There are good static analysis utilities for PHP: PHPStan, Psalm, Phan, Exakat. Linters do their job well, but very slowly, because almost all are written in PHP (or Java). For personal use or a small project, this is normal, but for a site with millions of users, this is a critical factor. A slow linter slows down the CI pipeline and makes it impossible to use it as a solution that can be integrated into a text editor or IDE. A site with millions of users is VKontakte. Development and addition of new functions, testing and fixing bugs, reviews - all this should go quickly, in the conditions of hard deadlines. Therefore, a good and fast linter that can check the code base for 5 million lines in 5-10 seconds is an irreplaceable thing. There are no suitable linters on the market, so Yuri Nasretdinov (youROCK) from VKontakte wrote his help to development teams - NoVerify. This is a linter for PHP, which is written in Go. It works 10-30 times faster than analogs, can find something that PhpStorm does not warn about, easily extends and integrates well into projects in which they have not heard of static analysis before. Iskander Sharipovwill tell about this linter . Under the cat: how to choose a linter and prefer to write your own, why NoVerify is so fast and how it is arranged inside, why it is written in Go, what it can find and how it expands, what compromises you had to make for it and what can be built on its basis.Iskander Sharipov (quasilyte) works in the backend infrastructure of VKontakte and is well acquainted with NoVerify. In the past, he was engaged in the Go-compiler in the Intel team. He doesn’t write in PHP, but this is his favorite language for static analysis - it has a lot of things that can go wrong.Note. To understand the background, read the article by Yuri Nasretdinov, the author of NoVerify on Habré, with a background and comparison with some existing linters, which are usually written in PHP. All statements in the direction of PHP (in the article by Yuri and here) are a joke. Iskander loves PHP, everyone loves PHP.
A site with millions of users is VKontakte. Development and addition of new functions, testing and fixing bugs, reviews - all this should go quickly, in the conditions of hard deadlines. Therefore, a good and fast linter that can check the code base for 5 million lines in 5-10 seconds is an irreplaceable thing. There are no suitable linters on the market, so Yuri Nasretdinov (youROCK) from VKontakte wrote his help to development teams - NoVerify. This is a linter for PHP, which is written in Go. It works 10-30 times faster than analogs, can find something that PhpStorm does not warn about, easily extends and integrates well into projects in which they have not heard of static analysis before. Iskander Sharipovwill tell about this linter . Under the cat: how to choose a linter and prefer to write your own, why NoVerify is so fast and how it is arranged inside, why it is written in Go, what it can find and how it expands, what compromises you had to make for it and what can be built on its basis.Iskander Sharipov (quasilyte) works in the backend infrastructure of VKontakte and is well acquainted with NoVerify. In the past, he was engaged in the Go-compiler in the Intel team. He doesn’t write in PHP, but this is his favorite language for static analysis - it has a lot of things that can go wrong.Note. To understand the background, read the article by Yuri Nasretdinov, the author of NoVerify on Habré, with a background and comparison with some existing linters, which are usually written in PHP. All statements in the direction of PHP (in the article by Yuri and here) are a joke. Iskander loves PHP, everyone loves PHP.Product Development
In VKontakte, this is a website development on KPHP. Speed is important for VKontakte: fixing bugs, adding and developing new functions from the first phase to the last. But speed is accompanied by errors , especially when there are hard deadlines - we are in a hurry, nervous and make more mistakes than in a calm situation.Errors affect users . We do not want them to suffer, therefore we control quality. But quality control slows down development . This we also do not want, so the effect must be minimized.To do this, we could conduct more code reviews without fail, hire more testersand write more tests. But all this is poorly automated: the review must be done, and the tests must be written.The main tasks of my team are different.Collect metrics, analyze and quickly repair . If something went wrong, we want to quickly roll it back, understand what’s wrong, fix it and quickly add the working code back to production.Monitor the rigor of the pipeline so that non-working code doesn’t get into production at all - you don’t need to roll it back. Here linters come to the rescue - static code analyzers. We’ll talk about this.Choose a linter
Let's choose a linter that we add to the pipeline. We take a simple approach - we formulate the requirements.Linter should work fast . There are several steps in our pipeline: the operation of the linter should not take much time and time-consuming developer, while he is waiting for feedback.Support for "their" checks . Most likely, the linter does not have everything we need - we will have to add our own checks. They should find problems typical of our code base, check the code from the point of view of our project. Not all of this can be (or conveniently) covered by tests.Support for “own” checks. We can write many tests, but will they be well supported? For example, if we write on regular expressions, they will become more complicated when you need to take into account the context, semantics and syntax of the language. Therefore, tests are not an option.Most of the linters we reviewed are written in PHP. But they do not pass on demand. Linters in PHP (there is no AOT compilation yet) work 10-20 times slower than in other languages - our largest file can be analyzed for tens of seconds. This slows down the workflow too much and too much — this is a fatal flaw . What do developers do in this case? They write their own.Therefore, we wrote our NoVerify PHP linter on Go. Why on it? Spoiler: not only because Jura decided so.Noverify
Go is a good compromise between development speed and productivity.
The first "proof" in the picture with "infographics": good execution speed, easy support. We lose in speed of development, but the first two points are more important to us.The figures are taken from the head, they are not backed up by anything.For the second “evidence”, he argued more simply.PHP is slower, Go is faster, and so on. We chose Go for three reasons.Go as a language for utilities is easy to learn at a basic level . In the PHP development team, for sure, someone heard about Go, looked at Docker, knows that it is written in Go, maybe even saw the source. With a basic understanding, after one or two weeks of intensive Go learning, they will be able to write code on it.Go is quite effective . Even a beginner will not be able to make many mistakes, because Go has good tuning and a lot of linter. In Go, the average code is slightly better than in other languages, because there are much fewer ways to shoot your own leg.Go apps are easy to maintain.Go is a fairly mature programming language for which almost all the developer tools that you can wish for are available.We will verify NoVerify with our requirements.- NoVerify is several times faster than alternatives .
- For it, you can write extensions , both Open Source, and your own. It is important that we can separate these checks, and you can write your own.
- Easy to test and develop. Partly, because the standard Go distribution has a standard framework with profiling and testing. It is mainly used for unit testing. Particularly dexterous can be used for integration, as we do - we have integration testing written through Go tests.
Compromise of Integration
Let's start with the problem. When you start any linter for the first time on an old project that did not use any analysis, you will most likely see this. Oh my code! No one will ever correct so many mistakes. I want to close the project, remove the linter and never run it again. What to do to avoid this?
Oh my code! No one will ever correct so many mistakes. I want to close the project, remove the linter and never run it again. What to do to avoid this?Integrate
Run in diff mode . We do not want to run all checks on the whole project with a million errors at every CI step. Perhaps you know about baseline: in NoVerify, this is out of the box, you do not need to embed a separate utility. We immediately considered that such a regime was needed.Add legacy (vendors) to the exceptions . It’s easier not to touch some things, to leave aside even with a defect, so as not to modify it yourself and not leave a mark in history.We start with a subset of checks . You can not connect everything that includes style. To begin with, it finds real bugs: we’ll find, fix, and switch to something new.We collect feedback from colleagues. How to understand when it's time to turn on something else? Ask colleagues. As soon as they are glad that the errors have disappeared and almost nothing is found, turn on something else - it's time to work.Git setup
Diff mode means that you have a version control system - Git. If you have SVN, then the instruction will not help, go to Git.We install pre-push hook with a linter and check before we start the code. We check on the local machine with an option --no-verifyto bypass the linter . It would probably be more convenient to use a pre-receive hook and disable the server-side linter, but for historical reasons, a lot of things happen in VK in a pre-push hook, so NoVerify was built in there too.After the push, CI checks are launched. NoVerify has two modes of operation: with full analysis and without it. On CI, you most likely want (and can) run--git-full-diff- machines in CI can be loaded harder and check even those files that have not changed. On local machines, we can run a less strict, but faster analysis of only changed files (5-15 seconds faster). False positives
Consider the example below: in this function, something containing a field is accepted, but the type is not described in any way. It is not a fact that there is a field at all when a function is called from different contexts. In a strict version, the linter could complain: “It is not clear what type it is, how can I return a field without checks?” But this is not necessarily a mistake.function get_foo($obj) {
return $obj->foo;
^^^
}
Warning:
Property "foo" does not exist
False positives interfere.
This is the main reason for abandoning linter. People choose other options that find fewer errors, but produce fewer false positives.They often push around when something worked, but this is not a mistake. Many have a mechanism to bypass linter - to run with the flag without checking the linter. In our country, this flag was called no-verifya pre-push hook. We often used it and the name was immortalized in the name of the linter.Pickiness
Another linter property. For example, many do not understand aliases. In PHP, sizeofthis is an analogue count: it does not calculate the size, but returns the number of elements. The mental model of C developers has a sizeofdifferent meaning. If in the code base there is sizeof, most likely, mean count. But this is nitpicking.$len = sizeof($x);
^^^^^^
Warning:
use "count" instead of "sizeof"
What to do with it?
Be strict and force to rule everything without exception . To impose rules, to demand, to observe and not to allow them to circumvent - never works. For such rigidity to work, the team must consist of the same people: character, level of culture, pedantry and perception of the quality of the code. If this is not so, there will be a riot. It’s easier to assemble a team from your clones than to force to follow all the rules. Do not block push / commit on comments like fixing sizeofon count. Most likely, this is not an error, but a nit-picking and does not affect the code. But then 99% of the responses will be ignored (by the team) and there will always be extra ones in the code sizeof.Allow some level of configuration for different teams and developers.You can configure the configuration for each command so that those who do not want to change sizeofto countcan not do this. Let everyone else follow the rules. A good option, but the consistency will sag, and in some directories the code will be slightly worse.Run such checks once a month, on subbotniks . Checks can be run not every time on the CI or pre-push hook, but in the routine Cron once a month. Run and edit everything you find after active development. But this work requires resources for automation and verification.Do nothing. Turning off stylistic checks is also an option.Compromise
 There will always be a compromise between a happy developer and a happy linter. It is easy to make a linter happy: the most strict mode and the lack of workarounds. Perhaps after that no one will remain in the team, so if the linter interferes with the work, this is a problem.
There will always be a compromise between a happy developer and a happy linter. It is easy to make a linter happy: the most strict mode and the lack of workarounds. Perhaps after that no one will remain in the team, so if the linter interferes with the work, this is a problem.Useful action above all.
NoVerify Technical Details
Private checks VKontakte. Noverify is written something like this. In GitHub, the NoVerify repository is divided into two parts: the framework that is used to implement the linter, and separate checks, vklints . This is done so that the linter loads third-party checks: you can write a separate module on Go and they register themselves in the framework. After starting from the NoVerify binary, the framework loads all the registered sets of checks and they work as a whole. 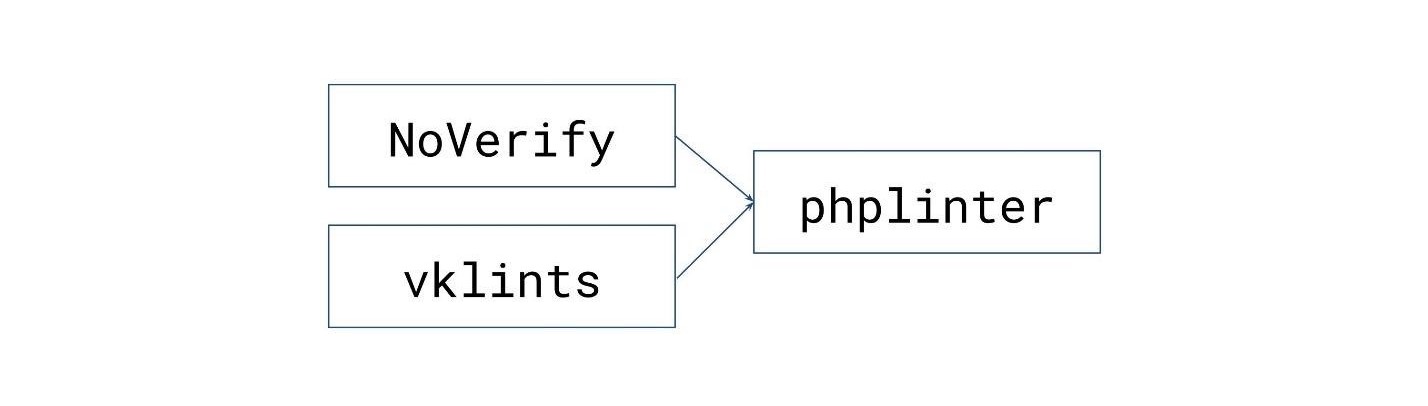 NoVerify is both a library and a binary (linter).Our checks are called vklints . They find that they do not see PhpStorm and Open Source NoVerify - important errors that are not suitable for general use.What is vklints?Checking the specifics of using certain functions , classes, and even global variables that do not follow our conventions. This is something that cannot be used in special places for various reasons described in the style guide.Additional style checks. They do not correspond to what is accepted in the PHP-community, are not described in the PHP Standard Recommendation or even contradict it, but for us it is the standard. There is no point in adding them to Open Source because you don’t want to follow them.Strict comparison requirements for some types . For example, we have a check that requires comparing strings with a comparison operator
NoVerify is both a library and a binary (linter).Our checks are called vklints . They find that they do not see PhpStorm and Open Source NoVerify - important errors that are not suitable for general use.What is vklints?Checking the specifics of using certain functions , classes, and even global variables that do not follow our conventions. This is something that cannot be used in special places for various reasons described in the style guide.Additional style checks. They do not correspond to what is accepted in the PHP-community, are not described in the PHP Standard Recommendation or even contradict it, but for us it is the standard. There is no point in adding them to Open Source because you don’t want to follow them.Strict comparison requirements for some types . For example, we have a check that requires comparing strings with a comparison operator ===. In particular, it requires passing a flag for strict comparison of functions in order to compare strings.Suspicious array keys.Another interesting mistake: sometimes, when developers commit, they can press key combinations before saving the file. These characters sometimes remain in a string or in a piece of code. Once, in the key of the array was the Russian letter “Y”. Most likely, the developer pressed CTRL-S in the Russian layout, saved the file and committed. Sometimes we find such keys in arrays, but new errors will no longer pass.Dynamic rules are a simpler NoVerify extension mechanism described in PHP. A separate article has been written about this: how to add checks to NoVerify without writing a single line of Go code .How NoVerify Works
To parse PHP you need a parser . We cannot use the PHP parser in PHP: it is slow, from Go it can only be used through a wrapper in C. Therefore, we use the parser in Go.This parser has several problems. Unfortunately, he can only work with UTF-8 and we need to distinguish between UTF-8 and not UTF-8 . In addition to UTF-8, Windows-1251 is often found in Russian PHP projects. We also have such files. How do we recognize them? The file encodings.xmllists all the paths where the files with UTF-8 are. If we encounter a file outside these paths, then on the fly we stream to UTF-8 by streaming stream (without converting in advance).Parsing and analysis
Completed in a few steps. On the first - we load metadata from phpstorm-stubs . This is data that looks like PHP code, but is never executed and describes the types of inputs / outputs from standard functions. The phpStorm metadata has a useful override directive for the linter ... It allows us to describe, for example, that we accept an array of type T[]and return the type array_pop).Phpstorm-stubs is loaded first. We use metadata as the initial type information - the foundation. This foundation is absorbed by the linter and we begin to analyze the sources.We load the current master before absorption. We check the code in two modes:- local changes : regarding baseline we find new errors in the code;
- we indicate the range of revisions : the first and last revisions, and between them everything is inclusive - this is the new code, and everything that “before” is old.
Next comes the analysis stage.AST analysis . We now have metadata, type information. We take all the PHP-source, parsim and analyze directly above the AST - we do not have an intermediate representation at the moment. Analyzing a raw AST is not very convenient, especially if you depend on the libraries and data types that it represents. The analysis results are stored in the cache . It is used in reanalysis, which is much faster.Reports and filtering . Then we generate reports or warnings twice : first we find warnings for the old version of the code (before baseline), then for the new one. Reports are filtered by comparison (diff) - we look for warnings that appeared in the new version of the code and pass them to the user. In some static analyzers, this is called “baseline mode”.Double code analysis (in diff mode) is very slow. But we can afford it - NoVerify is still dozens of times faster than other PHP linkers. At the same time, it has a reserve for additional acceleration, at least by 30 percent.How do we analyze files? In PHP, you can call a function before it is defined - you need to know the information about this function before analyzing it. Therefore, first we go through the entire file in AST, index it, identify the types of all functions, register the classes, and only then analyze it. Analysis is the second pass through the file . Most interpreters and compilers also work with two passes and more. In order not to “scan” the file a second time, you must have declarations before use, as in C, for example.Type inference
The most interesting part is that errors are most often encountered here. It still does not correspond to the correctness of the PHP type system, which is difficult to define formally.What does the model look like.Semantic model (demo).Types of types:- Expected is what we describe in the comments. We expect some types in the program, but this does not mean that they are really used in it.
- Actual - real ones that are in the program. For example, if we assign a number to something, then it is obvious that
intor float(if this is a floating-point number) will be Actual types.
Actual types seem to be "stronger" - they are real, true. But sometimes we can get a type only by annotation.Annotations (in Expected types) can be divided into two categories: trust and distrust . For example, phpstorm-stubs belong to the first category. They are considered moderated (without errors) before we use them. Unreliable ones are those that other developers write, because they may have errors.Actual types can also be divided into several parts: values, assertion, predicates and type hint, which extends the capabilities of PHP 7. But there is a problem that type hint does not solve.Expected vs Actual
Let's say a class Foohas an inheritor. From the descendant class, we can call methods that are not in Foo, because the descendant extends the parent. But if we get the heir Foofrom new static()with this annotation of the return type (from self), then a problem will arise. We can call this method, but the IDE will not prompt you - you need to specify static(). This is a late static binding in PHP , when not the Fooclass inheritor can return . class Foo {
public function newStatic() : self {
return new static();
}
}
When we write new static(), not only the class can return new Foo. For example, if a Fooclass is inherited from bar, then there may be new bar. Accordingly, we need at least two type information. None of them are redundant - both are needed.Therefore, the Actual type here will be self- for the PHP interpreter. But for the IDE and for the linters to work, we need static. If we call this code from the context of the heir class, we need to know the information that this is not the same base class and it has more methods.class Foo {
public function newStatic() : self {
return new static();
}
}
Type hint
Static typing and type hint are not the same thing.
You may have heard that you can only check at the boundaries of functions. At the borders, we check the inputs and outputs, where the input is the function arguments. Inside the function, you can do any nonsense: assign a foovalue int, although you described what it is T. You can complain that you are violating the types that you declared, but for PHP there is no error . declare(strict_types=1);
function f(T $foo) {
$foo = 10;
return $foo;
}
An example is more difficult - we return foo? At the beginning of the function, we determined that fooit was T, and there is no information about the return. declare(strict_types=1);
function f(T $foo) {
$foo = 10;
return $foo;
}
Which type is correct? The first two, we will analyze the difference between them. PhpStorm and linter output the second option. Despite the fact that it always returns int, the type T|intis deduced - the "union" of types. This is a type that can be assigned both of these values: first we had information about the type T, then we assigned it 10, so the type of the variable foomust be compatible with these two types.Annotations
Comments and annotations may lie.
In the example below, we wrote that we are returning a number, but returning a string. If the linter worked only at the level of annotations and type hint, then we would consider that it always returns int. But Actual types just help get away from this: here, the Expected type is this int, and the Actual type is a string. Linter knows that the string is returned and may warn you that you promised to return int. This separation is important to us.
function f() { return "I lied!"; }
Inheritance of annotations. Here, I mean that a class that implements some kind of interface has a method. The method has good comments, documentation, types - it is needed to implement the interface. But there are no comments in the implementation: there is only @inheritdocor nothing at all.interface IFoo {
public function foo();
}
class Fooer implements IFoo {
public function foo() { return "10"; }
}
What returns this method? It seems that what is described in the - interface is returned int, but in fact a string. This is not good: PHP is all the same, but convergence is important to us.There are two options to fix this code. The obvious is to returnint . But perhaps you need to return a different type. What to do? Write that we return the string . In this case, explicit type information is necessary for both the IDE and the linter in order to correctly analyze the code.interface IFoo {
public function foo();
}
class Fooer implements IFoo {
public function foo() { return "10"; }
}
This information would not be needed at all if people wrote comments, not @inheritdoc. It is not necessary for PhpStorm to understand what types you have. But if the types are not described correctly, there will be a problem.PhpStorm and the linter have sets of disjoint bugs when we use the same files for metadata (types). If we fix everything we need in phpstorm-stubs from the JetBrains repository, then the IDE will most likely break. If you leave everything by default, not everything will work correctlyfor us. Therefore, we have a small fork - VKCOM / phpstorm-stubs . A couple of patches have been added to fix something that does not fit. I can not recommend it for PhpStorm, but it is necessary for the linter to work.Open source
Noverify is an open source project. It is posted on GitHub .Brief instructions "if something went wrong."If something is broken or does not start. The wrong reaction is to resent and remove NoVerify. The correct reaction: to issue a ticket on GitHub and talk about your problem. Most likely, it will be resolved in 1-2 days.You are missing some feature. Wrong reaction: remove NoVerify and write your own linter (although writing your own linter is always cool). The correct reaction: to issue a ticket on GitHub and, perhaps, we will add a new function. It is more complicated with features than with errors - a discussion arises, and each person has a different vision of the implementation in the team. But in the end, they are still being implemented.If you are interested in the development of the project or you just want to talk about static analysis, go to our chat room - noverify_linter .PHP-, , , , PHP Russia.
, . , , . telegram- @PHPRussiaConfChannel. , .