In einem früheren Artikel, in dem ich über die Überwachung einer PostgreSQL-Datenbank sprach , gab es einen solchen Satz:Wachsen wait- Die Anwendung hat sich auf den Sperren einer Person "ausgeruht" . Wenn dies eine vergangene einmalige Anomalie ist - eine Gelegenheit, den ursprünglichen Grund zu verstehen.
Diese Situation ist eine der unangenehmsten für den DBA:- Auf den ersten Blick funktioniert die Basis
- Es sind keine Serverressourcen erschöpft
- ... aber einige der Anfragen "verlangsamen"
 Die Chancen , die Sperren "im Moment" zu erwischen, sind äußerst gering und können nur wenige Sekunden dauern, verschlechtern jedoch die geplante Ausführungszeit der Anforderung um das Zehnfache. Sie möchten jedoch nicht sitzen und verfolgen, was online passiert, sondern in einer ruhigen Umgebung herausfinden,
Die Chancen , die Sperren "im Moment" zu erwischen, sind äußerst gering und können nur wenige Sekunden dauern, verschlechtern jedoch die geplante Ausführungszeit der Anforderung um das Zehnfache. Sie möchten jedoch nicht sitzen und verfolgen, was online passiert, sondern in einer ruhigen Umgebung herausfinden, welcher der Entwickler genau das Problem bestraft hat - wer, mit wem und aufgrund welcher Ressource der Datenbank in Konflikt geraten ist.Aber wie? Im Gegensatz zu der Anfrage mit ihrem Plan, mit der Sie im Detail verstehen können, wie die Ressourcen waren und wie lange es gedauert hat, hinterlässt das Schloss keine so offensichtlichen Spuren ...Es sei denn, es handelt sich um einen kurzen Protokolleintrag: Aber versuchen wir, ihn zu fangen!process ... still waiting for ...
Wir fangen das Schloss im Protokoll
Aber damit mindestens diese Zeile im Protokoll angezeigt wird, muss der Server korrekt konfiguriert sein:log_lock_waits = 'on'
... und legen Sie eine Mindestgrenze für unsere Analyse fest:deadlock_timeout = '100ms'
Wenn der Parameter aktiviert ist log_lock_waits, bestimmt dieser Parameter auch, nach welcher Zeit Nachrichten über das Warten auf das Blockieren in das Serverprotokoll geschrieben werden. Wenn Sie versuchen, die durch Sperren verursachten Verzögerungen zu untersuchen, ist es sinnvoll, sie im Vergleich zum üblichen Wert zu reduzieren deadlock_timeout.
Alle Deadlocks, die während dieser Zeit keine Zeit zum "Lösen" haben, werden zerrissen. Und hier sind die „üblichen“ Sperren, die von mehreren Einträgen in das Protokoll eingegeben werden:2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest DETAIL: Process holding the lock: 38154. Wait queue: 38162.
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest CONTEXT: SQL statement "SELECT pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer )"
PL/pgSQL function inline_code_block line 2 at PERFORM
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest STATEMENT: DO $$ BEGIN
PERFORM pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer );
EXCEPTION
WHEN query_canceled THEN RETURN;
END; $$;
…
2019-03-27 00:06:46.077 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms
Dieses Beispiel zeigt, dass wir vom Erscheinen der Sperre im Protokoll bis zum Zeitpunkt ihrer Auflösung nur 50 ms Zeit hatten. Nur in diesem Intervall können wir zumindest einige Informationen darüber erhalten, und je schneller wir dies tun können, desto mehr Sperren können wir analysieren.Hier ist die wichtigste Information für uns die PID des Prozesses , der auf die Sperre wartet. Darauf können wir Informationen zwischen dem Protokoll und dem Status der Datenbank vergleichen. Und gleichzeitig herauszufinden, wie problematisch ein bestimmtes Schloss war - das heißt, wie lange es "hing".Dazu benötigen wir nur ein paar RegExp im Inhaltsdatensatz LOG:const RE_lock_detect = /^process (\d+) still waiting for (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
const RE_lock_acquire = /^process (\d+) acquired (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
Wir kommen zum Protokoll
Eigentlich bleibt es ein wenig - das Protokoll zu nehmen, zu lernen, wie man es überwacht und entsprechend reagiert.Wir haben bereits alles dafür - einen Online-Protokollparser und eine voraktivierte Datenbankverbindung, über die ich in einem Artikel über unser PostgreSQL-Überwachungssystem gesprochen habe :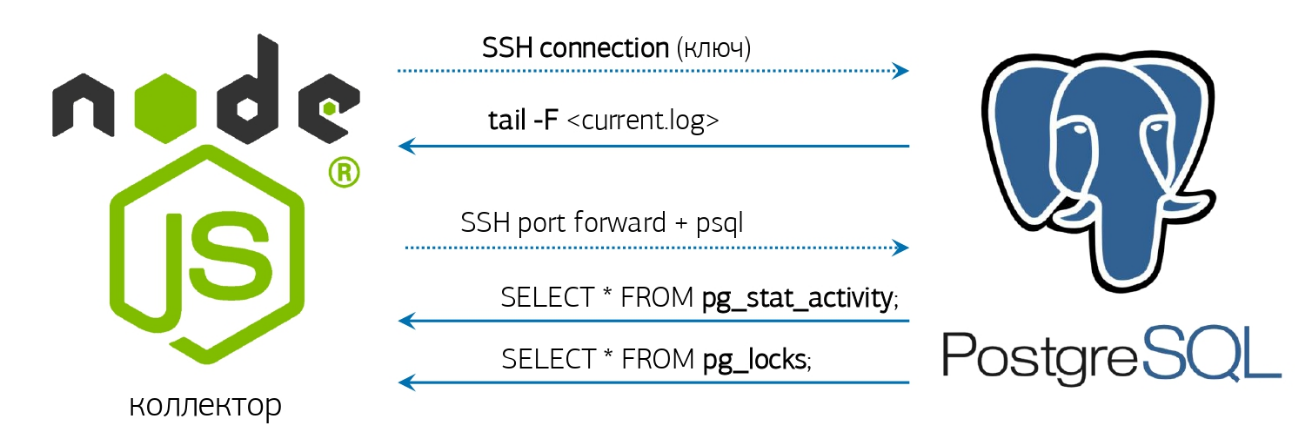 Wenn Sie jedoch kein ähnliches System bereitgestellt haben, ist es in Ordnung, wir werden alles tun "Direkt von der Konsole"!Wenn die installierte Version von PostgreSQL 10 und höher Glück hat, weil dort die Funktion pg_current_logfile () angezeigt wurde , die explizit den Namen der aktuellen Protokolldatei angibt . Es wird einfach genug sein, es von der Konsole zu bekommen:
Wenn Sie jedoch kein ähnliches System bereitgestellt haben, ist es in Ordnung, wir werden alles tun "Direkt von der Konsole"!Wenn die installierte Version von PostgreSQL 10 und höher Glück hat, weil dort die Funktion pg_current_logfile () angezeigt wurde , die explizit den Namen der aktuellen Protokolldatei angibt . Es wird einfach genug sein, es von der Konsole zu bekommen:psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) <> '/' THEN current_setting('data_directory') ELSE '' END || '/' || pg_current_logfile()"
Wenn die Version plötzlich jünger ist, wird sich alles herausstellen, aber etwas komplizierter:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}'
Wir tail -ferhalten den vollständigen Dateinamen, den wir eingeben und der dort angezeigt wird 'still waiting for'.Nun, sobald etwas in diesem Thread aufgetaucht ist, rufen wir ...Analyseanforderung
Leider ist das Objekt des Blockierens im Protokoll keineswegs immer die Ressource, die den Konflikt verursacht hat. Wenn Sie beispielsweise versuchen, parallel einen gleichnamigen Index zu erstellen, enthält das Protokoll nur so etwas still waiting for ExclusiveLock on transaction 12345.Daher müssen wir den Status aller Sperren für den für uns interessanten Prozess aus der Datenbank entfernen . Und Informationen nur über zwei Prozesse (wer die Sperre aktiviert hat / wer sie erwartet) reichen nicht aus, da häufig eine „Kette“ von Erwartungen an unterschiedliche Ressourcen zwischen Transaktionen besteht:tx1 [resA] -> tx2 [resA]
tx2 [resB] -> tx3 [resB]
...
Klassiker: „Großvater für Rübe, Großmutter für Großvater, Enkelin für Großmutter, ...“Daher werden wir eine Anfrage schreiben, die uns genau sagt, wer die Hauptursache für Probleme entlang der gesamten Schleusenkette für eine bestimmte PID wurde:WITH RECURSIVE lm AS (
SELECT
rn
, CASE
WHEN lm <> 'Share' THEN row_number() OVER(PARTITION BY lm <> 'Share' ORDER BY rn)
END rx
, lm || 'Lock' lm
FROM (
SELECT
row_number() OVER() rn
, lm
FROM
unnest(
ARRAY[
'AccessShare'
, 'RowShare'
, 'RowExclusive'
, 'ShareUpdateExclusive'
, 'Share'
, 'ShareRowExclusive'
, 'Exclusive'
, 'AccessExclusive'
]
) T(lm)
) T
)
, lt AS (
SELECT
row_number() OVER() rn
, lt
FROM
unnest(
ARRAY[
'relation'
, 'extend'
, 'page'
, 'tuple'
, 'transactionid'
, 'virtualxid'
, 'object'
, 'userlock'
, 'advisory'
, ''
]
) T(lt)
)
, lmx AS (
SELECT
lr.rn lrn
, lr.rx lrx
, lr.lm lr
, ld.rn ldn
, ld.rx ldx
, ld.lm ld
FROM
lm lr
JOIN
lm ld ON
ld.rx > (SELECT max(rx) FROM lm) - lr.rx OR
(
(lr.rx = ld.rx) IS NULL AND
(lr.rx, ld.rx) IS DISTINCT FROM (NULL, NULL) AND
ld.rn >= (SELECT max(rn) FROM lm) - lr.rn
)
)
, lcx AS (
SELECT DISTINCT
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
pg_locks ld
JOIN
pg_locks lr ON
lr.pid <> ld.pid AND
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) IS NOT DISTINCT FROM (ld.locktype, ld.database, ld.relation, ld.page, ld.tuple, ld.virtualxid, ld.transactionid::text::bigint, ld.classid, ld.objid, ld.objsubid) AND
(lr.granted, ld.granted) = (TRUE, FALSE)
JOIN
lmx ON
(lmx.lr, lmx.ld) = (lr.mode, ld.mode)
WHERE
(ld.pid, ld.granted) = ($1::integer, FALSE)
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN ARRAY[relation::text]
WHEN 'extend' THEN ARRAY[relation::text]
WHEN 'page' THEN ARRAY[relation, page]::text[]
WHEN 'tuple' THEN ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN ARRAY[transactionid::text]
WHEN 'virtualxid' THEN regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN ARRAY[classid::text]
WHEN 'advisory' THEN ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp "locked"
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, (lc.locktype, lc.database, lc.relation, lc.page, lc.tuple, lc.virtualxid, lc.transactionid::text::bigint, lc.classid, lc.objid, lc.objsubid) IS NOT DISTINCT FROM lcx.target "conflict"
FROM
lcx
JOIN
pg_locks lc ON
lc.pid IN (lcx.ldp, lcx.lrp);
Problem Nr. 1 - Langsamer Start
Wie Sie im Beispiel aus dem Protokoll sehen können, befinden sich neben der Zeile, die das Auftreten einer Sperre ( LOG) signalisiert , drei weitere Zeilen ( DETAIL, CONTEXT, STATEMENT), die erweiterte Informationen melden.Zuerst haben wir auf die Bildung eines vollständigen „Pakets“ aller 4 Einträge gewartet und uns danach der Datenbank zugewandt. Wir können die Bildung des Pakets jedoch erst abschließen, wenn der nächste (bereits fünfte!) Datensatz mit den Details eines anderen Prozesses oder nach Zeitüberschreitung eintrifft. Es ist klar, dass beide Optionen unnötiges Warten hervorrufen.Um diese Verzögerungen zu beseitigen, haben wir auf die Stream-Verarbeitung von Sperrdatensätzen umgestellt . Das heißt, wir wenden uns jetzt der Zieldatenbank zu, sobald wir den ersten Datensatz sortiert haben, und stellen fest, dass es sich um die dort beschriebene Sperre handelt.Problem Nr. 2 - langsame Anfrage
Einige der Schlösser hatten jedoch keine Zeit, analysiert zu werden. Sie begannen tiefer zu graben - und fanden heraus, dass auf einigen Servern unsere Analyseanforderung für 15-20 ms ausgeführt wird !Der Grund stellte sich als alltäglich heraus - die Gesamtzahl der aktiven Sperren auf der Basis erreichte mehrere Tausend: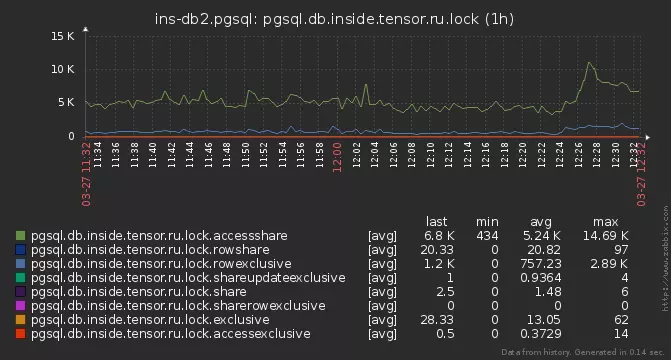
pg_locks
Hierbei ist zu beachten, dass Sperren in PostgreSQL nirgendwo „gespeichert“ werden, sondern nur in der Systemansicht pg_locks dargestellt werden , die die Funktion direkt widerspiegelt pg_lock_status. Und in unserer Anfrage lesen wir dreimal daraus ! In der Zwischenzeit lesen wir diese Tausenden von Sperrinstanzen und verwerfen diejenigen, die nicht mit unserer PID zusammenhängen. Die Sperre selbst konnte "aufgelöst" werden. DieLösung bestand darin , den Status von pg_locks im CTE zu "materialisieren". Danach können Sie ihn so oft durchlaufen, wie Sie möchten ändert sich nicht. Darüber hinaus war es nach dem Sitzen auf dem Algorithmus möglich, alles auf nur zwei seiner Scans zu reduzieren.Übermäßige Dynamik
Und wenn auch ein wenig genauerer Blick auf der Abfrage oben, können wir sehen , dass der CTE lmund lmxnicht in irgendeiner Weise auf die Daten gebunden, sondern einfach berechnet immer die gleiche „statische“ Matrix Definition des Konflikts zwischen dem Modi blockiert . Stellen wir es also einfach als Qualität ein VALUES.Problem Nr. 3 - Nachbarn
Aber ein Teil der Schlösser wurde immer noch übersprungen. Normalerweise geschah dies nach dem folgenden Schema: Jemand blockierte eine beliebte Ressource, und mehrere Prozesse liefen schnell und schnell darauf oder entlang einer Kette weiter .Infolgedessen haben wir die erste PID abgefangen, sind zur Zielbasis gegangen (und um sie nicht zu überlasten, behalten wir nur eine Verbindung bei), haben die Analyse durchgeführt, mit dem Ergebnis zurückgegeben, die nächste PID genommen ... Aber das Leben an der Basis ist es nicht wert, und die PID-Sperre # 2 ist schon weg!Warum müssen wir eigentlich für jede PID separat in die Datenbank gehen, wenn wir die Sperren immer noch aus der allgemeinen Liste in der Anforderung filtern? Nehmen wir sofort die gesamte Liste der in Konflikt stehenden Prozesse direkt aus der Datenbank und verteilen ihre Sperren auf alle PIDs, die während der Ausführung der Anforderung in das Protokoll aufgenommen wurden:WITH lm(ld, lr) AS (
VALUES
('AccessShareLock', '{AccessExclusiveLock}'::text[])
, ('RowShareLock', '{ExclusiveLock,AccessExclusiveLock}'::text[])
, ('RowExclusiveLock', '{ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareUpdateExclusiveLock', '{ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareRowExclusiveLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ExclusiveLock', '{RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('AccessExclusiveLock', '{AccessShareLock,RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
)
, locks AS (
SELECT
(
locktype
, database
, relation
, page
, tuple
, virtualxid
, transactionid::text::bigint
, classid
, objid
, objsubid
) target
, *
FROM
pg_locks
)
, ld AS (
SELECT
*
FROM
locks
WHERE
NOT granted
)
, lr AS (
SELECT
*
FROM
locks
WHERE
target::text = ANY(ARRAY(
SELECT DISTINCT
target::text
FROM
ld
)) AND
granted
)
, lcx AS (
SELECT DISTINCT
lr.target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
ld
JOIN
lr
ON lr.pid <> ld.pid AND
lr.target IS NOT DISTINCT FROM ld.target
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN
ARRAY[relation::text]
WHEN 'extend' THEN
ARRAY[relation::text]
WHEN 'page' THEN
ARRAY[relation, page]::text[]
WHEN 'tuple' THEN
ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN
ARRAY[transactionid::text]
WHEN 'virtualxid' THEN
regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN
ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN
ARRAY[classid::text]
WHEN 'advisory' THEN
ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp as locked
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, lc.target IS NOT DISTINCT FROM lcx.target as conflict
FROM
lcx
JOIN
locks lc
ON lc.pid IN (lcx.ldp, lcx.lrp);
Jetzt haben wir Zeit, auch die Sperren zu analysieren, die nur 1-2 ms nach dem Eintritt in das Protokoll existieren.Analysiere das
Warum haben wir es eigentlich so lange versucht? Was bringt uns das?type | target | locked | pid | mode | granted | conflict
---------------------------------------------------------------------------------------
relation | {225388639} | f | 216547 | AccessShare | t | f
relation | {423576026} | f | 216547 | AccessShare | t | f
advisory | {225386226,194303167,2} | t | 24964 | Exclusive | f | t
relation | {341894815} | t | 24964 | AccessShare | t | f
relation | {416441672} | f | 216547 | AccessShare | t | f
relation | {225964322} | f | 216547 | AccessShare | t | f
...
In dieser Tabelle sind Werte targetmit einem Typ für uns nützlich relation, da jeder dieser Werte eine OID einer Tabelle oder eines Index ist . Jetzt bleibt nur noch sehr wenig zu lernen, wie man die Datenbank nach uns noch unbekannten OIDs abfragt, um sie in eine für Menschen lesbare Form zu übersetzen:SELECT $1::oid::regclass;
Wenn wir nun die vollständige „Matrix“ der Sperren und alle Objekte kennen, denen sie von jeder Transaktion überlagert wurden, können wir schließen, „was überhaupt passiert ist“ und welche Ressource den Konflikt verursacht hat, selbst wenn die Anforderung blockiert wurde, waren wir unbekannt. Dies kann beispielsweise leicht passieren, wenn die Ausführungszeit einer Blockierungsanforderung nicht lang genug ist, um zum Protokoll zu gelangen, die Transaktion jedoch nach Abschluss aktiv war und lange Zeit Probleme verursachte.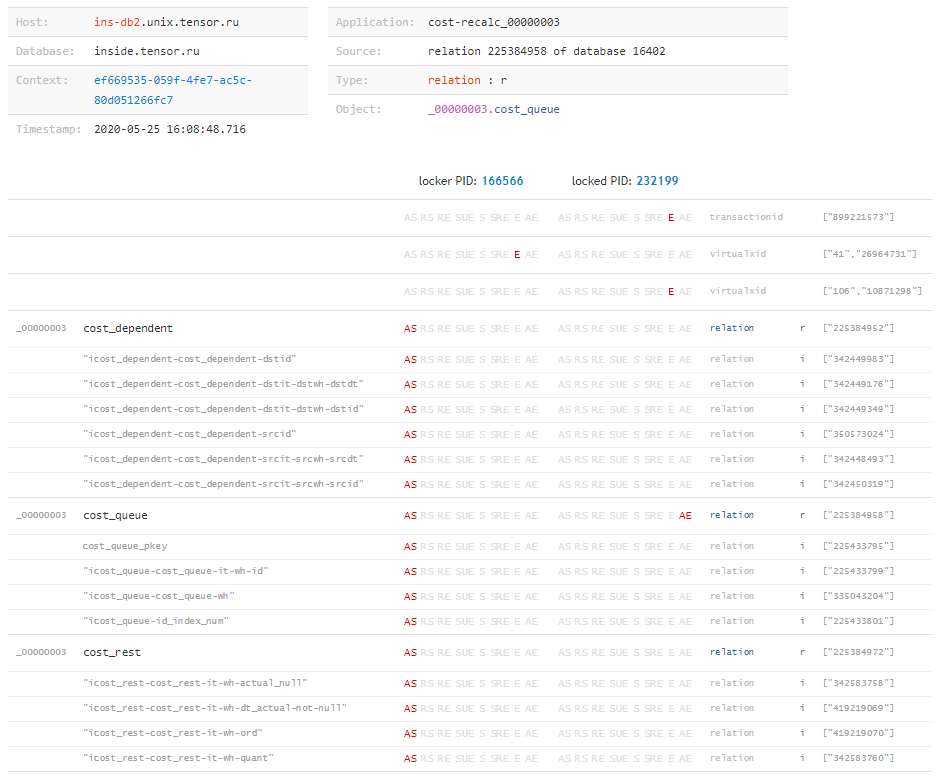 Aber darüber - in einem anderen Artikel.
Aber darüber - in einem anderen Artikel."Ganz von alleine"
In der Zwischenzeit werden wir die Vollversion von "Überwachung" sammeln, die automatisch den Status der Sperren für unser Archiv entfernt, sobald etwas Verdächtiges im Protokoll erscheint:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}' \
| xargs -l -I{} tail -f {} \
| stdbuf -o0 grep 'still waiting for' \
| xargs -l -I{} date '+%Y%m%d-%H%M%S.%N' \
| xargs -l -I{} psql -U postgres postgres -f detect-lock.sql -o {}-lock.log
Und als nächstes detect-lock.sqldie letzte Anfrage stellen. Ausführen - und eine Reihe von Dateien mit dem gewünschten Inhalt abrufen:# cat 20200526-181433.331839375-lock.log
type | target | locked | pid | mode | granted | conflict
---------------+----------------+--------+--------+--------------+---------+----------
relation | {279588430} | t | 136325 | RowExclusive | t | f
relation | {279588422} | t | 136325 | RowExclusive | t | f
relation | {17157} | t | 136325 | RowExclusive | t | f
virtualxid | {110,12171420} | t | 136325 | Exclusive | t | f
relation | {279588430} | f | 39339 | RowExclusive | t | f
relation | {279588422} | f | 39339 | RowExclusive | t | f
relation | {17157} | f | 39339 | RowExclusive | t | f
virtualxid | {360,11744113} | f | 39339 | Exclusive | t | f
virtualxid | {638,4806358} | t | 80553 | Exclusive | t | f
advisory | {1,1,2} | t | 80553 | Exclusive | f | t
advisory | {1,1,2} | f | 80258 | Exclusive | t | t
transactionid | {3852607686} | t | 136325 | Exclusive | t | f
extend | {279588422} | t | 136325 | Exclusive | f | t
extend | {279588422} | f | 39339 | Exclusive | t | t
transactionid | {3852607712} | f | 39339 | Exclusive | t | f
(15 rows)
Na dann - setzen Sie sich und analysieren Sie ...