Hallo allerseits, mein Name ist Fedor Indukaev, ich arbeite als Analyst bei Yandex.Routing. Heute möchte ich Ihnen etwas über die Aufgabe der Visualisierung sich überschneidender Mengen und über das Open-Source-Python-Paket erzählen, das ich erstellt habe, um es zu lösen. Dabei lernen wir, wie sich Venn- und Euler-Diagramme unterscheiden, lernen den Dienst der Auftragsverteilung kennen und berühren tangential ein Wissenschaftsgebiet wie die Bioinformatik. Wir werden von einfach zu komplexer wechseln. Gehen!Worum geht es und warum wird es benötigt?
Fast jeder, der sich mit explorativen Datenanalysen befasste, musste mindestens einmal nach einer Antwort auf Fragen dieser Art suchen:- Es gibt einen Datensatz mit mehreren unabhängigen binären Variablen. Welche von ihnen werden oft zusammen gefunden?
- Es gibt mehrere Tabellen mit Objekten derselben Art, die IDs haben. Wie hängen die ID-Sätze aus verschiedenen Tabellen zusammen - entweder hat jede Tabelle ihre eigene ID oder in allen Tabellen die gleiche, oder die Sätze unterscheiden sich, aber nur geringfügig?
- Es gibt mehrere Arten. Welche Organismen haben ähnliche Sätze von Genen oder Proteinen?
- Wie zeichne ich wie ein Kreisdiagramm, wenn sich Kategorien überschneiden? (Dies wird zwar nicht für alle zum Problem: siehe Prozentsätze in der folgenden Abbildung.)
Alle diese Fragen können auf den gleichen Wortlaut reduziert werden. Es klingt so: Es werden einige endliche Mengen angegeben, die sich möglicherweise überschneiden, und wir müssen ihre relative Position bewerten - das heißt, um zu verstehen, wie genau sie sich schneiden.Wir werden uns auf Visualisierungen und Softwaretools konzentrieren, um dieses Problem zu lösen.Venn-Diagramme
Solche Zeichnungen mit zwei oder drei Kreisen sind meines Erachtens jedem bekannt und bedürfen keiner Erklärung:Ein Merkmal des Venn-Diagramms ist, dass es statisch ist. Die Zahlen darauf sind gleich und symmetrisch angeordnet. Die Abbildung zeigt alle möglichen Kreuzungen, auch wenn die meisten tatsächlich leer sind. Solche Diagramme eignen sich zur Veranschaulichung abstrakter Konzepte oder Mengen, deren genaue Abmessungen unbekannt oder unwichtig sind. Die grundlegenden Informationen hier sind nicht im Zeitplan enthalten, sondern in den Unterschriften.
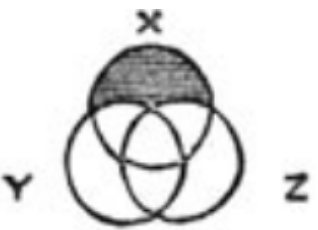 So wurden sie von John Venn, einem englischen Mathematiker und Philosophen, konzipiert. In seinem Artikel von 1880er schlug Diagramme zur grafischen Darstellung logischer Sätze vor. Zum Beispiel gibt die Aussage „jedes X ist entweder Y oder Z“ ein Diagramm auf der rechten Seite (Abbildung aus dem Originalartikel). Der Bereich, der die Aussage nicht erfüllt, ist schwarz schattiert: die X, die weder Y noch Z sind. Die Hauptbotschaft des Artikels ist, dass statische Zeichnungen ohne Änderung der Form und Anordnung von Figuren für logische Zwecke besser geeignet sind als die diskutierten dynamischen Euler-Diagramme wird unten gehen.Es ist klar, dass bei der Analyse von Daten der Umfang von Venn-Diagrammen begrenzt ist. Sie geben nur qualitative Informationen, aber keine quantitativen und spiegeln weder die Größe noch die Leere von Kreuzungen wider. Wenn Sie dies nicht aufhält, steht Ihnen das venn- Paket zur Verfügung , für das solche Diagramme erstellt werden Sätze. Für jedes es gibt ein oder zwei typische Bilder, und nur die Signaturen unterscheiden sich:Wenn wir etwas dynamischeres von den Daten abhängig haben möchten, sollten Sie einen anderen Ansatz beachten: Euler-Diagramme.
So wurden sie von John Venn, einem englischen Mathematiker und Philosophen, konzipiert. In seinem Artikel von 1880er schlug Diagramme zur grafischen Darstellung logischer Sätze vor. Zum Beispiel gibt die Aussage „jedes X ist entweder Y oder Z“ ein Diagramm auf der rechten Seite (Abbildung aus dem Originalartikel). Der Bereich, der die Aussage nicht erfüllt, ist schwarz schattiert: die X, die weder Y noch Z sind. Die Hauptbotschaft des Artikels ist, dass statische Zeichnungen ohne Änderung der Form und Anordnung von Figuren für logische Zwecke besser geeignet sind als die diskutierten dynamischen Euler-Diagramme wird unten gehen.Es ist klar, dass bei der Analyse von Daten der Umfang von Venn-Diagrammen begrenzt ist. Sie geben nur qualitative Informationen, aber keine quantitativen und spiegeln weder die Größe noch die Leere von Kreuzungen wider. Wenn Sie dies nicht aufhält, steht Ihnen das venn- Paket zur Verfügung , für das solche Diagramme erstellt werden Sätze. Für jedes es gibt ein oder zwei typische Bilder, und nur die Signaturen unterscheiden sich:Wenn wir etwas dynamischeres von den Daten abhängig haben möchten, sollten Sie einen anderen Ansatz beachten: Euler-Diagramme.Euler-Diagramme
Im Gegensatz zu Venn-Diagrammen werden hier Form und Position der Figuren in der Ebene ausgewählt, um die Beziehung von Mengen oder Konzepten darzustellen. Wenn eine Kreuzung leer ist, überlappen sich die Figuren auch nicht, wann immer dies möglich ist, wie in der Figur über Pflanzen und Tiere.Bitte beachten Sie, dass sich die Zeichnung zur Frage in der Vorlesung von den beiden anderen unterscheidet. Es ist nicht nur die Position der Figuren wichtig, sondern auch die Größe der Schnittpunkte - jeder Humor ist in ihnen eingeschlossen.Diese Idee kann für unsere Aufgabe verwendet werden. Nehmen Sie zwei oder drei Sätze und zeichnen Sie Kreise mit Flächen, die proportional zur Größe dieser Sätze sind. Und dann werden wir versuchen, die Kreise in der Ebene so anzuordnen, dass die Überlappungsbereiche auch proportional zur Größe der Schnittpunkte sind.Genau das macht das Paket (trotz seines Namens)matplotlib-venn : Das Zeichnen von zwei Sätzen mit exakten Proportionen ist einfach. Aber schon um drei kann die Methode fehlschlagen. Zum Beispiel sei eine der drei Mengen genau der Schnittpunkt der beiden anderen:Das Bild sieht nicht gut aus, es erschien ein seltsamer Bereich mit der Nummer 0. Es ist jedoch nicht verwunderlich, da der Schnittpunkt zweier Kreise nicht als Kreis dargestellt werden kann.Und hier ist ein noch deprimierenderes Beispiel: zwei Mengen und ihre symmetrische Differenz (Vereinigung minus Schnittpunkt):Es stellte sich als etwas völlig Seltsames heraus: Achten Sie darauf, wie viele Nullen es gibt!Das erste Beispiel kann weiterhin gespeichert werden, wenn Rechtecke anstelle von Kreisen verwendet werden (der Schnittpunkt von Rechtecken ist ebenfalls ein Rechteck), während das zweite Beispiel mindestens nicht konvexe Formen erfordert. Nun, mehr als drei Sätze, dieses Paket wird im Prinzip nicht unterstützt.Ich kenne keine anderen öffentlichen Tools für Python, die den Euler-Venn-Ansatz entwickeln, und die Geschichte meiner eigenen Experimente wird noch weiter gehen. Bevor ich fortfahre, werde ich einen kleinen Exkurs machen, um zu erklären, warum ich überhaupt die Aufgabe übernommen habe, Sets zu visualisieren.
zwei Sätzen mit exakten Proportionen ist einfach. Aber schon um drei kann die Methode fehlschlagen. Zum Beispiel sei eine der drei Mengen genau der Schnittpunkt der beiden anderen:Das Bild sieht nicht gut aus, es erschien ein seltsamer Bereich mit der Nummer 0. Es ist jedoch nicht verwunderlich, da der Schnittpunkt zweier Kreise nicht als Kreis dargestellt werden kann.Und hier ist ein noch deprimierenderes Beispiel: zwei Mengen und ihre symmetrische Differenz (Vereinigung minus Schnittpunkt):Es stellte sich als etwas völlig Seltsames heraus: Achten Sie darauf, wie viele Nullen es gibt!Das erste Beispiel kann weiterhin gespeichert werden, wenn Rechtecke anstelle von Kreisen verwendet werden (der Schnittpunkt von Rechtecken ist ebenfalls ein Rechteck), während das zweite Beispiel mindestens nicht konvexe Formen erfordert. Nun, mehr als drei Sätze, dieses Paket wird im Prinzip nicht unterstützt.Ich kenne keine anderen öffentlichen Tools für Python, die den Euler-Venn-Ansatz entwickeln, und die Geschichte meiner eigenen Experimente wird noch weiter gehen. Bevor ich fortfahre, werde ich einen kleinen Exkurs machen, um zu erklären, warum ich überhaupt die Aufgabe übernommen habe, Sets zu visualisieren.Ein paar Worte zur API zum Erstellen optimaler Routen
Wie gesagt, unsere Abteilung macht Yandex.routing. Eine unserer Dienstleistungen hilft Online-Shops, Lieferservices und jedem Unternehmen, dessen Geschäft die Logistik umfasst, optimale Transportwege zu entwickeln.Clients interagieren mit dem Dienst, indem sie API-Anforderungen senden. Jede Anfrage enthält eine Liste von Bestellungen (Lieferpunkten) mit Koordinaten, Lieferintervallen usw. sowie eine Liste von Maschinen, die Bestellungen liefern müssen. Unser Algorithmus verarbeitet all diese Daten und erstellt optimale Routen unter Berücksichtigung von Staus, Fahrzeugkapazität und vielem mehr.Wir haben Hunderte, nicht Millionen von Kunden, wie die beliebten Yandex B2C-Dienste. Daher ist uns das Glück jedes Kunden besonders wichtig. Außerdem ist es möglich, ihm mehr Aufmerksamkeit zu schenken und tiefer in seine Aufgaben einzutauchen. Insbesondere hierfür ist es hilfreich, Tools zu haben, mit denen Sie verstehen, welche Anfragen der Kunde an uns sendet.Ich werde ein Beispiel geben. Angenommen, an einem Tag gingen 24 Anfragen von Romashka ein. Dies kann bedeuten, dass:- Sie arbeiten im ganzen Land und haben 24 Routensätze für 24 Lager gebaut.
- Es gibt nur ein Lager, aber der Kunde erhält ständig neue Bestellungen. Um sie zu berücksichtigen, müssen Sie die Routen stündlich aktualisieren.
- Anfragen des Kunden werden mit einem Fehler gebildet, aufgrund dessen er 24 Mal hintereinander keine gute Lösung für eine einzelne Aufgabe finden konnte.
A priori ist völlig unklar, was wirklich passiert ist. Wenn wir jedoch schnell 24 Sätze von Auftrags-IDs vergleichen können, wird die Situation sofort klar. Wenn sie sich überhaupt nicht schneiden, ist dies der erste Fall (24 Lagerhäuser). Wenn die Sätze von einem zum anderen fließen, der zweite (geplante Aktualisierung der Routen). Nun, 24 fast identische Sets sind ein mögliches Zeichen dafür, dass der Kunde Hilfe benötigt.Vereinfachen Sie die Aufgabe: von Kreisen zu Streifen
Für einige Zeit habe ich das matplotlib-venn-Paket verwendet, aber die Einschränkung von „zweieinhalb“ Sätzen war natürlich frustrierend. Ich dachte über verschiedene Herangehensweisen an das Problem nach und beschloss, von Kreisen und allgemein zweidimensionalen Grundelementen zu eindimensionalen horizontalen Streifen überzugehen. Schnittpunkte können dann vertikal überlagert dargestellt werden:Lineare Dimensionen werden vom Auge besser wahrgenommen als Quadrate, komplexe Trigonometrie ist für die Konstruktion nicht erforderlich, und der Abstand von Sätzen entlang der Y-Achse macht den Graphen weniger überlastet. Darüber hinaus verbessert sich unser erstes erfolgloses Beispiel (zwei Mengen und ihre Schnittmenge als dritte) von selbst:Das Problem mit der symmetrischen Differenz ist immer noch da. Aber wir werden es als Alexander der Große mit dem gordischen Knoten behandeln: Lassen Sie uns, falls nötig, eines der Sets in zwei Teile schneiden:Das rote Set ist in zwei statt in einem Streifen dargestellt, aber daran ist nichts auszusetzen. Beide sind auf gleicher Höhe und haben die gleiche Farbe, so dass ihre Einheit optisch gut lesbar ist.Es ist leicht zu überprüfen, ob auf diese Weise unter genauer Einhaltung der Proportionen drei beliebige Sätze dargestellt werden können. Somit ist das Problem für gleich 2 oder 3 kann als aufgelöst betrachtet werden. Ein weiteres Plus dieses Ansatzes ist, dass es einfach ist, auf eine beliebige Anzahl von Sätzen anzuwenden, was wir sehr bald tun werden. Alles, was benötigt wird, ist, nicht einen, sondern eine beliebige Anzahl von Zeilenumbrüchen aufzulösen. Aber zuerst eine kleine einfache Kombinatorik.Ein bisschen Rechnen
Schauen wir uns das Venn-Diagramm mit drei Kreisen an und berechnen, wie viele Bereiche sich die Kreise teilen:Jeder Bereich wird dadurch bestimmt, ob er innerhalb oder außerhalb jedes der drei Kreise liegt, aber der äußere Bereich ist überflüssig. Insgesamt bekommen wir . Andere Positionen der drei Kreise können weniger Bereiche bis zu 1 ergeben, wenn alle Kreise zusammenfallen. Wenn wir dieses Argument von Kreisen auf Mengen übertragen, erhalten wir jedesSätze brechen sich nicht mehr als solcher Elementarteile. Es ist wichtig, dass jeder dieser Teile entweder vollständig oder nicht vollständig in einem dieser Sets enthalten ist. In unseren neuen Diagrammen sind Spalten solche elementaren Teile.Weitere Sets!
Wir wollen diese Schemata also auf den Fall verallgemeinern :Zum Sätze, mit denen wir ein Gitter bekommen Zeilen und Spalten, wie wir gerade berechnet haben. Es bleibt, jede Zeile durchzugehen und die Zellen auszufüllen, die den in diesem Satz enthaltenen Elementarteilen entsprechen. Nehmen Sie zur Veranschaulichung ein Modellbeispiel mit fünf Sätzen:programming_languages = {'python', 'r', 'c', 'c++', 'java', 'julia'}
geographic_places = {'java', 'buffalo', 'turkey', 'moscow'}
letters = {'a', 'r', 'c', 'i', 'z'}
human_names = {'robin', 'julia', 'alice', 'bob', 'conrad'}
animals = {'python', 'buffalo', 'turkey', 'cat', 'dog', 'robin'}
Wenn wir wie oben beschrieben handeln, erhalten wir die folgende Abbildung:Es liest sich schlecht: Es gibt zu viele Lücken in den Zeilen, alle Sätze werden in Kohl gehackt. Aber da wir keine Pausen mögen, warum nicht direkt die Aufgabe festlegen, sie zu minimieren? Schließlich ist die Reihenfolge der Spalten unbedeutend, nichts hindert uns daran, sie nach Belieben neu anzuordnen. Wir kommen zu diesem Problem: Finden Sie eine Permutation der Spalten einer gegebenen Matrix von Nullen und Einsen mit einer minimalen Anzahl von Lücken zwischen Einheiten in Zeilen.Wie mir später gesagt wurde, ist dies praktisch die Aufgabe eines reisenden Verkäufers in der Hamming-Metrik , es ist NP-vollständig . Wenn nur wenige Spalten vorhanden sind (z. B. nicht mehr als 12), können Sie die erforderliche Permutation durch umfassende Suche finden. Andernfalls müssen Sie auf bestimmte Heuristiken zurückgreifen.Wir wenden einen einfachen gierigen Algorithmus an. Nennen wir die Ähnlichkeit zweier Spalten die Anzahl der Positionen, an denen die Werte in diesen Spalten übereinstimmen. Nehmen Sie die beiden ähnlichsten Spalten und setzen Sie sie zusammen. Als nächstes werden wir die Sequenz auf beiden Seiten dieses Paares eifrig aufbauen. Unter den verbleibenden Spalten finden wir diejenige, die einer der beiden am ähnlichsten ist. Fügen Sie sie hinzu - und so weiter mit den übrigen Spalten.Hier sind die Zahlen vor und nach der Anwendung des Algorithmus:Es ist viel besser geworden. In diesem Stadium hatte ich das Gefühl, dass etwas Nützliches herauskam. Nachdem ich experimentiert hatte, bemerkte ich, dass der Algorithmus dazu neigt, bei lokalen Minima zu bleiben. Wir haben es geschafft, dies mit einer einfachen Randomisierung gut zu behandeln: Wir machen ein wenig Rauschen über die Ähnlichkeit der Spalten, führen den Algorithmus aus, wiederholen 1000 Mal, wählen die beste von 1000 Lösungen aus.Das Ergebnis ist bereits ein ziemlich funktionierendes Werkzeug, aber Sie können weitere nützliche Informationen hinzufügen. Ich habe zwei zusätzliche Diagramme erstellt: Die Größen der Originalsätze werden rechts angezeigt, und das obere Diagramm für jede Kreuzung zeigt, in wie vielen unserer Sätze es sich befindet. Tatsächlich ist dies nichts anderes als die Summe unserer Binärmatrix in Zeilen (rechts) und in Spalten (oben):Ich habe auch die Option hinzugefügt, die Sätze selbst (d. H. Zeilen) nach dem gleichen Prinzip wie Spalten zu ordnen: mit Minimierung der Anzahl der Unterbrechungen. Infolgedessen werden ähnliche Sätze gruppiert:Anwendung in der Arbeit
Zunächst begann ich natürlich, das neue Tool für die Aufgabe zu verwenden, für die es erstellt wurde: Kundenanfragen für unsere API zu untersuchen. Die Ergebnisse haben mir gefallen. So sah zum Beispiel der Arbeitstag eines Kunden aus. Jede Zeile ist eine Anforderung an die API (viele IDs der darin enthaltenen Bestellungen), und die Signatur in der Mitte ist der Zeitpunkt für das Senden von Anforderungen:Den ganzen Tag in voller Sicht. Um 10:49 Uhr schickte eine Kundenlogistik mit einem Intervall von 23 Sekunden zwei identische Anfragen mit 129 Bestellungen. Von 11:25 bis 15:53 gab es drei Anfragen mit unterschiedlichen 152 Bestellungen. Um 16:43 Uhr kam eine dritte einmalige Anfrage mit 114 Bestellungen an. Um diese Anfrage zu lösen, hat der Logistiker dann vier manuelle Änderungen vorgenommen (dies kann über unsere Benutzeroberfläche erfolgen).Und so sieht ein idealer Tag aus: Alle unabhängigen Aufgaben wurden einmal gelöst, es waren keine Korrekturen oder Auswahl von Parametern erforderlich:Und hier ist ein Beispiel eines Kunden, der alle 15 bis 30 Minuten Anfragen sendet, um in Echtzeit eingegangene Bestellungen zu berücksichtigen:Selbst bei 50 Sätzen zeigte der Algorithmus deutlich die in den Daten verborgene Struktur. Sie können sehen, wie alte Aufträge aus Anforderungen entfernt und bei der Ausführung durch neue ersetzt wurden.Mit einem Wort, ich habe es vollständig geschafft, meinen Arbeitsbedarf mit dem erstellten Tool zu schließen.Banane für Skala (nicht wirklich)
Während ich bestehende Ansätze studierte, stieß ich mehrmals auf eine Zeichnung aus der Zeitschrift Nature , in der die Genome von Bananen und fünf anderen Pflanzen verglichen werden:Beachten Sie, wie sich die Größen der Regionen auf 13 und 149 Elemente beziehen (durch Pfeile gekennzeichnet): Die zweite ist um ein Vielfaches kleiner. Von Verhältnismäßigkeit ist also keine Rede.Natürlich wollte ich mich an solchen Daten versuchen, aber das Ergebnis gefiel mir nicht:Die Grafik sieht chaotisch aus. Der Grund ist, dass erstens fast alle Kreuzungen (62 von 63 möglichen) nicht leer sind und zweitens sich ihre Größen um drei Größenordnungen unterscheiden. Infolgedessen werden numerische Anmerkungen sehr überfüllt.Um mein Tool für solche Daten bequem zu machen, habe ich mehrere Parameter hinzugefügt. Zum einen können Sie die Spaltenbreiten teilweise ausrichten, zum anderen werden Anmerkungen ausgeblendet, wenn die Spaltenbreite unter einem angegebenen Wert liegt.Diese Option ist recht gut zu lesen, aber dafür musste ich die genaue Proportionalität der Größe opfern.Wie sich herausstellte, hatte ich Recht, wenn ich auf das Gebiet der Bioinformatik achtete. Ich habe Reddit einen Beitrag über mein Tool in den Bereichen R / Visualisierung , R / Datascience und R / Bioinformatik gesendet. Letzteres wurde am besten angenommen, die Bewertungen waren wirklich begeistert.Produktkonvertierung
Am Ende wurde mir klar, dass es sich um ein gutes Werkzeug handelt, das für viele nützlich sein kann. Daher entstand die Idee, daraus ein vollständiges Open-Source-Paket zu machen. Natürlich war die Zustimmung der Führer notwendig, aber die Jungs hatten nicht nur nichts dagegen, sondern unterstützten mich auch, wofür ich ihnen vielmals danke.Ich arbeitete hauptsächlich an Wochenenden und begann, den Code schrittweise auf den Markt zu bringen, Tests zu schreiben und mich mit dem Paketsystem in Python zu befassen. Dies ist mein erstes Projekt dieser Art, daher hat es mehrere Monate gedauert.Es war auch eine schwierige Aufgabe, einen guten Namen zu finden, und ich kam schlecht damit zurecht. Ausgewählter Name (super venn) kann nicht als erfolgreich bezeichnet werden, da das gesamte Salz der Venn-Diagramme statisch ist, aber im Gegenteil, ich habe versucht, die tatsächlichen Dimensionen genau darzustellen. Aber als ich das merkte, wurde das Projekt bereits veröffentlicht und es war zu spät, um den Namen zu ändern.Analoga
Natürlich war ich nicht der erste, der diesen Ansatz zur Visualisierung von Mengen verwendete: Die Idee liegt im Allgemeinen an der Oberfläche. Es gibt zwei ähnliche Webanwendungen im Open Access: RainBio und Linear Diagram Generator , die zweite verwendet genau das gleiche Prinzip wie meine. (Die Autoren haben auch einen Artikel auf 40 Seiten geschrieben , in dem experimentell verglichen wurde, was besser wahrgenommen wird - horizontale oder vertikale Linien, dünn oder dick usw. Es schien mir sogar, dass der Artikel für sie primär war, und das Werkzeug selbst war nur eine Ergänzung dazu .)Um diese beiden Anwendungen mit meinem Paket zu vergleichen, verwenden wir das Beispiel erneut mit Worten. Sie können selbst entscheiden, welche Option lesbarer und informativer ist.RainbioLinearer DiagrammgeneratorSupervennAndere Ansätze
Man kann nur das UpSet- Projekt erwähnen , das als Webanwendung und Pakete für R und Python existiert. Das Grundprinzip kann anhand der Anzeige der Bananengenomdaten verstanden werden. Das Diagramm ist rechts beschnitten, es werden nur 30 Schnittpunkte von 62 angezeigt:Interessanterweise erhalten Sie fast dasselbe, wenn Sie Supervenn verwenden, um die Spalten nach Breite zu sortieren und die Spalten mithilfe der Option für die Breitenausrichtung gleich zu machen, obwohl dies nicht sofort erkennbar ist. Es fehlen lediglich vertikale Linien mit Schnittgrößen. Stattdessen werden am unteren Rand des Diagramms nur Zahlen angezeigt:Beim Schreiben dieses Textes habe ich versucht, die Python-Version von UpSet zu verwenden, aber ich habe festgestellt, dass das Paket seit 2016 nicht aktualisiert wurde, die Dokumentation das Eingabeformat in keiner Weise beschreibt und der Testfall mit einem Fehler abstürzt. Die Webversion funktioniert, sie hat viele nützliche Hilfsfunktionen, aber die Arbeit damit ist aufgrund der komplizierten Art der Dateneingabe ziemlich schwierig.Schließlich ist online ein interessanter Überblick über Set-Visualisierungstechniken verfügbar . Nicht alle von ihnen sind als Softwaretools implementiert. Hier sind einige Bilder, um Ihre Aufmerksamkeit zu erregen:Ich war besonders an der Bubble-Sets- Methode (untere Reihe) interessiert , mit der Sie kleine Sets über einer bestimmten Anordnung von Elementen in einer Ebene anzeigen können. Dies kann beispielsweise praktisch sein, wenn die Elemente an der Zeitachse (a) oder an der Karte (b) angebracht sind. Bisher wurde diese Methode nur in Java und JavaScript implementiert (die Links befinden sich auf der Autorenseite), und es wäre großartig, wenn sich jemand verpflichten würde, sie nach Python zu portieren.Ich schickte Briefe mit einer kurzen Beschreibung des Projekts an die Autoren von UpSet und die Bewertung und erhielt gute Bewertungen. Zwei von ihnen versprachen sogar, Supervenn in ihre Vorlesungen zur Visualisierung von Sets aufzunehmen.Fazit
Wenn Sie das Paket verwenden möchten, ist es auf GitHub und in PyPI: pip install Aufsicht verfügbar . Ich bin dankbar für Kommentare zum Code und zur Verwendung des Pakets, für Ideen und Kritik. Ich würde mich besonders freuen, Empfehlungen zur Verbesserung des Spaltenpermutationsalgorithmus für große zu lesen und Tipps zum Schreiben von Tests für Diagrammfunktionen. Vielen Dank für Ihre Aufmerksamkeit!Verweise
1. John Venn. Zur schematischen und mechanischen Darstellung von Sätzen und Argumenten . The London, Edinburgh and Dublin Philosophical Magazine, Juli 1880.2. J.-B. Lamy und R. Tsopra. RainBio: Proportionale Visualisierung großer Mengen in der Biologie . IEEE-Transaktionen zu Visualisierung und Computergrafik, doi: 10.1109 / TVCG.2019.2921544.3. Peter Rodgers, Gem Stapleton und Peter Chapman. Visualisieren von Sets mit linearen Diagrammen . ACM-Transaktionen zur Interaktion zwischen Computern und Menschen 22 (6) pp. 27: 1-27: 39 September 2015. doi: 10.1145 / 2810012.4. Alexander Lex, Nils Gehlenborg, Hendrik Strobelt, Romain Vuillemot, Hanspeter PfisterUpSet: Visualisierung sich überschneidender Mengen. IEEE-Transaktionen zu Visualisierung und Computergrafik (InfoVis'14), 2014.5. Bilal Alsallakh, Luana Micallef, Wolfgang Aigner, Helwig Hauser, Silvia Miksch und Peter Rodgers. Der Stand der Set-Visualisierung . Computergrafik-Forum. Band 00 (2015), Nummer 0 S. 1–27 10.1111 / cgf.12722.6. Christopher Collins, Gerald Penn und Sheelagh Carpendale. Blasensätze: Aufdecken von Mengenbeziehungen zu Isokonturen über vorhandene Visualisierungen . IEEE Trans. über Visualisierung und Computergrafik (Proc. der IEEE Conf. on Information Visualization), vol. 15, iss. 6, pp. 1009–1016, 2009.