Massive PostgreSQL query optimization. Kirill Borovikov (Tensor)
The report presents some approaches that allow you to monitor the performance of SQL queries when there are millions of them per day , and hundreds of controlled PostgreSQL servers.What technical solutions allow us to efficiently process such a volume of information, and how it facilitates the life of an ordinary developer.Who is interested in analyzing specific problems and different techniques for optimizing SQL queries and solving typical DBA problems in PostgreSQL ? You can also read a series of articles on this topic. My name is Kirill Borovikov, I represent the company "Tensor" . Specifically, I specialize in working with databases in our company.Today I’ll tell you how we are doing query optimization, when you need not to “pick up” the performance of a single request, but to solve the problem en masse. When there are millions of requests, and you need to find some approaches to solving this big problem.In general, “Tensor” for our million customers is VLSI - our application : a corporate social network, video communication solutions, for internal and external document management, accounting systems for bookkeeping and storage ... That is, such a “mega-combine” for integrated business management, which is more than 100 different internal projects.To ensure that they all work and develop normally, we have 10 development centers throughout the country, they have more than 1000 developers .We have been working with PostgreSQL since 2008 and have accumulated a large amount of what we process - this is client data, statistical, analytical, data from external information systems - more than 400TB . Only “in production” there are about 250 servers, and in total the database servers that we monitor are about 1000.
My name is Kirill Borovikov, I represent the company "Tensor" . Specifically, I specialize in working with databases in our company.Today I’ll tell you how we are doing query optimization, when you need not to “pick up” the performance of a single request, but to solve the problem en masse. When there are millions of requests, and you need to find some approaches to solving this big problem.In general, “Tensor” for our million customers is VLSI - our application : a corporate social network, video communication solutions, for internal and external document management, accounting systems for bookkeeping and storage ... That is, such a “mega-combine” for integrated business management, which is more than 100 different internal projects.To ensure that they all work and develop normally, we have 10 development centers throughout the country, they have more than 1000 developers .We have been working with PostgreSQL since 2008 and have accumulated a large amount of what we process - this is client data, statistical, analytical, data from external information systems - more than 400TB . Only “in production” there are about 250 servers, and in total the database servers that we monitor are about 1000. SQL is a declarative language. You describe not “how” something should work, but “what” you want to receive. DBMS knows better how to make JOIN - how to connect your tablets, what conditions to impose, what will go by index, what not ...Some DBMSs accept hints: “No, connect these two tablets in such and such a queue”, but PostgreSQL doesn’t. This is the conscious position of the leading developers: “Better we’ll finish the query optimizer than let the developers use some kind of hint.”But, despite the fact that PostgreSQL does not allow “outside” to control itself, it perfectly allows you to see what happens “inside” when you execute your query and where it has problems.
SQL is a declarative language. You describe not “how” something should work, but “what” you want to receive. DBMS knows better how to make JOIN - how to connect your tablets, what conditions to impose, what will go by index, what not ...Some DBMSs accept hints: “No, connect these two tablets in such and such a queue”, but PostgreSQL doesn’t. This is the conscious position of the leading developers: “Better we’ll finish the query optimizer than let the developers use some kind of hint.”But, despite the fact that PostgreSQL does not allow “outside” to control itself, it perfectly allows you to see what happens “inside” when you execute your query and where it has problems. In general, with what classic problems does the developer [come to DBA] usually? “Here we have fulfilled the request, and everything is slow , everything hangs, something happens ... Some kind of trouble!”The reasons are almost always the same:
In general, with what classic problems does the developer [come to DBA] usually? “Here we have fulfilled the request, and everything is slow , everything hangs, something happens ... Some kind of trouble!”The reasons are almost always the same:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... And for everything else, we need a plan ! We need to see what is happening inside the server. The query execution plan for PostgreSQL is a tree of the query execution algorithm in a textual representation. It is the algorithm that, as a result of the analysis by the planner, was recognized as the most effective.Each tree node is an operation: extracting data from a table or index, building a bitmap, joining two tables, joining, intersecting, or eliminating samples. Fulfillment of the request is a passage through the nodes of this tree.To get a query plan, the easiest way is to execute the statement
The query execution plan for PostgreSQL is a tree of the query execution algorithm in a textual representation. It is the algorithm that, as a result of the analysis by the planner, was recognized as the most effective.Each tree node is an operation: extracting data from a table or index, building a bitmap, joining two tables, joining, intersecting, or eliminating samples. Fulfillment of the request is a passage through the nodes of this tree.To get a query plan, the easiest way is to execute the statement EXPLAIN. To get with all the real attributes, that is, actually execute a query based on - EXPLAIN (ANALYZE, BUFFERS) SELECT ....The bad point: when you execute it, it happens “here and now”, therefore it is suitable only for local debugging. If you take some high-loaded server, which is under a strong stream of data changes, and you see: “Ay! Here we are slower to Xia a request. " Half an hour, an hour ago - while you were running and getting this request from the logs, carrying it again to the server, you have all the dataset and statistics changed. You execute it to debug - and it runs fast! And you cannot understand the why, why it was slow. In order to understand what was exactly at the moment when the request is executed on the server, smart people wrote the auto_explain module. It is present in almost all of the most common PostgreSQL distributions, and you can simply activate it in the config file.If he understands that a request is being executed longer than the border that you told him, he takes a “snapshot” of the plan for this request and writes them together in a log .
In order to understand what was exactly at the moment when the request is executed on the server, smart people wrote the auto_explain module. It is present in almost all of the most common PostgreSQL distributions, and you can simply activate it in the config file.If he understands that a request is being executed longer than the border that you told him, he takes a “snapshot” of the plan for this request and writes them together in a log . Everything seems to be fine now, we go to the log and see there ... [text footstep]. But we can’t say anything about him, except for the fact that this is an excellent plan, because it took 11ms to complete.Everything seems to be fine - but nothing is clear about what really happened. Apart from the total time, we don’t see much. Because to look at such a "latuha" plain text is generally beloved.But even if it is beloved, albeit uncomfortable, but there are more major problems:
Everything seems to be fine now, we go to the log and see there ... [text footstep]. But we can’t say anything about him, except for the fact that this is an excellent plan, because it took 11ms to complete.Everything seems to be fine - but nothing is clear about what really happened. Apart from the total time, we don’t see much. Because to look at such a "latuha" plain text is generally beloved.But even if it is beloved, albeit uncomfortable, but there are more major problems:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
Under these circumstances, understand "Who is the weakest link?" almost unrealistic. Therefore, even the developers themselves in the "manual" write that "Understanding the plan is an art that needs to be learned, experience ..." .But we have 1000 developers, and each of them will not pass this experience into their heads. I, you, he - they know, and someone over there - is no longer there. Maybe he will learn, or maybe not, but he needs to work now - and where would he get this experience.Plan visualization
Therefore, we realized that in order to deal with these problems, we need a good visualization of the plan . [article]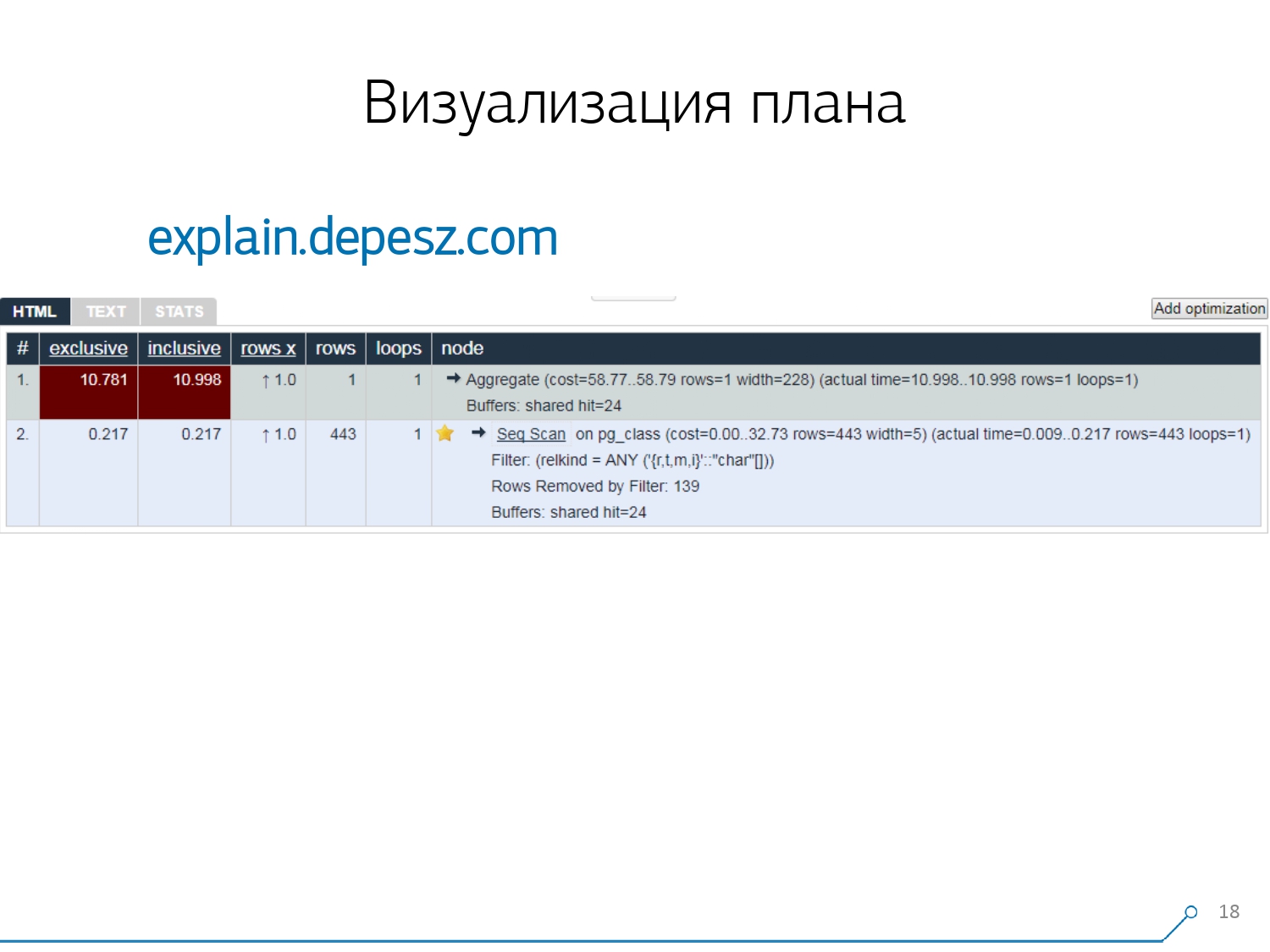 We went first “around the market” - let's look on the Internet for what exists in general.But, it turned out that relatively “live” solutions that are more or less developed, there are very few - literally, one thing: explain.depesz.com from Hubert Lubaczewski. At the entrance to the field "feed" a textual representation of the plan, it shows you a plate with the parsed data:
We went first “around the market” - let's look on the Internet for what exists in general.But, it turned out that relatively “live” solutions that are more or less developed, there are very few - literally, one thing: explain.depesz.com from Hubert Lubaczewski. At the entrance to the field "feed" a textual representation of the plan, it shows you a plate with the parsed data:- proper node working time
- total time over the entire subtree
- the number of records that were retrieved and which was statistically expected
- the node body itself
This service also has the ability to share the archive of links. You threw your plan there and say: “Hey, Vasya, here’s a link for you, something is wrong there.” But there are some minor problems.Firstly, a huge amount of copy-paste. You take a piece of the log, put it there, and again and again.Secondly, there is no analysis of the amount of data read - the very buffers that it displays
But there are some minor problems.Firstly, a huge amount of copy-paste. You take a piece of the log, put it there, and again and again.Secondly, there is no analysis of the amount of data read - the very buffers that it displays EXPLAIN (ANALYZE, BUFFERS), here we do not see. He simply does not know how to disassemble, understand and work with them. When you read a lot of data and understand that you can "decompose" incorrectly on a disk and cache in memory, this information is very important.The third negative point is the very weak development of this project. The commits are very small, it’s good if every six months, and the code in Perl.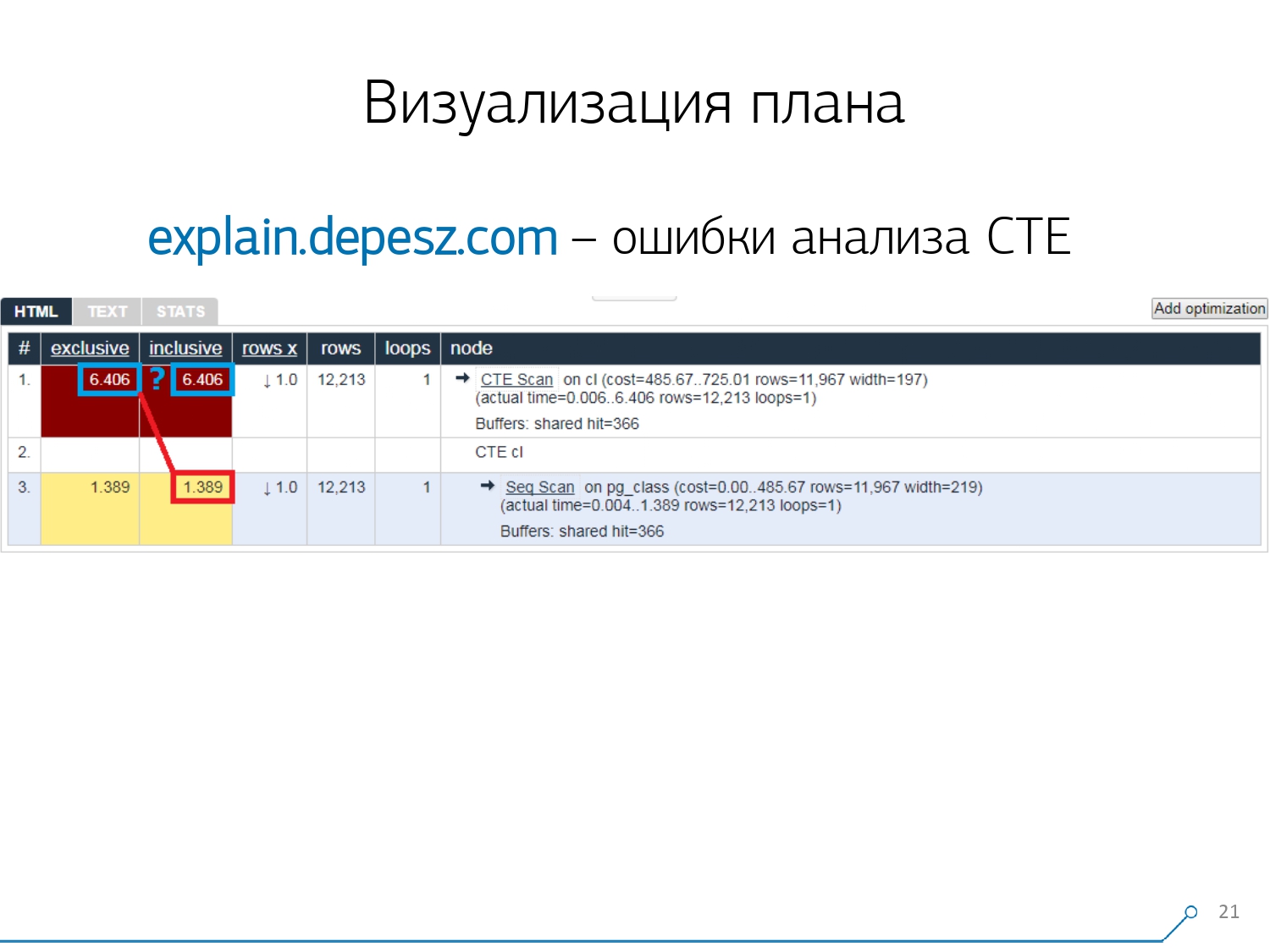 But this is all “lyrics”, one could somehow live with it, but there is one thing that has turned us away from this service. These are Common Table Expression (CTE) analysis errors and various dynamic nodes like InitPlan / SubPlan.If you believe this picture, then we have the total execution time of each individual node is greater than the total execution time of the entire request. It's simple - the generation time of this CTE was not subtracted from the CTE Scan node . Therefore, we no longer know the correct answer, how much did the CTE scan itself take.
But this is all “lyrics”, one could somehow live with it, but there is one thing that has turned us away from this service. These are Common Table Expression (CTE) analysis errors and various dynamic nodes like InitPlan / SubPlan.If you believe this picture, then we have the total execution time of each individual node is greater than the total execution time of the entire request. It's simple - the generation time of this CTE was not subtracted from the CTE Scan node . Therefore, we no longer know the correct answer, how much did the CTE scan itself take. Then we realized that it was time to write our own - hooray! Each developer says: “Now we will write our own, it’ll just be super!”They took a typical web services stack: the core on Node.js + Express, pulled Bootstrap and for beautiful diagrams - D3.js. And our expectations were justified - we received the first prototype in 2 weeks:
Then we realized that it was time to write our own - hooray! Each developer says: “Now we will write our own, it’ll just be super!”They took a typical web services stack: the core on Node.js + Express, pulled Bootstrap and for beautiful diagrams - D3.js. And our expectations were justified - we received the first prototype in 2 weeks:- own plan parser
That is, now we can generally parse any plan from those generated by PostgreSQL. - correct analysis of dynamic nodes - CTE Scan, InitPlan, SubPlan
- analysis of the distribution of buffers - where pages of data from memory are read, where from the local cache, where from disk
- received visibility
So that it’s not “in the log” that it’s “digging”, but that you see the “weakest link” immediately in the picture.
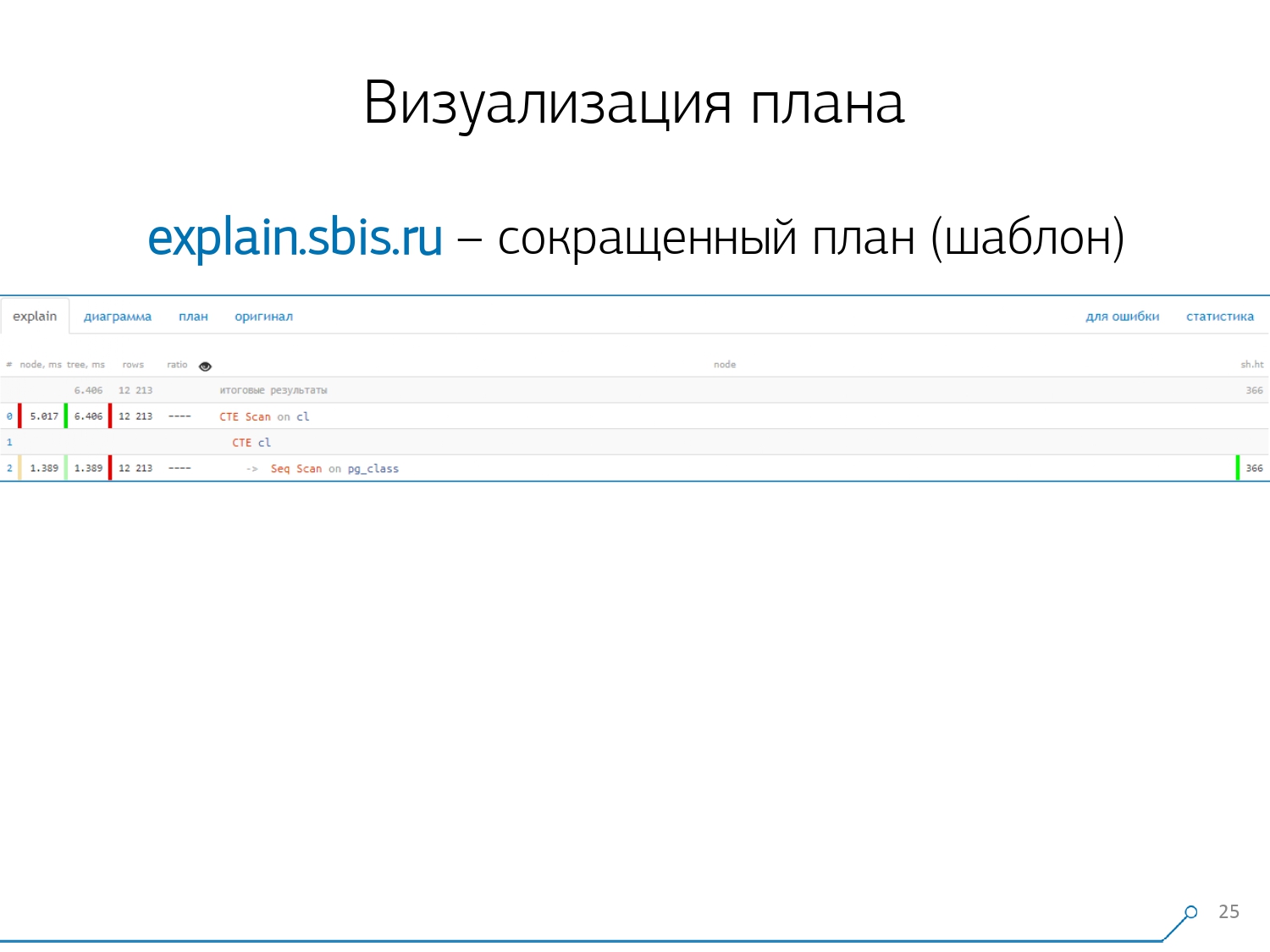 We got something like this - immediately with syntax highlighting. But usually our developers are no longer working with a complete presentation of the plan, but with a shorter one. After all, we have already parsed all the digits and threw them left and right, and in the middle we left only the first line: what kind of node it is: CTE Scan, CTE or Seq Scan generation by some type of label.This abbreviated view is what we call the plan template .
We got something like this - immediately with syntax highlighting. But usually our developers are no longer working with a complete presentation of the plan, but with a shorter one. After all, we have already parsed all the digits and threw them left and right, and in the middle we left only the first line: what kind of node it is: CTE Scan, CTE or Seq Scan generation by some type of label.This abbreviated view is what we call the plan template .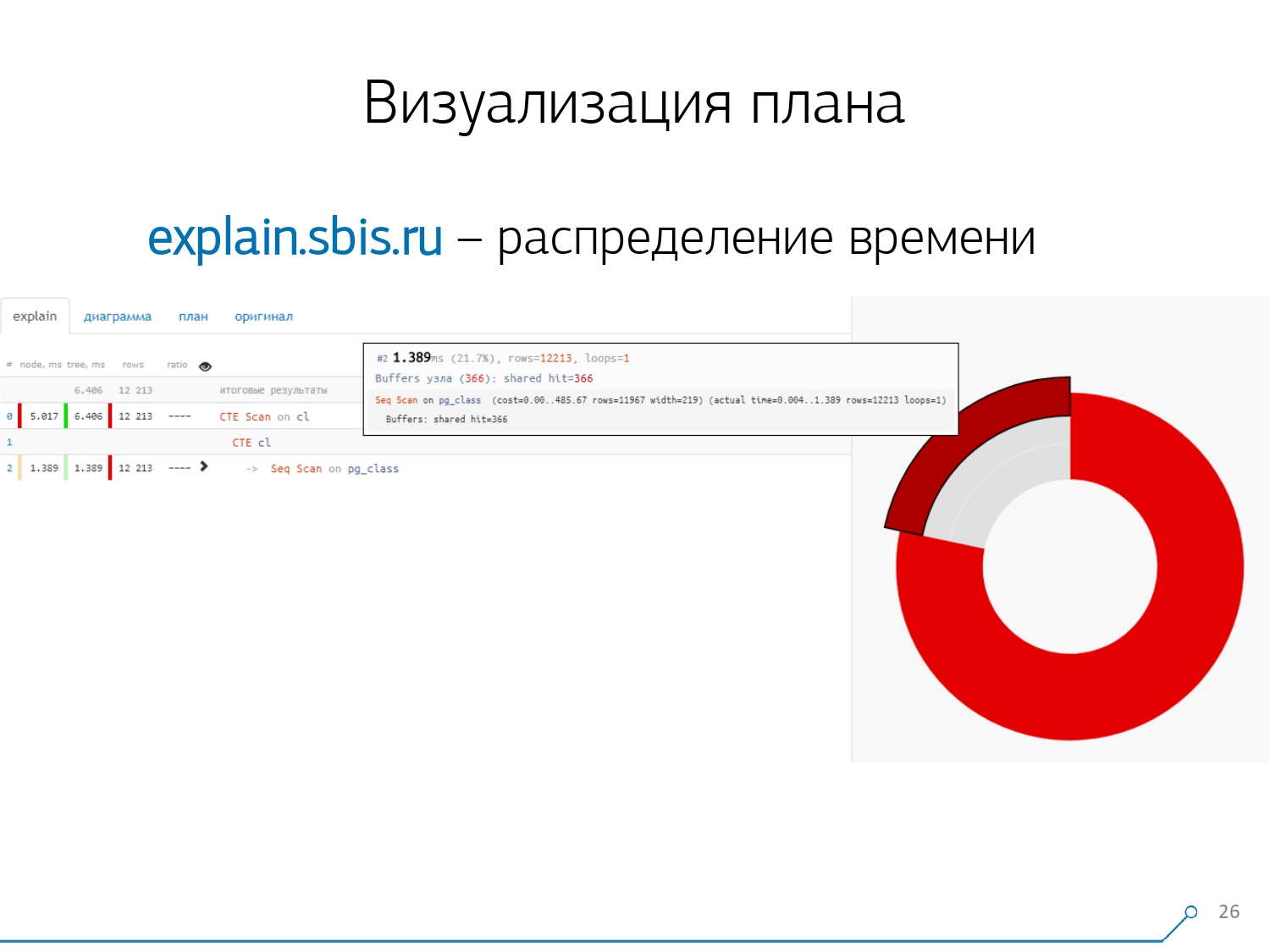 What else would be convenient? It would be convenient to see what proportion of which node of the total time is allocated to us - and just “stuck” the pie chart on the side .We point to the node and see - with us, it turns out that Seq Scan took less than a quarter of the entire time, and the remaining 3/4 took CTE Scan. Horror! This is a small remark about the “rate of fire” of CTE Scan, if you actively use them in your queries. They are not very fast - they lose even to the usual table scan. [article] [article]But usually such diagrams are more interesting, more complicated when we immediately point to a segment, and we see, for example, that more than half of all the time some Seq Scan “ate”. Moreover, there was some kind of Filter inside, a bunch of records were dropped on it ... You can directly throw this picture to the developer and say: “Vasya, everything is bad with you here! Understand, look - something is wrong! ”
What else would be convenient? It would be convenient to see what proportion of which node of the total time is allocated to us - and just “stuck” the pie chart on the side .We point to the node and see - with us, it turns out that Seq Scan took less than a quarter of the entire time, and the remaining 3/4 took CTE Scan. Horror! This is a small remark about the “rate of fire” of CTE Scan, if you actively use them in your queries. They are not very fast - they lose even to the usual table scan. [article] [article]But usually such diagrams are more interesting, more complicated when we immediately point to a segment, and we see, for example, that more than half of all the time some Seq Scan “ate”. Moreover, there was some kind of Filter inside, a bunch of records were dropped on it ... You can directly throw this picture to the developer and say: “Vasya, everything is bad with you here! Understand, look - something is wrong! ” Naturally, there was a “rake”.The first thing they “stepped on” is the problem of rounding. The node time of each individual in the plan is indicated with an accuracy of 1 μs. And when the number of node cycles exceeds, for example, 1000 - after execution PostgreSQL divided it “up to”, then in the reverse calculation we get the total time “somewhere between 0.95ms and 1.05ms”. When the account is spent in microseconds - nothing yet, but when already for [milli] seconds - it is necessary to take this information into account when “untying” resources on the nodes of the plan “who has how much consumed whom”.
Naturally, there was a “rake”.The first thing they “stepped on” is the problem of rounding. The node time of each individual in the plan is indicated with an accuracy of 1 μs. And when the number of node cycles exceeds, for example, 1000 - after execution PostgreSQL divided it “up to”, then in the reverse calculation we get the total time “somewhere between 0.95ms and 1.05ms”. When the account is spent in microseconds - nothing yet, but when already for [milli] seconds - it is necessary to take this information into account when “untying” resources on the nodes of the plan “who has how much consumed whom”. The second point, more complex, is the distribution of resources (those same buffers) among dynamic nodes. This cost us the first 2 weeks on the prototype plus the plus of week 4.To get this problem is quite simple - we make a CTE and we are supposedly reading something in it. In fact, PostgreSQL is smart and won't read anything right there. Then we take the first record from it, and the first hundred from the same CTE to it.
The second point, more complex, is the distribution of resources (those same buffers) among dynamic nodes. This cost us the first 2 weeks on the prototype plus the plus of week 4.To get this problem is quite simple - we make a CTE and we are supposedly reading something in it. In fact, PostgreSQL is smart and won't read anything right there. Then we take the first record from it, and the first hundred from the same CTE to it.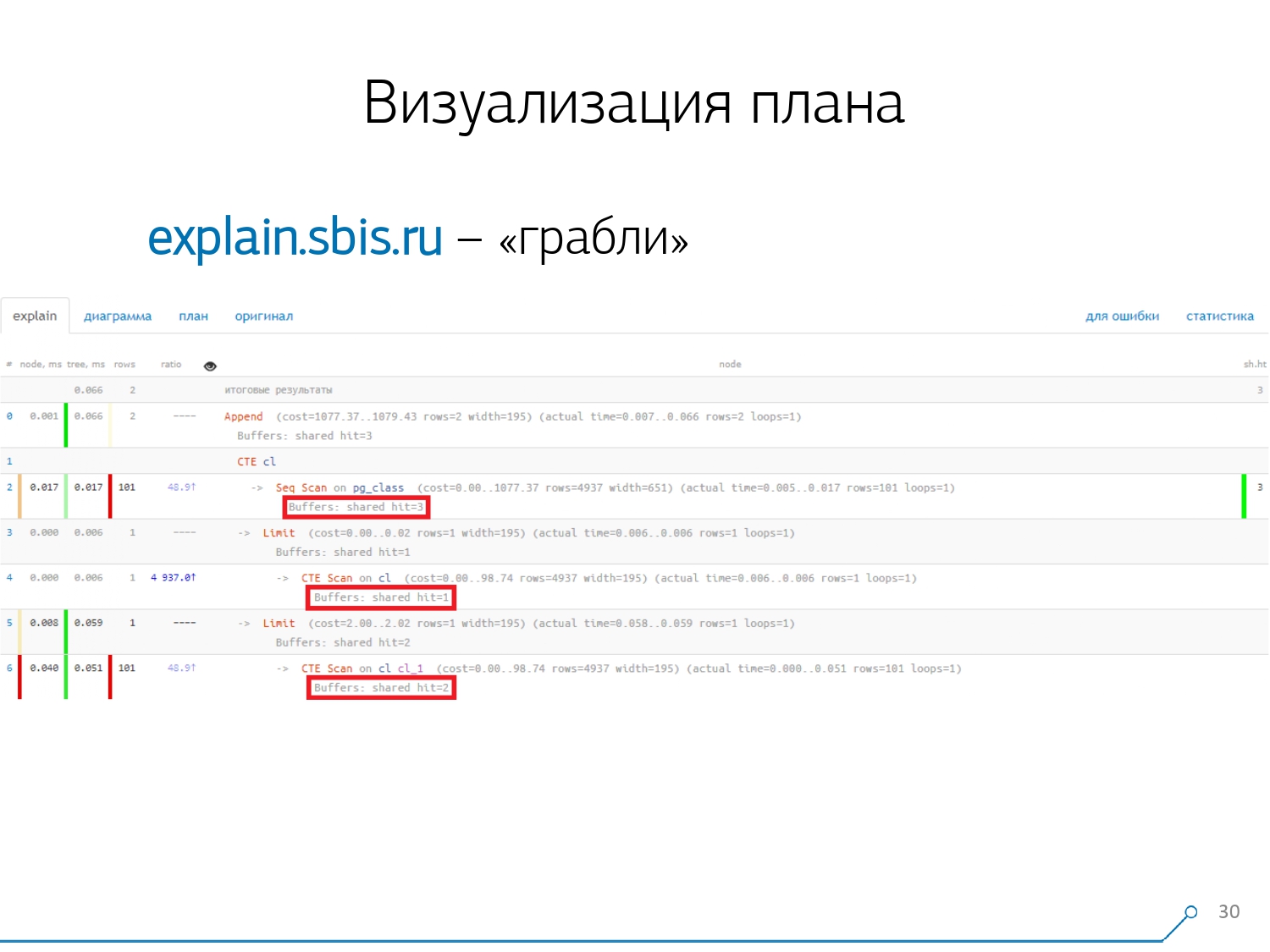 We look at the plan and understand - strange, we have 3 buffers (data pages) were "consumed" in Seq Scan, another 1 in CTE Scan, and 2 more in the second CTE Scan. That is, if everything is simply summed up, we get 6, but from the plate we read only 3! CTE Scan does not read anything from anywhere, but works directly with the process memory. That is, there is clearly something wrong here!In fact, it turns out that here all those 3 pages of data that were requested from Seq Scan, first 1 asked for the 1st CTE Scan, and then the 2nd, and they read another 2. That is, 3 pages were read in total data, not 6.
We look at the plan and understand - strange, we have 3 buffers (data pages) were "consumed" in Seq Scan, another 1 in CTE Scan, and 2 more in the second CTE Scan. That is, if everything is simply summed up, we get 6, but from the plate we read only 3! CTE Scan does not read anything from anywhere, but works directly with the process memory. That is, there is clearly something wrong here!In fact, it turns out that here all those 3 pages of data that were requested from Seq Scan, first 1 asked for the 1st CTE Scan, and then the 2nd, and they read another 2. That is, 3 pages were read in total data, not 6.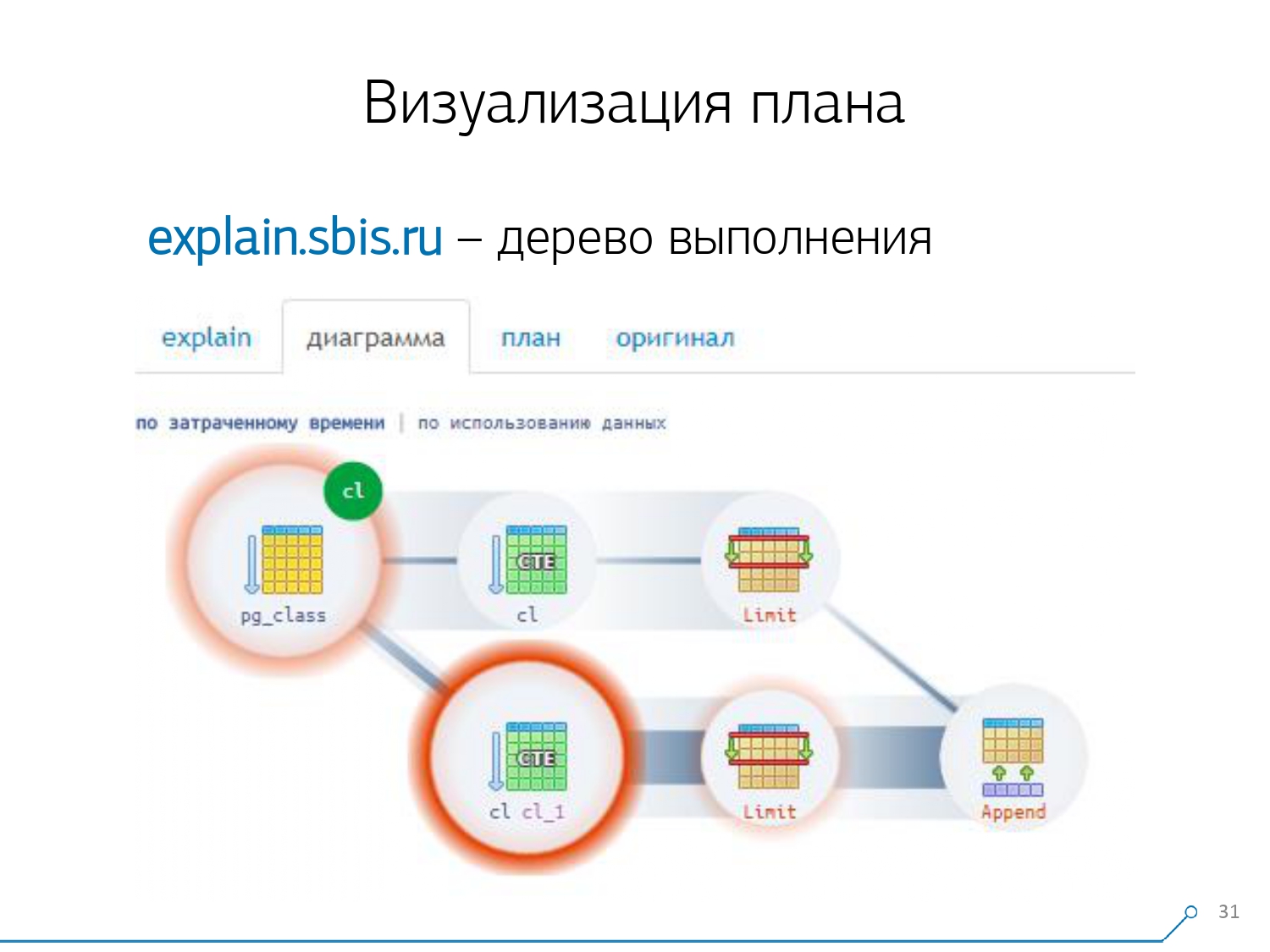 And this picture led us to understand that the implementation of the plan is no longer a tree, but just some kind of acyclic graph. And we got a chart like this so that we understand "what-where it came from at all." That is, here we created a CTE from pg_class, and asked for it twice, and almost all the time it took us up the branch when we asked for it the second time. It is clear that reading the 101st record is much more expensive than just the 1st of the tablet.
And this picture led us to understand that the implementation of the plan is no longer a tree, but just some kind of acyclic graph. And we got a chart like this so that we understand "what-where it came from at all." That is, here we created a CTE from pg_class, and asked for it twice, and almost all the time it took us up the branch when we asked for it the second time. It is clear that reading the 101st record is much more expensive than just the 1st of the tablet. We exhaled for a while. They said: “Now, Neo, you know kung fu! Now our experience is right on your screen. Now you can use it. ” [article]
We exhaled for a while. They said: “Now, Neo, you know kung fu! Now our experience is right on your screen. Now you can use it. ” [article]Log Consolidation
Our 1000 developers breathed a sigh of relief. But we understood that we only have hundreds of “battle” servers, and all this “copy-paste” by the developers is not at all convenient. We realized that we needed to collect it ourselves. In general, there is a regular module that can collect statistics, however, it also needs to be activated in the config - this is the pg_stat_statements module . But he did not suit us.Firstly, it assigns different QueryId to the same queries on different schemes within the same database . That is, if you first make
In general, there is a regular module that can collect statistics, however, it also needs to be activated in the config - this is the pg_stat_statements module . But he did not suit us.Firstly, it assigns different QueryId to the same queries on different schemes within the same database . That is, if you first make SET search_path = '01'; SELECT * FROM user LIMIT 1;, and then SET search_path = '02';the same request, then there will be different entries in the statistics of this module, and I will not be able to collect general statistics precisely in the context of this request profile, without taking into account the schemes.The second point that prevented us from using it is the lack of plans . That is, there is no plan, there is only the request itself. We see what was slowing down, but we don’t understand why. And here we return to the problem of a rapidly changing dataset.And the last point is the lack of "facts . " That is, it is impossible to address a specific instance of query execution - it is not there, there are only aggregated statistics. Although it’s possible to work with it, it’s just very difficult.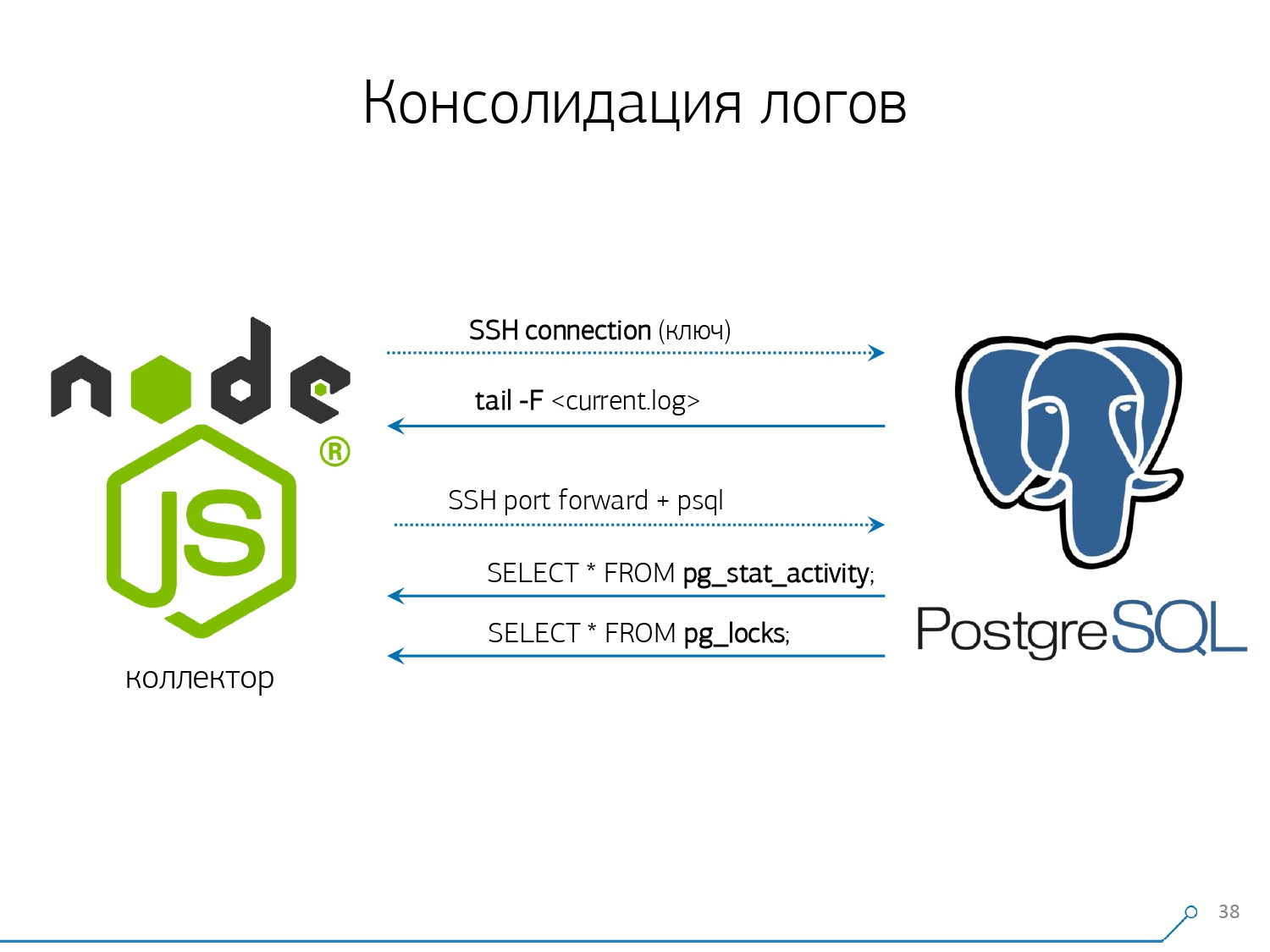 Therefore, we decided to fight “copy-paste” and began to write a collector .The collector is connected via SSH, “pulls” a secure connection to the server with the database using the certificate and
Therefore, we decided to fight “copy-paste” and began to write a collector .The collector is connected via SSH, “pulls” a secure connection to the server with the database using the certificate and tail -F“clings” to it to the log file. So in this sessionwe get a complete “mirror” of the entire log file that the server generates. The load on the server itself is minimal, because we do not parse anything there, we simply mirror the traffic.Since we already started writing the interface on Node.js, we continued to write the collector on it. And this technology paid off, because it’s very convenient to use JavaScript to work with poorly formatted text data, which is the log. And the Node.js infrastructure itself as a backend platform allows you to easily and conveniently work with network connections, and indeed with some kind of data streams.Accordingly, we “pull” two connections: the first is to “listen” to the log itself and take it to ourselves, and the second is to periodically ask the database. “But in the log it arrived that the plate with oid 123 was blocked,” but it doesn’t say anything to the developer, and it would be nice to ask the base “What is OID = 123 after all?” And so we periodically ask the base for something that we don’t know at home yet. “You just didn’t take into account, there is a kind of elephant-like bees! ..” We started to develop this system when we wanted to monitor 10 servers. The most critical in our understanding, on which there were some problems that were difficult to deal with. But during the first quarter we got a hundred for monitoring - because the system “went in”, everyone wanted it, everyone was comfortable.All this must be added, the data stream is large, active. Actually, we monitor what we are able to deal with - then we use it. We also use PostgreSQL as a data warehouse. But nothing is faster to “pour” data into it than
“You just didn’t take into account, there is a kind of elephant-like bees! ..” We started to develop this system when we wanted to monitor 10 servers. The most critical in our understanding, on which there were some problems that were difficult to deal with. But during the first quarter we got a hundred for monitoring - because the system “went in”, everyone wanted it, everyone was comfortable.All this must be added, the data stream is large, active. Actually, we monitor what we are able to deal with - then we use it. We also use PostgreSQL as a data warehouse. But nothing is faster to “pour” data into it than COPYthere is no operator yet.But just “pouring” the data is not really our technology. Because if you have about 50k requests per second on a hundred servers, then this will generate 100-150GB of logs per day for you. Therefore, we had to carefully “saw” the base.Firstly, we did the partitioning every day , because, by and large, nobody is interested in the correlation between the days. What is the difference that you had yesterday, if tonight you rolled out a new version of the application - and already some new statistics.Secondly, we learned (were forced) to write very, very quickly usingCOPY . That is, not just COPYbecause it is faster than INSERT, but even faster. The third point - I had to abandon the triggers, respectively, and from Foreign Keys . That is, we do not have absolutely referential integrity. Because if you have a table on which there is a pair of FK, and you say in the database structure that “here is a log entry refers to FK, for example, a group of records”, then when you insert it, PostgreSQL has nothing left how to take and honestly execute
The third point - I had to abandon the triggers, respectively, and from Foreign Keys . That is, we do not have absolutely referential integrity. Because if you have a table on which there is a pair of FK, and you say in the database structure that “here is a log entry refers to FK, for example, a group of records”, then when you insert it, PostgreSQL has nothing left how to take and honestly execute SELECT 1 FROM master_fk1_table WHERE ...with the identifier that you are trying to insert - just to check that this entry is there, that you are not "breaking off" this Foreign Key with your insert.We get instead of one record in the target table and its indices, another plus of reading from all the tables to which it refers. And we don’t need it at all - our task is to write down as much as possible and as quickly as possible with the least load. So FK - down!The next point is aggregation and hashing. Initially, they were implemented in the database with us - after all, it’s convenient to immediately, when the record arrives, make “plus one” in some kind of plate right in the trigger . It’s good, convenient, but the same thing is bad - insert one record, but you are forced to read and write something else from another table. Moreover, not only that, read and write - and also do it every time.Now imagine that you have a plate in which you simply count the number of requests that passed on a particular host:+1, +1, +1, ..., +1. And you, in principle, do not need it - all this can be summed up in the memory on the collector and sent to the database at a time +10.Yes, your logical integrity may “fall apart” in case of some problems, but this is almost an unrealistic case - because you have a normal server, it has a battery in the controller, you have a transaction log, a log on the file system ... In general, not worth it. It’s not worth the loss of productivity that you get due to the work of triggers / FK, the costs that you incur at the same time.Same thing with hashing. A certain request flies to you, you compute a certain identifier from the database from it, write to the database and then tell it to everyone. All is well, until at the time of recording a second person comes to you who wants to record it - and you have a lock, and this is already bad. Therefore, if you can take out the generation of some IDs on the client (relative to the database), it is better to do this.We were just ideally suited to use MD5 from the text - a request, plan, template, ... We calculate it on the collector side, and “pour” the already prepared ID into the database. MD5 length and daily partitioning allow us not to worry about possible collisions.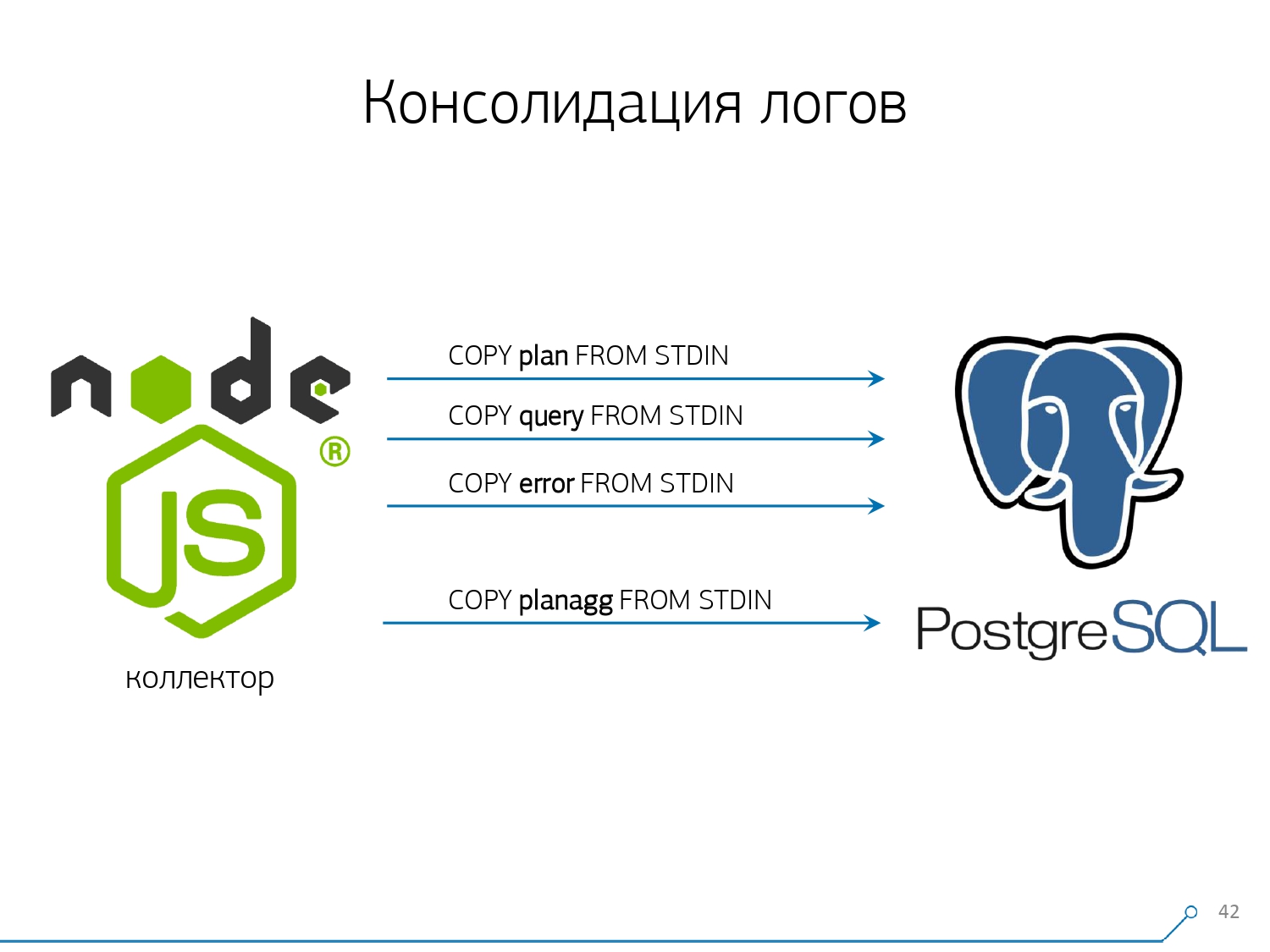 But in order to record all this quickly, we needed to modify the recording procedure itself.How do you usually write data? We have some kind of dataset, we decompose it into several tables, and then COPY - first in the first, then in the second, in the third ... It is inconvenient, because we kind of write one data stream in three steps sequentially. Unpleasant. Is it possible to do faster? Can!To do this, it is enough just to decompose these flows in parallel with each other. It turns out that we have errors, requests, templates, locks, flying in separate streams ... - and we write it all in parallel. To do this, just keep the COPY channel permanently open on each individual target table .
But in order to record all this quickly, we needed to modify the recording procedure itself.How do you usually write data? We have some kind of dataset, we decompose it into several tables, and then COPY - first in the first, then in the second, in the third ... It is inconvenient, because we kind of write one data stream in three steps sequentially. Unpleasant. Is it possible to do faster? Can!To do this, it is enough just to decompose these flows in parallel with each other. It turns out that we have errors, requests, templates, locks, flying in separate streams ... - and we write it all in parallel. To do this, just keep the COPY channel permanently open on each individual target table . That is, the collector always has a streaminto which I can write the data I need. But so that the database sees this data, and someone does not hang in the locks, waiting for this data to be written, COPY must be interrupted at a certain frequency . For us, a period of the order of 100ms turned out to be the most effective - close and immediately open it again on the same table. And if we don’t have one stream at some peaks, then we do pooling to a certain limit.In addition, we found out that for such a load profile, any aggregation when records are collected in packets is evil. Classical evil is
That is, the collector always has a streaminto which I can write the data I need. But so that the database sees this data, and someone does not hang in the locks, waiting for this data to be written, COPY must be interrupted at a certain frequency . For us, a period of the order of 100ms turned out to be the most effective - close and immediately open it again on the same table. And if we don’t have one stream at some peaks, then we do pooling to a certain limit.In addition, we found out that for such a load profile, any aggregation when records are collected in packets is evil. Classical evil is INSERT ... VALUESbeyond 1000 records. Because at this moment you have a peak recording on the media, and everyone else who is trying to write something to disk will wait.To get rid of such anomalies, simply do not aggregate anything, do not buffer at all . And if buffering to disk does occur (fortunately, the Stream API in Node.js allows you to find out) - postpone this connection. That's when the event comes to you that it is free again - write to it from the accumulated queue. In the meantime, it’s busy - take the next free one from the pool and write to it.Before implementing this approach to data recording, we had approximately 4K write ops, and in this way we reduced the load by 4 times. Now they have grown another 6 times due to new observable bases - up to 100MB / s. And now we store logs for the last 3 months in the amount of about 10-15TB, hoping that in just three months any developer can solve any problem.We understand the problems
But just collecting all this data is good, useful, appropriate, but not enough - you need to understand it. Because it’s millions of different plans per day. But millions are uncontrollable, you must first do "less." And, first of all, it is necessary to decide how you will organize this “smaller” one.We have identified for ourselves three key points:
But millions are uncontrollable, you must first do "less." And, first of all, it is necessary to decide how you will organize this “smaller” one.We have identified for ourselves three key points:- who sent this request.
That is, from which application he “flew”: web-interface, backend, payment system or something else. - where did this happen
On which particular server. Because if you have several servers under one application, and suddenly one “blunted” (because the “disk has rotted”, “memory leaked”, some other trouble), then you need to specifically address the server. - how the problem manifested itself in one way or another
To understand “who” sent us the request, we use a regular tool - setting a session variable: SET application_name = '{bl-host}:{bl-method}';- send the host name of the business logic from which the request is made, and the name of the method or application that initiated it.After we passed the “owner” of the request, it must be displayed in the log - for this we configure the variable log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Anyone interested can see in the manual what this all means. It turns out that we see in the log:- time
- process and transaction identifiers
- base name
- IP of the person who sent this request
- and method name
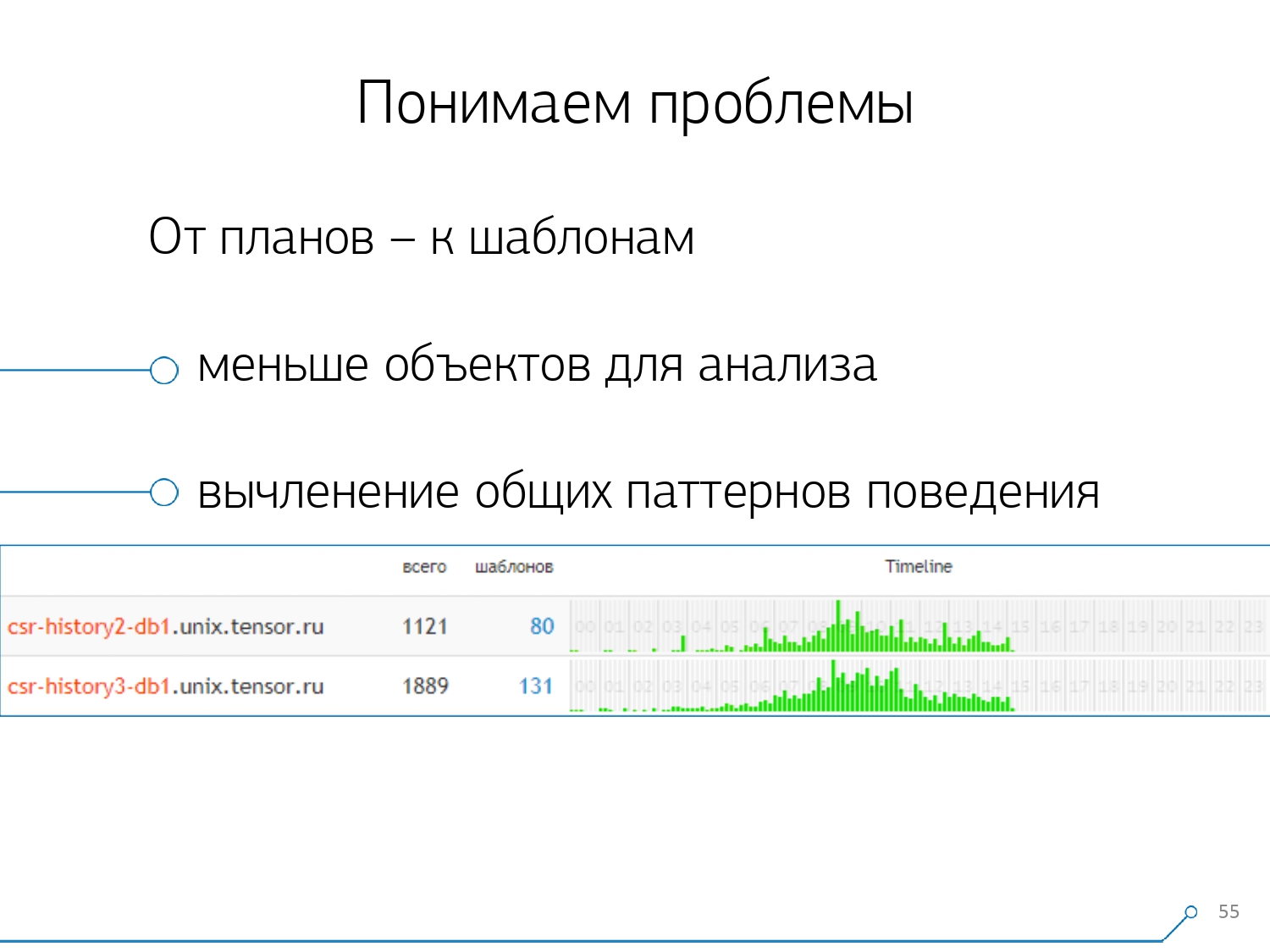 Then we realized that it is not very interesting to look at the correlation of one request between different servers. It happens infrequently when you have one application that equally craps here and there. But even if it is the same, look at any of these servers.So, the “one server - one day” section turned out to be enough for any analysis.The first analytical section is the very “template” - an abbreviated form of presentation of the plan, cleared of all numerical indicators. The second section is the application or method, and the third is the specific node of the plan that caused us problems.When we moved from specific instances to templates, we immediately received two advantages:
Then we realized that it is not very interesting to look at the correlation of one request between different servers. It happens infrequently when you have one application that equally craps here and there. But even if it is the same, look at any of these servers.So, the “one server - one day” section turned out to be enough for any analysis.The first analytical section is the very “template” - an abbreviated form of presentation of the plan, cleared of all numerical indicators. The second section is the application or method, and the third is the specific node of the plan that caused us problems.When we moved from specific instances to templates, we immediately received two advantages:
, .
, «» - , . , - , , , — , , — , , . , , .
 The remaining methods are based on the indicators that we extract from the plan: how many times such a template occurred, the total and average time, how much data was read from the disk, and how much from the memory ...Because you, for example, come to the analytics page by host, see - something too much on the disk to read the beginning. The disk on the server does not cope - and who reads from it?And you can sort by any column and decide what you will deal with right now - with the load on the processor or the disk, or with the total number of requests ... Sorted, looked “top”, repaired - rolled out a new version of the application.[video lecture]And right away you can see different applications that come with the same template from a request like
The remaining methods are based on the indicators that we extract from the plan: how many times such a template occurred, the total and average time, how much data was read from the disk, and how much from the memory ...Because you, for example, come to the analytics page by host, see - something too much on the disk to read the beginning. The disk on the server does not cope - and who reads from it?And you can sort by any column and decide what you will deal with right now - with the load on the processor or the disk, or with the total number of requests ... Sorted, looked “top”, repaired - rolled out a new version of the application.[video lecture]And right away you can see different applications that come with the same template from a request likeSELECT * FROM users WHERE login = 'Vasya'. Frontend, backend, processing ... And you wonder why the user should read the processing if he does not interact with him.The opposite way is to immediately see from the application what it is doing. For example, a frontend is this, this, this, and this once an hour (just the timeline helps). And immediately the question arises - it seems to be not the business of the front-end to do something once an hour ... After some time, we realized that we lacked aggregated statistics in terms of plan nodes . We isolated from the plans only those nodes that do something with the data of the tables themselves (read / write them by index or not). In fact, relative to the previous picture, only one aspect is added - how many records this node brought to us , and how many it dropped (Rows Removed by Filter).You do not have a suitable index on the plate, you make a request to it, it flies past the index, falls into Seq Scan ... you have filtered out all the records except one. And why do you need 100M filtered records per day, is it better to roll the index?
After some time, we realized that we lacked aggregated statistics in terms of plan nodes . We isolated from the plans only those nodes that do something with the data of the tables themselves (read / write them by index or not). In fact, relative to the previous picture, only one aspect is added - how many records this node brought to us , and how many it dropped (Rows Removed by Filter).You do not have a suitable index on the plate, you make a request to it, it flies past the index, falls into Seq Scan ... you have filtered out all the records except one. And why do you need 100M filtered records per day, is it better to roll the index? Having examined all the plans by nodes, we realized that there are some typical structures in the plans that are very likely to look suspicious. And it would be nice to tell the developer: “Friend, here you first read by index, then sort it, and then cut it off” - as a rule, there is one record.Everyone who wrote queries with this pattern probably came across: “Give me the last order for Vasya, his date” And if you do not have an index by date, or the index used does not have a date, then go exactly on such a “rake” and step on .But we know that this is a "rake" - so why not immediately tell the developer what he should do. Accordingly, opening the plan now, our developer immediately sees a beautiful picture with prompts, where he is immediately told: "You have problems here and here, but they are solved this way."As a result, the amount of experience that was needed to solve problems in the beginning and now has fallen significantly. Here we have such a tool.
Having examined all the plans by nodes, we realized that there are some typical structures in the plans that are very likely to look suspicious. And it would be nice to tell the developer: “Friend, here you first read by index, then sort it, and then cut it off” - as a rule, there is one record.Everyone who wrote queries with this pattern probably came across: “Give me the last order for Vasya, his date” And if you do not have an index by date, or the index used does not have a date, then go exactly on such a “rake” and step on .But we know that this is a "rake" - so why not immediately tell the developer what he should do. Accordingly, opening the plan now, our developer immediately sees a beautiful picture with prompts, where he is immediately told: "You have problems here and here, but they are solved this way."As a result, the amount of experience that was needed to solve problems in the beginning and now has fallen significantly. Here we have such a tool.
Source: https://habr.com/ru/post/undefined/
All Articles