NiFi wird immer beliebter und mit jeder neuen Version werden immer mehr Tools für die Arbeit mit Daten verfügbar. Es kann jedoch erforderlich sein, ein eigenes Tool zu haben, um ein bestimmtes Problem zu lösen. Apache Nifi hat über 300 Prozessoren im Basispaket. Nifi-Prozessor Es ist der Hauptbaustein für die Erstellung eines Datenflusses im NiFi-Ökosystem. Prozessoren bieten eine Schnittstelle, über die NiFi Zugriff auf die Flussdatei, ihre Attribute und Inhalte bietet. Ein eigener benutzerdefinierter Prozessor spart Energie, Zeit und Aufmerksamkeit des Benutzers, da anstelle vieler einfacher Prozessorelemente nur eines in der Benutzeroberfläche angezeigt und nur eines ausgeführt wird (nun, oder wie viel Sie schreiben). Wie bei Standardprozessoren können Sie mit einem benutzerdefinierten Prozessor verschiedene Vorgänge ausführen und den Inhalt einer Flussdatei verarbeiten. Heute werden wir über Standardtools zur Erweiterung der Funktionalität sprechen.
Es ist der Hauptbaustein für die Erstellung eines Datenflusses im NiFi-Ökosystem. Prozessoren bieten eine Schnittstelle, über die NiFi Zugriff auf die Flussdatei, ihre Attribute und Inhalte bietet. Ein eigener benutzerdefinierter Prozessor spart Energie, Zeit und Aufmerksamkeit des Benutzers, da anstelle vieler einfacher Prozessorelemente nur eines in der Benutzeroberfläche angezeigt und nur eines ausgeführt wird (nun, oder wie viel Sie schreiben). Wie bei Standardprozessoren können Sie mit einem benutzerdefinierten Prozessor verschiedene Vorgänge ausführen und den Inhalt einer Flussdatei verarbeiten. Heute werden wir über Standardtools zur Erweiterung der Funktionalität sprechen.ExecuteScript
ExecuteScript ist ein universeller Prozessor, der zur Implementierung von Geschäftslogik in einer Programmiersprache (Groovy, Jython, Javascript, JRuby) entwickelt wurde. Mit diesem Ansatz erhalten Sie schnell die gewünschte Funktionalität. Um den Zugriff auf NiFi-Komponenten in einem Skript zu ermöglichen, können die folgenden Variablen verwendet werden:Sitzung : Eine Variable vom Typ org.apache.nifi.processor.ProcessSession. Mit der Variablen können Sie Operationen mit Flowfile ausführen, z. B. create (), putAttribute () und Transfer () sowie read () und write ().Kontext : org.apache.nifi.processor.ProcessContext. Es kann verwendet werden, um Prozessoreigenschaften, Beziehungen, Controller-Services und StateManager abzurufen.REL_SUCCESS : Beziehung "Erfolg".REL_FAILURE : FehlerbeziehungDynamische Eigenschaften : In ExecuteScript definierte dynamische Eigenschaften werden als Variablen an die Skript-Engine übergeben und als PropertyValue festgelegt. Auf diese Weise können Sie den Wert der Eigenschaft abrufen, den Wert in den entsprechenden Datentyp konvertieren, z. B. logisch usw.Zur Verwendung wählen Sie einfach Script Engineden Speicherort der Datei Script Filemit unserem Skript oder dem Skript selbst aus und geben Sie ihn an Script Body.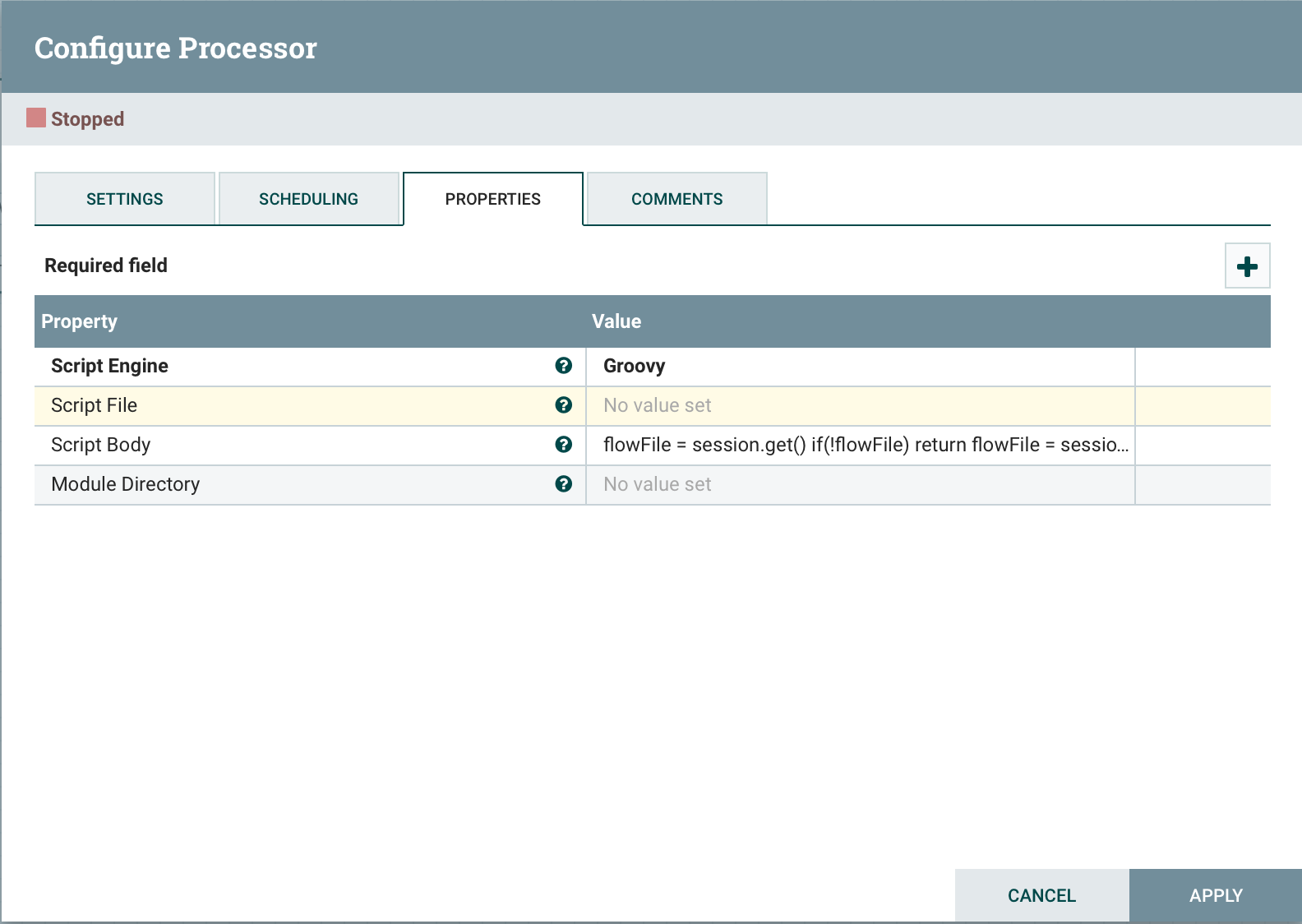 Schauen wir uns einige Beispiele an:Holen Sie sich eine Stream-Datei aus der Warteschlange
Schauen wir uns einige Beispiele an:Holen Sie sich eine Stream-Datei aus der WarteschlangeflowFile = session.get()
if(!flowFile) return
Generieren Sie eine neue FlowFileflowFile = session.create()
// Additional processing here
Attribut zu FlowFile hinzufügenflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Extrahieren und verarbeiten Sie alle Attribute.flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Loggerlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
Sie können erweiterte Funktionen in ExecuteScript verwenden. Weitere Informationen hierzu finden Sie im Artikel ExecuteScript-Kochbuch.ExecuteGroovyScript
ExecuteGroovyScript hat die gleiche Funktionalität wie ExecuteScript, aber anstelle eines Zoos gültiger Sprachen können Sie nur eine - groovy - verwenden. Der Hauptvorteil dieses Prozessors ist die bequemere Nutzung von Servicediensten. Zusätzlich zu den Standardvariablen Sitzung, Kontext usw. Sie können dynamische Eigenschaften mit dem Präfix CTL und SQL definieren. Ab Version 1.11 wurde die Unterstützung für RecordReader und Record Writer angezeigt. Alle Eigenschaften sind HashMap, das den "Dienstnamen" als Schlüssel verwendet, und der Wert ist abhängig von der Eigenschaft ein bestimmtes Objekt:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
Diese Informationen erleichtern bereits das Leben. Wir können in die Quellen schauen oder Dokumentation für eine bestimmte Klasse finden.Arbeiten mit der DatenbankWenn wir die SQL.DB-Eigenschaft definieren und DBCPService binden, greifen wir über den Code auf die Eigenschaft zu. SQL.DB.rows('select * from table')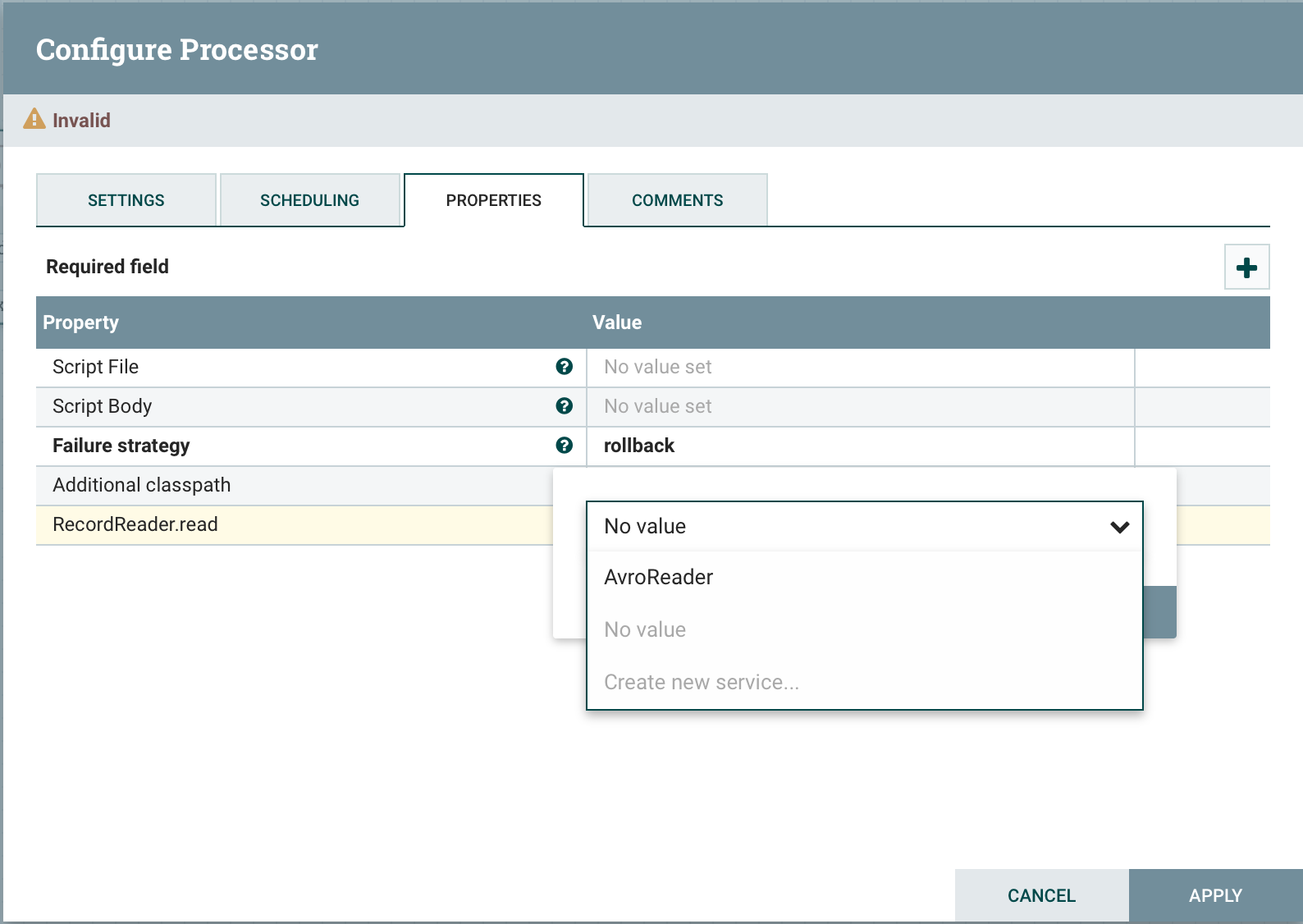 Der Prozessor akzeptiert vor der Ausführung automatisch eine Verbindung vom dbcp-Dienst und verarbeitet die Transaktion. Datenbanktransaktionen werden automatisch zurückgesetzt, wenn ein Fehler auftritt, und bei Erfolg festgeschrieben. In ExecuteGroovyScript können Sie Start- und Stoppereignisse abfangen, indem Sie die entsprechenden statischen Methoden implementieren.
Der Prozessor akzeptiert vor der Ausführung automatisch eine Verbindung vom dbcp-Dienst und verarbeitet die Transaktion. Datenbanktransaktionen werden automatisch zurückgesetzt, wenn ein Fehler auftritt, und bei Erfolg festgeschrieben. In ExecuteGroovyScript können Sie Start- und Stoppereignisse abfangen, indem Sie die entsprechenden statischen Methoden implementieren.import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
Ein weiterer interessanter Prozessor. Um es zu verwenden, müssen Sie eine Klasse deklarieren, die die Implementierungsschnittstelle implementiert, und eine Prozessorvariable definieren. Sie können einen beliebigen PropertyDescriptor oder eine Beziehung definieren, auch auf das übergeordnete ComponentLog zugreifen und die Methoden void onScheduled (ProcessContext-Kontext) und void onStopped (ProcessContext-Kontext) definieren. Diese Methoden werden aufgerufen, wenn ein geplantes Startereignis in NiFi (onScheduled) auftritt und wenn es stoppt (onScheduled).class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Die Logik muss in der Methode implementiert sein void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
Es ist nicht erforderlich, alle in der Schnittstelle deklarierten Methoden zu beschreiben. Lassen Sie uns also eine abstrakte Klasse umgehen, in der wir die folgende Methode deklarieren:abstract void executeScript(ProcessContext context, ProcessSession session)
Die Methode, die wir aufrufen werdenvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Jetzt deklarieren wir eine Nachfolgerklasse BaseGroovyProcessorund beschreiben unser executeScript. Außerdem fügen wir Relationship RELSUCCESS und RELFAILURE hinzu.import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
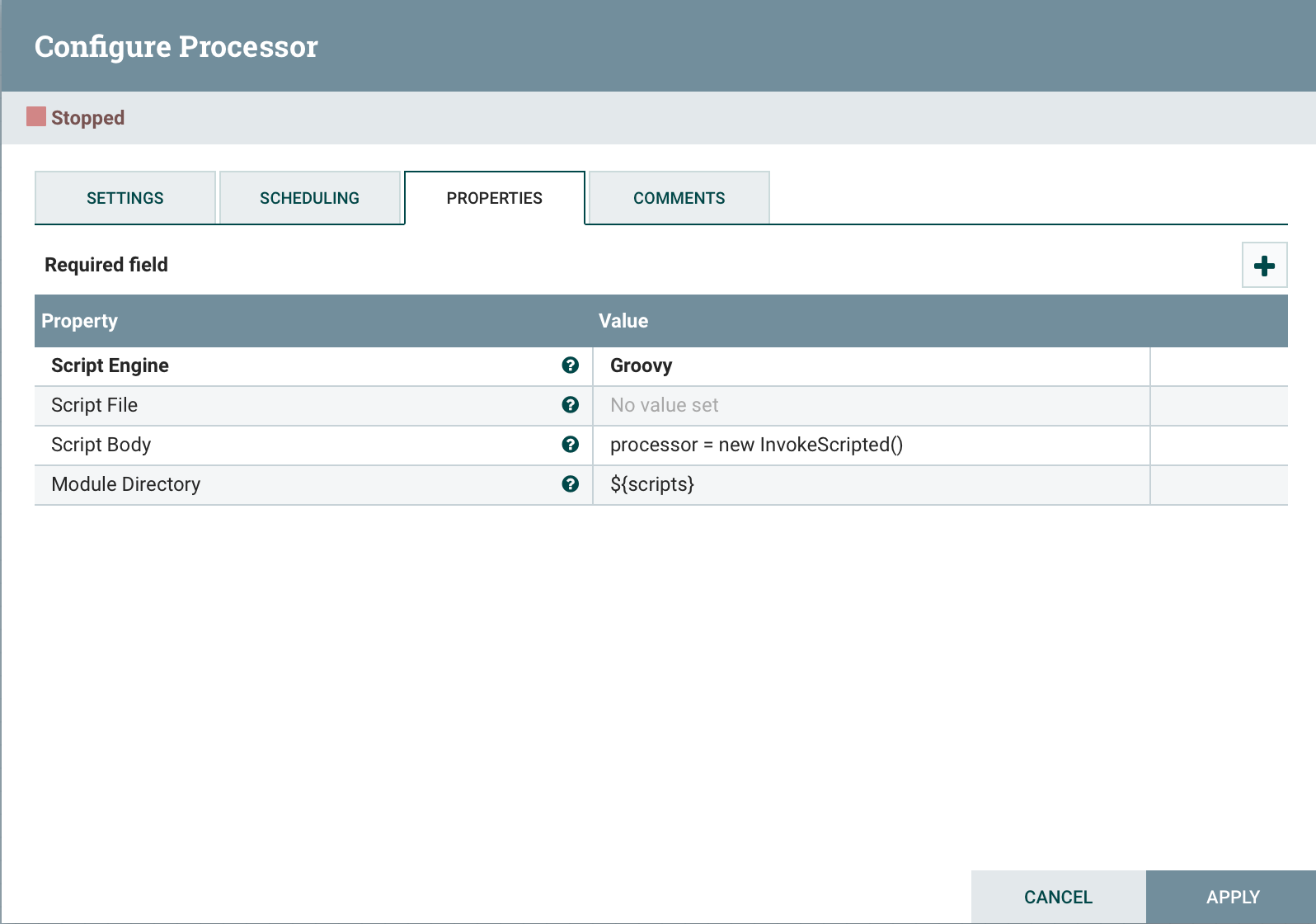 Am Ende des Codes hinzufügen.
Am Ende des Codes hinzufügen. processor = new InvokeScripted()Dieser Ansatz ähnelt dem Erstellen eines benutzerdefinierten Prozessors.Fazit
Das Erstellen eines benutzerdefinierten Prozessors ist nicht die einfachste Sache - zum ersten Mal müssen Sie hart arbeiten, um dies herauszufinden, aber die Vorteile dieser Aktion sind unbestreitbar.Beitrag erstellt vom Rostelecom Data Management Team