A brief comparison of the SDS architecture or finding a suitable storage platform (GlusterVsCephVsVirtuozzoStorage)
This article is written to help you choose the right solution for yourself and to understand the differences between SDS such as Gluster, Ceph and Vstorage (Virtuozzo).The text uses links to articles with a more detailed disclosure of certain problems, so the descriptions will be as brief as possible using key points without unnecessary water and background information that you can independently obtain on the Internet if you wish.In fact, of course, the topics covered require tones of text, but in the modern world more and more people don’t like to read a lot))), so you can quickly read and make a choice, and if it’s unclear to follow the links or google incomprehensible words))), and this article as a transparent wrapper for these deep topics, showing the filling - the main key points of each decision.Gluster
Let's start with Gluster, which is actively used by manufacturers of hyperconverged platforms with SDS based on open source for virtual environments and can be found on the RedHat website in the storage section, where you are offered to choose from two SDS options: Gluster or Ceph.Gluster consists of a stack of translators - services that do all the work of distributing files, etc. Brick - a service that serves one disk, Volume - a volume (pool) - which combines these bricks. Next comes the service for distributing files into groups due to the function DHT (distributed hash table). We will not include the Sharding service in the description since the links below will describe the problems associated with it.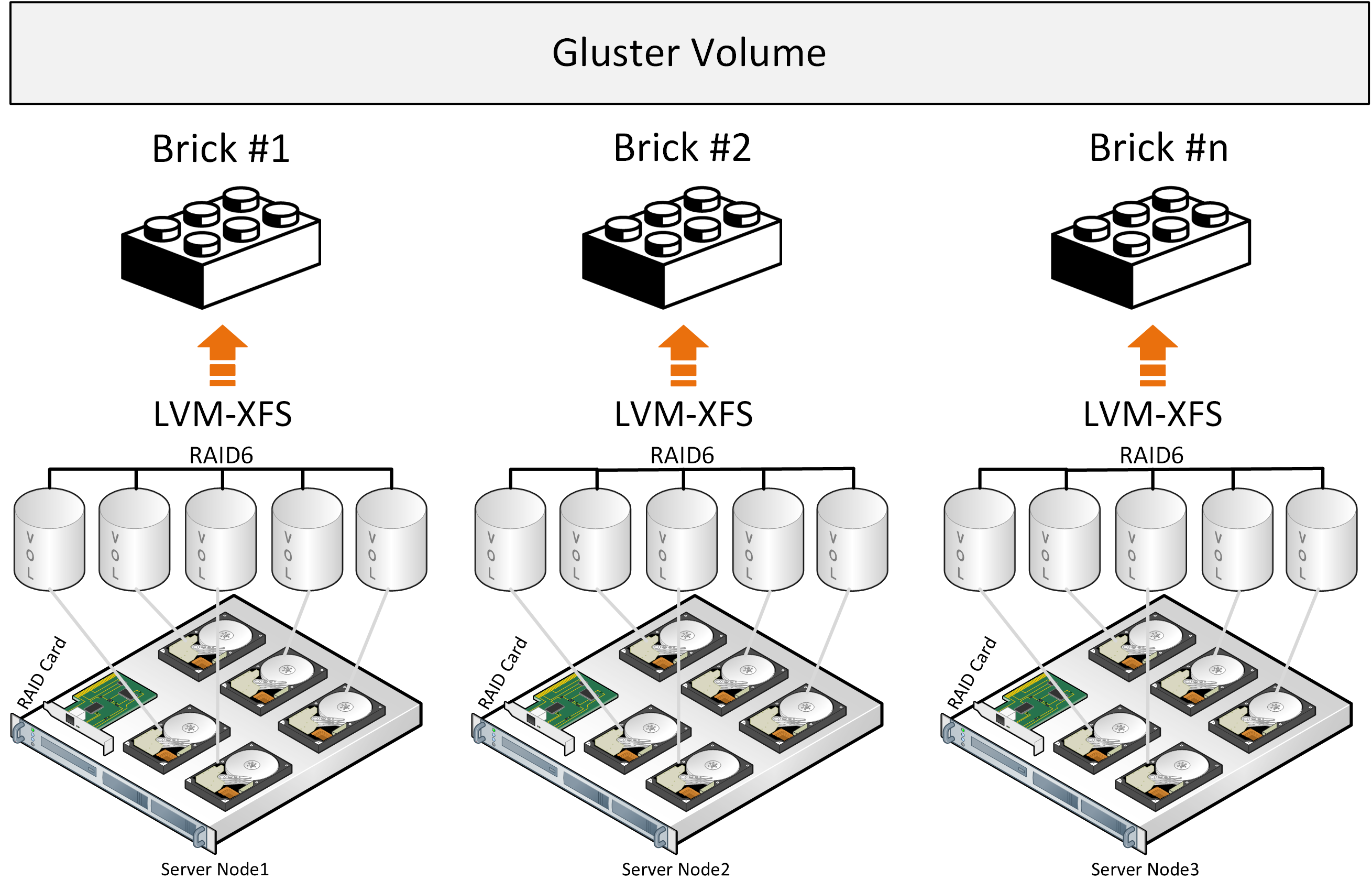 When recording, the entire file lays in the brick and its copy is written in parallel on the brick on the second server. Further, the second file will already be written to the second group of two brik (or more) on different servers.If the files are about the same size and the volume will consist of only one group, then everything is fine, but under other conditions, the following problems will arise from the descriptions:
When recording, the entire file lays in the brick and its copy is written in parallel on the brick on the second server. Further, the second file will already be written to the second group of two brik (or more) on different servers.If the files are about the same size and the volume will consist of only one group, then everything is fine, but under other conditions, the following problems will arise from the descriptions:- the place in the groups is not evenly utilized, it depends on the size of the files and if there is not enough space in the group to write the file, you will get an error, the file will not be written and will not be redistributed to another group;
- when writing one file, IO goes to only one group, the rest are idle;
- You cannot get the IO of the entire volume when writing a single file;
- , , .
From the official description of the architecture, one also involuntarily understands that gluster works as a file storage on top of the classic hardware RAID. There have been development attempts to shard files into blocks, but this is all an add-on that puts performance losses on an existing architectural approach, plus the use of freely distributed components with performance limitations like Fuse. There are no metadata services, which limits the storage and distribution capabilities of files when distributing files into blocks. Better performance can be observed with the “Distributed Replicated” configuration, and the number of nodes must be at least 6 to create a reliable replica of 3 with optimal load distribution.These conclusions are also related to the description of the experience of using Gluster and when compared with Ceph , and there is also a description of the experience to the understanding of this more productive and more reliable “Replicated Distributed” configuration . The picture shows the load distribution when recording two files, where copies of the first file are laid out on the first three servers, which are combined in the volume 0 group and three copies of the second file fall on the second group volume1 of the three servers. Each server has one disk.The general conclusion is that you can use Gluster, but with the understanding that there will be limitations in performance and fault tolerance, which create difficulties under certain conditions of a hyperconverged solution, where resources are also needed for the computing loads of virtual environments.
The picture shows the load distribution when recording two files, where copies of the first file are laid out on the first three servers, which are combined in the volume 0 group and three copies of the second file fall on the second group volume1 of the three servers. Each server has one disk.The general conclusion is that you can use Gluster, but with the understanding that there will be limitations in performance and fault tolerance, which create difficulties under certain conditions of a hyperconverged solution, where resources are also needed for the computing loads of virtual environments.
There are also some Gluster performance indicators that can be achieved under certain conditions by limiting in fault tolerance.
Ceph
eph , . Glusterfs Ceph, Ceph , .
eph Gluster , . , , (), latency .
CRUSH, . PG — ( ) . PG , CRUSH . PG — -, . , , PG . OSD – .
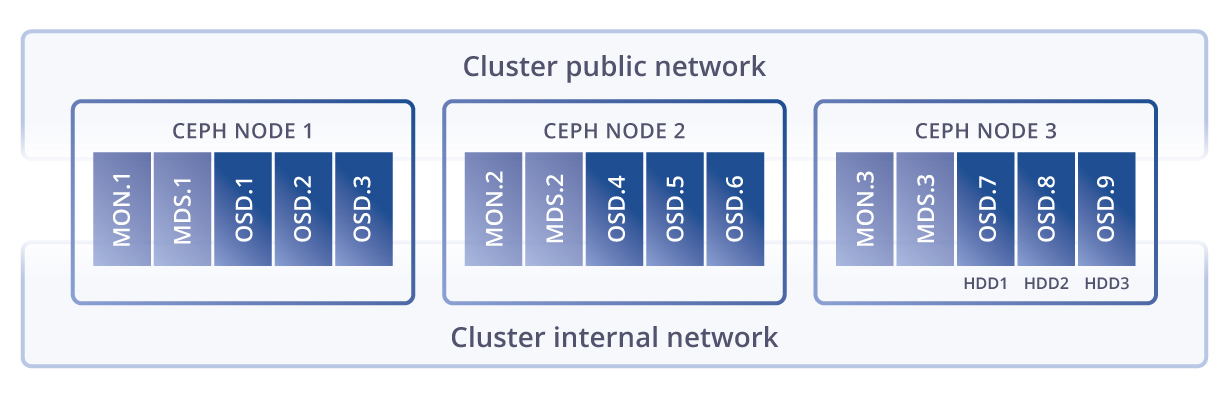
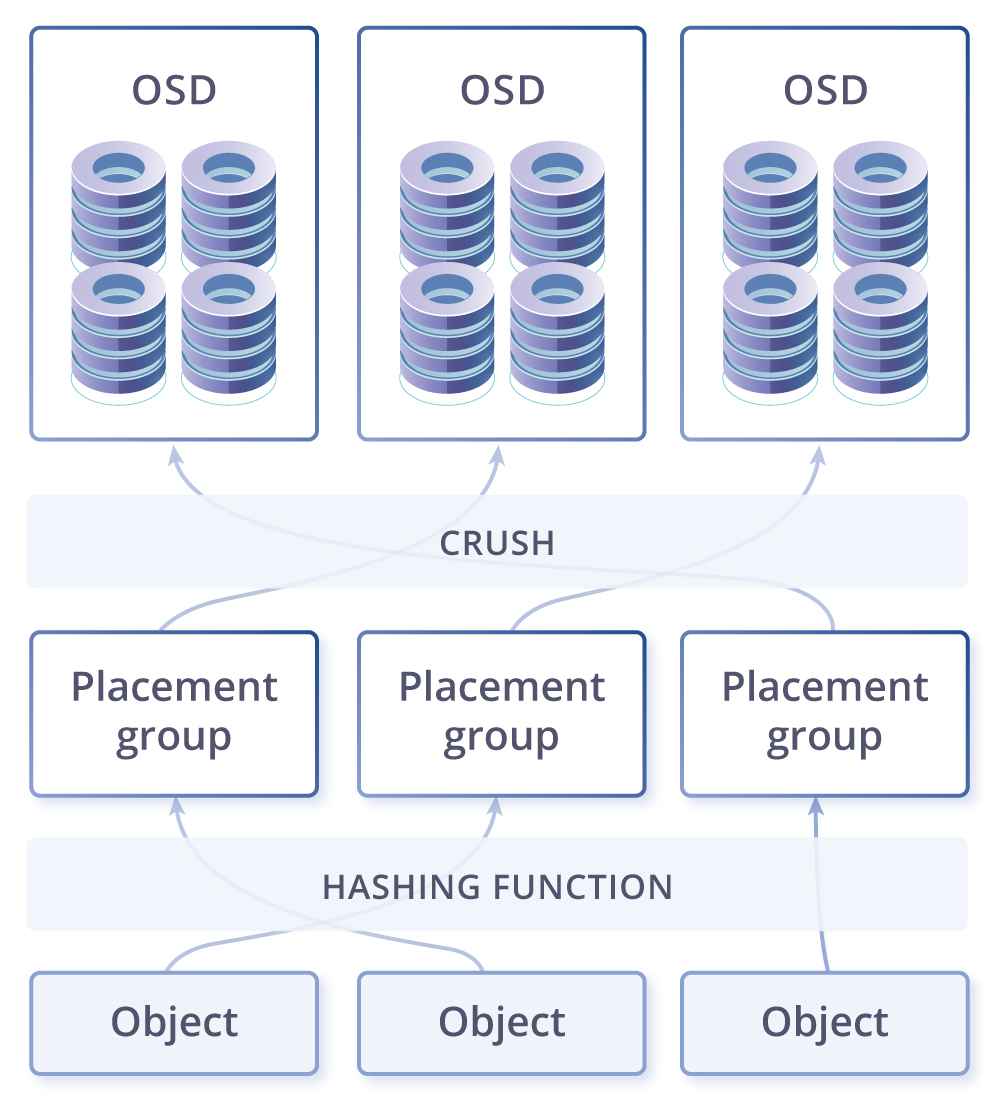
. -. - , . , , - - ( ). , -, — , . .
- , , . . , – ( , ). – , . - , ( ), , , Ceph PG self-healing . , Ceph ( ), , .
-, . Ceph Gluster . – , linux, , , .
Vstorage
Virtuozzo storage(Vstorage), , , , . , .
kvm-qemu, , : FUSE(, open source), MDS (Metadata service), Chunk service, . , SSD, (erase coding raid6) all flash. EC(erase coding) : . eph EC , , Virtuozzo Storage “log-structured file system”, . EC , . – , .
, , , .
eph Virtuozzo storage.
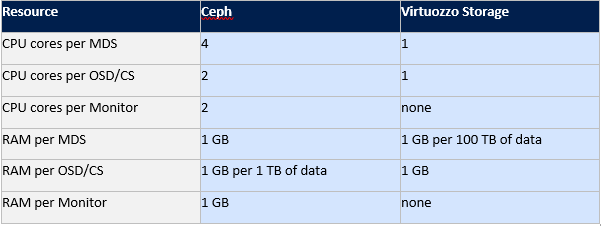
Gluster Ceph , , Virtuozzo . Vstorage .
, , .
: ( FUSE), (MDS) ( CS), MDS , . . , 256.

, - , 256. , .… SSD , ( ), SSD, SSD, HDD, . SSD . , SSD , Latency , SSD, . , IOPS Vstorage , , , , ..
SSD, , , HDD. (MDS) , Paxos. FUSE, , , .
, , , . . SDS, fuse fast path Virtuozzo Storage. fuse open source , IOPS- . , eph Gluster.
: Virtuozzo Storage, Ceph Gluster.
, Virtuozzo Storage: , Fuse fast path, , compute(/), , . Ceph, Gluster, , .
The plans include a desire to write a comparison between vSAN, Space Direct Storage, Vstorage and Nutanix Storage, testing Vstorage on HPE, Huawei equipment, as well as Vstorage integration scenarios with external hardware storage systems, so if you liked the article, it would be nice to get feedback from you , which could enhance the motivation for new articles based on your comments and suggestions. Source: https://habr.com/ru/post/undefined/
All Articles