it came at the tail of JSON. "You think up and process - it is necessary that you can"!In order of increasing interest - the third: “We want to be able to not only use the API that you will make us, but want to understand ourselves ...” And in an arbitrary order say: “Give us the union from this object to that through the third object. And let your system itself understand how to do it all, ask the database and return the result in JSON. ”We had such a story at the entrance.Estimated Estimates
 AC: - According to our approximate calculations, in order to implement this whole concept, each control object needed to participate in seven interfaces: simple (simplic), for object-wide write / read and delete ...Three more - for universal write / read / delete, t That is, that we can throw it all in any order and how to transfer the soup set to the system, and she will figure out in what order to delete, put, read.One more thing - to build a hierarchy so that we can indicate to the system - “Give us back from object to object”; and it returns a tree of nested objects.
AC: - According to our approximate calculations, in order to implement this whole concept, each control object needed to participate in seven interfaces: simple (simplic), for object-wide write / read and delete ...Three more - for universal write / read / delete, t That is, that we can throw it all in any order and how to transfer the soup set to the system, and she will figure out in what order to delete, put, read.One more thing - to build a hierarchy so that we can indicate to the system - “Give us back from object to object”; and it returns a tree of nested objects.Implementation complexity
SC: - In addition to the technical requirements that came to us at the time of the start of this story, we had additional difficulties. Firstly, this is some uncertainty of requirements. Not every team could not always clearly articulate what they need from the service, and often the moment of truth was born at the moment of prototyping some story on the def circuit. And while it reached prom, there could be several cycles.AC: - This is the very turbulence that was announced at the beginning.SC: - Next ...There was a prohibitive deadline, because even at the time of launch more than five teams depended on us. Classics of the genre: the result was needed yesterday. The work option is in scalded horse mode, which is what we did.The third is a large amount of development. Nastya on her slide showed that when we looked at the requirements of what and how to do, we realized: 1 object requires seven APIs (either for it, or participation in seven APIs). This means that if we have a patch (6 objects, model, 42 API) goes in a week ...
Firstly, this is some uncertainty of requirements. Not every team could not always clearly articulate what they need from the service, and often the moment of truth was born at the moment of prototyping some story on the def circuit. And while it reached prom, there could be several cycles.AC: - This is the very turbulence that was announced at the beginning.SC: - Next ...There was a prohibitive deadline, because even at the time of launch more than five teams depended on us. Classics of the genre: the result was needed yesterday. The work option is in scalded horse mode, which is what we did.The third is a large amount of development. Nastya on her slide showed that when we looked at the requirements of what and how to do, we realized: 1 object requires seven APIs (either for it, or participation in seven APIs). This means that if we have a patch (6 objects, model, 42 API) goes in a week ...Standard approach
AC: - Yes, actually 42 APIs per week is just the tip of the iceberg. We are well aware that in order to ensure that these 42 APIs work, we need:- firstly, create a storage structure for the object;
- secondly, to ensure the logic of its processing;
- thirdly, write the very API in which the object participates (or is configured specifically for it);
- fourthly, it would be nice to ideally cover all of this with the contours of testing, test and say that everything is fine;
- fifthly (the same cherry on the cake), to document this whole story.
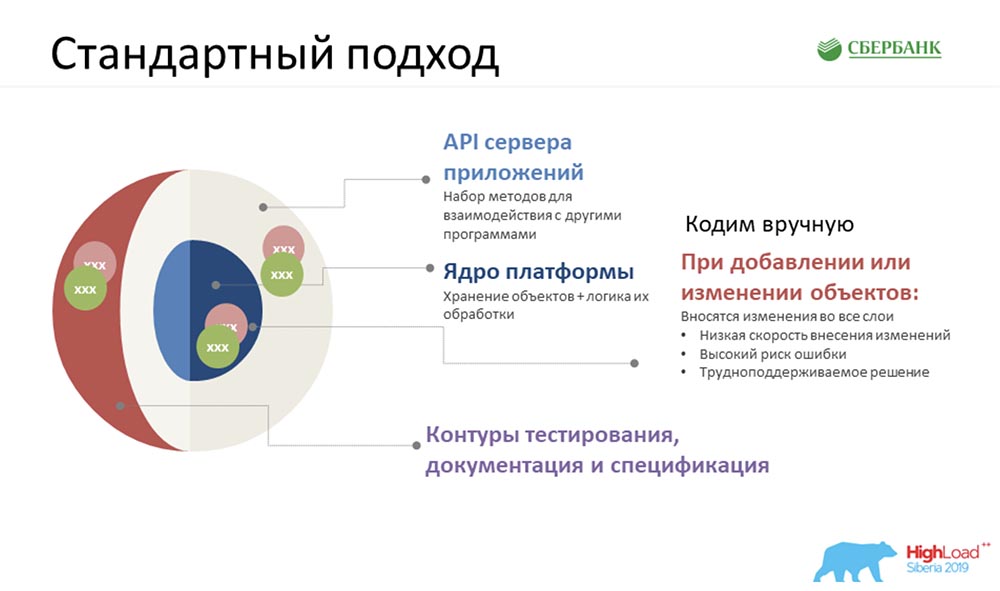 Naturally, the first thing that occurred to us (at the start we showed you an approximate diagram) - we had about 35 objects. Something had to be done with them, all this had to be deduced, and there was very little time. And the first idea that occurred to us was to sit down, roll up our sleeves and start coding.Even after working in this mode for a couple of days (we had three teams), we reached such a glowing temperature ... Everyone was nervous ... And we realized that we needed to look for a different approach.
Naturally, the first thing that occurred to us (at the start we showed you an approximate diagram) - we had about 35 objects. Something had to be done with them, all this had to be deduced, and there was very little time. And the first idea that occurred to us was to sit down, roll up our sleeves and start coding.Even after working in this mode for a couple of days (we had three teams), we reached such a glowing temperature ... Everyone was nervous ... And we realized that we needed to look for a different approach.Custom approach
We began to pay attention to what we are doing. The idea of this approach has always been before our eyes, because we have been engaged in metadata for a very long time. Somehow, right away, it didn’t occur to us ...As you might guess, the essence of this idea is to use metadata. It consists in the fact that we collect the structure of our repository (this is certain metadata), once we create a template for some code (for example, several APIs or procedures for processing logic, scripts for creating structures). Once we create this template, and then run through all the metadata. By tags, properties are substituted into the code (object names, fields, important characteristics), and the resulting code is ready. That is, it is enough to get confused once - create a template, and then use all this information for both existing and new objects. Here we introduce another concept - #META_META. I will explain why, so as not to confuse you.Our system is engaged in metadata management, and the approach that we use describes a metadata management system, i.e. two metas. “MetaMeta” - we called it at home, inside the team. In order not to confuse the others further, we will use this very term.
That is, it is enough to get confused once - create a template, and then use all this information for both existing and new objects. Here we introduce another concept - #META_META. I will explain why, so as not to confuse you.Our system is engaged in metadata management, and the approach that we use describes a metadata management system, i.e. two metas. “MetaMeta” - we called it at home, inside the team. In order not to confuse the others further, we will use this very term.Mechanism for ensuring historization and revision
SC: - You summarized the rest of our speech. We will tell in more detail.I must say that when we were preparing for the speech, we were asked to give technical information that could be of interest to colleagues. We will do it. Further, the slides will go more technical - perhaps someone will see something interesting for themselves.First, how we solved the issue of historization and revision. Perhaps this is similar to how many do. Consider this using metadata as an example, which describe a single field in the posting table (as an example):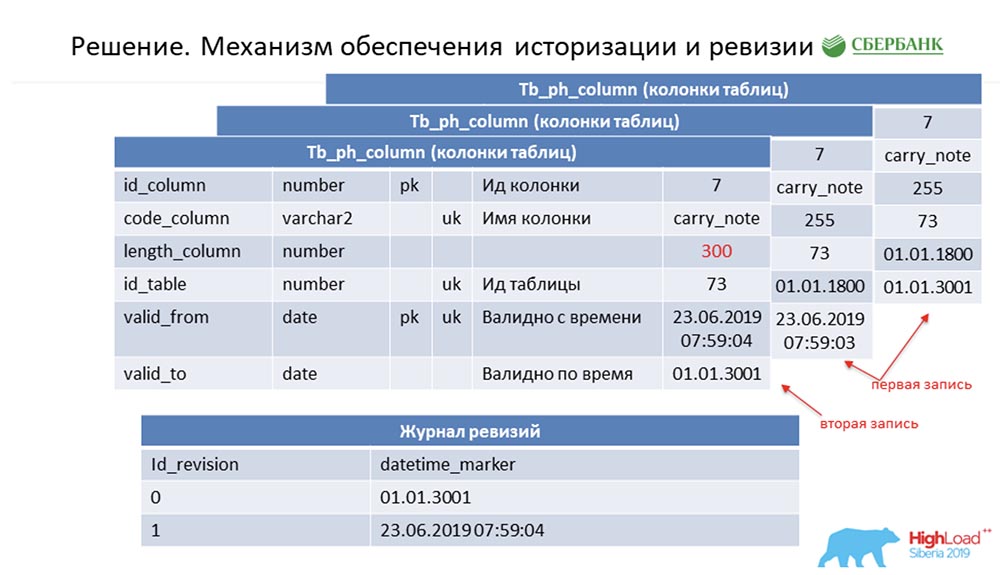 It has an id - "7", a name - carry_note, a link id_table 73, and a field - 255. We enter in the primary and alternative key a field (of type date) from the time point from which this entry becomes valid - valid_from. And one more field - by what date this record is valid (valid_to). In this case, they are filled by default - it is clear that this entry is always valid in principle. And this happens until we want to change, say, the length of the field.As soon as we want to do this, we close the valid_to record (we fix the timestamp at which the event occurred). At the same time, we make a new record ("300"). It is easy to notice that in this situation, if you look at the database from some time point by the “battle” (between) between valid_from and valid_to, then we will get a single record, but relevant at that time. And at the same time, we simultaneously kept some revision log:
It has an id - "7", a name - carry_note, a link id_table 73, and a field - 255. We enter in the primary and alternative key a field (of type date) from the time point from which this entry becomes valid - valid_from. And one more field - by what date this record is valid (valid_to). In this case, they are filled by default - it is clear that this entry is always valid in principle. And this happens until we want to change, say, the length of the field.As soon as we want to do this, we close the valid_to record (we fix the timestamp at which the event occurred). At the same time, we make a new record ("300"). It is easy to notice that in this situation, if you look at the database from some time point by the “battle” (between) between valid_from and valid_to, then we will get a single record, but relevant at that time. And at the same time, we simultaneously kept some revision log: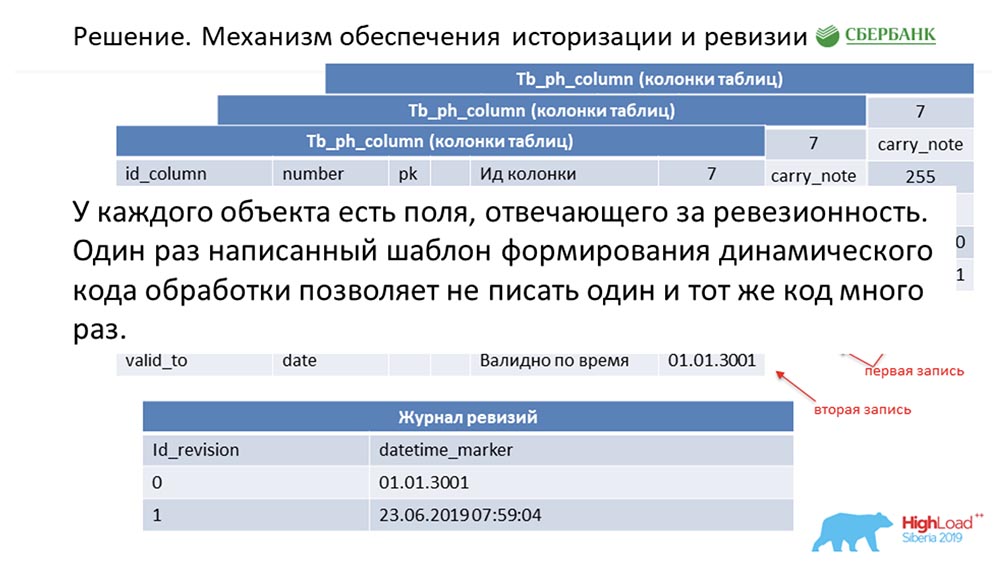 In it we recorded revisions that are increasing in sequence (sequence) id, and the time point that corresponds to this revision id. So we were able to close the first demand.AC:- I guess, yes! Here the approach is the same. We understand that each object in the system has these two required fields, and once we got confused - encoded the processing logic of this template, and then (when generating the dynamic code) we simply substitute the names of the corresponding objects. So every object in our system becomes revision, and all this can be processed - we generally do not write a single line of code.
In it we recorded revisions that are increasing in sequence (sequence) id, and the time point that corresponds to this revision id. So we were able to close the first demand.AC:- I guess, yes! Here the approach is the same. We understand that each object in the system has these two required fields, and once we got confused - encoded the processing logic of this template, and then (when generating the dynamic code) we simply substitute the names of the corresponding objects. So every object in our system becomes revision, and all this can be processed - we generally do not write a single line of code.Batch update
SC: - The second requirement for me was a little more interesting. Honestly, when it came to the entrance, at first I just got into a stupor. But the decision has come!I remind you, this is the same case when, let's say, JSON with a packet came to us for the nth number of objects that need to be inserted into the system. At the same time, at the beginning we have 10 columns referring to a nonexistent table, and the table went in the JSON tail. What to do? We found a way out in using the mechanism of recursive hierarchical queries - this is for sure the well-known connect by prior construction. We did it as follows: here is a fragment of our production code:
We found a way out in using the mechanism of recursive hierarchical queries - this is for sure the well-known connect by prior construction. We did it as follows: here is a fragment of our production code: At this point (a section of code circled in a red oval) is the main point that gives an idea. And here the object is linked to another object linked by a foreign key, which is in the system.To understand: if someone writes code in Oracle, there are All_columns, All_all_ tables, All_constraint tables - this is the dictionary that is processed by the scripts (like the ones shown on the slide above).At the output, we get fields that give us the priority of processing objects, and additionally give a descriptor - it is essentially a unique string identifier for any metadata record. The code by which the descriptor is received is also indicated on the slide above.For example, a field - what could it look like? This is the platform code: oracle KP., Production. KP, my_scheme. KP, my_table. KP, etc., where KP is the field code. So there will be such a descriptor.AC: - What are the issues here? We have objects in the system and the order of their insertion is very important for us. For example, we cannot insert columns in front of tables, because a column must refer to a specific table. As we do as standard: first we insert the tables, in response we get an id array, by these IDs we throw the columns and do the second insert operation.In reality, as Stas showed, the length of this chain reaches 8-9 objects. The user, using the standard approach, needs to perform all these operations in turn (all these 9 operations) and clearly understand their order so that no error occurs.As far as I correctly interpret Stas, we can transfer all these objects to the system in any order and don’t bother about how we need to make this insertion - we just threw a soup set into the system, and it all determined in which order to insert.The only thing I have is the question: what if we insert the object for the first time? We inserted the table before, we don’t know its id. How do we indicate (a purely hypothetical example) that we need to insert two tables, each of which has a column? How do we indicate that in this JSON column refers to table1, not table2?SC: - A descriptor! The handle that we indicated on that slide (previous).And on this slide, the very solution is given:
At this point (a section of code circled in a red oval) is the main point that gives an idea. And here the object is linked to another object linked by a foreign key, which is in the system.To understand: if someone writes code in Oracle, there are All_columns, All_all_ tables, All_constraint tables - this is the dictionary that is processed by the scripts (like the ones shown on the slide above).At the output, we get fields that give us the priority of processing objects, and additionally give a descriptor - it is essentially a unique string identifier for any metadata record. The code by which the descriptor is received is also indicated on the slide above.For example, a field - what could it look like? This is the platform code: oracle KP., Production. KP, my_scheme. KP, my_table. KP, etc., where KP is the field code. So there will be such a descriptor.AC: - What are the issues here? We have objects in the system and the order of their insertion is very important for us. For example, we cannot insert columns in front of tables, because a column must refer to a specific table. As we do as standard: first we insert the tables, in response we get an id array, by these IDs we throw the columns and do the second insert operation.In reality, as Stas showed, the length of this chain reaches 8-9 objects. The user, using the standard approach, needs to perform all these operations in turn (all these 9 operations) and clearly understand their order so that no error occurs.As far as I correctly interpret Stas, we can transfer all these objects to the system in any order and don’t bother about how we need to make this insertion - we just threw a soup set into the system, and it all determined in which order to insert.The only thing I have is the question: what if we insert the object for the first time? We inserted the table before, we don’t know its id. How do we indicate (a purely hypothetical example) that we need to insert two tables, each of which has a column? How do we indicate that in this JSON column refers to table1, not table2?SC: - A descriptor! The handle that we indicated on that slide (previous).And on this slide, the very solution is given: The descriptors are used in the system as a kind of mnemonic field that does not exist, but replaces id. At that moment, when at first the system understands that it is necessary to insert the table - insert, it will receive id; and already at the stage of generating the SQL query for the insert and column, it will operate on id. The user can not take a steam bath: “Give the handle and execute!”. The system will do.
The descriptors are used in the system as a kind of mnemonic field that does not exist, but replaces id. At that moment, when at first the system understands that it is necessary to insert the table - insert, it will receive id; and already at the stage of generating the SQL query for the insert and column, it will operate on id. The user can not take a steam bath: “Give the handle and execute!”. The system will do.Universal query on a group of related objects
Perhaps my favorite case. This is the favorite technical requirement we had. They came to us and said: “Guys, do it so that the system can do everything! From object to object, please. Guess how it all joins among themselves. Give us back, JSON, please. We don’t want to program a lot using your service ”...Question:“ How ?! ”We actually went the same way. Exactly the same construction: It was used to solve this problem. The only difference is that there was a valid filter, which unwound this hierarchical tree only for those stories where a descriptor was required. Relatively speaking, it was unique for each object. Here, all possible connections in the system are untwisted (we have about 50 objects).All possible connections between objects are prepared in advance. If we have an object involved in three relationships, respectively, three lines will be prepared so that the algorithm can understand. And as soon as the JSON request arrives to us, we go to the place where this story was prepared in advance in MeteMet, we are looking for the way we need. If we don’t find, this is one story, if we find it, we form a query in the database. Running - returning JSON (as requested).AC: - As a result, we can transfer to the system which object we want to receive from. And if you can outline a clear connection between two objects, then the system itself will figure out what level of nesting the object will return to you in the tree:It is very flexible! Once again, our users are in a state of “turbulence”: today they need one thing, tomorrow they need another. And this solution allows us to adapt the structure very flexibly. These were three key cases that were used on our core side.SC: - Let's summarize some. It’s clear that now we won’t tell all the chips because of the limited time. Three cases, in our opinion, we carried out and told. We succeeded, we were able to put all the most complex logic, and the one that should work uniformly for each metadata management object, into the kernel code.We could not make this code 100% dynamic, which means that with any created objects (it doesn’t matter if they were already created or which will be created later; the main thing is to be created according to the rules), the system can work - nothing needs to be added, rewritten. Just testing is enough. We parked this whole story into three universal methods. In my opinion, there are enough of them to solve almost any business problem:
It was used to solve this problem. The only difference is that there was a valid filter, which unwound this hierarchical tree only for those stories where a descriptor was required. Relatively speaking, it was unique for each object. Here, all possible connections in the system are untwisted (we have about 50 objects).All possible connections between objects are prepared in advance. If we have an object involved in three relationships, respectively, three lines will be prepared so that the algorithm can understand. And as soon as the JSON request arrives to us, we go to the place where this story was prepared in advance in MeteMet, we are looking for the way we need. If we don’t find, this is one story, if we find it, we form a query in the database. Running - returning JSON (as requested).AC: - As a result, we can transfer to the system which object we want to receive from. And if you can outline a clear connection between two objects, then the system itself will figure out what level of nesting the object will return to you in the tree:It is very flexible! Once again, our users are in a state of “turbulence”: today they need one thing, tomorrow they need another. And this solution allows us to adapt the structure very flexibly. These were three key cases that were used on our core side.SC: - Let's summarize some. It’s clear that now we won’t tell all the chips because of the limited time. Three cases, in our opinion, we carried out and told. We succeeded, we were able to put all the most complex logic, and the one that should work uniformly for each metadata management object, into the kernel code.We could not make this code 100% dynamic, which means that with any created objects (it doesn’t matter if they were already created or which will be created later; the main thing is to be created according to the rules), the system can work - nothing needs to be added, rewritten. Just testing is enough. We parked this whole story into three universal methods. In my opinion, there are enough of them to solve almost any business problem:- firstly, this same universal “updater” is a method that can do update / insert / delete (delete is closing a record) on one or a group of objects transferred in random order.
- the second is a method that can return universal information on only one object;
- the third is the same method that can return Join information connected by groups of objects.
That's how it turned out, and we made the core. And then we'll move on to your favorite part.Application Entry Point
AC: - Yes, this is my favorite part, because this is my area of responsibility - Application Server. To understand what situation I was in, I will try to plunge you into a problem again.Stas did a good job and passed me these three standard methods that manipulated these objects. This is a purely sketchy description - in reality there are many more: Let's go back to the very beginning to immerse you ... How will the metadata in the system be presented here?
Let's go back to the very beginning to immerse you ... How will the metadata in the system be presented here?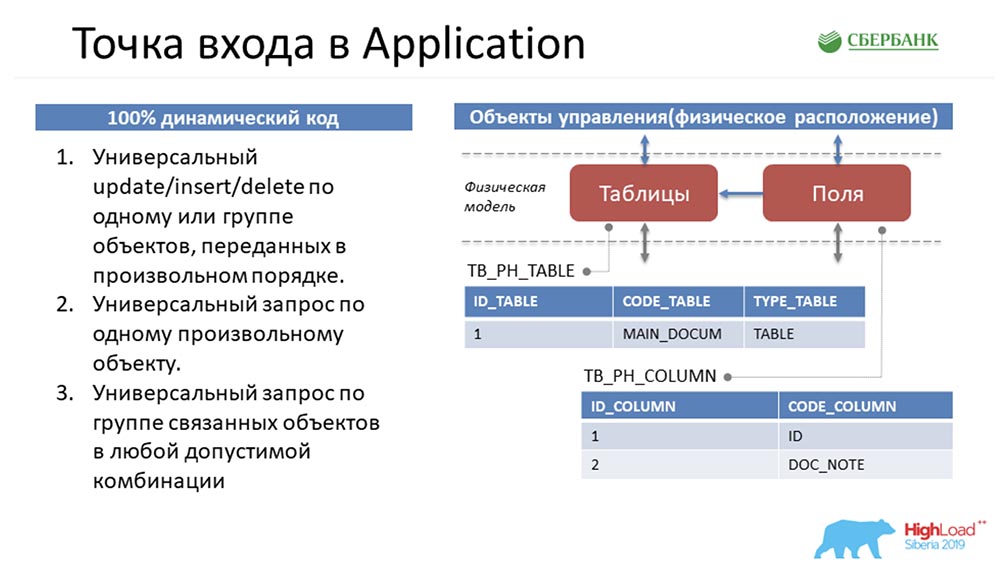 If we see that there is a table in the environment, it will fall into our system as one record in the table object and a couple of records in the field object. Essentially, we have put together a structure.We can notice that the quantity of these objects is different. Then, to manipulate these objects, to bring everything to a universal structure, so that all three methods understand what is being discussed, Stas makes a move with the horse. It takes, and flips all objects, that is, it represents any object in our metadata management system as four lines:
If we see that there is a table in the environment, it will fall into our system as one record in the table object and a couple of records in the field object. Essentially, we have put together a structure.We can notice that the quantity of these objects is different. Then, to manipulate these objects, to bring everything to a universal structure, so that all three methods understand what is being discussed, Stas makes a move with the horse. It takes, and flips all objects, that is, it represents any object in our metadata management system as four lines: Since any object in our metadata management system is physically a table, any object can be decomposed according to these four signs: line number , table, field and field value. It was Stas who came up with all this, and I needed to somehow implement it and give it to users.SC:- Sorry, but how can I convey to you in a flat answer columns, for example, which have not yet been created, will be created sometime, and God knows what they can be? .. Therefore, the only option in the conditions of dynamic code is to configure the interaction between core and application, to transmit this information to you - only as we see it. I believe that from my point of view this decision was ingenious, because it came just from you.AC: - Now we will not argue about this. Two weeks before the end of the deadline, I stayed with the fact that I had these three methods on my hands (on the left on the previous slide) that manipulated the universal structure (on the right on the same slide).My first thought was to simply wrap everything up at the API level and go to the user with this, saying: “Look, what a brilliant thing! You can do anything! Transfer any objects, or even nonexistent ones. Cool, yeah"?!
Since any object in our metadata management system is physically a table, any object can be decomposed according to these four signs: line number , table, field and field value. It was Stas who came up with all this, and I needed to somehow implement it and give it to users.SC:- Sorry, but how can I convey to you in a flat answer columns, for example, which have not yet been created, will be created sometime, and God knows what they can be? .. Therefore, the only option in the conditions of dynamic code is to configure the interaction between core and application, to transmit this information to you - only as we see it. I believe that from my point of view this decision was ingenious, because it came just from you.AC: - Now we will not argue about this. Two weeks before the end of the deadline, I stayed with the fact that I had these three methods on my hands (on the left on the previous slide) that manipulated the universal structure (on the right on the same slide).My first thought was to simply wrap everything up at the API level and go to the user with this, saying: “Look, what a brilliant thing! You can do anything! Transfer any objects, or even nonexistent ones. Cool, yeah"?! And they say: “But you understand that your service is not at all specialized? As a user, I don’t understand what objects I can transfer to the system, how I can manipulate them ... For me it is a black box, I’m generally afraid that I’ll submit data; I can be mistaken - I am scared. Make it so that I can clearly follow the instructions and see what objects are in the system and what methods of manipulation I can use. ”
And they say: “But you understand that your service is not at all specialized? As a user, I don’t understand what objects I can transfer to the system, how I can manipulate them ... For me it is a black box, I’m generally afraid that I’ll submit data; I can be mistaken - I am scared. Make it so that I can clearly follow the instructions and see what objects are in the system and what methods of manipulation I can use. ”Speck. An approach
Then it became clear to us that it was cool to make a spec for our service. In short, to make a list of objects of our system, a list of points, manipulations and what objects they juggle with each other. It so happened that in our company we use Swagger for these purposes as some kind of architectural solution. Having looked at the Swagger structure, I realized that I need to take somewhere the structure of objects that are in the system. From the kernel, I received only three standard methods and a table changer. Nothing else. For me then it seemed an impossible task to get the whole structure that is in the repository from these four standard fields. I sincerely did not understand where to get me all the descriptions of objects, all the permissible values, all the logic ...SC:- What does it mean where? You and I have MetaMeta, which provides the kernel in real-time mode. The kernel in real-time execution generates an SQL query that communicates with the database. Everything is there, not just what you need. There are also links between objects.AC: - On the advice of Stas, then I went to MetaMetu and was surprised, because all the necessary gentleman's kit for generating standard specs was present there. Then the idea came up that you need to create a template and paint everything according to seven possible scenarios - 7 standard APIs for each object.
Having looked at the Swagger structure, I realized that I need to take somewhere the structure of objects that are in the system. From the kernel, I received only three standard methods and a table changer. Nothing else. For me then it seemed an impossible task to get the whole structure that is in the repository from these four standard fields. I sincerely did not understand where to get me all the descriptions of objects, all the permissible values, all the logic ...SC:- What does it mean where? You and I have MetaMeta, which provides the kernel in real-time mode. The kernel in real-time execution generates an SQL query that communicates with the database. Everything is there, not just what you need. There are also links between objects.AC: - On the advice of Stas, then I went to MetaMetu and was surprised, because all the necessary gentleman's kit for generating standard specs was present there. Then the idea came up that you need to create a template and paint everything according to seven possible scenarios - 7 standard APIs for each object.Speck. OAS + Handlebars
So, it’s easy to notice what the spec consists of: You can go to the OAS website and Handlebars (at the bottom of the slide) and see what it should consist of - there is a set of Endpoints, a set of methods, and at the end there are models. The code is repeated from time to time. For each object, we must write get, put. delete; for a group of objects, we must write this and so on.The trick was to write the whole story once and no longer bathe. The slide shows an example of real code. Blue objects are tags in Handlebars, this is a template engine; quite flexible, I advise everyone - you can customize it for yourself, write custom tag handlers ...In place of these blue tags, when this template is run over all-all metadata, all significant properties are substituted - the name of the object, its description, some kind of logic (for example, that we need to add an additional parameter, depending on the property) and so on. At the end is a link to the model that he is interpreting.
You can go to the OAS website and Handlebars (at the bottom of the slide) and see what it should consist of - there is a set of Endpoints, a set of methods, and at the end there are models. The code is repeated from time to time. For each object, we must write get, put. delete; for a group of objects, we must write this and so on.The trick was to write the whole story once and no longer bathe. The slide shows an example of real code. Blue objects are tags in Handlebars, this is a template engine; quite flexible, I advise everyone - you can customize it for yourself, write custom tag handlers ...In place of these blue tags, when this template is run over all-all metadata, all significant properties are substituted - the name of the object, its description, some kind of logic (for example, that we need to add an additional parameter, depending on the property) and so on. At the end is a link to the model that he is interpreting.Application code. Swagger Codegen + Handlebars
All of this we encoded, recorded, made up a spec. Everything was very cool and good. We got all 7 possible scenarios for each object.Gave it to the user. He said: “Wow! Cool! Now we want to use it! ” What is the problem, again?We have a spec that describes each method in detail, what to do with it, what objects to manipulate. And there are three standard kernel methods that take the inverted table described above as input.Then you just had to cross one with the other (now it seems easy to me). That is, when a user calls a method in the interface, we had to correctly and correctly forward it to the kernel, turning the model (where we have beautiful specifications) into these four standard fields. That was all that had to be done. In order to put all this into practice, we needed “nominative” transformations ...
In order to put all this into practice, we needed “nominative” transformations ...Conversions
Swagger initially has such a tool - Swagger Codegen. If you ever went into specs, made up, then there is a button “Generate server part”. Click, choose a language - a finished project is generated for you.It is generated remarkably: there are all class descriptions, all endpoint descriptions ... - it works. You can run it locally - it will work. The trouble is one: it returns stubs - each method is not incremented.The idea was to add logic based on these seven scenarios in the code generator - “spoil” one of the standard templates, configure it for yourself. Here is just an example of real code that we use in the template engine and a list of the actions that we needed to perform in order to configure this code generator for ourselves: The most important thing that they did was to connect the necessary libraries, write classes for communicating with the kernel, and interpret (depending on the scenario) the call of one or more methods on the kernel side. The model was also turned over: from the beautiful one indicated in the spec to four fields, and then transformed back.Probably the most difficult case here was to give the user a tree, because the kernel also returns four lines to us - go and see what level the hierarchy is on. We used the mechanism of external relations, which is in the IDE, that is, we went to MetaMetu, looked at all the paths from one to another and dynamically generate a tree through them. The user can ask us from any object for whatever he wants - a beautiful tree will be returned to him at the exit, in which everything is already structurally laid out.SC: - I will stop you for a second, because I am already starting to get lost. I’ll ask you in the style of “Do I understand that correctly” ...You want to say that we have calculated all the most complicated, most complex code that would have to be written for some new object. And in order to save time, not to do it, we managed to shove it all into the kernel and make this story dynamic ... But this API (as they joked, “stubborn”) is so “can do anything” that it’s scary to give it to the outside: with it, you can corrupt metadata. This is on the one hand.On the other hand, we realized that we cannot communicate with our customer clients unless we give them an API, which will be a unique projection of those metadata management objects that are embedded in the system (in fact, execute a certain contract for our service). It would seem that everything - we hit: if there is no object - it is not there, and when it appears - the contract extension appears, a new code.We seem to have got into avoidable manual coding, but here you propose to do this code by button. Again, we manage to get away from history when we need to write something with our hands. This is true?AC: - Yes, it really is. In general, my idea was to start programming once and for all, at least with the help of template engines. Write the code once, and then relax. And even if a new object appears in the system - by the button we start the update, everything is tightened, we have a new structure, new methods are generated, everything is fine and fine.
The most important thing that they did was to connect the necessary libraries, write classes for communicating with the kernel, and interpret (depending on the scenario) the call of one or more methods on the kernel side. The model was also turned over: from the beautiful one indicated in the spec to four fields, and then transformed back.Probably the most difficult case here was to give the user a tree, because the kernel also returns four lines to us - go and see what level the hierarchy is on. We used the mechanism of external relations, which is in the IDE, that is, we went to MetaMetu, looked at all the paths from one to another and dynamically generate a tree through them. The user can ask us from any object for whatever he wants - a beautiful tree will be returned to him at the exit, in which everything is already structurally laid out.SC: - I will stop you for a second, because I am already starting to get lost. I’ll ask you in the style of “Do I understand that correctly” ...You want to say that we have calculated all the most complicated, most complex code that would have to be written for some new object. And in order to save time, not to do it, we managed to shove it all into the kernel and make this story dynamic ... But this API (as they joked, “stubborn”) is so “can do anything” that it’s scary to give it to the outside: with it, you can corrupt metadata. This is on the one hand.On the other hand, we realized that we cannot communicate with our customer clients unless we give them an API, which will be a unique projection of those metadata management objects that are embedded in the system (in fact, execute a certain contract for our service). It would seem that everything - we hit: if there is no object - it is not there, and when it appears - the contract extension appears, a new code.We seem to have got into avoidable manual coding, but here you propose to do this code by button. Again, we manage to get away from history when we need to write something with our hands. This is true?AC: - Yes, it really is. In general, my idea was to start programming once and for all, at least with the help of template engines. Write the code once, and then relax. And even if a new object appears in the system - by the button we start the update, everything is tightened, we have a new structure, new methods are generated, everything is fine and fine.Tuning MetaMeta
In order to make our service even better, we enriched the standard MetaMeta. At the entrance, we had what was left of the core. We also added an additional description to the objects, objects are grouped in areas. We display all this in the spec so that the user understands what he is manipulating and with what object he is currently communicating.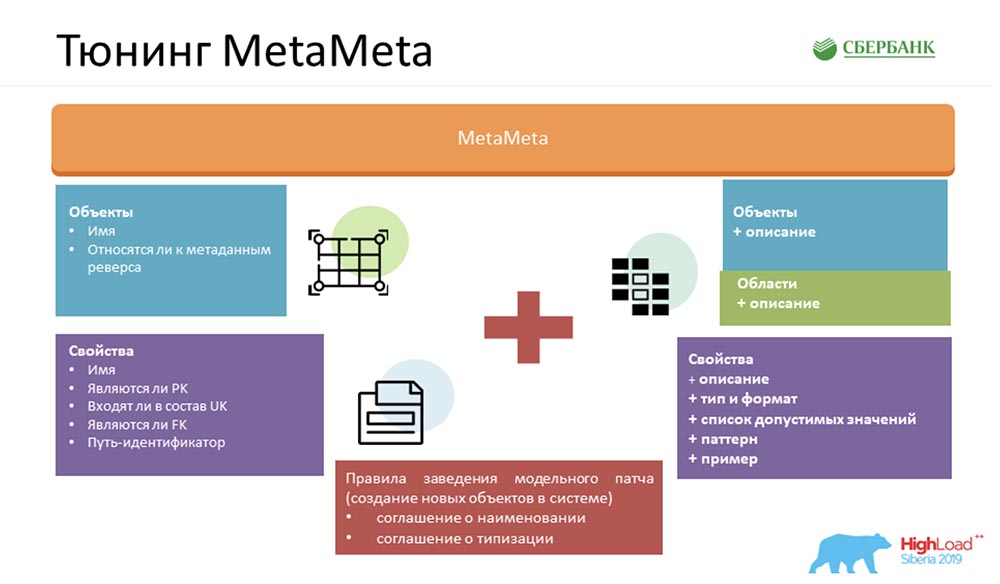 Only we added some little things there - types, formats, lists of acceptable values, patterns, examples. This also pleases users - they already clearly understand what can be inserted, what cannot. We also provide a client artifact to the user, which allows us to catch errors when communicating with our service (precisely by format, already at the compilation stage).But most importantly, for all this magic to work, we needed to agree on the inside: create a set of certain rules. There are not many of them - I counted three (there are two of them on the slide, so one will have to remember):
Only we added some little things there - types, formats, lists of acceptable values, patterns, examples. This also pleases users - they already clearly understand what can be inserted, what cannot. We also provide a client artifact to the user, which allows us to catch errors when communicating with our service (precisely by format, already at the compilation stage).But most importantly, for all this magic to work, we needed to agree on the inside: create a set of certain rules. There are not many of them - I counted three (there are two of them on the slide, so one will have to remember):- Naming convention. We specifically name objects in the system in order to make it easier to recognize scenarios for their further use.
- Typing agreement. This is to correctly determine the types, formats, and that they fought between the kernel and the application server, we use the check system, by which we understand which format a particular property belongs to.
- Valid foreign keys. If the object is given an invalid link to another object, then all this magic will work incorrectly.
Result
SC: - It's cool, but a lot of theory. Can you give some practical example?AC: - Yes, I specially prepared it. Before leaving for the conference, on Friday evening, literally 5 minutes before the end of the working day, Stas told me: “Oh, look! I released a model patch - how cool! It would be nice to update our service. " The patch contained only two objects, but I understand that with the old approach I would have to get confused and write or add 7 APIs.Immediately I just had the click of a button to make all this magic work. I specially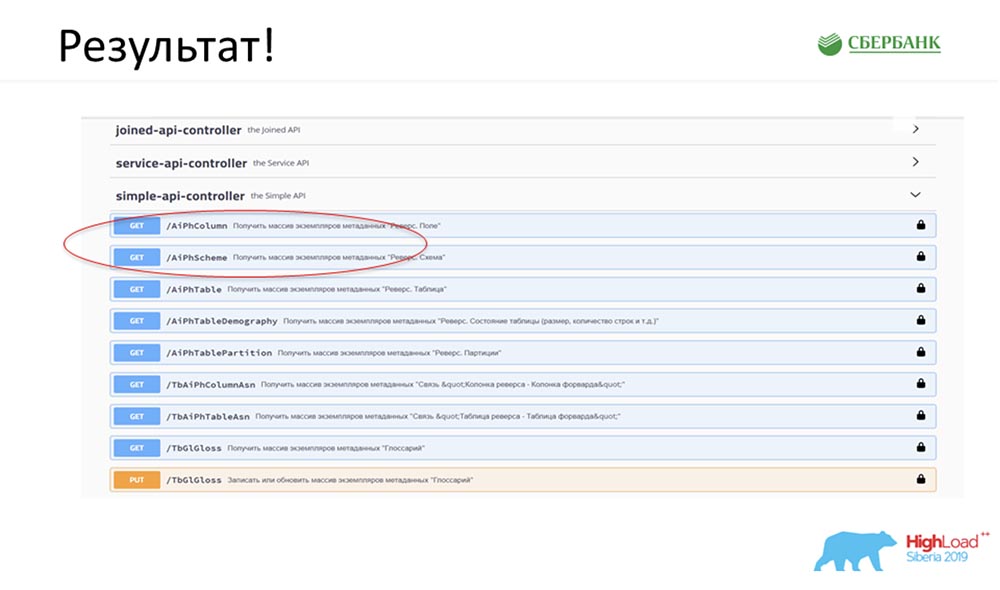 circled in red the place where the magic is about to happen: I click on the button ... These are of course screenshots, but in reality everything works like this:
circled in red the place where the magic is about to happen: I click on the button ... These are of course screenshots, but in reality everything works like this: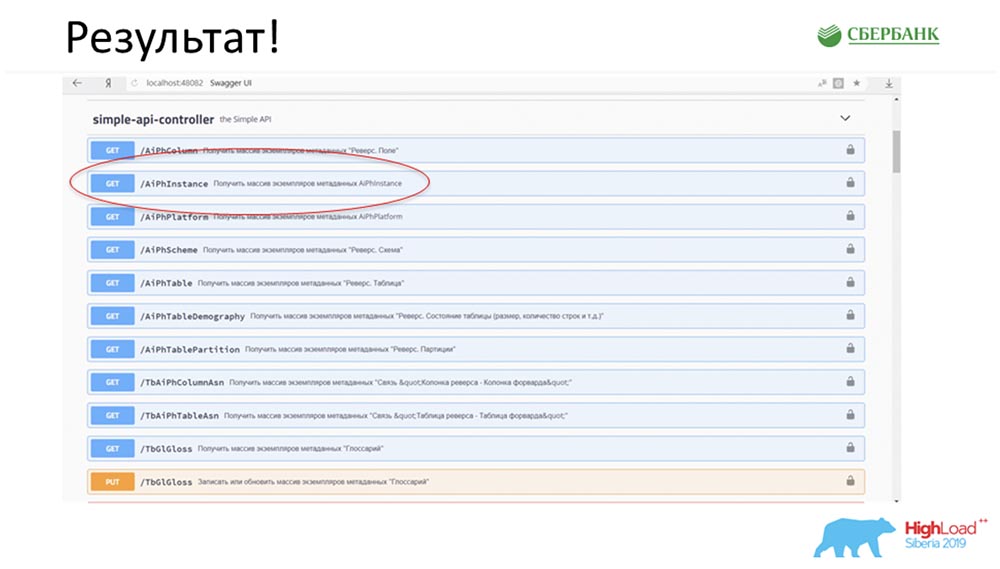 We have a new method (between the two), which already gives data, by which we in the hierarchy can query the entire structure, all nested objects:
We have a new method (between the two), which already gives data, by which we in the hierarchy can query the entire structure, all nested objects: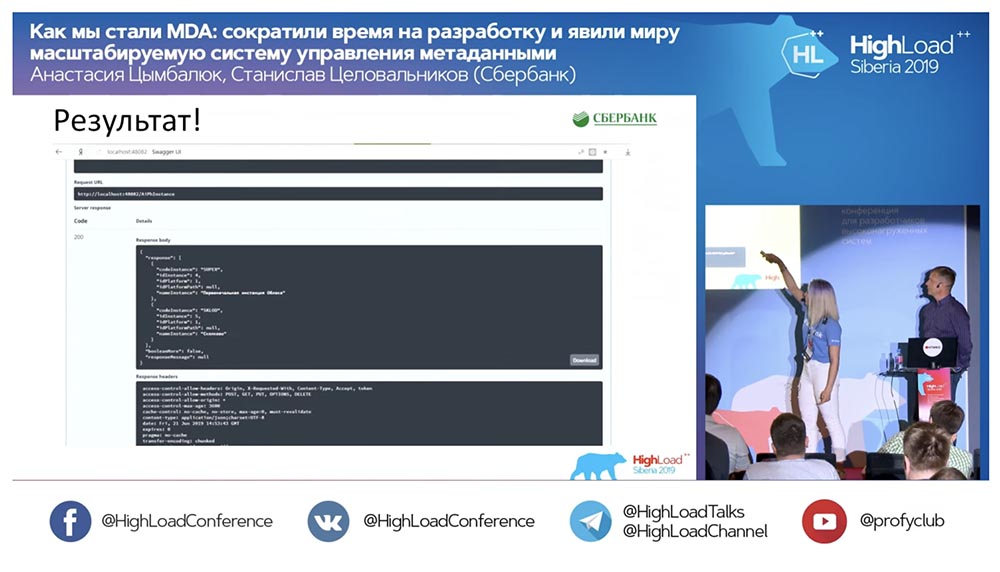
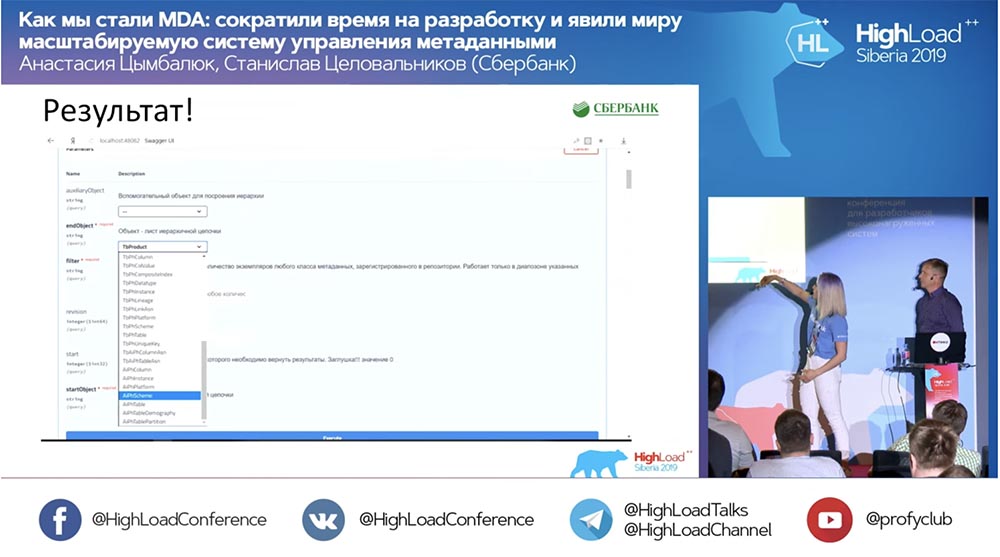
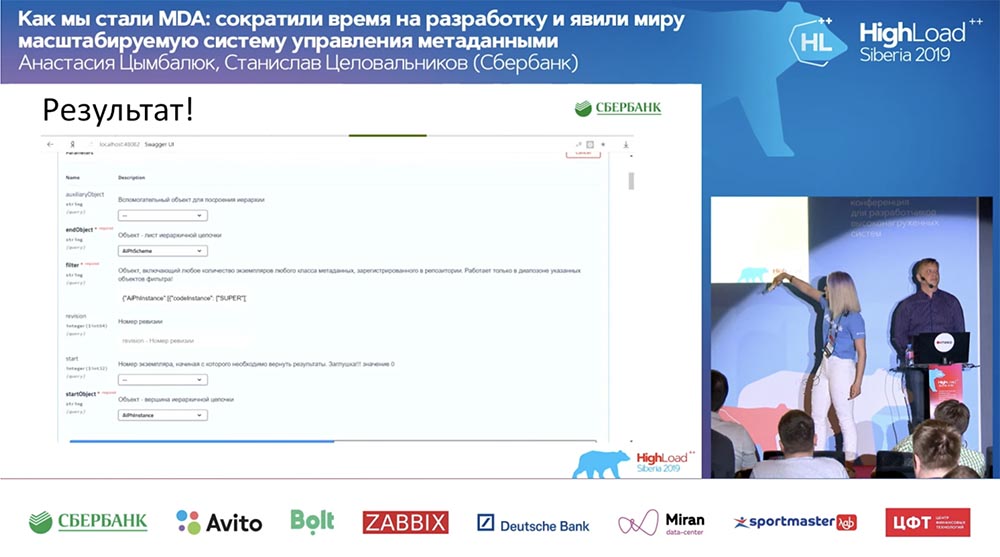 And it all works! I have not written a single line of code at all.
And it all works! I have not written a single line of code at all.Summary
SC: - Firstly, what is the fact? We managed the most complex logic, which would take our programmers the most time, to pack in 100% dynamic kernel code that can work with objects - those that are and those that will be: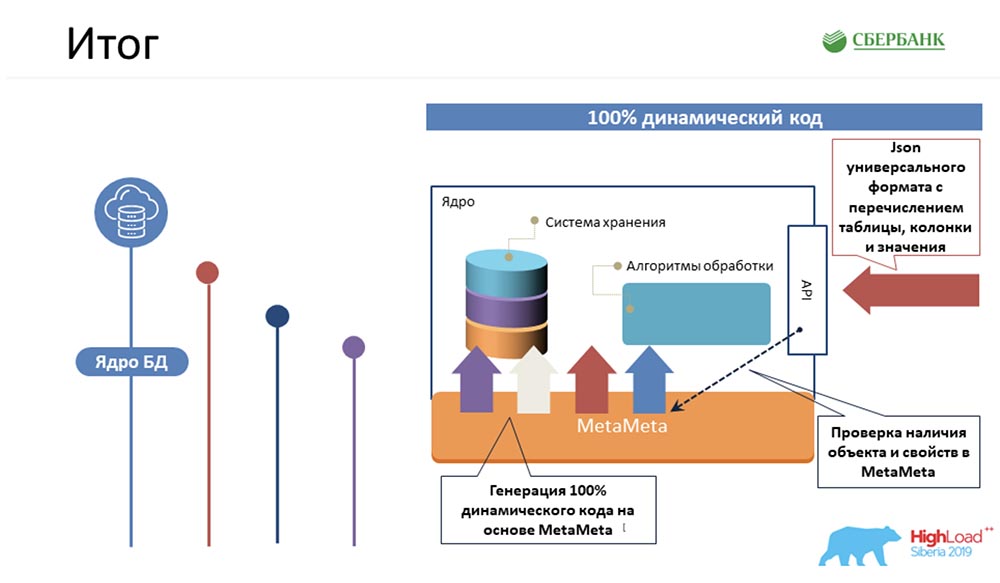 Secondly, we succeeded at the application server level (where it’s not possible) to also avoid programming due to code generation - the same button that you demonstrated:
Secondly, we succeeded at the application server level (where it’s not possible) to also avoid programming due to code generation - the same button that you demonstrated: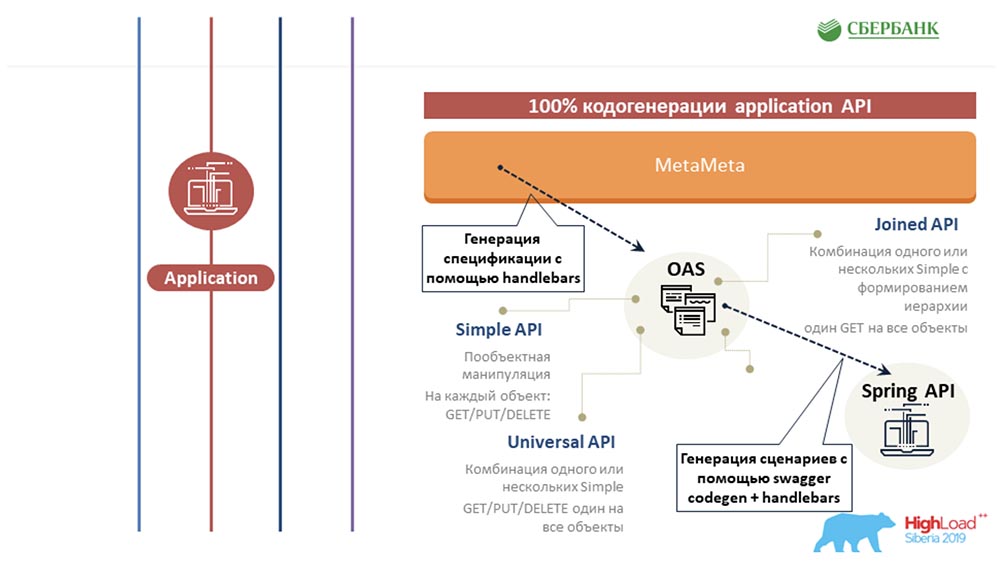 AC: - We tried to extend the same approach based on metadata to other areas, to the testing area. We also write a template once for some object, insert tags there. And when this template is run along the metadata, it generates a finished sheet with all the test scenarios, that is, in fact, we cover all objects with tests.
AC: - We tried to extend the same approach based on metadata to other areas, to the testing area. We also write a template once for some object, insert tags there. And when this template is run along the metadata, it generates a finished sheet with all the test scenarios, that is, in fact, we cover all objects with tests.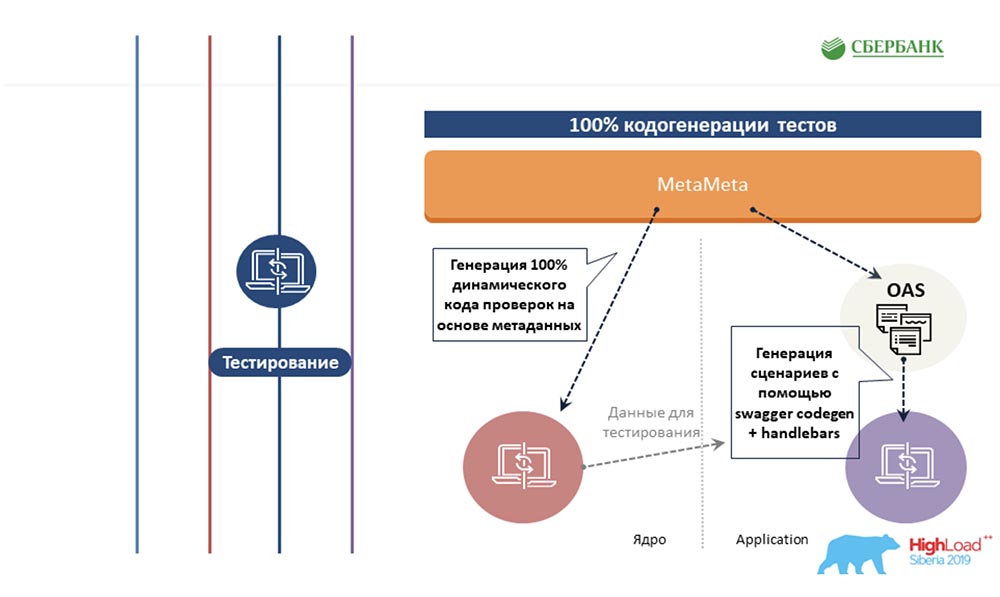 Next up is the cherry on the cake. I know that few people like to document what they do. We solved this pain based on metadata too. Once we prepared a template with html markup, tagged it. And when we go over the metadata, all these tags are substituted with their properties corresponding to the objects.
Next up is the cherry on the cake. I know that few people like to document what they do. We solved this pain based on metadata too. Once we prepared a template with html markup, tagged it. And when we go over the metadata, all these tags are substituted with their properties corresponding to the objects. The output is a beautiful finished html page. Then we publish in Confluence, and we can give our users in a human-readable format so that they can see what we have in the system, how to work with it, some minimal description, acceptable values, required properties, keys ... They can all do this see and can quite easily figure it out.As a result, we have four main points, and this approach is called MDA (Model Driven Architecture). For some reason, this translates as “model-driven architecture,” although I would call it a “software development method.”
The output is a beautiful finished html page. Then we publish in Confluence, and we can give our users in a human-readable format so that they can see what we have in the system, how to work with it, some minimal description, acceptable values, required properties, keys ... They can all do this see and can quite easily figure it out.As a result, we have four main points, and this approach is called MDA (Model Driven Architecture). For some reason, this translates as “model-driven architecture,” although I would call it a “software development method.” What is the point? You create a model, agree on certain rules. Then you create once transformation patterns of this model in some programming language available to you. All this works to change old objects, to add new ones. You write the code once and no longer bother.SC: - I honestly waited for the whole report when you answer this question. Let's move on to my favorite slides.
What is the point? You create a model, agree on certain rules. Then you create once transformation patterns of this model in some programming language available to you. All this works to change old objects, to add new ones. You write the code once and no longer bother.SC: - I honestly waited for the whole report when you answer this question. Let's move on to my favorite slides.Decision. Process. Before
AC: - “The process. Before ”- this is our pride, because we used to program a lot, ate almost nothing — we were very evil. I had to perform all these 5 steps for each object: It was very sad and took us a lot of time. Now we have reduced this food chain to three links, the most important of which is simply to correctly create the object, and nothing more:
It was very sad and took us a lot of time. Now we have reduced this food chain to three links, the most important of which is simply to correctly create the object, and nothing more: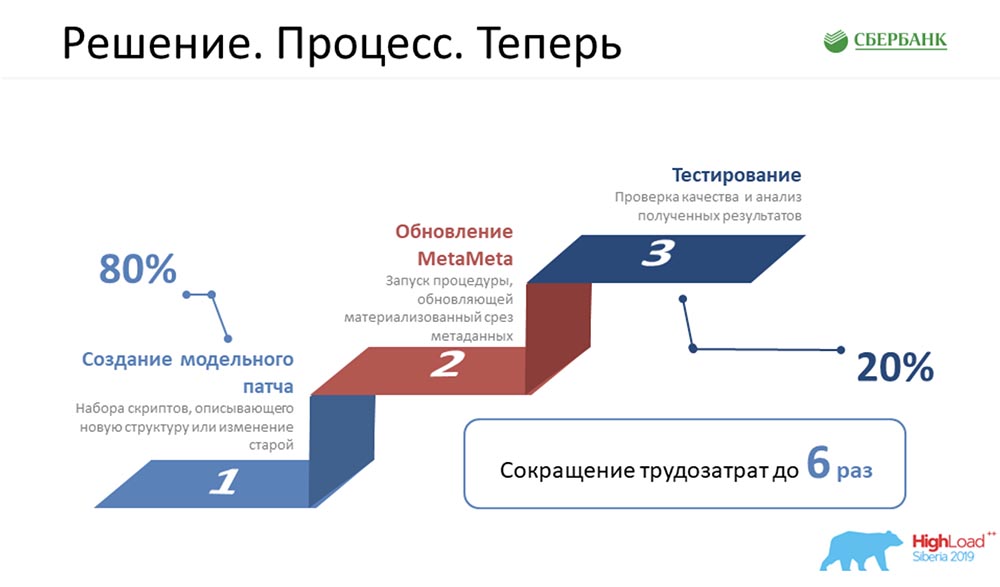 MetaMeta is launched by a button (update), then testing. We are currently looking to ensure that nothing falls off from us, since we recently began to apply this approach. We are trying to control this whole process.According to estimates, all our labor costs for the development of all our software have been reduced by 6 times.SC:- From myself, I want to sincerely say that the number 6 is not blown, it is even conservative. In fact, the efficiency is even higher.
MetaMeta is launched by a button (update), then testing. We are currently looking to ensure that nothing falls off from us, since we recently began to apply this approach. We are trying to control this whole process.According to estimates, all our labor costs for the development of all our software have been reduced by 6 times.SC:- From myself, I want to sincerely say that the number 6 is not blown, it is even conservative. In fact, the efficiency is even higher.Future plans
You asked at the end of the report to dwell on our plans. First of all, it seems that we must achieve not just a complete, but an alienated and boxed solution. These technologies can be applied somewhere nearby, where appropriate. I would like to achieve a finished product that will be developed, and which we will be able to offer on behalf of Sberbank.Of course, if we talk about immediate tasks, they are all displayed on the slides with bullets. Despite the optimization that we received, the load on the team is still quite serious. I can’t say with certainty from which quarter we can move on to the implementation of these steps.Number 6 and the case that Nastya brought - they are honest. It really was on Friday, when we needed to get documents (plane, travel, etc.). The adjacent team was scheduled for testing on Monday, and we needed to release this patch, not to set the guys up. It worked! This is a real case. I would be happy if this could come in handy for any of you. If you have any questions, we are available. And after the report, here too for some time. Ask. We will be happy to help you!AC:- Indeed, this approach, I think, can begin to be used by everyone. Not necessarily in our form (we are engaged in metadata management). It can be a control system of anything. All you need to have at hand is a relational view of things, take metadata from there, understand some template engines and understand some programming language (how it works).All these tools are in the public domain - you can already start googling and understand how to use them. I am sure that using them will make your life easier, better, and generally free up time for new, ambitious, cool tasks. Thank!
I would be happy if this could come in handy for any of you. If you have any questions, we are available. And after the report, here too for some time. Ask. We will be happy to help you!AC:- Indeed, this approach, I think, can begin to be used by everyone. Not necessarily in our form (we are engaged in metadata management). It can be a control system of anything. All you need to have at hand is a relational view of things, take metadata from there, understand some template engines and understand some programming language (how it works).All these tools are in the public domain - you can already start googling and understand how to use them. I am sure that using them will make your life easier, better, and generally free up time for new, ambitious, cool tasks. Thank!Questions
Question from the audience (hereinafter - A): - Do I understand correctly that everything is piled up because you use a relational database? It seems to me that if you looked towards the document-oriented database, all this solution would be much easier for you than I see now.SC: - Not really. What we started with when we talked about people working at the glossary level and the spider that goes to the prom, reads these stories and checks - indeed, the table with the field that is responsible for this glossary term takes place at the prom . They said from our service: “Guys, you should have a REST API. How you do it is your problem. Here is a list of allowed technologies - use something from this list (this is what we can use in Sberbank). ”This is the level of our solution, applied architecture. For us, on the contrary, it was easier to do this not to relational. Why? I will give an example, one of many ... For example, I need to ensure, when I write a field, that it does not refer anywhere to a table that does not exist. I just do a foreign key in the database and am not worried. I’m not writing a line - she will not let me make this record. And there are many such examples!Here we should rather talk about something else. A more complicated story: we will release a model patch with an adjustment / certification data set, and there are 6 objects there. And inevitably, for you to provide this gentlemanly set of APIs, you need three months to work (offhand). It will take us a week and a half. Without applying these technologies, it was simply impossible to survive in these conditions. We simply would not give such a level of service!This is possible if you built the production in such a way that you have a model patch (new object), a button “Do everything well” and some software that will test in client emulation mode. Earned a new one, the old one didn’t fall off - this had to be achieved, but how - it was the team’s choice. A: - I have a second question. And what is an example of use from life? I understand that theoretically it looks like that you can at least describe the whole world with your META_META object ... But in life, how do you use it? Judging by how it is implemented (everything should be put into each other), it should slow down!SC:- By the way, no (surprisingly)! Another application of this story is code generators. This is where some storefronts, storages are built, and you are ETL, you are trying to park all possible options to nine templates, nine template engines that are described in advance. Using metadata, you describe this transformation, using these templates as stubs. Further, this machine without programming gives an ETL code, generates code based on metadata. I believe that there are also such technologies, approaches will be appropriate and correct.A: - I was counting on a more specific example.A: - Tell me, please, it was written in your requirements that you need to do complex structural queries (Join and the like). What language is it implemented in, or do you describe it somehow logically?SC:- Access through the REST API, most often it is Java, although it can be any language. Our service has been published (dhttps, ask https - you will get JSON back). Those pieces of code that we showed are SQL. In order to understand in what order it should be processed, we did some SQL tuning over the DBMS dictionaries and parked it in a separate scheme in the form of materialized representations. Accordingly, when a model patch is released, the “Refresh materialized view” button is clicked (+ fields appear). But really our code is Java and Oracle.AC:- It is worth noting here that we decided to divide the areas of responsibility. We deliberately transferred all the magic to the kernel, and Application simply correctly interprets these answers. That is, the Join mechanism itself occurs in the kernel, and Java simply competently scatters it all in the tree and gives the user the final result.A: - And what does Code Gens do - do you already write down the logic of complex queries there? Or is it done on the client side? We need to understand which side is being described ... They presented, it turns out, Code Gen, on which it is necessary to accurately describe in some structure: for example, I want my API to learn such and such Join, go through the list; then say whether there is inside or not ... - complex queries are enough. At what stage is this written?SC:- If I understand your question correctly, this is exactly the story when our customers, our customers (this is a team inside the kernel, the platform) say: “Listen, we don’t want to program - give us this.” “This is it” everything was done in the core. The core - essentially what? 80 percent, maybe 90 - this is the generation of dynamic code, the text that will be called from under PL / SQL, but turned to the database. There, even in time, this line is generated longer, then the database is accessed (for example, the Join request), returns, wraps it in JSON, and displays it upside down. Further, Java transforms all this into a contract, which depends on the structure.AND:- Revealed a batch update solution. And how is the delivery guarantee made - has the whole package arrived, or part of the package? Do they have a certain cachend? And how to make sure that neither the service falls, nor the data structures have any kind of coherence, so that there are no errors?SC: - We have a protocol - there are two update modes. In one of them you can set the flag “Apply all that you can.” There is some software that Excel converts to JSON - there may be 10 thousand lines. And you, strictly speaking, two lines can be invalid (error). And either you say: “Apply everything that you can”; or “Only apply if the whole story will not have a single error.” There, the integral status will be rollback, for example. In fact, an insert is made to the database, but commit is not called.In case of an error - it calls rollback, it is in the protocol; you get the protocol anyway. You get a status on each line, and you have an identifier in a separate field - either a number (object id), or some alternative key, or both. The protocol makes it possible to understand what happened to my request.AC: - The user himself indicates in which of the options he should move. We pass this parameter to the side of the core, and the core already produces all the magic, gives us the answer, and we interpret it.AND:“Why didn't you use any built-in expression compiler that would help define the rule?” Suppose we have a template, I am blogging in some language (typed / not typed script language); wrote: "I want a list." Passed this snippet so that some code processor would chew it all up, put it into a NoSQL database, as suggested in the first question ... Still, it is not clear why a relational database and why and how to deal with data redundancy? A man sends you a template with a billion rubbish ... How are these agreements reached when a person needs it?
A: - I have a second question. And what is an example of use from life? I understand that theoretically it looks like that you can at least describe the whole world with your META_META object ... But in life, how do you use it? Judging by how it is implemented (everything should be put into each other), it should slow down!SC:- By the way, no (surprisingly)! Another application of this story is code generators. This is where some storefronts, storages are built, and you are ETL, you are trying to park all possible options to nine templates, nine template engines that are described in advance. Using metadata, you describe this transformation, using these templates as stubs. Further, this machine without programming gives an ETL code, generates code based on metadata. I believe that there are also such technologies, approaches will be appropriate and correct.A: - I was counting on a more specific example.A: - Tell me, please, it was written in your requirements that you need to do complex structural queries (Join and the like). What language is it implemented in, or do you describe it somehow logically?SC:- Access through the REST API, most often it is Java, although it can be any language. Our service has been published (dhttps, ask https - you will get JSON back). Those pieces of code that we showed are SQL. In order to understand in what order it should be processed, we did some SQL tuning over the DBMS dictionaries and parked it in a separate scheme in the form of materialized representations. Accordingly, when a model patch is released, the “Refresh materialized view” button is clicked (+ fields appear). But really our code is Java and Oracle.AC:- It is worth noting here that we decided to divide the areas of responsibility. We deliberately transferred all the magic to the kernel, and Application simply correctly interprets these answers. That is, the Join mechanism itself occurs in the kernel, and Java simply competently scatters it all in the tree and gives the user the final result.A: - And what does Code Gens do - do you already write down the logic of complex queries there? Or is it done on the client side? We need to understand which side is being described ... They presented, it turns out, Code Gen, on which it is necessary to accurately describe in some structure: for example, I want my API to learn such and such Join, go through the list; then say whether there is inside or not ... - complex queries are enough. At what stage is this written?SC:- If I understand your question correctly, this is exactly the story when our customers, our customers (this is a team inside the kernel, the platform) say: “Listen, we don’t want to program - give us this.” “This is it” everything was done in the core. The core - essentially what? 80 percent, maybe 90 - this is the generation of dynamic code, the text that will be called from under PL / SQL, but turned to the database. There, even in time, this line is generated longer, then the database is accessed (for example, the Join request), returns, wraps it in JSON, and displays it upside down. Further, Java transforms all this into a contract, which depends on the structure.AND:- Revealed a batch update solution. And how is the delivery guarantee made - has the whole package arrived, or part of the package? Do they have a certain cachend? And how to make sure that neither the service falls, nor the data structures have any kind of coherence, so that there are no errors?SC: - We have a protocol - there are two update modes. In one of them you can set the flag “Apply all that you can.” There is some software that Excel converts to JSON - there may be 10 thousand lines. And you, strictly speaking, two lines can be invalid (error). And either you say: “Apply everything that you can”; or “Only apply if the whole story will not have a single error.” There, the integral status will be rollback, for example. In fact, an insert is made to the database, but commit is not called.In case of an error - it calls rollback, it is in the protocol; you get the protocol anyway. You get a status on each line, and you have an identifier in a separate field - either a number (object id), or some alternative key, or both. The protocol makes it possible to understand what happened to my request.AC: - The user himself indicates in which of the options he should move. We pass this parameter to the side of the core, and the core already produces all the magic, gives us the answer, and we interpret it.AND:“Why didn't you use any built-in expression compiler that would help define the rule?” Suppose we have a template, I am blogging in some language (typed / not typed script language); wrote: "I want a list." Passed this snippet so that some code processor would chew it all up, put it into a NoSQL database, as suggested in the first question ... Still, it is not clear why a relational database and why and how to deal with data redundancy? A man sends you a template with a billion rubbish ... How are these agreements reached when a person needs it? SC:“I will try to answer as I understood the question.” Most of the program communicates with us now. When the mechanism of integration interaction is set up, not so much people communicate with us as programs. There are, of course, cases when people send a la exelniks for the primary spill: we make JSONs from them, upload, but this is more of a primary setting.And we have a mode when you sent 5,000 lines, of which 4,900 returned with the status "I processed, I did not find any changes, I did nothing." But this is reflected in the protocol and there is no error. This is on the one hand redundancy.We have this whole story stored in an approximate to the third, normal form, which just does not imply redundancy, in contrast to some denormalized structures that are used, for example, for shop windows.Why relational? Code generators work for us, and sensitivity to the quality of metadata in the system is very high. And when we have the opportunity to configure foreign key using relational and ensure ... The record simply does not lie down - there will be an error if something is wrong in the system, if a failure occurs. And we want, but we are not looking for additional work ...We are not measured because of how many lines of code we wrote: “Have you solved the question of the service and its stability or not?” You may not write at all - the main thing is that it works. In this sense, it was simply faster and more convenient for us to do so.I don’t take a specific vendor, but relational databases have been developing for 20 years! It's not just like that. Take, for example, Word or Excel on Windows - you don’t program the code there, which with the help of "Assembler" accesses and moves the heads of the hard drive to write a file ... The same is here! We just used those developments that were in RDBMS, and it was convenient.AC:- To ensure all of our requirements, the integrity of metadata was important to us. And here we probably also wanted to convey that we don’t have to cling at all - we use relational, not relational ... The essence of the report is that you can also start using it. Not necessarily on a relational basis, because for sure others also have some kind of metadata that can be collected: at least, what tables, fields, and this is all programmed.A: - The system involves some use. How do you plan (or have already done) the delivery of data to your system? It is clear that some kind of updating the data structure is going on the grocery. How does this all come to you? Automatically, or your agent is standing, or are you bending all the development teams so that you receive updates?AC:- We have two modes of operation. One is when the developers themselves or the teams themselves are forced to bullet metadata into the system through REST services. The second mode of operation is that same “vacuum cleaner”: we ourselves go into the environment and take all possible metadata from there. We do this once a day, and just check what the developers sent us.
SC:“I will try to answer as I understood the question.” Most of the program communicates with us now. When the mechanism of integration interaction is set up, not so much people communicate with us as programs. There are, of course, cases when people send a la exelniks for the primary spill: we make JSONs from them, upload, but this is more of a primary setting.And we have a mode when you sent 5,000 lines, of which 4,900 returned with the status "I processed, I did not find any changes, I did nothing." But this is reflected in the protocol and there is no error. This is on the one hand redundancy.We have this whole story stored in an approximate to the third, normal form, which just does not imply redundancy, in contrast to some denormalized structures that are used, for example, for shop windows.Why relational? Code generators work for us, and sensitivity to the quality of metadata in the system is very high. And when we have the opportunity to configure foreign key using relational and ensure ... The record simply does not lie down - there will be an error if something is wrong in the system, if a failure occurs. And we want, but we are not looking for additional work ...We are not measured because of how many lines of code we wrote: “Have you solved the question of the service and its stability or not?” You may not write at all - the main thing is that it works. In this sense, it was simply faster and more convenient for us to do so.I don’t take a specific vendor, but relational databases have been developing for 20 years! It's not just like that. Take, for example, Word or Excel on Windows - you don’t program the code there, which with the help of "Assembler" accesses and moves the heads of the hard drive to write a file ... The same is here! We just used those developments that were in RDBMS, and it was convenient.AC:- To ensure all of our requirements, the integrity of metadata was important to us. And here we probably also wanted to convey that we don’t have to cling at all - we use relational, not relational ... The essence of the report is that you can also start using it. Not necessarily on a relational basis, because for sure others also have some kind of metadata that can be collected: at least, what tables, fields, and this is all programmed.A: - The system involves some use. How do you plan (or have already done) the delivery of data to your system? It is clear that some kind of updating the data structure is going on the grocery. How does this all come to you? Automatically, or your agent is standing, or are you bending all the development teams so that you receive updates?AC:- We have two modes of operation. One is when the developers themselves or the teams themselves are forced to bullet metadata into the system through REST services. The second mode of operation is that same “vacuum cleaner”: we ourselves go into the environment and take all possible metadata from there. We do this once a day, and just check what the developers sent us. SC: - Of the four levels that we examined, the top three levels (glossary, logical models, physical models) are the story that comes to us by default in Metadata Broker mode, and we are a passive participant. They call us, pass us something, ask; our task is to park in a consistent manner. Although there are cases when we set up some stories with the resources of the team, if we are very interested in having this metadata.As Nastya said, regarding the story with the reverse (in the technical jargon we call it “vacuum cleaner”), we go to the industrial environment and read some data. There are different cases - we are ready to discuss later, we are ready to tell many interesting stories.A: - I am from the center of financial technology. I saw a familiar word there - main DACUM. Our platform has its own metadata. How are you friends - directly with the Oracle tables or with our metadata in this case? Because in our case, being friends with Oracle tables is not entirely indicative.SC:- There is such a table main DACUM, which contains the wiring. This is not a secret: there were and are products that work on this story. These are one of the sources of information in the repository. There is some kind of system that is a data provider. Naturally, it is in the focus of our attention in terms of metadata, because one of the stories that we should show and have not touched here at all (due to the topic of the report) is the Data lineage. You must show where the data history of this field comes from. In this sense, if there is a main DACUM table, we know about it.
SC: - Of the four levels that we examined, the top three levels (glossary, logical models, physical models) are the story that comes to us by default in Metadata Broker mode, and we are a passive participant. They call us, pass us something, ask; our task is to park in a consistent manner. Although there are cases when we set up some stories with the resources of the team, if we are very interested in having this metadata.As Nastya said, regarding the story with the reverse (in the technical jargon we call it “vacuum cleaner”), we go to the industrial environment and read some data. There are different cases - we are ready to discuss later, we are ready to tell many interesting stories.A: - I am from the center of financial technology. I saw a familiar word there - main DACUM. Our platform has its own metadata. How are you friends - directly with the Oracle tables or with our metadata in this case? Because in our case, being friends with Oracle tables is not entirely indicative.SC:- There is such a table main DACUM, which contains the wiring. This is not a secret: there were and are products that work on this story. These are one of the sources of information in the repository. There is some kind of system that is a data provider. Naturally, it is in the focus of our attention in terms of metadata, because one of the stories that we should show and have not touched here at all (due to the topic of the report) is the Data lineage. You must show where the data history of this field comes from. In this sense, if there is a main DACUM table, we know about it.A bit of advertising :)
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to your friends, cloud VPS for developers from $ 4.99 , a unique analog of entry-level servers that was invented by us for you: The whole truth about VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps from $ 19 or how to divide the server? (options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).Dell R730xd 2 times cheaper at the Equinix Tier IV data center in Amsterdam? Only we have 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV from $ 199 in the Netherlands!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - from $ 99! Read about How to Build Infrastructure Bldg. class c using Dell R730xd E5-2650 v4 servers costing 9,000 euros per penny? Source: https://habr.com/ru/post/undefined/
All Articles