From scripts to our own platform: how we automated development at the Cyan Institute
 At RIT 2019, our colleague Alexander Korotkov made a report on the development automation at the CIAN: to simplify life and work, we use our own Integro platform. It monitors the life cycle of tasks, removes routine operations from developers, and significantly reduces the number of bugs in production. In this post we will supplement Alexander’s report and tell you how we went from simple scripts to combining open source products through our own platform and what a separate automation team does.
At RIT 2019, our colleague Alexander Korotkov made a report on the development automation at the CIAN: to simplify life and work, we use our own Integro platform. It monitors the life cycle of tasks, removes routine operations from developers, and significantly reduces the number of bugs in production. In this post we will supplement Alexander’s report and tell you how we went from simple scripts to combining open source products through our own platform and what a separate automation team does. Level zero
“There is no zero level, I don’t know such a thing”
Shifu master from the Kung Fu Panda m / fAutomation at the Cyan Institute started 14 years after the company was founded. Then there were 35 people in the development team. Hard to believe, right? Of course, automation did exist in some form, but a separate area of continuous integration and code delivery began to form in 2015. At that time, we had a huge monolith from Python, C # and PHP deployed on Linux / Windows servers. For the deployment of this monster, we had a set of scripts that we ran manually. There was also a monolith assembly, causing pain and suffering due to conflicts when merging branches, editing defects and rebuilding "with a different set of tasks in the build." The simplified process looked like this: This did not suit us, and we wanted to build a repeatable, automated and controlled build and deployment process. To do this, we needed a CI / CD system, and we chose between the free version of Teamcity and the free Jenkins, since we worked with them and both suited us for a set of functions. We chose Teamcity as a more recent product. Then we did not use microservice architecture and did not count on a large number of tasks and projects.
This did not suit us, and we wanted to build a repeatable, automated and controlled build and deployment process. To do this, we needed a CI / CD system, and we chose between the free version of Teamcity and the free Jenkins, since we worked with them and both suited us for a set of functions. We chose Teamcity as a more recent product. Then we did not use microservice architecture and did not count on a large number of tasks and projects.We come to the idea of our own system
The implementation of Teamcity removed only a part of the manual work: there was still the creation of Pull Request, promotion of tasks by status in Jira, selection of tasks for release. Teamcity could no longer cope with this. It was necessary to choose the path of further automation. We considered options for working with scripts in Teamcity or switching to third-party automation systems. But in the end, they decided that they needed the maximum flexibility that only their own solution gives. So the first version of the internal automation system called Integro appeared.Teamcity is engaged in automation at the start-up level of build and deployment processes, and Integro has focused on top-level automation of development processes. It was necessary to combine work with tasks in Jira with processing the associated source code in Bitbucket. At this stage, Integro began to have their own workflows for working with tasks of various types. Due to the increase in automation in business processes, the number of projects and runs in Teamcity has increased. So a new problem came: one free Teamcity instance was missing (3 agents and 100 projects), we added another instance (3 more agents and 100 projects), then another. As a result, we got a system of several clusters, which was difficult to manage: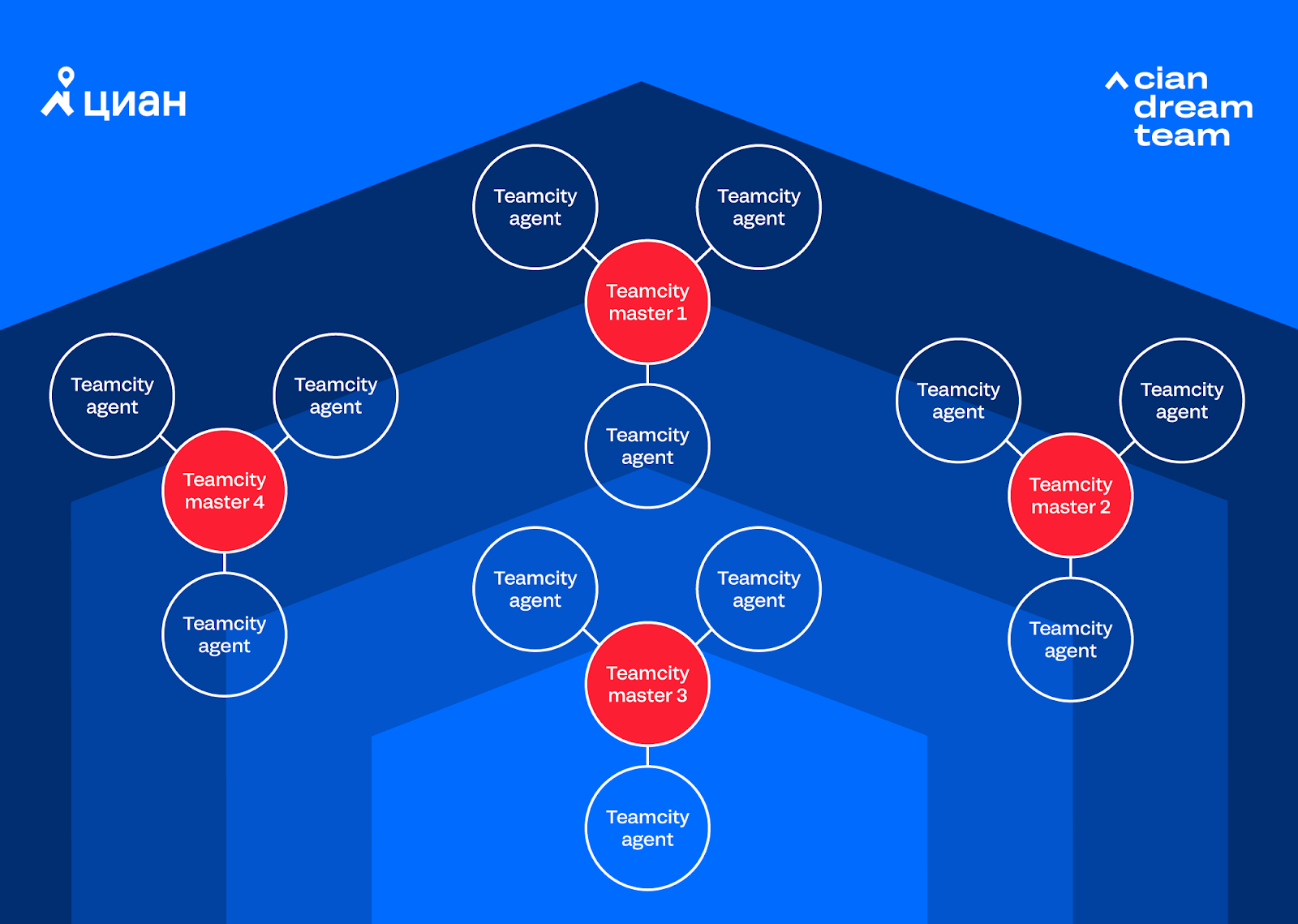 When the question of the 4th instance came up, we realized that we can’t live like that anymore, since the total costs of supporting the 4 instances no longer fit into any framework. The question arose of buying a paid Teamcity or opting for a free Jenkins. We carried out calculations on instances and plans for automation and decided that we would live on Jenkins. After a couple of weeks, we switched to Jenkins and got rid of the headache part associated with supporting multiple Teamcity instances. Therefore, we were able to focus on developing Integro and completing Jenkins for ourselves.With the growth of basic automation (in the form of automatic creation of Pull Requests, collection and publication of Code coverage and other checks), there was a strong desire to refuse manual releases as much as possible and give this work to robots. In addition, the company began moving to microservices, which required frequent releases, and separately from each other. So we gradually came to the automatic releases of our microservices (for now, we are releasing the monolith manually due to the complexity of the process). But, as it usually happens, a new complexity has arisen.
When the question of the 4th instance came up, we realized that we can’t live like that anymore, since the total costs of supporting the 4 instances no longer fit into any framework. The question arose of buying a paid Teamcity or opting for a free Jenkins. We carried out calculations on instances and plans for automation and decided that we would live on Jenkins. After a couple of weeks, we switched to Jenkins and got rid of the headache part associated with supporting multiple Teamcity instances. Therefore, we were able to focus on developing Integro and completing Jenkins for ourselves.With the growth of basic automation (in the form of automatic creation of Pull Requests, collection and publication of Code coverage and other checks), there was a strong desire to refuse manual releases as much as possible and give this work to robots. In addition, the company began moving to microservices, which required frequent releases, and separately from each other. So we gradually came to the automatic releases of our microservices (for now, we are releasing the monolith manually due to the complexity of the process). But, as it usually happens, a new complexity has arisen. Automate Testing
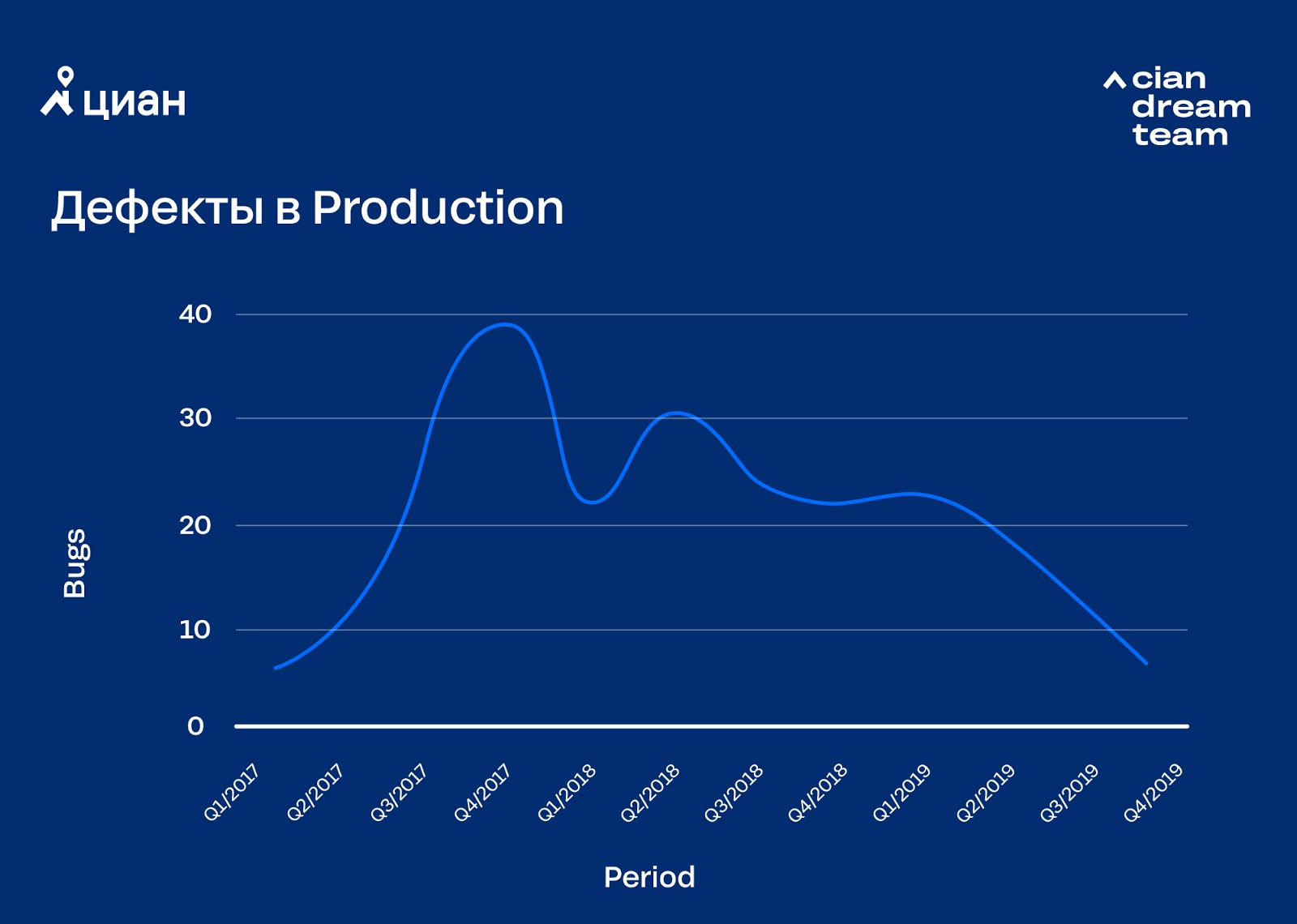 Due to the automation of releases, development processes have accelerated, partly due to the omission of some stages of testing. And this led to a temporary loss of quality. It sounds corny, but along with the acceleration of releases, it was necessary to change the methodology of product development. It was necessary to think about test automation, inculcating personal responsibility (here we are talking about “accepting an idea in the head” rather than monetary fines) of the developer for the released code and bugs in it, as well as about the decision to issue / not issue the task through an automatic deployment. Eliminating quality problems, we came to two important decisions: we began to carry out canary testing and introduced automatic monitoring of the error background with automatic response to its excess. The first solution made it possible to find obvious errors before the code fully got into production, the second reduced the response time to problems in production. Mistakes, of course, do occur, but we spend most of our time and energy not on correction, but on minimization.
Due to the automation of releases, development processes have accelerated, partly due to the omission of some stages of testing. And this led to a temporary loss of quality. It sounds corny, but along with the acceleration of releases, it was necessary to change the methodology of product development. It was necessary to think about test automation, inculcating personal responsibility (here we are talking about “accepting an idea in the head” rather than monetary fines) of the developer for the released code and bugs in it, as well as about the decision to issue / not issue the task through an automatic deployment. Eliminating quality problems, we came to two important decisions: we began to carry out canary testing and introduced automatic monitoring of the error background with automatic response to its excess. The first solution made it possible to find obvious errors before the code fully got into production, the second reduced the response time to problems in production. Mistakes, of course, do occur, but we spend most of our time and energy not on correction, but on minimization. Automation team
Now we have a staff of 130 developers, and we continue to grow . The team for continuous integration and code delivery (hereinafter referred to as the Deploy and Integration or DI team) consists of 7 people and works in 2 directions: development of the automation platform Integro and DevOps. DevOps is responsible for the Dev / Beta environment of the CIAN website, the Integro environment, helps developers to solve problems and develops new approaches to scaling environments. Integro's line of business deals with both Integro itself and related services, for example, plug-ins for Jenkins, Jira, Confluence, and also develops auxiliary utilities and applications for development teams. The DI team works in conjunction with the Platform team, which develops architectures, libraries, and development approaches within the company. At the same time, any developer inside the CIAN can contribute to automation, for example, make microautomation to the needs of the team or share a cool idea on how to make automation even better.Puff pie automation in cyan
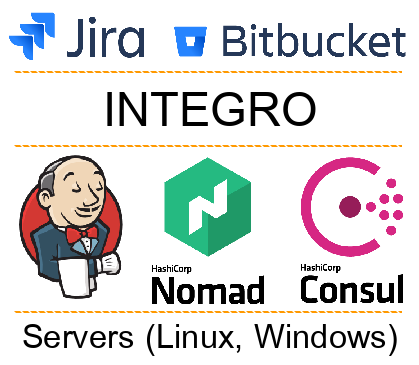 All systems involved in automation can be divided into several layers:
All systems involved in automation can be divided into several layers:- External systems (Jira, Bitbucket, etc.). Development teams work with them.
- Platform Integro. Most often, developers do not work with it directly, but it is she who supports the work of all automation.
- Delivery, orchestration and discovery services (e.g. Jeknins, Consul, Nomad). With their help, we deploy the code on the servers and ensure that the services work with each other.
- Physical layer (server, OS, related software). At this level, our code works. It can be either a physical server or a virtual one (LXC, KVM, Docker).
Based on this concept, we divide the areas of responsibility within the DI team. The first two levels are in the area of responsibility of the Integro development area, and the last two levels are already in the area of responsibility of DevOps. This separation allows you to focus on tasks and does not interfere with interaction, because we are next to each other and constantly exchange knowledge and experience.Integro
Let's focus on Integro and start with the technology stack:- CentOs 7
- Docker + Nomad + Consul + Vault
- Java 11 (the old Integro monolith will remain in Java 8)
- Spring Boot 2.X + Spring Cloud Config
- PostgreSql 11
- Rabbitmq
- Apache ignite
- Camunda (embedded)
- Grafana + Graphite + Prometheus + Jaeger + ELK
- Web UI: React (CSR) + MobX
- SSO: Keycloak
We adhere to the principle of microservice development, although we have legacy in the form of a monolith of the earlier version of Integro. Each microservice is spinning in its docker container, the services communicate with each other through HTTP requests and RabbitMQ messages. Microservices find each other through Consul and execute a request to it, passing authorization through SSO (Keycloak, OAuth 2 / OpenID Connect). As a real-life example, consider the interaction with Jenkins, which consists of the following steps:
As a real-life example, consider the interaction with Jenkins, which consists of the following steps:- The workflow management microservice (hereinafter referred to as the Flow microservice) wants to run the assembly in Jenkins. To do this, he finds through Consul IP: PORT microservice integration with Jenkins (hereinafter Jenkins microservice) and sends him an asynchronous request to start the assembly in Jenkins.
- After receiving the request, the Jenkins microservice generates and responds with a Job ID, by which it will then be possible to identify the result of the work. Along with this, he starts the build in Jenkins through a call to the REST API.
- Jenkins builds and, when finished, sends a webhook with the results to the Jenkins microservice.
- A Jenkins microservice, having received a webhook, generates a message about the completion of the request processing and attaches the results to it. The generated message is sent to the RabbitMQ queue.
- Through RabbitMQ, the published message gets to the Flow microservice, which learns about the result of processing its task by comparing the Job ID from the request and the received message.
Now we have about 30 microservices that can be divided into several groups:- Configuration management.
- (, ).
- .
- (jenkins, nomad, consul . .).
- (, . .).
- Web- (UI , . .).
- - .
- workflow .
Workflow
Integro automates activities related to the task life cycle. Simplified by the life cycle of a task, we mean the workflow of a task in Jira. In our development processes, there are several variations of workflow depending on the project, type of task and options selected in a particular task. Consider the workflow that we use most often: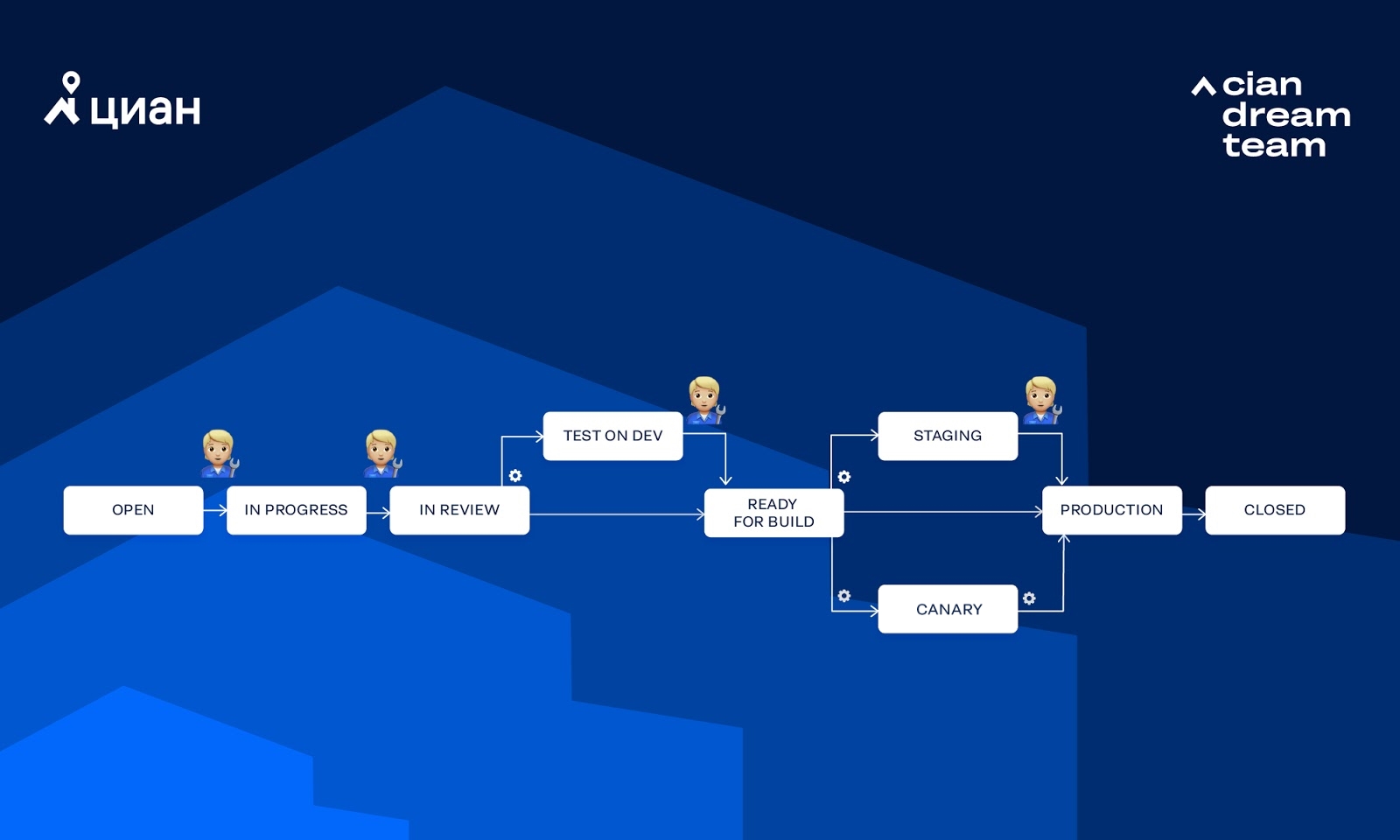 In the diagram, the gear indicates that transition is called by Integro automatically, while the human figure means that transition is called manually by the person. Let's look at a few ways that a task can go through this workflow.Completely manual testing for DEV + BETA without canary tests (usually we release a monolith):
In the diagram, the gear indicates that transition is called by Integro automatically, while the human figure means that transition is called manually by the person. Let's look at a few ways that a task can go through this workflow.Completely manual testing for DEV + BETA without canary tests (usually we release a monolith):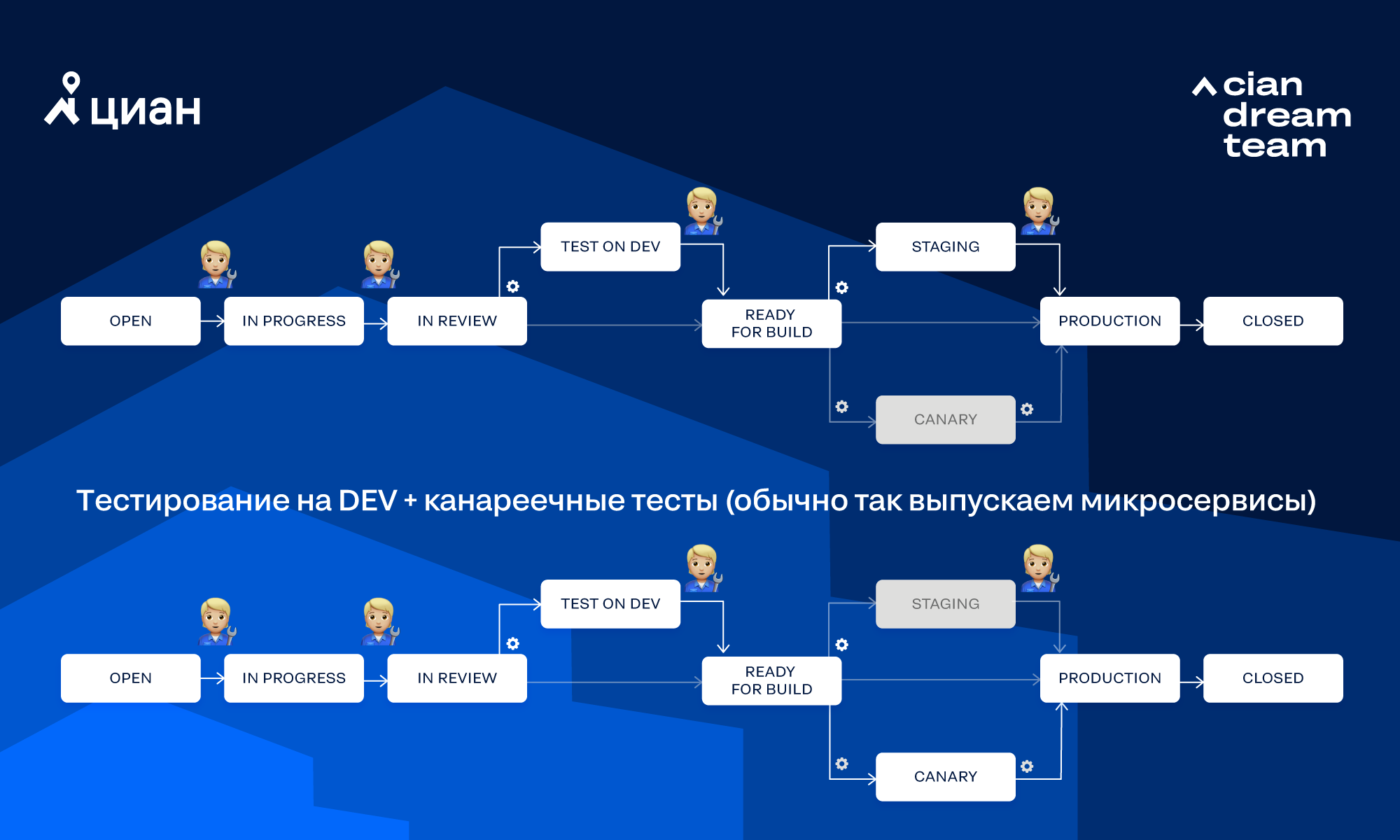 There may be other combinations of transition. Sometimes the path that the task will take can be selected through options in Jira.
There may be other combinations of transition. Sometimes the path that the task will take can be selected through options in Jira.Task movement
Consider the basic steps that are performed when the task moves along the workflow "Testing for DEV + Canary Tests":1. The developer or PM creates the task.2. The developer takes the task to work. Upon completion, transfers it to the status of IN REVIEW.3. Jira sends Webhook towards the Jira microservice (is responsible for integration with Jira).4. The Jira microservice sends a request to the Flow service (it is responsible for the internal workflows in which the work is performed) to start the workflow.5. Inside the Flow service:- The reviewers for the task are assigned (Users-microservice that knows everything about users + Jira-microservice).
- Source- ( , ) , ( Jira). , .
- :
i) master- (Git- ).
ii) (Bitbucket-).
iii) Pull Request (Bitbucket-).
iv) Pull Request (Notify- ).
v) , DEV (Jenkins- Jenkins).
vi) , Integro Approve Pull Request (Bitbucket-). - Integro Approve Pull Request .
- As soon as all necessary Approve have been received (including the automated tests have been successfully passed), Integro transfers the task to the Test on Dev status (Jira microservice).
6. Testers test the task. If there are no problems, then they transfer the task to Ready For Build status.7. Integro “sees” that the task is ready for release, and launches its deployment in canary mode (Jenkins microservice). Readiness for release is determined by a set of rules. For example, a task in the required status, there are no locks on other tasks, now there are no active calculations of this microservice, etc.8. The task is transferred to the Canary status (Jira microservice).9. Jenkins runs through Nomad a deployment of tasks in canary mode (usually 1-3 instances) and notifies the release monitoring service (DeployWatch microservice) of the calculation.10. DeployWatch-microservice collects background errors and responds to it if necessary. If the background error is exceeded (the norm of the background is calculated automatically), developers are notified via the Notify microservice. If after 5 minutes the developer did not respond (clicked Revert or Stay), then automatic rollback of the canary instances starts. If the background is not exceeded, then the developer must manually launch the deployment of the task for Production (by pressing the button in the UI). If within 60 minutes the developer did not launch a deployment in Production, then the canary instances will also be pumped out for security reasons.11. After launching the deployment to Production:- The task is transferred to the Production status (Jira microservice).
- The Jenkins microservice starts the deployment process and notifies the deployment of the DeployWatch microservice.
- DeployWatch-microservice verifies that all containers were updated on Production (there were cases when not all were updated).
- A notification about the results of the deployment to Production is sent through the Notify microservice.
12. The developers will have 30 minutes to start the rollback of the task with Production in case of detection of incorrect behavior of the microservice. After this time the task will be automatically poured into the master (Git-microservice).13. After a successful merge in master, the task status will be changed to Closed (Jira microservice).The scheme does not pretend to be fully detailed (in reality, there are even more steps), but it allows you to evaluate the degree of integration into the processes. We do not consider this scheme ideal and improve the processes of automatic tracking of releases and deploy.What's next
We have big plans for the development of automation, for example, the rejection of manual operations during monolith releases, improvement of monitoring during automatic deployment, improvement of interaction with developers.But let’s stop at this place. We covered superficially many topics in the automation review, some did not touch upon them at all, so we will be happy to answer questions. We are waiting for suggestions on what to cover in detail, write in the comments.Source: https://habr.com/ru/post/undefined/
All Articles