In diesem Artikel werde ich ein Beispiel dafür erzählen und zeigen, wie eine Person mit minimaler Data Science-Erfahrung Daten aus dem Forum sammeln und Beiträge mithilfe des LDA-Modells thematisch modellieren konnte, und schmerzhafte Themen für Menschen mit Zöliakie-Intoleranz aufdecken.Letztes Jahr musste ich meine Kenntnisse im Bereich des maschinellen Lernens dringend verbessern. Ich bin Produktmanager für Data Science, Maschinelles Lernen und KI oder auf andere Weise Technischer Produktmanager KI / ML. Geschäftsfähigkeiten und die Fähigkeit, Produkte zu entwickeln, wie dies normalerweise bei Projekten der Fall ist, die sich an Benutzer richten, die nicht im technischen Bereich tätig sind, reichen nicht aus. Sie müssen die grundlegenden technischen Konzepte der ML-Branche verstehen und bei Bedarf selbst ein Beispiel schreiben können, um das Produkt zu demonstrieren.Seit ungefähr 5 Jahren entwickle ich Front-End-Projekte, entwickle komplexe Webanwendungen für JS und React, aber ich habe mich nie mit maschinellem Lernen, Laptops und Algorithmen befasst. Als ich die Nachricht von Otus sah, dass sie ohne zu zögern einen fünfmonatigen experimentellen Kurs über maschinelles Lernen eröffneten , entschied ich mich daher, mich einem Probetest zu unterziehen, und nahm an dem Kurs teil.Fünf Monate lang gab es jede Woche zweistündige Vorträge und Hausaufgaben für sie. Dort lernte ich die Grundlagen von ML kennen: verschiedene Regressionsalgorithmen, Klassifikationen, Modellensembles, Gradientenverstärkung und sogar leicht betroffene Cloud-Technologien. Wenn Sie sich jede Vorlesung genau anhören, gibt es im Prinzip genügend Beispiele und Erklärungen für Hausaufgaben. Trotzdem musste ich mich manchmal, wie bei jedem anderen Codierungsprojekt, der Dokumentation zuwenden. Angesichts meiner Vollzeitbeschäftigung war es sehr praktisch zu studieren, da ich die Aufzeichnung einer Online-Vorlesung jederzeit überarbeiten konnte.Am Ende der Schulung dieses Kurses mussten alle das Abschlussprojekt absolvieren. Die Idee für das Projekt entstand ganz spontan. Zu diesem Zeitpunkt begann ich bei Stanford mit der Ausbildung zum Unternehmer, wo ich in das Team kam, das an dem Projekt für Menschen mit Zöliakie-Intoleranz arbeitete. Während der Marktforschung war ich interessiert zu wissen, über welche Sorgen, worüber sie sprechen, worüber sich Leute mit dieser Funktion beschweren.Im Verlauf der Studie fand ich auf celiac.com ein Forummit einer großen Menge an Material über Zöliakie. Es war offensichtlich, dass manuelles Scrollen und Lesen von mehr als 100.000 Posts unpraktisch war. So kam mir die Idee, das Wissen, das ich in diesem Kurs erhalten habe, anzuwenden: alle Fragen und Kommentare aus dem Forum zu einem bestimmten Thema zu sammeln und eine thematische Modellierung mit den häufigsten Wörtern in jedem von ihnen zu erstellen.Schritt 1. Datenerfassung aus dem Forum
Das Forum besteht aus vielen Themen unterschiedlicher Größe. Insgesamt hat dieses Forum ungefähr 115.000 Themen und ungefähr eine Million Beiträge mit Kommentaren dazu. Ich interessierte mich für das spezifische Unterthema „Umgang mit Zöliakie“ , was wörtlich „mit Zöliakie fertig werden“ bedeutet, wenn es auf Russisch mehr bedeutet, „weiterhin mit der Diagnose einer Zöliakie zu leben und irgendwie mit Schwierigkeiten fertig zu werden“. Dieses Unterthema enthält ca. 175.000 Kommentare.Das Herunterladen der Daten erfolgte in zwei Schritten. Zunächst musste ich alle Seiten unter dem Thema durchgehen und alle Links zu allen Posts sammeln, damit ich im nächsten Schritt bereits einen Kommentar sammeln konnte.url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
Da sich das Forum als ziemlich alt herausstellte, hatte ich großes Glück und die Website hatte keine Sicherheitsprobleme. Um die Daten zu sammeln, reichte es aus, die User-Agent- Kombination aus der Bibliothek fake_useragent , Beautiful Soup zu verwenden , um mit HTML-Markup zu arbeiten und die Anzahl der Seiten zu kennen:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
Laden Sie dann das HTML-DOM jeder Seite herunter, um mithilfe der BeautifulSoup Python-Bibliothek einfach und problemlos Daten daraus abzurufen .
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
Um die Daten herunterzuladen, musste ich die für die Analyse erforderlichen Felder ermitteln: Suchen Sie die Werte dieser Felder im DOM und speichern Sie sie im Wörterbuch. Ich selbst kam aus dem Front-End-Bereich, daher war es für mich trivial, mit Haushalten und Gegenständen zu arbeiten.def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
Insgesamt habe ich ungefähr 15.450 Beiträge zu diesem Thema gesammelt.coping_posts_info = collect_post_info(coping_pages)
Jetzt konnten sie in den DataFrame übertragen werden, so dass sie dort wunderschön lagen, und gleichzeitig in einer CSV-Datei gespeichert werden, sodass Sie nicht erneut warten mussten, wenn die Daten von der Site gesammelt wurden, wenn das Notebook versehentlich kaputt ging oder ich versehentlich eine Variable neu definiert habe, bei der.df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
Nachdem ich eine Sammlung von Beiträgen gesammelt hatte, sammelte ich die Kommentare selbst.def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
SCHRITT 2 Datenanalyse und thematische Modellierung
Im vorherigen Schritt haben wir Daten aus dem Forum gesammelt und die endgültigen Daten in Form von 153777 Zeilen mit Fragen und Kommentaren erhalten.Aber nur die gesammelten Daten sind nicht interessant. Das erste, was ich tun wollte, war eine sehr einfache Analyse: Ich habe Statistiken für die 30 meistgesehenen und 30 am meisten kommentierten Themen abgeleitet.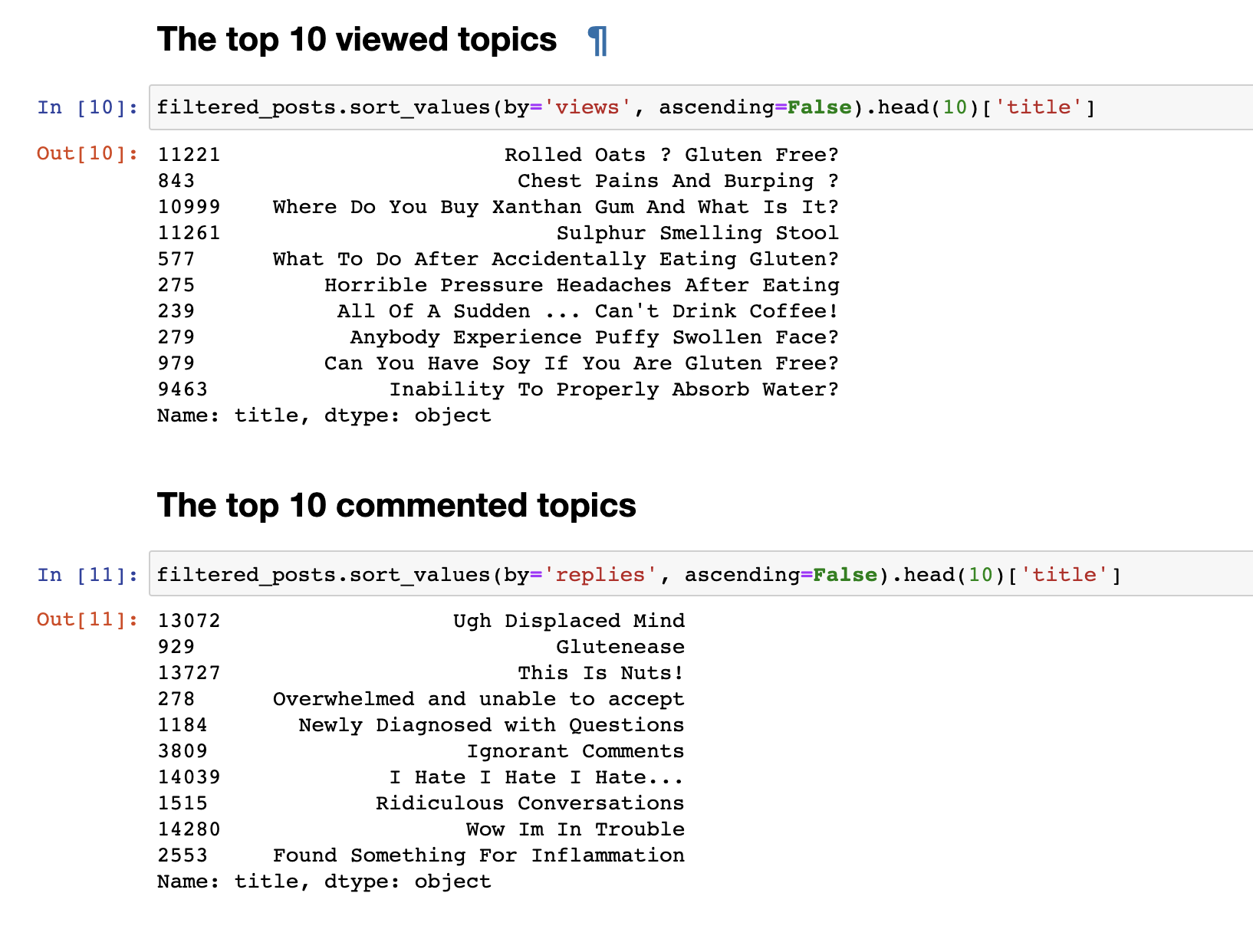 Die meistgesehenen Beiträge stimmten nicht mit den am meisten kommentierten überein. Die Titel kommentierter Beiträge sind bereits auf den ersten Blick erkennbar. Ihre Namen sind emotionaler: "Ich hasse, ich hasse, ich hasse" oder " Arrogante Kommentare" oder "Wow, ich bin in Schwierigkeiten . " Und die meistgesehenen haben ein Fragenformat: "Kann ich Soja essen?", "Warum kann ich Wasser nicht richtig aufnehmen?"und andere.Wir haben eine einfache Textanalyse durchgeführt. Um direkt zu einer komplexeren Analyse zu gelangen, müssen Sie die Daten selbst vorbereiten, bevor Sie sie zur Eingabe nach Themen an die Eingabe des LDA-Modells senden. Entfernen Sie dazu Kommentare mit weniger als 30 Wörtern, um Spam und bedeutungslose kurze Kommentare herauszufiltern. Wir bringen sie in Kleinbuchstaben.
Die meistgesehenen Beiträge stimmten nicht mit den am meisten kommentierten überein. Die Titel kommentierter Beiträge sind bereits auf den ersten Blick erkennbar. Ihre Namen sind emotionaler: "Ich hasse, ich hasse, ich hasse" oder " Arrogante Kommentare" oder "Wow, ich bin in Schwierigkeiten . " Und die meistgesehenen haben ein Fragenformat: "Kann ich Soja essen?", "Warum kann ich Wasser nicht richtig aufnehmen?"und andere.Wir haben eine einfache Textanalyse durchgeführt. Um direkt zu einer komplexeren Analyse zu gelangen, müssen Sie die Daten selbst vorbereiten, bevor Sie sie zur Eingabe nach Themen an die Eingabe des LDA-Modells senden. Entfernen Sie dazu Kommentare mit weniger als 30 Wörtern, um Spam und bedeutungslose kurze Kommentare herauszufiltern. Wir bringen sie in Kleinbuchstaben.
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
Löschen Sie unnötige Stoppwörter, um unsere Textauswahl zu löschenstop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
Wir fügen auch Bigramme hinzu und bilden eine Tüte mit Wörtern, um stabile Phrasen hervorzuheben, z. B. glutenfrei, support_group und andere Phrasen, die, wenn sie gruppiert sind, eine bestimmte Bedeutung haben.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Jetzt sind wir endlich bereit, das LDA-Modell selbst direkt zu trainieren.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
Am Ende des Trainings erhalten wir letztendlich das Ergebnis der gebildeten Themen. Was ich am Ende dieses Beitrags angehängt habe.for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
Wie sich vielleicht bemerkbar macht, haben sich die Themen inhaltlich als ziemlich unterschiedlich herausgestellt. Ihnen zufolge wird klar, wovon Menschen mit Zöliakie-Intoleranz sprechen. Grundsätzlich geht es um Essen, Restaurants, kontaminiertes Essen mit Gluten, schreckliche Schmerzen, Behandlung, Arztbesuche, Familienangehörige, Missverständnisse und andere Dinge, denen sich Menschen im Zusammenhang mit ihrem Problem jeden Tag stellen müssen.Das ist alles. Vielen Dank für Ihre Aufmerksamkeit. Ich hoffe, Sie finden dieses Material interessant und nützlich. Und doch, da ich kein DS-Entwickler bin, urteile nicht streng. Wenn es etwas hinzuzufügen oder zu verbessern gibt, freue ich mich immer über konstruktive Kritik, schreibe.30 Themen anzeigen