Von einem Google Blog-Editor: Haben Sie sich jemals gefragt, wie die Ingenieure von Google Cloud Technical Solutions (TSE) mit Ihren technischen Supportanrufen umgehen? Die technischen Support-Ingenieure von TSE sind dafür verantwortlich, die von den Benutzern identifizierten Problemquellen zu ermitteln und zu beheben. Einige dieser Probleme sind recht einfach, aber manchmal stößt man auf einen Appell, der die Aufmerksamkeit mehrerer Ingenieure gleichzeitig erfordert. In diesem Artikel wird uns einer der TSE-Mitarbeiter über ein sehr kniffliges Problem aus seiner jüngsten Praxis berichten - den Fall fehlender DNS-Pakete. Im Verlauf dieser Geschichte werden wir sehen, wie es den Ingenieuren gelungen ist, die Situation zu lösen, und welche neuen Dinge sie im Verlauf der Fehlerbehebung gelernt haben. Wir hoffen, dass diese Geschichte Ihnen nicht nur über einen tief verwurzelten Fehler berichtet, sondern auch ein Verständnis für die Prozesse vermittelt, die beim Senden einer Anfrage zur Unterstützung von Google Cloud auftreten. Die Fehlerbehebung ist sowohl eine Wissenschaft als auch eine Kunst. Alles beginnt mit der Erstellung einer Hypothese über die Ursache des nicht standardmäßigen Verhaltens des Systems, wonach es auf Festigkeit geprüft wird. Bevor wir jedoch eine Hypothese formulieren, müssen wir das Problem klar identifizieren und genau formulieren. Wenn die Frage zu vage klingt, müssen Sie alles richtig analysieren. Dies ist die "Kunst" der Fehlerbehebung.Im Kontext von Google Cloud sind solche Prozesse manchmal kompliziert, da Google Cloud Schwierigkeiten hat, die Privatsphäre seiner Nutzer zu gewährleisten. Aus diesem Grund haben TSE-Ingenieure weder Zugriff auf die Bearbeitung Ihrer Systeme noch auf die Möglichkeit, Konfigurationen so umfassend anzuzeigen wie Benutzer. Um eine unserer Hypothesen zu testen, können wir (Ingenieure) das System daher nicht schnell ändern.Einige Benutzer glauben, dass wir alles reparieren werden, als ob die Mechaniker im Autoservice, und uns einfach die ID der virtuellen Maschine senden würden, während der Prozess in Wirklichkeit in einem Konversationsformat abläuft: Sammeln von Informationen, Generieren und Bestätigen (oder Widerlegen) von Hypothesen und letztendlich Lösen Probleme beruhen auf der Kommunikation mit dem Kunden.
Die Fehlerbehebung ist sowohl eine Wissenschaft als auch eine Kunst. Alles beginnt mit der Erstellung einer Hypothese über die Ursache des nicht standardmäßigen Verhaltens des Systems, wonach es auf Festigkeit geprüft wird. Bevor wir jedoch eine Hypothese formulieren, müssen wir das Problem klar identifizieren und genau formulieren. Wenn die Frage zu vage klingt, müssen Sie alles richtig analysieren. Dies ist die "Kunst" der Fehlerbehebung.Im Kontext von Google Cloud sind solche Prozesse manchmal kompliziert, da Google Cloud Schwierigkeiten hat, die Privatsphäre seiner Nutzer zu gewährleisten. Aus diesem Grund haben TSE-Ingenieure weder Zugriff auf die Bearbeitung Ihrer Systeme noch auf die Möglichkeit, Konfigurationen so umfassend anzuzeigen wie Benutzer. Um eine unserer Hypothesen zu testen, können wir (Ingenieure) das System daher nicht schnell ändern.Einige Benutzer glauben, dass wir alles reparieren werden, als ob die Mechaniker im Autoservice, und uns einfach die ID der virtuellen Maschine senden würden, während der Prozess in Wirklichkeit in einem Konversationsformat abläuft: Sammeln von Informationen, Generieren und Bestätigen (oder Widerlegen) von Hypothesen und letztendlich Lösen Probleme beruhen auf der Kommunikation mit dem Kunden.Problem in Betracht gezogen
Heute haben wir eine Geschichte mit einem guten Ende. Einer der Gründe für die erfolgreiche Lösung des vorgeschlagenen Falls ist eine sehr detaillierte und genaue Beschreibung des Problems. Unten sehen Sie eine Kopie des ersten Tickets (bearbeitet, um vertrauliche Informationen zu verbergen): Diese Nachricht enthält viele nützliche Informationen für uns:
Diese Nachricht enthält viele nützliche Informationen für uns:- Angegebene VM
- Das Problem wird angezeigt - DNS funktioniert nicht
- Es wird angezeigt, wo sich das Problem manifestiert - VM und Container
- Die Schritte, die der Benutzer unternommen hat, um das Problem zu identifizieren, werden angezeigt.
Die Beschwerde wurde als „P1: Kritische Auswirkung - In der Produktion nicht verwendbarer Service“ registriert. Dies bedeutet eine ständige Überwachung der Situation rund um die Uhr gemäß dem Schema „Follow the Sun“ (der Link kann detaillierter über die Prioritäten von Benutzeranrufen gelesen werden ), wobei die Übermittlung von einem technischen Supportteam erfolgt zum anderen bei jeder Zeitzonenverschiebung. Als das Problem unser Team in Zürich erreichte, gelang es ihr tatsächlich, den Globus zu umrunden. Zu diesem Zeitpunkt ergriff der Benutzer Maßnahmen, um die Folgen zu verringern. Er befürchtete jedoch eine Wiederholung der Produktionssituation, da der Hauptgrund immer noch nicht gefunden wurde.Als das Ticket Zürich erreichte, hatten wir bereits folgende Informationen zur Hand:- Inhalt
/etc/hosts - Inhalt
/etc/resolv.conf - Fazit
iptables-save - Die vom Befehl kompilierte
ngreppcap-Datei
Mit diesen Daten waren wir bereit, mit der Phase der „Untersuchung“ und Fehlerbehebung zu beginnen.Unsere ersten Schritte
Zunächst haben wir die Protokolle und den Status des Metadatenservers überprüft und sichergestellt, dass er ordnungsgemäß funktioniert. Der Metadatenserver antwortet mit der IP-Adresse 169.254.169.254 und ist unter anderem für die Steuerung der Domainnamen verantwortlich. Wir haben außerdem überprüft, ob die Firewall mit VM ordnungsgemäß funktioniert und keine Pakete blockiert.Es war ein seltsames Problem: Der nmap-Test widerlegte unsere Haupthypothese über den Verlust von UDP-Paketen, sodass wir mental mehrere weitere Optionen und Möglichkeiten ableiteten, diese zu überprüfen:- Verschwinden Pakete selektiv? => Überprüfen Sie die iptables-Regeln
- Ist die MTU zu klein ? => Ausgabe prüfen
ip a show - Betrifft das Problem nur UDP-Pakete oder TCP? => Wegfahren
dig +tcp - Werden generierte Dig-Pakete zurückgegeben? => Wegfahren
tcpdump - Funktioniert libdns richtig? => Fahren Sie weg
strace, um die Paketübertragung in beide Richtungen zu überprüfen
Hier beschließen wir, den Benutzer anzurufen, um Fehler live zu beheben.Während des Anrufs können wir verschiedene Dinge überprüfen:- Nach mehreren Überprüfungen schließen wir iptables-Regeln aus der Liste der Gründe aus.
- Wir überprüfen Netzwerkschnittstellen und Routing-Tabellen und überprüfen die MTU
- Wir stellen fest, dass
dig +tcp google.com(TCP) so funktioniert, wie es sollte, aber dig google.com(UDP) nicht funktioniert - Nachdem es
tcpdumpausgeführt wurde, während es funktioniert dig, stellen wir fest, dass UDP-Pakete zurückgegeben werden - Wir rennen
strace dig google.comund sehen, wie Dig richtig anruft sendmsg()und recvms()der zweite wird jedoch durch Timeout unterbrochen
Leider ist die Schicht kurz vor dem Ende und wir sind gezwungen, das Problem in die nächste Zeitzone zu übertragen. Der Appell weckte jedoch das Interesse an unserem Team, und ein Kollege schlägt vor, das Quell-DNS-Paket mit dem Python-Modul Scrapy zu erstellen.from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())
Dieses Fragment erstellt ein DNS-Paket und sendet die Anforderung an den Metadatenserver.Der Benutzer führt den Code aus, die DNS-Antwort wird zurückgegeben und die Anwendung empfängt sie, wodurch das Fehlen eines Problems auf Netzwerkebene bestätigt wird.Nach der nächsten "Weltreise" kehrt der Appell zu unserem Team zurück, und ich übersetze ihn vollständig auf mich selbst, da ich glaube, dass es für den Benutzer bequemer ist, wenn der Appell nicht mehr von Ort zu Ort kreist.In der Zwischenzeit erklärt sich der Benutzer damit einverstanden, eine Momentaufnahme des Systemabbilds bereitzustellen. Dies sind sehr gute Nachrichten: Die Möglichkeit, das System selbst zu testen, beschleunigt die Fehlerbehebung erheblich, da Sie den Benutzer nicht mehr auffordern müssen, Befehle auszuführen, mir Ergebnisse zu senden und diese zu analysieren. Ich kann alles selbst tun!Kollegen beginnen mich ein wenig zu beneiden. Beim Mittagessen besprechen wir den Appell, aber niemand hat eine Ahnung, was los ist. Glücklicherweise hat der Benutzer selbst bereits Minderungsmaßnahmen ergriffen und hat es nicht eilig, sodass wir Zeit haben, das Problem vorzubereiten. Und da wir ein Bild haben, können wir alle Tests durchführen, die uns interessieren. Fein!Einen Schritt zurückgehen
Eine der häufigsten Fragen in einem Interview für einen Systemingenieur lautet: "Was passiert, wenn Sie www.google.com anpingen ?" Die Frage ist vornehm, weil der Kandidat von der Shell über den Benutzerraum bis zum Kern des Systems und weiter zum Netzwerk beschrieben werden muss. Ich lächle: Manchmal sind Interviewfragen auch im wirklichen Leben nützlich ...Ich beschließe, diese eychar-Frage auf das aktuelle Problem anzuwenden. Wenn Sie versuchen, den DNS-Namen zu ermitteln, geschieht ungefähr Folgendes:- Die Anwendung ruft die Systembibliothek auf, z. B. libdns
- libdns überprüft die Systemkonfiguration, welchen DNS-Server es verwenden soll (im Diagramm ist es 169.254.169.254, Metadatenserver)
- libdns verwendet Systemaufrufe, um einen UDP-Socket (SOKET_DGRAM) zu erstellen und UDP-Pakete mit einer DNS-Anforderung in beide Richtungen zu senden
- Über die sysctl-Schnittstelle können Sie den UDP-Stack auf Kernelebene konfigurieren
- Der Kernel interagiert mit der Hardware, um Pakete über eine Netzwerkschnittstelle über das Netzwerk zu übertragen
- Der Hypervisor fängt das Paket ab und leitet es an den Metadatenserver weiter, wenn es damit in Kontakt kommt
- Der Metadatenserver ermittelt den DNS-Namen anhand seiner Hexerei und gibt die Antwort auf die gleiche Weise zurück
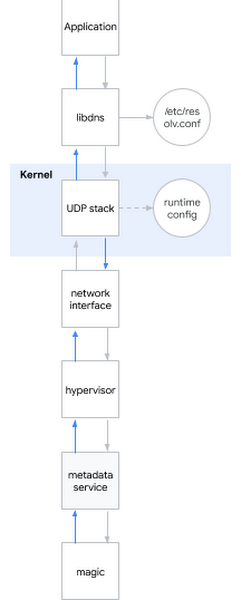 Ich möchte Sie daran erinnern, welche Hypothesen wir bereits berücksichtigt haben:Hypothese: Defekte Bibliotheken
Ich möchte Sie daran erinnern, welche Hypothesen wir bereits berücksichtigt haben:Hypothese: Defekte Bibliotheken- Test 1: Führen Sie strace im System aus und überprüfen Sie, ob dig die richtigen Systemaufrufe verursacht
- Ergebnis: Richtige Systemaufrufe werden aufgerufen
- Test 2: Durch Srapy, um zu überprüfen, ob wir die Namen unter Umgehung der Systembibliotheken ermitteln können
- Ergebnis: wir können
- Test 3: Führen Sie rpm –V für das libdns-Paket und die md5sum-Bibliotheksdateien aus
- Ergebnis: Der Bibliothekscode ist vollständig identisch mit dem Code im funktionierenden Betriebssystem
- Test 4: Mounten Sie das Image des Stammsystems des Benutzers ohne dieses Verhalten auf der VM, führen Sie chroot aus und prüfen Sie, ob DNS funktioniert
- Ergebnis: DNS funktioniert ordnungsgemäß
Schlussfolgerung basierend auf Tests: Das Problem liegt nicht in Bibliotheken.Hypothese: Es liegt ein Fehler in den DNS-Einstellungen vor- Test 1: Überprüfen Sie tcpdump und prüfen Sie, ob DNS-Pakete nach dem Ausführen von dig korrekt gesendet und zurückgegeben werden
- Ergebnis: Pakete werden korrekt übertragen
- Test 2: Überprüfen Sie den Server erneut
/etc/nsswitch.confund/etc/resolv.conf - Ergebnis: alles ist richtig
Testbasierte Schlussfolgerung: Das Problem liegt nicht in der DNS-Konfigurationshypothese: Kernel beschädigt- Test: Installieren Sie einen neuen Kernel, überprüfen Sie die Signatur und starten Sie ihn neu
- Ergebnis: ähnliches Verhalten
Schlussfolgerung basierend auf Tests: Der Kernel ist nicht beschädigtHypothese: Falsches Verhalten des Benutzernetzwerks (oder der Netzwerkschnittstelle des Hypervisors)- Test 1: Überprüfen Sie die Firewall-Einstellungen
- Ergebnis: Die Firewall leitet DNS-Pakete sowohl auf dem Host als auch auf dem GCP weiter
- Test 2: Abfangen des Datenverkehrs und Verfolgen der Richtigkeit der Übertragung und Rückgabe von DNS-Abfragen
- Ergebnis: tcpdump bestätigt den Empfang von Rückpaketen durch den Host
Testbasierte Schlussfolgerung: Das Problem liegt nicht im Netzwerk.Hypothese: Der Metadatenserver funktioniert nicht- Test 1: Überprüfen Sie die Metadatenserverprotokolle auf Anomalien
- Ergebnis: Die Protokolle enthalten keine Anomalien
- Test 2: Umgehen Sie den Metadatenserver
dig @8.8.8.8 - Ergebnis: Die Berechtigung wird auch ohne Verwendung eines Metadatenservers verletzt
Test-basiertes Fazit: Das Problem ist nicht in dem Metadaten - ServerFazit: wir alle Subsysteme mit Ausnahme der getesteten Laufzeiteinstellungen!Eintauchen in die Kernel-Laufzeiteinstellungen
Um die Kernel-Laufzeit zu konfigurieren, können Sie die Befehlszeilenoptionen (grub) oder die sysctl-Schnittstelle verwenden. Ich habe reingeschaut /etc/sysctl.confund nur gedacht, ich habe ein paar benutzerdefinierte Einstellungen gefunden. Ich hatte das Gefühl, etwas ergriffen zu haben, und entließ alle Nicht-Netzwerk- oder Nicht-TCP-Einstellungen, die von den Bergeinstellungen übrig blieben net.core. Dann wandte ich mich an die Stelle, an der die VM über die Host-Berechtigungen verfügt, und begann nacheinander die Einstellungen für die defekte VM anzuwenden, bis ich den Verbrecher erreichte:net.core.rmem_default = 2147483647
Hier ist es, eine DNS-brechende Konfiguration! Ich habe ein Instrument des Verbrechens gefunden. Aber warum passiert das? Ich brauchte noch ein Motiv.Das Festlegen der Basisgröße des DNS-Paketpuffers erfolgt über net.core.rmem_default. Ein typischer Wert variiert irgendwo innerhalb von 200 KB. Wenn Ihr Server jedoch viele DNS-Pakete empfängt, können Sie den Puffer vergrößern. Wenn der Puffer zum Zeitpunkt des Eintreffens eines neuen Pakets voll ist, z. B. weil die Anwendung es nicht schnell genug verarbeitet, verlieren Sie Pakete. Unser Client hat die Puffergröße korrekt erhöht, weil er Angst vor Datenverlust hatte, weil er die Anwendung zum Sammeln von Metriken über DNS-Pakete verwendet hat. Der von ihm festgelegte Wert war das maximal mögliche: 2 31 -1 (wenn Sie 2 31 festlegen , gibt der Kernel "UNGÜLTIGES ARGUMENT" zurück).Plötzlich wurde mir klar, warum nmap und scapy richtig funktionierten: Sie verwendeten rohe Sockel! Raw-Sockets unterscheiden sich von normalen Sockets: Sie umgehen iptables und sind nicht gepuffert!Aber warum verursacht ein „zu großer Puffer“ Probleme? Es funktioniert offensichtlich nicht wie beabsichtigt.Zu diesem Zeitpunkt konnte ich das Problem auf mehreren Kernen und mehreren Verteilungen reproduzieren. Das Problem hat sich bereits im 3.x-Kernel manifestiert und manifestiert sich nun auch im 5.x-Kernel.In der Tat beim Startsysctl -w net.core.rmem_default=$((2**31-1))
DNS funktioniert nicht mehr.Ich begann über einen einfachen binären Suchalgorithmus nach Arbeitswerten zu suchen und stellte fest, dass das System mit 2147481343 funktioniert. Diese Zahl war jedoch für mich ein bedeutungsloser Satz von Zahlen. Ich habe den Kunden eingeladen, diese Nummer auszuprobieren, und er antwortete, dass das System mit google.com funktioniert, aber dennoch einen Fehler mit anderen Domains gemeldet hat, sodass ich meine Untersuchung fortsetzte.Ich habe Dropwatch installiert , ein Tool, das ich vorher hätte verwenden sollen: Es zeigt, wo genau das Paket im Kernel ist. Die Funktion war schuldig udp_queue_rcv_skb. Ich habe die Kernelquellen heruntergeladen und verschiedene Funktionen hinzugefügt , umprintk zu verfolgen, wo das Paket speziell hinkommt. Ich fand schnell den richtigen Zustandifund starrte ihn eine Weile einfach an, denn dann kam schließlich alles zu einem ganzen Bild zusammen: 2 31 -1, eine bedeutungslose Zahl, eine leere Domäne ... Es war ein Stück Code in __udp_enqueue_schedule_skb:if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;
Beachten Sie:rmem hat den Typ intsize ist vom Typ u16 (vorzeichenloses 16-Bit-Int) und speichert die Paketgrößesk->sk_rcybuf ist vom Typ int und speichert die Größe des Puffers, die per Definition gleich dem Wert in ist net.core.rmem_default
Wenn Sie sk_rcvbufsich 2 31 nähern , kann das Summieren der Paketgröße zu einem ganzzahligen Überlauf führen . Und da es sich um ein int handelt, wird sein Wert negativ, sodass die Bedingung wahr wird, wenn sie falsch sein sollte (mehr dazu finden Sie unter Bezugnahme ).Der Fehler wird auf triviale Weise korrigiert: durch Casting auf unsigned int. Ich habe den Patch angewendet und das System neu gestartet. Danach hat der DNS wieder funktioniert.Geschmack des Sieges
Ich habe meine Ergebnisse an den Client weitergeleitet und den LKML- Kernel-Patch gesendet . Ich bin zufrieden: Jedes Puzzleteil hat sich zu einem Ganzen zusammengeschlossen. Ich kann genau erklären, warum wir das beobachtet haben, was wir beobachtet haben, und vor allem konnten wir durch Zusammenarbeit eine Lösung für das Problem finden!Es ist erwähnenswert, dass sich der Fall als selten herausstellte, und glücklicherweise werden solche komplexen Anrufe selten von Benutzern von uns empfangen.
