Hinweis perev. : Obwohl diese Überprüfung nicht den Status eines sorgfältig entwickelten technischen Vergleichs bestehender Lösungen für die dauerhafte Speicherung von Daten in Kubernetes beansprucht, kann sie ein guter Ausgangspunkt für Administratoren sein, die für dieses Problem relevant sind. Die größte Aufmerksamkeit wurde der Piräus-Lösung gewidmet, deren Vertrautheit nicht nur Linstor-Liebhabern zugute kommt, sondern auch denen, die noch nichts von diesen Projekten gehört haben. Dies ist eine unwissenschaftliche Übersicht über Speicherlösungen für Kubernetes. Problemstellung: Erfordert die Fähigkeit, ein dauerhaftes Volume auf den Festplatten des Knotens zu erstellen, dessen Daten im Falle einer Beschädigung oder eines Neustarts des Knotens gespeichert werden.Die Motivation für diesen Vergleich ist die Notwendigkeit, die Serverflotte des Unternehmens von mehreren dedizierten Bare-Metal-Servern auf den Kubernetes-Cluster zu migrieren.Mein Unternehmen ist ein brasilianisches Startup-Unternehmen namens Escavador mit einem enormen Computerbedarf (hauptsächlich CPU) und einem sehr begrenzten Budget. Wir entwickeln NLP-Lösungen zur Strukturierung von Rechtsdaten.
Dies ist eine unwissenschaftliche Übersicht über Speicherlösungen für Kubernetes. Problemstellung: Erfordert die Fähigkeit, ein dauerhaftes Volume auf den Festplatten des Knotens zu erstellen, dessen Daten im Falle einer Beschädigung oder eines Neustarts des Knotens gespeichert werden.Die Motivation für diesen Vergleich ist die Notwendigkeit, die Serverflotte des Unternehmens von mehreren dedizierten Bare-Metal-Servern auf den Kubernetes-Cluster zu migrieren.Mein Unternehmen ist ein brasilianisches Startup-Unternehmen namens Escavador mit einem enormen Computerbedarf (hauptsächlich CPU) und einem sehr begrenzten Budget. Wir entwickeln NLP-Lösungen zur Strukturierung von Rechtsdaten.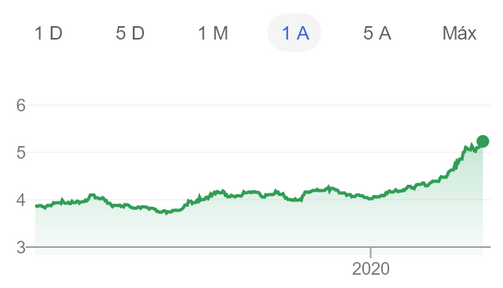 Aufgrund der Krise mit COVID-19 fiel der brasilianische Real gegenüber dem US-Dollar auf ein RekordtiefUnsere Landeswährung wird tatsächlich sehr unterschätzt, sodass das durchschnittliche Gehalt eines Senior-Entwicklers nur 2000 USD pro Monat beträgt. Daher können wir uns den Luxus nicht leisten, erhebliche Beträge für Cloud-Dienste auszugeben. Als ich die Berechnungen das letzte Mal durchgeführt habe, haben wir [dank der Verwendung meiner Server] 75% gespart, verglichen mit dem, was ich für AWS bezahlen müsste. Mit anderen Worten, ein anderer Entwickler kann für das eingesparte Geld eingestellt werden - ich denke, dass dies eine viel rationellere Verwendung der Mittel ist.Inspiriert von einer Reihe von Veröffentlichungen von Vito Botta, habe ich beschlossen, mit Rancher einen K8s-Cluster zu erstellen (und bisher so gut ...). Vito führte auch eine hervorragende Analyse verschiedener Speicherlösungen durch. Der klare Gewinner war Linstor (er hat es sogar herausgegriffenSonderliga ). Spoiler: Ich stimme ihm zu.Seit einiger Zeit verfolge ich den Verkehr um Kubernetes, habe mich aber erst kürzlich entschlossen, daran teilzunehmen. Dies ist vor allem darauf zurückzuführen, dass der Anbieter über eine neue Reihe von Ryzen-Prozessoren verfügt. Und dann war ich sehr überrascht zu sehen, dass sich viele Lösungen noch in der Entwicklung oder im unreifen Zustand befinden (insbesondere für Bare-Metal-Cluster: VM-Virtualisierung, MetalLB usw.). Tresore auf Bare Metal befinden sich noch in einem ausgereiften Stadium, obwohl sie durch eine Vielzahl von kommerziellen und Open Source-Lösungen repräsentiert werden. Ich beschloss, die wichtigsten vielversprechenden und kostenlosen Lösungen zu vergleichen (gleichzeitig ein kommerzielles Produkt zu testen, um zu verstehen, was ich verliere). Angebot an
Aufgrund der Krise mit COVID-19 fiel der brasilianische Real gegenüber dem US-Dollar auf ein RekordtiefUnsere Landeswährung wird tatsächlich sehr unterschätzt, sodass das durchschnittliche Gehalt eines Senior-Entwicklers nur 2000 USD pro Monat beträgt. Daher können wir uns den Luxus nicht leisten, erhebliche Beträge für Cloud-Dienste auszugeben. Als ich die Berechnungen das letzte Mal durchgeführt habe, haben wir [dank der Verwendung meiner Server] 75% gespart, verglichen mit dem, was ich für AWS bezahlen müsste. Mit anderen Worten, ein anderer Entwickler kann für das eingesparte Geld eingestellt werden - ich denke, dass dies eine viel rationellere Verwendung der Mittel ist.Inspiriert von einer Reihe von Veröffentlichungen von Vito Botta, habe ich beschlossen, mit Rancher einen K8s-Cluster zu erstellen (und bisher so gut ...). Vito führte auch eine hervorragende Analyse verschiedener Speicherlösungen durch. Der klare Gewinner war Linstor (er hat es sogar herausgegriffenSonderliga ). Spoiler: Ich stimme ihm zu.Seit einiger Zeit verfolge ich den Verkehr um Kubernetes, habe mich aber erst kürzlich entschlossen, daran teilzunehmen. Dies ist vor allem darauf zurückzuführen, dass der Anbieter über eine neue Reihe von Ryzen-Prozessoren verfügt. Und dann war ich sehr überrascht zu sehen, dass sich viele Lösungen noch in der Entwicklung oder im unreifen Zustand befinden (insbesondere für Bare-Metal-Cluster: VM-Virtualisierung, MetalLB usw.). Tresore auf Bare Metal befinden sich noch in einem ausgereiften Stadium, obwohl sie durch eine Vielzahl von kommerziellen und Open Source-Lösungen repräsentiert werden. Ich beschloss, die wichtigsten vielversprechenden und kostenlosen Lösungen zu vergleichen (gleichzeitig ein kommerzielles Produkt zu testen, um zu verstehen, was ich verliere). Angebot an Speicherlösungen bei CNCF LandscapeAber zuerst möchte ich Sie warnen, dass ich neu bei K8s bin.Für Experimente wurden 4 Arbeiter mit der folgenden Konfiguration verwendet: Ryzen 3700X-Prozessor, 64 GB ECC-Speicher, NVMe 2 TB groß. Benchmarks wurden unter Verwendung des Bildes
Speicherlösungen bei CNCF LandscapeAber zuerst möchte ich Sie warnen, dass ich neu bei K8s bin.Für Experimente wurden 4 Arbeiter mit der folgenden Konfiguration verwendet: Ryzen 3700X-Prozessor, 64 GB ECC-Speicher, NVMe 2 TB groß. Benchmarks wurden unter Verwendung des Bildes sotoaster/dbench:latest(auf fio) mit der Flagge erstellt O_DIRECT.Longhorn
Longhorn hat mir sehr gut gefallen. Es ist vollständig in Rancher integriert und kann mit einem Klick über Helm installiert werden. Longhorn von Rancher installierenDies ist ein Open Source-Tool mit dem Status eines Sandbox-Projekts der Cloud Native Computing Foundation (CNCF). Die Entwicklung wird von Rancher finanziert - einem ziemlich erfolgreichen Unternehmen mit einem bekannten [gleichnamigen] Produkt.
Longhorn von Rancher installierenDies ist ein Open Source-Tool mit dem Status eines Sandbox-Projekts der Cloud Native Computing Foundation (CNCF). Die Entwicklung wird von Rancher finanziert - einem ziemlich erfolgreichen Unternehmen mit einem bekannten [gleichnamigen] Produkt. Eine hervorragende grafische Oberfläche ist ebenfalls verfügbar - alles kann daraus gemacht werden. Mit der Leistung ist alles in Ordnung. Das Projekt befindet sich noch in der Beta-Phase, was durch Probleme auf GitHub bestätigt wird.Beim Testen habe ich einen Benchmark mit 2 Replikaten und Longhorn 0.8.0 gestartet:
Eine hervorragende grafische Oberfläche ist ebenfalls verfügbar - alles kann daraus gemacht werden. Mit der Leistung ist alles in Ordnung. Das Projekt befindet sich noch in der Beta-Phase, was durch Probleme auf GitHub bestätigt wird.Beim Testen habe ich einen Benchmark mit 2 Replikaten und Longhorn 0.8.0 gestartet:- Zufälliges Lesen / Schreiben, IOPS: 28,2 k / 16,2 k;
- Lese- / Schreibbandbreite: 205 Mb / s / 108 Mb / s;
- Durchschnittliche Lese- / Schreiblatenz (usec): 593,27 / 644,27;
- Sequentielles Lesen / Schreiben: 201 Mb / s / 108 Mb / s;
- Gemischtes zufälliges Lesen / Schreiben, IOPS: 14.7k / 4904.
Openebs
Dieses Projekt hat auch den CNCF-Sandbox-Status. Mit einer großen Anzahl von Sternen auf GitHub sieht es nach einer vielversprechenden Lösung aus. In seiner Rezension beklagte sich Vito Botta über unzureichende Leistung. Der Mayadata-CEO antwortete ihm wie folgt:Informationen sind sehr veraltet. OpenEBS unterstützte früher 3, jetzt jedoch 4 Engines, wenn Sie die dynamische Bereitstellung und die lokale PV-Orchestrierung aktivieren, die mit NVMe-Geschwindigkeit ausgeführt werden können. Darüber hinaus ist die MayaStor-Engine jetzt geöffnet und erhält bereits positive Bewertungen (obwohl sie den Alpha-Status hat).
Auf der OpenEBS-Projektseite gibt es eine solche Erklärung zum Status:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
Es hat viele Motoren, und der letzte scheint in Bezug auf die Leistung recht vielversprechend zu sein: „MayaStor - Alpha-Motor mit NVMe über Stoffen“. Leider habe ich es wegen des Alpha-Versionsstatus nicht getestet.In Tests wurde Version 1.8.0 für die Jiva-Engine verwendet. Außerdem habe ich zuvor cStor überprüft, aber die Ergebnisse nicht gespeichert, was sich jedoch als etwas langsamer als jiva herausstellte. Für den Benchmark wurde ein Helmdiagramm mit allen Standardeinstellungen installiert und die von Helm ( openebs-jiva-default) standardmäßig erstellte Speicherklasse verwendet. Die Leistung erwies sich als die schlechteste aller in Betracht gezogenen Lösungen (ich wäre dankbar für Ratschläge zur Verbesserung).OpenEBS 1.8.0 mit Jiva Engine (3 Replikate?):- Zufälliges Lesen / Schreiben, IOPS: 2182/1527;
- Lese- / Schreibbandbreite: 65,0 Mbit / s / 41,9 Mbit / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
Dies ist eine kommerzielle Lösung, die kostenlos ist, wenn bis zu 110 GB Speicherplatz verwendet werden. Eine kostenlose Entwicklerlizenz erhalten Sie, indem Sie sich über die Produktbenutzeroberfläche registrieren. Es bietet bis zu 500 GB Speicherplatz. In Rancher wird es als Partner aufgeführt, sodass die Installation mit Helm einfach und problemlos war.Dem Benutzer wird ein grundlegendes Bedienfeld angeboten. Das Testen dieses Produkts war begrenzt, da es kommerziell ist und nicht zu unserem Wert passt. Trotzdem wollte ich sehen, wozu kommerzielle Projekte in der Lage sind.Der Test verwendet die vorhandene Speicherklasse "Schnell" (Vorlage 0.2.19, 1 Master + 0 Replikat?). Die Ergebnisse waren erstaunlich. Sie übertrafen frühere Lösungen deutlich.- Zufälliges Lesen / Schreiben, IOPS: 117k / 90,4k;
- Lese- / Schreibbandbreite: 2124 Mbit / s / 457 Mbit / s;
- Durchschnittliche Lese- / Schreiblatenz (usec): 63,44 / 86,52;
- Sequentielles Lesen / Schreiben: 1907 Mb / s / 448 Mb / s;
- Gemischtes zufälliges Lesen / Schreiben, IOPS: 81,9k / 27,3k.
Piräus (basierend auf Linstor)
Lizenz: GPLv3Der bereits erwähnte Vito Botta entschied sich schließlich für Linstor, was ein weiterer Grund war, diese Lösung auszuprobieren. Auf den ersten Blick sieht das Projekt ziemlich seltsam aus. Es gibt fast keine Sterne auf GitHub, ein ungewöhnlicher Name, und er existiert nicht einmal auf CNCF Landscape. Aber bei näherer Betrachtung ist nicht alles so beängstigend, weil:- DRBD wird als grundlegender Replikationsmechanismus verwendet (tatsächlich wurde es von denselben Personen entwickelt). Gleichzeitig ist DRBD 8.x seit mehr als 10 Jahren Teil des offiziellen Linux-Kernels. Und wir sprechen über Technologie, die seit über 20 Jahren weiterentwickelt wird.
- Die Medien werden von LINSTOR gesteuert, ebenfalls eine ausgereifte Technologie desselben Unternehmens. Die erste Version von Linstor-Server erschien im Februar 2018 auf GitHub. Es ist kompatibel mit verschiedenen Technologien / Systemen wie Proxmox, OpenNebula und OpenStack.
- Anscheinend entwickelt Linbit das Projekt aktiv weiter und führt ständig neue Funktionen und Verbesserungen ein. Die 10. Version von DRBD hat noch den Alpha-Status , verfügt jedoch bereits über einige einzigartige Funktionen, wie z. B. Löschcodierung (analog zur Funktionalität von RAID5 / 6 - ca. Transl.) .
- Das Unternehmen ergreift bestimmte Maßnahmen , um eines der CNCF-Projekte zu werden.
Okay, das Projekt sieht überzeugend genug aus, um ihm seine wertvollen Daten anzuvertrauen. Aber kann er Alternativen wiederholen? Lassen Sie uns einen Blick darauf werfen.Installation
Vito spricht über die Installation von Linstor hier . In den Kommentaren empfiehlt jedoch einer der Linstor-Entwickler ein neues Projekt namens Piräus. So wie ich es verstehe, wird Piräus zum Linbit Open Source-Projekt, das alles kombiniert, was mit K8 zu tun hat. Das Team arbeitet an dem entsprechenden Operator , aber Piraeus kann derzeit mithilfe dieser YAML-Datei installiert werden:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
Beachtung! Sie holen Konfigurationen aus meinem persönlichen Repository ab. Schauen Sie sich das offizielle Repository an! Ich habe die Version der Bilder aktualisiert, um den Fehler zu beheben, der bei der Verwendung in Ubuntu auftritt.Das offizielle Piräus-Repository finden Sie hier .Sie können auch das kvaps-Repository verwenden (es scheint noch dynamischer zu sein als das offizielle Piraeus-Repository): https://github.com/kvaps/kube-linstor (nutzen Sie diese Gelegenheit, um Andrey zu begrüßenkvaps- ca. perev.) . Alle Knoten funktionieren nach der Installation
Alle Knoten funktionieren nach der InstallationVerwaltung
Die Administration erfolgt über die Kommandozeile. Der Zugriff darauf ist über die Befehlsshell des Piraeus-Controller-Knotens möglich. Auf dem Controller-Knoten wird Linstor-Server ausgeführt. Es ist eine Abstraktionsschicht über drbd, die die gesamte Knotenflotte verwalten kann. Der folgende Screenshot zeigt einige nützliche Befehle für die beliebtesten Aufgaben, zum Beispiel:
Auf dem Controller-Knoten wird Linstor-Server ausgeführt. Es ist eine Abstraktionsschicht über drbd, die die gesamte Knotenflotte verwalten kann. Der folgende Screenshot zeigt einige nützliche Befehle für die beliebtesten Aufgaben, zum Beispiel:linstor node list - eine Liste der verbundenen Knoten und deren Status anzeigen;linstor volume list - eine Liste der erstellten Volumes und deren Speicherort anzeigen;linstor node info - Zeigen Sie die Fähigkeiten jedes Knotens an.
 Linstor-Befehle Einevollständige Liste der Befehle finden Sie in der offiziellen Dokumentation: Benutzerhandbuch LINSTOR .In Situationen wie Split Brain kann auf drbd direkt über die Knoten zugegriffen werden.
Linstor-Befehle Einevollständige Liste der Befehle finden Sie in der offiziellen Dokumentation: Benutzerhandbuch LINSTOR .In Situationen wie Split Brain kann auf drbd direkt über die Knoten zugegriffen werden.Notfallwiederherstellung
Ich habe mein Bestes getan, um meinen Cluster zu löschen, einschließlich Hard Reset auf Knoten. Aber Linstor war überraschend hartnäckig.Drbd erkennt ein Problem namens Split Brain perfekt. In meiner Situation ist der sekundäre Knoten nicht mehr repliziert worden.Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
Details finden Sie in der offiziellen Dokumentation von drbd . Der sekundäre Knoten ist nicht mehr repliziert.In meinem Fall habe ich zur Lösung des Problems die sekundären Daten gelöscht und mit der Synchronisierung mit dem primären Knoten begonnen. Da ich grafische Oberflächen bevorzuge, habe ich dafür das Dienstprogramm drbdtop verwendet. Mit seiner Hilfe können Sie den Status visuell überwachen und Befehle innerhalb von Knoten ausführen.Ich musste in die Konsole auf dem Problemknoten piraues gehen (es war
Der sekundäre Knoten ist nicht mehr repliziert.In meinem Fall habe ich zur Lösung des Problems die sekundären Daten gelöscht und mit der Synchronisierung mit dem primären Knoten begonnen. Da ich grafische Oberflächen bevorzuge, habe ich dafür das Dienstprogramm drbdtop verwendet. Mit seiner Hilfe können Sie den Status visuell überwachen und Befehle innerhalb von Knoten ausführen.Ich musste in die Konsole auf dem Problemknoten piraues gehen (es war worker2-gpu): Gehe zum KnotenDort habe ich drdbtop installiert. Laden Sie dieses Dienstprogramm hier herunter:
Gehe zum KnotenDort habe ich drdbtop installiert. Laden Sie dieses Dienstprogramm hier herunter:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 Ausführen des Dienstprogramms drbdtop SchauenSie sich das untere Bedienfeld an. Es gibt Befehle, mit denen das geteilte Gehirn repariert werden kann:
Ausführen des Dienstprogramms drbdtop SchauenSie sich das untere Bedienfeld an. Es gibt Befehle, mit denen das geteilte Gehirn repariert werden kann: Danach werden die Knoten automatisch verbunden und synchronisiert.
Danach werden die Knoten automatisch verbunden und synchronisiert.Wie kann man die Geschwindigkeit erhöhen?
Standardmäßig zeigen Piräus / Linstor / drbd eine hervorragende Leistung (siehe unten). Die Standardeinstellungen sind angemessen und sicher. Die Schreibgeschwindigkeit war jedoch eher schwach. Da die Server in meinem Fall über verschiedene Rechenzentren verteilt sind (obwohl sie physisch relativ nahe beieinander liegen), habe ich beschlossen, ihre Leistung zu optimieren.Ausgangspunkt für die Optimierung ist die Definition eines Replikationsprotokolls. Standardmäßig wird Protokoll C verwendet, das auf die Schreibbestätigung auf dem Remote-Sekundärknoten wartet. Das Folgende ist eine Beschreibung der möglichen Protokolle:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
Aus diesem Grund verwende ich in Linstor auch das asynchrone Protokoll (es unterstützt die synchrone / halbsynchrone / asynchrone Replikation). Sie können es mit dem folgenden Befehl aktivieren:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
Das Ergebnis seiner Implementierung ist die Aktivierung des asynchronen Protokolls und eine Erhöhung des Puffers auf 1 MB. Es ist relativ sicher. Oder Sie können den folgenden Befehl verwenden (er ignoriert das Löschen von Datenträgern und erhöht den Puffer erheblich):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
Beachten Sie, dass bei einem Ausfall des Primärknotens ein kleiner Teil der Daten möglicherweise nicht die Replikate erreicht.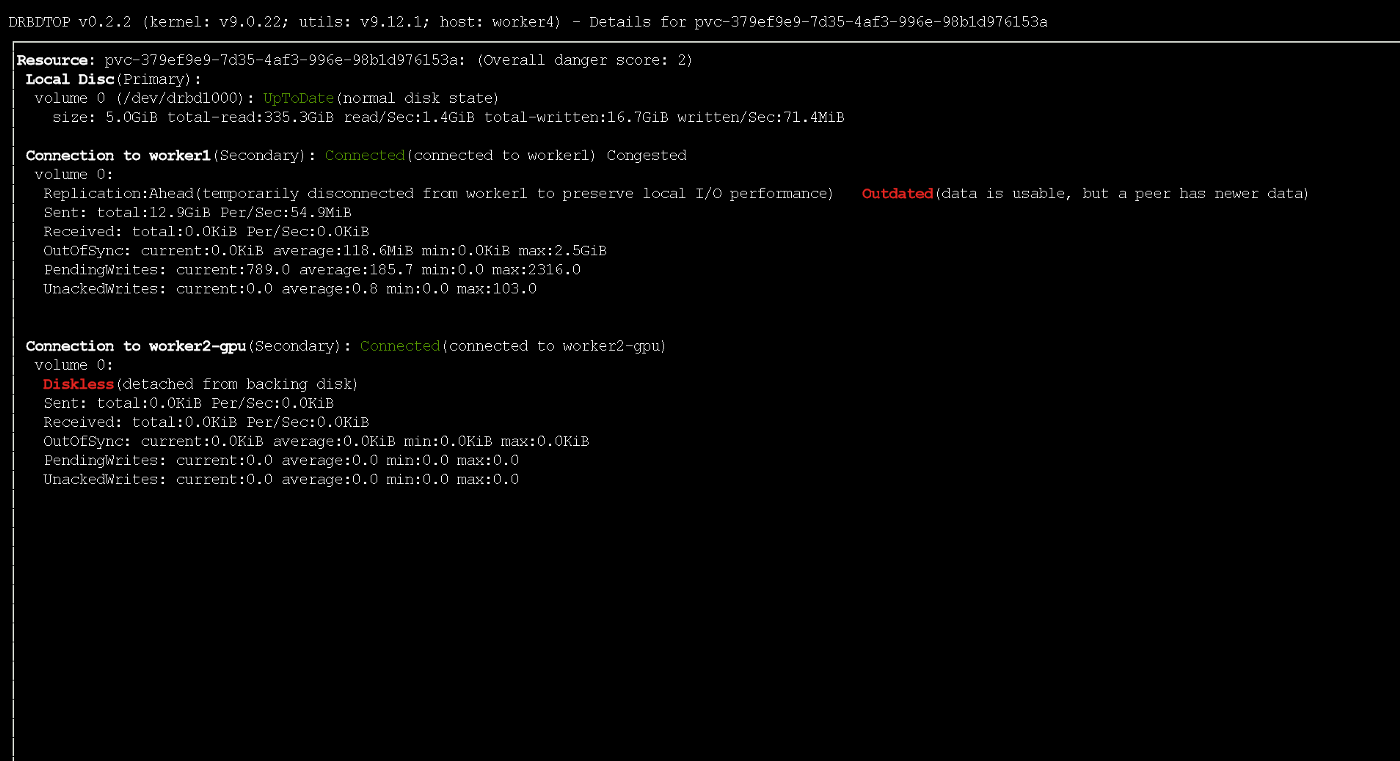 Während der aktiven Aufzeichnung erhielt der Knoten vorübergehend den veralteten Status mithilfe des ASYNC-Protokolls
Während der aktiven Aufzeichnung erhielt der Knoten vorübergehend den veralteten Status mithilfe des ASYNC-ProtokollsTesten
Alle Benchmarks wurden mit dem folgenden Job durchgeführt:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
Die Verzögerung zwischen den Maschinen ist wie folgt : ttl=61 time=0.211 ms. Der gemessene Durchsatz zwischen ihnen betrug 943 Mbit / s. Auf allen Knoten wird Ubuntu 18.04 ausgeführt. Ergebnisse ( Tabelle auf sheetu.com )
Wie aus der Tabelle hervorgeht, zeigten Piraeus und StorageOS die besten Ergebnisse. Der Anführer war Piräus mit zwei Repliken und einem asynchronen Protokoll.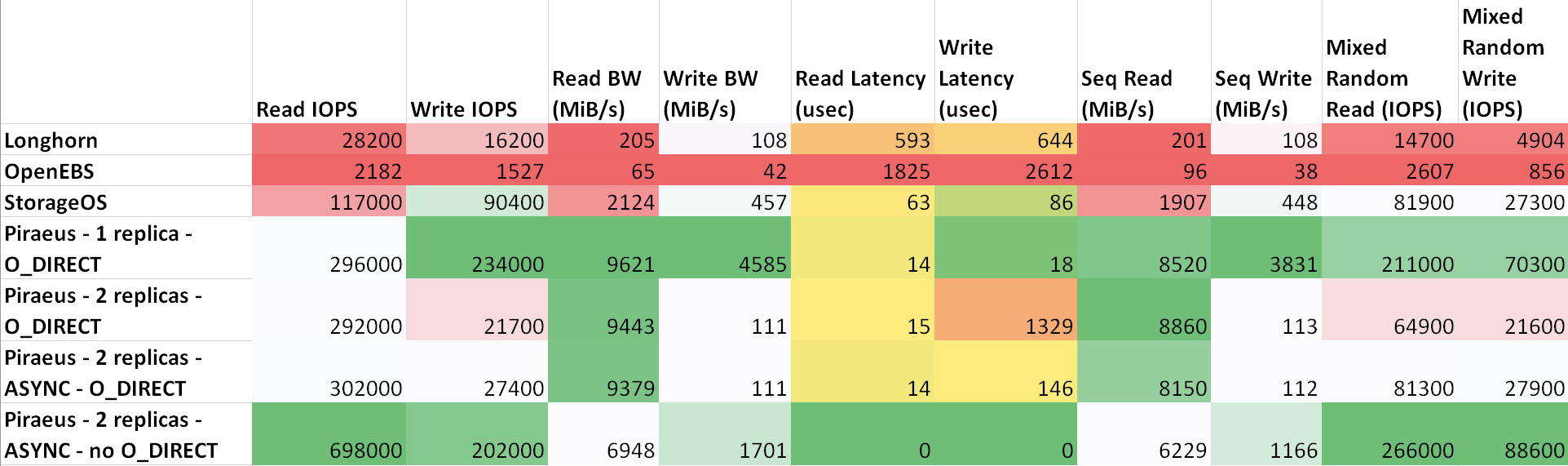
Ergebnisse
Ich habe einige Speicherlösungen in Kubernetes einfach und vielleicht nicht richtig verglichen.Am meisten hat mir Longhorn wegen seiner schönen Benutzeroberfläche und der Integration mit Rancher gefallen. Die Ergebnisse sind jedoch nicht inspirierend. Offensichtlich konzentrieren sich Entwickler in erster Linie auf Sicherheit und Korrektheit und lassen Geschwindigkeit für später.Seit einiger Zeit verwende ich Linstor / Piräus in den Produktionsumgebungen einiger Projekte. Bisher war alles in Ordnung: Festplatten wurden erstellt und gelöscht, Knoten wurden ohne Ausfallzeiten neu gestartet ...Meiner Meinung nach ist Piräus ziemlich einsatzbereit, muss aber verbessert werden. Er schrieb über einige Fehler im Projektkanal in Slack, aber als Antwort rieten sie mir nur, Kubernetes zu unterrichten (und das ist richtig, da ich es immer noch nicht verstehe). Nach ein wenig Korrespondenz gelang es mir immer noch, die Autoren davon zu überzeugen, dass es einen Fehler in ihrem Init-Skript gab. Gestern, nach dem Aktualisieren des Kernels und dem Neustart, weigerte sich der Knoten zu booten. Es stellte sich heraus, dass das Kompilieren des Skripts, das das drbd-Modul in den Kernel integriert, fehlgeschlagen ist . Ein Rollback auf die vorherige Kernelversion löste das Problem.Das ist im Allgemeinen alles. Angesichts der Tatsache, dass sie es zusätzlich zu drbd implementiert haben, stellte sich heraus, dass es sich um eine sehr zuverlässige Lösung mit hervorragender Leistung handelt. Bei Problemen können Sie sich direkt an das drbd-Management wenden und das Problem beheben. Im Internet gibt es viele Fragen und Beispiele zu diesem Thema.Wenn ich etwas falsch gemacht habe, wenn etwas verbessert werden kann oder Sie Hilfe benötigen, kontaktieren Sie mich auf Twitter oder GitHub .PS vom Übersetzer
Lesen Sie auch in unserem Blog: