For years, experts in C ++ have been discussing the semantics of values, immutability, and resource sharing through communication. About a new world without mutexes and races, without Command and Observer patterns. In fact, everything is not so simple. The main problem is still in our data structures. Immutable data structures do not change their values. To do something with them, you need to create new values. The old values remain in the same place, so they can be read from different streams without problems and locks. As a result, resources can be shared more rationally and orderly, because old and new values can use common data. Thanks to this, they are much faster to compare with each other and compactly store the history of operations with the possibility of cancellation. All this fits perfectly on multi-threaded and interactive systems: such data structures simplify the architecture of desktop applications and allow services to scale better. Immutable structures are the secret to the success of Clojure and Scala, and even the JavaScript community now takes advantage of them, because they have the Immutable.js library,written in the bowels of the company Facebook.Under the cut - video and translation of the Juan Puente report from the C ++ Russia 2019 Moscow conference. Juan talks about Immer , a library of immutable structures for C ++. In the post:
Immutable data structures do not change their values. To do something with them, you need to create new values. The old values remain in the same place, so they can be read from different streams without problems and locks. As a result, resources can be shared more rationally and orderly, because old and new values can use common data. Thanks to this, they are much faster to compare with each other and compactly store the history of operations with the possibility of cancellation. All this fits perfectly on multi-threaded and interactive systems: such data structures simplify the architecture of desktop applications and allow services to scale better. Immutable structures are the secret to the success of Clojure and Scala, and even the JavaScript community now takes advantage of them, because they have the Immutable.js library,written in the bowels of the company Facebook.Under the cut - video and translation of the Juan Puente report from the C ++ Russia 2019 Moscow conference. Juan talks about Immer , a library of immutable structures for C ++. In the post:- architectural advantages of immunity;
- creation of an effective persistent vector type based on RRB trees;
- analysis of architecture on the example of a simple text editor.
The tragedy of value-based architecture
To understand the importance of immutable data structures, we discuss the semantics of values. This is a very important feature of C ++, I consider it one of the main advantages of this language. For all this, it is very difficult to use the semantics of values as we would like. I believe that this is the tragedy of value-based architecture, and the road to this tragedy is paved with good intentions. Suppose we need to write interactive software based on a data model with a representation of a user-editable document. When architecture based on the values at the heart of this model uses simple and convenient types of values that already exist in the language: vector, map, tuple,struct. Application logic is created from functions that take documents by value and return a new version of a document by value. This document may change inside the function (as it happens below), but the semantics of values in C ++, applied to the argument by value and the return type by value, ensure that there are no side effects.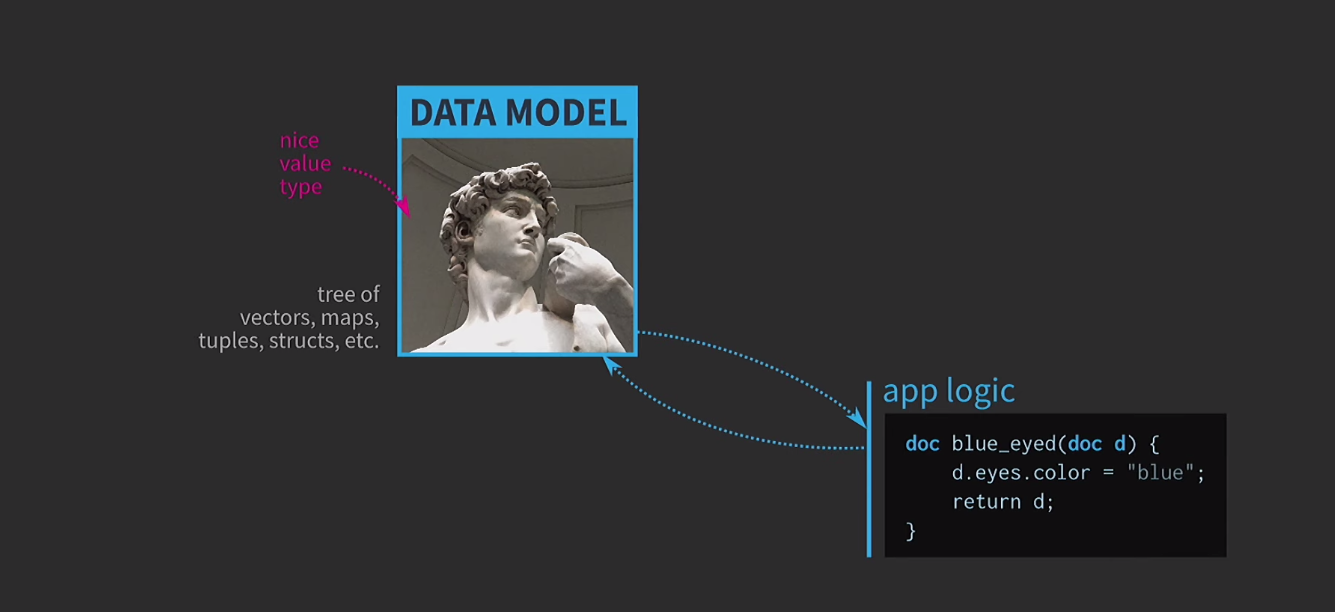 This feature is very easy to analyze and test.
This feature is very easy to analyze and test. Since we are working with values, we will try to implement the undo of the action. This can be difficult, but with our approach it is a trivial task: we have
Since we are working with values, we will try to implement the undo of the action. This can be difficult, but with our approach it is a trivial task: we have std::vectorwith different states various copies of the document.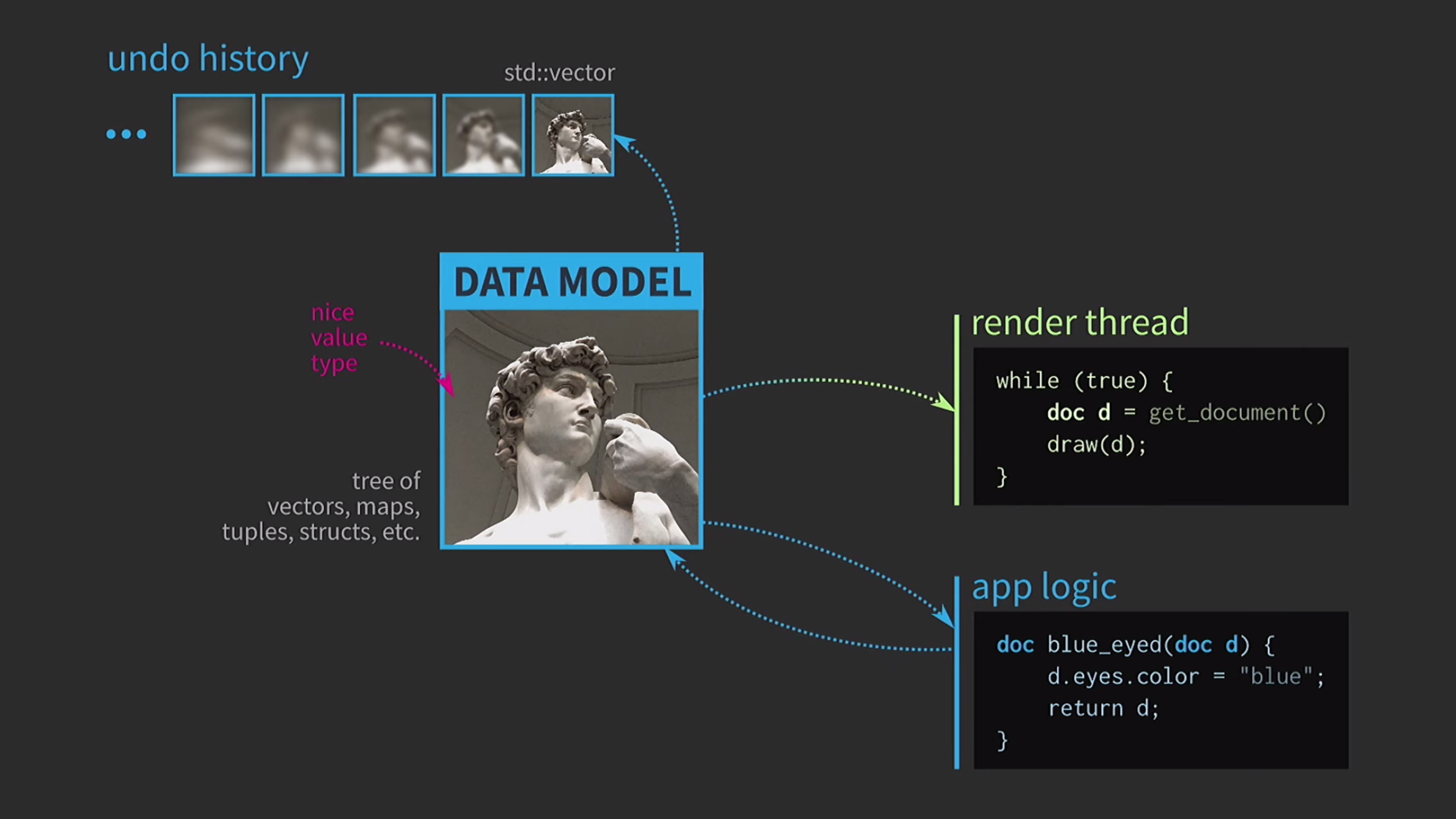 Suppose we also have a UI, and to ensure its responsiveness, the mapping of the UI needs to be done in a separate thread. The document is sent to another stream by message, and the interaction also takes place on the basis of messages, and not through the sharing of state using
Suppose we also have a UI, and to ensure its responsiveness, the mapping of the UI needs to be done in a separate thread. The document is sent to another stream by message, and the interaction also takes place on the basis of messages, and not through the sharing of state using mutexes. When the copy is received by the second stream, there you can perform all the necessary operations. Saving a document to disk is often very slow, especially if the document is large. Therefore, using
Saving a document to disk is often very slow, especially if the document is large. Therefore, using std::asyncthis operation is performed asynchronously. We use a lambda, put an equal sign inside it to have a copy, and now you can save without other primitive types of synchronization.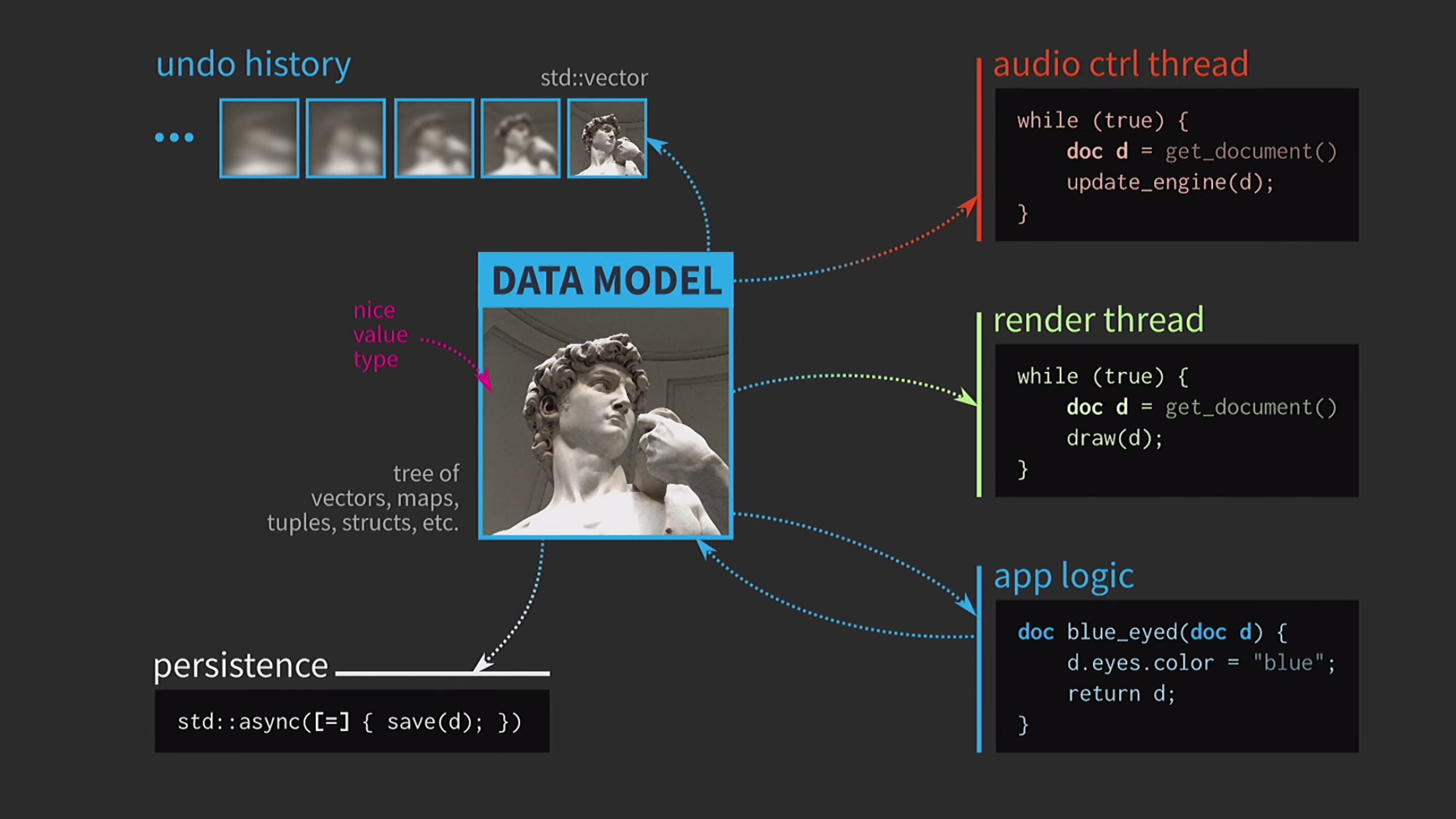 Further, suppose we also have a sound control flow. As I said, I worked a lot with music software, and sound is another representation of our document, it must be in a separate stream. Therefore, a copy of the document is also required for this stream.As a result, we got a very beautiful, but not too realistic scheme.
Further, suppose we also have a sound control flow. As I said, I worked a lot with music software, and sound is another representation of our document, it must be in a separate stream. Therefore, a copy of the document is also required for this stream.As a result, we got a very beautiful, but not too realistic scheme.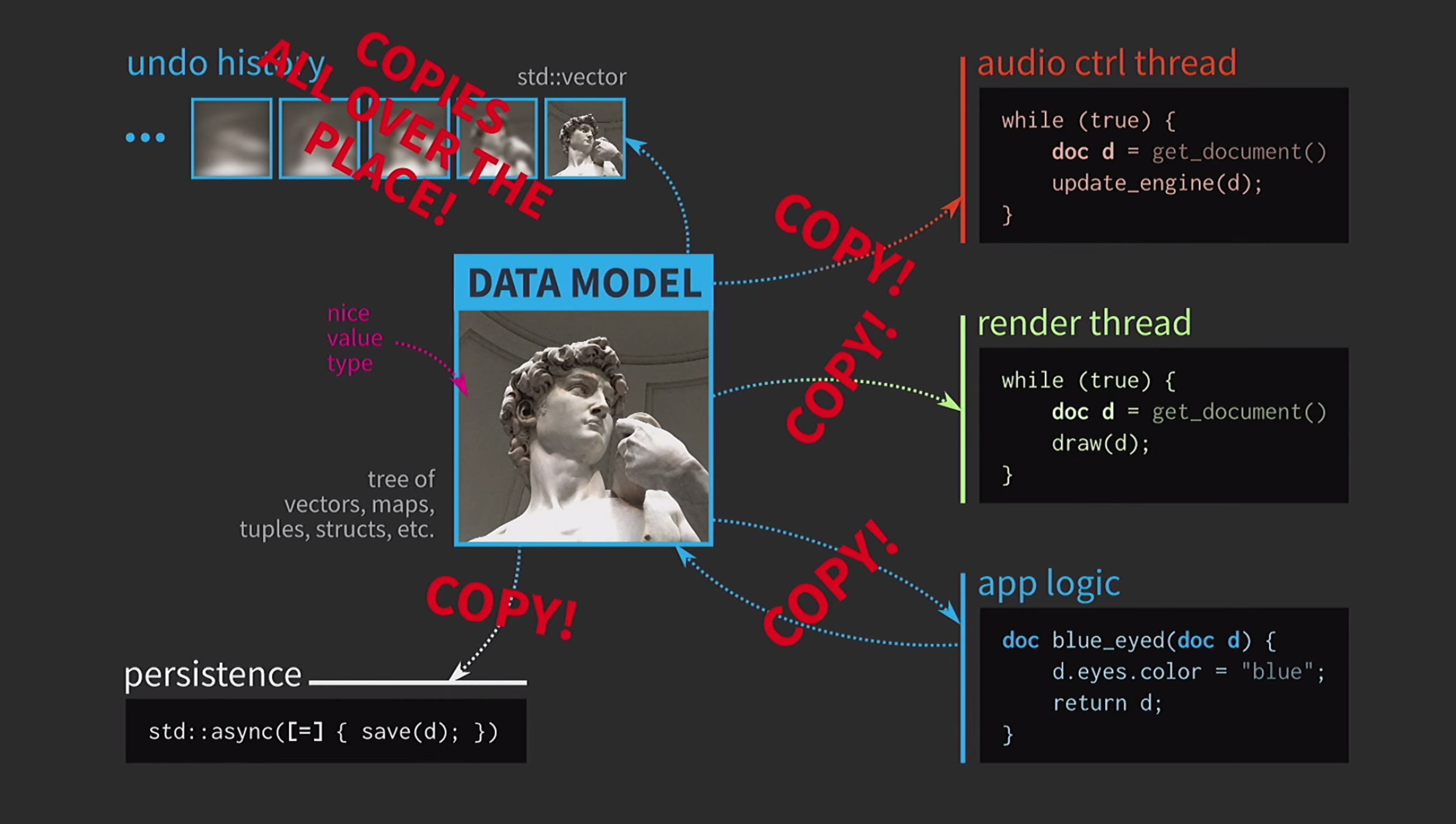 It constantly has to copy documents, the action history for cancellation takes gigabytes, and for each rendering of the UI you need to make a deep copy of the document. In general, all interactions are too costly.
It constantly has to copy documents, the action history for cancellation takes gigabytes, and for each rendering of the UI you need to make a deep copy of the document. In general, all interactions are too costly.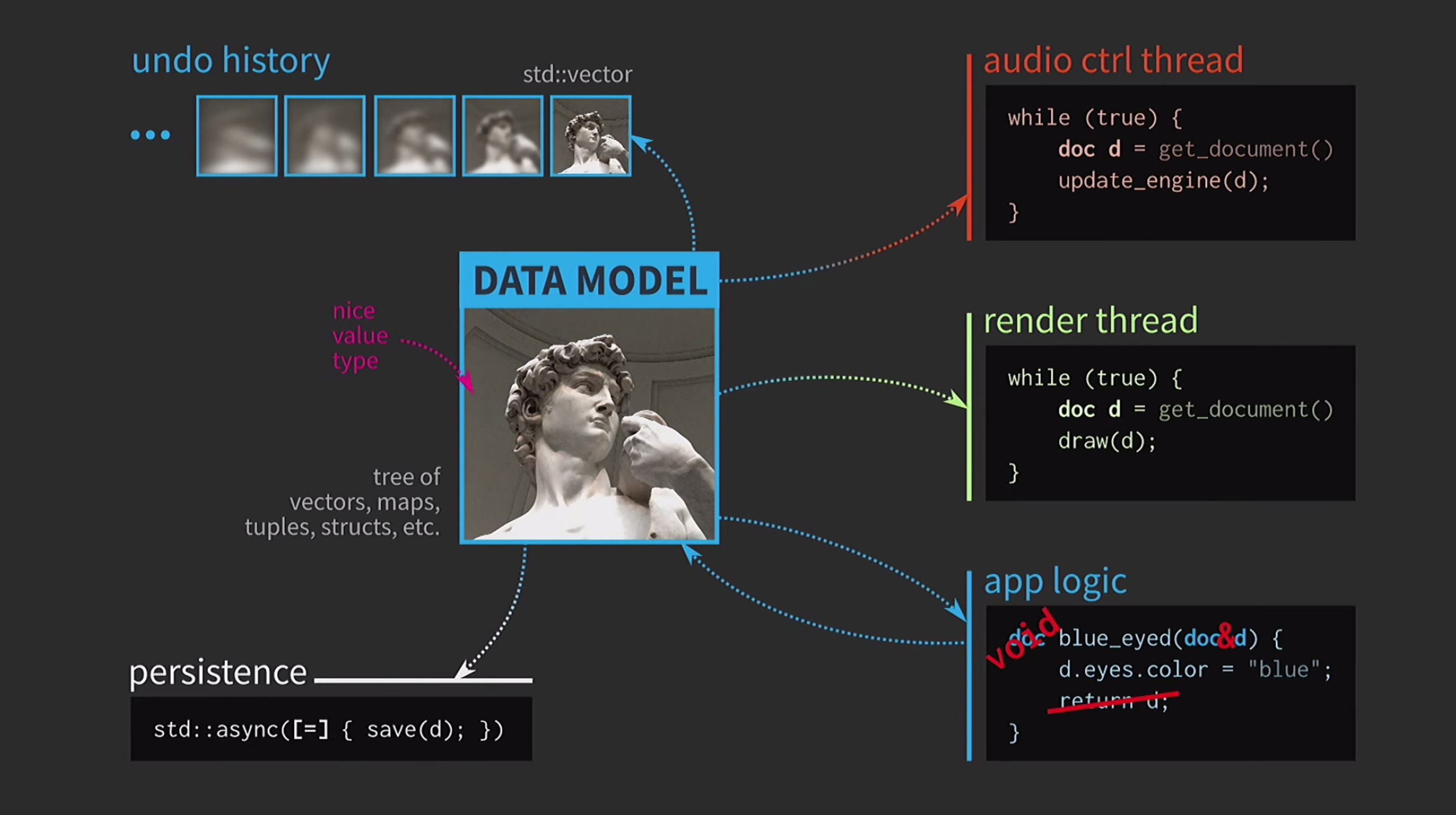 What is the C ++ developer doing in this situation? Instead of accepting a document by value, the application logic now accepts a link to the document and updates it if necessary. In this case, you do not need to return anything. But now we are not dealing with values, but with objects and locations. This creates new problems: if there is a link to the state with shared access, you need it
What is the C ++ developer doing in this situation? Instead of accepting a document by value, the application logic now accepts a link to the document and updates it if necessary. In this case, you do not need to return anything. But now we are not dealing with values, but with objects and locations. This creates new problems: if there is a link to the state with shared access, you need it mutex. This is extremely costly, so there will be some representation of our UI in the form of an extremely complex tree from various Widgets.All of these elements should receive updates when a document changes, so some queuing mechanism is needed for change signals. Further, the history of the document is no longer a set of states; it will be an implementation of the Team pattern. The operation must be implemented twice, in one direction and in the other, and make sure that everything is symmetrical. Saving in a separate thread is already too difficult, so this will have to be abandoned.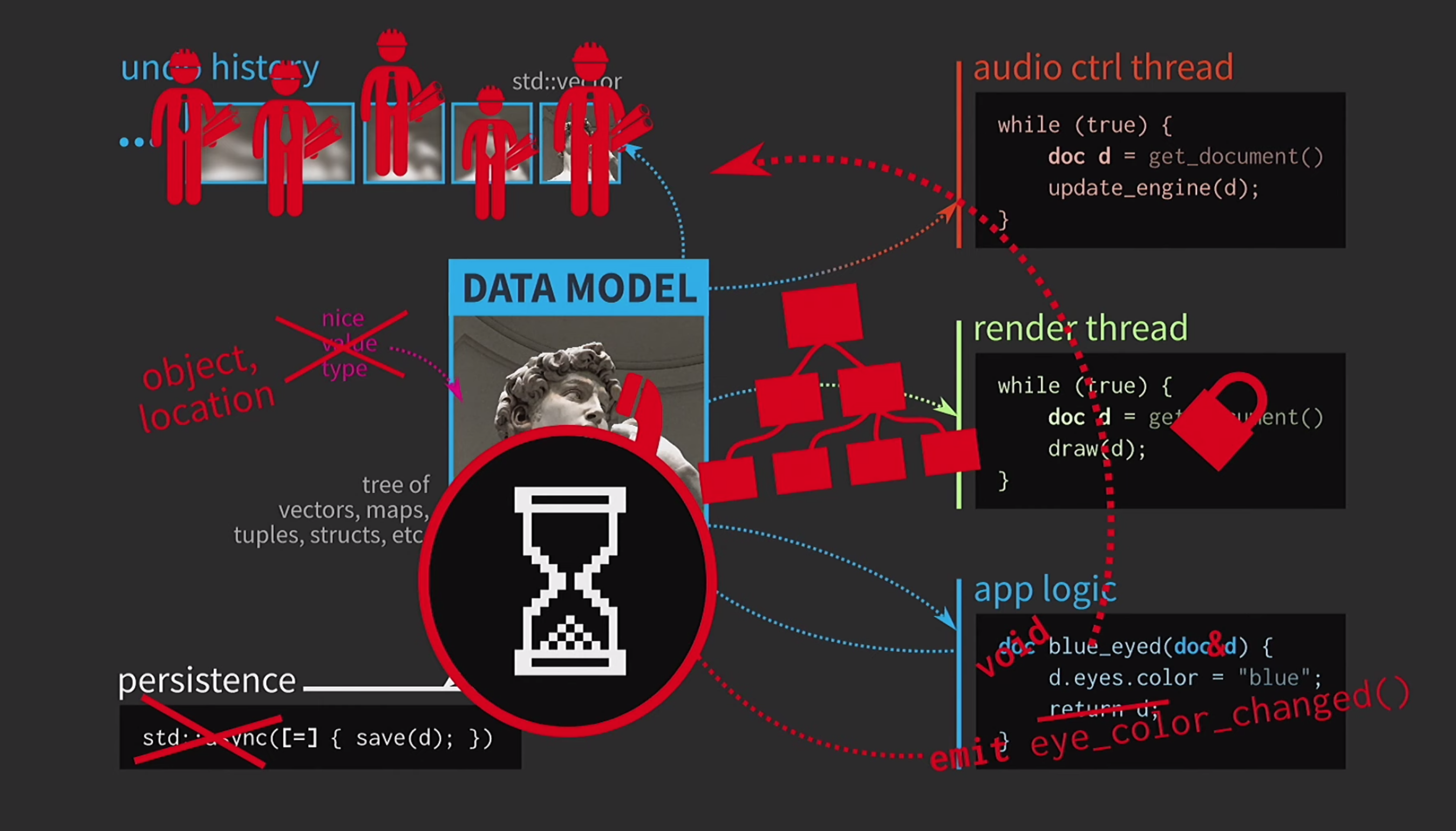 Users are already used to the hourglass picture, so it's okay if they wait a bit. Another thing is scary - the pasta monster now rules our code.At what point did everything go downhill? We designed our code very well, and then we had to compromise due to copying. But in C ++, copying is required to pass by value only for mutable data. If the object is immutable, then the assignment operator can be implemented so that it copies only the pointer to the internal representation and nothing more.
Users are already used to the hourglass picture, so it's okay if they wait a bit. Another thing is scary - the pasta monster now rules our code.At what point did everything go downhill? We designed our code very well, and then we had to compromise due to copying. But in C ++, copying is required to pass by value only for mutable data. If the object is immutable, then the assignment operator can be implemented so that it copies only the pointer to the internal representation and nothing more.const auto v0 = vector<int>{};
Consider a data structure that could help us. In the vector below, all methods are marked as const, so it is immutable. At execution .push_back, the vector does not update; instead, a new vector is returned, to which the transferred data is added. Unfortunately, we cannot use square brackets with this approach because of how they are defined. Instead, you can use the function.setwhich returns a new version with an updated item. Our data structure now has a property that is called persistence in functional programming. It means not that we save this data structure to the hard drive, but the fact that when it is updated, the old content is not deleted - instead, a new fork of our world is created, that is, the structure. Thanks to this, we can compare past values with present - this is done with the help of two assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
Changes can now be directly checked, they are no longer hidden properties of the data structure. This feature is especially valuable in interactive systems where we constantly have to change data.Another important property is structural sharing. Now we are not copying all the data for each new version of the data structure. Even with .push_backand.setnot all data is copied, but only a small part of it. All our forks have common access to a compact view, which is proportional to the number of changes, not the number of copies. It also follows that the comparison is very fast: if everything is stored in one memory block, in one pointer, then you can simply compare the pointers and not examine the elements that are inside them, if they are equal.Since such a vector, it seems to me, is extremely useful, I implemented it in a separate library: this is immer - a library of immutable structures, an open source project.When writing it, I wanted its use to be familiar to C ++ developers. There are many libraries that implement the concepts of functional programming in C ++, but it gives the impression that the developers write for Haskell, and not for C ++. This creates inconvenience. In addition, I achieved good performance. People use C ++ when available resources are limited. Finally, I wanted the library to be customizable. This requirement is related to the performance requirement.In search of a magic vector
In the second part of the report, we will consider how this immutable vector is structured. The easiest way to understand the principles of such a data structure is by starting with a regular list. If you are a little familiar with functional programming (using Lisp or Haskell as an example), you know that lists are the most common immutable data structures.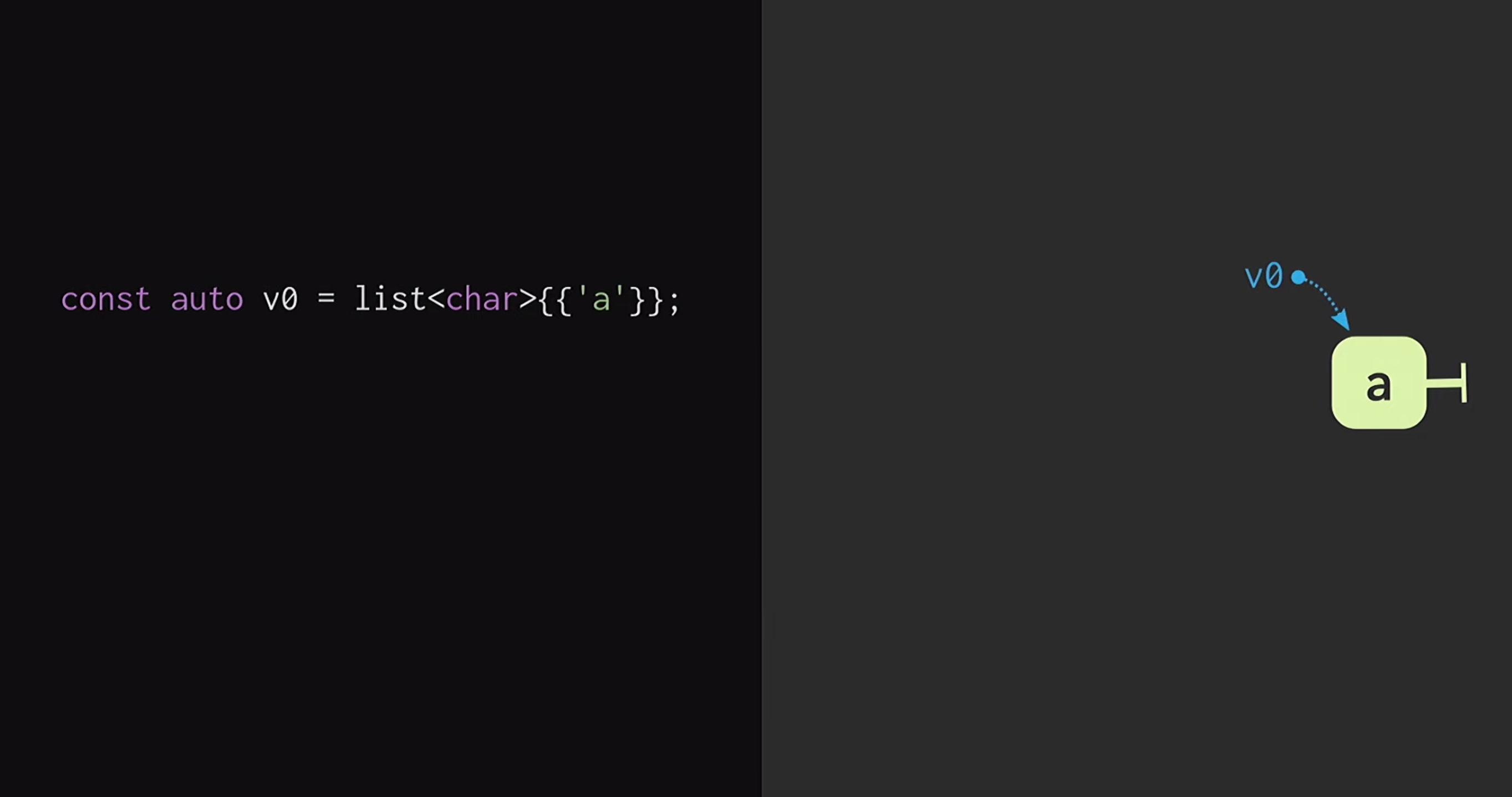 To begin, let us assume that we have a list with a single node
To begin, let us assume that we have a list with a single node v1they v0indicate different elements.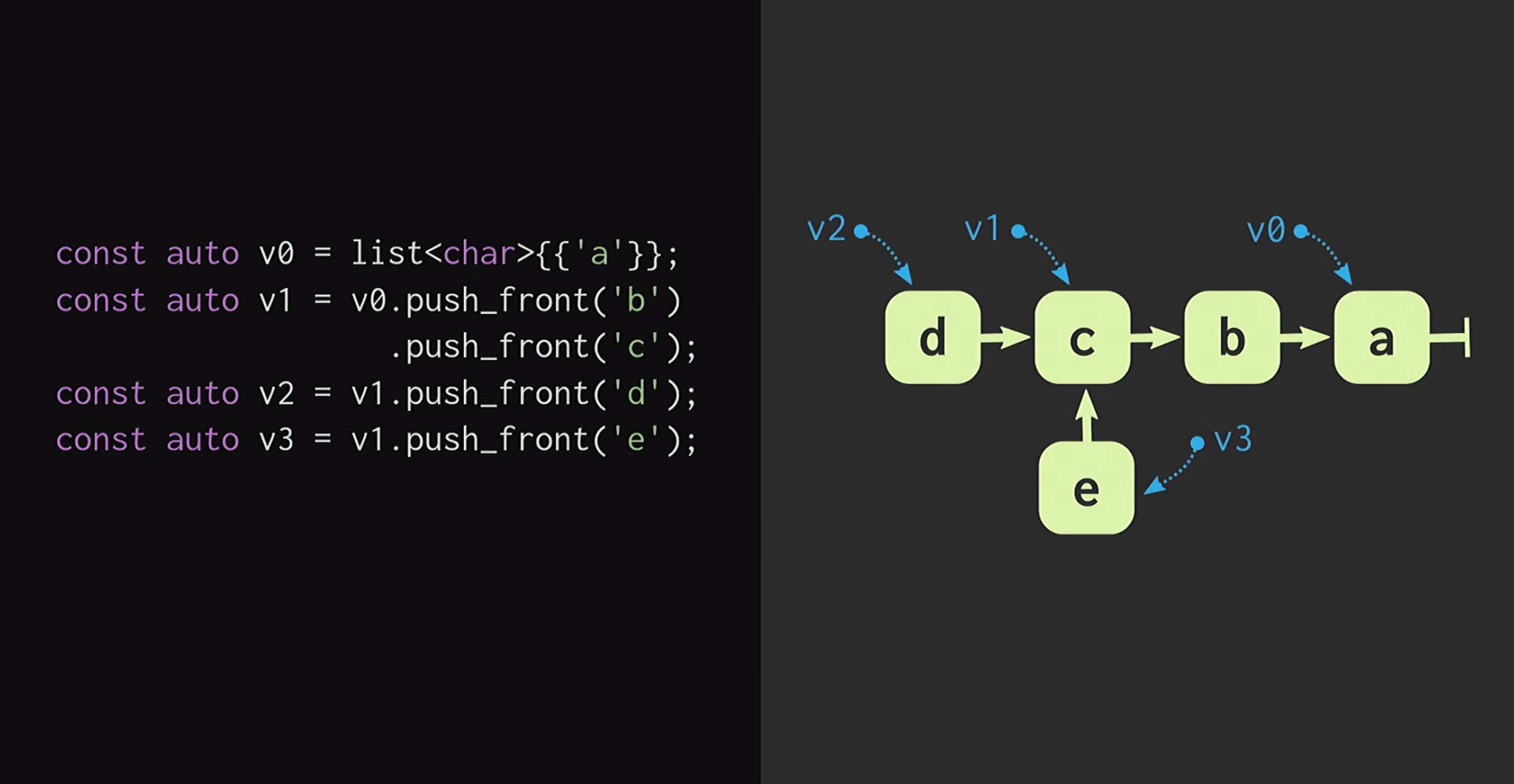 We can also create a fork of reality, that is, create a new list that has the same ending, but a different beginning.Such data structures have been studied for a long time: Chris Okasaki wrote the fundamental work of Purely Functional Data Structures . In addition, the Finger Tree data structure proposed by Ralf Hinze and Ross Paterson is very interesting . But for C ++, such data structures do not work well. They use small nodes, and we know that in C ++ small nodes mean a lack of caching efficiency.In addition, they often rely on properties that C ++ does not have, such as laziness. Therefore, the work of Phil Bagwell on immutable data structures is much more useful for us - a link written in the early 2000s, as well as the work of Rich Hickey - link, author of Clojure. Rich Hickey created a list, which is actually not a list, but based on modern data structures: vectors and hash maps. These data structures have caching efficiency and interact well with modern processors, for which it is undesirable to work with small nodes. Such structures can be used in C ++.How to build an immune vector? At the heart of any structure, even remotely resembling a vector, there must be an array. But the array does not have structural sharing. To change any element of the array, without losing the persistence property, you must copy the entire array. In order not to do this, the array can be split into separate pieces.Now, when updating a vector element, we need to copy only one piece, and not the entire vector. But such pieces themselves are not a data structure; they must be combined in one way or another. Put them in another array. Once again, the problem arises that the array can be very large, and then copying it again will take too much time.We divide this array into pieces, place them again in a separate array, and repeat this procedure until there is only one root array. The resulting structure is called a residual tree. This tree is described by the constant M = 2B, that is, the branching factor. This branch indicator should be a power of two, and we will very soon find out why. In the example on the slide, blocks of four characters are used, but in practice, blocks of 32 characters are used. There are experiments with which you can find the optimal block size for a particular architecture. This allows you to achieve the best ratio of structural shared access to access time: the lower the tree, the less access time.Reading this, developers writing in C ++ probably think: but any tree-based structures are very slow! Trees grow with an increase in the number of elements in them, and because of this, access times are degraded. That is why programmers prefer
We can also create a fork of reality, that is, create a new list that has the same ending, but a different beginning.Such data structures have been studied for a long time: Chris Okasaki wrote the fundamental work of Purely Functional Data Structures . In addition, the Finger Tree data structure proposed by Ralf Hinze and Ross Paterson is very interesting . But for C ++, such data structures do not work well. They use small nodes, and we know that in C ++ small nodes mean a lack of caching efficiency.In addition, they often rely on properties that C ++ does not have, such as laziness. Therefore, the work of Phil Bagwell on immutable data structures is much more useful for us - a link written in the early 2000s, as well as the work of Rich Hickey - link, author of Clojure. Rich Hickey created a list, which is actually not a list, but based on modern data structures: vectors and hash maps. These data structures have caching efficiency and interact well with modern processors, for which it is undesirable to work with small nodes. Such structures can be used in C ++.How to build an immune vector? At the heart of any structure, even remotely resembling a vector, there must be an array. But the array does not have structural sharing. To change any element of the array, without losing the persistence property, you must copy the entire array. In order not to do this, the array can be split into separate pieces.Now, when updating a vector element, we need to copy only one piece, and not the entire vector. But such pieces themselves are not a data structure; they must be combined in one way or another. Put them in another array. Once again, the problem arises that the array can be very large, and then copying it again will take too much time.We divide this array into pieces, place them again in a separate array, and repeat this procedure until there is only one root array. The resulting structure is called a residual tree. This tree is described by the constant M = 2B, that is, the branching factor. This branch indicator should be a power of two, and we will very soon find out why. In the example on the slide, blocks of four characters are used, but in practice, blocks of 32 characters are used. There are experiments with which you can find the optimal block size for a particular architecture. This allows you to achieve the best ratio of structural shared access to access time: the lower the tree, the less access time.Reading this, developers writing in C ++ probably think: but any tree-based structures are very slow! Trees grow with an increase in the number of elements in them, and because of this, access times are degraded. That is why programmers prefer std::unordered_map, rather than std::map. I hasten to reassure you: our tree grows very slowly. A vector containing all possible values of a 32-bit int is only 7 levels high. It can be experimentally shown that with this data size, the ratio of the cache to the load volume significantly affects performance than the depth of the tree.Let's see how an access to an element of a tree is performed. Suppose you need to turn to element 17. We take a binary representation of the index and divide it into groups the size of a branching factor. In each group, we use the corresponding binary value and thus go down the tree.Next, suppose we need to make a change in this data structure, that is, execute the method
In each group, we use the corresponding binary value and thus go down the tree.Next, suppose we need to make a change in this data structure, that is, execute the method .set.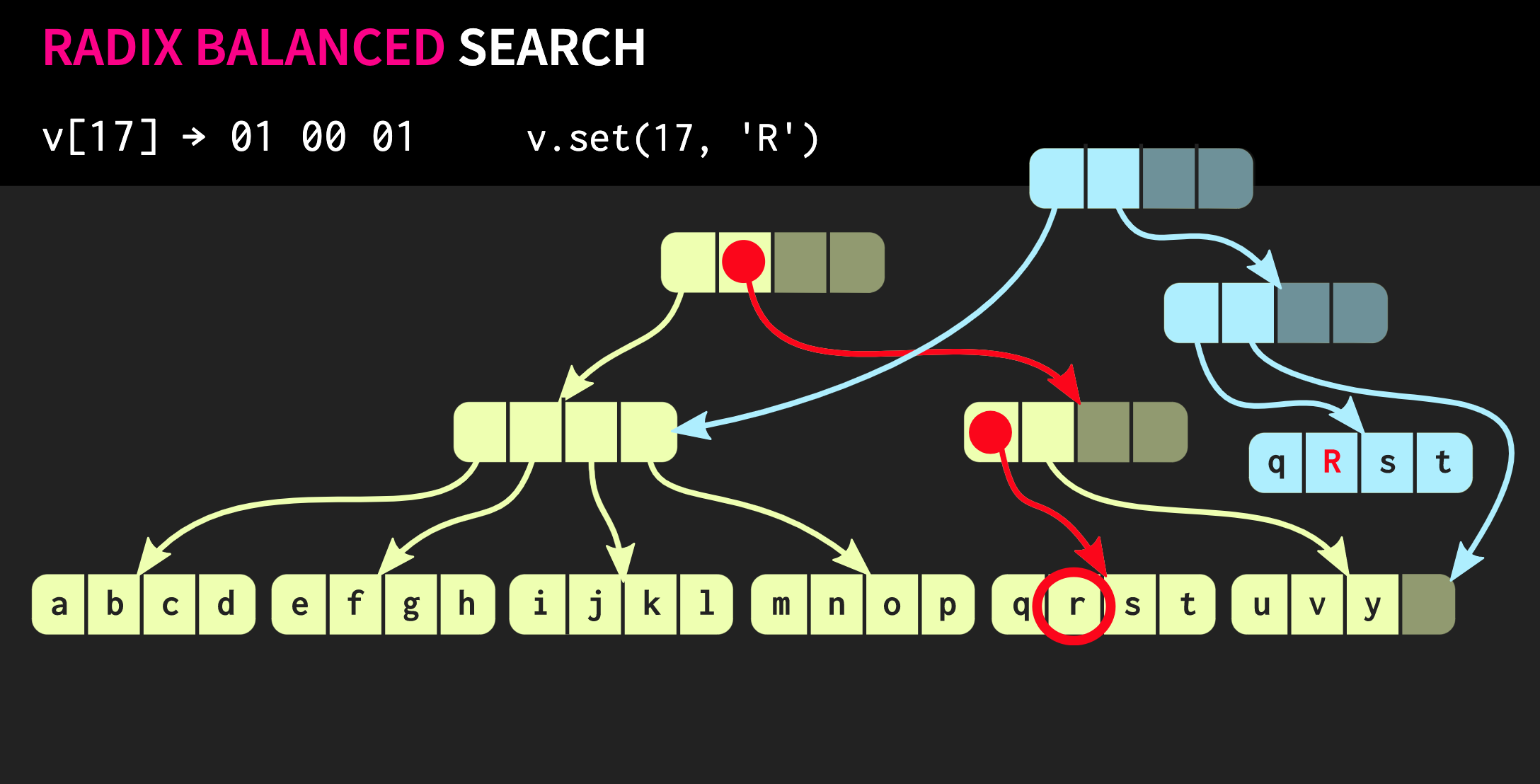 To do this, first you need to copy the block in which the element is located, and then copy each internal node on the way to the element. On the one hand, quite a lot of data has to be copied, but at the same time a significant part of this data is common, this compensates for their volume.By the way, there is a much older data structure that is very similar to the one I described. These are memory pages with a page table tree. Her management is also carried out using a call
To do this, first you need to copy the block in which the element is located, and then copy each internal node on the way to the element. On the one hand, quite a lot of data has to be copied, but at the same time a significant part of this data is common, this compensates for their volume.By the way, there is a much older data structure that is very similar to the one I described. These are memory pages with a page table tree. Her management is also carried out using a call fork.Let's try to improve our data structure. Suppose we need to connect two vectors. The data structure described so far has the same limitations std::vector:as it has empty cells in its rightmost part. Since the structure is perfectly balanced, these empty cells cannot be in the middle of the tree. Therefore, if there is a second vector that we want to combine with the first, we will need to copy the elements to empty cells, which will create empty cells in the second vector, and in the end we will have to copy the whole second vector. Such an operation has computational complexity O (n), where n is the size of the second vector.We will try to achieve a better result. There is a modified version of our data structure called relaxed radix balanced tree. In this structure, nodes that are not on the left-most path may have empty cells. Therefore, in such incomplete (or relaxed) nodes, it is necessary to calculate the size of the subtree. Now you can perform a complex but logarithmic join operation. This operation of constant time complexity is O (log (32)). Since the trees are shallow, the access time is constant, albeit relatively long. Due to the fact that we have such a union operation, a relaxed version of this data structure is called confluent: in addition to being persistent, and you can fork it, two such structures can be combined into one.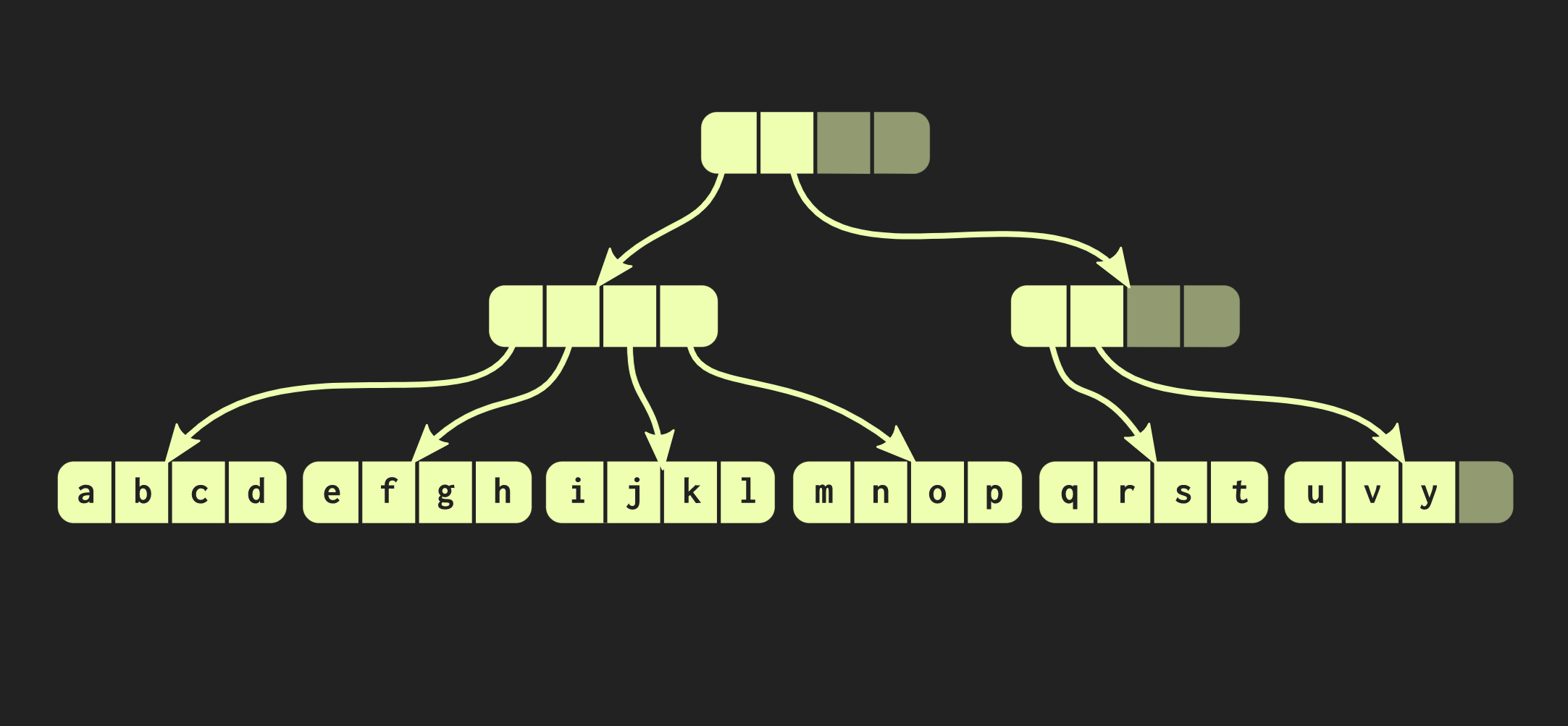 In the example that we have worked with so far, the data structure is very neat, but in practice, the implementations in Clojure and other functional languages look different. They create containers for each value, that is, each element in the vector is in a separate cell, and leaf nodes contain pointers to these elements. But this approach is extremely inefficient, in C ++ usually do not put every value in a container. Therefore, it would be better if these elements are located in nodes directly. Then another problem arises: different elements have different sizes. If the element is the same size as the pointer, our structure will look like the one shown below:
In the example that we have worked with so far, the data structure is very neat, but in practice, the implementations in Clojure and other functional languages look different. They create containers for each value, that is, each element in the vector is in a separate cell, and leaf nodes contain pointers to these elements. But this approach is extremely inefficient, in C ++ usually do not put every value in a container. Therefore, it would be better if these elements are located in nodes directly. Then another problem arises: different elements have different sizes. If the element is the same size as the pointer, our structure will look like the one shown below: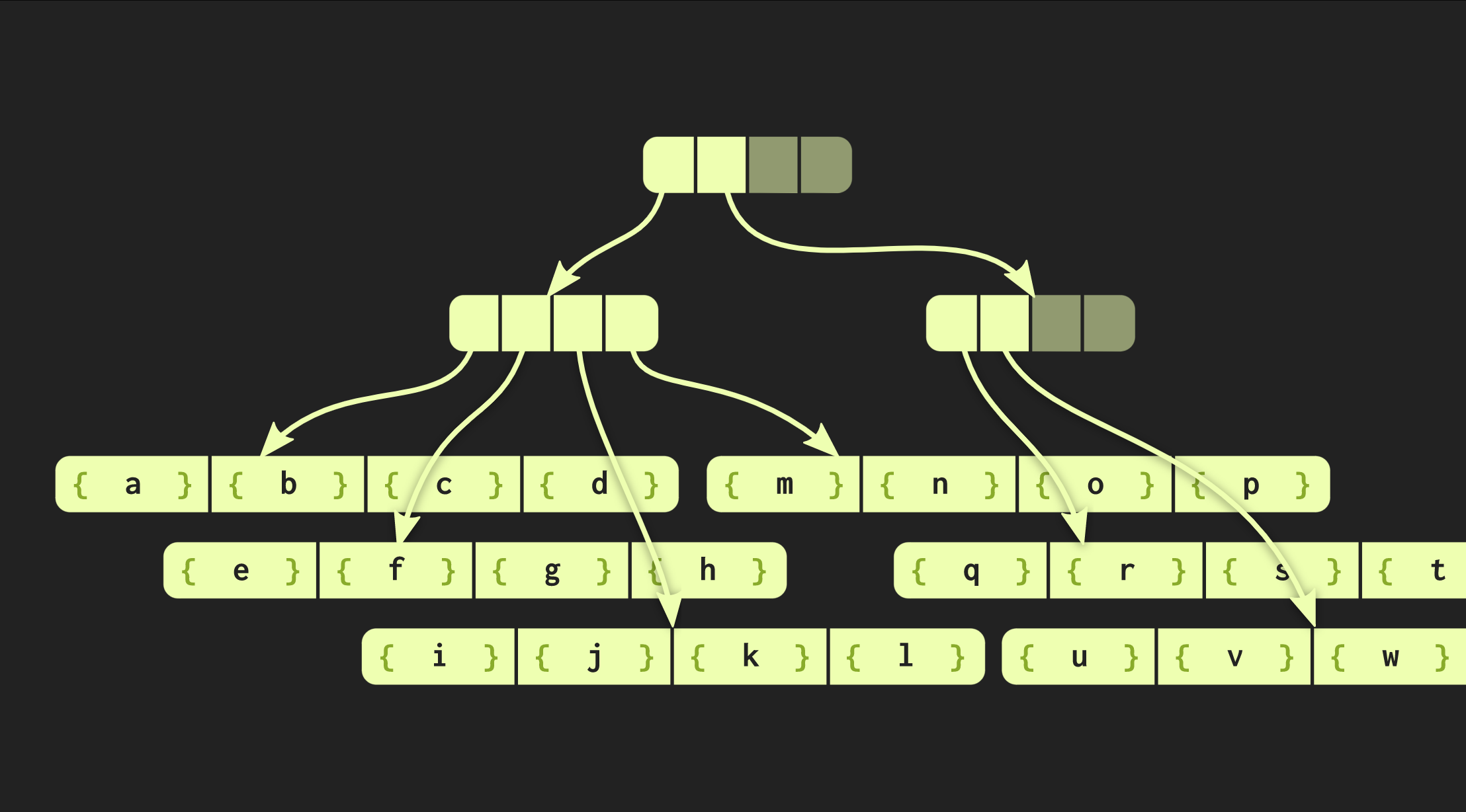 But if the elements are large, then the data structure loses the properties we measured (access time O (log (32) ()), because copying one of the sheets now takes longer. Therefore, I changed this data structure so that with increasing size the number of elements contained in it decreased the number of these elements in the leaf nodes.On the contrary, if the elements are small, they can now fit more.The new version of the tree is called embedding radix balanced tree.It is described not by one constant, but by two: one of them describes internal nodes, and the second - leafy .. Implementation of the tree in C ++ can calculate the optimal size of the leaf element depending on the size of the pointers and the elements themselves.Our tree is already working quite well, but it can still be improved. Take a look at a function similar to a function
But if the elements are large, then the data structure loses the properties we measured (access time O (log (32) ()), because copying one of the sheets now takes longer. Therefore, I changed this data structure so that with increasing size the number of elements contained in it decreased the number of these elements in the leaf nodes.On the contrary, if the elements are small, they can now fit more.The new version of the tree is called embedding radix balanced tree.It is described not by one constant, but by two: one of them describes internal nodes, and the second - leafy .. Implementation of the tree in C ++ can calculate the optimal size of the leaf element depending on the size of the pointers and the elements themselves.Our tree is already working quite well, but it can still be improved. Take a look at a function similar to a function iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
It takes an input vector, executes push_backat the end of the vector for each integer between firstand last, and returns what happened. Everything is in order with the correctness of this function, but it works inefficiently. Each call push_backcopies the leftmost block unnecessarily: the next call pushes another element and the copy is repeated again, and the data copied by the previous method is deleted.You can try another implementation of this function, in which we abandon persistence within the function. Can be used transient vectorwith a mutable API that is compatible with the regular API vector. Within such a function, each call push_backchanges the data structure.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
This implementation is more efficient, and it allows you to reuse new elements on the right path. At the end of the function, a call .persistent()is made that returns immutable vector. Possible side effects remain invisible from outside the function. The original one vectorwas and remains immutable, only the data created inside the function is changed. As I said, an important advantage of this approach is that you can use std::back_inserterstandard algorithms that require mutable APIs.Consider another example.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
The function does not accept and returns vector, but a call chain is executed inside push_back. Here, as in the previous example, unnecessary copying inside the call may occur push_back. Note that the first value that is executed push_backis the named value, and the rest is r-value, that is, anonymous links. If you use reference counting, the method push_backcan refer to reference counters for nodes for which memory is allocated in the tree. And in the case of r-value, if the number of links is one, it becomes clear that no other part of the program accesses these nodes. Here the performance is exactly the same as in the case with transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
Further, to help the compiler, we can execute it move(v), since it vis not used anywhere else in the function. We had an important advantage, which was not in the transientvariant: if we pass the returned value of another say_hi to the say_hi function, then there will be no extra copies. In the case of c, transientthere are boundaries at which excess copying can occur. In other words, we have a persistent, immutable data structure, the performance of which depends on the actual amount of shared access in runtime. If there is no sharing, then the performance will be the same as that of a mutable data structure. This is an extremely important property. The example that I already showed you above can be rewritten with a method move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
So far we have talked about vectors, and in addition to them there are also hash maps. They are dedicated to a very useful report by Phil Nash: The holy grail. A hash array mapped trie for C ++ . It describes hash tables implemented based on the same principles that I just talked about.I am sure many of you have doubts about the performance of such structures. Do they work quickly in practice? I have done many tests, and in short my answer is yes. If you want to learn more about the test results, they are published in my article for the International Conference of Functional Programming 2017. Now, I think, it is better to discuss not absolute values, but the effect that this data structure has on the system as a whole. Of course, updating our vector is slower because you need to copy several data blocks and allocate memory for other data. But bypassing our vector is performed at almost the same speed as a normal one. It was very important for me to achieve this, since reading data is performed much more often than changing it.In addition, due to the slower update, there is no need to copy anything, only the data structure is copied. Therefore, the time spent on updating the vector is, as it were, amortized for all copies performed in the system. Therefore, if you apply this data structure in an architecture similar to the one that I described at the beginning of the report, performance will increase significantly.Ewig
I will not be unfounded and demonstrate my data structure using an example. I wrote a small text editor. This is an interactive tool called ewig , in which documents are represented by immutable vectors. I have a copy of the entire Wikipedia in Esperanto saved on my disk, it weighs 1 gigabyte (at first I wanted to download the English version, but it is too big). Whatever text editor you use, I am sure that he will not like this file. And when you download this file in ewig , you can immediately edit it, because the download is asynchronous. File navigation works, nothing hangs, no mutex, no synchronization. As you can see, the downloaded file takes 20 million lines of code.Before considering the most important properties of this tool, let's pay attention to a funny detail. At the beginning of the line, highlighted in white at the bottom of the image, you see two hyphens. This UI is most likely familiar to emacs users; hyphens there mean that the document has not been modified in any way. If you make any changes, then asterisks are displayed instead of hyphens. But, unlike other editors, if you erase these changes in ewig (do not undo it, just delete it), then hyphens will be displayed instead of asterisks because all previous versions of the text are saved in ewig . Thanks to this, a special flag is not needed to show whether the document has been changed: the presence of changes is determined by comparison with the original document.Consider another interesting property of the tool: copy the entire text and paste it a couple of times in the middle of the existing text. As you can see, this happens instantly. Joining vectors here is a logarithmic operation, and the logarithm of several millions is not such a long operation. If you try to save this huge document to your hard drive, it will take much longer, because the text is no longer presented as a vector obtained from the previous version of this vector. When saving to disk, serialization occurs, so persistence is lost.
At the beginning of the line, highlighted in white at the bottom of the image, you see two hyphens. This UI is most likely familiar to emacs users; hyphens there mean that the document has not been modified in any way. If you make any changes, then asterisks are displayed instead of hyphens. But, unlike other editors, if you erase these changes in ewig (do not undo it, just delete it), then hyphens will be displayed instead of asterisks because all previous versions of the text are saved in ewig . Thanks to this, a special flag is not needed to show whether the document has been changed: the presence of changes is determined by comparison with the original document.Consider another interesting property of the tool: copy the entire text and paste it a couple of times in the middle of the existing text. As you can see, this happens instantly. Joining vectors here is a logarithmic operation, and the logarithm of several millions is not such a long operation. If you try to save this huge document to your hard drive, it will take much longer, because the text is no longer presented as a vector obtained from the previous version of this vector. When saving to disk, serialization occurs, so persistence is lost.Return to value-based architecture
 Let's start with how you can’t return to this architecture: using the usual Java-style Controller, Model and View, which are most often used for interactive applications in C ++. There is nothing wrong with them, but they are not suitable for our problem. On the one hand, the Model-View-Controller pattern allows for separation of tasks, but on the other, each of these elements is an object, both from an object-oriented point of view and from the point of view of C ++, that is, these are memory areas with mutable condition. View knows about Model; which is much worse - Model indirectly knows about View, because there is almost certainly a callback through which the View is notified when the Model changes. Even with the best implementation of object-oriented principles, we get a lot of mutual dependencies.
Let's start with how you can’t return to this architecture: using the usual Java-style Controller, Model and View, which are most often used for interactive applications in C ++. There is nothing wrong with them, but they are not suitable for our problem. On the one hand, the Model-View-Controller pattern allows for separation of tasks, but on the other, each of these elements is an object, both from an object-oriented point of view and from the point of view of C ++, that is, these are memory areas with mutable condition. View knows about Model; which is much worse - Model indirectly knows about View, because there is almost certainly a callback through which the View is notified when the Model changes. Even with the best implementation of object-oriented principles, we get a lot of mutual dependencies.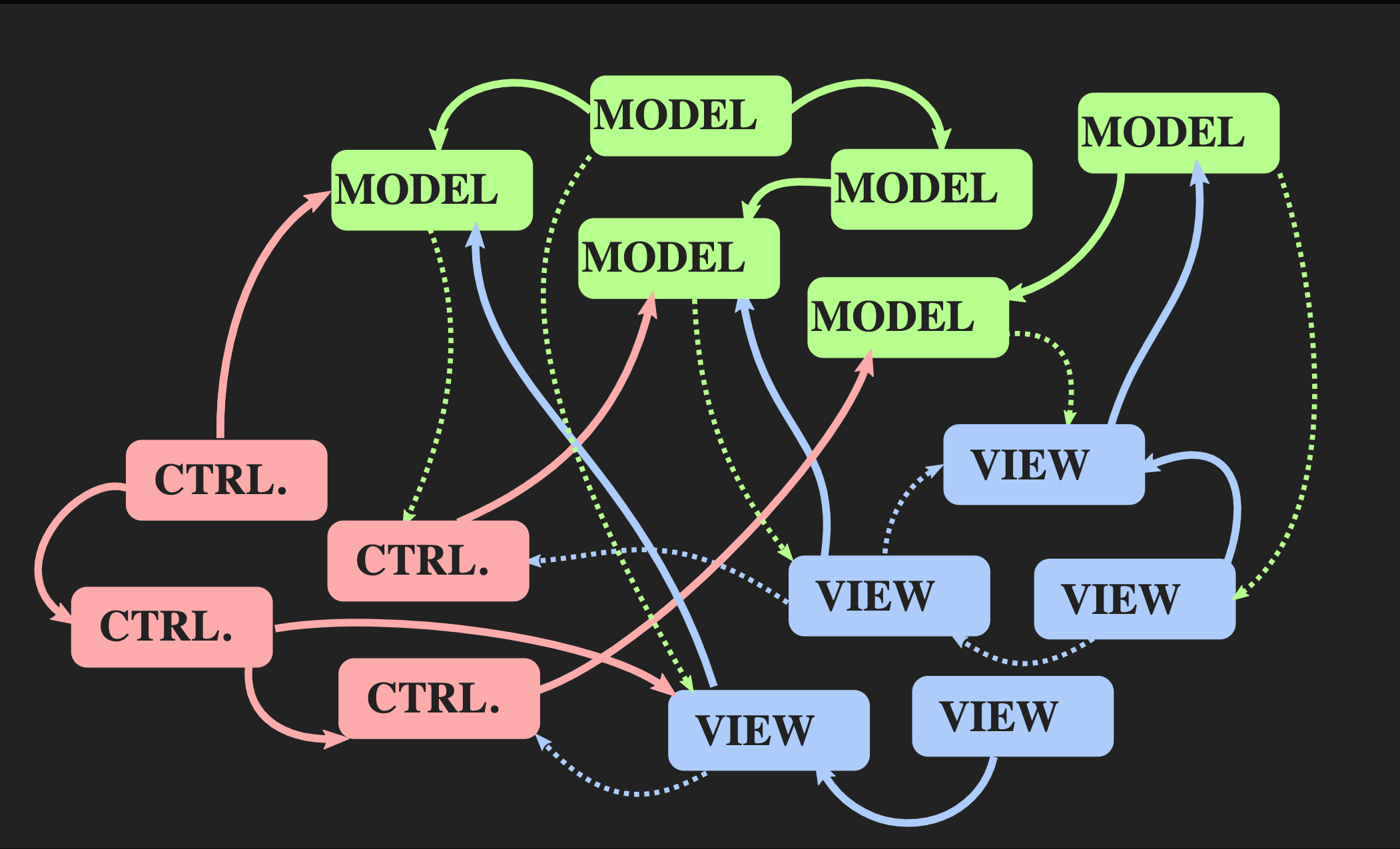 As the application grows and new Model, Controller, and View are added, a situation arises when, to change a segment of the program, you need to know about all parts associated with it, about all View that receive notification through
As the application grows and new Model, Controller, and View are added, a situation arises when, to change a segment of the program, you need to know about all parts associated with it, about all View that receive notification through callback, etc. As a result, for all the familiar pasta monster begins to peer through these dependencies.Is another architecture possible? There is an alternative approach to the Model-View-Controller pattern called “Unidirectional Data Flow Architecture”. This concept was not invented by me, it is used quite often in web development. On Facebook, this is called the Flux architecture, but in C ++, it is not yet applied.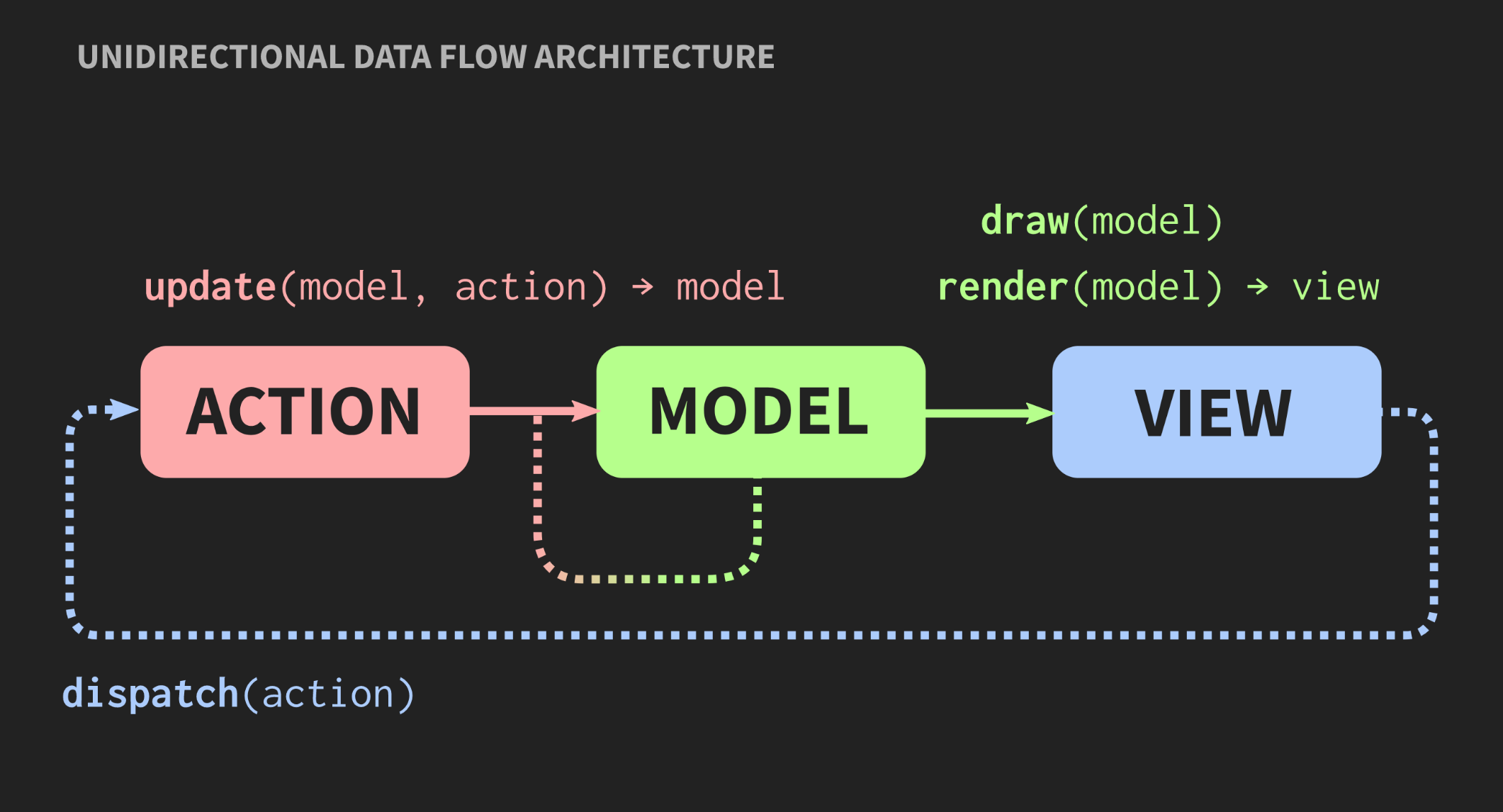 Elements of such an architecture are already familiar to us: Action, Model and View, but the meaning of blocks and arrows is different. Blocks are values, not objects and not regions with mutable states. This applies even to View. Further, arrows are not links, because without objects there can be no links. Here the arrows are functions. Between Action and Model, there is an update function that accepts the current Model, that is, the current state of the world, and Action, which is a representation of an event, for example, a mouse click, or an event of another level of abstraction, for example, an element or symbol is inserted into a document. The update function updates the document and returns the new state of the world. Model connects to the View function render, which takes the Model and returns the view. This requires a framework in which View can be represented as values.In web development, React does this, but in C ++ there is nothing like it yet, although who knows, if there are people who want to pay me to write something like this, it may soon appear. In the meantime, you can use the Immediate mode API, in which the draw function allows you to create a value as a side effect.Finally, the View should have a mechanism that allows the user or other event sources to send Action. There is an easy way to implement this, it is presented below:
Elements of such an architecture are already familiar to us: Action, Model and View, but the meaning of blocks and arrows is different. Blocks are values, not objects and not regions with mutable states. This applies even to View. Further, arrows are not links, because without objects there can be no links. Here the arrows are functions. Between Action and Model, there is an update function that accepts the current Model, that is, the current state of the world, and Action, which is a representation of an event, for example, a mouse click, or an event of another level of abstraction, for example, an element or symbol is inserted into a document. The update function updates the document and returns the new state of the world. Model connects to the View function render, which takes the Model and returns the view. This requires a framework in which View can be represented as values.In web development, React does this, but in C ++ there is nothing like it yet, although who knows, if there are people who want to pay me to write something like this, it may soon appear. In the meantime, you can use the Immediate mode API, in which the draw function allows you to create a value as a side effect.Finally, the View should have a mechanism that allows the user or other event sources to send Action. There is an easy way to implement this, it is presented below:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
With the exception of saving and loading asynchronously, this is the code that is used in the editor just presented. There is an object here terminalthat allows you to read and write from the command line. Further, applicationthis is the value of Model, it stores the entire state of the application. As you can see at the top of the screen, there is a function that returns a new version application. The cycle inside the function is executed until the application needs to close, that is, until !state.done. In the loop, a new state is drawn, then the next event is requested. Finally, the state is stored in a local variable state, and the loop starts again. This code has a very important advantage: only one mutable variable exists throughout the execution of the program, it is an object state.Clojure developers call this single-atom architecture: there is one single point across the entire application through which all changes are made. The application logic does not participate in updating this point in any way; this makes a specially designed cycle for this. Thanks to this, the application logic consists entirely of pure functions, like functions update.With this approach to writing applications, the way of thinking about software is changing. Work now begins not with the UML diagram of interfaces and operations, but with the data itself. There are some similarities with data-oriented design. True, data-oriented design is usually used to obtain maximum performance, here, in addition to speed, we strive for simplicity and correctness. The emphasis is slightly different, but there are important similarities in the methodology.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
Above are the main data types of our application. The main body of the application consists of line, which is flex_vector, and flex_vector is vectorone for which you can perform a join operation. Next textis the vector in which it is stored line. As you can see, this is a very simple representation of the text. Textstored with the help fileof which has a name, that is, an address in the file system, and actually text. As fileused another type, a simple but very useful: box. This is a single element container. It allows you to put in a heap and move an object, copying which may be too resource-intensive.Another important type: snapshot. Based on this type, a cancel function is active. It contains a document (in the formtext) and cursor position (coord). This allows you to return the cursor to the position in which it was during editing.The next type is buffer. This is a term from vim and emacs, as open documents are called there. In bufferthere is a file from which the text was downloaded, as well as the content of the text - this allows you to check for changes in the document. To highlight part of the text, there is an optional variable selection_startindicating the beginning of the selection. The vector from snapshotis the story of the text. Note that we do not use the Team pattern; history consists only of states. Finally, if the cancellation has just been completed, we need a position index in the state history history_pos.The next type: application. It contains an open document (buffer), key_mapandkey_seqfor keyboard shortcuts, as well as a vector from textfor the clipboard and another vector for messages displayed at the bottom of the screen. So far, in the debut version of the application there will be only one thread and one type of action that takes input key_codeand coord.Most likely, many of you are already thinking about how to implement these operations. If taken by value and returned by value, then in most cases the operations are quite simple. The code of my text editor is posted on github , so you can see how it actually looks. Now I will dwell in detail only on the code that implements the undo function.Cancel
Correctly writing a cancellation without the appropriate infrastructure is not so simple. In my editor, I implemented it along the lines of emacs, so first a couple of words about its basic principles. The return command is missing here, and thanks to this, you can not lose your job. If a return is necessary, any change is made to the text, and then all cancellation actions become again part of the cancellation history. This principle is depicted above. The red rhombus here shows a position in history: if a cancellation has just not been completed, the red rhombus is always at the very end. If you cancel, the rhombus will move one state back, but at the same time another state will be added to the end of the queue - the same as the user currently sees (S3). If you cancel again and return to state S2, state S2 is added to the end of the queue. If now the user makes some kind of change, it will be added to the end of the queue as a new state of S5, and a rhombus will be moved to it. Now, when undoing past actions, the previous undo actions will be scrolled first. To implement such a cancellation system, the following code is enough:
This principle is depicted above. The red rhombus here shows a position in history: if a cancellation has just not been completed, the red rhombus is always at the very end. If you cancel, the rhombus will move one state back, but at the same time another state will be added to the end of the queue - the same as the user currently sees (S3). If you cancel again and return to state S2, state S2 is added to the end of the queue. If now the user makes some kind of change, it will be added to the end of the queue as a new state of S5, and a rhombus will be moved to it. Now, when undoing past actions, the previous undo actions will be scrolled first. To implement such a cancellation system, the following code is enough:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
There are two actions, recordand undo. Recordperformed during any operation. This is very convenient since we don’t need to know if any editing of the document has occurred. The function is transparent to the application logic. After any action, the function checks if the document has changed. If a change has occurred, the push_backcontents and cursor position for are executed history. If the action did not lead to a change history_pos(that is, the input received is buffernot caused by the cancel action), then history_posa value is assigned null. If necessary undo, we check history_pos. If it has no meaning, we consider it to history_posbe at the end of the story. If the cancellation history is not empty (i.e.history_posnot at the very beginning of the story), cancellation is performed. The current content and cursor are replaced and changed history_pos. The irrevocability of a cancel operation is achieved by a function recordthat is also called during the cancel operation.So, we have an operation undothat takes up 10 lines of code, and which without changes (or with minimal changes) can be used in almost any other application.Time travel
About time travel. As we will see now, this is a topic related to cancellation. I will demonstrate the work of a framework that will add useful functionality to any application with a similar architecture. The framework here is called ewig-debug . This version of ewig includes some debugging features. Now from the browser you can open the debugger, in which you can examine the state of the application. We see that the last action was resizing, because I opened a new window, and my window manager automatically resized the already open window. Of course, for automatic serialization in JSON, I had to add annotation for struct from the special reflection library. But the rest of the system is quite universal, it can be connected to any similar application. Now in the browser you can see all the completed actions. Of course, there is an initial state that has no action. This is the state that was before the download. Moreover, by double-clicking I can return the application to its previous state. This is a very useful debugging tool that allows you to track the occurrence of a malfunction in the application.If you are interested, you can listen to my report on CPPCON 19, The most valuable values, there I will examine this debugger in detail.In addition, value-based architecture is discussed in more detail there. In it, I also tell you how to implement actions and organize them hierarchically. This ensures the modularity of the system and eliminates the need to keep everything in one big update function. In addition, that report talks about asynchrony and multi-threaded file downloads. There is another version of this report in which half an hour of additional material is Postmodern immutable data structures.
We see that the last action was resizing, because I opened a new window, and my window manager automatically resized the already open window. Of course, for automatic serialization in JSON, I had to add annotation for struct from the special reflection library. But the rest of the system is quite universal, it can be connected to any similar application. Now in the browser you can see all the completed actions. Of course, there is an initial state that has no action. This is the state that was before the download. Moreover, by double-clicking I can return the application to its previous state. This is a very useful debugging tool that allows you to track the occurrence of a malfunction in the application.If you are interested, you can listen to my report on CPPCON 19, The most valuable values, there I will examine this debugger in detail.In addition, value-based architecture is discussed in more detail there. In it, I also tell you how to implement actions and organize them hierarchically. This ensures the modularity of the system and eliminates the need to keep everything in one big update function. In addition, that report talks about asynchrony and multi-threaded file downloads. There is another version of this report in which half an hour of additional material is Postmodern immutable data structures.To summarize
I think it's time to take stock. I will quote Andy Wingo - he is an excellent developer, he devoted a lot of time to V8 and compilers in general, finally, he is engaged in supporting Guile, implementing Scheme for GNU. Recently, he wrote on his Twitter: “To achieve a slight acceleration of the program, we measure every small change and leave only those that give a positive result. But we really achieve significant acceleration, blindly, investing a lot of effort, not having 100% confidence and guided only by intuition. What a strange dichotomy. ”It seems to me that C ++ developers are succeeding in the first genre. Give us a closed system, and we, armed with our tools, will squeeze out everything that is possible from it. But in the second genre we are not used to working. Of course, the second approach is more risky, and often it leads to a waste of great effort. On the other hand, by completely rewriting a program, it can often be made easier and faster. I hope I managed to convince you to at least try this second approach.Juan Puente spoke at the C ++ Russia 2019 Moscow conference and talked about data structures that allow you to do interesting things. Part of the magic of these structures lies in copy elision - this is what Anton Polukhin and Roman Rusyaev will talk about at the upcoming conference . Follow the program updates on the site.