Hallo!In diesem Artikel werde ich Ihnen erklären, wie Sie eine Seite in Atlassian Confluence mit einer Tabelle erstellen, deren Daten aus einer REST-Anforderung stammen.Wir werden in Confluence eine Seite mit einer Tabelle erstellen, die Projektdaten in Jira enthält. Wir erhalten diese Daten von Jira mithilfe der Projektmethode aus der Standard-Jira-REST-API.Sie können das Video zu diesem Artikel hier ansehen .Installieren Sie Power Scripts for Confluence
Wir werden die Jira REST-API mithilfe des Power Scripts for Confluence- Plugins aufrufen . Dies ist ein kostenloses Plugin, daher kostet Sie diese Lösung nichts.Nun, das erste, was wir tun müssen, ist das Power Scripts for Confluence-Plugin in unserem Confluence zu installieren. Detaillierte Anweisungen dazu finden Sie hier .Schreiben Sie ein Skript
Gehen Sie nun zum Menüpunkt Zahnrad -> Apps verwalten -> SIL Manager. Erstellen Sie die Datei getProjects.sil mit dem folgenden Code:
Erstellen Sie die Datei getProjects.sil mit dem folgenden Code:struct Project {
string key;
string name;
string projectTypeKey;
}
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
Project [] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
runnerLog(projects);
return projects;
Ändern Sie die Adresse von host.docker.internal : 8080 / in die Adresse Ihrer Jira-Instanz.Führen Sie das Skript aus, um zu überprüfen, ob die Daten aus Jira ausgewählt wurden: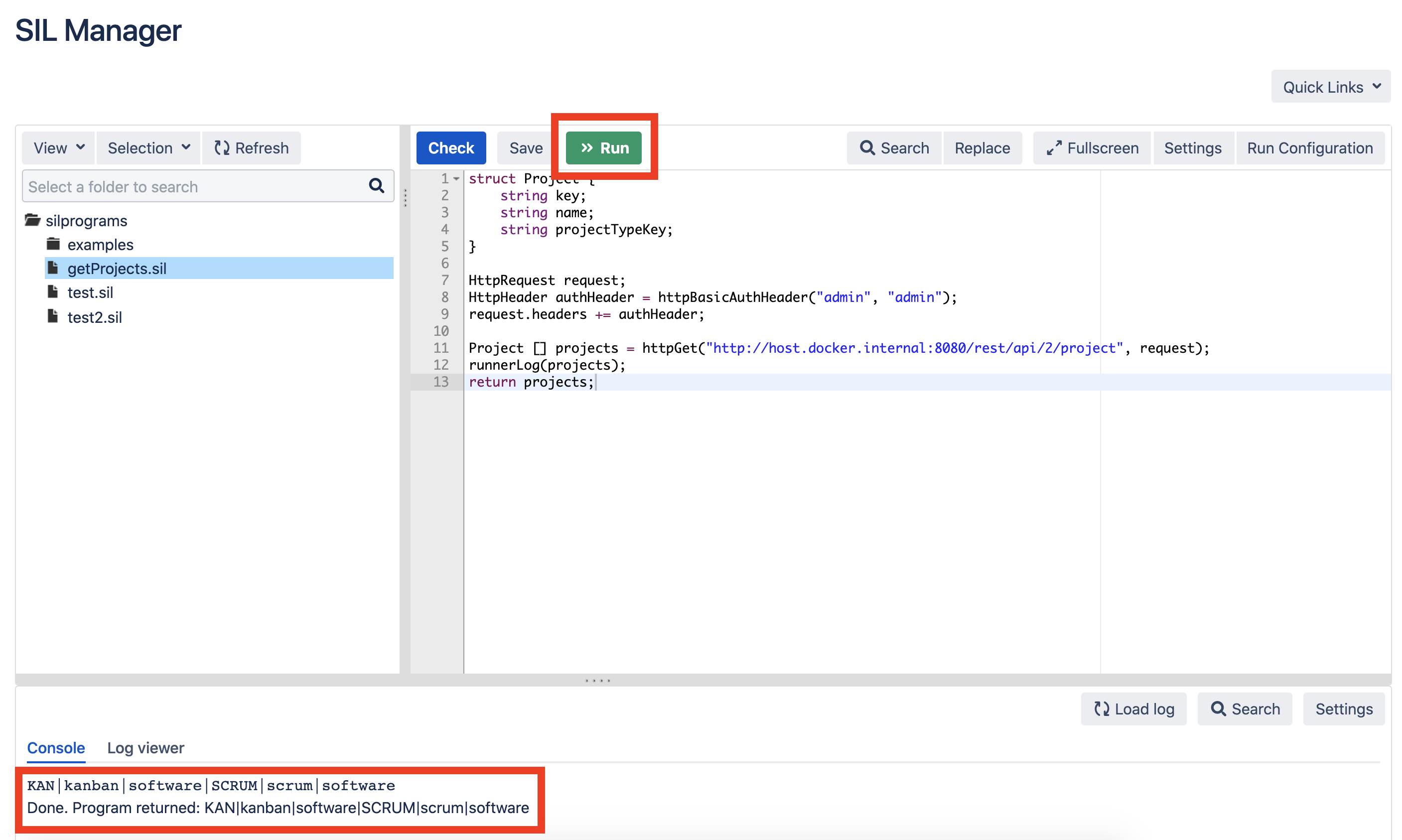
Erstellen Sie eine Seite in Confluence
Erstellen Sie nun eine Seite in Confluence mit dem SIL-Tabellenmakro . Geben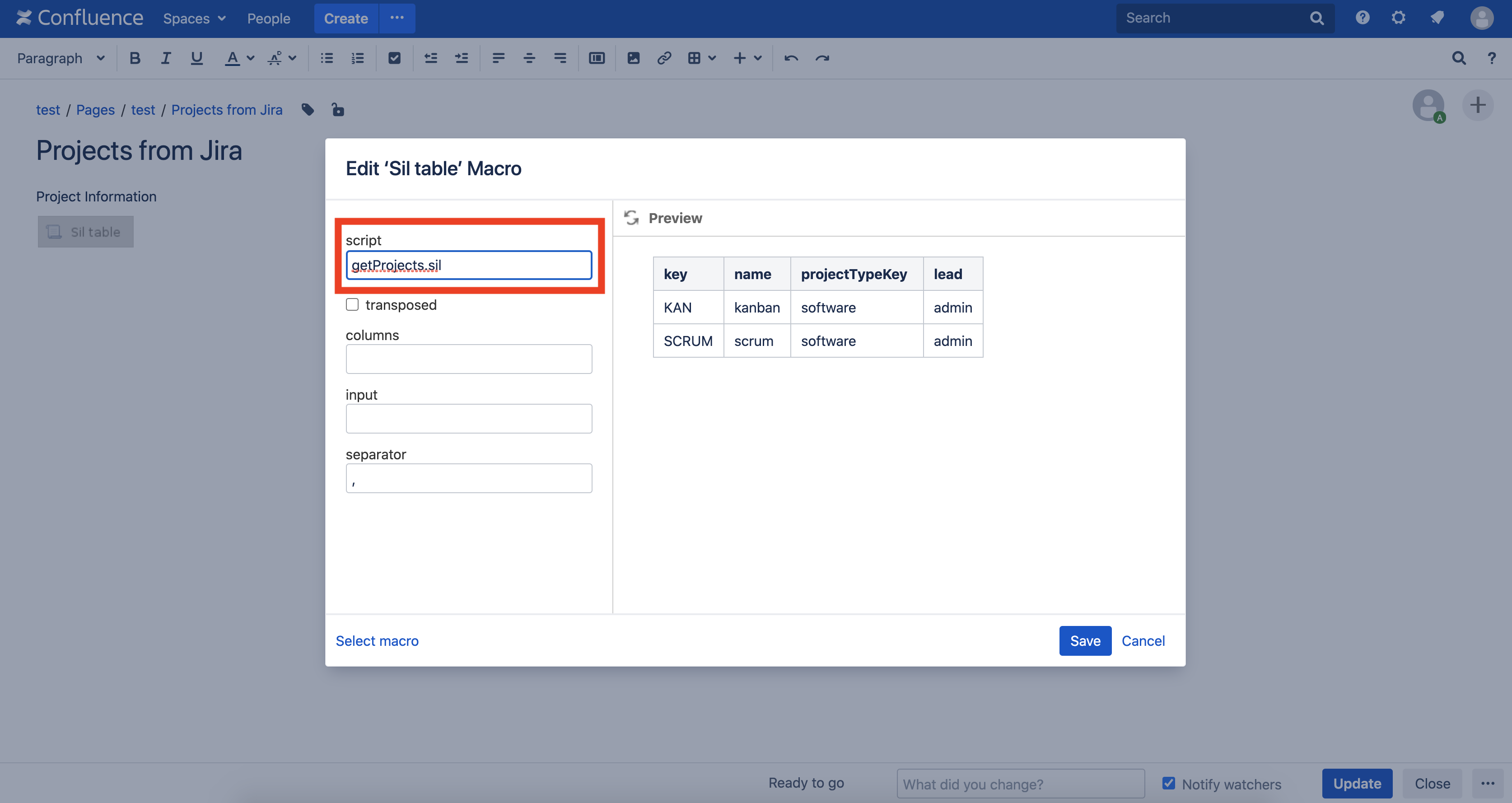 Sie im Feld "Skripte" den Namen unseres Skripts "getProjects.sil" ein: Veröffentlichen Sie die Seite, und Sie sehen das folgende Ergebnis:
Sie im Feld "Skripte" den Namen unseres Skripts "getProjects.sil" ein: Veröffentlichen Sie die Seite, und Sie sehen das folgende Ergebnis: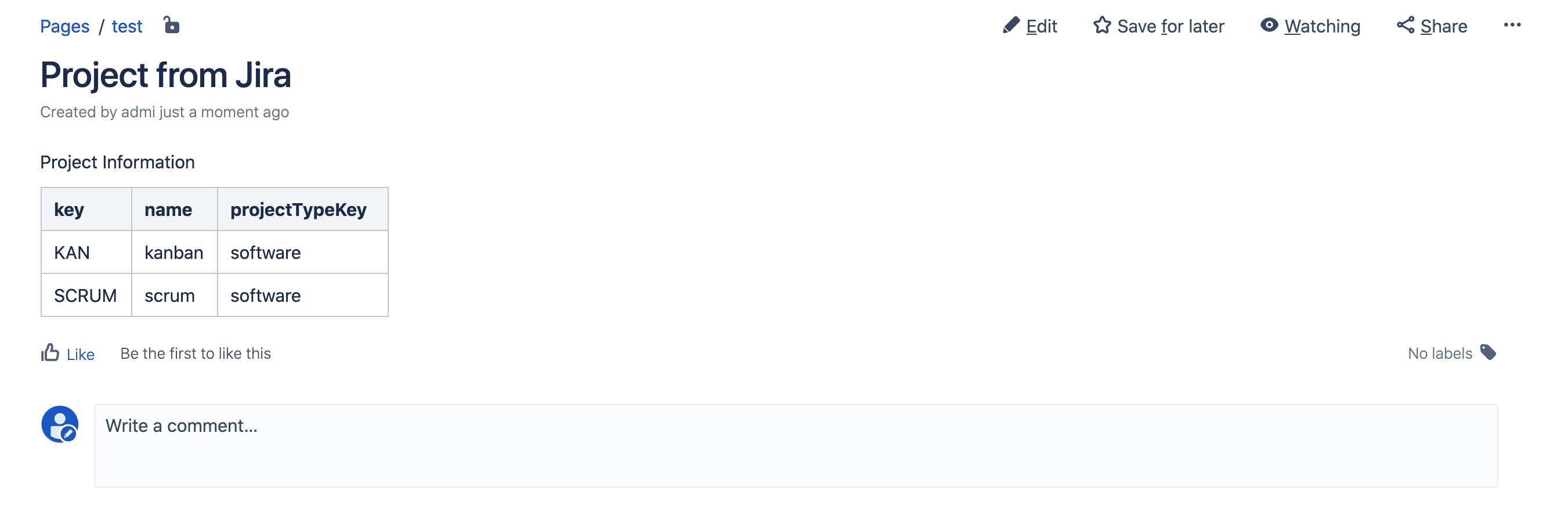
Lassen Sie uns die Aufgabe komplizieren
Fügen Sie der Tabelle die folgenden Funktionen hinzu:- Informationen zum Projektmanager anzeigen
- Geben Sie den Feldern verständlichere Namen und vorzugsweise auf Russisch
Nehmen Sie zunächst Änderungen am Skript getProjects.sil vor.Gleichzeitig überarbeiten wir ein wenig.Unser Skript wird Folgendes tun:- Erhalten Sie Projektdaten von Jira durch einen Aufruf der Jira REST-API
- Wir konvertieren die empfangenen Projektdaten in eine tabellarische Ansicht
- Drucken Sie das Ergebnis
So sieht es im Code aus:Project [] projects = getProjectData();
TableRow [] tableRows = convertProjectDataToTableData(projects);
return tableRows;
Geben wir nun an, wie wir Projektdaten erhalten:- Erstellen Sie eine Anfrage
- Erstellen Sie in der Anforderung einen Header mit Informationen über den Benutzer, der Daten von Jira empfängt
- Fügen Sie den Parameter expand zu unserer Abfrage hinzu. Wir müssen Daten über den Projektmanager auswählen, aber in der Standardantwort gibt es keine solchen Daten. Daher müssen wir Jira mitteilen, dass wir die Daten zum Projektmanager in der Antwort sehen möchten. Hierzu wird der Parameter expand verwendet.
- Wir erfüllen die Anfrage
- Daten zurückgeben
Aber die Wörter wurden zu Code:function getProjectData() {
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
HttpQueryParam param = httpCreateParameter("expand", "description,lead,url,projectKeys");
request.parameters += param;
Project[] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
return projects;
}
Definieren wir nun Datenstrukturen für unsere Projekte.Hier ist die Antwort, die die Projektmethode von der Jira REST-API zurückgibt (ich habe unnötige Daten gelöscht, um die Antwort kürzer und daher lesbarer zu machen):[
{
"key":"KAN",
"lead":{
"name":"admin",
"displayName":"Alexey Matveev",
},
"name":"kanban",
"projectTypeKey":"software"
},
{
"key":"SCRUM",
"description":"",
"lead":{
"name":"admin",
"displayName":"Alexey Matveev",
},
"name":"scrum",
"projectTypeKey":"software"
}
]
Wie wir sehen können, werden die Werte für die Felder key, name und projectTypeKey auf der ersten Ebene unseres json definiert. Aber für das Lead-Feld sehen wir anstelle des Werts json. Und dieser JSON enthält bereits die Werte der Felder name und displayName. Daher erstellen wir zuerst eine Struktur für json im Feld Lead (Lead):struct Lead {
string name;
string displayName;
}
Jetzt sind wir bereit, die Struktur für die erste Ebene unseres json (Projekts) zu erstellen:struct Project {
string key;
string name;
string projectTypeKey;
Lead lead;
}
Das Problem ist jedoch, dass das SIL-Tabellenmakro nur mit json mit einer Verschachtelungsebene arbeiten kann. Daher müssen wir unsere Struktur mit zwei Verschachtelungsebenen (Projekt) in eine Struktur mit einer Verschachtelungsebene (flache Struktur) konvertieren. Erstellen Sie zunächst eine flache Struktur (TableRow):struct TableRow {
string key;
string name;
string projectTypeKey;
string lead;
string leadDisplayName;
}
Und jetzt schreiben wir eine Funktion zum Konvertieren der Daten in der Projektstruktur in die TableRow-Struktur:function convertProjectDataToTableData(Project [] projectData) {
TableRow [] tableRows;
for (Project project in projectData) {
TableRow tableRow;
tableRow.key = project.key;
tableRow.name = project.name;
tableRow.projectTypeKey = project.projectTypeKey;
tableRow.lead = project.lead.name;
tableRow.leadDisplayName = project.lead.displayName;
tableRows = arrayAddElement(tableRows, tableRow);
}
return tableRows;
}
Alle. Das Skript ist fertig!Hier ist der endgültige getProjects.sil-Code:struct Lead {
string name;
string displayName;
}
struct Project {
string key;
string name;
string projectTypeKey;
Lead lead;
}
struct TableRow {
string key;
string name;
string projectTypeKey;
string lead;
string leadDisplayName;
}
function getProjectData() {
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
HttpQueryParam param = httpCreateParameter("expand", "description,lead,url,projectKeys");
request.parameters += param;
string pp = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
runnerLog(pp);
Project[] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
return projects;
}
function convertProjectDataToTableData(Project [] projectData) {
TableRow [] tableRows;
for (Project project in projectData) {
TableRow tableRow;
tableRow.key = project.key;
tableRow.name = project.name;
tableRow.projectTypeKey = project.projectTypeKey;
tableRow.lead = project.lead.name;
tableRow.leadDisplayName = project.lead.displayName;
tableRows = arrayAddElement(tableRows, tableRow);
}
return tableRows;
}Project [] projects = getProjectData();
TableRow [] tableRows = convertProjectDataToTableData(projects);
return tableRows;
Jetzt aktualisieren wir die Seite in Confluence und sehen, dass unsere Daten zum Projektmanager abgerufen wurden: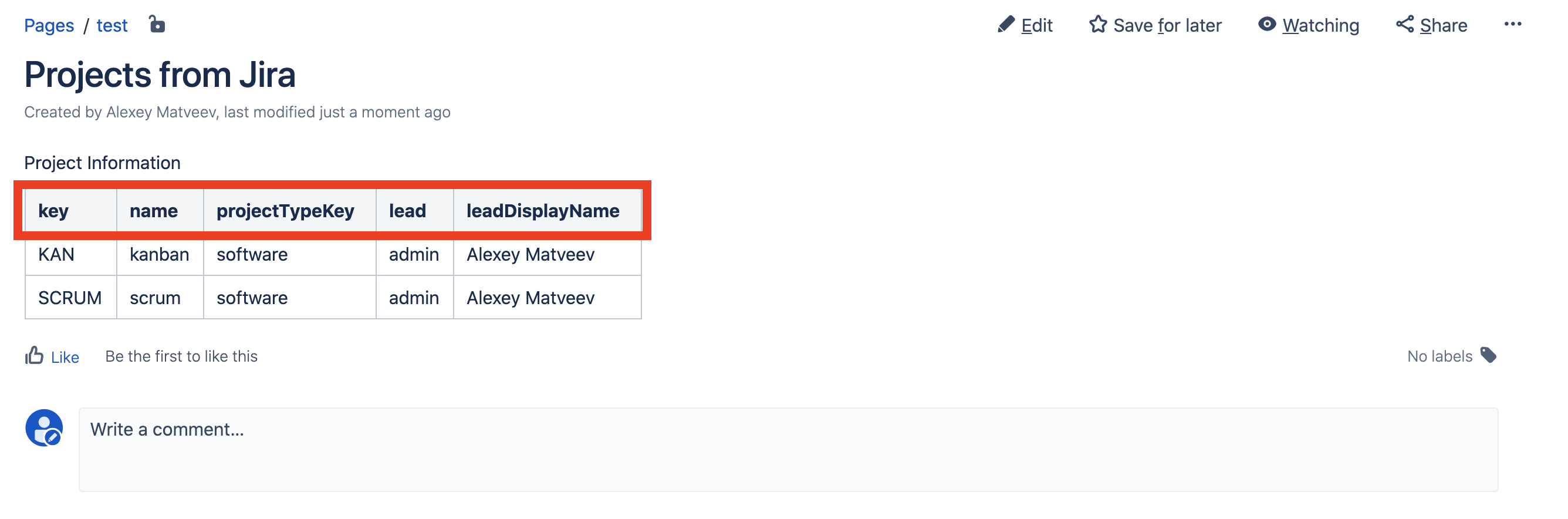 Aber die Spaltennamen sind irgendwie dunkel. Geben wir schönere Namen.Wir bearbeiten die Seite, bearbeiten das SIL-Tabellenmakro und geben "Projektschlüssel, Projektname, Projekttyp, Projektmanager, Name des Projektmanagers" in das Spaltenfeld ein:
Aber die Spaltennamen sind irgendwie dunkel. Geben wir schönere Namen.Wir bearbeiten die Seite, bearbeiten das SIL-Tabellenmakro und geben "Projektschlüssel, Projektname, Projekttyp, Projektmanager, Name des Projektmanagers" in das Spaltenfeld ein: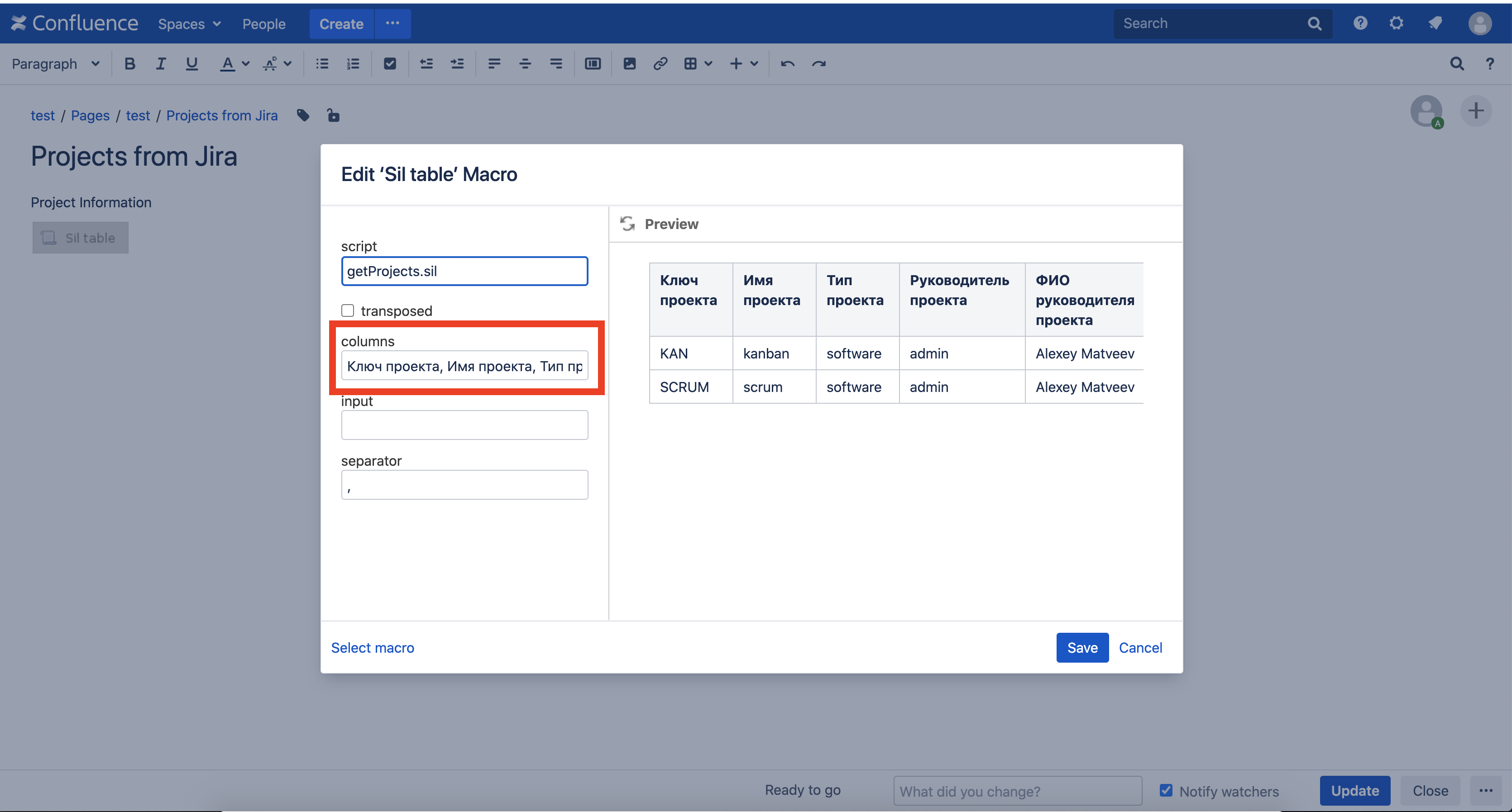 Speichern Sie die Seite und hier ist das Ergebnis:
Speichern Sie die Seite und hier ist das Ergebnis: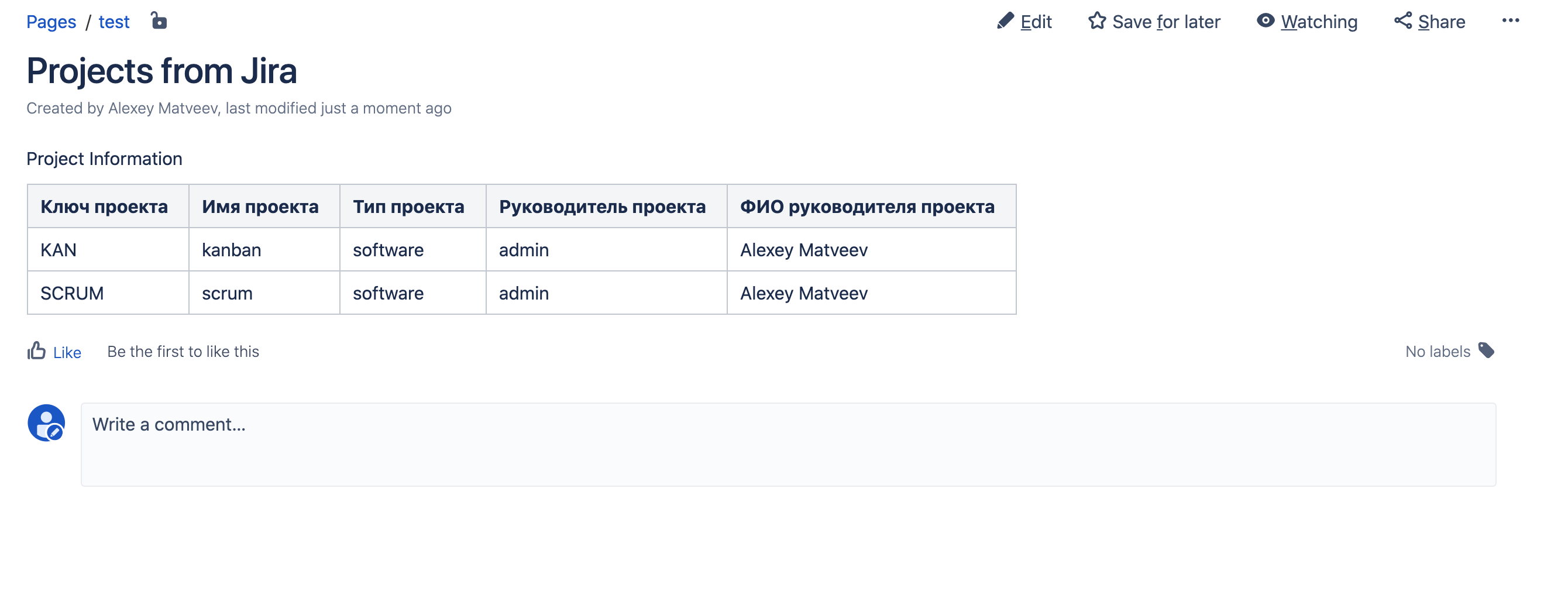 Alles hat sich herausgestellt!
Alles hat sich herausgestellt!