Fortsetzung des ersten Teils des Artikels „IoT, wo Sie nicht gewartet haben. Entwicklung und Test (Teil 1) “ließ nicht lange auf sich warten. Dieses Mal werde ich Ihnen sagen, wie die Architektur des Projekts war und auf welche Art von Rechen wir getreten sind, als wir mit dem Testen unserer Lösung begonnen haben.Haftungsausschluss: Kein einziger Mülleimer wurde schwer getroffen.
Projektarchitektur
Wir haben ein typisches Microservice-Projekt. Die Schicht der Mikrodienste der „unteren Ebene“ empfängt Daten von Geräten und Sensoren und speichert sie in Kafka. Anschließend können geschäftsorientierte Mikrodienste mit den von Kafka empfangenen Daten arbeiten, um den aktuellen Status der Geräte anzuzeigen, Analysen zu erstellen und ihre Modelle zu optimieren.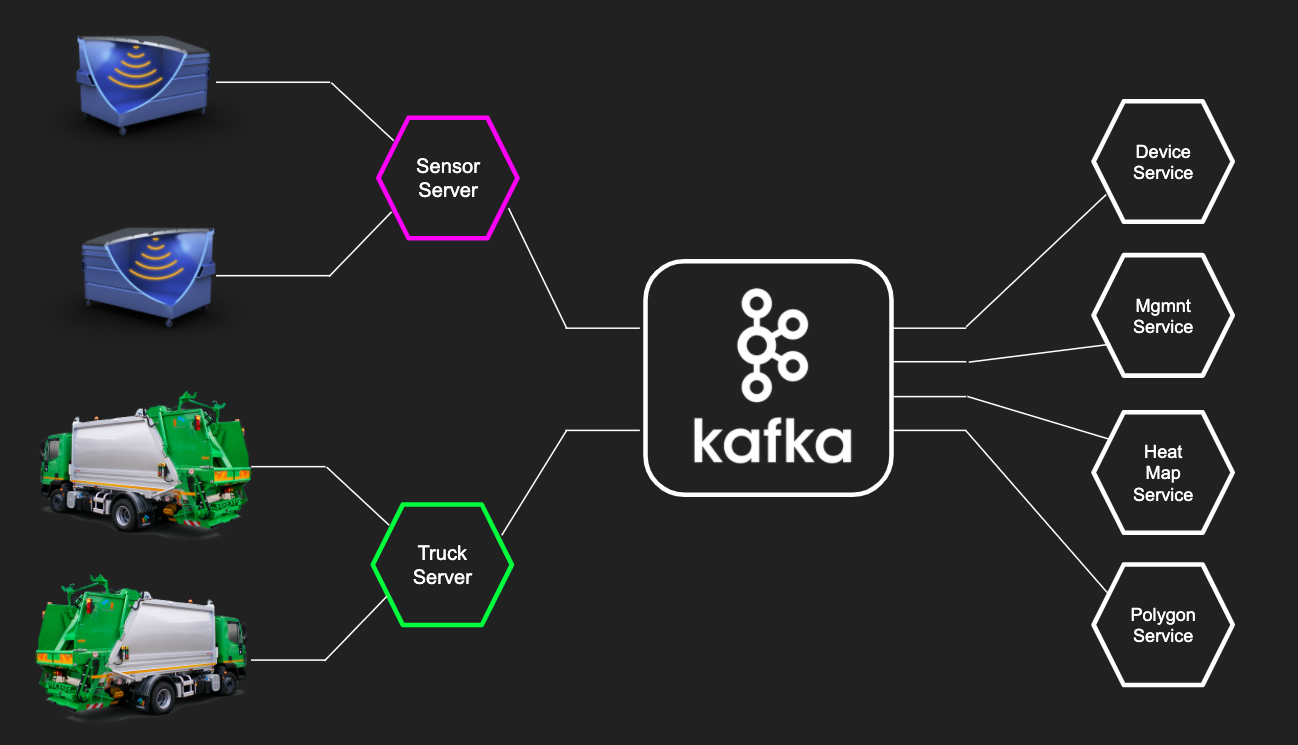 Kafka im IoT-Projekt lief sehr cool. Im Vergleich zu anderen Systemen wie RabbitMQ bietet Kafka mehrere Vorteile:
Kafka im IoT-Projekt lief sehr cool. Im Vergleich zu anderen Systemen wie RabbitMQ bietet Kafka mehrere Vorteile:- Arbeiten mit Streams : Rohdaten von Sensoren können verarbeitet werden, um einen Stream zu erhalten. Und mit Streams können Sie flexibel konfigurieren, was Sie in ihnen filtern möchten, und es ist einfach, Streaming durchzuführen (neue Datenströme erstellen).
- : Kafka , , , . - , - , . , Kafka , . , , , .
Backend
Schauen wir uns zunächst das uns vertraute Backend an. Die gesamte Geschäftsschicht der Anwendung basiert auf demselben Java- und Spring-Stack. Um Microservice-Anwendungen in einer realen Umgebung zu testen, verwenden wir die Testcontainer-Bibliothek. Sie können damit problemlos externe Bindungen (Kafka, PostgreSQL, MongoDB usw.) in Docker bereitstellen.Zuerst heben wir den erforderlichen Container in Docker auf, starten die Anwendung und führen auf der realen Instanz bereits Testdaten aus.Wie genau wir das machen, habe ich beim Heisenbug 2019 Piter im Bericht „Microservice Wars: JUnit Episode 5 - TestContainers Strikes Back“ ausführlich besprochen:Schauen wir uns ein kleines Beispiel an, wie es aussah. Der untergeordnete Dienst nimmt Daten von Geräten und sendet sie an Kafka. Und der Heat Map-Dienst aus dem Geschäftsbereich nimmt Daten von kafka und erstellt eine Heat Map. Testen wir den Empfang von Daten mit dem Heat Map-Dienst (über Kafka).
Testen wir den Empfang von Daten mit dem Heat Map-Dienst (über Kafka).@KafkaTestContainer
@SpringBootTest
class KafkaIntegrationTest {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
void sendTest() {
kafkaTemplate.send(TOPIC_NAME, MEASSAGE_BODY)
}
}
Wir schreiben einen regelmäßigen Integrations-SpringBoot-Test, der sich jedoch im annotationsbasierten Stil der Konfiguration der Testumgebung unterscheidet. Annotation ist @KafkaTestContainererforderlich, um Kafka zu erheben. Um es zu verwenden, müssen Sie die Bibliothek verbinden:spring-test-kafkaWenn die Anwendung gestartet wird, startet Spring und der Kafka-Container startet in Docker. Dann verwenden wir es im Test kafkaTemplate, injizieren es in den Testfall und senden die Daten an Kafka, um die Logik der Verarbeitung neuer Daten aus dem Thema zu testen.All dies geschieht auf einer normalen Kafka-Instanz, ohne eingebettete Optionen, sondern nur mit der Version, die sich in der Produktion dreht. Der Heat Map-Dienst verwendet MongoDB als Speicher, und der Test für MongoDB sieht ähnlich aus:
Der Heat Map-Dienst verwendet MongoDB als Speicher, und der Test für MongoDB sieht ähnlich aus:@MongoDbDataTest
class SensorDataRecordServiceTest {
@Autowired
private SensorDataRecordRepository repository;
@Test
@MongoDataSet(value ="sensor_data.json")
void findSingle() {
var log = repository.findAllByDeviceId("001");
assertThat(log).hasSize(1);
...
}
}
Annotation @MongoDbDataTeststartet MongoDB in Docker ähnlich wie Kafka. Nach dem Start der Anwendung können wir das Repository verwenden, um mit MongoDB zu arbeiten.Um diese Funktionalität in Ihren Tests zu verwenden, müssen Sie lediglich die Bibliothek verbinden:spring-test-mongoÜbrigens gibt es dort viele andere Nützlichkeiten. Sie können beispielsweise die Datenbank über die Anmerkung in die Datenbank laden, bevor Sie den Test ausführen, @MongoDataSetwie im obigen Beispiel oder Stellen Sie anhand der Anmerkung @ExpectedMongoDataSetsicher, dass nach Abschluss des Testfalls in der Datenbank der genaue Datensatz angezeigt wurde, den wir erwarten.Ich werde Ihnen mehr über die Arbeit mit Testdaten am Heisenbug 2020 Piter erzählen , der vom 15. bis 18. Juni online stattfinden wird.
IoT-spezifische Dinge testen
Wenn der Geschäftsteil ein typisches Backend ist, enthielt die Arbeit mit Daten von Geräten viele Rechen und Besonderheiten in Bezug auf Hardware.Sie haben ein Gerät und müssen es koppeln. Dazu benötigen Sie Dokumentation. Es ist gut, wenn Sie ein Stück Eisen haben und darauf andocken. Alles begann jedoch anders: Es gab nur Dokumentation, und das Gerät war noch unterwegs. Wir haben eine kleine Anwendung gedreht, die theoretisch hätte funktionieren sollen, aber sobald echte Geräte eintrafen, wurden unsere Erwartungen mit der Realität konfrontiert.Wir dachten, dass die Eingabe ein Binärformat sein würde, und das Gerät begann, uns eine XML-Datei zuzuwerfen. Und in solch einer schwierigen Form wurde die erste Regel für das IoT-Projekt geboren:Glauben Sie niemals der Dokumentation!
Grundsätzlich waren die vom Gerät empfangenen Daten mehr oder weniger klar: Time- Dies ist der Zeitstempel, DevEUI- die Kennung des Geräts LrrLATund LrrLON- die Koordinaten. Aber was ist das
Aber was ist das payload_hex? Wir sehen 8 Ziffern, was kann in ihnen sein? Ist es der Abstand zum Müll, die Spannung des Sensors, der Signalpegel, der Neigungswinkel, die Temperatur oder alles zusammen? Irgendwann dachten wir, dass die chinesischen Hersteller dieser Geräte eine Art Archivierung von Feng Shui kannten und alles, was möglich war, in 8 Ziffern packen konnten. Wenn Sie jedoch nach oben schauen, können Sie sehen, dass die Zeit in einer regulären Zeile geschrieben ist und dreimal mehr Bits enthält, dh Bytes, die offensichtlich niemand gespeichert hat. Als Ergebnis stellte sich heraus, dass speziell in dieser Firmware die Hälfte der Sensoren im Gerät einfach ausgeschaltet ist und Sie auf eine neue Firmware warten müssen.Während sie warteten, stellten wir im Büro einen Prüfstand her, der eigentlich ein gewöhnlicher Karton war. Wir befestigten das Gerät an der Abdeckung und warfen alle Büromaterialien in die Schachtel. Wir brauchten auch eine Testkopie des Wagens des Trägers, und seine Rolle wurde von der Maschine eines der Entwickler im Projekt gespielt.Jetzt sahen wir auf der Karte, wo die Pappkartons standen, und wir wussten, wohin der Entwickler reiste (Spoiler: Work-Home, und niemand hat die Bar am Freitagabend abgesagt). Das System mit Prüfständen hielt jedoch nicht lange, da es große Unterschiede zu echten Containern gibt. Wenn wir zum Beispiel über den Beschleunigungsmesser sprechen, haben wir die Box von einer Seite zur anderen gedreht und Messwerte vom Sensor erhalten, und alles schien zu funktionieren. In Wirklichkeit gibt es jedoch einige Einschränkungen.
Das System mit Prüfständen hielt jedoch nicht lange, da es große Unterschiede zu echten Containern gibt. Wenn wir zum Beispiel über den Beschleunigungsmesser sprechen, haben wir die Box von einer Seite zur anderen gedreht und Messwerte vom Sensor erhalten, und alles schien zu funktionieren. In Wirklichkeit gibt es jedoch einige Einschränkungen. In den ersten Versionen des Geräts wurde der Winkel nicht in absoluten Werten, sondern in relativen Werten gemessen. Und als die Box mehr geneigt war als das in der Firmware festgelegte Delta, begann der Sensor falsch zu arbeiten oder konnte die Drehung sogar nicht reparieren.
In den ersten Versionen des Geräts wurde der Winkel nicht in absoluten Werten, sondern in relativen Werten gemessen. Und als die Box mehr geneigt war als das in der Firmware festgelegte Delta, begann der Sensor falsch zu arbeiten oder konnte die Drehung sogar nicht reparieren. Natürlich wurden all diese Fehler im Prozess korrigiert, aber zu Beginn brachten die Unterschiede zwischen der Box und dem Container viele Probleme mit sich. Und wir haben den Tank von allen Seiten gebohrt, während wir entschieden haben, wie der Sensor in den Container eingesetzt werden soll, damit wir beim Anheben des Tanks mit dem Auto des Trägers genau aufgezeichnet haben, dass der Müll entladen wurde.Neben dem Problem mit dem Neigungswinkel haben wir zunächst nicht berücksichtigt, wie hoch der tatsächliche Müll im Container sein wird. Und wenn wir Styropor und Kissen in diese Schachtel geworfen haben, dann haben die Leute in Wirklichkeit alles in einen Behälter gegeben, sogar Zement und Sand. Als Ergebnis zeigte der Sensor an, dass der Behälter leer war, obwohl er tatsächlich voll war. Wie sich herausstellte, warf jemand während der Reparatur ein kühles schallabsorbierendes Material, das die Signale vom Sensor dämpfte.Zu diesem Zeitpunkt haben wir uns entschlossen, mit dem Vermieter des Geschäftszentrums, in dem sich das Büro befindet, übereinzustimmen, um Sensoren an den Müllcontainern zu installieren. Wir haben die Baustelle vor dem Büro ausgestattet, und von diesem Moment an haben sich das Leben und der Alltag der Projektentwickler dramatisch verändert. Normalerweise möchten Sie zu Beginn des Arbeitstages Kaffee trinken, die Nachrichten lesen und hier haben Sie buchstäblich das ganze Band voller Müll:
Natürlich wurden all diese Fehler im Prozess korrigiert, aber zu Beginn brachten die Unterschiede zwischen der Box und dem Container viele Probleme mit sich. Und wir haben den Tank von allen Seiten gebohrt, während wir entschieden haben, wie der Sensor in den Container eingesetzt werden soll, damit wir beim Anheben des Tanks mit dem Auto des Trägers genau aufgezeichnet haben, dass der Müll entladen wurde.Neben dem Problem mit dem Neigungswinkel haben wir zunächst nicht berücksichtigt, wie hoch der tatsächliche Müll im Container sein wird. Und wenn wir Styropor und Kissen in diese Schachtel geworfen haben, dann haben die Leute in Wirklichkeit alles in einen Behälter gegeben, sogar Zement und Sand. Als Ergebnis zeigte der Sensor an, dass der Behälter leer war, obwohl er tatsächlich voll war. Wie sich herausstellte, warf jemand während der Reparatur ein kühles schallabsorbierendes Material, das die Signale vom Sensor dämpfte.Zu diesem Zeitpunkt haben wir uns entschlossen, mit dem Vermieter des Geschäftszentrums, in dem sich das Büro befindet, übereinzustimmen, um Sensoren an den Müllcontainern zu installieren. Wir haben die Baustelle vor dem Büro ausgestattet, und von diesem Moment an haben sich das Leben und der Alltag der Projektentwickler dramatisch verändert. Normalerweise möchten Sie zu Beginn des Arbeitstages Kaffee trinken, die Nachrichten lesen und hier haben Sie buchstäblich das ganze Band voller Müll: Beim Testen des Temperatursensors wie beim Beschleunigungsmesser wurden in der Realität neue Szenarien vorgestellt. Der Schwellenwert für die Temperatur ist ziemlich schwer zu wählen, damit wir rechtzeitig wissen, dass der Sensor eingeschaltet ist, und uns nicht von ihm verabschieden. Zum Beispiel erwärmen sich Behälter im Sommer sehr stark unter der Sonne, und das Einstellen einer zu niedrigen Schwellentemperatur ist mit ständigen Benachrichtigungen des Sensors behaftet. Und wenn das Gerät wirklich brennt und jemand anfängt, es zu löschen, müssen Sie sich darauf vorbereiten, dass der Tank oben mit Wasser gefüllt wird. Dann lässt ihn jemand fallen und er löscht auf dem Boden. In diesem Szenario überlebt der Sensor offensichtlich nicht.
Beim Testen des Temperatursensors wie beim Beschleunigungsmesser wurden in der Realität neue Szenarien vorgestellt. Der Schwellenwert für die Temperatur ist ziemlich schwer zu wählen, damit wir rechtzeitig wissen, dass der Sensor eingeschaltet ist, und uns nicht von ihm verabschieden. Zum Beispiel erwärmen sich Behälter im Sommer sehr stark unter der Sonne, und das Einstellen einer zu niedrigen Schwellentemperatur ist mit ständigen Benachrichtigungen des Sensors behaftet. Und wenn das Gerät wirklich brennt und jemand anfängt, es zu löschen, müssen Sie sich darauf vorbereiten, dass der Tank oben mit Wasser gefüllt wird. Dann lässt ihn jemand fallen und er löscht auf dem Boden. In diesem Szenario überlebt der Sensor offensichtlich nicht.
Daher die zweite Regel: Lesen Sie die erste Regel. Das heißt - vertraue niemals der Dokumentation.
Was kann getan werden? Führen Sie beispielsweise ein Reverse Engineering durch: Wir setzen uns an die Konsole, sammeln Daten, drehen den Sensor, drehen etwas davor und versuchen, Muster zu identifizieren. So können Sie den Abstand, den Status des Containers und die Prüfsumme isolieren. Einige der Daten waren jedoch schwer zu interpretieren, da unsere chinesischen Gerätehersteller offenbar Fahrräder lieben. Und um eine Gleitkommazahl im Binärformat für die Interpretation des Neigungswinkels zu packen, haben sie beschlossen, zwei Bytes zu nehmen und durch 35 zu teilen. In dieser ganzen Geschichte hat es uns sehr geholfen, dass die unterste Schicht von Diensten, die mit Geräten arbeiten, von oben und unten isoliert war Alle Daten wurden über kafka übertragen, für die Verträge vereinbart und gesichert wurden.Dies hat in Bezug auf die Entwicklung sehr geholfen, denn wenn die untere Ebene kaputt ging, sahen wir leise Geschäftsdienstleistungen, da der Vertrag fest in ihnen festgelegt ist. Daher besteht diese zweite Regel für die Entwicklung von IoT-Projekten darin, Dienste zu isolieren und Verträge zu nutzen.
In dieser ganzen Geschichte hat es uns sehr geholfen, dass die unterste Schicht von Diensten, die mit Geräten arbeiten, von oben und unten isoliert war Alle Daten wurden über kafka übertragen, für die Verträge vereinbart und gesichert wurden.Dies hat in Bezug auf die Entwicklung sehr geholfen, denn wenn die untere Ebene kaputt ging, sahen wir leise Geschäftsdienstleistungen, da der Vertrag fest in ihnen festgelegt ist. Daher besteht diese zweite Regel für die Entwicklung von IoT-Projekten darin, Dienste zu isolieren und Verträge zu nutzen.Der Bericht war noch viel interessanter: Simulation, Lasttests, und im Allgemeinen würde ich Ihnen raten, diesen Bericht zu lesen.
Im dritten Teil werde ich über ein Simulationsmodell sprechen, bleiben Sie dran!