Catastrophic Cloud: How It Works
Hello, Habr!After the New Year holidays, we restarted a disaster-resistant cloud based on two sites. Today we’ll tell you how it works and show what happens to client virtual machines when individual cluster elements fail and the whole site falls (spoiler - everything is fine with them). Disaster-proof cloud storage at the OST site.
Disaster-proof cloud storage at the OST site.What is inside
Under the hood of the cluster are Cisco UCS servers with VMware ESXi hypervisor, two INFINIDAT InfiniBox F2240 storage systems, Cisco Nexus network equipment, as well as Brocade SAN switches. The cluster is spaced into two sites - OST and NORD, i.e., in each data center an identical set of equipment. Actually, this makes it catastrophic.Within one platform, the main elements are also duplicated (hosts, SAN switches, network card).Two sites are connected by dedicated fiber optic paths, also reserved.A few words about storage. The first disaster-resistant cloud we built on NetApp. INFINIDAT was chosen here, and here's why:- Active-Active replication option. It allows the virtual machine to remain operational even if one of the storage systems completely fails. I’ll tell you more about replication later.
- Three disk controllers for increased system resiliency. Usually there are two.
- Ready solution. An already assembled rack came to us, which only needs to be connected to the network and configured.
- Attentive technical support. INFINIDAT engineers constantly analyze logs and events of storage systems, install new versions in the firmware, and help with configuration.
Here are some photos from unpacking:

How does it work
The cloud is already resilient within itself. It protects the client from single hardware and software failures. Catastrophic will help protect against mass failures within the same site: for example, failure of the storage system (or SDS cluster, which happens often :)), mass errors in the storage network and more. Well and most importantly: such a cloud saves when an entire site becomes inaccessible due to fire, blackout, raider capture, alien landings.In all of these cases, client virtual machines continue to run, and here's why.The cluster scheme is designed so that any ESXi host with client virtual machines can access either of two storage systems. If the storage on the OST site fails, then the virtual machines will continue to work: the hosts on which they work will access the storage on NORD for data. This is how the connection diagram in the cluster looks.This is possible due to the fact that an Inter-Switch Link is configured between the SAN factories of the two sites: the Fabric A OST SAN switch is connected to the Fabric A NORD SAN switch, similarly to Fabric B SAN switches.Well, so that all these intricacies of SAN factories make sense, Active-Active replication is configured between the two storage systems: information is written almost simultaneously to the local and remote storage systems, RPO = 0. It turns out that on one SHD the original data is stored, on the other - their replica. Data is replicated at the storage volume level, and VM data (its disks, configuration file, swap file, etc.) is already stored on them.The ESXi host sees the primary volume and its replica as a single storage device. There are 24 paths from the ESXi host to each disk device:12 paths associate it with the local storage (optimal paths), and the remaining 12 - with the remote (not optimal paths). In a normal situation, ESXi accesses data on the local storage using “optimal” paths. If this storage system fails, ESXi loses its optimal paths and switches to “non-optimal” ones. Here's how it looks in the diagram.
This is how the connection diagram in the cluster looks.This is possible due to the fact that an Inter-Switch Link is configured between the SAN factories of the two sites: the Fabric A OST SAN switch is connected to the Fabric A NORD SAN switch, similarly to Fabric B SAN switches.Well, so that all these intricacies of SAN factories make sense, Active-Active replication is configured between the two storage systems: information is written almost simultaneously to the local and remote storage systems, RPO = 0. It turns out that on one SHD the original data is stored, on the other - their replica. Data is replicated at the storage volume level, and VM data (its disks, configuration file, swap file, etc.) is already stored on them.The ESXi host sees the primary volume and its replica as a single storage device. There are 24 paths from the ESXi host to each disk device:12 paths associate it with the local storage (optimal paths), and the remaining 12 - with the remote (not optimal paths). In a normal situation, ESXi accesses data on the local storage using “optimal” paths. If this storage system fails, ESXi loses its optimal paths and switches to “non-optimal” ones. Here's how it looks in the diagram. The scheme of a disaster-resistant cluster.All client networks are established on both sites through a common network factory. Provider Edge (PE) runs on each site, on which client networks are terminated. PEs are combined into a single cluster. If PE fails on one site, all traffic is redirected to the second site. Thanks to this, virtual machines from the site without PE remain available over the network for the client.Let us now see what will happen to the client virtual machines in case of various failures. Let's start with the lightest options and end with the most serious - the failure of the entire site. In the examples, the main site will be OST, and the backup, with data replicas, will be NORD.
The scheme of a disaster-resistant cluster.All client networks are established on both sites through a common network factory. Provider Edge (PE) runs on each site, on which client networks are terminated. PEs are combined into a single cluster. If PE fails on one site, all traffic is redirected to the second site. Thanks to this, virtual machines from the site without PE remain available over the network for the client.Let us now see what will happen to the client virtual machines in case of various failures. Let's start with the lightest options and end with the most serious - the failure of the entire site. In the examples, the main site will be OST, and the backup, with data replicas, will be NORD.What happens to a client virtual machine if ...
Replication Link Fails. The replication between the storage systems of the two sites stops.ESXi will only work with local disk devices (along the optimal paths).Virtual machines continue to work. There is a gap ISL (Inter-Switch Link). The case is unlikely. Unless some mad excavator digs up several optical routes at once, which pass through independent routes and are brought to the sites through different inputs. But anyway. In this case, ESXi hosts lose half of their paths and can only access their local storage. Replicas are collected, but hosts will not be able to access them.Virtual machines work normally.
There is a gap ISL (Inter-Switch Link). The case is unlikely. Unless some mad excavator digs up several optical routes at once, which pass through independent routes and are brought to the sites through different inputs. But anyway. In this case, ESXi hosts lose half of their paths and can only access their local storage. Replicas are collected, but hosts will not be able to access them.Virtual machines work normally. Refuses a SAN switch on one of the sites.ESXi hosts lose some of their storage paths. In this case, the hosts on the site where the switch failed will work only through their own HBA.At the same time, virtual machines continue to work normally.
Refuses a SAN switch on one of the sites.ESXi hosts lose some of their storage paths. In this case, the hosts on the site where the switch failed will work only through their own HBA.At the same time, virtual machines continue to work normally. All SAN switches on one of the sites fail. Let's say such a disaster happened at the OST site. In this case, ESXi hosts on this site will lose all paths to their disk devices. The standard VMware vSphere HA mechanism comes into play: it will restart all the OST platform virtual machines in NORD after a maximum of 140 seconds.Virtual machines running on the hosts of the NORD site work normally.
All SAN switches on one of the sites fail. Let's say such a disaster happened at the OST site. In this case, ESXi hosts on this site will lose all paths to their disk devices. The standard VMware vSphere HA mechanism comes into play: it will restart all the OST platform virtual machines in NORD after a maximum of 140 seconds.Virtual machines running on the hosts of the NORD site work normally.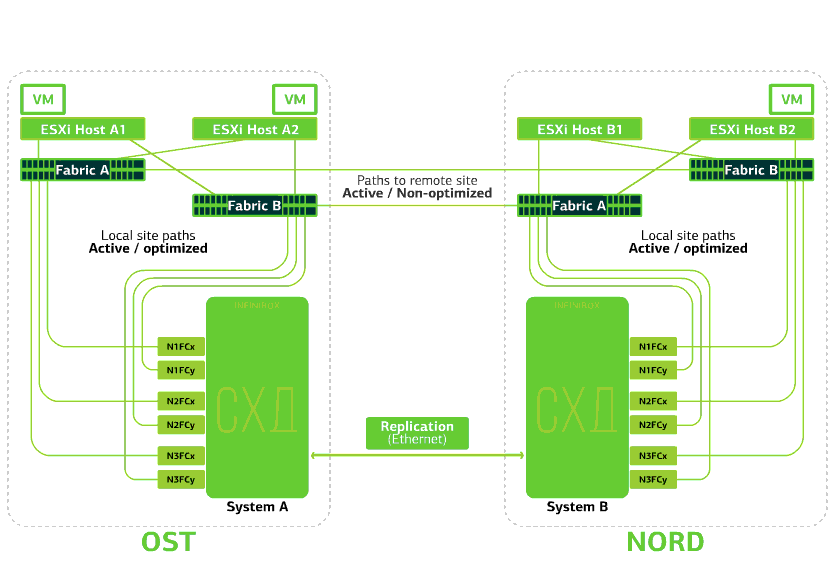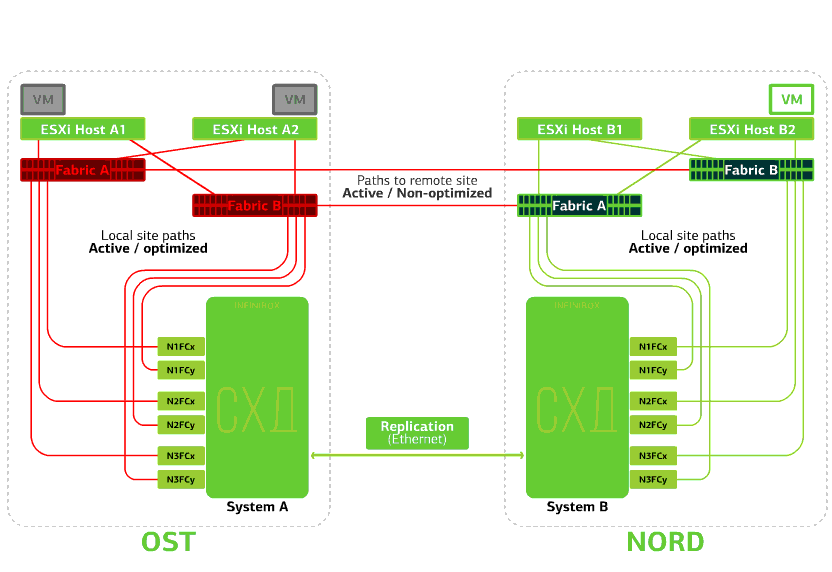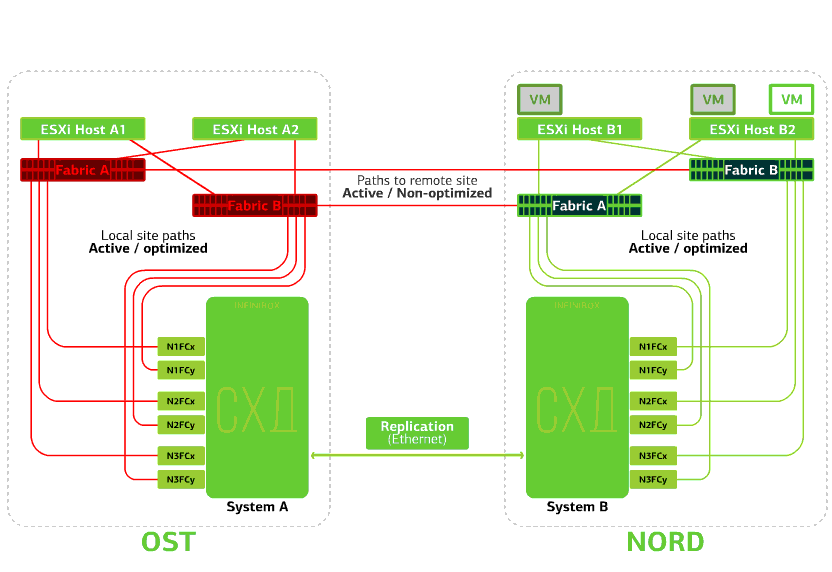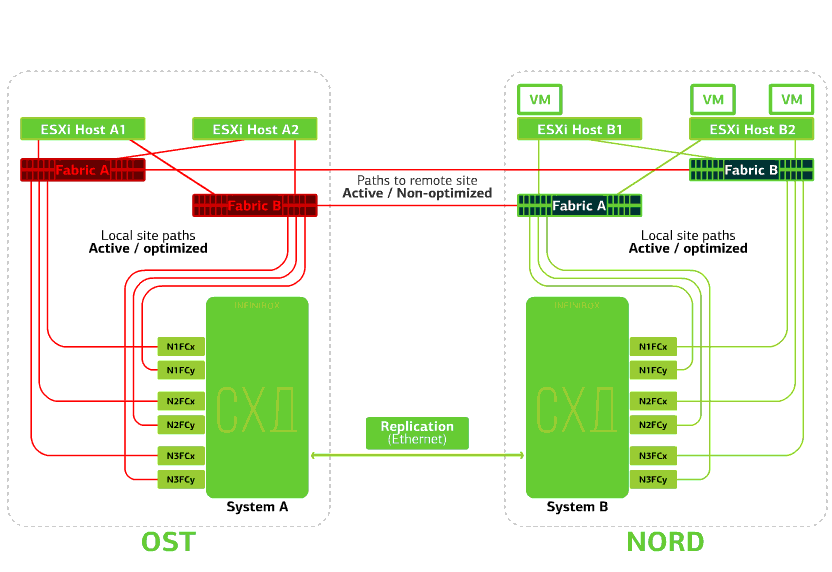 Refuses ESXi host on one site.Here the vSphere HA mechanism works again: virtual machines from a failed host are restarted on other hosts - on the same or remote site. The restart time of the virtual machine is up to 1 minute.If all ESXi hosts of the OST platform fail, there are no options: VMs restart on another. The restart time is the same.
Refuses ESXi host on one site.Here the vSphere HA mechanism works again: virtual machines from a failed host are restarted on other hosts - on the same or remote site. The restart time of the virtual machine is up to 1 minute.If all ESXi hosts of the OST platform fail, there are no options: VMs restart on another. The restart time is the same.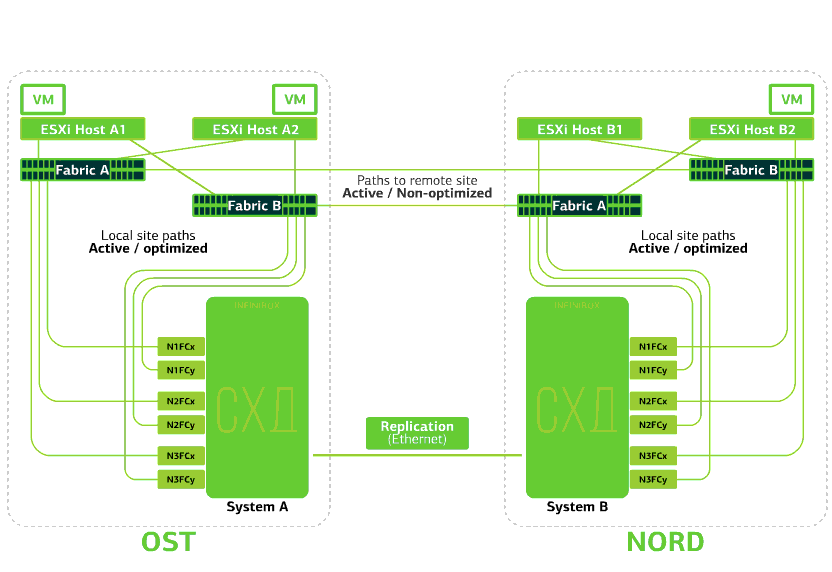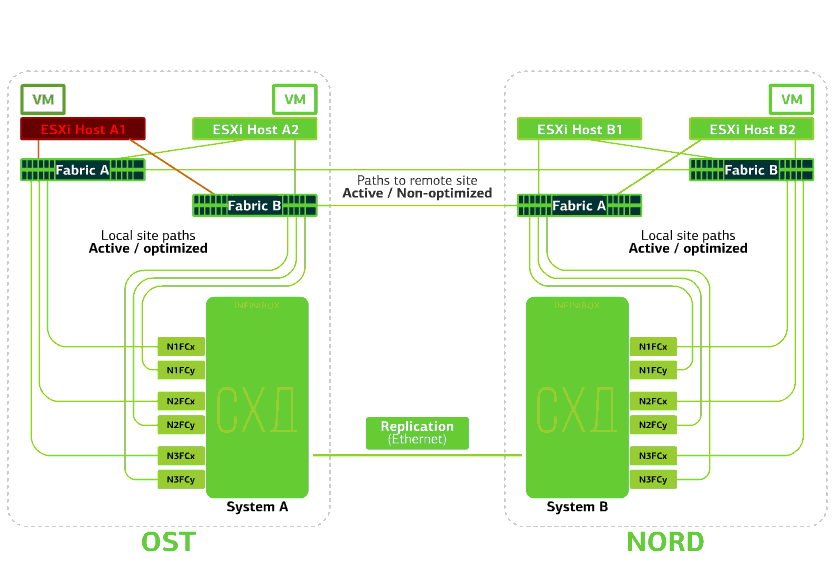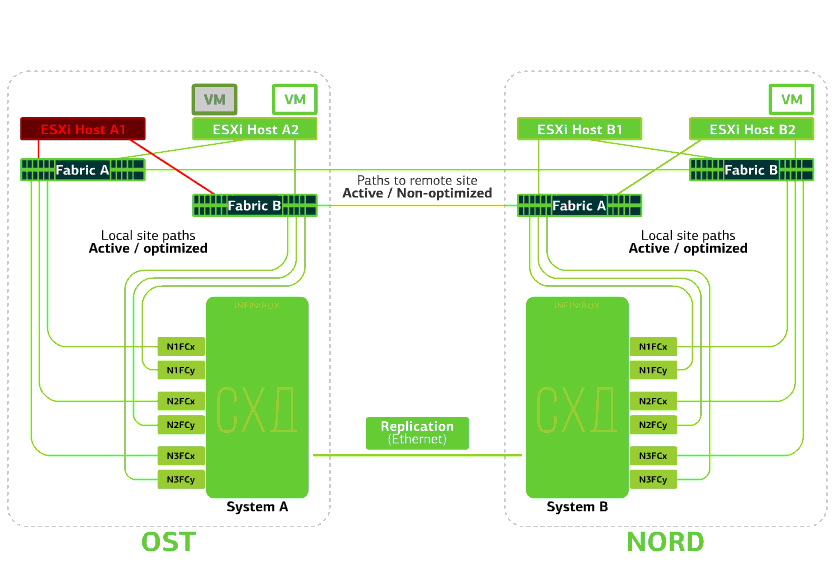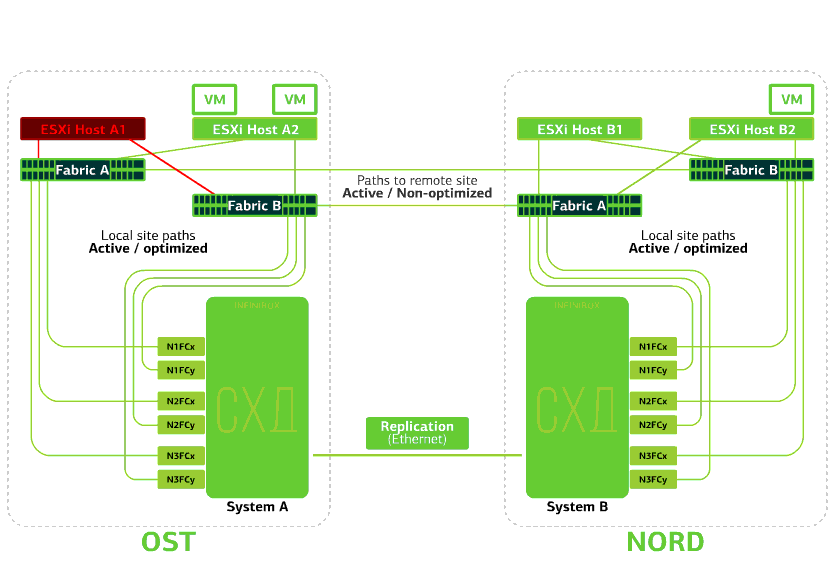 Refuses storage on the same site. Let's say the storage system refused at the OST site. Then the OST ESXi hosts switch to work with storage replicas in NORD. After the failed storage system returns to the system, forced replication occurs, the OST ESXi hosts will again start contacting the local storage system.Virtual machines have been working all this time.
Refuses storage on the same site. Let's say the storage system refused at the OST site. Then the OST ESXi hosts switch to work with storage replicas in NORD. After the failed storage system returns to the system, forced replication occurs, the OST ESXi hosts will again start contacting the local storage system.Virtual machines have been working all this time. Fails one of the sites.In this case, all virtual machines will restart on the backup site through the vSphere HA mechanism. VM restart time - 140 seconds. In this case, all network settings of the virtual machine will be saved, and it remains available to the client over the network.To restart the machines on the backup site without problems, each site is only half full. The second half is the reserve in case all virtual machines are moved from the second, injured site.
Fails one of the sites.In this case, all virtual machines will restart on the backup site through the vSphere HA mechanism. VM restart time - 140 seconds. In this case, all network settings of the virtual machine will be saved, and it remains available to the client over the network.To restart the machines on the backup site without problems, each site is only half full. The second half is the reserve in case all virtual machines are moved from the second, injured site.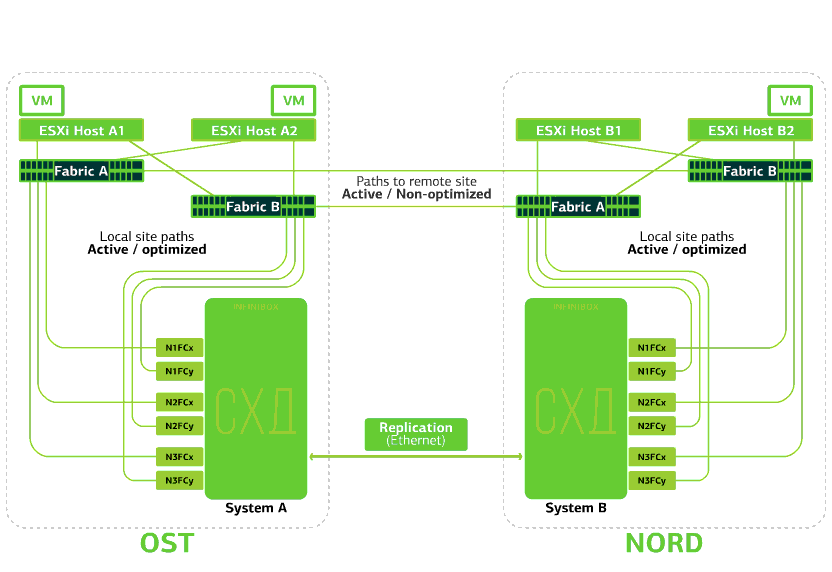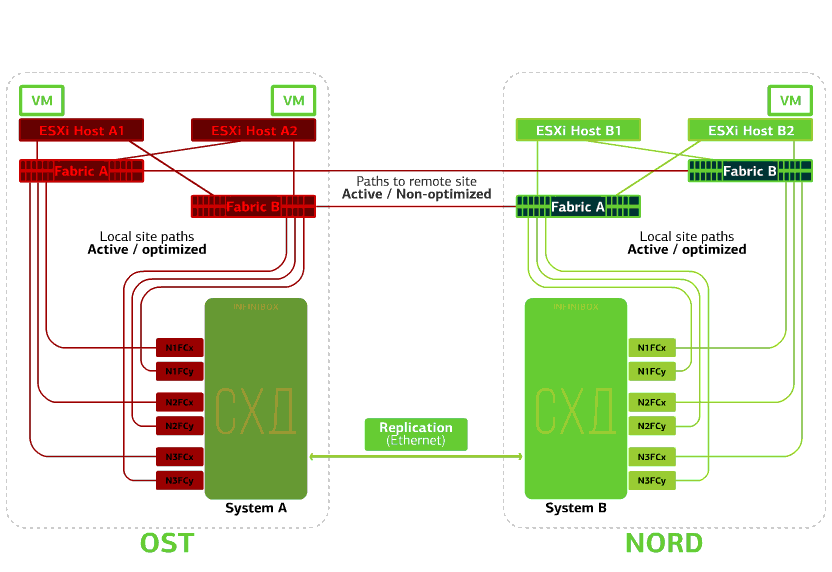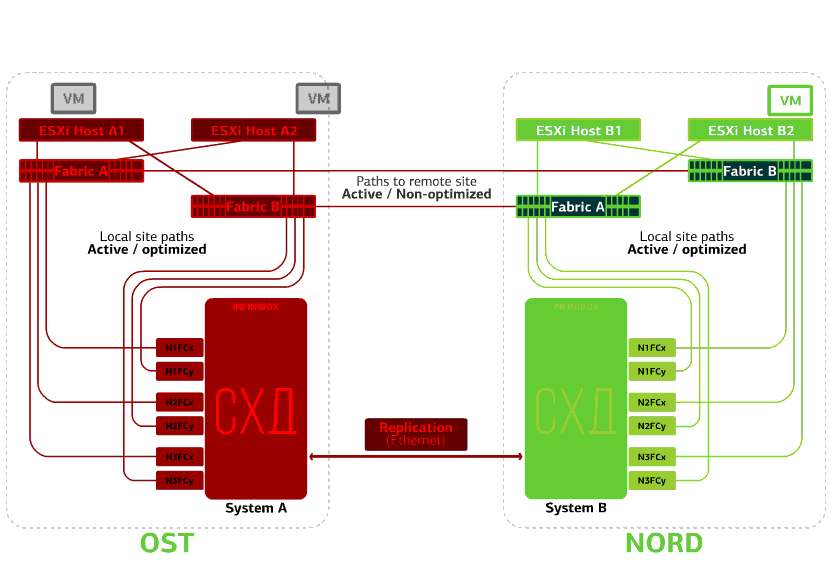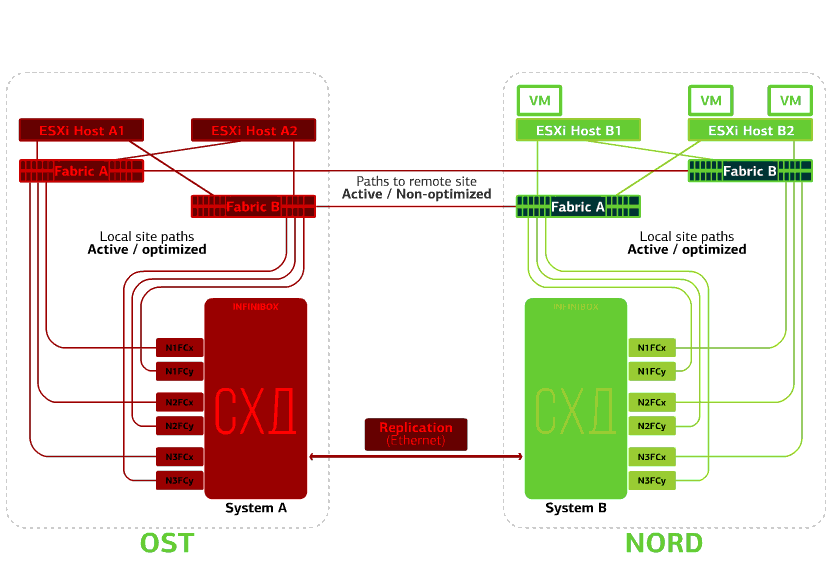 A disaster-proof cloud based on two data centers protects against such failures.This pleasure is not cheap, because, in addition to the main resources, you need a reserve on the second site. Therefore, they place business-critical services in such a cloud, the long downtime of which incurs large financial and reputational losses, or if disaster tolerance requirements are imposed on the information system from the regulators or internal regulations of the company.Sources:
A disaster-proof cloud based on two data centers protects against such failures.This pleasure is not cheap, because, in addition to the main resources, you need a reserve on the second site. Therefore, they place business-critical services in such a cloud, the long downtime of which incurs large financial and reputational losses, or if disaster tolerance requirements are imposed on the information system from the regulators or internal regulations of the company.Sources:- www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
- support.infinidat.com/hc/en-us/articles/207057109-InfiniBox-best-practices-guides
Source: https://habr.com/ru/post/undefined/
All Articles