Hallo wieder. Heute setzen wir die Übersetzungsreihe im Vorfeld des Beginns des Grundkurses „Mathematik für Datenwissenschaften“ fort .
In einem kürzlich erschienenen Artikel haben wir darüber gesprochen, wie ein Anomaliedetektor in Power BI durch Integration von PyCaret erstellt werden kann, und Analysten und Datenanalysten dabei geholfen, Berichten und Dashboards ohne großen Aufwand maschinelles Lernen hinzuzufügen.In diesem Artikel wird erläutert, wie Sie eine Clusteranalyse mit PyCaret und Power BI durchführen. Wenn Sie noch nichts über PyCaret gehört haben, können Sie sich hier damit vertraut machen .Was wir im heutigen Leitfaden besprechen werden:- Was ist Clustering? Arten von Clustering.
- Lernen ohne Lehrer und Implementieren eines Clustering-Modells in Power BI.
- Analyse der Ergebnisse und Visualisierung der Informationen im Dashboard.
- Wie kann ein Clustering-Modell in der Produktion in Power BI bereitgestellt werden?
Bevor wir anfangen ...
Wenn Sie Python bereits zuvor verwendet haben, haben Sie höchstwahrscheinlich bereits Anaconda auf Ihrem Computer. Wenn nicht, können Sie die Anaconda-Distribution von Python 3.7 oder höher hier herunterladen .Umgebung einrichten
Bevor Sie die PyCaret-Funktionen für maschinelles Lernen in Power BI verwenden können, müssen Sie eine virtuelle Umgebung erstellen und darin installieren pycaret. Dazu müssen wir drei Schritte ausführen:Schritt 1 - Erstellen einer virtuellen UmgebungÖffnen Sie die Anaconda-Eingabeaufforderung und geben Sie Folgendes ein:conda create --name myenv python=3.7
Schritt 2 - PyCaret installieren FührenSie den folgenden Befehl an der Anaconda-Eingabeaufforderung aus:pip install pycaret
Die Installation kann 15 bis 20 Minuten dauern. Wenn Sie während der Installation auf Probleme stoßen, können Sie sich auf unserer Seite auf GitHub mit deren Lösung vertraut machen .Schritt 3 - Geben Sie in Power BI an, wo Python installiert ist.Die erstellte virtuelle Umgebung muss Power BI zugeordnet sein. Sie können dies mithilfe der globalen Einstellungen in Power BI Desktop tun (Datei -> Optionen -> Global -> Python-Skripterstellung). Die Anaconda-Umgebung wird standardmäßig in das Verzeichnis gestellt:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
Was ist Clustering?
Clustering ist eine Methode zum Aufteilen von Daten in Gruppen nach ähnlichen Merkmalen. Solche Gruppen können nützlich sein, um Daten zu untersuchen, Muster zu identifizieren und Teilmengen von Daten zu analysieren. Durch das Clustering von Daten können zugrunde liegende Datenstrukturen identifiziert werden, was in vielen Branchen hilfreich ist. Hier sind einige häufige Anwendungen für das Clustering in Unternehmen:- Marketing Kundensegmentierung.
- Analyse des Verbraucherverhaltens für Werbeaktionen und Rabatte.
- Identifizierung von Geoclustern während eines Ausbruchs, wie zum Beispiel COVID-19.
Clustering-Typen
Angesichts der subjektiven Natur von Clustering-Aufgaben gibt es verschiedene Algorithmen, die sich besser zur Lösung bestimmter Arten von Aufgaben eignen. Jeder Algorithmus hat seine eigenen Eigenschaften und mathematischen Begründungen, die der Verteilung von Clustern zugrunde liegen.Im heutigen Tutorial geht es um die Clusteranalyse in Power BI mit einer Python-Bibliothek namens PyCaret, und wir werden nicht weiter auf die Mathematik eingehen. Heute werden wir die k-means-Methode anwenden - eine der einfachsten und beliebtesten Unterrichtsmethoden ohne Lehrer. Weitere Informationen zur k-means-Methode finden Sie hier .
Heute werden wir die k-means-Methode anwenden - eine der einfachsten und beliebtesten Unterrichtsmethoden ohne Lehrer. Weitere Informationen zur k-means-Methode finden Sie hier .Geschäftlicher Zusammenhang
In diesem Handbuch verwenden wir einen vorgefertigten Datensatz aus der Global Health Expenditure-Datenbank der Weltgesundheitsorganisation. Es enthält die Gesundheitsausgaben als Prozentsatz des nationalen BIP für mehr als 200 Länder von 2000 bis 2017.Unsere Aufgabe ist es, Muster und Gruppen in diesen Daten mit der k-means-Methode zu finden.Daten finden Sie hier .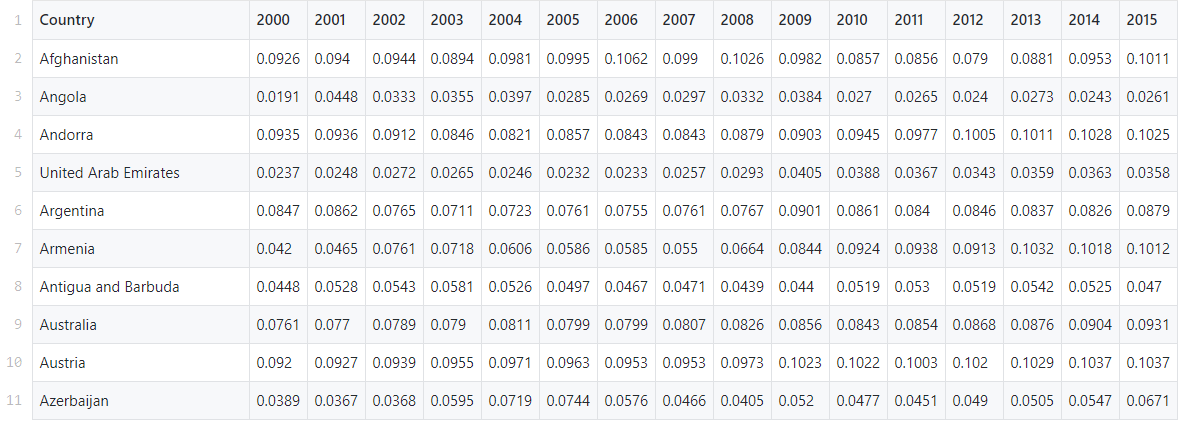
Also fangen wir an
Nachdem Sie die Anaconda-Umgebung eingerichtet und PyCaret installiert haben, die Grundlagen der Clusteranalyse und den Geschäftskontext verstanden haben, ist es an der Zeit, sich dem Geschäft zu widmen.1. Datenerfassung
Der erste Schritt besteht darin, das Dataset in Power BI Desktop zu importieren. Sie können Daten über den Webconnector herunterladen. (Power BI Desktop → Daten abrufen → Aus dem Web ). Link zur CSV-Datei: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .
Link zur CSV-Datei: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .2. Modelltraining
Um das Clustering-Modell in Power BI zu erlernen, müssen Sie ein Python-Skript im Power Query Editor ausführen ( Power Query Editor → Transformieren → Python-Skript ausführen ). Verwenden Sie den folgenden Code als Skript:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 Wir haben die Spalte "Land" des Sets mit dem Parameter ignoriert
Wir haben die Spalte "Land" des Sets mit dem Parameter ignoriert ignore_features. Es gibt viele Gründe, warum Sie möglicherweise bestimmte Spalten ausschließen müssen, um das Modell des maschinellen Lernens besser zu trainieren.Mit PyCaret können Sie unnötige Spalten ausblenden, anstatt sie zu löschen, da Sie sie möglicherweise in Zukunft für weitere Analysen benötigen. Zum Beispiel wollten wir im Moment nicht "Land" für das Training verwenden und haben diese Spalte an übergeben ignore_features.In PyCaret gibt es 8 gebrauchsfertige Algorithmen für maschinelles Lernen.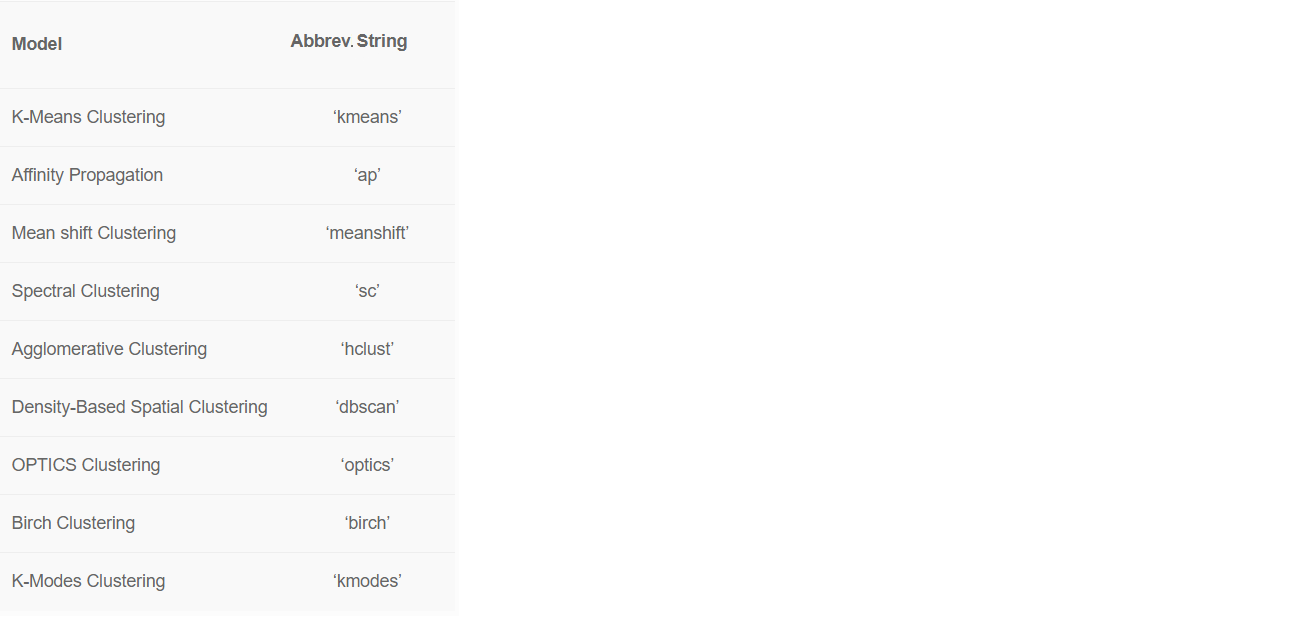 Standardmäßig trainiert PyCaret das k-means-Clustering-Modell auf vier Clustern. Die Standardwerte können jedoch leicht geändert werden:
Standardmäßig trainiert PyCaret das k-means-Clustering-Modell auf vier Clustern. Die Standardwerte können jedoch leicht geändert werden:- Verwenden Sie den Modellparameter in , um den Modelltyp zu ändern
get_clusters(). - Verwenden Sie die Option, um die Anzahl der Cluster zu ändern
num_clusters.
Auf diese Weise können Sie beispielsweise k-means Clustering in 6 Cluster durchführen.from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
Schlussfolgerung:
 Eine weitere Spalte mit einer Clusterbezeichnung wird dem Originaldatensatz hinzugefügt. Dann werden alle Werte im Jahr Spalte verwendet , um die Daten und weitere visualisieren in Strom BI zu normalisieren.So sieht das Endergebnis in Power BI aus.
Eine weitere Spalte mit einer Clusterbezeichnung wird dem Originaldatensatz hinzugefügt. Dann werden alle Werte im Jahr Spalte verwendet , um die Daten und weitere visualisieren in Strom BI zu normalisieren.So sieht das Endergebnis in Power BI aus.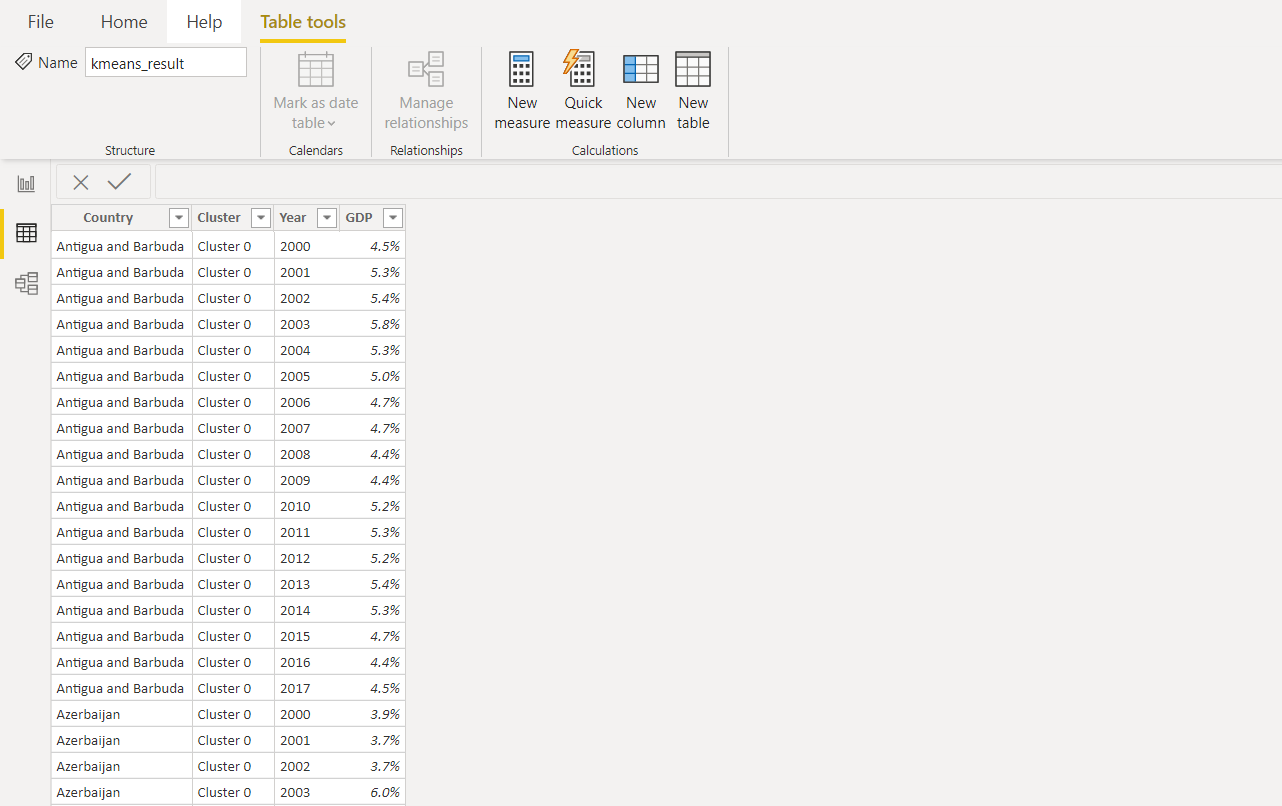
3. Dashboard
Wenn Sie in Power BI Cluster-Labels erhalten haben, können Sie diese im Dashboard in Power BI für Analysen visualisieren: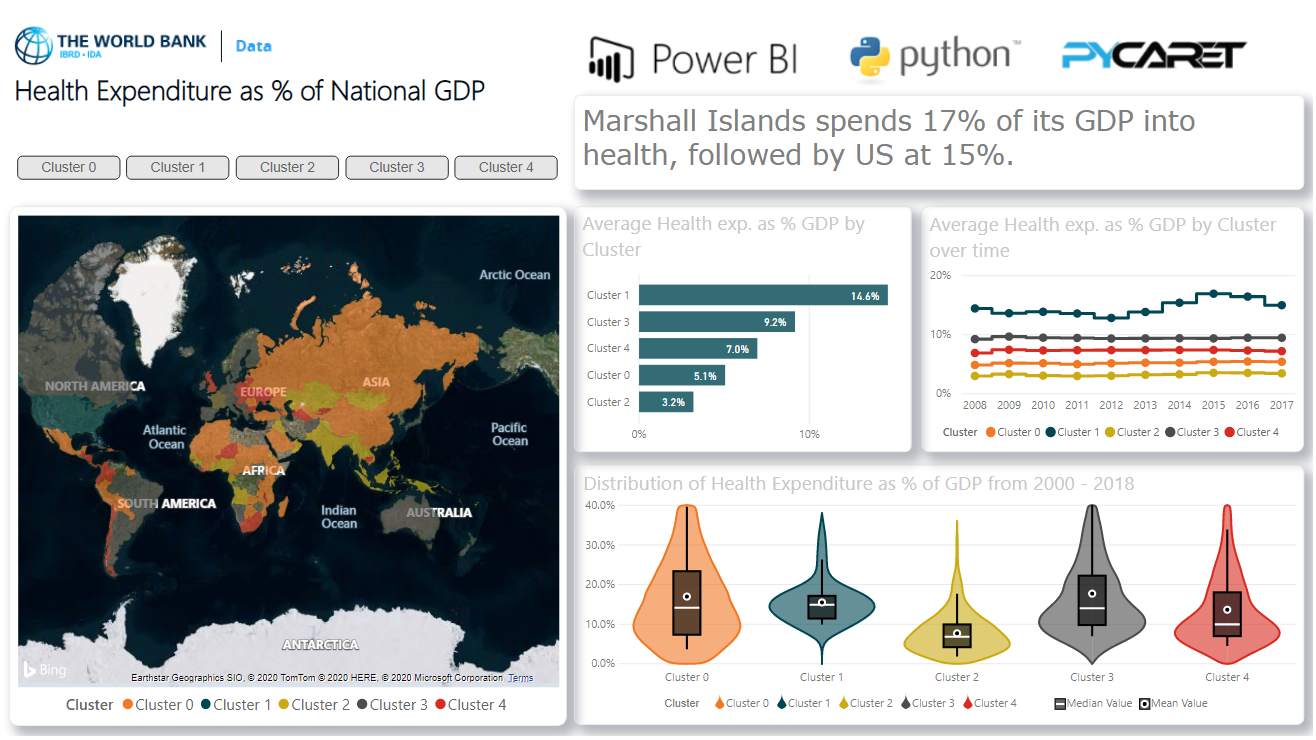
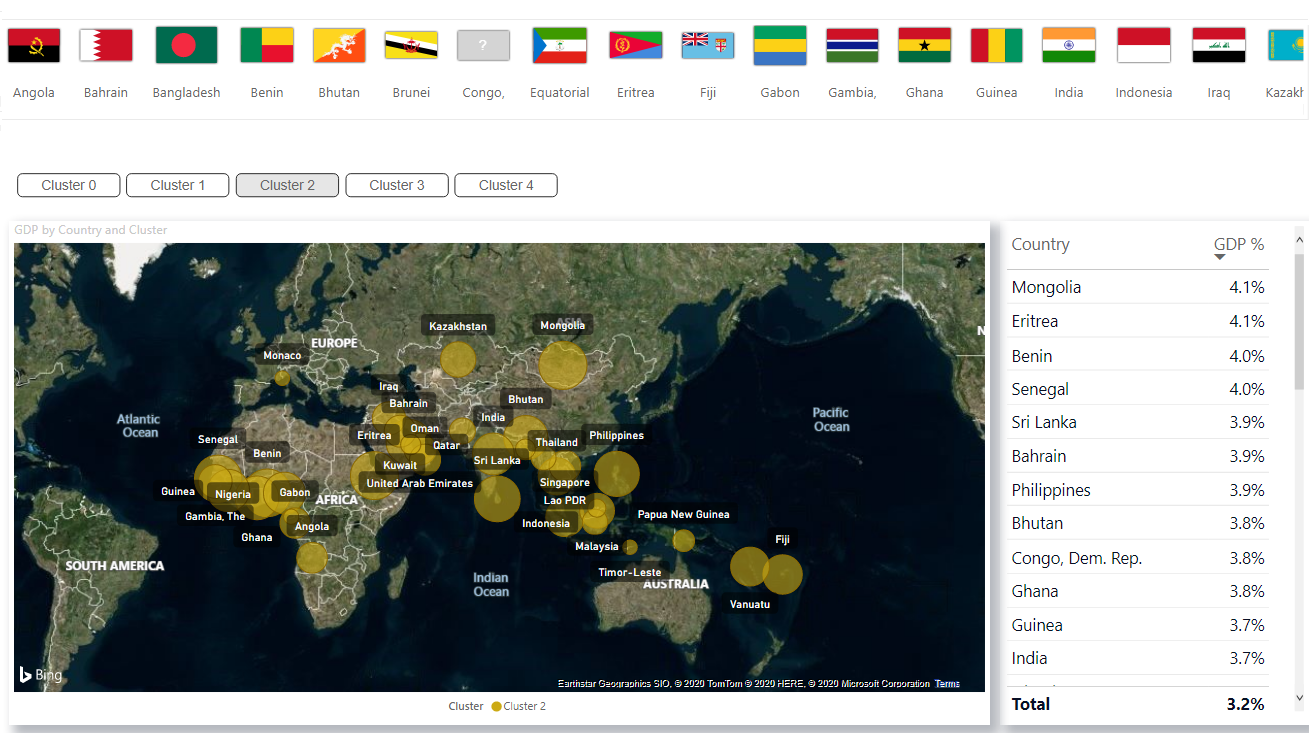 Sie können die PBIX-Datei und das Dataset von GitHub herunterladen .
Sie können die PBIX-Datei und das Dataset von GitHub herunterladen .Clustering-Implementierung
Oben haben wir die einfachste Clustering-Implementierung in Power BI demonstriert. Ich stelle fest, dass diese Methode das Clustering-Modell jedes Mal trainiert, wenn ein Dataset in Power BI aktualisiert wird. Dies kann aus folgenden Gründen ein Problem sein:- Wenn das Modell für die neuen Daten neu trainiert wird, können sich die Clusterbezeichnungen ändern (dh wenn früher einige Datenpunkte dem ersten Cluster zugewiesen wurden, können sie beim erneuten Training dem zweiten Cluster zugewiesen werden).
- Sie sollten nicht jedes Mal mehrere Stunden damit verbringen, das Modell neu zu trainieren.
Eine effektivere Möglichkeit, Clustering in Power BI zu implementieren, anstatt es immer wieder neu zu lernen, besteht darin, ein vorab geschultes Modell zum Erstellen von Cluster-Labels zu verwenden.Frühes Modelltraining
Sie können jede integrierte Entwicklungsumgebung (IDE) oder jedes Notebook verwenden, um das Modell zu trainieren. In diesem Beispiel haben wir das Clustering-Modell in Visual Studio Code trainiert.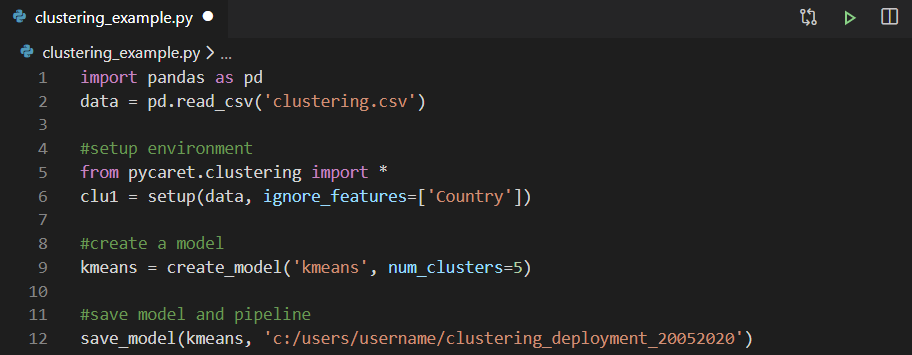 Anschließend wird das trainierte Modell als Pickle-Datei gespeichert und in Power Query importiert, um Cluster-Labels zu generieren.
Anschließend wird das trainierte Modell als Pickle-Datei gespeichert und in Power Query importiert, um Cluster-Labels zu generieren. Wenn Sie mehr über die Implementierung der Clusteranalyse in Jupyter Notebook mit PyCaret erfahren möchten, sehen Sie sich dieses zweiminütige Video an.
Wenn Sie mehr über die Implementierung der Clusteranalyse in Jupyter Notebook mit PyCaret erfahren möchten, sehen Sie sich dieses zweiminütige Video an.Verwendung des vorab trainierten Modells
Führen Sie den folgenden Code aus, um Tags aus dem vorab trainierten Modell zu generieren:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
Das Ergebnis ist das gleiche wie zuvor. Der einzige Unterschied besteht darin, dass bei Verwendung des vorab trainierten Modells die Tags basierend auf dem neuen Datensatz unter Verwendung des alten Modells und nicht auf der Grundlage des umgeschulten Modells generiert werden.Arbeiten Sie mit Power BI Service
Nachdem Sie die .pbix-Datei in den Power BI-Dienst hochgeladen haben, müssen Sie einige weitere Schritte ausführen, um eine reibungslose Integration der Pipeline für maschinelles Lernen in Ihre Datenpipeline sicherzustellen. Die Schritte sind wie folgt:- Aktivieren Sie die geplante Aktualisierung des Datasets. Auf diese Weise können Sie die Arbeitsmappe mit Ihrem zu aktualisierenden Dataset mithilfe eines Python-Skripts planen. Lesen Sie dazu den Abschnitt Konfigurieren der geplanten Aktualisierung , der auch Informationen zu Personal Gateway enthält.
- Personal Gateway installieren - Sie benötigen ein Personal Gateway, das in demselben Verzeichnis installiert sein muss, in dem Python installiert ist. Der Power BI-Dienst muss Zugriff auf die Python-Umgebung haben. Hier erfahren Sie mehr über die Installation und Konfiguration von Personal Gateway.
Wenn Sie mehr über die Clusteranalyse erfahren möchten, können Sie sich mit unserem Handbuch in diesem Notizbuch vertraut machen .
Steig auf den Kurs.