etcd 3.4.3: storage reliability and security research
Note perev. : The content of this article is not entirely typical of our blog. However, as many people know, etcd is located in the heart of Kubernetes, which is why this study, conducted by an independent consultant in the field of reliability, turned out to be interesting among engineers operating this system. In addition, it is interesting in the context of how Open Source-projects that have already proven themselves in production are being improved even at such a very "low" level. The key-value (KV) etc vault is a distributed database based on the Raft consensus algorithm. In an analysis conducted in 2014 , we found that etcd 0.4.1 was affected by the so-called stale reads by default(read operations that return an old, irrelevant value due to a delay in synchronization - approx. transl.) . We decided to return to etcd (this time - to version 3.4.3) in order to again evaluate in detail its potential in the field of reliability and security.We have found that operation with pairs of "key-value" strictly serializable and that the processes of the observer (watches) delivered to every change in the order key. However, locks in etcd are fundamentally unsafe, and the risks associated with them are exacerbated by a bug, as a result of which the relevance of lease is not checked after waiting for the lock. You can read the comment of the etcd developers on our report on the project blog .The study was sponsored by the Cloud Native Computing Foundation (CNCF), part of The Linux Foundation. It was carried out in full compliance with Jepsen ethical policies .
The key-value (KV) etc vault is a distributed database based on the Raft consensus algorithm. In an analysis conducted in 2014 , we found that etcd 0.4.1 was affected by the so-called stale reads by default(read operations that return an old, irrelevant value due to a delay in synchronization - approx. transl.) . We decided to return to etcd (this time - to version 3.4.3) in order to again evaluate in detail its potential in the field of reliability and security.We have found that operation with pairs of "key-value" strictly serializable and that the processes of the observer (watches) delivered to every change in the order key. However, locks in etcd are fundamentally unsafe, and the risks associated with them are exacerbated by a bug, as a result of which the relevance of lease is not checked after waiting for the lock. You can read the comment of the etcd developers on our report on the project blog .The study was sponsored by the Cloud Native Computing Foundation (CNCF), part of The Linux Foundation. It was carried out in full compliance with Jepsen ethical policies .1. Background
Etc KV repository is a distributed system designed to be used as a basis for coordination. Like Zookeeper and Consul , etcd stores small amounts of rarely updated states ( by default up to 8 GB ) in the form of a key-value map and provides strictly serializable read, write and microtransactions throughout the data warehouse, as well as coordination primitives like locks , tracking (watches) and leader selection. Many distributed systems, such as Kubernetes and OpenStack , use etcd to store cluster metadata, coordinate coordinated views of data, choose a leader, etc.In 2014, we already conducted an evaluation of etcd 0.4.1 . Then we found that by default it is prone to stale reads due to optimization. While the work on Raft principles discusses the need to split read operations into threads and pass them through a consensus system to ensure viability, etcd reads on any leader locally without checking for a more current state on the newer leader. The etcd development team implemented the optional quorum flag , and in the etcd version 3.0 API , linearizability for all operations except tracking operations appeared by default . The etcd 3.0 API concentrates on a KV flat map where the keys and values are opaque( opaque ) byte arrays. Using range queries, you can simulate hierarchical keys. Users can read, write and delete keys, as well as monitor the flow of updates for a single key or range of keys. The etcd toolkit is complemented by leases (variable objects with a limited lifetime, which are maintained in the active state by heartbeat-requests of the client), locks (dedicated named objects bound to leases) and the choice of leaders.In version 3.0, etcd offers a limited transactional APIfor atomic operations with many keys. In this model, a transaction is a conditional expression with a predicate, a true branch, and a false branch. A predicate can be a conjunction of several key comparisons: equality or various inequalities, according to versions of one key, global revision etcd, or the current key value. True and false branches may include multiple read and write operations; all of them are applied atomically depending on the result of predicate estimation.1.1 Guarantees of consistency in documentation
As of October 2019, the etcd documentation for the API states that “all API calls demonstrate consistent consistency — the strongest form of consistency guarantee available on distributed systems.” This is not so: consistent consistency is strictly weaker than linearizability, and linearizability is definitely achievable in distributed systems. Further, the documentation states that “during the read operation, etcd does not guarantee the transfer of [the most recent (measured by the external clock following the completion of the query)] value available on any member of the cluster”. This is also a too conservative statement: if etcd provides linearizability, read operations are always associated with the most recent committed state in linearization order.The documentation also claims that etcd guarantees serializable isolation: all operations (even those that affect several keys) are performed in some general order. The authors describe serializable isolation as “the strongest isolation level available in distributed systems.” This (depending on what you mean by the “isolation level”) is also not true; strict serializability is stronger than simple serializability, while the former is also achievable in distributed systems.The documentation says that all operations (except tracking) in etcd are linearizable by default. In this case, linearizability is defined as consistency with weakly synchronized global clocks. It should be noted that such a definition is not only incompatible with the definition of linearizabilityHerlihy & Wing, but also implies a violation of causality: nodes with leading hours will try to read the results of operations that have not even begun. We assume that etcd is still not a time machine, and since it is based on the Raft algorithm, the generally accepted definition of linearizability should be applied.Since KV operations in etcd are serializable and linearizable, we think that in fact etcd provides strict serialization by default . This makes sense, since all keys etcd are in a single state machine, and Raft provides complete ordering of all operations on this state machine. In fact, the entire etcd dataset is a single linearizable object.Optional flag serializable lowersThe level of read operations from strict to regular serializable consistency, allowing reading of an outdated committed state. Note that the flag serializabledoes not affect the serializability of the story; KV operations etcd are serializable in all cases.2. Test development
To create a test suite, we used the appropriate Jepsen library. The version etcd 3.4.3 (the latest as of October'19) was analyzed, working on Debian Stretch clusters consisting of 5 nodes. We have implemented a number of faults in these clusters, including network partitions, isolating individual nodes, partitioning the cluster into a majority and a minority, as well as non-transitive partitions with an overlapping majority. They “dropped” and suspended random subsets of nodes, and also deliberately disabled leaders. Temporal distortions of up to several hundred seconds were introduced, both at multisecond intervals and at millisecond ones (fast “flicker”). Since etcd supports dynamically changing the number of components, we randomly added and removed nodes during testing.Test loads included registers, sets, and transactional tests for checking operations on KV, as well as specialized loads for locks and watches.2.1 Registers
To evaluate the reliability of etcd during KV operations, a register test was developed during which random read, write, compare-and-set operations were performed on unit keys. The results were evaluated using the Knossos linearizability tool using the comparison / installation register model and version information.2.2 Sets
To quantify stale reads, a test was developed that used a compare-and-set transaction to read a set of integers from a single key and then add a value to this set. During the test, we also carried out a parallel reading of the entire set. After completion of the test, the results were analyzed for the occurrence of cases when the element, which was known to be present in the set, was absent in the reading results. These cases were used to quantify stale reads and lost updates.2.3 Append Test
To verify strict serializability, an append test was developed during which transactions were read in parallel and added values to lists consisting of unique sets of integers. Each list was stored in one etcd key, and additions were made within each transaction, reading each key that needed to be changed in one transaction, and then these keys were written and reads were performed in the second transaction, which was protectedto ensure that no recorded key has changed since the first read. At the end of the test, we plotted the relationship between transactions based on real-time priority and the relationship of read and add operations. Checking this graph for loops made it possible to determine whether the operations were strictly serializable.While etcd prevents transactions from writing the same key multiple times, you can create transactions with up to one record per key. We also made sure that read operations within the same transaction reflected previous write operations from the same transaction.2.4 Locks
As a coordination service, etcd promises built-in support for distributed locking . We investigated these locks in two ways. At first, randomized lock and unlock requests were generated , receiving a lease for each lock and leaving it open using the built-in etc client in the Java client keepaliveuntil released . We tested the results with Knossos to see if they form a linearized implementation of the lock service.For a more practical test (and to quantify the frequency of lock failures), we used locks and etcd to organize mutual exclusion when making updates to the set in in-memoryand searched for lost updates in this set. This test allowed us to directly confirm whether systems using etcd as a mutex can safely update the internal state.The third version of the lock test involved guards on the lease key to modify the set stored in etcd.2.5 Tracking
In order to verify that the watchs provide information about each key update, one key was created as part of the test and blindly assigned unique integer values. Meanwhile, customers shared this key for several seconds at a time. Each time after the initiation of the watch, the client began with the revision on which it had stopped the last time.At the end of this process, we made sure that each client observed the same sequence of key changes.3. Results
3.1 Tracking from the 0th revision
When tracking a key, clients can specify an initial revision , which is “an optional revision with which tracking starts (inclusively)”. If the user wants to see each operation with a certain key, he can specify the first revision of etcd. What is this audit? The data model and glossary do not provide an answer to this question; revisions are described as monotonically increasing 64-bit counters, but it is unclear whether etcd starts from 0 or 1. It is reasonable to assume that the countdown is from scratch (just in case).Alas, this is wrong. Requesting the 0th revision causes etcd to start broadcasting updates, starting with the current revision on the server plus one, but not with the very first. The request for the 1st revision gives all the changes. This behavior is not documented anywhere .We believe that in practice this subtlety is unlikely to lead to problems in production, since most clusters do not linger on the first revision. In addition, etcd compresses the story anyway over time, so in real-world applications, most likely, in any case, it does not require reading all versions, starting with the 1st revision. Such behavior is justified, but it would not hurt the corresponding description in the documentation.3.2 Mythical locks
The API documentation for locks states that a locked key "can be used in conjunction with transactions to ensure that updates in etcd occur only when the lock is owned." Strange, but it does not provide any guarantees for the locks themselves and their purpose is not explained.However, in other materials, maintainers etcd still share information about the use of locks. For example, the etcd 3.2 release announcement describes an application etcdctlfor blocking file sharing changes on a disk. In addition, in an issue on GitHub with a question about the specific purpose of the locks, one of the etcd developers answered the following:etcd , ( ) , ( etcd), - :
- etcd;
- - ( , etcd);
- .
Just such an example is given in etcdctl: a lock was used to protect the team put, but did not bind the lock key to the update.Alas, this is not safe because it allows multiple clients to simultaneously hold the same lock. The problem is aggravated by the suspension of processes, network crashes or partitions, however, it can also occur in completely healthy clusters without any external failures. For example, in this test run, process number 3 successfully sets the lock, and process 1 gets the same lock in parallel even before process 3 has the opportunity to remove it: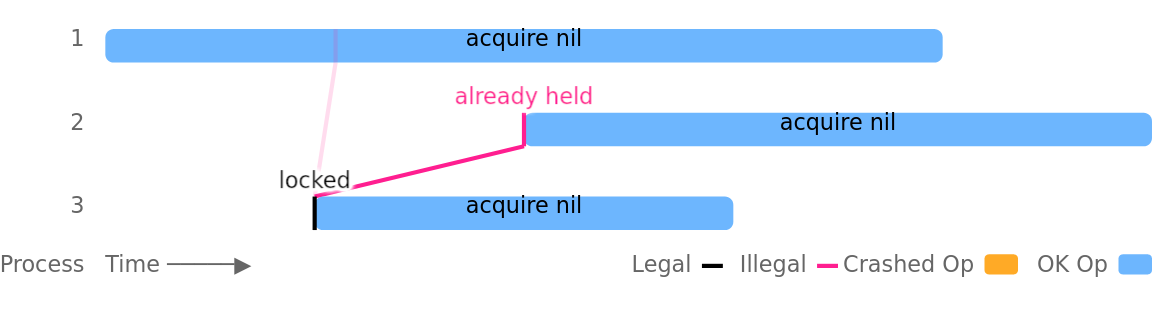 The mutex violation was most noticeable on leases with short TTLs: TTLs of 1, 2, and 3 seconds were not able to provide mutual exclusion after only a few minutes of testing (even in healthy clusters). Process suspensions and network partitions led to problems even faster.In one of our lock-test variants, etcd mutexes were used to protect joint updates of a set of integers (as the documentation etcd suggests). Each update reads the current in-memory sample value, and, after about one second, writes this collection back with the addition of a unique element. With leases with a two-second TTL, five parallel processes, and a process pause every five seconds, we were able to cause a steady loss of about 18% of confirmed updates.This problem was exacerbated by the internal locking mechanism in etcd. If a client waited for another client to unlock it, lost its lease, and after that the lock was released, the server did not double-check lease to make sure it is still valid before informing the client that the lock is now behind it.The inclusion of an additional lease check, as well as the selection of longer TTLs and careful setting of election timeouts, will reduce the frequency of this problem. However, mutex violations cannot be completely eliminated, since distributed locks are fundamentally unsafe in asynchronous systems. Dr. Martin Kleppmann convincingly describes this in his articleAbout distributed locks. According to him, blocking services must sacrifice correctness in order to maintain viability in asynchronous systems: if the process crashes while controlling the blocking, the blocking service needs some way to force the blocking to be unlocked. However, if the process actually did not fall, but simply runs slowly or is temporarily unavailable, unlocking it can lead to it being held in several places at the same time.But even if the distributed blocking service uses, say, some kind of magic failure detector and can actually guarantee mutual exclusion, in the case of some non-local resource, its use will still be unsafe. Suppose process A sends a message to database D while holding a lock. After that, process A crashes, and process B receives a lock and also sends a message to base D. The problem is that a message from process A (due to asynchrony) can come after a message from process B, violating the mutual exception that the lock was supposed to provide. .To prevent this problem, it is necessary to rely on the fact that the storage system itself will support the correctness of transactions or, if the locking service provides such a mechanism, use“ Fencing” token that will be included in all operations performed by the lock holder. It will ensure that no operations of the previous lock holder occur suddenly between operations of the current lock owner. For example, in Google’s Chubby blocking service, these tokens are called sequencers . In etcd, you can use the lock key revision as a globally ordered blocking token.In addition, lock keys in etcd can be used to protect transactional updates in etcd itself. Checking the lock key version as part of the transaction, users can prevent a transaction if the lock is no longer held (i.e. the lock key version is greater than zero). In our tests, this approach allowed us to successfully isolate read-modify-write operations in which the write was the only transaction protected by locking. This approach provides isolation similar to barrage tokens, but (like barrage tokens) does not guarantee atomicity: a process may crash or lose a mutex during an update consisting of many operations, leaving etcd in a logically inconsistent state.The results of work in the issues of the project:
The mutex violation was most noticeable on leases with short TTLs: TTLs of 1, 2, and 3 seconds were not able to provide mutual exclusion after only a few minutes of testing (even in healthy clusters). Process suspensions and network partitions led to problems even faster.In one of our lock-test variants, etcd mutexes were used to protect joint updates of a set of integers (as the documentation etcd suggests). Each update reads the current in-memory sample value, and, after about one second, writes this collection back with the addition of a unique element. With leases with a two-second TTL, five parallel processes, and a process pause every five seconds, we were able to cause a steady loss of about 18% of confirmed updates.This problem was exacerbated by the internal locking mechanism in etcd. If a client waited for another client to unlock it, lost its lease, and after that the lock was released, the server did not double-check lease to make sure it is still valid before informing the client that the lock is now behind it.The inclusion of an additional lease check, as well as the selection of longer TTLs and careful setting of election timeouts, will reduce the frequency of this problem. However, mutex violations cannot be completely eliminated, since distributed locks are fundamentally unsafe in asynchronous systems. Dr. Martin Kleppmann convincingly describes this in his articleAbout distributed locks. According to him, blocking services must sacrifice correctness in order to maintain viability in asynchronous systems: if the process crashes while controlling the blocking, the blocking service needs some way to force the blocking to be unlocked. However, if the process actually did not fall, but simply runs slowly or is temporarily unavailable, unlocking it can lead to it being held in several places at the same time.But even if the distributed blocking service uses, say, some kind of magic failure detector and can actually guarantee mutual exclusion, in the case of some non-local resource, its use will still be unsafe. Suppose process A sends a message to database D while holding a lock. After that, process A crashes, and process B receives a lock and also sends a message to base D. The problem is that a message from process A (due to asynchrony) can come after a message from process B, violating the mutual exception that the lock was supposed to provide. .To prevent this problem, it is necessary to rely on the fact that the storage system itself will support the correctness of transactions or, if the locking service provides such a mechanism, use“ Fencing” token that will be included in all operations performed by the lock holder. It will ensure that no operations of the previous lock holder occur suddenly between operations of the current lock owner. For example, in Google’s Chubby blocking service, these tokens are called sequencers . In etcd, you can use the lock key revision as a globally ordered blocking token.In addition, lock keys in etcd can be used to protect transactional updates in etcd itself. Checking the lock key version as part of the transaction, users can prevent a transaction if the lock is no longer held (i.e. the lock key version is greater than zero). In our tests, this approach allowed us to successfully isolate read-modify-write operations in which the write was the only transaction protected by locking. This approach provides isolation similar to barrage tokens, but (like barrage tokens) does not guarantee atomicity: a process may crash or lose a mutex during an update consisting of many operations, leaving etcd in a logically inconsistent state.The results of work in the issues of the project:4. Discussion
In our tests, etcd 3.4.3 lived up to expectations regarding KV operations: we observed strictly serializable consistency of read, write, and even multi-key transactions, despite the suspension of processes, crashes, manipulation of the clock and network, as well as a change in the number of cluster members . Strictly serializable behavior was implemented by default in KV operations; performance of readings with the flag serializableset led to the appearance of stale reads (as described in the documentation).Monitor (watches) to work correctly - at least on the individual keys. Until the compression of the history destroyed the old data, the watch successfully issued each key update.However, it turned out that locks in etcd (like all distributed locks) do not provide mutual exclusion. Different processes can hold the lock at the same time - even in healthy clusters with perfectly synchronized clocks. The documentation with the locking API did not say anything about this, and the examples of locks presented were unsafe. However, some of the problems with the locks had to go after the release of this patch .As a result of our collaboration, the etcd team made a number of amendments to the documentation (they have already appeared on GitHub and will be published in future versions of the project website). The GitHub Warranties API page now states that by default etcd is strictly serializableand the claim that serial and serializable are the strongest levels of consistency available in distributed systems has been removed. With regard to revisions, it is now indicated that the start should be from unit (1) , although the API documentation still does not say that an attempt to start from the 0th revision will result in “outputting events that occurred after the current revision plus 1” instead of the expected "dispatch of all events." Documentation of lock security issues is under development .Some documentation changes, such as describing the special behavior of etcd when trying to read, starting with a zero revision, still require attention.As usual, we emphasize that Jepsen prefers an experimental approach to security verification: we can confirm the presence of bugs, but not their absence. Considerable efforts are being made to find problems, but we cannot prove the general correctness of etcd.4.1 Recommendations
If you use locks in etcd, think about whether you need them for security or to simply increase performance by probabilisticly limiting concurrency. Etcd locks can be used to increase performance, but using them for security purposes can be risky.In particular, if you use the etcd lock to protect a shared resource such as a file, database or service, this resource should guarantee security without blocking. One way to achieve this is to use a monotonous barrage token . It may be, for example, an etcd revision associated with the current held lock key. The shared resource must ensure that once the client has used the tokenyto perform some operation, any operation with a token x < ywill be rejected. This approach does not ensure atomicity, but it does guarantee that operations within the framework of locking are performed in order, and not intermittently.We suspect that ordinary users are unlikely to encounter this problem. But if you still rely on reading all the changes from etcd, starting with the first revision, remember that you need to pass 1, not 0 as a parameter. Our experiments show that a zero revision in this case means "current revision", not "Earliest."Finally, locks and etcd (like all distributed locks) mislead users: they may want to use them as regular locks, but they will be very surprised when they realize that these locks do not provide mutual exclusion. The API documentation, blog posts, issues on GitHub don't say anything about this risk. We recommend that you include information in the etcd documentation that locks do not provide mutual exclusion and provide examples of using barrage tokens to update the status of shared resources instead of examples that could lead to loss of updates.4.2 Further plans
The etcd project has been considered stable for several years: the Raft algorithm based on it has worked well, the API for KV operations is simple and straightforward. Although some additional features have recently received a new API, its semantics are relatively simple. We believe that we have already studied enough basic commands like getand put, transactions, blocking and tracking. However, there are other tests that should be performed.At the moment, we have not conducted a sufficiently detailed assessment of deletions.: There may be boundary cases associated with versions and revisions, when objects are constantly created and deleted. In future tests, we intend to subject the removal operations to more careful study. We also did not test range queries or tracking operations with multiple keys, although we suspect that their semantics are similar to operations with single keys.In the tests, we used the suspension of processes, crashes, manipulations with the clock, the network was divided and the composition of the cluster changed; behind the scenes there were problems like disk damage and other Byzantine failures at the level of one node. These opportunities may be explored in future research.The work was supported by the Cloud Native Computing Foundation., part of The Linux Foundation , and complies with Jepsen's ethical policies . We would like to thank the etcd team for their help, and the following representatives in particular: Chris Aniszczyk, Gyuho Lee, Xiang Li, Hitoshi Mitake, Jingyi Hu and Brandon Philips.PS from the translator
Read also in our blog: Source: https://habr.com/ru/post/undefined/
All Articles